论文阅读-EfficientAD
文章目录
- 1 概述
- 2 模块
- 2.1 PDN
- 2.2 局部异常
- 2.3 逻辑异常
- 2.4 归一化
- 3 效果
- 参考资料
1 概述
EfficientAD是一种用于检测图像中异常特征的模型,训练过程中,仅需要正常样本。它基于教师-学生架构,提出了一种轻量级特征提取器,可以在现代 GPU 上在不到一毫秒的时间内处理图像。图1-1展示了不同的异常检测模型耗时与AUROC指标之间的对比,可以看出在速度和效果上,EfficientAD的优势都非常明显。

整篇文章的思路是这样的,作者的目标是实现轻量化,因此提出了一个及其轻量的网络结构,名字叫PDN(patch description network)。这个网络除了轻量之外,还有一个好处是其感受野固定是33×3333 \times 3333×33个像素,因此正常区域不会受到距离较远的异常特征的影响而被判为异常。作者把这个网络应用于异常检测比较常见的教师-学生框架,训练时使用正常样本让学生模拟教师的输出,预测时希望学生在从未见过的异常区域与老师表现不一致,以此来检测异常,这部分是局部异常。为了保证学生在正常特征上与教师预测结果都一致性和在异常特征上与教师预测的差异性,分别提出了一种损失。为了解决全局的逻辑异常,又引入了自动编码器来与学生计算差异。最终为了同意局部异常图和全局异常图的分数匹配,又提出了一种归一化方法。
2 模块
2.1 PDN
本文使用仅由四个卷积层组成的网络作为特征提取器,如图2-1所示。每个输出神经元都有一个 33×3333×3333×33 像素的感受野,因此每个输出特征向量描述一个 33×3333×3333×33 的patch。由于这种明确的对应关系,作者将该网络称为patch description network(PDN)。 PDN 是完全卷积的,可以应用于可变大小的图像,以在单个前向传递中生成所有特征向量。
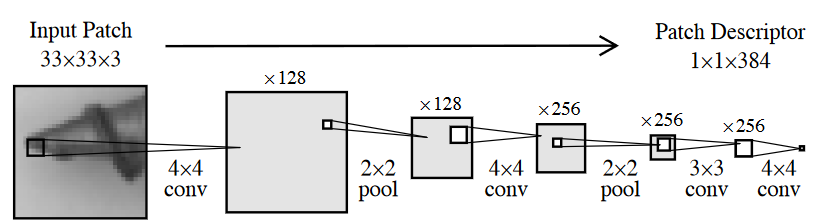
本文的教师和学生网络都使用的PDN,其中教师网络是预训练过的,预训练的方式是对WideResNet-101进行蒸馏,代码可以参见pretraining.py。通过最小化PDN输出与从预训练WideResNet-101提取的特征之间的均方差,在 ImageNet 的图像上训练 PDN。
除了更高的效率之外,与最近方法使用的深度网络相比,PDN 还有另一个好处。根据设计,PDN 生成的特征向量仅取决于其各自 33×33 块中的像素。另一方面,预训练分类器的特征向量表现出对图像其他部分的远程依赖性。如图2-2所示,以 PatchCore 的特征提取器为例。 PDN 定义明确的感受野确保图像某一部分的异常不会触发其他远处部分的异常特征向量,从而影响异常的定位。

不过,在预训练PDN时,PDN的感受野是33×33,但是WideResNet-101的感受野不止这些,这样训练出来的结果是否会有一些问题呢?也就是要求PDN在只有33×33感受野的前提下,预测出和WideResNet-101同样感受野的特征,这有点DINO的味道?
PDN的具体结构可见表2-1,需要注意的是,在具体的代码实现中,padding是可以被省略,并使用zero-padding进行补充的,作者解释这是为了提速,但实际测试下来关闭padding的效果也更好。

我们再来看看PDN的具体代码实现,当设置padding=False时,所有nn.Conv2d模块的padding都会被置为0。当输入为256×256256 \times 256256×256时,如果padding=False,则输出为384×56×56384 \times 56 \times 56384×56×56,如果padding=True,则输出为384×64×64384 \times 64 \times 64384×64×64。为了让padding=False的输出尺寸与padding=True时对齐,也就是和原图的尺寸对齐,会对产生的特征图进行一个padding,也就是map_combined = torch.nn.functional.pad(map_combined, (4, 4, 4, 4)),上下左右都pad尺寸为4的距离,就变成384×64×64384 \times 64 \times 64384×64×64。这样的做法也就导致了EfficientAD在padding=False时无法预测到四周区域的异常,需要保证异常区域出现在384×56×56384 \times 56 \times 56384×56×56的范围内。
def get_pdn_small(out_channels=384, padding=False):pad_mult = 1 if padding else 0return nn.Sequential(nn.Conv2d(in_channels=3, out_channels=128, kernel_size=4,padding=3 * pad_mult),nn.ReLU(inplace=True),nn.AvgPool2d(kernel_size=2, stride=2, padding=1 * pad_mult),nn.Conv2d(in_channels=128, out_channels=256, kernel_size=4,padding=3 * pad_mult),nn.ReLU(inplace=True),nn.AvgPool2d(kernel_size=2, stride=2, padding=1 * pad_mult),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3,padding=1 * pad_mult),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=out_channels, kernel_size=4))
根据anomalib/issue/2009中的描述,padding=False的结果示意图如下图2-3所示。
padding=True的结果示意图如下图2-4所示。

