小杰-大模型(five)——大模型部署与应用——Qwen2.5-0.5B本地部署
1. Qwen2.5-0.5B本地部署
根据之前的学习,我们知道,人工智能算法可以使用Windows或者Linux进行训练和部署,同时Windows和Linux都有对应的深度学习框架和NVIDIA加速CUDA,如PyTorch。
1.1 Qwen2.5-0.5B大模型介绍
1.1.1 Qwen2.5-0.5B大模型介绍
Qwen2.5是Qwen大模型的全新系列(以前版本有Qwen1,Qwen1.5,Qwen 2),参数量从 0.5B到 72B不等(其中“ B ”表示“十亿”, 72B 即为 720 亿)。我们以Qwen2.5-0.5B为例介绍本地部署方式。
网址:https://qwen.readthedocs.io/zh-cn/latest/
1.1.2 Qwen2.5-0.5B大模型量化介绍
1.1.2.1从魔搭社区模型库中输入量化,得到量化后的模型
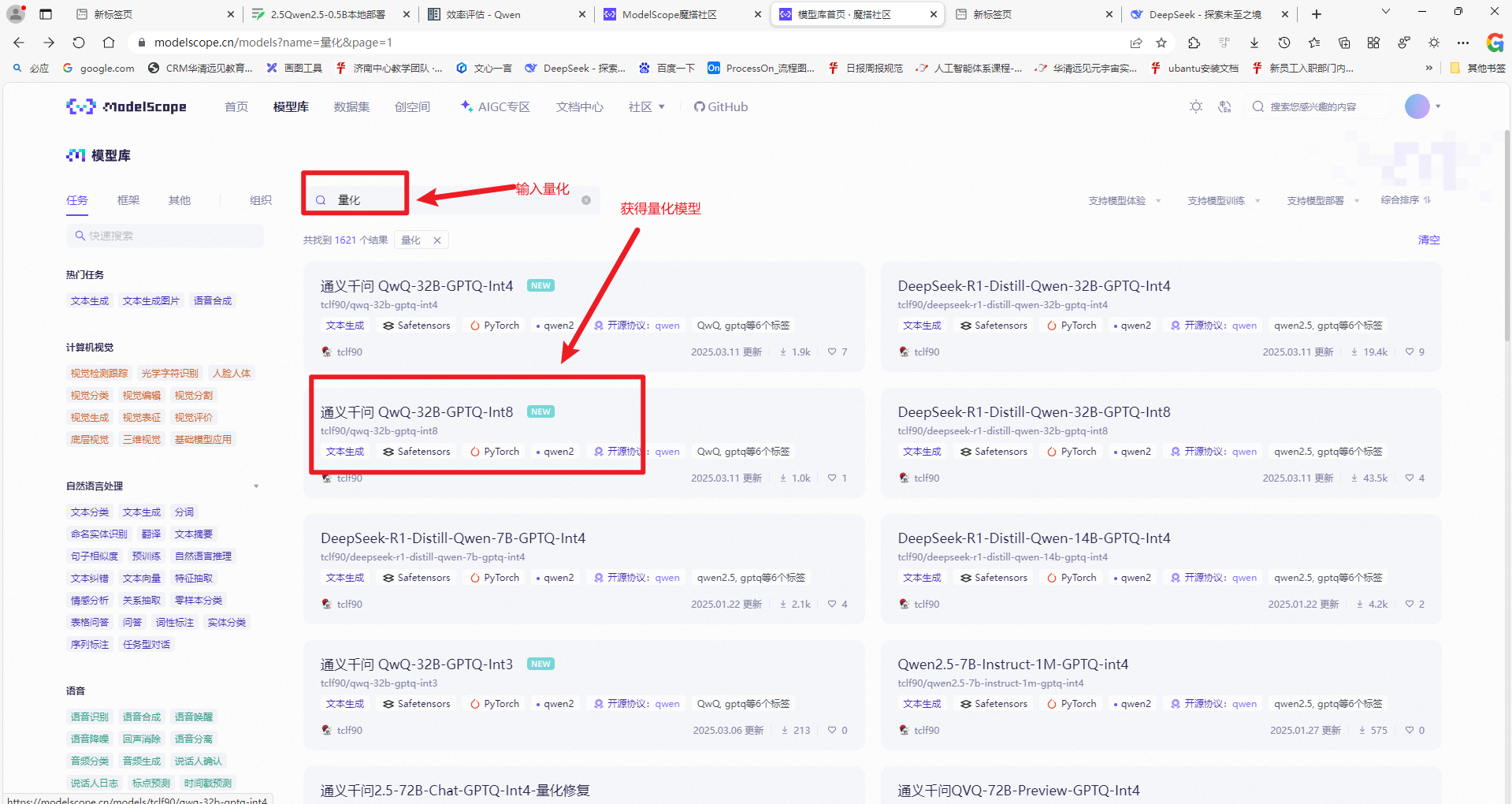
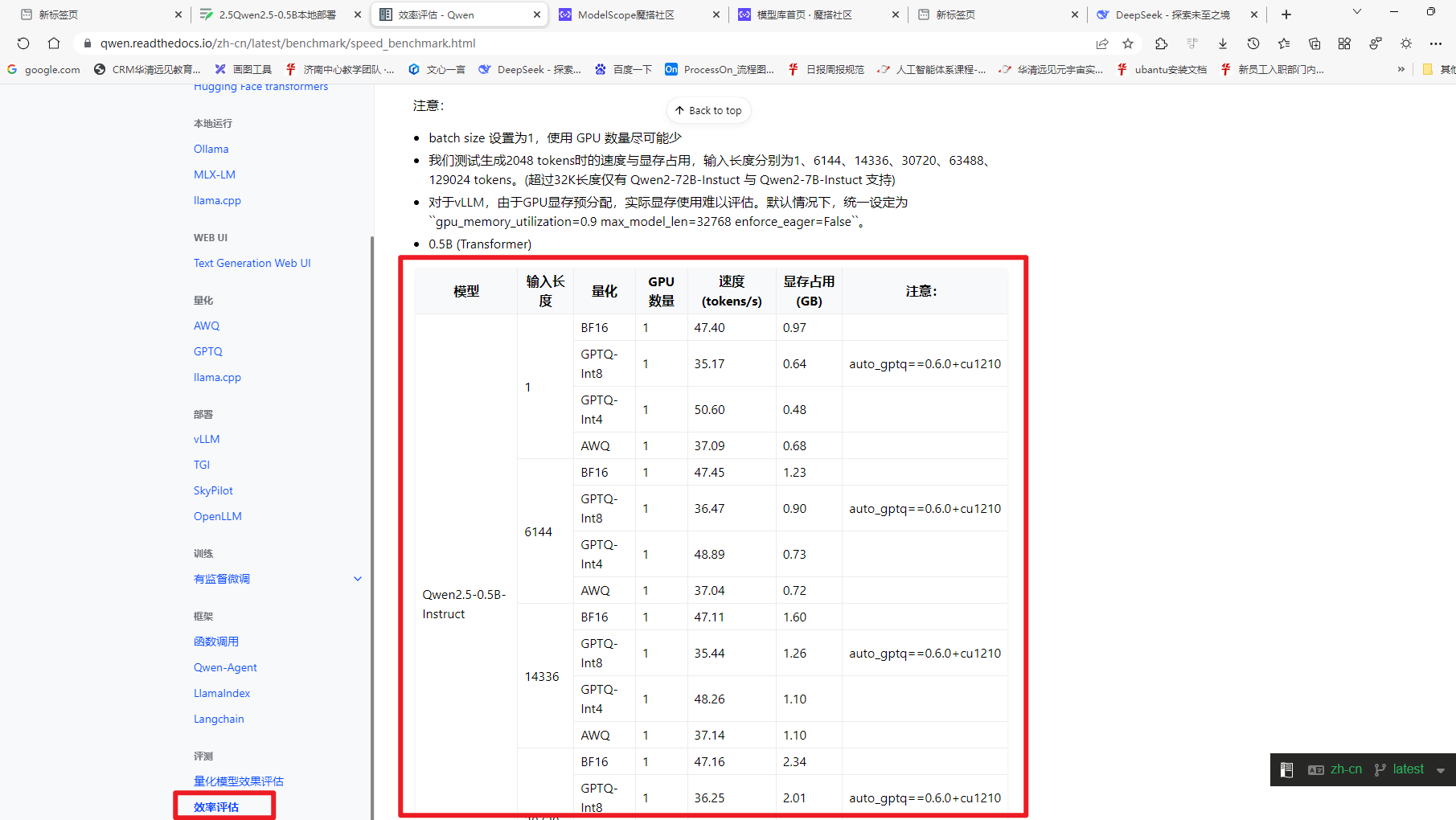
1.1.2.2为啥要量化及量化效果
网址:https://qwen.readthedocs.io/zh-cn/latest/ 下选择评测下的效果评估如下图
1.2 部署Qwen2.5-0.5B大模型的步骤
1.2 部署Qwen2.5-0.5B大模型的步骤
1. 环境准备
1.1使用Conda创建虚拟环境
1.点击开始,并在输入框输入Anaconda如下
2.选择并打开
3.创建新的Python虚拟环境
# 安装 Miniconda 或 Anaconda 后,创建新的虚拟环境
conda create --name AI_env python=3.11.9
4.可选择激活或者不激活如下操作
# 激活虚拟环境
conda activate AI_env步骤2:在Pycharm中使用创建的环境
在设置中添加刚创建的虚拟环境。
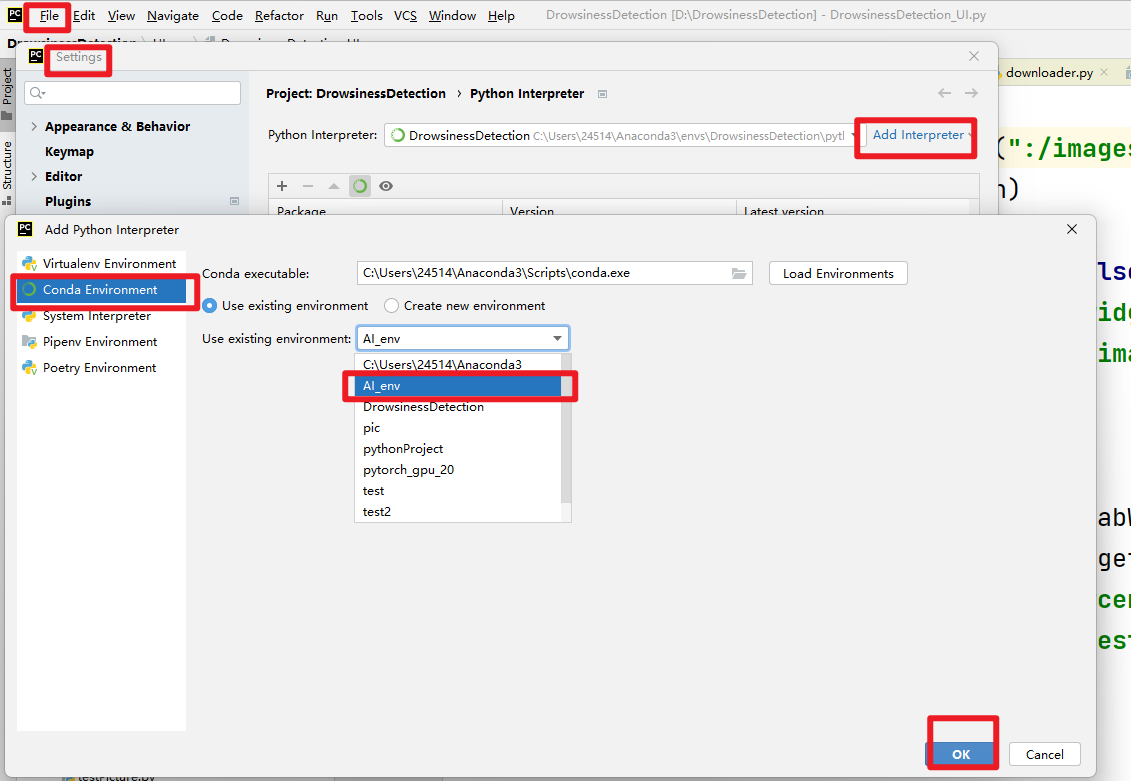
步骤3:安装必要依赖
