transformer记录一(输入步骤讲解)
一、简介
transformer 是谷歌研究团队于 2017 年在论文《Attention Is All You Need》中提出的里程碑式深度学习架构,其核心突破在于以自注意力机制替代传统循环神经网络(RNN)的序列化处理模式,实现了序列数据的并行化建模。
与 RNN 依赖时序递进的 “逐 token 处理” 不同,Transformer 通过自注意力直接计算序列中所有元素的全局关联,既解决了 RNN 因长序列梯度衰减导致的 “长距离依赖捕捉能力弱” 问题,又摆脱了序列化计算对训练效率的桎梏(可利用 GPU 并行加速)。这一架构彻底重塑了序列建模范式:在自然语言处理(NLP)领域,它支撑了 BERT、GPT 等预训练大模型的诞生,推动机器翻译、文本生成等任务精度跃升;在计算机视觉(CV)领域,衍生出 Vision Transformer(ViT)等模型,打破了卷积网络的垄断;在跨模态领域,更是成为 CLIP、GPT-4 等多模态模型的核心骨架,实现了文本、图像、语音等数据的统一建模。
作为现代深度学习的 “通用基础设施”,Transformer 的出现不仅解决了传统架构的效率与能力瓶颈,更奠定了大规模预训练模型的技术根基,至今仍是 AI 领域最具影响力的核心架构之一。
但是很多人不了解这个底层的基建,今天我们来了解下他的步骤,具体如下(如有错误请指出)。
下面是标准的transformer图
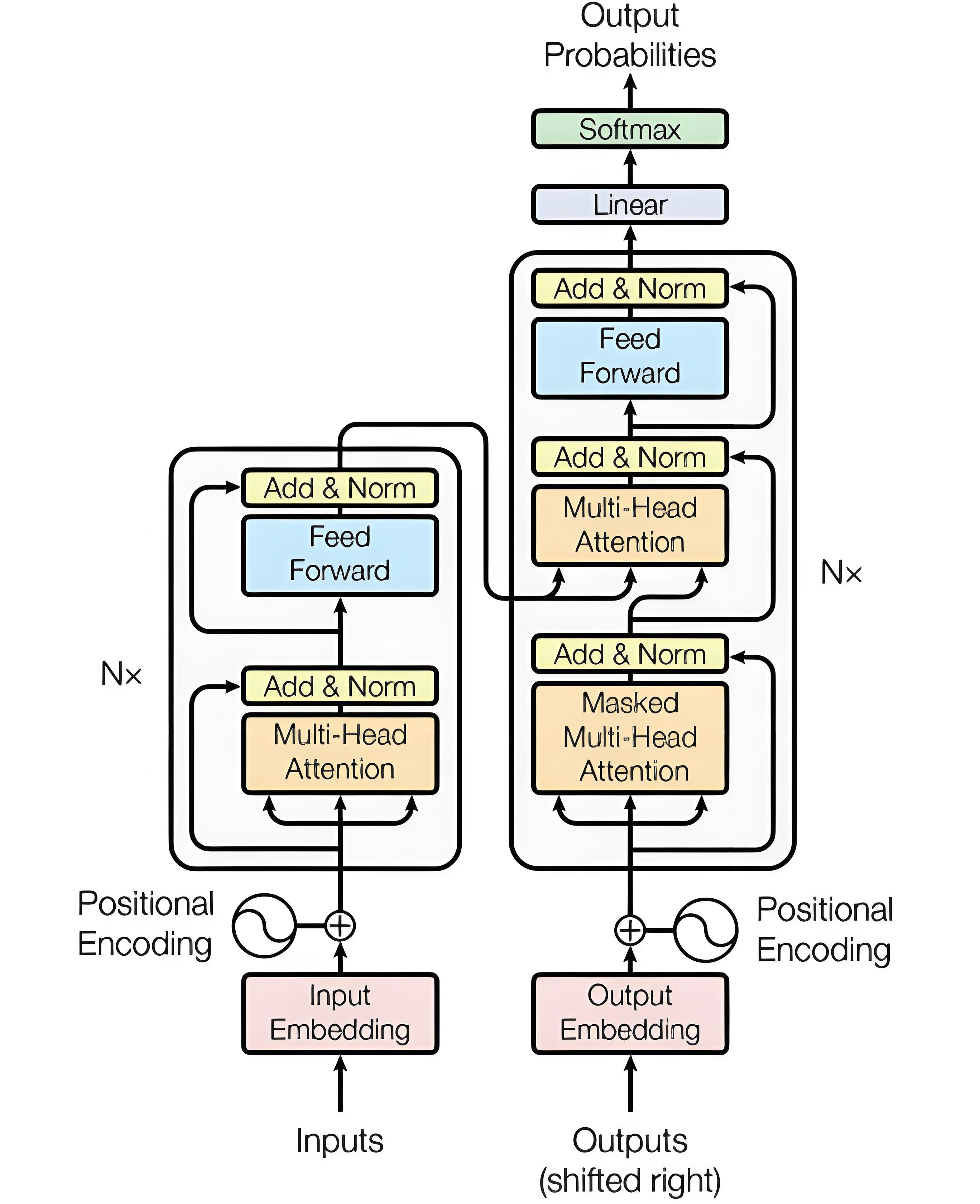
首先带来一张图片,讲解了transformer的编码器步骤:

二、输入流程
输入及编码器流程
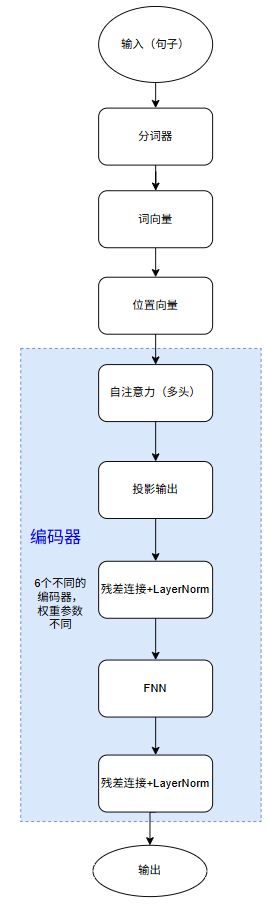
具体详细流程如下图:(以输入句子:小莲,我喜欢你)
下面我们根据具体讲解下输入流程:
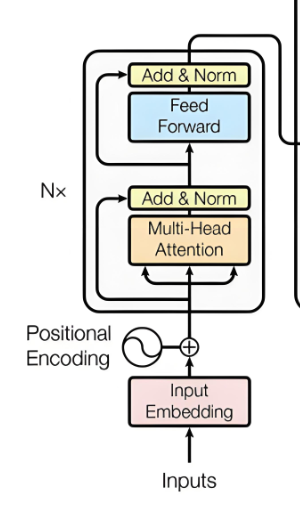
下面以语句“小莲,我喜欢你” 这样的句子来输入,假设向量维度为512。
