【大模型实战笔记 5】基于Streamlit的多模态AI聊天机器人应用开发实战
《基于Streamlit的多模态AI聊天机器人应用开发实战》
- 《基于Streamlit的多模态AI聊天机器人应用开发实战》
- 1. 项目概述与技术栈
- 2. 架构设计与核心模块
- 2.1 模块化架构设计
- 2.2 状态管理与配置系统
- 3. 核心模块技术实现详解
- 3.1 文本对话模块深度解析
- 3.2 文生图模块技术剖析
- 3.3 语音转文本模块技术实现
- 3.4 文本转语音模块深度优化
- 3.5 图像理解模块多模态技术
- 4. 性能优化与最佳实践
- 4.1 资源管理优化策略
- 4.2 用户体验深度优化
- 4.3 安全稳定性保障
- 5. 部署方案与扩展展望
- 5.1 生产环境部署
- 5.2 技术扩展方向
- 6. 实现效果
1. 项目概述与技术栈
本项目基于OpenAI API和Streamlit框架构建了一个功能完整的多模态AI聊天机器人应用。应用集成了五大核心AI能力:智能文本对话(Chat Completions API)、高质量图像生成(DALL·E 3)、精准语音识别(Whisper)、自然语音合成(TTS)和先进图像理解(GPT-4o)。技术栈采用Python 3.12.4作为开发语言,Streamlit 1.39.0作为Web框架,配合OpenAI官方客户端库、Pillow图像处理库、tiktoken Token计数库和audio-recorder-streamlit音频录制组件。
2. 架构设计与核心模块
2.1 模块化架构设计