在pycharm终端 使用以下命令安装所需的依赖库
安装 pytorch cpu版本(可选)
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple/安装 pytorch gpu版本(可选,如果有CUDA)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126安装 transformers
pip install transformers==4.45.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/pycharm中 安装魔搭社区
pip install modelscope==1.18.12. 下载Qwen模型
为了加快下载速度,我们使用魔搭社区的下载方式。
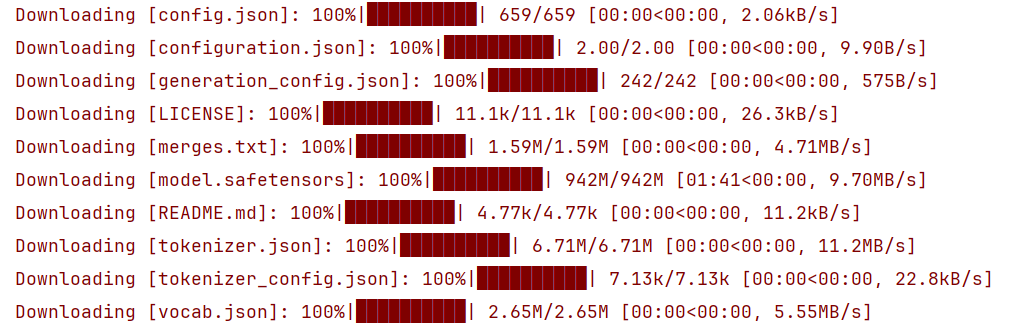
下载模型
新建文件downloador.py
from modelscope.hub.snapshot_download import snapshot_download#'Qwen/Qwen2.5-0.5B-Instruct'为魔搭社区上的路径。
# 'models'为本地路径。
llm_model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir='models')下载完毕(下载过程中最好不要有断网等操作)解释:
3. 模型推理
transformers 是一个非常流行的库,由 Hugging Face 提供,用于处理自然语言处理(NLP)任务。这个库中包含了许多预训练模型以及相应的工具,可以用来进行文本生成、情感分析、翻译等多种任务。
代码中需要 AutoModelForCausalLM 和 AutoTokenizer ,它们是 transformers 库中的两个重要组件,它们的作用如下:
- AutoTokenizer:
