redis实战day2(秒杀)
目录
优惠卷秒杀:
1.全局唯一ID:
2.添加优惠卷:
3.秒杀下单:
4.一人一单(单体项目一步步解决)
分布式锁:
1.基本原理和实现方式对比:
2.Redis分布式锁的实现核心思路
redission
1-redission功能介绍:
2.redission可重入锁原理
3.redission锁重试和WatchDog机制(源码解读)
3.1redission锁重试
3.2看门狗机制
3.3redission锁的MutiLock原理
优惠卷秒杀:
1.全局唯一ID:
每个店铺都可以发布优惠券:
如果订单表使用数据库自增ID就存在一些问题:
-
id的规律性太明显
-
受单表数据量的限制
场景分析:如果我们的id具有太明显的规则,用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
场景分析二:随着我们商城规模越来越大,mysql的单表的容量不宜超过500W,数据量过大之后,我们要进行拆库拆表,但拆分表了之后,他们从逻辑上讲他们是同一张表,所以他们的id是不能一样的, 于是乎我们需要保证id的唯一性。
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
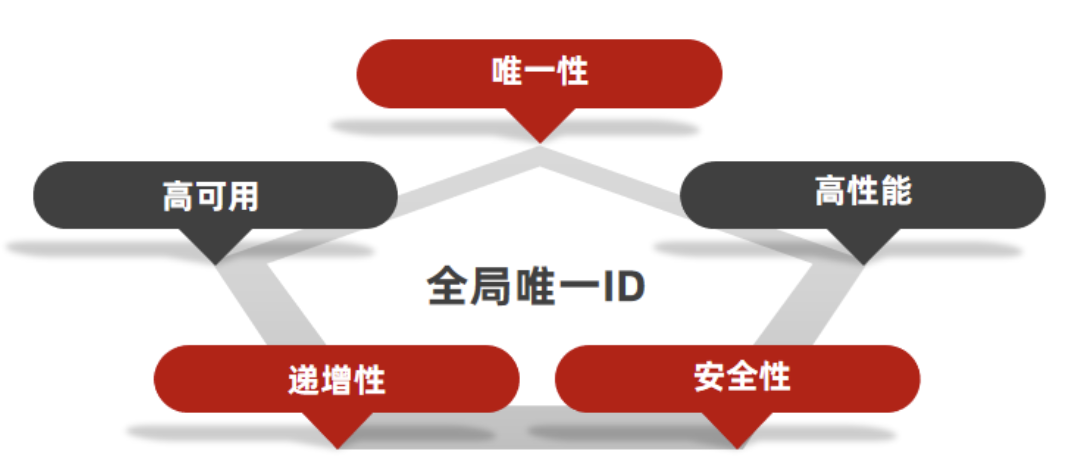
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:  上面都是二进制形式
上面都是二进制形式
Redis实现全局唯一Id:
@Component
public class RedisIdWorker {/*** 开始时间戳*/private static final long BEGIN_TIMESTAMP = 1640995200L;/*** 序列号的位数*/private static final int COUNT_BITS = 32;private StringRedisTemplate stringRedisTemplate;public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}public long nextId(String keyPrefix) {// 1.生成时间戳LocalDateTime now = LocalDateTime.now();long nowSecond = now.toEpochSecond(ZoneOffset.UTC);long timestamp = nowSecond - BEGIN_TIMESTAMP;// 2.生成序列号// 2.1.获取当前日期,精确到天String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));// 2.2.自增长long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);// 3.拼接并返回return timestamp << COUNT_BITS | count;}
}
ZoneOffset.UTC表示世界协调时(UTC)的时区偏移量,也就是 +0 时区。long nowSecond = now.toEpochSecond(ZoneOffset.UTC);这行代码的作用是:
将
LocalDateTime对象now转换为从 1970-01-01T00:00:00Z 开始的秒数使用 UTC 时区 进行计算,避免时区差异导致的时间戳不一致问题
例如:
LocalDateTime now = LocalDateTime.now();// 使用系统默认时区(可能产生差异) long defaultSecond = now.toEpochSecond(ZoneOffset.ofHours(8)); // 使用UTC时区(统一标准) long utcSecond = now.toEpochSecond(ZoneOffset.UTC);
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));这行代码的作用:
DateTimeFormatter.ofPattern("yyyy:MM:dd"):创建一个日期格式化器,格式为 "年:月:日"
now.format(...):将当前时间格式化为指定格式的字符串结果示例:
"2024:03:15"
方式 输出示例 说明 不格式化 2024-03-15T10:30:45.123ISO-8601 标准格式 格式化后 2024:03:15自定义格式
StringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date)这是一个 Redis 的原子自增操作:
stringRedisTemplate.opsForValue():获取操作 String 类型值的接口
.increment(key):对指定 key 的值执行原子性的 +1 操作返回值:自增后的新值
特点:
原子性:多个客户端同时操作也不会出现并发问题
自动创建:如果 key 不存在,会先初始化为 0,然后执行 +1
键名构成:
"icr:业务前缀:2024:03:15"
测试类
@Test
void testIdWorker() throws InterruptedException {CountDownLatch latch = new CountDownLatch(300);Runnable task = () -> {for (int i = 0; i < 100; i++) {long id = redisIdWorker.nextId("order");System.out.println("id = " + id);}latch.countDown();};long begin = System.currentTimeMillis();for (int i = 0; i < 300; i++) {es.submit(task);}latch.await();long end = System.currentTimeMillis();System.out.println("time = " + (end - begin));
}1.创建任务(定义工作内容)
Runnable task = () -> {for (int i = 0; i < 100; i++) {long id = redisIdWorker.nextId("order");System.out.println("id = " + id);}latch.countDown(); };✅ 只是定义:这里只是创建了一个
Runnable对象,描述了"要做什么",但还没有执行2. 提交并执行任务
for (int i = 0; i < 300; i++) {es.submit(task); // 提交任务并开始执行 }✅ 提交即执行:
es.submit(task)不仅提交任务,还立即开始执行(由线程池分配线程来执行)
es.submit(task)详细解释
es.submit(task)是 Java 并发编程中向线程池提交任务的核心方法。
es是一个 ExecutorService(执行器服务)实例也就是我们常说的线程池
它负责管理和调度线程来执行任务
// 创建固定大小的线程池 ExecutorService es = Executors.newFixedThreadPool(10);// 或者创建缓存线程池 ExecutorService es = Executors.newCachedThreadPool();es.submit(task);"请线程池帮我执行这个任务"线程池处理
线程池内部: ├─ 如果有空闲线程 → 立即执行任务 ├─ 如果没有空闲线程但线程数未达上限 → 创建新线程执行 └─ 如果线程数已达上限 → 任务进入队列等待
知识小贴士:关于countdownlatch
CountDownLatch是 Java 并发编程中的一个同步工具类,可以理解为 "倒计时门闩" 或 "计数器锁"countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
1、countDown
2、await
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
主线程开始 │ ├─ 创建计数器(300) ├─ 定义任务模板 ├─ 记录开始时间 │ ├─ 提交300个任务到线程池 │ ├─ 线程1: 生成100个ID → 计数器-1 │ ├─ 线程2: 生成100个ID → 计数器-1 │ ├─ ... │ └─ 线程300: 生成100个ID → 计数器-1 │ ├─ 主线程等待(await) │ (等待计数器从300减到0) │ └─ 所有任务完成 → 计算总耗时
场景设定:
线程池大小:10个线程
CPU能力:1个核心(只能真正同时运行1个线程)
任务数量:15个任务
1.任务分配
// 提交15个任务 for (int i = 1; i <= 15; i++) {es.submit(task); }结果:
立即执行:10个任务被分配给10个线程,进入就绪状态
等待队列:5个任务进入线程池的等待队列
2.CPU调度(时间片轮转)
text
时间轴: t1 t2 t3 t4 t5 CPU: [线程A] [线程B] [线程C] [线程A] [线程D] ... 状态: 运行 运行 运行 运行 运行具体过程:
操作系统调度:CPU通过时间片轮转在10个线程间快速切换
微观串行:每个时刻只有1个线程真正在CPU上运行
宏观并发:由于切换速度极快(纳秒级),看起来像是10个线程同时在运行
3.任务完成与队列处理
初始:线程池[10个活跃线程] + 队列[5个等待任务]步骤1:线程A完成任务 → 从队列取任务6 → 继续执行 步骤2:线程B完成任务 → 从队列取任务7 → 继续执行 ... 步骤5:线程E完成任务 → 从队列取任务10 → 继续执行此时:队列为空,所有15个任务都在执行或已完成
2.添加优惠卷:
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀抢购:
tb_voucher:优惠券的基本信息,优惠金额、使用规则等 tb_seckill_voucher:优惠券的库存、开始抢购时间,结束抢购时间。特价优惠券才需要填写这些信息
平价卷由于优惠力度并不是很大,所以是可以任意领取
而代金券由于优惠力度大,所以像第二种卷,就得限制数量,从表结构上也能看出,特价卷除了具有优惠卷的基本信息以外,还具有库存,抢购时间,结束时间等等字段
新增普通卷代码: VoucherController
@PostMapping
public Result addVoucher(@RequestBody Voucher voucher) {voucherService.save(voucher);return Result.ok(voucher.getId());
}新增秒杀卷代码:
@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {// 保存优惠券save(voucher);// 保存秒杀信息SeckillVoucher seckillVoucher = new SeckillVoucher();seckillVoucher.setVoucherId(voucher.getId());seckillVoucher.setStock(voucher.getStock());seckillVoucher.setBeginTime(voucher.getBeginTime());seckillVoucher.setEndTime(voucher.getEndTime());seckillVoucherService.save(seckillVoucher);// 保存秒杀库存到Redis中stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());