项目采用高度模块化的架构设计,每个功能模块独立封装:
- wilber_home.py:主页面和配置中心
- wilber_chat.py:文本对话核心引擎
- wilber_drawing.py:文生图创作工具
- wilber_speech_to_text.py:语音识别引擎
- wilber_text_to_speech.py:语音合成系统
- wilber_vision.py:多模态视觉理解
2.2 状态管理与配置系统
应用使用Streamlit的会话状态机制管理全局状态,通过st.session_state实现API密钥、对话历史等关键数据的持久化。配置系统采用分层设计,基础配置层管理模型参数,功能配置层控制各模块特性,界面配置层处理显示逻辑。配置文件支持热重载,无需重启服务即可生效。
3. 核心模块技术实现详解
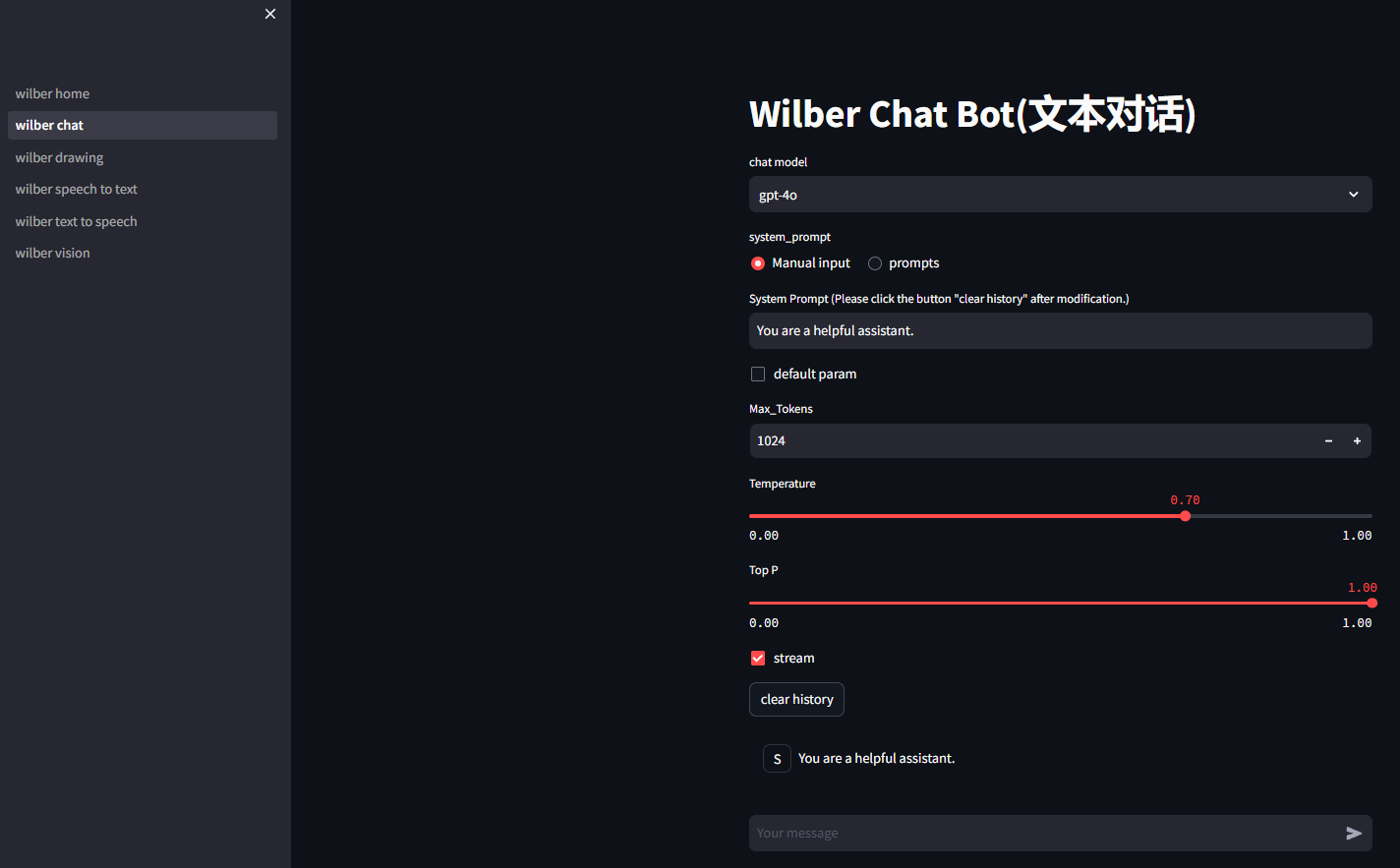
3.1 文本对话模块深度解析
文本对话模块是整个应用的技术核心,实现了基于Chat Completions API的智能对话系统。关键技术包括:
流式输出实现:
if stream:placeholder = st.empty()streaming_text = ''for chunk in response:chunk_text = chunk.choices[0].delta.contentif chunk_text:streaming_text += chunk_textplaceholder.markdown(streaming_text)
