【RL】Scaling RL Compute for LLMs
Note
- ScaleRL配方中包含了哪些关键技术选择?这些选择是如何影响渐近性能和计算效率的?
- 异步Pipeline-RL设置:提高训练稳定性和效率。
- 强制长度中断:防止推理输出长度爆炸,提高训练稳定性。
- 截断的重要性采样RL损失(CISPO):提高渐近性能。
- 提示级损失平均:优化损失聚合方式,提高计算效率。
- 批次级优势归一化:提高计算效率。
- FP32精度在logits:减少数值不匹配,提高渐近性能。
- 零方差过滤:排除贡献为零的提示,提高计算效率。
- 无正重采样:排除通过率过高的提示,提高计算效率。
- 这些技术选择通过不同的方式影响了渐近性能和计算效率。例如,异步Pipeline-RL设置和强制长度中断主要提高训练稳定性和效率;截断的重要性采样RL损失和FP32精度修复显著提高渐近性能;提示级损失平均、批次级优势归一化、零方差过滤和无正重采样主要提高计算效率。
- ScaleRL在不同训练轴上的扩展表现出怎样的可预测性?具体表现在哪些方面?
- 更大的批量大小:在较大的批量大小下,ScaleRL的训练稳定性和性能均表现出色。
- 更长的生成长度:尽管增加生成长度会降低早期的进展速度,但最终提高了渐近性能。
- 多任务RL:在同时进行数学和代码任务的训练中,ScaleRL表现出清晰的并行幂律趋势。
- 更大的MoE模型:在训练更大的MoE模型时,ScaleRL保持了可预测的扩展行为,且性能更高。
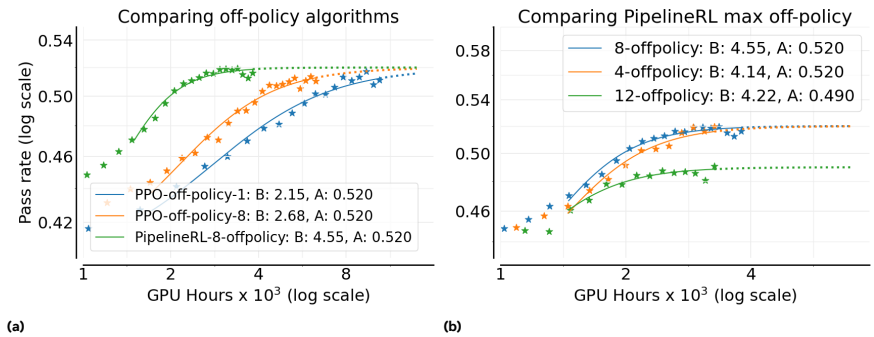
- 论文里的 “8 off-policy”= k=8,含义是:一次生成的数据被用于做 8 次策略更新(PPO-off-policy-k),或在 PipelineRL-k 里训练器最多领先生成器 8 步。
- CISPO略优于GSPO,两者均优于DAPO(性能上限A更高)
文章目录
- Note
- 一、研究背景
- 二、研究方法
- 三、实验设计
- 1、异步RL的设置
- 2、Loss Type
- 3、Loss Aggregation
- 4、 Advantage Normalization
- 5、Zero-Variance Filtering
- 6、Adaptive Prompt Filtering
- 四、实验效果
- 五、论文评价
- 1、论文优点
- 2、不足和反思
- Reference
一、研究背景
论文:The Art of Scaling Reinforcement Learning Compute for LLMs
链接:https://arxiv.org/abs/2510.13786
- 研究问题:这篇文章要解决的问题是如何有效地扩展强化学习(RL)计算以训练大型语言模型(LLMs)。尽管预训练已经建立了可预测的扩展方法,但RL计算的扩展方法仍然缺乏科学性和系统性。
- 研究难点:该问题的研究难点包括:如何系统地评估和预测RL计算的扩展性,如何在不同的设计选择中找到最佳的平衡点,以及如何在不增加计算成本的情况下进行大规模实验。
- 相关工作:该问题的研究相关工作包括:OpenAI的o1系列模型、Deepseek-R1-Zero、MiniMax和Magistral等方法,这些工作主要集中在特定算法或模型上的优化,而不是通用的扩展方法。
二、研究方法
这篇论文提出了一个系统的研究框架,用于分析和预测LLMs中RL计算的扩展性。具体来说,
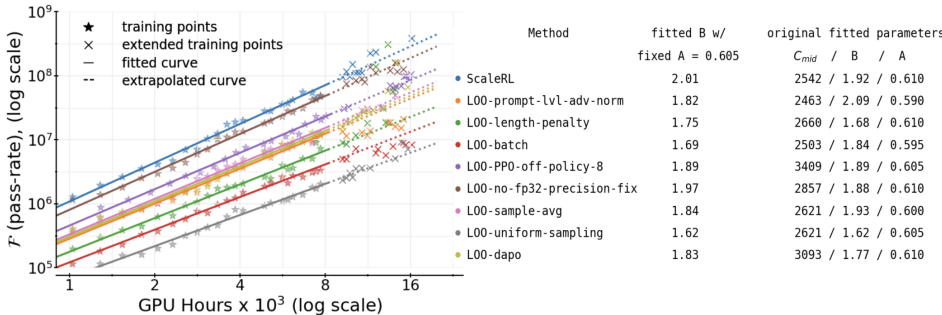
- 理论分析:首先,作者提出了一个基于S型饱和曲线的理论框架,用于描述验证集上的期望奖励与训练计算之间的关系。公式如下:RC=A−D/CBR_C=A-D / C^BRC=A−D/CB