2.1 分词器(Token)
在自然语言处理(NLP)中,分词器(Tokenizer) 是连接人类语言与模型输入的关键桥梁。它的核心任务是将连续的文本(如句子或段落)切分为模型可处理的离散单元——即 token(词元),并为每个 token 分配唯一的数字索引,从而将非结构化的原始文本转化为结构化的符号序列。
由于模型(如 Transformer、RNN 等)无法直接“理解”字符串,必须依赖分词器将其拆解为具有语义意义的基本单元,再通过词汇表(Vocabulary)映射为整数 ID,最终转换为向量形式供后续嵌入层和神经网络计算使用。
可以说,分词器是所有文本模型不可或缺的前置组件:没有它,输入对模型而言仅是一串无意义的字符,无法建立有效的语义表示与关联。
我们常常看到大模型是如何收费的,就是根据token收费,那这个token是如何来的了,就是通过分词器进行分割的,你一个句子由分词器分出多少token,分出来的越多他越挣钱(开玩笑哈,分词器肯定要合理分割的,具体原理就不讲了)
具体会如下,他会把句子进行合理的划分,比如词语划分一起,这个具体看分词器的功能,我们常说的token就是通过分词器把一个句子分出多少token。
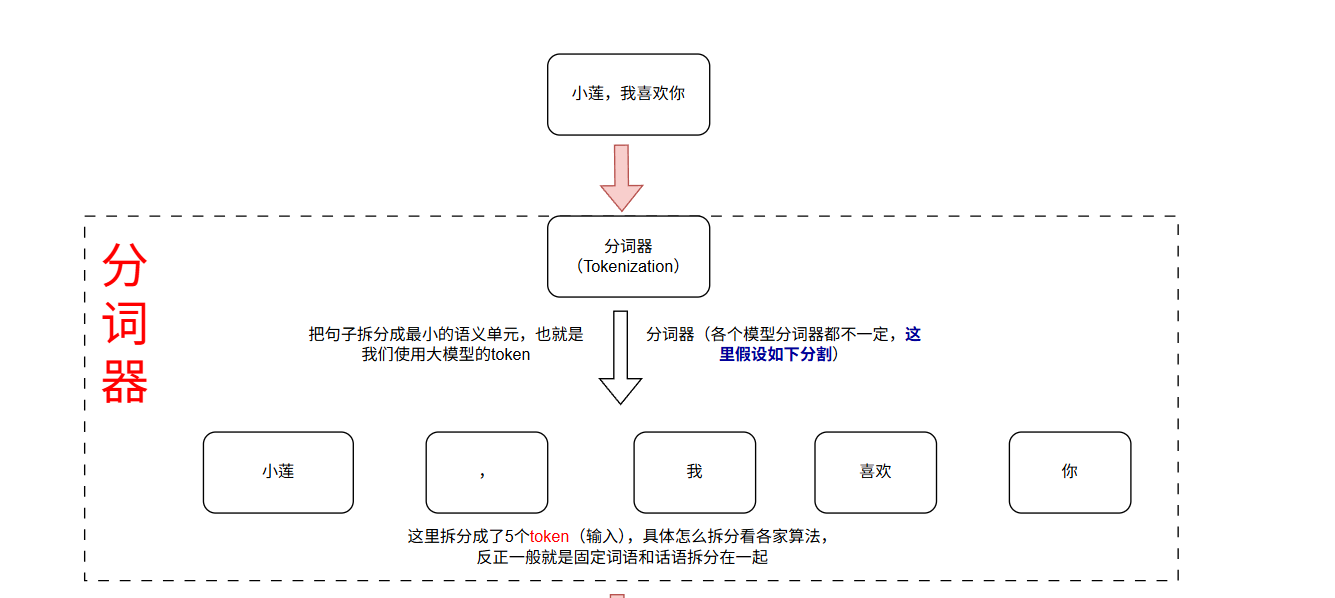
这里就把“小莲,我喜欢你”分割成了5个token,那么这里就拿到了5个token输入的钱了。
至此分词器就到此结束。
2.2 词向量(Embedding)
模型是无法直接去处理文字的,深度神经网络算法都是处理的向量、张量这种矩阵,所以这里需要把token转换为向量,用到了embedding技术。
在自然语言处理(NLP)中,词向量(Word Vector) 是将人类语言中的 “词” 转化为计算机可理解的稠密数值向量的技术,核心目标是让 “语义相似的词具有相似的向量表示”,从而让模型能够通过向量运算捕捉词与词之间的语义关联(如同义、反义、上下位等)。它是连接 “离散文本符号” 与 “连续数值计算” 的桥梁,是现代 NLP 模型(如 Transformer、RNN)理解语言的基础。