}VoucherController
@PostMapping("seckill")
public Result addSeckillVoucher(@RequestBody Voucher voucher) {voucherService.addSeckillVoucher(voucher);return Result.ok(voucher.getId());
}VoucherServiceImpl
@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {// 保存优惠券save(voucher);// 保存秒杀信息SeckillVoucher seckillVoucher = new SeckillVoucher();seckillVoucher.setVoucherId(voucher.getId());seckillVoucher.setStock(voucher.getStock());seckillVoucher.setBeginTime(voucher.getBeginTime());seckillVoucher.setEndTime(voucher.getEndTime());seckillVoucherService.save(seckillVoucher);// 保存秒杀库存到Redis中stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());
}3.秒杀下单:
3.1基本代码实现
秒杀下单应该思考的内容:
下单时需要判断两点:
-
秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
-
库存是否充足,不足则无法下单
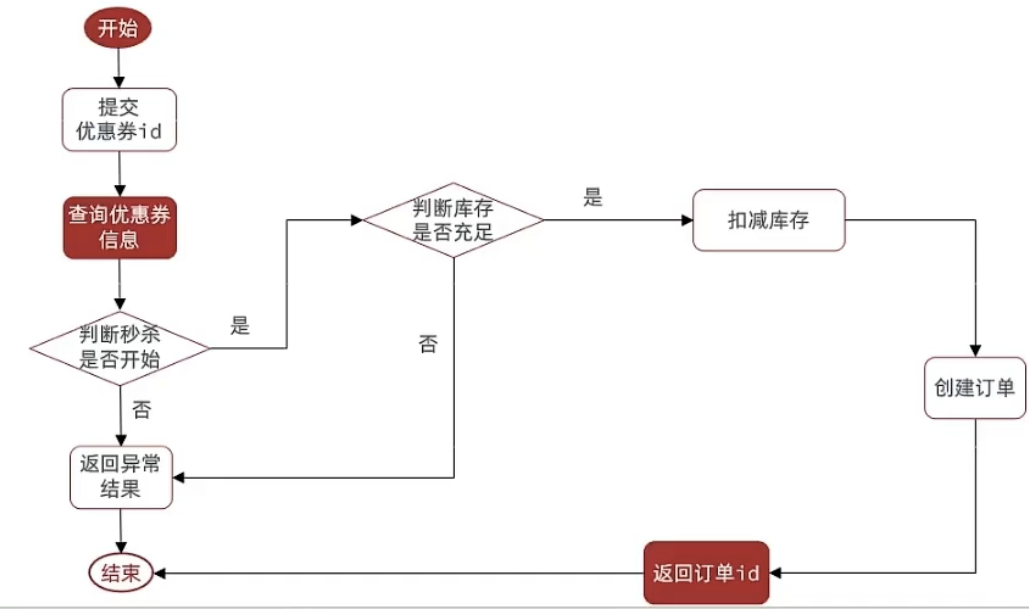
下单核心逻辑分析:
当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件
比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。
VoucherOrderServiceImpl
@Override
public Result seckillVoucher(Long voucherId) {// 1.查询优惠券SeckillVoucher voucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀尚未开始!");}// 3.判断秒杀是否已经结束if (voucher.getEndTime().isBefore(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀已经结束!");}// 4.判断库存是否充足if (voucher.getStock() < 1) {// 库存不足return Result.fail("库存不足!");}//5,扣减库存boolean success = seckillVoucherService.update().setSql("stock= stock -1").eq("voucher_id", voucherId).update();if (!success) {//扣减库存return Result.fail("库存不足!");}//6.创建订单VoucherOrder voucherOrder = new VoucherOrder();// 6.1.订单idlong orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);// 6.2.用户idLong userId = UserHolder.getUser().getId();voucherOrder.setUserId(userId);// 6.3.代金券idvoucherOrder.setVoucherId(voucherId);save(voucherOrder);return Result.ok(orderId);}3.2库存超卖问题分析
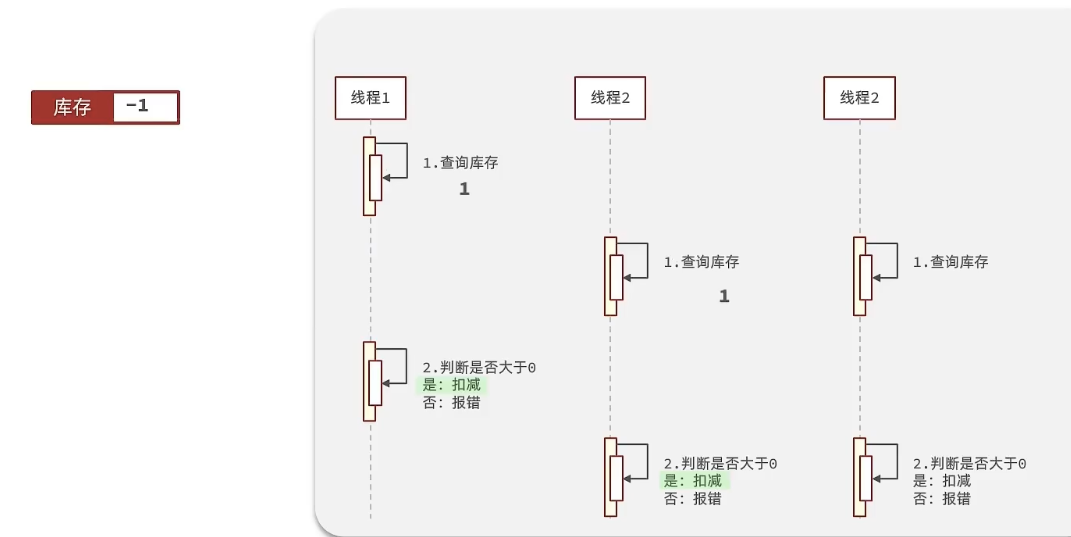
有关超卖问题分析:在我们原有代码中是这么写的
if (voucher.getStock() < 1) {// 库存不足return Result.fail("库存不足!");}//5,扣减库存boolean success = seckillVoucherService.update().setSql("stock= stock -1").eq("voucher_id", voucherId).update();if (!success) {//扣减库存return Result.fail("库存不足!");}
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:见下图: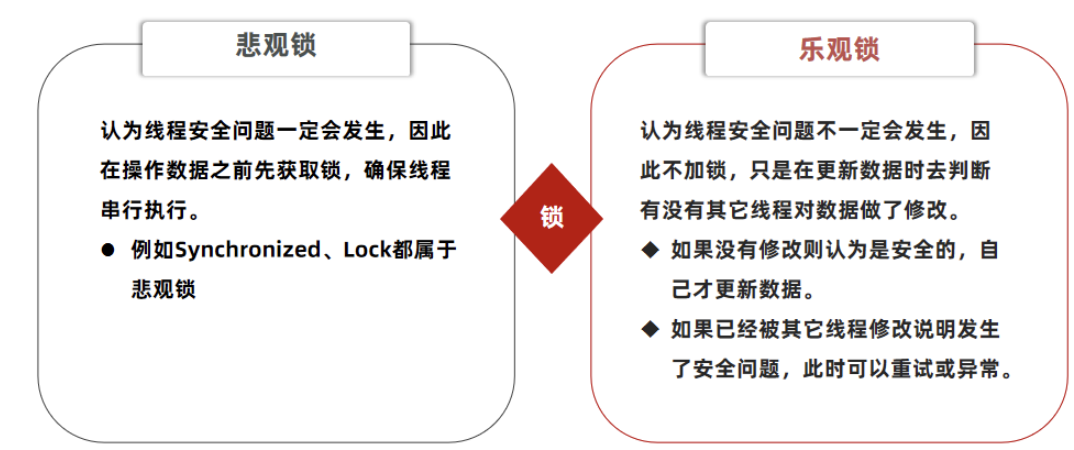
| 特性 | 悲观锁 | 乐观锁 |
|---|---|---|
| 核心思想 | “先取锁,再访问”。假设每次数据访问都会导致冲突,因此在操作数据之前,必须先获取锁,确保在锁的持有期间,没有其他事务能修改数据。 | “先访问,更新时再检查”。假设大部分情况下数据不会冲突,因此直接操作数据,只在提交更新时,检查数据是否被其他事务修改过。 |
| 实现方式 | 依赖数据库或编程语言提供的锁机制。 • 数据库: SELECT ... FOR UPDATE• Java: synchronized、ReentrantLock | 通过程序逻辑实现,通常使用版本号或CAS机制。 • 版本号: UPDATE ... SET ..., version=version+1 WHERE id=? AND version=?• CAS: UPDATE ... SET balance=80 WHERE id=? AND balance=100 |
| 操作步骤 | 1. 开始事务。 2. 获取锁(如 FOR UPDATE)。3. 读取、修改数据。 4. 提交事务(释放锁)。 | 1. 读取数据及版本号。 2. 在内存中修改数据。 3. 提交更新,检查版本号/旧值。 4. 若失败,则重试或报错。 |
| 类比 | 独占模式:就像租房子,你签了合同(拿到锁)期间,别人不能住。 | 协作模式:就像合租公寓,大家都可以进厨房,但如果你发现你准备用的调料被别人用光了(数据变了),你就得重新规划你的菜谱(重试)。 |
| 优点 | • 简单粗暴:实现简单,理解直观。 • 强一致性:能保证操作过程中的绝对隔离,无冲突。 | • 性能高:无锁操作,并发能力强,适合读多写少的场景。 • 避免死锁:由于不长期持有锁,死锁概率大大降低。 |
| 缺点 | • 性能开销大:加锁、释放锁消耗资源,并发量下降。 • 死锁风险:多个事务相互等待锁,容易产生死锁。 • 可扩展性差 | • 存在失败风险:更新可能失败,需要额外的重试逻辑。 • ABA问题(CAS法特有)。 • 在写冲突频繁的场景下,重试开销大,性能反而更差。 |
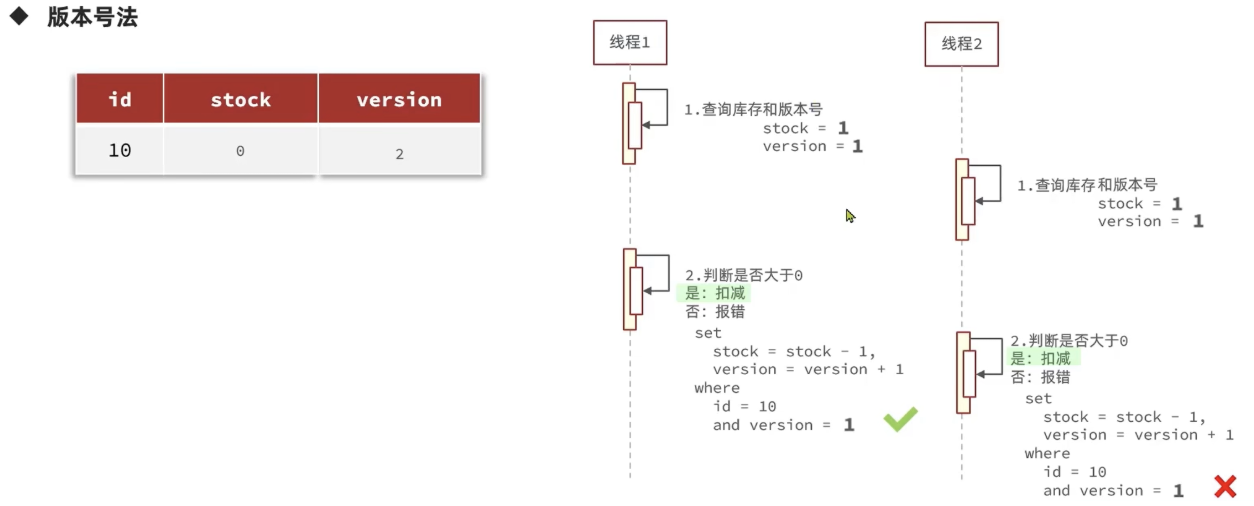
3.2.1 版本号法
这种方法通过一个独立的、单调递增的字段(版本号)来检测数据的变化。
工作原理:
-
读取数据:同时读取数据本身和当前的版本号(例如
version = 1)。 -
业务计算:在内存中修改数据。
-
更新数据:执行更新时,在 SET 子句中增加版本号,并在 WHERE 子句中指定之前读取的版本号。
-
sql
UPDATE table_name SET column1 = new_value, version = version + 1 WHERE id = #{id} AND version = #{old_version}; -
判断结果:
-
如果该行数据被成功更新(Affected rows > 0),说明在本次操作期间没有其他事务更新过该数据。因为
WHERE条件中的旧版本号匹配成功了。 -
如果更新失败(Affected rows = 0),说明在读取之后、更新之前,数据已经被其他事务修改(版本号已经增加),导致
WHERE条件不匹配。此时操作失败,需要进行重试。
-
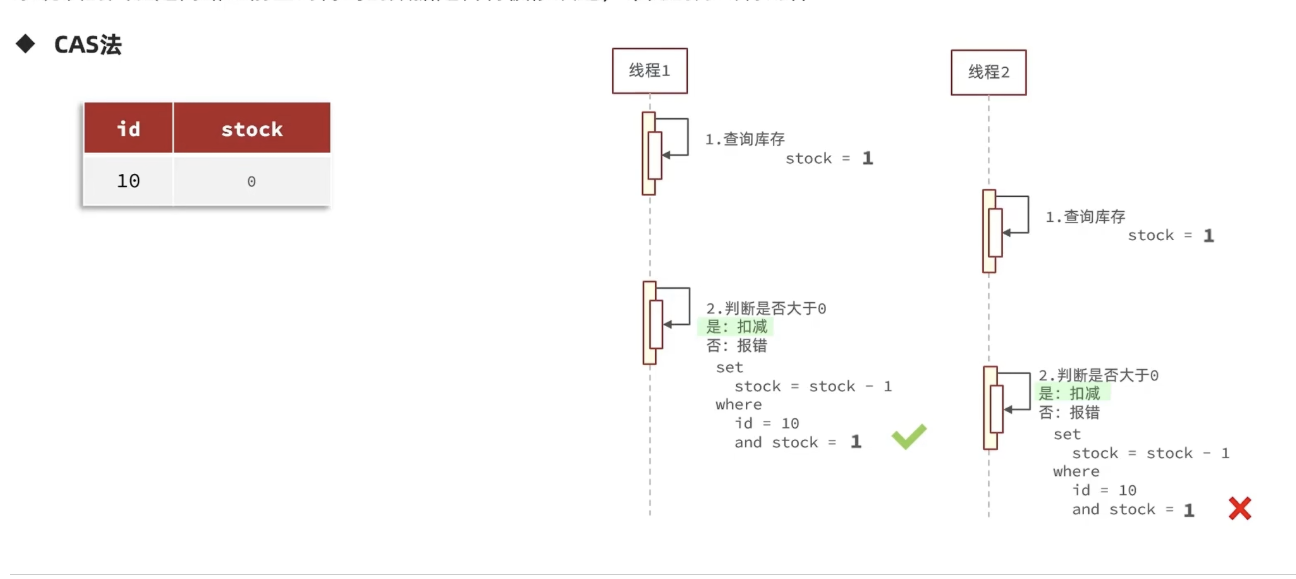
3.2.2cas法
工作原理:
-
读取数据:读取数据以及要修改字段的当前值(例如
balance = 100)。 -
业务计算:在内存中计算出新值(例如
new_balance = 100 - 20 = 80)。 -
更新数据:执行更新时,在 SET 子句中设置新值,并在 WHERE 子句中指定要修改字段的旧值。
sql
UPDATE table_name SET balance = 80 WHERE id = #{id} AND balance = 100; -
判断结果:
-
如果更新成功,说明在本次操作期间,
balance字段没有被其他事务修改。 -
如果更新失败,说明
balance已经被其他事务修改,当前值已不是100
-
存在ABA问题:这是CAS法的经典缺陷。假设 balance 的变化是 100 -> 50 -> 100,虽然在你的两次操作之间它确实被改动过,但最终值又变回了100。你的CAS操作会因为 WHERE balance=100 成立而成功执行,但它没有感知到中间的“波折”。这在某些业务场景下是危险的(例如,链表操作、状态机流转)。
3.2.3对比表格
| 特性 | 版本号法 | CAS 法 |
|---|---|---|
| 核心机制 | 通过一个独立的、单调递增的版本号字段来检测数据变化。 | 通过比较业务字段本身的旧值来检测变化。 |
| 检测粒度 | 记录级:只要记录有任何字段被更新,版本号就会变。 | 字段级:只关心你正在更新的那个字段是否被改变。 |
| ABA 问题 | 不存在。因为版本号只增不减,状态是单向的。 | 存在。字段值可能从A变为B再变回A,CAS会误判。 |
| 与业务耦合度 | 低。版本号是独立的技术性字段。 | 高。直接使用业务字段进行并发控制。 |
| 适用场景 | 通用场景,尤其是需要严格保证数据完整性和一致性的情况。 | 对特定业务字段进行原子更新,且该字段的ABA问题不会造成业务影响。 |
| 实现示例 | WHERE id=? AND version=? | WHERE id=? AND balance=? |
3.2.4 实际代码解决
这里给出对应sql语句
sql
UPDATE seckill_voucher
SET stock = stock - 1
WHERE voucher_id = #{voucherId} AND stock = #{voucher.getStock}
以上逻辑的核心含义是:只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的,但是以上这种方式通过测试发现会有很多失败的情况,失败的原因在于:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败
之前的方式要修改前后都保持一致,但是这样我们分析过,成功的概率太低,所以我们的乐观锁需要变一下,改成stock大于0 即可
所以根据实际情况,我们这里再次优化
sql
UPDATE seckill_voucher
SET stock = stock - 1
WHERE voucher_id = #{voucherId} AND stock > 0
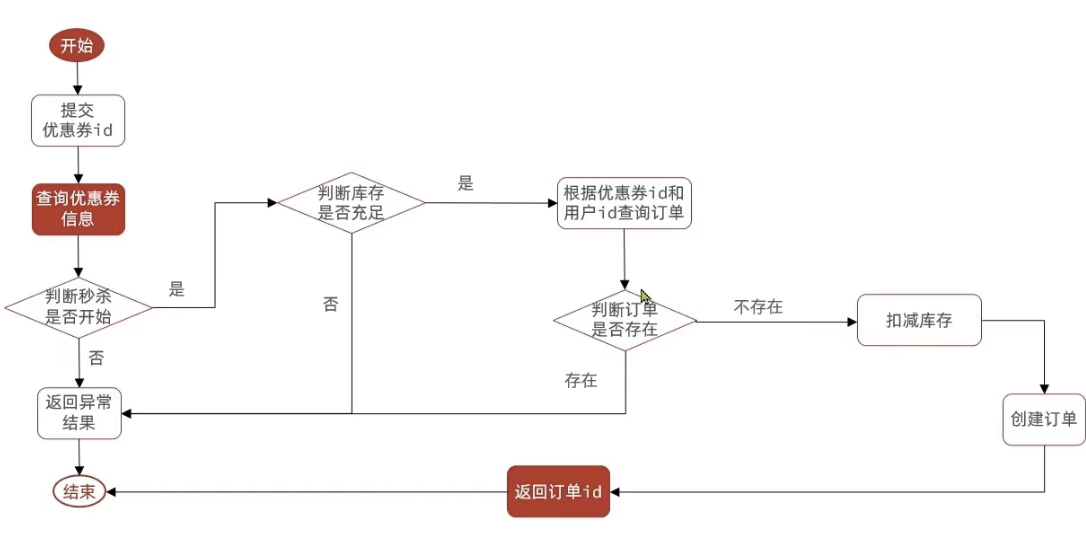
4.一人一单(单体项目一步步解决)
需求:修改秒杀业务,要求同一个优惠券,一个用户只能下一单
现在的问题在于:
优惠卷是为了引流,但是目前的情况是,一个人可以无限制的抢这个优惠卷,所以我们应当增加一层逻辑,让一个用户只能下一个单,而不是让一个用户下多个单
