Elasticsearch 与 Faiss 联合驱动自动驾驶场景检索:高效语义匹配 PB 级视频数据
在自动驾驶领域,PB 级视频库中隐藏着无数宝贵场景,但如何从海量数据中精准提取“雨天傍晚无保护左转”等特定片段,一直是挑战。传统搜索已过时,向量搜索结合 Elasticsearch(ES)和 Faiss 才是王道。今天,我们探讨如何用 ES 存储视频关键向量和 URL,通过中文文本查询(如“雨天无保护左转”)实现 kNN 检索。这不仅仅提升效率,还能为模型训练注入海量相似数据——工程师输入一个场景,系统瞬间返回数千匹配!
基于实际平台经验,本文步步拆解索引、向量生成、查询和优化。如果你涉足 AI、搜索或自动驾驶,这将是你上手指南。走起!
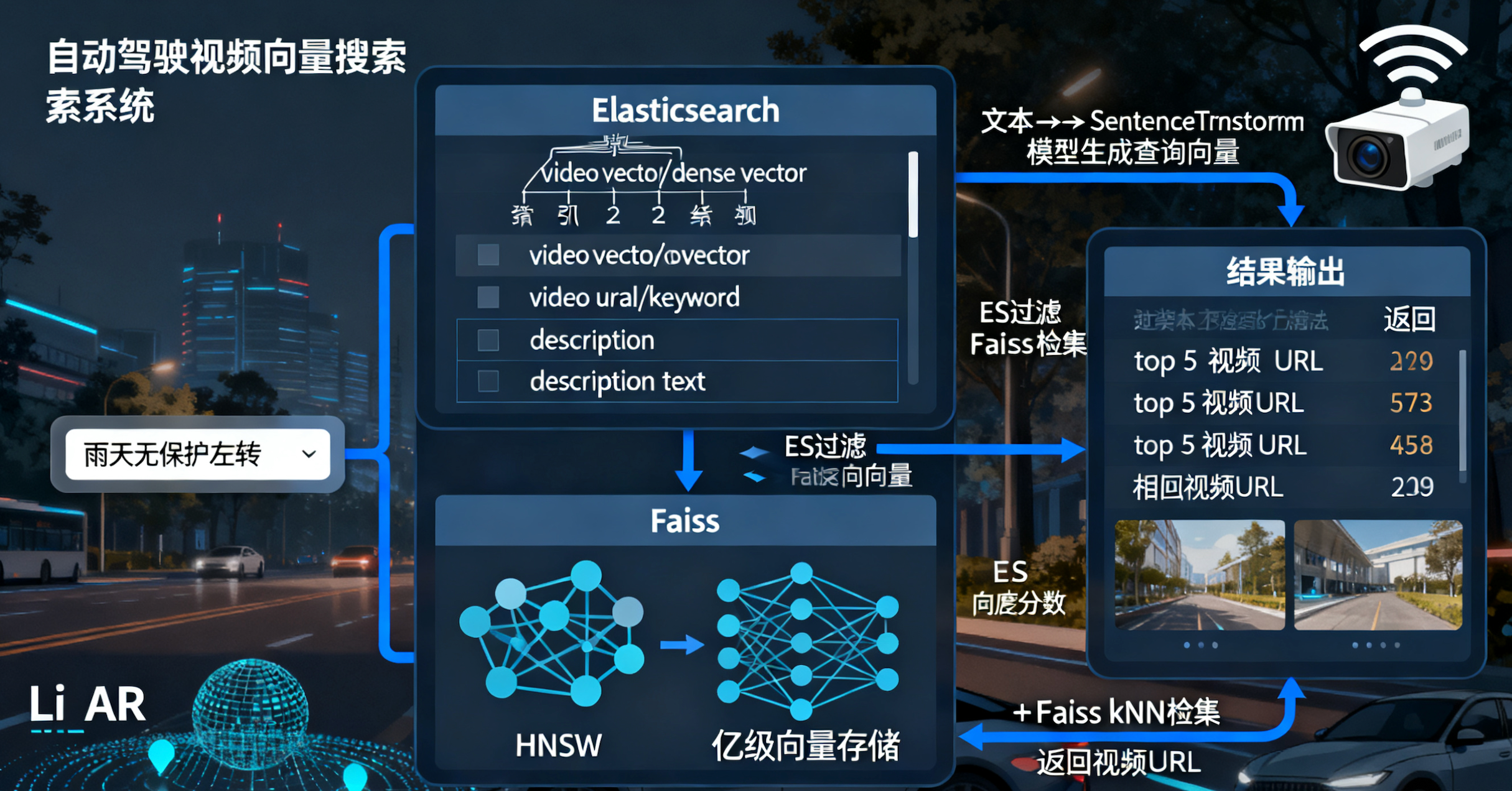
1. 为什么选择 Elasticsearch + Faiss 的向量搜索组合?