实测下来padding=False的结果更好,这应该是因为padding=True时,四周的特征抽取包括了0的padding,影响了特征的质量。
2.2 局部异常
为了检测异常特征向量,作者使用学生-教师(S-T)方法,其中教师由本文的蒸馏 PDN 给出。由于可以在一毫秒内执行 PDN,因此也为学生使用其架构,从而实现较低的整体延迟。然而,这种轻量级的学生-教师缺乏以前的方法所使用的技术来提高异常检测性能:集成多个教师和学生,使用金字塔层的特征,以及使用学生和教师网络之间的架构不对称性。因此,作者引入了一种训练损失,可以显着提高异常检测效果,而不会影响测试时的计算要求。
作者观察到,在标准 S-T 框架中,增加训练图像的数量可以提高学生模仿老师处理异常的能力。这会恶化异常检测性能。同时,刻意减少训练图像的数量会抑制正常图像的重要信息。本文的目标是向学生展示足够的数据,以便其能够在正常图像上充分模仿教师,同时避免泛化到异常图像。与在线困难示例挖掘类似,作者将学生的损失限制在图像中最相关的部分。这些是学生目前模仿老师最不像的patches。作者提出了硬特征损失,它仅使用损失最高的输出元素进行反向传播。
形式上,将教师 TTT 和学生 SSS 应用于训练图像 III,得到T(I)∈RC×W×HT(I) \in R^{C \times W \times H}T(I)∈RC×W×H 和S(I)∈RC×W×HS(I) \in R^{C \times W \times H}S(I)∈RC×W×H 。将每个元组 (c,w,h)(c, w, h)(c,w,h) 的平方差计算为 Dc,w,h=(T(I)c,w,h−S(I)c,w,h)2D_{c,w,h} = (T(I)_{c,w,h} − S(I)_{c,w,h})^2Dc,w,h=(T(I)c,w,h−S(I)c,w,h)2。基于挖掘因子 phard∈[0,1]p_{hard} ∈ [0, 1]phard∈[0,1],然后计算 DDD 元素的 phardp_{hard}phard 分位数。给定 phardp_{hard}phard 分位数 dhardd_{hard}dhard,将训练损失 LhardL_{hard}Lhard 计算为所有 Dc,w,h≥dhardD_{c,w,h} ≥ d_{hard}Dc,w,h≥dhard 的平均值。将 phardp_{hard}phard 设置为零将产生原始的 S-T 损失。在本文的实验中,将 phardp_{hard}phard 设置为 0.999,这相当于平均使用 D 的三个维度中每个维度的值的 10%10\%10% 进行反向传播。图2-5直观地显示了 phard=0.999p_{hard} = 0.999phard=0.999 时硬特征损失的影响。在推理过程中,2D 异常得分图 M∈RW×HM ∈ R^{W×H}M∈RW×H 由 Mw,h=C−1∑cDc,w,hM_{w,h} = C^{−1} \sum_c D_{c,w,h}Mw,h=C−1∑cDc,w,h 给出,即由跨通道的 DDD 平均得到。它为每个特征向量分配一个异常分数。通过使用硬特征损失,避免了正常图像上异常分数的异常值,即过杀检测。该损失注重于最不像老师的异常值,因此可以避免在正常图像产生异常值。

除了硬特征损失之外,在训练过程中还使用了另一种损失惩罚,进一步阻止学生在不属于正常训练图像的图像上模仿老师。在标准 S-T 框架中,教师在图像分类数据集上进行预训练,或者它是此类预训练网络的精炼版本。学生没有接受预训练数据集的训练,而仅接受应用程序的正常图像的训练。本文建议在学生训练期间也使用教师预训练的图像。具体来说,在每个训练步骤中从预训练数据集(在本文的例子中为 ImageNet)中采样随机图像 PPP。将学生的损失计算为 LST=Lhard+(CWH)−1∑c∥S(P)c∥F2L_{ST} = L_{hard} + (CWH)^{−1}\sum_c ∥S(P )_c∥^2_FLST=Lhard+(CWH)−1∑c∥S(P)c∥F2 。这种惩罚会阻碍学生将对老师的模仿推广到分布外的图像。也就是让学生对分布外的图像预测结果接近于0,一个正则项。
这种将分布外的预测结果强硬预测为0的方式有一些粗暴,如果训练数据分布接近于ImageNet的分布咋办?
2.3 逻辑异常
逻辑异常有多种类型,例如丢失、错放或多余的对象,或者违反几何约束(例如螺钉的长度)。正如 MVTec LOCO 数据集的作者所建议的,本文使用自动编码器来学习训练图像的逻辑约束并检测对这些约束的违反。图2-6描述了 EfficientAD 的异常检测方法,它由前面提到的学生-教师和一个自动编码器组成。自动编码器经过训练可以预测教师的输出。形式上,将自动编码器 AAA 应用于训练图像 III,产生 A(I)∈RC×W×HA(I) ∈ R^{C×W×H}A(I)∈RC×W×H ,并将损失计算为 LAE=(CWH)−1∑c∥T(I)c−A(I)c∥F2L_{AE} = (CWH)^{−1}\sum_c ∥T(I)_c − A(I)_c∥^2_FLAE=(CWH)−1∑c∥T(I)c−A(I)c∥F2 。作者使用标准卷积自动编码器,包括编码器中的跨步卷积和解码器中的双线性上采样。