具体操作逻辑如下:比如时间是否充足,如果时间充足,则进一步判断库存是否足够,然后再根据优惠卷id和用户id查询是否已经下过这个订单,如果下过这个订单,则不再下单,否则进行下单
 VoucherOrderServiceImpl
VoucherOrderServiceImpl
初步代码:增加一人一单逻辑
@Override
public Result seckillVoucher(Long voucherId) {// 1.查询优惠券SeckillVoucher voucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀尚未开始!");}// 3.判断秒杀是否已经结束if (voucher.getEndTime().isBefore(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀已经结束!");}// 4.判断库存是否充足if (voucher.getStock() < 1) {// 库存不足return Result.fail("库存不足!");}// 5.一人一单逻辑// 5.1.用户idLong userId = UserHolder.getUser().getId();
//这里查的是订单表int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();// 5.2.判断是否存在if (count > 0) {// 用户已经购买过了return Result.fail("用户已经购买过一次!");}//6,扣减库存boolean success = seckillVoucherService.update().setSql("stock= stock -1").eq("voucher_id", voucherId).update();if (!success) {//扣减库存return Result.fail("库存不足!");}//7.创建订单VoucherOrder voucherOrder = new VoucherOrder();// 7.1.订单idlong orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);voucherOrder.setUserId(userId);// 7.3.代金券idvoucherOrder.setVoucherId(voucherId);save(voucherOrder);return Result.ok(orderId);}存在问题:现在的问题还是和之前一样,并发过来,查询数据库,都不存在订单,所以我们还是需要加锁,但是乐观锁比较适合更新数据,而现在是插入数据,所以我们需要使用悲观锁操作
就像黄牛一次性直接发了1000个请求,
//这里查的是订单表
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
这里查询全通过了,那不就是他买了1000个吗?
注意:在这里提到了非常多的问题,我们需要慢慢的来思考,首先我们的初始方案是封装了一个createVoucherOrder方法,同时为了确保他线程安全,在方法上添加了一把synchronized 锁
@Transactional
public synchronized Result createVoucherOrder(Long voucherId) {Long userId = UserHolder.getUser().getId();// 5.1.查询订单int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();// 5.2.判断是否存在if (count > 0) {// 用户已经购买过了return Result.fail("用户已经购买过一次!");}// 6.扣减库存boolean success = seckillVoucherService.update().setSql("stock = stock - 1") // set stock = stock - 1.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0.update();if (!success) {// 扣减失败return Result.fail("库存不足!");}// 7.创建订单VoucherOrder voucherOrder = new VoucherOrder();// 7.1.订单idlong orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);// 7.2.用户idvoucherOrder.setUserId(userId);// 7.3.代金券idvoucherOrder.setVoucherId(voucherId);save(voucherOrder);// 7.返回订单idreturn Result.ok(orderId);
}但是这样添加锁,锁的粒度太粗了,在使用锁过程中,控制锁粒度 是一个非常重要的事情,因为如果锁的粒度太大,会导致每个线程进来都会锁住,所以我们需要去控制锁的粒度,以下这段代码需要修改为:(对每个用户的id加锁,因为我们防止的本身就是黄牛一次性买太多)
intern() 这个方法是从常量池中拿到数据,如果我们直接使用userId.toString() 他拿到的对象实际上是不同的对象,new出来的对象,我们使用锁必须保证锁必须是同一把,所以我们需要使用intern()方法
@Transactional
public Result createVoucherOrder(Long voucherId) {Long userId = UserHolder.getUser().getId();synchronized(userId.toString().intern()){// 5.1.查询订单int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();// 5.2.判断是否存在if (count > 0) {// 用户已经购买过了return Result.fail("用户已经购买过一次!");}// 6.扣减库存boolean success = seckillVoucherService.update().setSql("stock = stock - 1") // set stock = stock - 1.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0.update();if (!success) {// 扣减失败return Result.fail("库存不足!");}// 7.创建订单VoucherOrder voucherOrder = new VoucherOrder();// 7.1.订单idlong orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);// 7.2.用户idvoucherOrder.setUserId(userId);// 7.3.代金券idvoucherOrder.setVoucherId(voucherId);save(voucherOrder);// 7.返回订单idreturn Result.ok(orderId);}
}但是以上代码还是存在问题,问题的原因在于当前方法被spring的事务控制,如果你在方法内部加锁,可能会导致当前方法事务还没有提交,但是锁已经释放也会导致问题,所以我们选择将当前方法整体包裹起来,确保事务不会出现问题:如下:
在seckillVoucher 方法中,添加以下逻辑,这样就能保证事务的特性,同时也控制了锁的粒度
 但是以上做法依然有问题,因为你调用的方法,其实是this.的方式调用的,事务想要生效,还得利用代理来生效,所以这个地方,我们需要获得原始的事务对象, 来操作事务
但是以上做法依然有问题,因为你调用的方法,其实是this.的方式调用的,事务想要生效,还得利用代理来生效,所以这个地方,我们需要获得原始的事务对象, 来操作事务 Spring容器中的对象到底是什么?
Spring容器中的对象到底是什么?
@Service public class UserService {public void methodA() {System.out.println("methodA - this: " + this.getClass());}public void methodB() {System.out.println("methodB - this: " + this.getClass());this.methodA(); // 这里的this是什么?} }输出结果可能是:(这是一个很重要的问题。不加
this关键字,结果完全一样。)注入的userService: class com.example.UserService$$EnhancerBySpringCGLIB$$12345678 methodB - this: class com.example.UserService$$EnhancerBySpringCGLIB$$12345678 methodA - this: class com.example.UserService$$EnhancerBySpringCGLIB$$12345678
@Service public class UserService { @Transactionalpublic void methodA() {System.out.println("methodA - this: " + this.getClass());}public void methodB() {System.out.println("methodB - this: " + this.getClass());this.methodA(); // 这里的this是什么?} }输出结果可能是:(这是一个很重要的问题。不加
this关键字,结果完全一样。)注入的userService:class com.example.UserService$$EnhancerBySpringCGLIB$$12345678 methodB - this: class com.example.UserService$$EnhancerBySpringCGLIB$$12345678 methodA - this: class com.example.UserService
在Java中,以下两种写法是完全等价的:
java
methodA(); // 隐式调用 this.methodA(); // 显式调用
代理对象和目标对象的关系
java
// Spring创建的代理对象内部结构大致如下: public class UserService$$EnhancerBySpringCGLIB extends UserService {// 持有目标对象(真实实例)的引用private UserService target;// 拦截器链(包含事务拦截器、日志拦截器等)private List<MethodInterceptor> interceptors;@Overridepublic void businessMethod() {// 1. 执行AOP前置处理// 2. 调用目标对象的方法:target.businessMethod()// 3. 执行AOP后置处理} }
普通方法调用示例
@Service public class UserService {public void methodA() {System.out.println("执行方法A");// 普通业务逻辑}public void methodB() {System.out.println("执行方法B");methodA(); // 这里直接调用完全没问题}public void methodC() {System.out.println("执行方法C");this.methodA(); // 使用this调用也没问题} }
什么情况下会有问题?