计算机无法直接 “理解” 文本中的词(如 “猫”“狗”“动物”),必须将其转化为数值形式。早期的编码方式(如 One-Hot 编码)存在致命缺陷:
维度灾难:若词汇表有 10 万个词,每个词需用 10 万维向量表示(仅对应位置为 1,其余为 0),向量稀疏且维度极高,计算成本大;
语义割裂:One-Hot 向量之间的距离(如余弦相似度)均为 0,无法体现 “猫” 与 “狗” 都是 “动物” 的语义关联,模型无法学习到词的内在含义。
词向量通过稠密低维向量(通常为 50~1024 维)解决了这些问题:例如 “猫” 的向量可能是[0.2, 0.5, -0.1, ..., 0.3],“狗” 的向量是[0.18, 0.49, -0.08, ..., 0.29],两者向量相似(余弦相似度接近 1),直观体现了语义相关性。
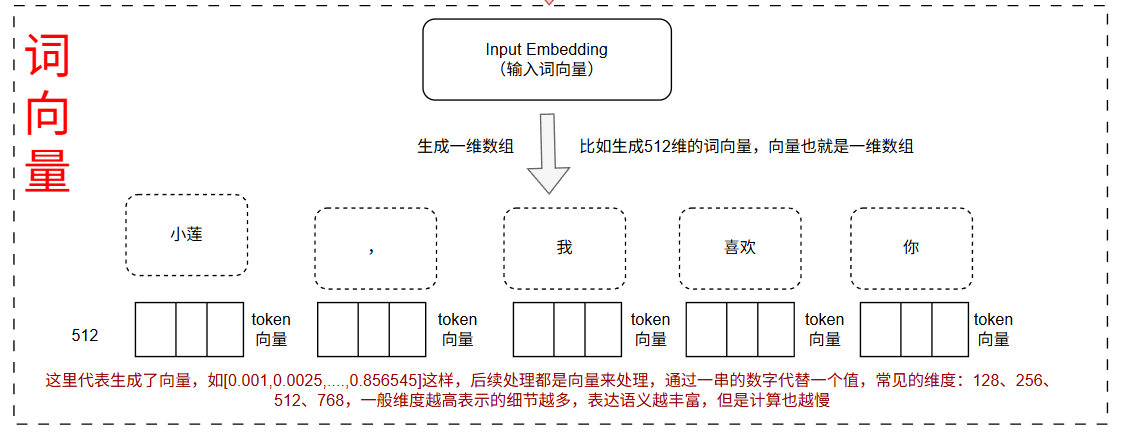
这里就是把token进一步转换为词向量,这里选择的是512维的向量,所以就有了5个512维的向量。
2.3 位置向量
由于transformer不知道token的顺序,不像RNN会记录时间和先后顺序,这里只是记录他们的关系,所以就加上了位置向量,把每个token的位置进行编码,然后和词向量相加得到了新的向量,具体如下得到5个512的向量,为了方便并发计算,把他们合并成一个5x512的张量。
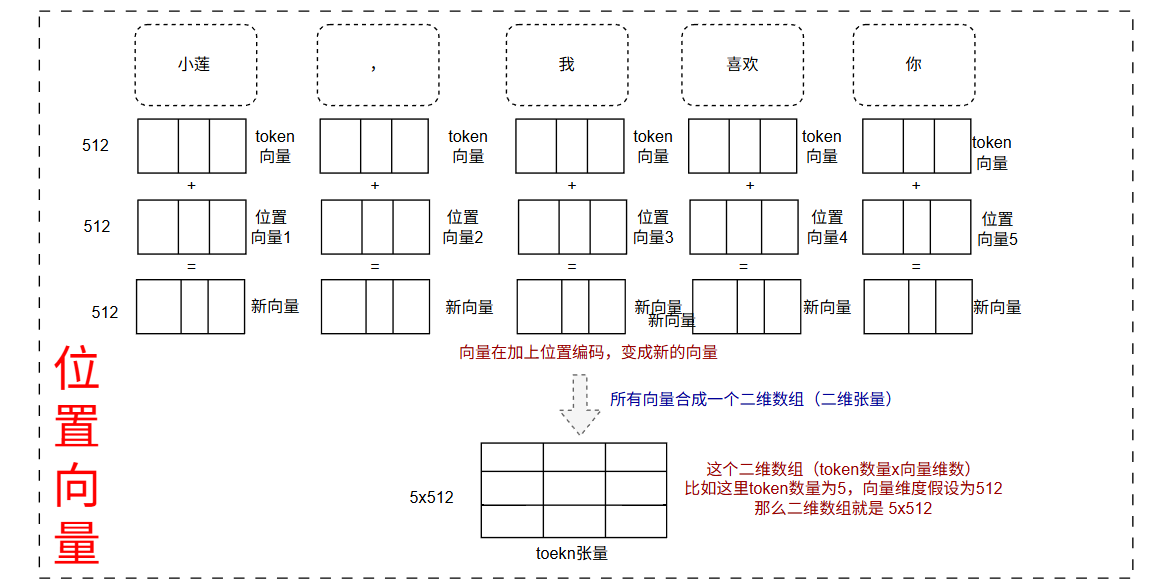 然后输出就进入到我们的编码器阶段了。这一步得到了一个5x512的张量,具体如下(缩写):
然后输出就进入到我们的编码器阶段了。这一步得到了一个5x512的张量,具体如下(缩写):

2.4 编码器
一个transformer包含多个编码器,一般标准包含6个编码器,其他的可能更多,一个编码器包含5个板块:自注意力层、投影输出层、残差连接+LayerNorm(1)、前馈神经网络(FFN)、残差连接+LayerNorm(2)
