多模态数据湖对接 AI 训练的技术方案
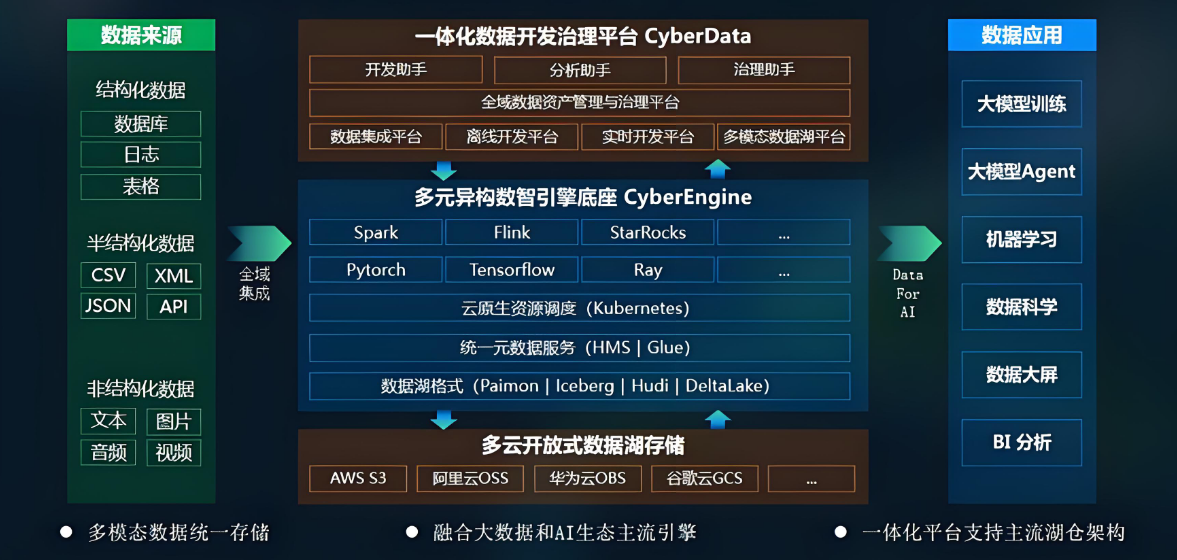
图片来源:(数新智能 cto 原攀峰:datacyber 面向 ai 时代的多模态数据湖设计与实)
数据湖凭借统一存储、格式兼容、生态灵活的特性,能高效整合文本、图像、音频、视频、结构化数据等多模态数据,为AI训练提供“一站式数据供给”——既解决多模态数据“存得下、管得好”的问题,又通过生态集成实现“用得顺”,直接对接AI训练框架(TensorFlow/PyTorch)。以下从多模态AI训练的数据需求、数据湖支撑架构、核心能力、实践流程展开说明:
数据湖支撑多模态AI训练的核心逻辑与实践
一、多模态AI训练对数据的核心需求
多模态AI模型(如CLIP、GPT-4V、文生图模型)的训练,需数据湖满足以下关键需求,否则会导致训练效率低、数据质量差:
- 格式兼容:需存储文本(TXT/JSON)、图像(JPG/PNG)、音频(WAV/MP3)、视频(MP4/AVI)、结构化标注(CSV/Parquet)等异构格式,且支持跨格式关联(如“图像文件路径+文本描述+分类标签”关联)。
- 规模适配:多模态训练数据量通常达PB级(如百万张图像+千万条文本),需数据湖支持弹性扩展,且能低成本存储冷数据(如历史训练样本)。
- 数据治理:需解决“脏数据”(如模糊图像、错误标注)、“数据关联”(如视频帧与字幕对齐)、“版本追溯”(训练数据迭代记录),否则会导致模型精度下降。
- 训练对接:需快速向AI框架输出数据(如按批次加载图像+标注、流式读取实时视频帧),且支持增量训练(新增数据无需全量重训)。
二、数据湖存储多模态数据的核心架构
数据湖通过“分层存储+统一元数据+格式适配”架构,适配多模态数据的多样性与规模性,典型架构如下:
1. 存储分层:按访问频率优化成本与性能
多模态数据访问频率差异大(如训练时高频读取图像,低频访问历史视频),数据湖通过分层存储平衡性能与成本:
- 热存储:采用SSD或云存储(如AWS S3标准层、阿里云OSS热数据),存储近期训练用的高频数据(如近3个月的图像、实时视频流),支持低延迟读取(毫秒级)。
- 温存储:采用HDD或云存储低频层(如S3 Infrequent Access),存储中期数据(如3-12个月的标注文本、音频片段),访问延迟秒级,成本比热存储低30%-50%。
- 冷存储:采用归档存储(如S3 Glacier、阿里云OSS归档),存储历史训练样本(如1年以上的视频数据集),成本极低(仅热存储1/10),访问需解冻(分钟级延迟)。
示例:某文生图模型训练,将“近1个月的高分辨率图像(热存储)+ 6个月的文本描述(温存储)+ 2年的低分辨率历史图像(冷存储)”分层存储,整体存储成本降低60%。
2. 格式兼容:无缝对接多模态数据类型
数据湖原生支持多模态数据的主流格式,无需格式转换即可直接被AI框架读取,核心兼容类型如下:
| 多模态数据类型 | 主流格式 | 数据湖存储适配方式 |
|---|---|---|
| 文本数据 | TXT、JSON、CSV、Parquet | 结构化文本(标注标签)用Parquet存储(支持SQL查询),非结构化文本(文章/对话)用JSON存储 |
| 图像数据 | JPG、PNG、BMP、TFRecord | 原始图像文件直接存储,预处理后的图像(如Resize、归一化)用TFRecord存储(加速训练加载) |
| 音频数据 | WAV、MP3、FLAC | 原始音频文件存储,特征数据(如MFCC)用Parquet存储(供语音模型直接使用) |
| 视频数据 | MP4、AVI、MOV | 原始视频文件存储,视频帧提取后用图像格式存储(如每10帧存1张JPG,供视频理解模型使用) |
| 结构化数据 | Parquet、ORC、CSV | 标注标签(如图像分类标签)、模型超参数用Parquet存储,支持高效关联查询 |
关键能力:数据湖通过“文件系统接口(HDFS/S3 API)+ 表格式(Hudi/Iceberg)”实现格式统一管理——例如用Iceberg表记录“图像文件路径+文本描述+分类标签”的关联元数据,底层图像文件存储在S3,训练时通过元数据快速定位并加载多模态数据。
三、数据湖为AI训练提供的核心支撑能力
数据湖不仅是“存储容器”,更通过数据治理、增量供给、生态集成三大能力,解决多模态AI训练的数据痛点:
1. 多模态数据治理:保障训练数据质量
AI训练的“数据质量决定模型精度”,数据湖通过以下治理能力清洗、标注、管理多模态数据:
-
元数据统一管理:
用数据湖的元数据服务(如Hive Metastore、AWS Glue DataBrew)记录多模态数据的核心属性——例如图像数据的“分辨率、拍摄时间、标注人员”,音频数据的“采样率、时长、语言类型”,支持按元数据筛选训练样本(如“筛选分辨率≥1080p的猫类图像”)。
示例:用Iceberg表存储多模态元数据,表结构包含data_type(文本/图像/音频)、file_path(存储路径)、label(标注标签)、quality_score(数据质量分),AI训练时通过WHERE quality_score > 0.8过滤低质量数据。 -
数据清洗与预处理:
集成Spark/Flink等计算引擎,对多模态数据做标准化处理——- 文本:去重、分词、停用词过滤(如用Spark NLP处理中文文本);
- 图像:Resize(统一尺寸为224×224)、归一化(像素值归一到[0,1])、去模糊(用OpenCV插件);
- 音频:降噪(去除背景噪音)、统一采样率(如16kHz)。
预处理后的数据存储到数据湖的“预处理层”,AI训练直接读取,避免重复计算。
-
标注工具集成:
对接多模态标注工具(如LabelStudio、Amazon SageMaker Ground Truth),将标注结果(如图像分类标签、音频情感标签)写入数据湖,与原始数据关联——例如LabelStudio标注的“图像ID+分类标签”以CSV格式存入数据湖,通过Iceberg表的image_id字段与原始图像文件关联,AI训练时一键加载“图像+标签”。
2. 增量数据供给:支持AI模型增量训练
多模态AI模型(如实时视频分析模型)需持续接入新数据(如每日新增的图像/视频)进行增量训练,数据湖通过以下能力实现“增量数据无缝供给”:
- 增量数据捕获:
用CDC工具(Flink CDC)、流处理引擎(Kafka+Flink)捕获实时新增的多模态数据——例如电商平台每日新增的商品图像(JPG)通过Flink写入数据湖,同时自动生成“图像路径+商品分类标签”的元数据记录。 - 表格式增量同步:
用Hudi/Iceberg/Paimon的增量读取能力,AI训练框架仅加载“上次训练后新增的数据”——例如基于Hudi的MOR表存储图像元数据,训练时通过hoodie.datasource.read.incr.path参数读取近1天新增的图像记录,避免全量扫描PB级历史数据,增量训练数据准备时间从24小时缩短至1小时。 - 版本控制与回滚:
数据湖表格式(如Delta Lake、Iceberg)支持数据版本管理——例如训练V1模型用版本1的多模态数据,训练V2模型时发现数据标注错误,可回滚到版本1重新训练,避免因数据问题导致模型迭代失败。
3. 生态集成:无缝对接AI训练流程
数据湖通过“存储接口+计算引擎+训练框架”的生态联动,让多模态数据直接流入AI训练 pipeline,无需人工干预:
- 对接AI框架:
数据湖的存储接口(HDFS/S3 API)原生支持TensorFlow/PyTorch的Dataset接口——例如PyTorch通过torchvision.datasets.ImageFolder直接读取数据湖S3路径下的图像文件夹,TensorFlow通过tf.data.TFRecordDataset读取数据湖预处理后的TFRecord格式图像数据,训练数据加载效率提升30%。 - 集成训练管理工具:
对接MLflow、Kubeflow等AI训练管理工具,将数据湖的多模态数据与训练任务关联——例如MLflow记录“训练任务ID+数据湖数据版本+模型精度”,实现“数据-模型-结果”的全链路追溯,方便复现训练过程。 - 分布式训练适配:
数据湖支持分布式文件系统(HDFS)和对象存储(S3/OSS),适配AI模型的分布式训练——例如用HDFS存储大规模图像数据集,PyTorch DDP(分布式数据并行)框架通过HDFS的块存储(Block)并行读取数据,100卡GPU训练时数据加载吞吐量达10GB/s,避免训练卡顿。
四、实践流程:数据湖支撑多模态AI训练的完整链路
以“图像-文本多模态分类模型(如判断图像与文本描述是否匹配)”为例,完整流程如下:
1. 数据接入:多模态数据入湖
- 文本数据:将互联网爬取的文本描述(JSON格式)通过Flink Stream Load写入数据湖,存储路径为
s3://data-lake/text/raw/20250101/,元数据记录到Iceberg表text_metadata(含text_id、content、create_time)。 - 图像数据:将同步的图像文件(JPG格式)通过S3 SDK上传到数据湖,存储路径为
s3://data-lake/image/raw/20250101/,元数据记录到Iceberg表image_metadata(含image_id、file_path、resolution)。 - 关联数据:用Spark SQL执行