这段代码通过创建占位符和逐块处理API响应,实现了实时的流式输出效果,显著提升了用户体验。
Token精确计数算法:
模块实现了基于tiktoken的Token计数功能,针对不同GPT模型采用不同的计算规则。对于GPT-4o系列模型,每条消息基础消耗3个Token,每个name属性消耗1个Token。算法遍历所有消息内容,进行精确编码计算,最后加上回复起始标记的固定开销。
参数调优体系:
- 温度系数(Temperature):控制输出的随机性,范围0.0-1.0
- Top P采样:核采样参数,影响词汇选择范围
- 最大Token数:限制单次响应的长度
- 系统提示词:支持自定义输入和预设模板双模式
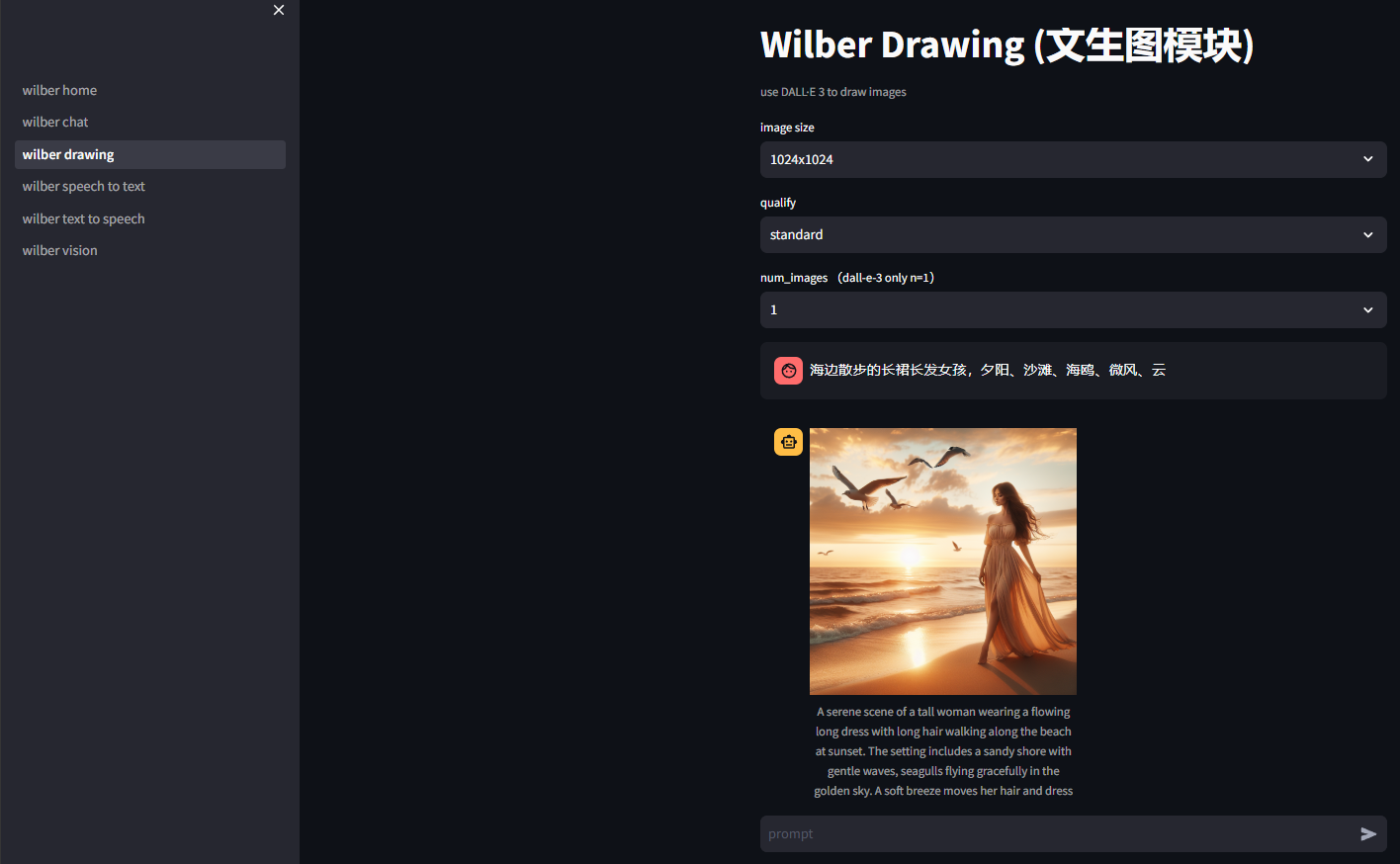
3.2 文生图模块技术剖析
文生图模块基于DALL·E 3模型实现高质量的图像生成,核心特性包括:
多参数图像生成:
response = client.images.generate(model="dall-e-3",prompt=prompt,size="1024x1024",quality="hd",n=1
)
支持多种图像尺寸(1024x1024、1024x1792、1792x1024)和质量等级(standard、hd)。由于DALL·E 3模型限制,每次只能生成单张图像。
智能提示词优化:
模块会自动显示修订后的提示词(revised_prompt),这是DALL·E 3模型对用户原始输入的优化版本。这个特性不仅提升了生成质量,还为用户提供了学习编写更好提示词的机会。
结果展示与下载:
生成的图像采用响应式设计显示,自动适应不同屏幕尺寸。同时提供直接下载链接,用户可方便保存创作成果。
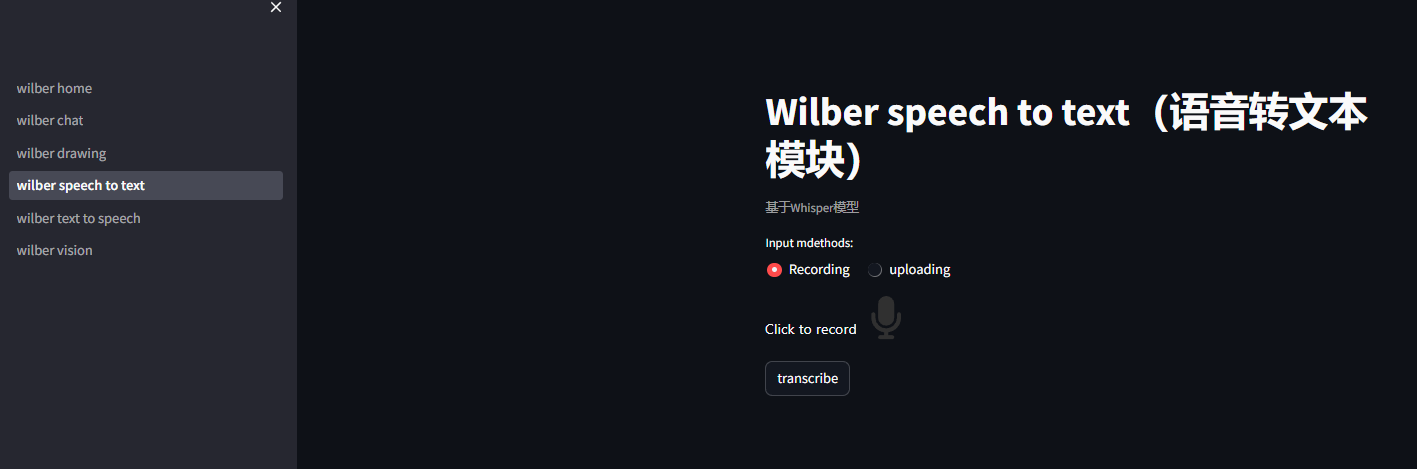
3.3 语音转文本模块技术实现
语音转文本模块基于Whisper-1模型,实现高精度的语音识别:
双输入模式设计:
- 实时录制:通过浏览器API实现,无需额外客户端
- 文件上传:支持WAV、MP3、WEBM等主流格式
中文识别优化:
transcript = client.audio.transcriptions.create(model="whisper-1",file=audio_file,response_format="text",prompt="中文"
)
通过设置语言提示参数,显著提升中文语音的识别准确率。系统自动处理音频格式转换和编码优化,确保识别质量。
文件处理机制:
实现严格的25MB文件大小限制,对上传文件进行格式验证。实时录制的音频自动转换为WAV格式,确保兼容性。
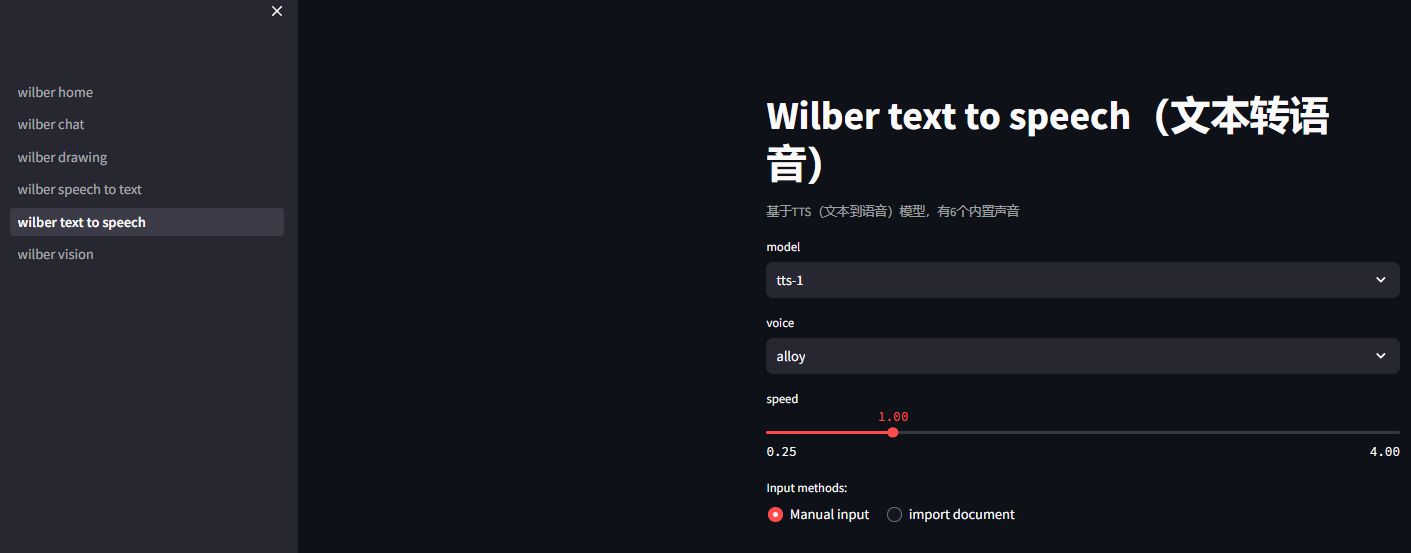
3.4 文本转语音模块深度优化
文本转语音模块提供完整的语音合成解决方案:
个性化语音配置:
- 模型选择:tts-1(快速响应)和tts-1-hd(高质量)
- 音色选项:6种不同音色(alloy、echo、fable、onyx、nova、shimmer)
- 语速调节:0.25倍到4.0倍宽范围调节
临时文件管理:
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as temp_file:speech_file_path = temp_file.name