2.4.1 自注意力(self-attention)
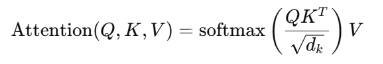
自注意力层是transformer的核心,这层把输入的每个token之间的关系紧密连接起来了,解决了RNN长上下文无法关联的问题、还支持并行计算提高速度等。
这里看自注意是如何计算的。
2.4.1.1 获取Q、K、V向量
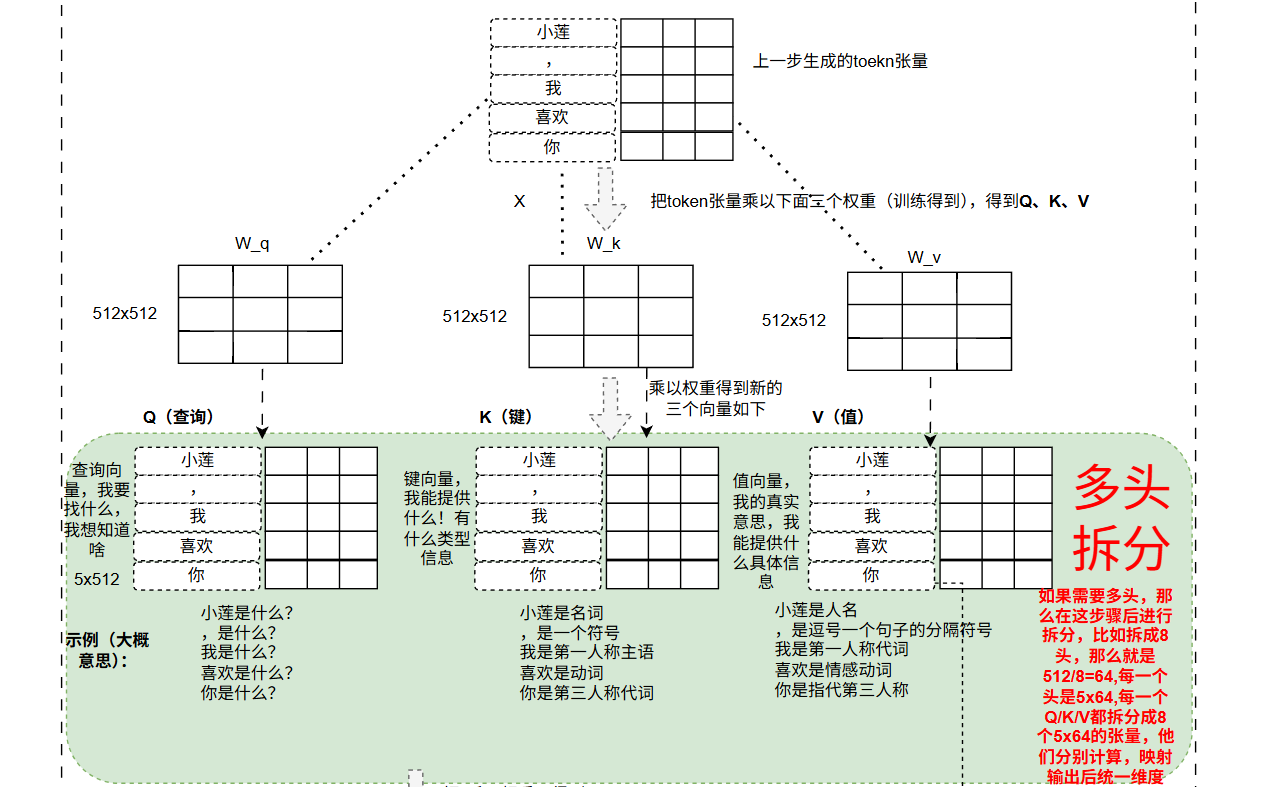
首先通过位置向量之后的输出分包乘以三个张量,W_q、W_k、W_v的张量,他们都是512x512的维度,他们都是通过训练得到的权重。
比如向量之后输出为X,那么下面得到了自注意力里面最关键的Q、K、V:
Q= x 乘以 W_q
K= x 乘以 W_k
V= x 乘以 W_v
Query(查询向量):“我在找什么?” 询问
Key(键向量):“我有什么信息?” 提供类型
Value(值向量):“我能提供的具体信息是什么?” 提供具体值
2.4.1.1多头
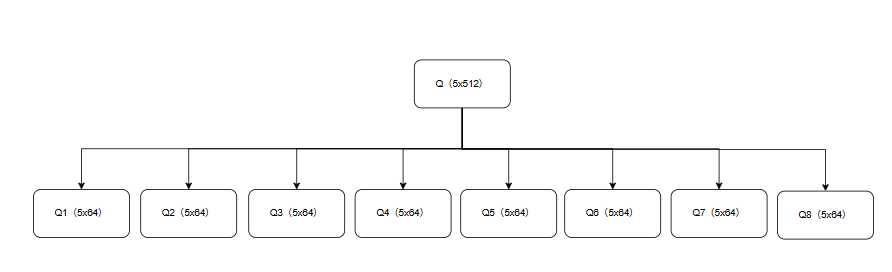
如果是单头那么上一步就结束了,如果是多头,那么需要进行分头,分头步骤也比较好操作,就是比如是512维,如果分割为8头,那么就是512/8=64,如:
Q(5x512) = Q1(5x64)、Q2(5x64)、Q3(5x64)、Q4(5x64)、Q5(5x64)、Q6(5x64)、Q7(5x64)、Q8(5x64)
K(5x512) = K1(5x64)、K2(5x64)、K3(5x64)、K4(5x64)、K5(5x64)、K6(5x64)、K7(5x64)、K8(5x64)
V(5x512) = V1(5x64)、V2(5x64)、V3(5x64)、V4(5x64)、V5(5x64)、V6(5x64)、V7(5x64)、V8(5x64)
这样就把一个5x512分割了8分,这样的好处就是可以多学习一些其他特征,比如什么情感等。
