RAG的检索与排序增强实现原理
图片来源网络,侵权联系删

文章目录
- 一、检索增强:从“单一匹配”到“多策略融合”
- 1. 混合检索的技术原理
- 2. 混合检索的实现细节
- 3. 混合检索的工业实践
- 二、排序增强:从“粗排”到“精排”
- 1. 重排序的技术原理
- 2. 重排序的实现细节
- 3. 重排序的工业实践
- 三、检索与排序增强的协同效应
- 四、最新进展与未来趋势
- 总结

一、检索增强:从“单一匹配”到“多策略融合”
传统RAG的检索环节多依赖单一语义检索(如向量相似度),但这种方式存在语义偏差(无法处理精确关键词)、长尾覆盖不足(罕见查询匹配差)等问题。检索增强的核心是混合检索(Hybrid Retrieval),即结合语义检索与关键词检索的优势,实现“精准匹配+广泛覆盖”的平衡。
1. 混合检索的技术原理
混合检索的本质是两种检索结果的加权融合 ,通过线性加权公式计算综合得分:
KaTeX parse error: Undefined control sequence: \[ at position 2: \̲[̲综合得分=α⋅BM25_sco…
KaTeX parse error: Undefined control sequence: \[ at position 2: \̲[̲\text{综合得分} =\a…
其中:
- BM25_score:基于关键词匹配的得分(由TF-IDF改进而来,考虑词频、文档长度归一化),擅长处理精确关键词(如产品型号、法律条款编号);
- Semantic_score:基于向量相似度的得分(由Sentence-BERT等模型生成),擅长处理语义泛化(如“适合夏天的鞋子”→“透气网面运动鞋”);
- α:权重参数(0≤α≤1),用于平衡两种检索的贡献。
2. 混合检索的实现细节
- 权重调优:通过网格搜索(Grid Search)或贝叶斯优化(Bayesian Optimization)在验证集上确定最佳α值。例如,电商场景中α通常取0.4-0.6(语义检索占比略高,兼顾精准与泛化);
- 归一化处理:由于BM25和Semantic_score的量纲不同(如BM25得分范围为0-100,Semantic_score范围为0-1),需先对两者进行Min-Max归一化(将得分映射到0-1区间),再进行加权融合;
- 结果融合:将关键词检索与语义检索的候选文档合并,按综合得分排序,保留Top-K(如Top-50)作为后续排序的输入。
3. 混合检索的工业实践
- 案例1(电商场景):某电商平台采用混合检索(BM25+语义检索),将搜索准确率提升15%-30%。其中,α=0.5时,既保证了关键词匹配的精准度(如“iPhone 15 Pro Max”的搜索结果),又覆盖了语义泛化的需求(如“2025年最新旗舰手机”的搜索结果);
- 案例2(法律场景):某法律AI企业采用混合检索,解决了“法律条款编号”(关键词检索)与“条款内容语义”(语义检索)的匹配问题,将法律问答的准确率提升20%。
二、排序增强:从“粗排”到“精排”
检索增强解决了“找得到”的问题,但初始检索结果(如Top-50)仍存在相关性排序不准确的问题(如将“次要相关”文档排在“核心相关”文档前面)。排序增强的核心是重排序(Reranking),即通过更精细的模型对初始候选文档进行二次排序,将“最相关”的文档排在前面。
1. 重排序的技术原理
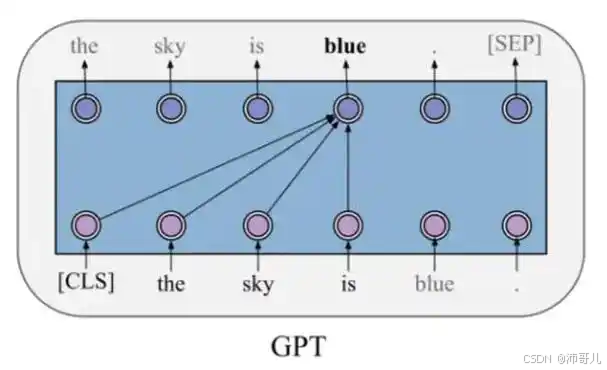
重排序的主流方法是交叉编码器(Cross-Encoder),其核心思想是将查询与文档拼接成一个输入,通过Transformer模型直接建模两者的深层交互。
- 输入结构:采用BERT-style的拼接方式,如
[CLS] Query [SEP] Document [SEP]; - 模型处理:Transformer的自注意力机制(Self-Attention)会学习查询与文档之间的细粒度语义关联(如查询中的“续航”与文档中的“电池容量”“使用时间”的关联);
- 得分计算:取
[CLS]token的隐藏状态作为全局表示,通过全连接层(MLP)输出相关性得分(如0-1之间的概率值)。
2. 重排序的实现细节
- 模型选择:2025年最新的重排序模型以开源Cross-Encoder为主,如:
- bge-reranker:完全开源,中等硬件即可执行,适合通用RAG场景;
- MixedBread(mxbai-rerank-v2):宣称SOTA性能,推理速度快,支持长上下文(如1024token以上),适合长文档场景;
- Cohere Rerank:私有API,多语言支持好,适合企业级应用(需付费)。
- 候选文档输入:重排序通常处理初始检索的Top-N候选(如Top-50),因为处理全部候选(如Top-1000)会增加计算成本。研究表明,处理Top-50的候选文档即可覆盖90%以上的核心相关文档;
- 批处理优化:为了提高推理速度,重排序模型通常采用批处理(Batch Processing)(如一次处理10个候选文档),减少模型加载次数。
3. 重排序的工业实践
- 案例1(通用RAG):某企业采用bge-reranker对初始检索的Top-50候选文档进行重排序,将相关性排序的准确率提升25%-35%。其中,对于“如何优化RAG的检索策略”这一问题,重排序后将“混合检索+重排序”的核心文档排在第一位,而初始检索将其排在第三位;
- 案例2(长文档场景):某技术文档平台采用**MixedBread(mxbai-rerank-v2)**对1000页的技术文档进行重排序,将“特定功能”的相关段落排在前面,将检索时间缩短40%(相比初始检索的Top-10)。