response.stream_to_file(speech_file_path)
采用临时文件机制生成语音文件,避免磁盘空间占用。文件在会话结束后自动清理,确保资源有效利用。
多输入方式支持:
支持手动文本输入和TXT文件导入双模式,满足不同场景的使用需求。
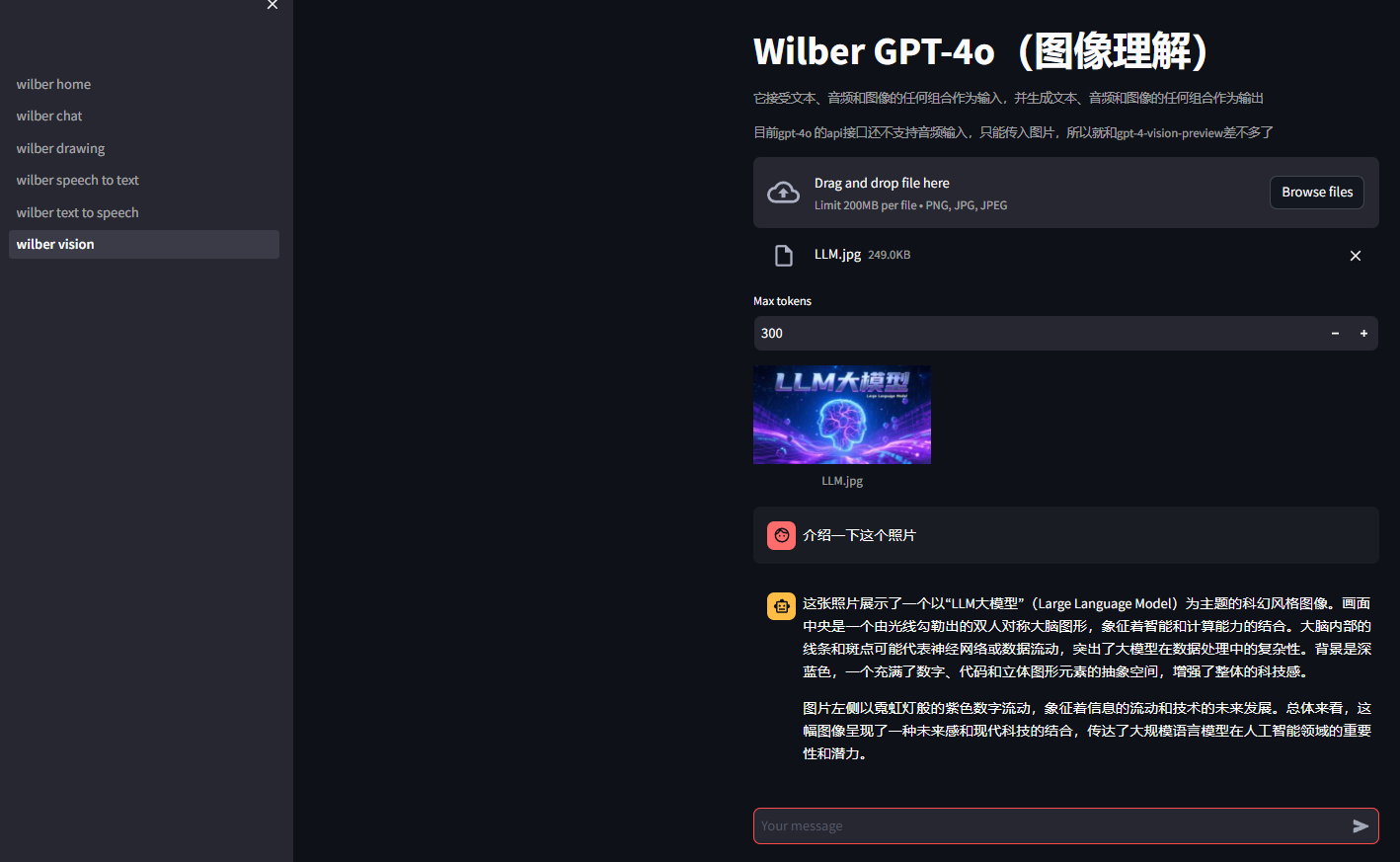
3.5 图像理解模块多模态技术
图像理解模块基于GPT-4o模型实现先进的视觉理解能力:
多模态消息构建:
base64_image = base64.b64encode(bytes_data).decode("utf-8")
payload = {"model": "gpt-4o","messages": [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}]}]
}
将文本提示和Base64编码的图像数据组合成符合API要求的多模态消息结构,实现真正的图文联合理解。
直接API调用策略:
采用HTTP请求直接调用API,绕过官方客户端库的限制,确保能够使用最新的模型特性。实现完整的错误处理机制,优雅处理网络异常和API错误。
图像预处理流程:
- 文件格式验证(PNG、JPG、JPEG)
- 大小检查(5MB限制)
- Base64编码转换
- 请求负载构建
4. 性能优化与最佳实践
4.1 资源管理优化策略
客户端缓存机制:
@st.cache_resource