比如向量Q分割成8分,就变成了如下:
2.4.1.2 注意力分数
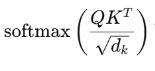
注意力分数(Attention Scores) 是 Transformer 自注意力机制中的核心中间量,用于衡量一个 token 对另一个 token 的关注程度。它决定了信息在序列内部如何流动和聚合。
注意力分数是注意力机制中 “衡量元素关联强度的原始指标”,通过 Query 与 Key 的点积计算,经缩放后用于后续权重归一化。它的核心作用是量化序列中每个元素与其他元素的相关性,为 “谁该被关注、关注多少” 提供原始依据,是注意力机制能捕捉序列依赖关系的基础。
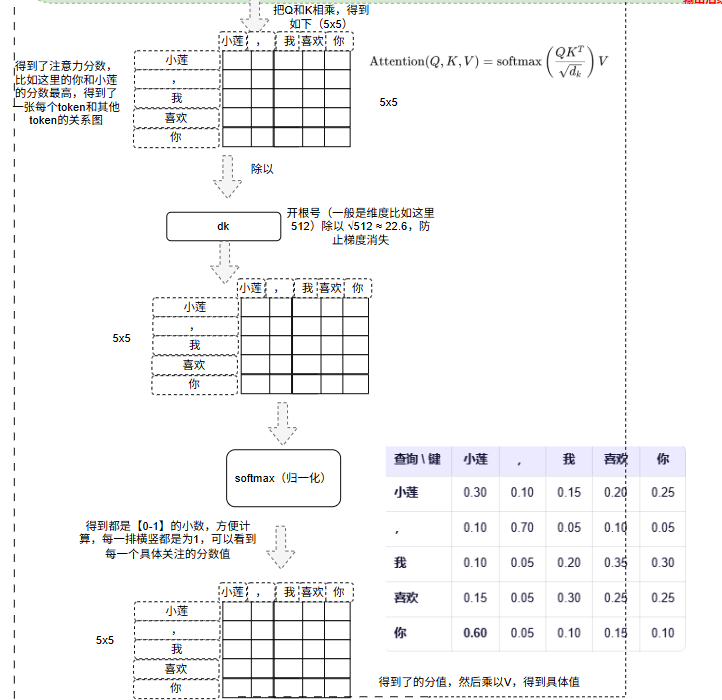
比如我们的例子中:会表示,你和小莲的分数最高,模型就知道你大概率代表小莲,这里是Q和K的乘积,如果是多头那么就是Q1*K1 会得到8个注意力分数,具体得到如下的分数图。
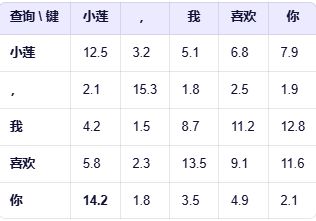
得到的注意力分数值太大不利益计算和后续的归一计算,如果值太大,那么softmax输出极度偏向最大值,其他位置接近 0。梯度也几乎为0,没法学习。所以这里需要缩放,除以维度的开平方,这个是值是根据实验得出来的最佳值,所以这里维度是512,![]() 那么值大概就是23左右。
那么值大概就是23左右。
缩放完成之后通过softmax进行归一化,得到0~1的小数,而且每行加起来为1,更容易表现相似度和联系,如下:
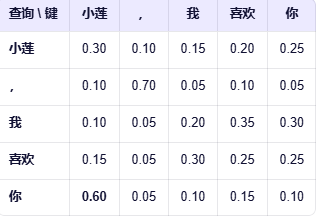
这样我们可以看到每个token(行)对应列(token)的关联度,如上,就可以看到,小莲和本身和喜欢、你关联度高等。
2.4.1.3 加权内容融合
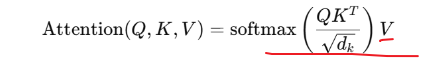