只有当方法需要AOP增强功能时,比如:
java
@Service public class UserService {@Transactional // 需要事务增强public void transactionalMethod() {// 数据库操作}@Async // 需要异步增强public void asyncMethod() {// 异步执行}@Cacheable // 需要缓存增强 public void cacheMethod() {// 缓存操作}public void callerMethod() {// 这些调用都会失效!transactionalMethod(); // 事务失效asyncMethod(); // 异步失效cacheMethod(); // 缓存失效} }
| 调用场景 | 普通方法 | 需要AOP增强的方法 |
|---|---|---|
this.method() | ✅ 正常 | ❌ AOP增强失效 |
proxy.method() | ✅ 正常 | ✅ AOP增强生效 |
直接调用 method() | ✅ 正常 | ❌ AOP增强失效 |
解决方案
方案1:注入自身代理
java
@Service public class OrderService {@Autowiredprivate OrderService self; // 注入代理对象public void createOrder(Order order) {orderMapper.insert(order);self.updateInventory(order); // 通过代理对象调用}@Transactionalpublic void updateInventory(Order order) {// 现在事务生效了!inventoryMapper.update(order.getProductId(), order.getQuantity());} }方案2:使用AopContext
java
@Service @EnableAspectJAutoProxy(exposeProxy = true) public class OrderService {public void createOrder(Order order) {orderMapper.insert(order);// 获取当前代理对象OrderService proxy = (OrderService) AopContext.currentProxy();proxy.updateInventory(order);} }
4.0(这种方案在集群环境下的并发问题 )
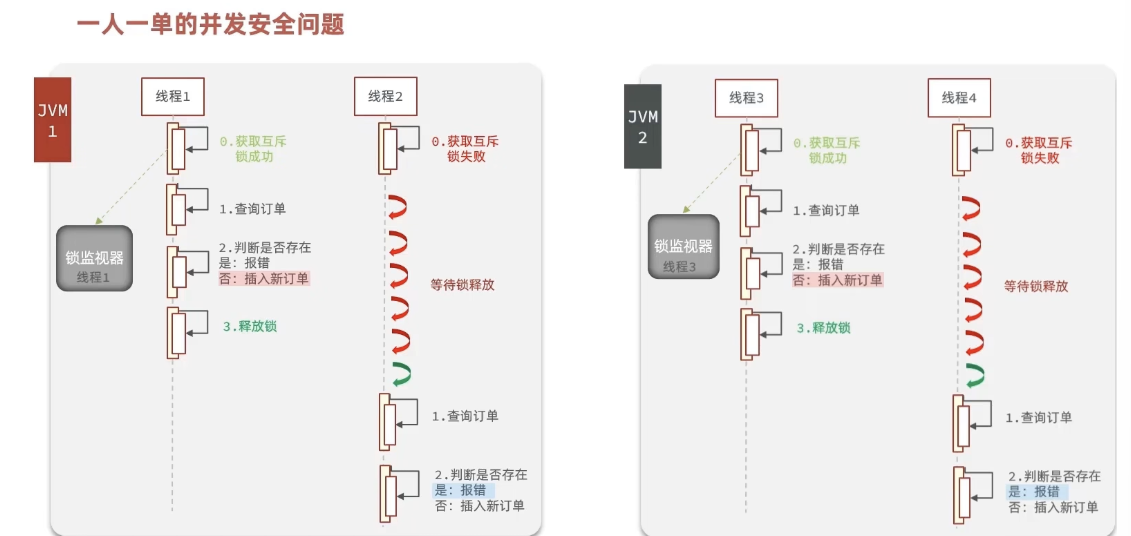
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了。
有关锁失效原因分析
由于现在我们部署了多个tomcat,每个tomcat都有一个属于自己的jvm,那么假设在服务器A的tomcat内部,有两个线程,这两个线程由于使用的是同一份代码,那么他们的锁对象是同一个,是可以实现互斥的,但是如果现在是服务器B的tomcat内部,又有两个线程,但是他们的锁对象写的虽然和服务器A一样,但是锁对象却不是同一个,所以线程3和线程4可以实现互斥,但是却无法和线程1和线程2实现互斥,这就是 集群环境下,syn锁失效的原因,在这种情况下,我们就需要使用分布式锁来解决这个问题。
分布式锁:
1.基本原理和实现方式对比:
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路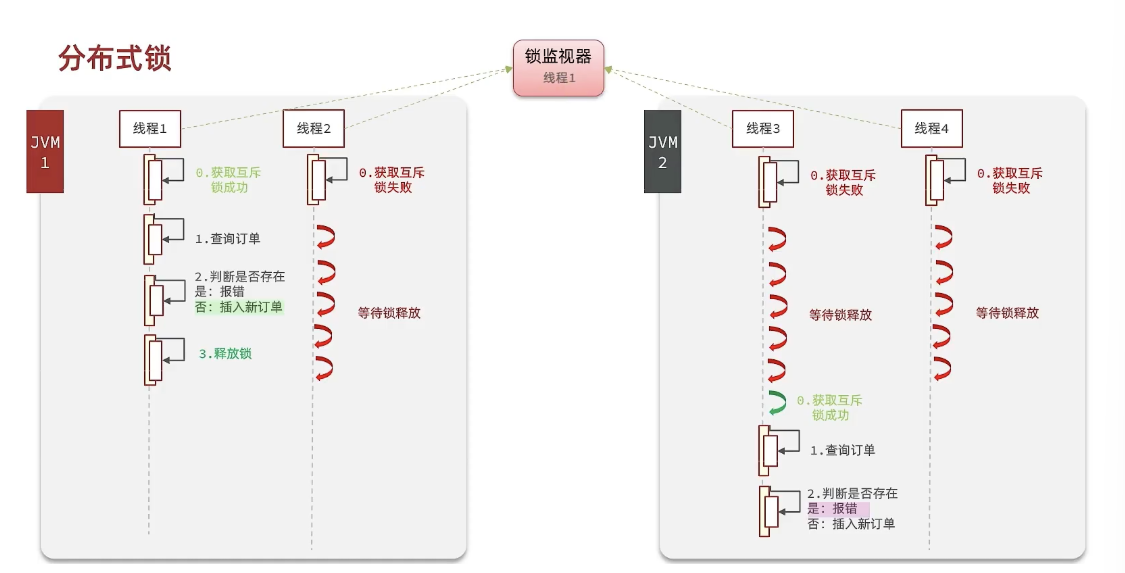
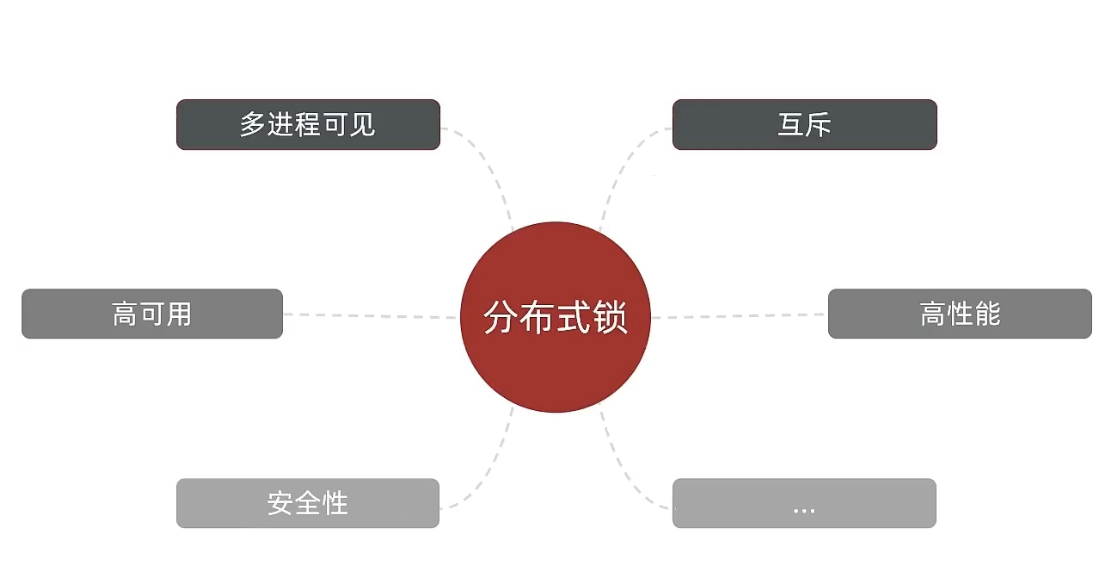
那么分布式锁他应该满足一些什么样的条件呢?