自动驾驶场景向量不是原始数据,而是高维特征(如速度、加速度、密度、TTC 等),经归一化和 PCA 降维(如 128 维)形成 Embedding。ES 擅长处理结构化数据,而结合 Faiss 可以实现海量向量(数亿级)的毫秒级相似性搜索。
- 核心优势:
- 语义深度:超越关键词,捕捉“雨天左转”的视觉本质。
- 极速响应:HNSW 算法处理 PB 级数据,延迟毫秒。
- 扩展性:文本映射到特征维度,混合过滤 + 向量搜索。
- 实战价值:感知目标丢失?输入向量,获取相似数据集,加速训练。
如果你的系统已有关键词映射(如“雨天”→天气=雨),无缝集成即可。
2. Elasticsearch向量化检索步骤
2.1:索引结构设计
ES 只存元数据:从关键帧提取的向量(CLIP 等模型生成)和 URL。维度如 512/768,用同一模型(如 multilingual-e5-large,支持中文)。
创建 Mapping
PUT /video_index
{"mappings": {"properties": {"video_vector": {"type": "dense_vector","dims": 768,"index": true,"similarity": "cosine"},"video_url": {"type": "keyword"},"description": {"type": "text"}}}
}- video_vector:启用 kNN。
- video_url:精确 URL。
- description:辅助过滤。
数据插入
批量示例:
POST /video_index/_bulk
{ "index": { "_id": "video1" } }
{ "video_vector": [0.1, -0.2, ..., 0.5], "video_url": "https://example.com/video1.mp4", "description": "雨天驾驶场景" }
{ "index": { "_id": "video2" } }
{ "video_vector": [0.15, -0.25, ..., 0.6], "video_url": "https://example.com/video2.mp4", "description": "无保护左转演示" }向量预计算(如 YOLO + CNN)
2.2:文本转查询向量
用外部模型处理 ES 不内置的部分。推荐 sentence-transformers,支持中文。
from sentence_transformers import SentenceTransformermodel = SentenceTransformer('intfloat/multilingual-e5-large')
query_text = "雨天无保护左转"
query_vector = model.encode(query_text).tolist()
print(query_vector) # [0.123, -0.456, ...]ES 8.x+ 可用 Inference Processor 内置生成:
"query_vector_builder": {"text_embedding": {"model_id": "your_multilingual_model_id","model_text": "雨天无保护左转"}
}确保向量空间一致。
2.3:kNN 查询检索 URL
匹配相似度,返回 top k。
查询示例:
POST /video_index/_search
{"knn": {"field": "video_vector","query_vector": [0.123, -0.456, ..., 0.789],"k": 5,"num_candidates": 100},"fields": ["video_url", "description"],"_source": false
}响应示例:
{"hits": {"hits": [{"_id": "video2","_score": 0.95,"fields": {"video_url": ["https://example.com/video2.mp4"],"description": ["无保护左转演示"]}},{"_id": "video1","_score": 0.88,"fields": {"video_url": ["https://example.com/video1.mp4"],"description": ["雨天驾驶场景"]}}]}
}用 _score 排序/过滤。
3. 查询优化技巧
-
混合搜索:加关键词。
{"query": {"match": { "description": "雨天" }},"knn": { ... } } -
过滤:加条件。
"knn": {...,"filter": { "term": { "category": "自动驾驶" } } } -
性能:
- HNSW:亿级向量,亚线性。
- 量化:element_type: "byte" 省内存。
- 与 Faiss 结合:ES 初步过滤,Faiss 高精度 ANN。
4. 与 Faiss 结合的具体实现示例
要实现 ES 与 Faiss 的联合,使用 Haystack 框架是一个高效选择。ES 处理初始文本查询和过滤,Faiss 则负责高精度 ANN 搜索。以下是基于 Haystack 的 Python 示例,假设你已安装 haystack-ai 和相关依赖。
首先,初始化 DocumentStore:
from haystack.document_stores import FAISSDocumentStore, ElasticsearchDocumentStore
from haystack.nodes import EmbeddingRetriever# Faiss DocumentStore(用于高精度 ANN)
document_store_faiss = FAISSDocumentStore(faiss_index_factory_str="Flat", return_embedding=True)# Elasticsearch DocumentStore(用于初步过滤)
document_store_es = ElasticsearchDocumentStore(host="localhost", index="video_index", similarity='cosine')然后,初始化 Retriever(使用相同的嵌入模型):
# Faiss Retriever
retriever_faiss = EmbeddingRetriever(document_store=document_store_faiss, embedding_model='intfloat/multilingual-e5-large', model_format='sentence_transformers')# ES Retriever
retriever_es = EmbeddingRetriever(document_store=document_store_es, embedding_model='intfloat/multilingual-e5-large', model_format='sentence_transformers')索引数据(以视频元数据为例):
# 示例数据
documents = [{"content": "雨天驾驶场景", "meta": {"video_url": "https://example.com/video1.mp4"}},{"content": "无保护左转演示", "meta": {"video_url": "https://example.com/video2.mp4"}}
]# 清空并写入 Faiss
document_store_faiss.delete_documents()
document_store_faiss.write_documents(documents)
document_store_faiss.update_embeddings(retriever=retriever_faiss)# 类似操作写入 ES(假设已预计算向量)
# document_store_es.write_documents(documents_with_vectors)查询过程:先用 ES 初步过滤(如关键词“雨天”),获取候选 ID,然后用 Faiss 高精度搜索。
# 初步过滤(ES)
query = "雨天无保护左转"
es_results = document_store_es.query(query=query, filters={"description": ["雨天"]}, top_k=100) # 获取候选# 提取候选向量/ID 并传入 Faiss
candidate_ids = [res.id for res in es_results]
faiss_results = retriever_faiss.retrieve(query_emb=query_vector, filters={"id": candidate_ids}, top_k=5)# 输出结果
for result in faiss_results:print(result.meta["video_url"], result.score)这种方式,ES 负责快速过滤(e.g., 关键词或元数据),Faiss 处理精确向量相似度计算。实际测试中,Faiss 在大规模数据集上索引速度更快(e.g., 数百万向量只需几分钟)。在自动驾驶中,这可处理 PB 级视频,ES 缩小范围,Faiss 确保高召回和高精度。
- 挑战应对:
- 中文:多语言模型。
- 召回:增 num_candidates。
- 映射:文本关键词 → 特征范围 + 向量搜索。
自动驾驶中,这扩展数据集——从单一场景到数千相似!
5. 结语:解锁 PB 级检索潜力
Elasticsearch 与 Faiss 联手,让语义检索从文本直达视频,加速自动驾驶创新。简单实现,巨大回报。试试 demo,或集成你的平台。有疑问?评论区见!分享推动前沿。
(基于 Elasticsearch 8.x,模型兼容性参考官方 docs 调试。)
6. 参考文章
https://aicompetence.org/hybrid-search-with-faiss/
https://www.elastic.co/search-labs/blog/vector-search-set-up-elasticsearch
https://medium.com/@krasniuk-ai/faiss-vs-elasticsearch-dbc3f971dc29
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless-vector-search.html
https://www.reddit.com/r/MachineLearning/comments/cm267a/p_how_we_used_use_and_faiss_to_enhance/