后面一步是把上述的注意力分数x值向量(V)进行内容融合 ,因为V是存储着512每个token的值,那么这里通过注意力分数融合能够得到具体意义的关联和意义。
如:第一排

第一个token小莲=小莲(0.3)*V(小莲)+,(0.1)*V(,) + 我(0.15)*V(我)+喜欢(0.20)*V(喜欢)+你(0.25)*V(你)
后续几排都如此算出那么,就可以得到了5x512的张量,每一个都存储着关联的表达信息。乘以 V,就是把“注意力”转化为“有意义的输出”。
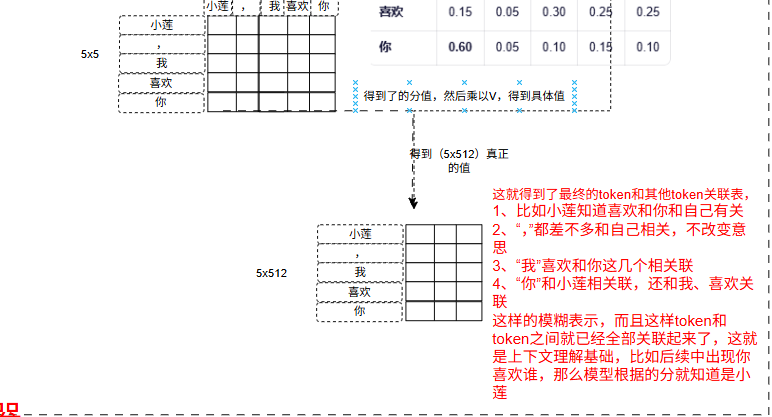
这里只是展示单头,如果是多头,8头那么就是分别的注意力分数xv(5,64)维,8个算法分别计算,输出8个加权内容融合。8个头他们之间这里没有关联,所以可以并行计算提高速度。
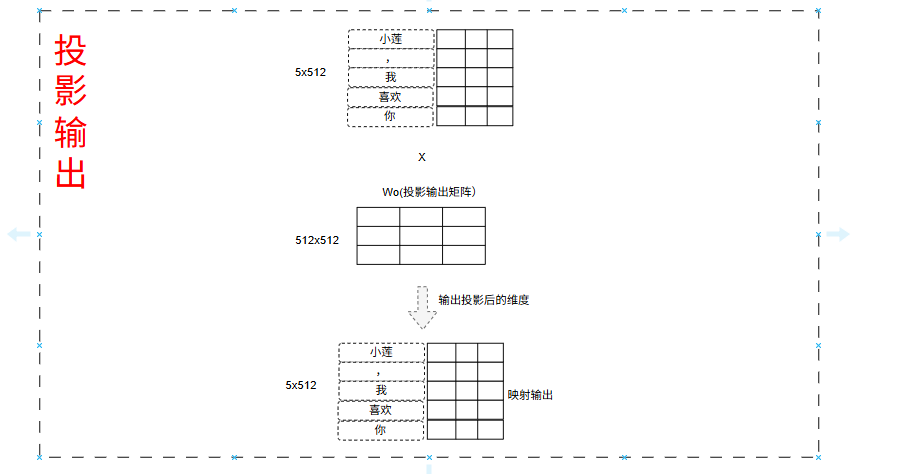
2.4.1.4 投影输出
在 Transformer 的多头注意力机制中,投影输出(Output Projection) 是多头注意力模块的最后一步操作,本质是一个线性变换(通过可学习的权重矩阵),作用是将多头注意力的并行计算结果整合为统一的特征向量,为后续网络层(如残差连接、前馈网络)提供适配的输入。
比如下面是8个5x64的张量,然后每行拼接得到了一个5x512的输出,那么和单头注意力一样的输出维度了。(python示例)
# 每个头输出: (5, 64)
# 8个头拼接:
concat = torch.cat([head_0, head_1, ..., head_7], dim=-1) # (5, 512)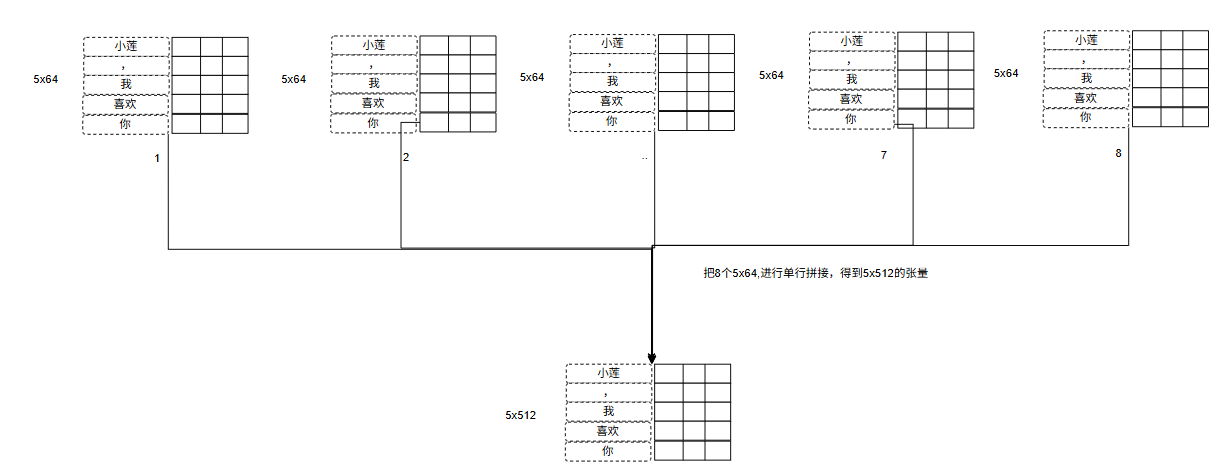
然后这个5x512的张量通过投影输出矩阵进行输出,投影矩阵式Wo(通过训练得到的)。
投影矩阵主要是用于融合多头注意力的特征,就似如下:
每个注意力头 = 一位专家,从不同角度分析句子
头1:分析语法结构
头2:解析指代关系
头3:捕捉情感倾向
...