def get_openai_client(url, api_key):client = OpenAI(base_url=url, api_key=api_key)return client
通过缓存装饰器避免重复创建OpenAI客户端实例,显著降低资源开销,提升应用响应速度。
流式处理优化:
对大文件采用流式处理方式,避免内存峰值问题。音频和图像文件逐步处理,确保系统稳定性。
4.2 用户体验深度优化
实时状态反馈:
- 加载动画和进度指示
- 流式输出的实时更新
- 操作状态的明确提示
错误处理体系:
- 分级错误提示机制
- 网络异常的自动重试
- 用户友好的错误信息
响应式设计:
界面自动适应不同设备尺寸,确保在桌面和移动端都能提供良好的使用体验。
4.3 安全稳定性保障
敏感信息保护:
API密钥通过密码输入框处理,避免明文显示。配置信息采用环境变量和用户输入双重机制。
输入验证机制:
客户端和服务端双重验证,确保数据的有效性和安全性。文件上传进行格式和大小检查。
容错与降级:
实现完整的重试和超时机制,网络波动时自动恢复。部分功能不可用时提供优雅降级。
5. 部署方案与扩展展望
5.1 生产环境部署
推荐使用Docker容器化部署方案,确保环境一致性。配合Nginx反向代理实现负载均衡和HTTPS加密。监控系统集成性能指标收集和错误追踪,确保服务稳定性。
5.2 技术扩展方向
- 多模型提供商集成:降低对单一服务的依赖风险
- 对话历史持久化:支持长期对话上下文管理
- 用户系统设计:实现个性化设置和资源配额
- 插件机制扩展:构建丰富的第三方功能生态
- 移动端深度适配:扩展应用使用场景和用户覆盖面
6. 实现效果