其中,RCR_CRC 表示期望奖励,CCC 表示训练计算,AAA 表示渐近通过率,BBB 是扩展指数,DDD 是一个常数,Cmid C_{\text {mid }}Cmid 是RL性能曲线的中点。 - 设计选择:通过对多种常见设计选择(如损失聚合、归一化、课程学习和离线策略算法)进行消融实验,分析了它们对渐近性能和计算效率的影响。
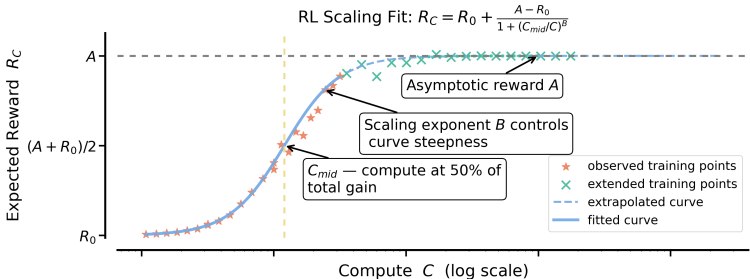
- 最佳实践配方:基于上述分析,提出了ScaleRL(可扩展RL)配方,结合了异步Pipeline-RL设置、强制长度中断、截断的重要性采样RL损失(CISPO)、提示级损失平均、批次级优势归一化、FP32精度在logits、零方差过滤和无正重采样等技术。
三、实验设计
- 数据集:使用Polaris-53K数据集进行数学RL实验,批量大小为768,每个提示有16代。
- 训练设置:训练使用序列长度为16,384个令牌,其中12,288个用于思考,2,048个用于解决方案,另外2,048个用于输入提示。采用异步Pipeline-RL设置,批量大小为48,中断次数为8。
- 参数配置:初始算法类似于GRPO,不包括KL正则化项,并使用不对称DAPO剪辑。FP32精度用于logits,损失聚合采用提示平均,优势归一化采用批次级归一化,零方差过滤和无正重采样。
1、异步RL的设置
- PPO-off-policy-k(Qwen3、ProRL使用):每次用old policy对B个prompt进行生成,分成k个大小为
B^的mini batch(k=B / B^),每次用B^个prompt进行梯度更新。 - Pipeline-RL-k(Magistral使用):每当trainer完成一次参数更新,立即将新的参数load到生成器中。生成器保留用旧参数已经生成的token和kv cache,而继续用新参数生成后续token。本文里作者引入参数k,表示限制训练器不会超过生成器k个step。
- Background Knowledge:现代RL中的生成和训练往往由不同的框架实现,因此生成LLM和训练LLM在计算机中是2个独立的、参数和实现框架都(可能)不同的模型。
Conclusion
- Pipeline RL 和PPO-off-policy相比,上限A相同,但训练效率B更高。
- Pipeline RL的k取8最佳。
注意:
On-policy:每次训练都要用最新模型生成的新轨迹。
Off-policy:可以重复利用旧模型生成的数据,或者来自其他策略的数据来训练,这样更省算力、训练效率更高。
2、Loss Type
- DAPO(ByteDance Seed):在token-level进行clip,被clip掉的token对梯度无贡献
- GSPO(Qwen):在sequence-level进行clip
- CISPO(Minimax):从vanilla REINFORCE出发,在重要性采样上使用clip和stop gradient操作,即使clip也会保留所有token的梯度贡献。
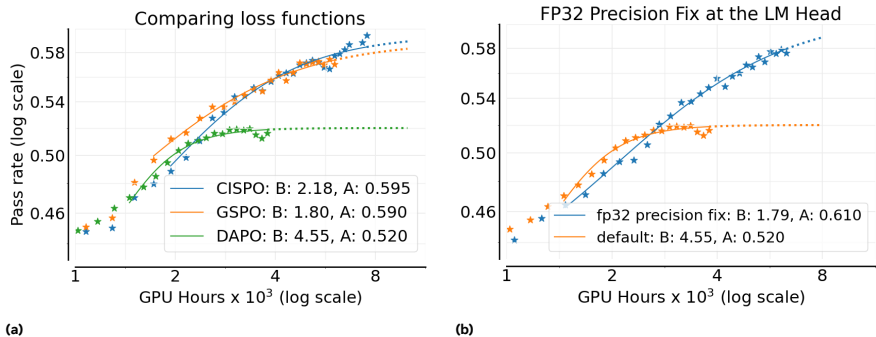
结论:CISPO略优于GSPO,两者均优于DAPO(性能上限A更高)
3、Loss Aggregation
作者对比了三种策略:(1)样本平均,即每个轨迹内部所有token先求平均(GRPO);(2)Prompt平均,即每个prompt的所有轨迹内部先求平均(DAPO);(3)Token平均,即一个batch中所有token求平均。
Conclusion(上图左):Prompt平均效果最好。
4、 Advantage Normalization
- 不同变体的差别在于,在计算Adv的时候,是否要除以reward的std,以及如何计算reward的std
