语义模型 - 从 Transformer 到 Qwen
语义模型
Transformers
Huggingface Transformers 是基于一个开源基于 transformer 模型结构提供的预训练语言库,它支持 Pytorch,Tensorflow2.0,并且支持两个框架的相互转换。
其本质上是一个 Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:Encoder 和 Decoder。
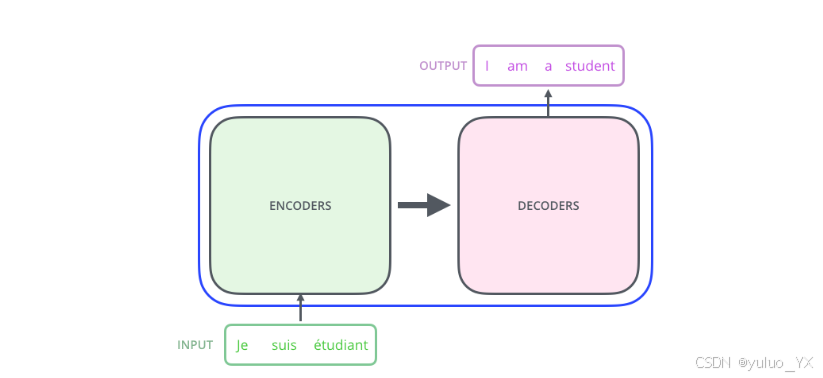
Decoder-Only & Encoder-Only
Decoder-Only 模型
GPT Qwen 等属于 Decoder-Only 模型,是生成式模型。
Encoder-Only 模型
其输出是一个embedding向量。与 decoder-only 的文本回答不同,encoder-only 模型将其“答案”编码成这种压缩的数值形式。
这个向量是模型输入的压缩表示,因此有时 encoder-only 模型也被称为表征模型(representational models)。
经常与 Decoder-Only 的模型一起使用,组建更强大的 AI 应用(例如 RAG)。
Bert
Bert 全称为 Bidirectional Encoder Representations from Transformers。是一种基于 Transformers 的双向编码器表示,它只使用了 Transformer 中的 Encoder 部分,用于语言理解的预训练模型。改进了单向编码器的局限性,通过双向上下文提供更强大的语义信息提取能力,广泛应用于多项NLP任务,并在多个基准测试中取得突破性成果。
举个例子理解下双向编码器:
今天天气很差,我们不得不取消户外运动。
将句中的某个字或词挖走,句子就变成:今天天气很( ),我们不得不取消户外运动。分别从单向编码(如 GPT)和双向编码(如 BERT)的角度来考虑“( )”中应该填什么词。
单向编码只会使用“今天天气很”这五个字的信息来推断“( )”内的字或词,从人类角度考虑,使用概率最大的词应该是:“好”“不错”“差”“糟糕”,而这些词可以被划分为截然不同的两类。
双向编码可以利用下文信息“我们不得不取消户外运动”来帮助模型判断,从人类角度考虑,概率最大的词应该是:“差”“糟糕”。
以此就可以直观地感受到,不考虑模型的复杂度和训练数据量,双向编码与单向编码相比,可以利用更多的上下文信息来辅助当前词的语义判断。在语义理解能力上表现更好。
ModernBERT
ModernBERT 是 BERT 的现代化版本,旨在提高下游任务的性能和处理效率。与其前身不同,它支持更长的 Token,更现代的训练方式
GPT
Generative Pre-trained Transformer(GPT)系列是由 OpenA 提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的 NLP 任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A 等。现在已经被广泛应用。
Qwen3
和 GPT 系列模型类似,都是基于 Transforms Decoder 的生成式 AI 模型,由阿里云发布,在架构上和 GPT 略有不同。
模型文件结构
模型保存形式
- .safetensors 由 Hugging Face 提出,侧重于安全性和效率,适合于那些希望快速部署且对安全有较高要求的场景,尤其在Hugging Face生态中。
- .ckpt 文件是 PyTorch Lightning 框架采用的模型存储格式,它不仅包含了模型参数,还包括优化器状态以及可能的训练元数据信息,使得用户可以无缝地恢复训练或执行推理。
- .bin 文件不是标准化的模型保存格式,但在某些情况下可用于存储原始二进制权重数据,加载时需额外处理。
- .pth 是PyTorch的标准模型保存格式,方便模型的持久化和复用,支持完整模型结构和参数的保存与恢复。
- .onnx(Open Neural Network Exchange)文件是一个开放格式,用于表示机器学习模型。它旨在提供一种标准的方式来表示深度学习模型,使得模型可以在不同的框架和工具之间进行转换和互操作
文件结构
以 Qwen 0.6B 为例。
Qwen3-0.6B
├── config.json # 控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等
├── generation_config.json
├── LICENSE
├── merges.txt
├── model.safetensors
├── README.md
├── tokenizer_config.json
├── tokenizer.json # tokenizer.json 和 tokenizer_config.json 分词的配置文件
└── vocab.json # vocab.txt 词典文件
扩展
激活函数
神经网络模拟的是人脑中的神经元结构,激活函数旨在帮助网络学习数据中的复杂模式。在神经元中,输入经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。
通俗来讲,就是将输入和输出的映射升纬,使模型适配更多的非线性情况。激活函数可以分为线性激活函数(线性方程控制输入到输出的映射,如 f(x)=x 等)以及非线性激活函数(非线性方程控制输入到输出的映射,比如Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish 等)
Tokenizer
Tokenizer分词算法是NLP大模型最基础的组件,基于Tokenizer可以将文本转换成独立的token列表,进而转换成输入的向量成为计算机可以理解的输入形式。
根据不同的切分粒度可以把tokenizer分为:
- 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。
- subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。
- 完整的分词流程包括:文本归一化,预切分,基于分词模型的切分,后处理。
- SentencePiece是一个分词工具,内置BEP等多种分词方法,基于Unicode编码并且将空格视为特殊的token。这是当前大模型的主流分词方案。
| 分词方法 | 典型模型 |
|---|---|
| BPE | GPT, GPT-2, GPT-J, GPT-Neo, RoBERTa, BART, LLaMA, ChatGLM-6B, Baichuan |
| WordPiece | BERT, DistilBERT,MobileBERT |
| Unigram | AlBERT, T5, mBART, XLNet |
LoRA 微调
LoRA:Low-Rank Adaptation of Large Language Models(低阶自适应参数高效微调 )。
基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型微调类似的效果。
参考
- https://zhuanlan.zhihu.com/p/535100411
- https://zhuanlan.zhihu.com/p/1911115248053755995
- https://yuluo-yx.github.io/blog/deep-learn-init/#%E5%88%86%E7%B1%BB%E9%97%AE%E9%A2%98%E5%BC%95%E5%85%A5
- https://yuluo-yx.github.io/docs/LLMs-AI-llms-what-token/#%E5%88%86%E8%AF%8D%E5%99%A8%E5%8E%9F%E7%90%86