可见性:多个线程都能看到相同的结果,注意:这个地方说的可见性并不是并发编程中指的内存可见性,只是说多个进程之间都能感知到变化的意思
互斥:互斥是分布式锁的最基本的条件,使得程序串行执行
高可用:程序不易崩溃,时时刻刻都保证较高的可用性
高性能:由于加锁本身就让性能降低,所有对于分布式锁本身需要他就较高的加锁性能和释放锁性能
安全性:安全也是程序中必不可少的一环
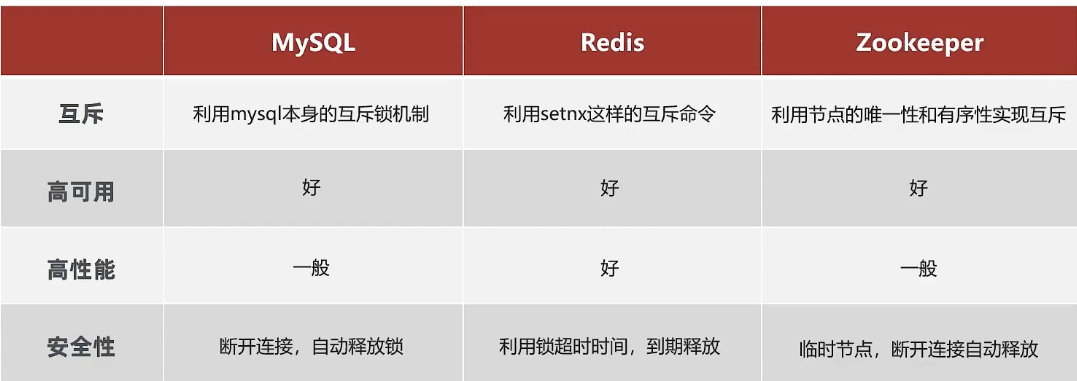
常见的分布式锁有三种
Mysql:mysql本身就带有锁机制,但是由于mysql性能本身一般,所以采用分布式锁的情况下,其实使用mysql作为分布式锁比较少见
Redis:redis作为分布式锁是非常常见的一种使用方式,现在企业级开发中基本都使用redis或者zookeeper作为分布式锁,利用setnx这个方法,如果插入key成功,则表示获得到了锁,如果有人插入成功,其他人插入失败则表示无法获得到锁,利用这套逻辑来实现分布式锁
Zookeeper:zookeeper也是企业级开发中较好的一个实现分布式锁的方案,由于本套视频并不讲解zookeeper的原理和分布式锁的实现,所以不过多阐述
在MySQL集群环境下实现互斥锁,主要有基于数据库表、行级锁和乐观锁几种方式。为了让你快速了解,我用一个表格来汇总它们的主要特点:
实现方式 核心原理 优点 缺点 适用场景 基于防重表 利用数据库表唯一索引约束,插入成功表示获锁。 实现简单,利用数据库机制保证互斥。 1. 数据库单点风险
2. 无失效时间,需额外处理
3. 非阻塞,插入失败直接返回
4. 通常不可重入并发量不高,对锁的可用性要求不苛刻的短期任务。 基于悲观锁 ( SELECT ... FOR UPDATE)基于数据库的行级排他锁,锁定锁表中的特定记录。 1. 由数据库保证互斥与阻塞
2. 可避免死锁(表锁情况下)。1. 数据库单点风险
2. 性能开销较大,可能影响系统可用性
3. 需要注意连接与会话的管理。需要阻塞等待锁,且并发量不是特别高的场景。 基于乐观锁 (通过版本号等机制) 通过版本号字段或条件判断,在更新时比较版本号或校验数据。 1. 避免数据库锁开销,性能较好
2. 实现相对简单。1. 需自行处理更新失败(如重试或返回失败)
2. 高并发下成功率下降,增加数据库压力。读多写少,并发冲突概率较低的场景。
一、基于防重表(唯一索引)
这种方法的核心是创建一张锁表,利用
method_name(或类似)字段的唯一性约束来保证互斥。
创建锁表:
sql
CREATE TABLE `distributed_lock` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`lock_type` varchar(64) NOT NULL COMMENT '锁类型,需唯一',`owner_id` varchar(255) NOT NULL COMMENT '持锁者标识,可用于实现可重入',`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `idx_lock_type` (`lock_type`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='分布式锁';加锁操作:尝试向表中插入一条代表锁的记录。若插入成功,则获取锁;若因唯一索引冲突插入失败,则获取锁失败。
sql
INSERT INTO `distributed_lock` (`lock_type`, `owner_id`) VALUES ('order_lock', 'server_1');解锁操作:删除对应的记录。
sql
DELETE FROM `distributed_lock` WHERE `lock_type` = 'order_lock' AND `owner_id` = 'server_1';注意事项与改进:
锁超时:可以增加一个
expire_time字段记录锁的过期时间,并通过后台任务清理超时的锁。可重入:通过
owner_id字段标识当前锁的持有者。同一持有者再次加锁时,可改为更新操作(如更新update_time)并判断是否为自己的锁,从而实现可重入。二、基于悲观锁(SELECT ... FOR UPDATE)
这种方式利用MySQL的行级排他锁(
SELECT ... FOR UPDATE)来实现。
加锁操作:在一个事务中查询目标锁记录并使用
FOR UPDATE。sql
BEGIN; SELECT * FROM `distributed_lock` WHERE `lock_type` = 'order_lock' FOR UPDATE;执行业务逻辑:如果上一步成功执行,当前会话便获得了锁,可以执行后续业务代码。
解锁操作:提交事务,释放锁。
sql
COMMIT;关键点:
务必确保
FOR UPDATE的查询条件使用了索引(最好是唯一索引),否则可能锁表。保持连接:加锁与解锁必须在同一个数据库连接(会话)中进行。
三、基于乐观锁(版本控制)
乐观锁不直接加锁,而是在更新数据时检查数据是否被其他会话修改过。
为业务数据表增加版本号字段:
sql
ALTER TABLE `your_business_table` ADD `version` int(11) NOT NULL DEFAULT '0';更新时检查版本号:
sql
UPDATE `your_business_table` SET `stock` = `stock` - 1, `version` = `version` + 1 WHERE `id` = 100 AND `version` = 5;判断更新结果:检查该UPDATE语句的影响行数。如果影响行数为0,说明版本号不符或数据已更新,意味着获取锁(或更新权)失败,需要根据业务逻辑(如重试)处理。
基于悲观锁(SELECT ... FOR UPDATE)
🔒
FOR UPDATE的详细机制锁的行为特性:
排他性:其他事务无法同时对同一行加任何类型的锁
阻塞性:如果锁已被占用,其他事务的
FOR UPDATE会阻塞等待事务绑定:锁的持有时间与事务生命周期一致
自动释放:事务提交(
COMMIT)或回滚(ROLLBACK)时自动释放锁实际效果示例:
事务A(获取锁):
sql
-- 事务A开始 BEGIN; SELECT * FROM `distributed_lock` WHERE `lock_type` = 'order_lock' FOR UPDATE; -- 此时事务A获得了 'order_lock' 的排他锁事务B(尝试获取同一锁):
sql
-- 事务B开始 BEGIN; SELECT * FROM `distributed_lock` WHERE `lock_type` = 'order_lock' FOR UPDATE; -- ⚠️ 这里会被阻塞,直到事务A提交或回滚!
2.Redis分布式锁的实现核心思路
实现分布式锁时需要实现的两个基本方法:
-
获取锁:
-
互斥:确保只能有一个线程获取锁
-
非阻塞:尝试一次,成功返回true,失败返回false
-
-
释放锁:
-
手动释放
-
超时释放:获取锁时添加一个超时时间
-
核心思路:
我们利用redis 的setNx 方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可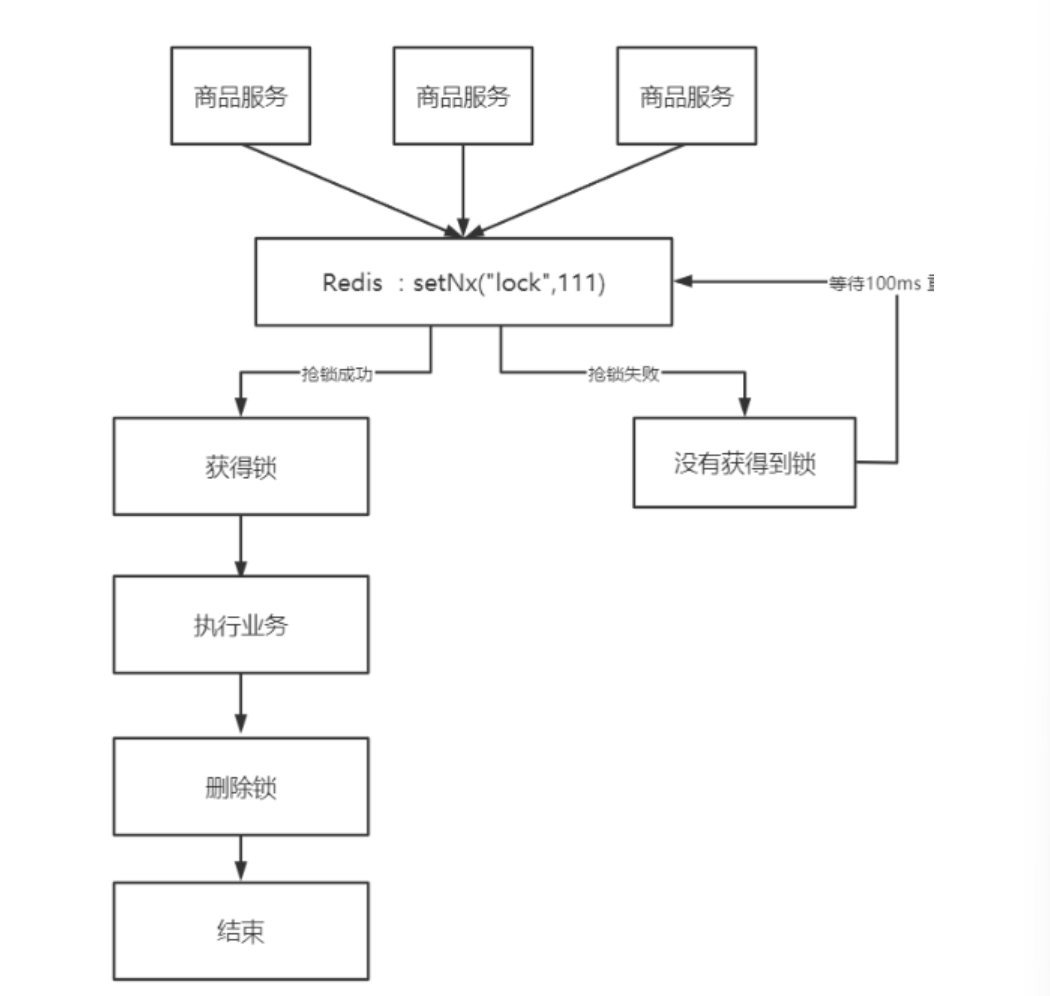
2.1实现分布式锁最初版本

新建SimpleRedisLock类:
- 加锁逻辑
利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
private String name;private StringRedisTemplate stringRedisTemplate;public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {this.name = name;this.stringRedisTemplate = stringRedisTemplate;}private static final String KEY_PREFIX="lock:"
@Override
public boolean tryLock(long timeoutSec) {// 获取线程标示String threadId = Thread.currentThread().getId()// 获取锁Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId + "", timeoutSec, TimeUnit.SECONDS);return Boolean.TRUE.equals(success);
}-
释放锁逻辑
public void unlock() {//通过del删除锁stringRedisTemplate.delete(KEY_PREFIX + name);
}-
修改业务代码
@Overridepublic Result seckillVoucher(Long voucherId) {// 1.查询优惠券SeckillVoucher voucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀尚未开始!");}// 3.判断秒杀是否已经结束if (voucher.getEndTime().isBefore(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀已经结束!");}// 4.判断库存是否充足if (voucher.getStock() < 1) {// 库存不足return Result.fail("库存不足!");}Long userId = UserHolder.getUser().getId();//创建锁对象(新增代码)SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);//获取锁对象boolean isLock = lock.tryLock(1200);//加锁失败if (!isLock) {return Result.fail("不允许重复下单");}try {//获取代理对象(事务)IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();return proxy.createVoucherOrder(voucherId);} finally {//释放锁lock.unlock();}}2.2Redis分布式锁误删情况(优化)版本2
逻辑说明:
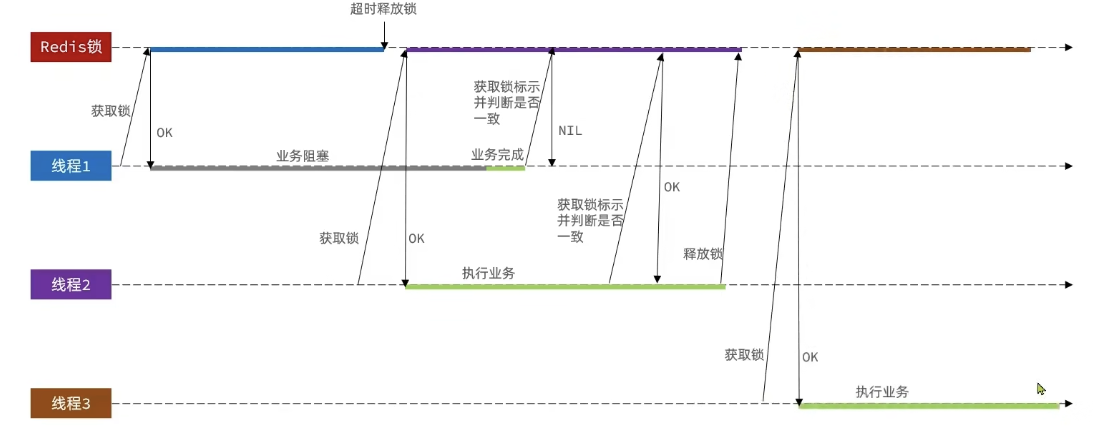
持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放,这时其他线程,线程2来尝试获得锁,就拿到了这把锁,然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除,这就是误删别人锁的情况说明
解决方案:解决方案就是在每个线程释放锁的时候,去判断一下当前这把锁是否属于自己,如果属于自己,则不进行锁的删除,假设还是上边的情况,线程1卡顿,锁自动释放,线程2进入到锁的内部执行逻辑,此时线程1反应过来,然后删除锁,但是线程1,一看当前这把锁不是属于自己,于是不进行删除锁逻辑,当线程2走到删除锁逻辑时,如果没有卡过自动释放锁的时间点,则判断当前这把锁是属于自己的,于是删除这把锁。
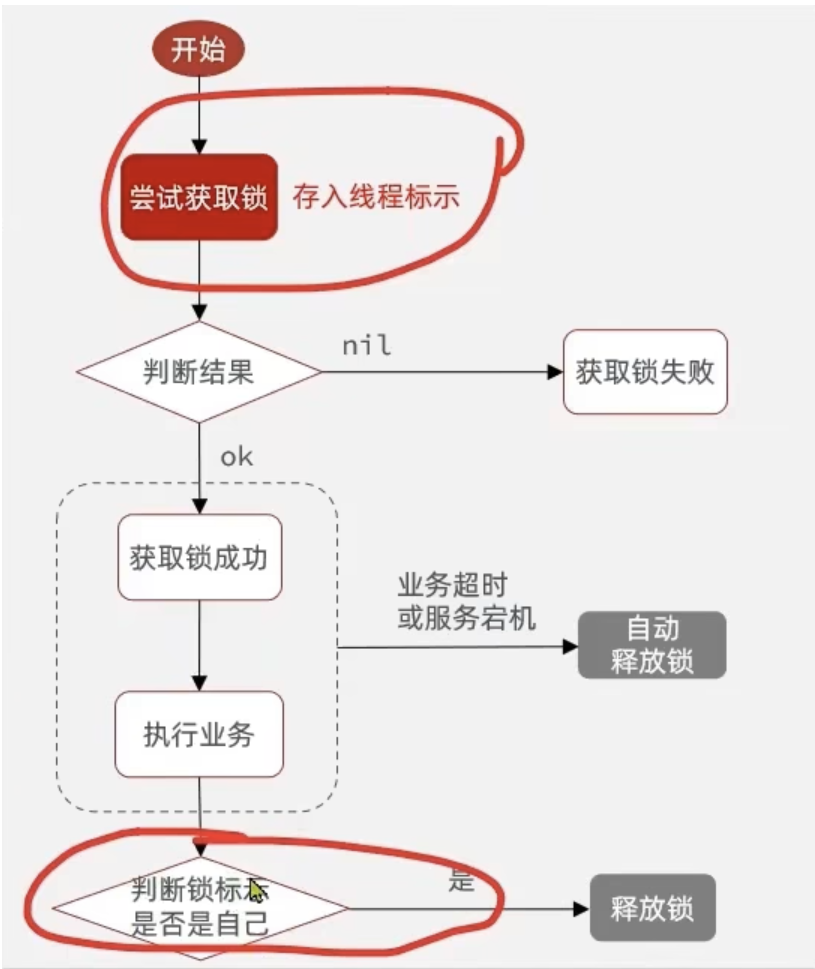
需求:修改之前的分布式锁实现,满足:在获取锁时存入线程标示(可以用UUID表示) 在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致
-
如果一致则释放锁
-
如果不一致则不释放锁
核心逻辑:在存入锁时,放入自己线程的标识,在删除锁时,判断当前这把锁的标识是不是自己存入的,如果是,则进行删除,如果不是,则不进行删除。
具体代码如下:加锁
private String name;private StringRedisTemplate stringRedisTemplate;public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {this.name = name;this.stringRedisTemplate = stringRedisTemplate;}private static final String KEY_PREFIX="lock:"
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
@Override
public boolean tryLock(long timeoutSec) {// 获取线程标示String threadId = ID_PREFIX + Thread.currentThread().getId();// 获取锁Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);return Boolean.TRUE.equals(success);
}释放锁
public void unlock() {// 获取线程标示String threadId = ID_PREFIX + Thread.currentThread().getId();// 获取锁中的标示String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);// 判断标示是否一致if(threadId.equals(id)) {// 释放锁stringRedisTemplate.delete(KEY_PREFIX + name);}