拼接 = 把所有专家报告并排放在一起
Wₒ 投影 = 主持人综合所有报告,提炼出一份统一、精炼的总结
2.4.2 残差连接+LayerNorm (一)
残差连接出来就是为了解决层数过多导致特征消失、坡度等问题,这里也是一样,加上残差连接之后可以增加很多训练层叠加,层数也多表达语义越高级,内容越复杂,大力出奇迹。
所以在 Transformer 的每个子层(自注意力、前馈网络)之后,都会依次应用 残差连接(Residual Connection) 和 Layer Normalization(LayerNorm)。这两个组件共同解决了深度网络中的梯度消失和训练不稳定问题,是模型能堆叠数十甚至上百层的关键。
下面图里用红线圈出两项都是残差连接+LayerNorm。
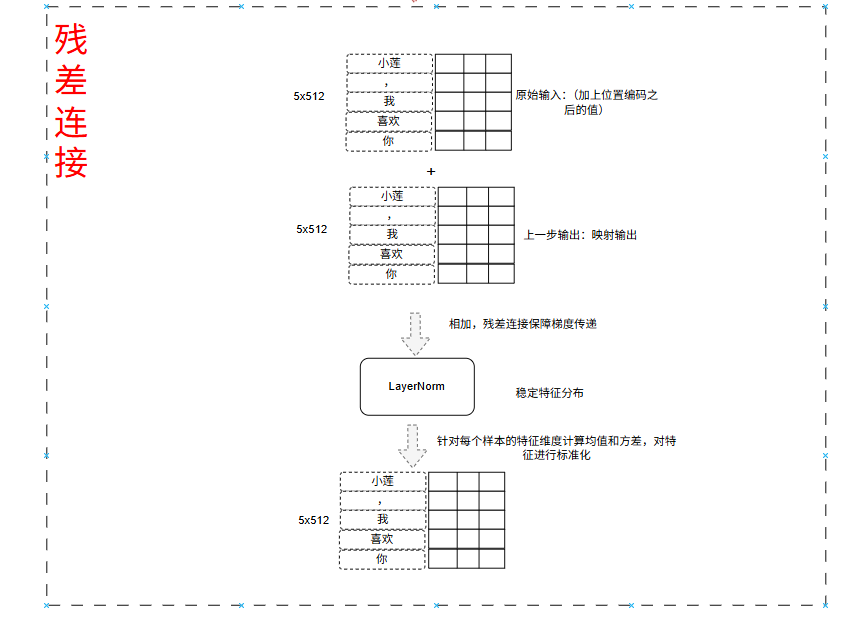
具体操作如图:
- 自注意力输出的(5x512)的张量 + 位置向量输出(5x512) 得到新的5x512的向量(融合初始特征防止丢失信息)
- LayerNorm(新的512向量) = 最后文档特征输出的张量(5x512)
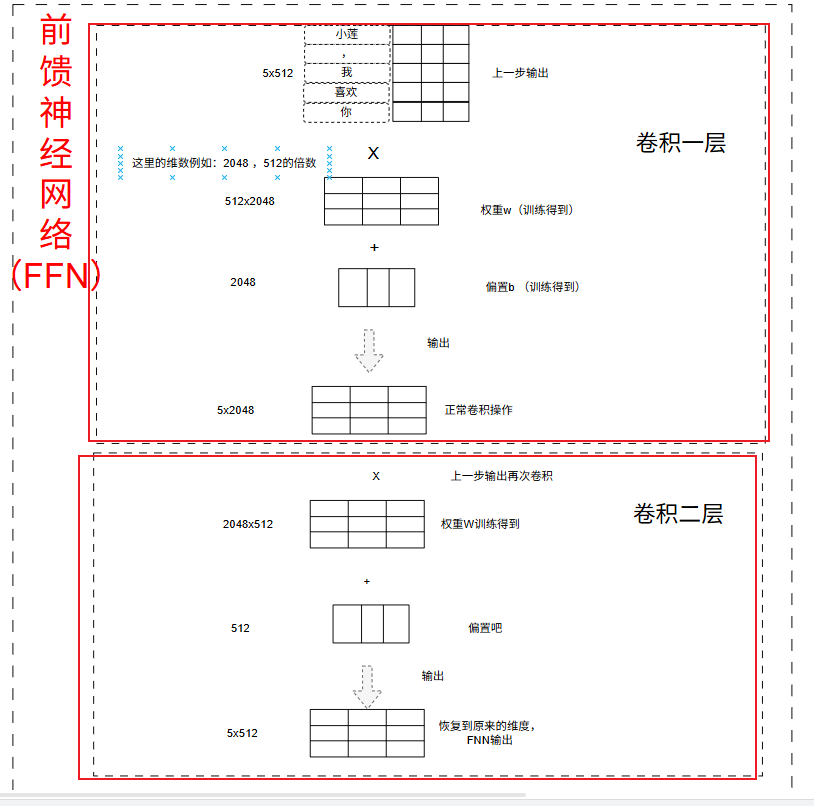
2.4.3 前馈神经网络(FFN)
在 Transformer 架构中,前馈神经网络(Feed-Forward Network, FFN) 是继自注意力机制之后的第二个核心子层。如果说自注意力负责 “token 之间的信息交流”,那么 FFN 就负责 “每个 token 的独立非线性变换”,是模型表达能力的关键来源。