三、检索与排序增强的协同效应
检索增强(混合检索)与排序增强(重排序)并非独立,而是协同作用,共同提升RAG系统的性能:
- 检索增强为排序增强提供高质量候选:混合检索通过“关键词+语义”的融合,扩大了候选文档的覆盖范围,避免了“语义检索”遗漏精确关键词的问题;
- 排序增强优化检索结果的顺序:重排序通过“深层语义交互”的建模,将“最相关”的文档排在前面,解决了初始检索“粗排”的问题。
研究表明,混合检索+重排序的组合可将RAG系统的事实准确率提升30%-50%(相比单一语义检索),用户满意度提升20%-30%(相比单一关键词检索)。
四、最新进展与未来趋势
- 模型蒸馏:为了降低重排序的计算成本,研究人员采用模型蒸馏(Model Distillation)技术,将Cross-Encoder的“深层语义交互”能力迁移到Bi-Encoder(更快的模型)中,实现“兼顾速度与效果”的重排序;
- 动态权重调整:根据查询类型(如事实查询、语义查询)动态调整混合检索的权重α(如事实查询取α=0.7,语义查询取α=0.3),提升检索的灵活性;
- 元数据增强:在检索与排序中加入元数据(如文档的“发布时间”“作者”“领域”),提升检索的“时效性”与“专业性”(如“2025年的AI趋势”优先检索2025年发布的文档)。
总结
RAG的检索与排序增强是**“多策略融合+精细化建模”**的过程:
- 检索增强通过混合检索(关键词+语义)解决“找得到”的问题,扩大候选文档的覆盖范围;
- 排序增强通过重排序(Cross-Encoder)解决“排得准”的问题,将最相关的文档排在前面;
- 两者的协同作用,显著提升了RAG系统的事实准确率与用户满意度,成为当前RAG技术优化的核心方向。
未来,随着模型蒸馏、动态权重调整等技术的进一步发展,检索与排序增强将更加高效、灵活,为RAG系统在企业级应用(如客服、知识管理)中的普及奠定基础。