}有关代码实操说明:
在我们修改完此处代码后,我们重启工程,然后启动两个线程,第一个线程持有锁后,手动释放锁,第二个线程 此时进入到锁内部,再放行第一个线程,此时第一个线程由于锁的value值并非是自己,所以不能释放锁,也就无法删除别人的锁,此时第二个线程能够正确释放锁,通过这个案例初步说明我们解决了锁误删的问题。
JVM重启后的线程ID分配
java
// 第一次启动Spring项目 public class FirstStart {public static void main(String[] args) {System.out.println("第一次启动 - 主线程ID: " + Thread.currentThread().getId()); // 通常是1Thread t1 = new Thread(() -> {});System.out.println("第一次启动 - 线程1 ID: " + t1.getId()); // 比如11Thread t2 = new Thread(() -> {});System.out.println("第一次启动 - 线程2 ID: " + t2.getId()); // 比如12} }// 关闭项目后,第二次启动 public class SecondStart {public static void main(String[] args) {System.out.println("第二次启动 - 主线程ID: " + Thread.currentThread().getId()); // 重新从1开始Thread t1 = new Thread(() -> {});System.out.println("第二次启动 - 线程1 ID: " + t1.getId()); // 重新从11开始(或类似的起始值)Thread t2 = new Thread(() -> {});System.out.println("第二次启动 - 线程2 ID: " + t2.getId()); // 12} }
2.3分布式锁的原子性问题(优化)版本3
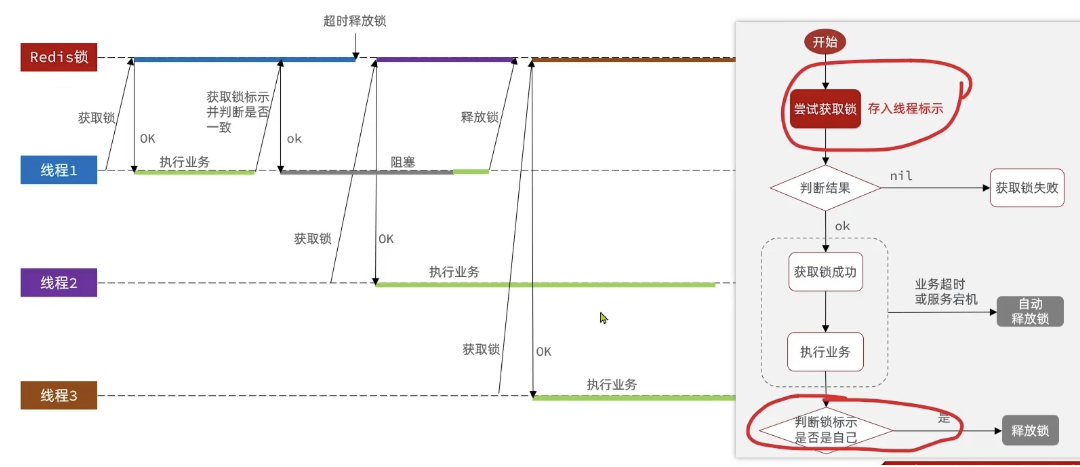
更为极端的误删逻辑说明:
线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删除锁,但是此时他的锁到期了,那么此时线程2进来,但是线程1他会接着往后执行,当他卡顿结束后,他直接就会执行删除锁那行代码,相当于条件判断并没有起到作用,这就是删锁时的原子性问题,之所以有这个问题,是因为线程1的拿锁,比锁,删锁,实际上并不是原子性的,我们要防止刚才的情况发生,
利用Lua脚本解决多条命令原子性问题:
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言,它的基本语法大家可以参考网站:https://www.runoob.com/lua/lua-tutorial.html,这里重点介绍Redis提供的调用函数,我们可以使用lua去操作redis,又能保证他的原子性,这样就可以实现拿锁比锁删锁是一个原子性动作了,作为Java程序员这一块并不作一个简单要求,并不需要大家过于精通,只需要知道他有什么作用即可。
这里重点介绍Redis提供的调用函数,语法如下:
redis.call('命令名称', 'key', '其它参数', ...)
例如,我们要执行set name jack,则脚本是这样:
# 执行 set name jack
redis.call('set', 'name', 'jack')
例如,我们要先执行set name Rose,再执行get name,则脚本如下:
# 先执行 set name jack
redis.call('set', 'name', 'Rose')
# 再执行 get name
local name = redis.call('get', 'name')
# 返回
return name
写好脚本以后,需要用Redis命令来调用脚本,调用脚本的常见命令如下:
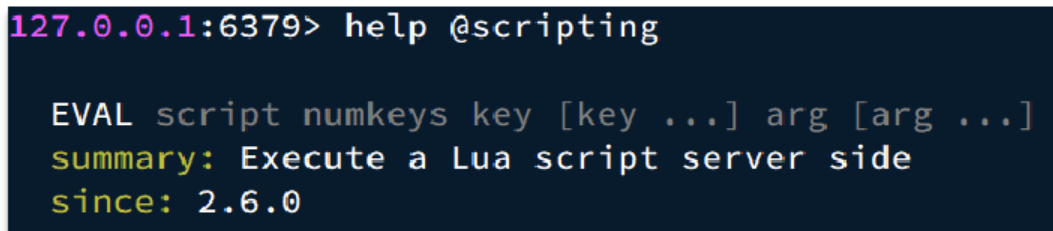
例如,我们要执行 redis.call('set', 'name', 'jack') 这个脚本,语法如下: 如果脚本中的key、value不想写死,可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数:
如果脚本中的key、value不想写死,可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数:
接下来我们来回一下我们释放锁的逻辑:
释放锁的业务流程是这样的
1、获取锁中的线程标示
2、判断是否与指定的标示(当前线程标示)一致
3、如果一致则释放锁(删除)
4、如果不一致则什么都不做
如果用Lua脚本来表示则是这样的:
最终我们操作redis的拿锁比锁删锁的lua脚本就会变成这样
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then-- 一致,则删除锁return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0
利用Java代码调用Lua脚本改造分布式锁
lua脚本本身并不需要大家花费太多时间去研究,只需要知道如何调用,大致是什么意思即可,所以在笔记中并不会详细的去解释这些lua表达式的含义。
我们的RedisTemplate中,可以利用execute方法去执行lua脚本,参数对应关系就如下图
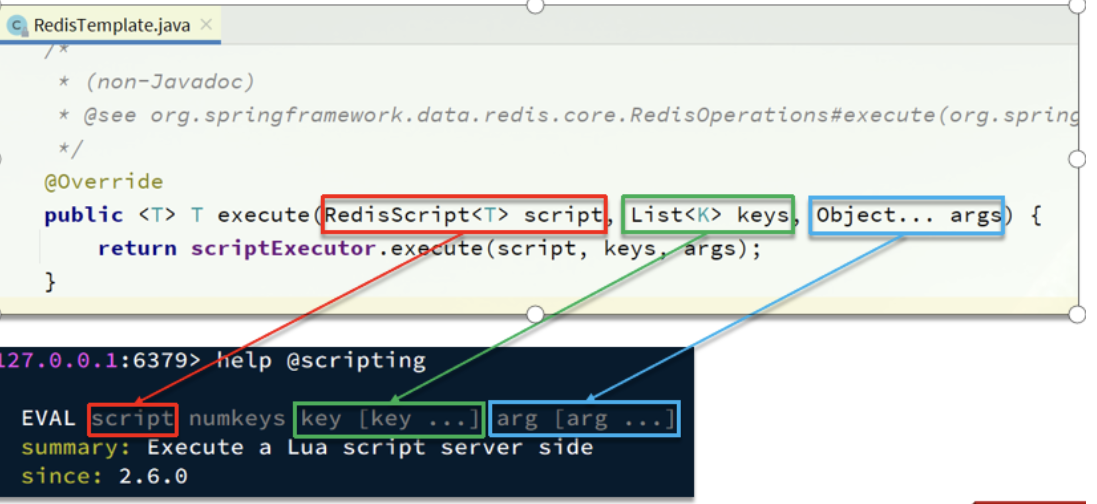
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;static {UNLOCK_SCRIPT = new DefaultRedisScript<>();UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));UNLOCK_SCRIPT.setResultType(Long.class);}public void unlock() {// 调用lua脚本stringRedisTemplate.execute(UNLOCK_SCRIPT,Collections.singletonList(KEY_PREFIX + name),ID_PREFIX + Thread.currentThread().getId());
}
经过以上代码改造后,我们就能够实现 拿锁比锁删锁的原子性动作了~测试逻辑:
第一个线程进来,得到了锁,手动删除锁,模拟锁超时了,其他线程会执行lua来抢锁,当第一天线程利用lua删除锁时,lua能保证他不能删除他的锁,第二个线程删除锁时,利用lua同样可以保证不会删除别人的锁,同时还能保证原子性。
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
private:私有,只在当前类使用
static final:静态常量,类加载时初始化且不可改变
DefaultRedisScript<Long>:Spring Data Redis提供的脚本执行器,<Long>表示脚本返回类型
static {UNLOCK_SCRIPT = new DefaultRedisScript<>();UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));UNLOCK_SCRIPT.setResultType(Long.class); }静态代码块特点:
在类加载时执行,且只执行一次
用于初始化静态变量
1. 创建脚本实例
UNLOCK_SCRIPT = new DefaultRedisScript<>();创建一个空的Redis脚本执行器实例。
2. 设置脚本位置
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
ClassPathResource("unlock.lua"):从classpath根目录查找unlock.lua文件文件位置通常:
src/main/resources/unlock.lua3. 设置返回类型
UNLOCK_SCRIPT.setResultType(Long.class);指定Lua脚本执行后的返回值类型为
Long,对应Redis的整数类型。通过这种初始化方式:
应用启动时就会加载
unlock.lua脚本后续调用
stringRedisTemplate.execute(UNLOCK_SCRIPT, ...)时直接使用预加载的脚本避免了每次执行时的文件IO和脚本解析开销
redission
1-redission功能介绍:
于setnx实现的分布式锁存在下面的问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
超时释放:我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。

Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
Redission提供了分布式锁的多种多样的功能
快速入门:
引入依赖:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.13.6</version> </dependency>
配置Redisson客户端:
@Configuration
public class RedissonConfig {
@Beanpublic RedissonClient redissonClient(){// 配置Config config = new Config();config.useSingleServer().setAddress("redis://192.168.150.101:6379")(用自己虚拟机的端口号).setPassword("123321");(自己的密码)// 创建RedissonClient对象return Redisson.create(config);}
}
如何使用Redission的分布式锁
@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{//获取锁(可重入),指定锁的名称RLock lock = redissonClient.getLock("anyLock");//尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位boolean isLock = lock.tryLock(1,10,TimeUnit.SECONDS);//判断获取锁成功if(isLock){try{System.out.println("执行业务"); }finally{//释放锁lock.unlock();}}}
在 VoucherOrderServiceI
@Resource
private RedissonClient redissonClient;@Override
public Result seckillVoucher(Long voucherId) {// 1.查询优惠券SeckillVoucher voucher = seckillVoucherService.getById(voucherId);// 2.判断秒杀是否开始if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀尚未开始!");}// 3.判断秒杀是否已经结束if (voucher.getEndTime().isBefore(LocalDateTime.now())) {// 尚未开始return Result.fail("秒杀已经结束!");}// 4.判断库存是否充足if (voucher.getStock() < 1) {// 库存不足return Result.fail("库存不足!");}Long userId = UserHolder.getUser().getId();//创建锁对象 这个代码不用了,因为我们现在要使用分布式锁//SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);RLock lock = redissonClient.getLock("lock:order:" + userId);//获取锁对象boolean isLock = lock.tryLock();//加锁失败if (!isLock) {return Result.fail("不允许重复下单");}try {//获取代理对象(事务)IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();return proxy.createVoucherOrder(voucherId);} finally {//释放锁lock.unlock();}}2.redission可重入锁原理

我们之前的代码,如果锁还是当单个key+value的话,像上面method1获取到锁以后,调用method2方法,但是这个时候method2方法获取锁就失败了!! method1和method2都是同一个请求同一个线程,这样不就出问题了吗?