- 这是一个自动化的分词器类,可以根据指定的预训练模型自动选择合适的分词器。分词器的主要功能是将原始文本转换为模型可以理解的形式,比如将句子分解成单词或子词单元,并将这些单元映射到对应的数字ID(这个过程通常称为“tokenization”)。不同的模型可能需要不同类型的分词策略,而
AutoTokenizer能够根据模型名称自动加载正确的分词器配置。
- AutoModelForCausalLM:
- 这个类代表了一个用于因果语言建模(即给定前文预测下一个词的任务)的自动模型。它能够根据指定的模型名称自动加载一个适合做语言生成任务的预训练模型。这类模型常用于文本生成、对话系统等场景。
这两个类配合使用时,通常流程如下:
- 首先,使用
AutoTokenizer加载或创建一个分词器实例,准备对输入文本进行处理。 - 然后,使用
AutoModelForCausalLM加载一个预训练的语言模型。 - 接下来,利用分词器将原始文本转换为模型输入所需的格式。
- 最后,将处理后的数据输入到模型中,执行特定的任务,如文本生成。
代码示例
使用Qwen2___5-0___5B-Instruct进行推理
import torch
#从transformers库中导入的AutoModelForCausalLM(用于因果语言模型)和AutoTokenizer(自动化的分词工具)。
from transformers import AutoTokenizer,AutoModelForCausalLM
#指定一下设备
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#使用预训练模型Qwen2.5-0.5B的分词器实例化 Tokenizer对象
tokenizer=AutoTokenizer.from_pretrained("Qwen2___5-0___5B-Instruct")
# print(tokenizer)
model=AutoModelForCausalLM.from_pretrained("Qwen2___5-0___5B-Instruct").to(device)
#设置对话的提示词
#用户输入 比如“你好”
prompt="你是谁?"
# 定义对话历史,包括系统信息(指示助手的角色)和用户输入的提示。
messages=[{"role":"system","content":"You are a helpful assistant."},{"role":"user","content":prompt}
]
# tokenizer.apply_chat_template这是用于应用聊天模板的方法,
# 将对话历史(messages)格式化为模型所需的输入文本格式
text=tokenizer.apply_chat_template(
# messages 输入的对话历史,通常是一个包含多轮对话的列表messages,
# tokenize=False,返回的是格式化后的文本字符串(而非分词后的 token IDs)tokenize=False,
# add_generation_prompt=True 在末尾添加一个生成提示符(例如 <|assistant|>),告诉模型接下来该生成回复add_generation_prompt=True
)
print(text)
model_inputs=tokenizer([text],return_tensors='pt').to(device)
print(model_inputs)# 使用模型生成新的token序列,最大生成新的token数量为512
generated_ids=model.generate(model_inputs.input_ids,max_new_tokens=512)
#解码
response =tokenizer.batch_decode(generated_ids)
# 截取生成的token序列,去除原始输入的部分。
generated_ids =[output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response=tokenizer.batch_decode(generated_ids,skip_special_tokens=True)[0]
# #从打印结果看包含特殊字符
print(response)