与基于patch的学生相比,自动编码器必须通过 64 个隐维度的瓶颈对完整图像进行编码和解码。对于具有逻辑异常的图像,自动编码器通常无法生成正确的隐编码来重建教师特征空间中的图像。然而,它的重建在正常图像上也存在缺陷,因为自动编码器通常难以重建细粒度模式。图2-6中的背景网格就是这种情况。在这些情况下,使用教师输出和自动编码器重建之间的差异作为异常图会导致过杀检测。相反,作者将学生网络的输出通道数量加倍,并训练它来预测自动编码器的输出以及教师的输出。令 S′(I)∈RC×W×HS^′(I) ∈ R^{C×W×H}S′(I)∈RC×W×H 表示学生的附加输出通道。学生的额外损失为 LSTAE=(CWH)−1∑c∥A(I)c−S′(I)c∥F2L_{STAE} = (CWH)^{−1}\sum_c∥A(I)_c − S^′(I)_c∥^2_FLSTAE=(CWH)−1∑c∥A(I)c−S′(I)c∥F2 。总训练损失是 LAEL_{AE}LAE、LSTL_{ST}LST 和 LSTAEL_{STAE}LSTAE 的总和。
学生学习自动编码器在正常图像上的系统重建误差,例如模糊重建。同时,它不会学习异常的重建错误,因为这些不是训练集的一部分。这使得自动编码器的输出和学生的输出之间的差异非常适合计算异常图。与学生教师类似,异常图是两个输出之间的平方差,跨通道平均。本文将该异常图称为全局异常图,并将由学生-教师对生成的异常图称为局部异常图。作者对这两个异常图进行平均以计算组合异常图,并使用其最大值作为图像级异常得分。因此,组合异常图包含学生-教师的检测结果和自动编码器-学生对的检测结果。在这些检测结果的计算中共享学生的隐藏层使本文的方法能够保持较低的计算要求,同时能够检测结构和逻辑异常。
EfficientAD的网络结构图如下图2-7所示。

2.4 归一化
局部和全局异常图必须先标准化为相似的比例,然后再对其进行平均以获得组合异常图。这对于仅在其中一张图中检测到异常的情况非常重要(如图2-6所示)。否则,一张图中的噪声可能会使另一张图中的准确检测在组合图中无法辨别。为了估计正常图像中噪声的规模,作者使用验证集的图像,即训练集中未见过的图像。对于两种异常图类型中的每一种,作者计算验证图像中所有像素异常分数的集合。然后,为每个集合计算两个 ppp 分位数:qaq_aqa 和 qbq_bqb,分别表示 p=ap = ap=a 和 p=bp = bp=b,实际情况下取 a=0.9a = 0.9a=0.9 和 b=0.995b=0.995b=0.995 。确定一个线性变换,将 qaq_aqa 映射到异常分数 0,将 qbq_bqb 映射到异常分数 0.1。在测试时,局部和全局异常图通过各自的线性变换进行归一化。注意,这里只用到了验证集中的正常图像,目的是把正常特征的最大分数映射到0.1左右。
通过使用分位数,标准化对于正常图像上的异常分数的分布变得稳健,该分布在不同场景之间可能有所不同。 qaq_aqa 和 qbq_bqb 之间的分数是否呈正态分布、高斯混合分布或遵循其他分布对归一化没有影响。映射目标值 0 和 0.1 的选择对异常检测指标(例如 ROC 曲线下面积 (AUROC))没有影响,这是因为 AUROC 仅取决于分数的排名,而不取决于分数的大小。本文选择 0 和 0.1,因为它们生成适合标准0到1色标的贴图。
3 效果
对于本文的方法,作者评估了两种变体:EfficientAD-S 和 EfficientAD-M。 EfficientAD-S 针对教师和学生使用表2-1中显示的架构。对于 EfficientAD-M,将教师和学生的隐藏卷积层中的内核数量加倍。此外,在第二个池化层之后和最后一个卷积层之后插入一个 1×11×11×1 卷积。
表3-1展示了不同SOTA模型在MVTec AD、VisA、MVTec LOCO指标的平均值对比以及速度对比结果。

表3-2展示了不同SOTA模型在不同数据集的AUROC指标对比结果。

图3-1展示了不同SOTA模型在不同GPU的耗时对比。

图3-2展示了EfficientAD在VisA上的可视化结果。

参考资料
[1] EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies
[2] Unofficial implementation of EfficientAD
[3] implementation of EfficientAD in Anomalib