我们的解决方法采取用hash结构存储
其中大key表示表示这把锁是否存在,用小key表示当前这把锁被哪个线程持有,所以接下来我们一起分析一下当前的这个lua表达式 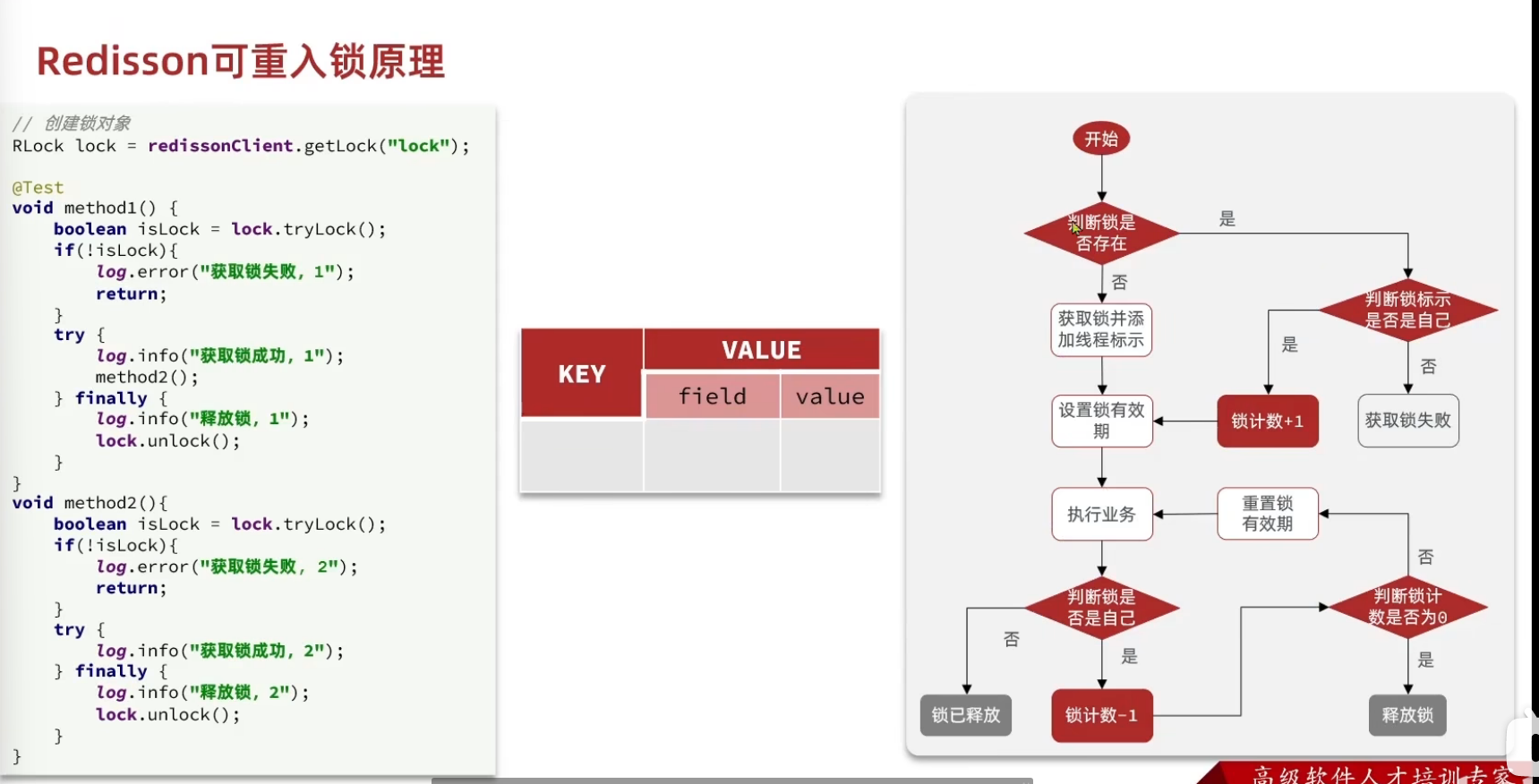
获取锁方法
exists: 判断数据是否存在 , 如果==0(表示没获取到这把锁),就表示当前这把锁不存在
redis.call('hset',key,threadId,"1");不存在的话就可以获取锁了,找到这个所对大key小key,设为1(因为这个时候判断了不存在,是第一次拿锁)
之后设置一下有效期
返回结果
如果当前这把锁存在,则第一个条件不满足,再判断
redis.call('hexists',key, threadId) == 1 判断存在不存在,存在的话redis会返回1
如果返回1了,说明存在,此时需要通过大key+小key判断当前这把锁是否是属于自己的,如果是自己的,则进行
redis.call('hincrby',key,threadId,"1") redis中的自增函数,让对应的大key小key自增1
将当前这个锁的value进行+1 ,
redis.call('expire', key,releaseTime); 然后再对其设置过期时间,之后返回结果return 1
如果以上两个条件都不满足,则表示当前这把锁抢锁失败,最后返回0 return 0
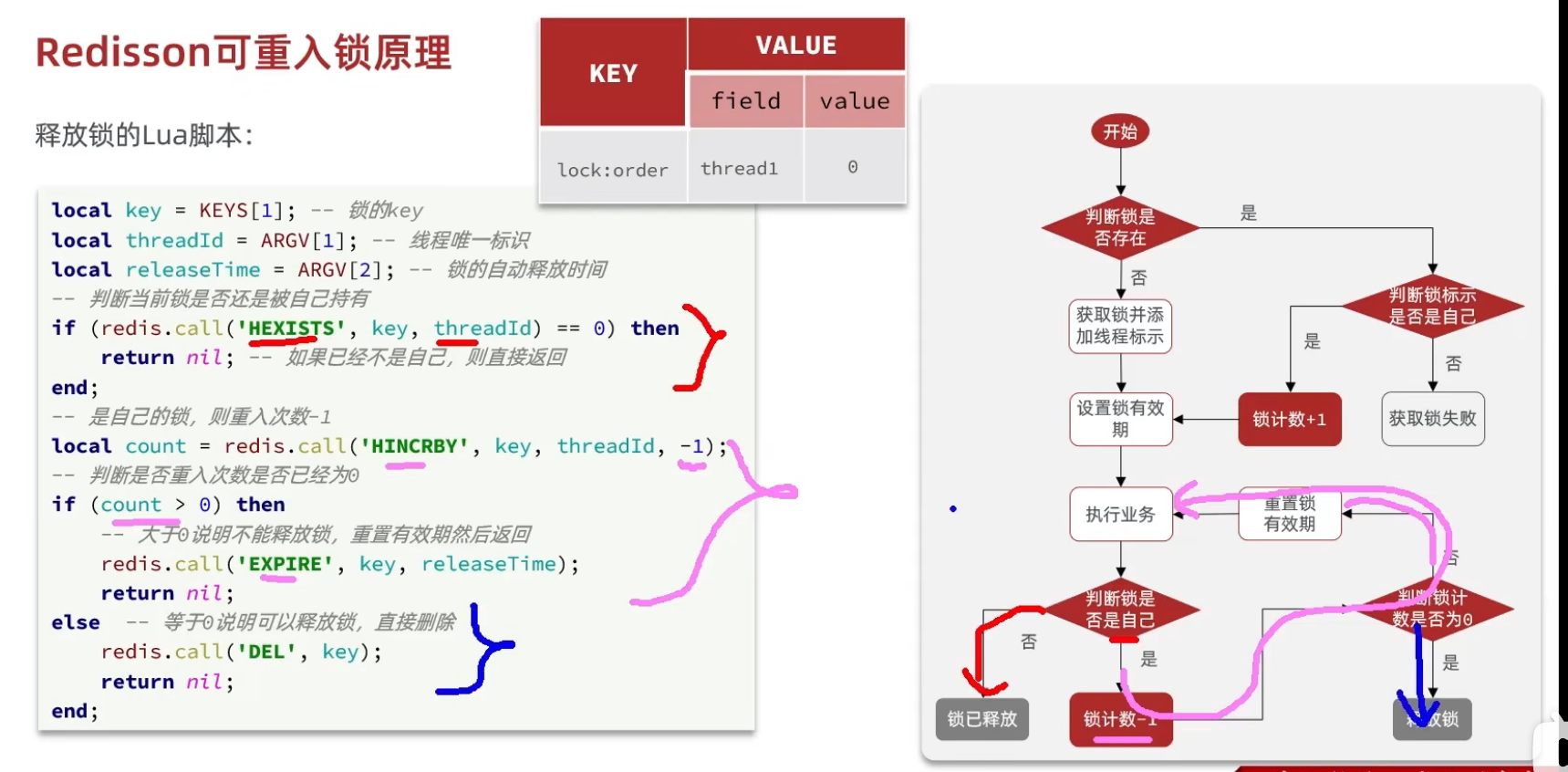
获取锁源码:
这个地方一共有3个参数
KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
ARGV[2]: id + ":" + threadId; 锁的小key