总结下:注意力让模型 “看到全局关联”,FFN 让模型 “吃透每个位置的细节”,两者协同让 Transformer 的特征表达能力更全面。
前馈神经网络(FFN)是一种 “信息单向传播” 的基础网络结构,在 Transformer 中,它作为注意力机制的 “配套工具”,通过 “升维→非线性激活→降维” 的流程,对每个位置的特征进行独立的非线性变换,弥补了注意力机制在 “局部特征提炼” 上的不足。
其实吧这里应该好理解,就是类似CNN的卷积操作了,对每个token特征进行提取、分类、复杂的语义处理。
假设上一次输出为x,这里的输出(5x512)= (w1*x+b1) * w2+b2
w1:512x2048 b1:2048
w2:2048x512 b2:512
最终的输出还是为5x512
2.4.4 残差连接+LayerNorm (二)
这里就是参差连接的第二个步骤,都是差不多的操作,只是这里的输入不同。
这里的输入是:
- 上一次参差连接(一)输出(5x512) + FNN输出(5x512) = 新的输出(5x512)
- LayerNorm(新的512向量) = 最后文档特征输出的张量(5x512)
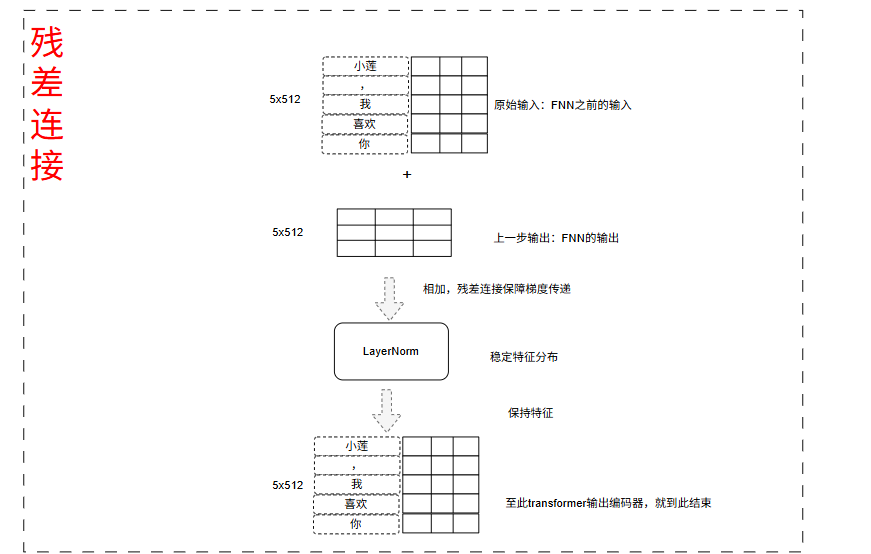
最总得到了5x512的向量,但是这里只是编码器一次的操作正常的情况下,会进行多次编码器的操作,标准的有6次编码器操作,以学习跟多的特征。
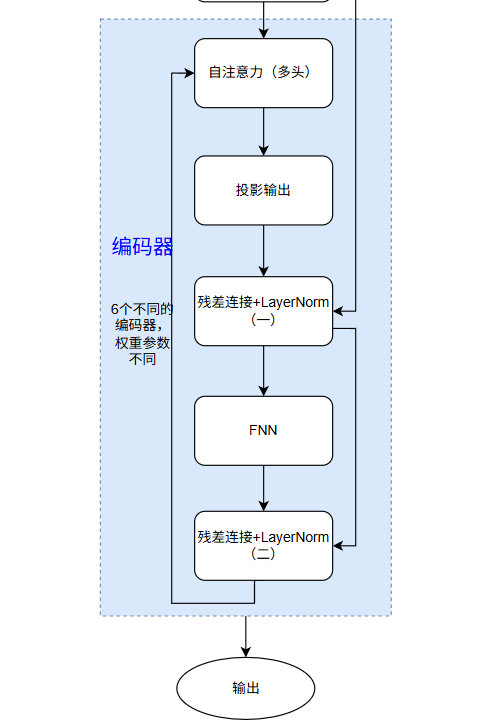
最终输出就丢入了解码器的输入了,编码器负责理解,解码器负责翻译。
至此输入到此结束。