- 作者对比了三种策略:(1)在单个prompt的所有rollout间计算std(GRPO);(2)在一个batch的所有rollout间计算std;(3)不使用std(Dr.GRPO)。
Conclusion:(上图右)作者观察到三者性能相似,由于(2)在理论上更优,所以使用(2)。
5、Zero-Variance Filtering
Conclusion:作者验证了,过滤掉零方差(所有rollout具有相同reward)的prompt,能带来提升
6、Adaptive Prompt Filtering
- Polaris中提出了一种简单的策略,用来过滤掉过于简单、不适合RL训练的prompt。其核心思想是,如果一个prompt的平均准确率超过0.9,就将其永久移除。
- Conclusion(上图右):作者验证了该策略提升了训练的上限A。
四、实验效果
- 渐近性能:不同设计选择的渐近性能有所不同,但通过适当的组合可以显著提高性能。
- 计算效率:某些设计选择主要调节计算效率,而不显著改变渐近性能。例如,批量级归一化和FP32精度修复显著提高了计算效率。
- 可扩展性:ScaleRL在不同训练轴上的扩展表现出可预测性,包括在更大的批量大小、更长的生成长度、多任务RL和更大的MoE模型上。
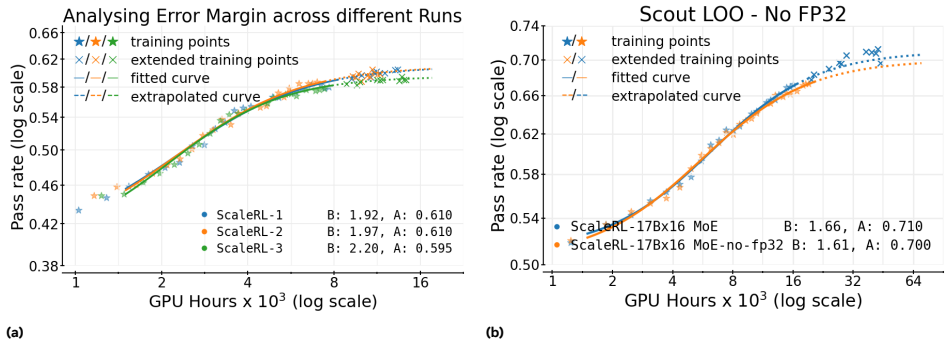
- 消融实验:通过逐一遍历设计选择,验证了每个选择在不同组合中的有效性。ScaleRL在所有实验中均表现出色,略微优于其他变体。
五、论文评价
1、论文优点
- 系统性研究:论文进行了超过400,000 GPU小时的大规模系统性研究,定义了分析和预测LLM中RL扩展的框架。
- 可预测的扩展曲线:提出了使用S型饱和曲线来拟合RL训练的性能和计算成本之间的关系,使得研究人员能够从较低计算成本的运行中推断出较高计算预算下的性能。
- 最佳实践配方:提出了ScaleRL配方,并在单个RL运行中成功扩展到100,000 GPU小时,验证了其有效性。
- 设计选择的影响分析:通过消融实验分析了多种常见设计选择对渐近性能和计算效率的影响,揭示了不同设计选择的累积效应。
- 可扩展性验证:在多个训练轴上增加计算时,ScaleRL保持了可预测的扩展,包括更大的批量大小、更长的生成长度、多任务RL和更大的MoE模型。
- 实用性和创新性:不仅提供了科学框架,还提供了一个实用的配方,使RL训练更接近于预训练中实现的预测性。
2、不足和反思
- 单次实验的限制:尽管ScaleRL在大规模实验中表现出色,但单次实验的结果仍然具有一定的随机性。未来工作可以通过多次独立实验来估计拟合扩展曲线的变异性,从而提高结果的可靠性。
- 设计选择的冗余性:尽管个别设计选择在组合配方中可能显得冗余,但它们在特定配置下仍然可以提供稳定性或鲁棒性。未来工作可以进一步研究这些设计选择在特定情况下的重要性。
- 多任务RL的可扩展性:虽然实验主要集中在数学领域,但多任务RL的可扩展性仍需进一步研究。未来工作可以探索不同训练数据混合对计算扩展预测性的影响。
- 结构化奖励和密集生成验证器:未来工作可以包括引入结构化或密集奖励以及更计算密集的生成验证器,以找到最佳的RL训练计算分配。
- 其他后训练范式的扩展:所介绍的方法论框架也可以应用于研究多回合RL、代理交互和长形式推理等其他后训练范式的扩展行为。
Reference
[1] https://arxiv.org/abs/2510.13786
[2] 大模型RL各种trick
[3] LLM大模型:post-train实战 - 使用GRPO微调LLM
[4] GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归