JOIN,将“图像元数据+文本描述+人工标注标签”关联,生成训练用的多模态元数据表multimodal_train,存储路径为s3://data-lake/multimodal/train/。
2. 数据预处理:标准化与特征提取
- 文本预处理:用Spark NLP对文本进行分词、Word2Vec特征提取,生成文本特征向量(Parquet格式),存储到
s3://data-lake/text/processed/。 - 图像预处理:用Flink + OpenCV对图像进行Resize(224×224)、归一化,转换为TFRecord格式,存储到
s3://data-lake/image/processed/。 - 特征关联:更新
multimodal_train表,添加text_feature_path和image_feature_path字段,关联预处理后的特征数据。
3. AI训练:数据湖直接供给训练
- 数据加载:PyTorch训练脚本通过
torch.utils.data.Dataset读取数据湖路径——class MultimodalDataset(Dataset):def __init__(self, metadata_path):# 读取数据湖的multimodal_train表(Parquet格式)self.metadata = pd.read_parquet("s3://data-lake/multimodal/train/multimodal_train.parquet")def __getitem__(self, idx):# 读取预处理后的图像特征和文本特征image_feat = torch.load(self.metadata.iloc[idx]["image_feature_path"])text_feat = torch.load(self.metadata.iloc[idx]["text_feature_path"])label = self.metadata.iloc[idx]["match_label"] # 0=不匹配,1=匹配return image_feat, text_feat, label - 分布式训练:用PyTorch DDP启动10卡GPU训练,通过S3的并行读取能力,每卡每秒加载1000个样本,训练周期从7天缩短至2天。
- 增量迭代:3天后,新增10万条图像-文本数据,用Hudi的增量读取能力,仅加载新增数据的特征,进行增量训练,模型精度从85%提升至88%。
4. 数据归档:训练数据冷存储
- 将训练完成的历史数据(如3个月前的原始图像、预处理特征)从S3热存储迁移到Glacier冷存储,存储成本降低80%;
- 用Iceberg表记录数据归档路径,后续模型复现或二次训练时,可解冻冷存储数据重新使用。
五、数据湖选型建议(适配多模态AI训练)
不同数据湖工具的多模态支撑能力有差异,需结合AI训练需求选型:
| 数据湖工具 | 多模态存储优势 | 适配AI训练场景 | 注意事项 |
|---|---|---|---|
| Hudi | 增量数据捕获强,支持图像/文本的增量更新 | 实时多模态训练(如每日新增数据增量训练) | 元数据管理较弱,需搭配Hive Metastore使用 |
| Iceberg | 元数据管理高效,支持跨格式数据关联 | 大规模离线多模态训练(如PB级图像分类) | 增量写入性能一般,适合批处理场景 |
| Delta Lake | 与Spark/PyTorch集成紧密,支持流批一体 | 流批混合多模态训练(如实时视频+离线文本) | 强依赖Spark生态,云存储适配性弱于Iceberg |
| Paimon | LSM-Tree架构,支持高频标注数据更新 | 多模态数据实时标注+训练(如LabelStudio联动) | 多模态大文件(视频)支持较弱,适合中小文件 |
核心建议:
- 离线大规模多模态训练(如文生图模型):优先选Iceberg(元数据强,多格式兼容);
- 实时增量多模态训练(如实时视频分析):优先选Hudi/Paimon(增量能力强);
- Spark生态主导的AI团队:优先选Delta Lake(集成成本低)。
总结
数据湖为多模态AI训练提供“统一存储底座+全链路数据治理+训练生态联动”的核心支撑——解决了多模态数据“格式散、规模大、质量差”的痛点,让AI训练从“数据准备占80%时间”转变为“数据直接可用”。未来随着多模态大模型(如GPT-4V、SAM)的普及,数据湖将进一步强化“模态无关存储”和“AI原生数据供给”能力,成为多模态AI训练的核心基础设施。