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"
最后返回pttl,即为当前这把锁的失效时间
释放锁方法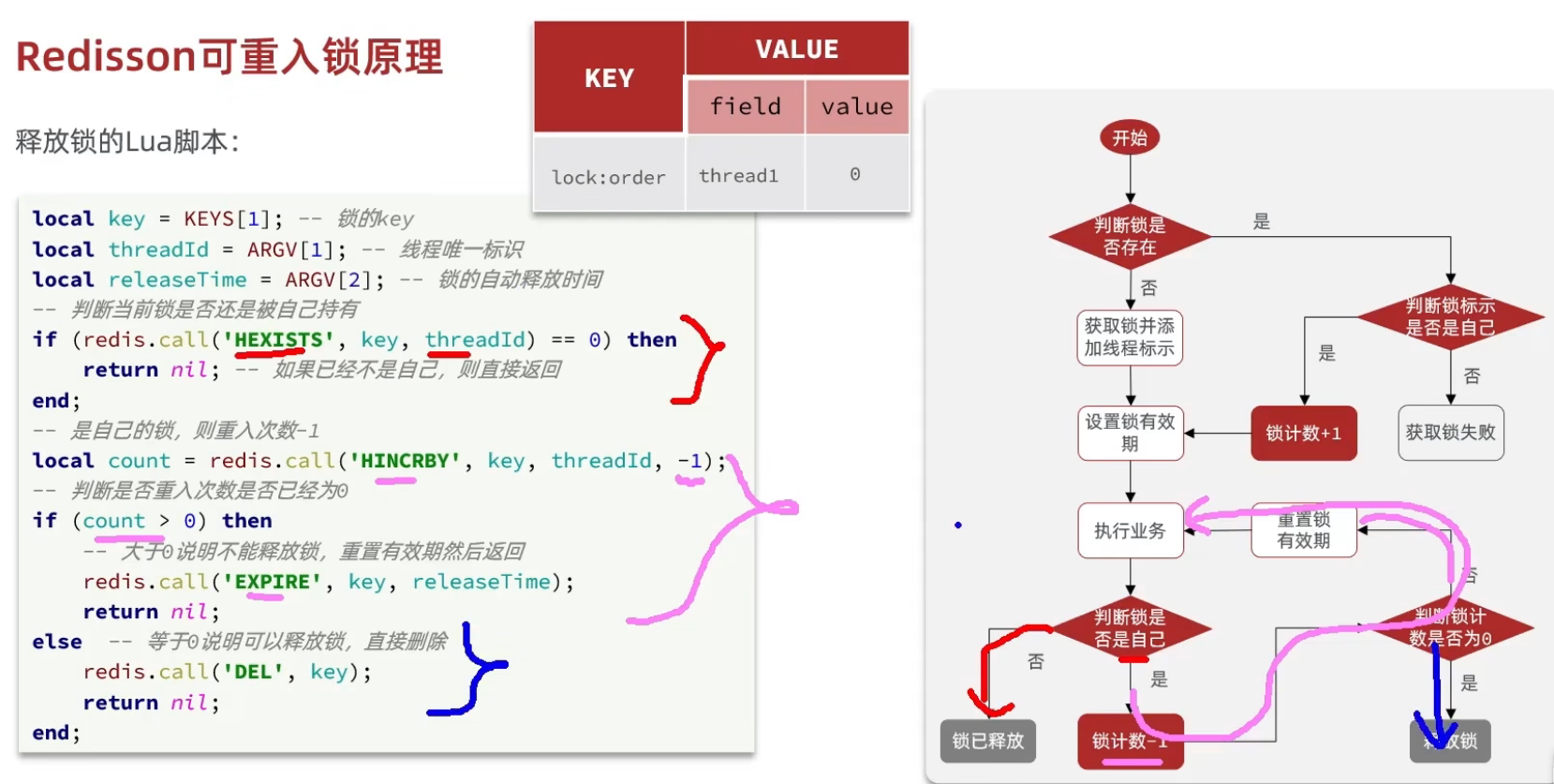
HEXISTS,先判断小key大key看这个锁是不是自己的,不是自己的就返回
如果是自己的锁,hincrby,让这个锁的value➖1
然后判断这时候value是不是大于0,如果大于零说明重入锁还没有结束,不能释放锁
如果发现大小等于0了,就可以释放锁了,直接删除即可
释放锁源码
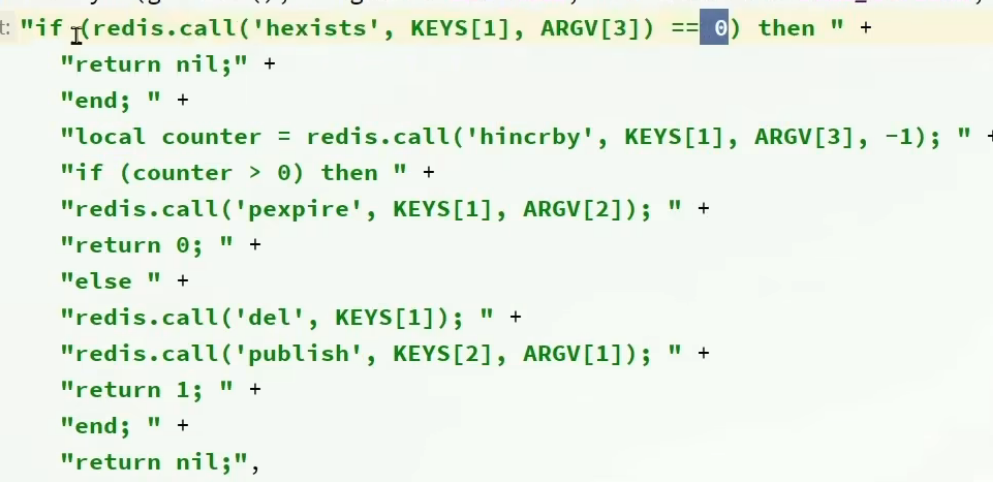
这个地方一共有3个参数
KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
ARGV[2]: id + ":" + threadId; 锁的小key
3.redission锁重试和WatchDog机制(源码解读)
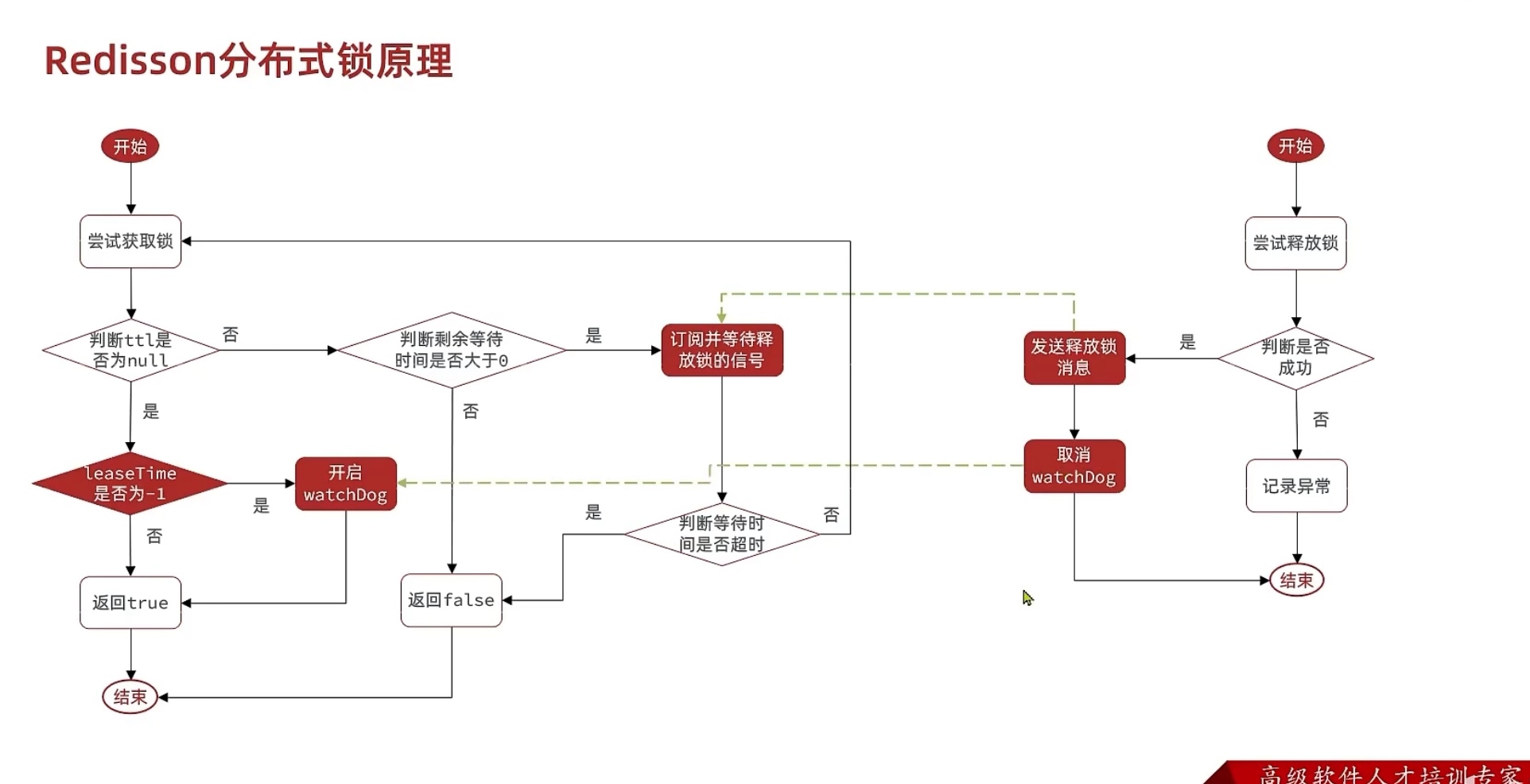
3.1redission锁重试
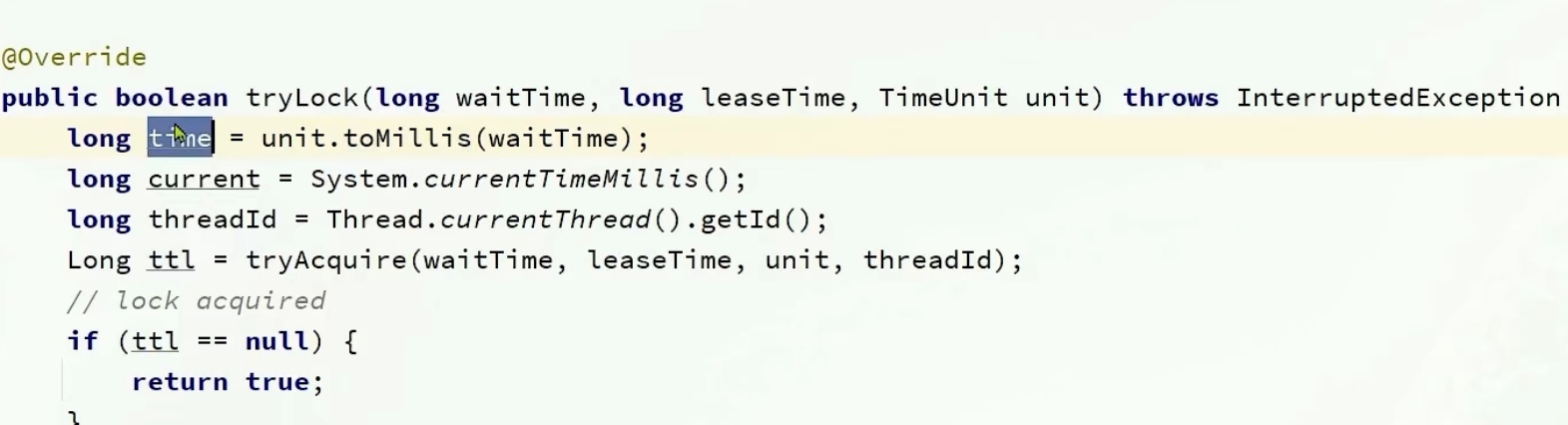
在调用trylock函数时,我们也会传进去一个waitTime(代表等待的时间)
time就是等待
current得到现在的时间
threadId得到当前线程的id
然后进入tryAcquire(尝试获取锁),tryAcquire里直接调用tryAcquireAsinc

leaseTime默认是-1,如果不是负一,就调用我传进来的leaseTime,如果是-1,就用我们的看门狗机制
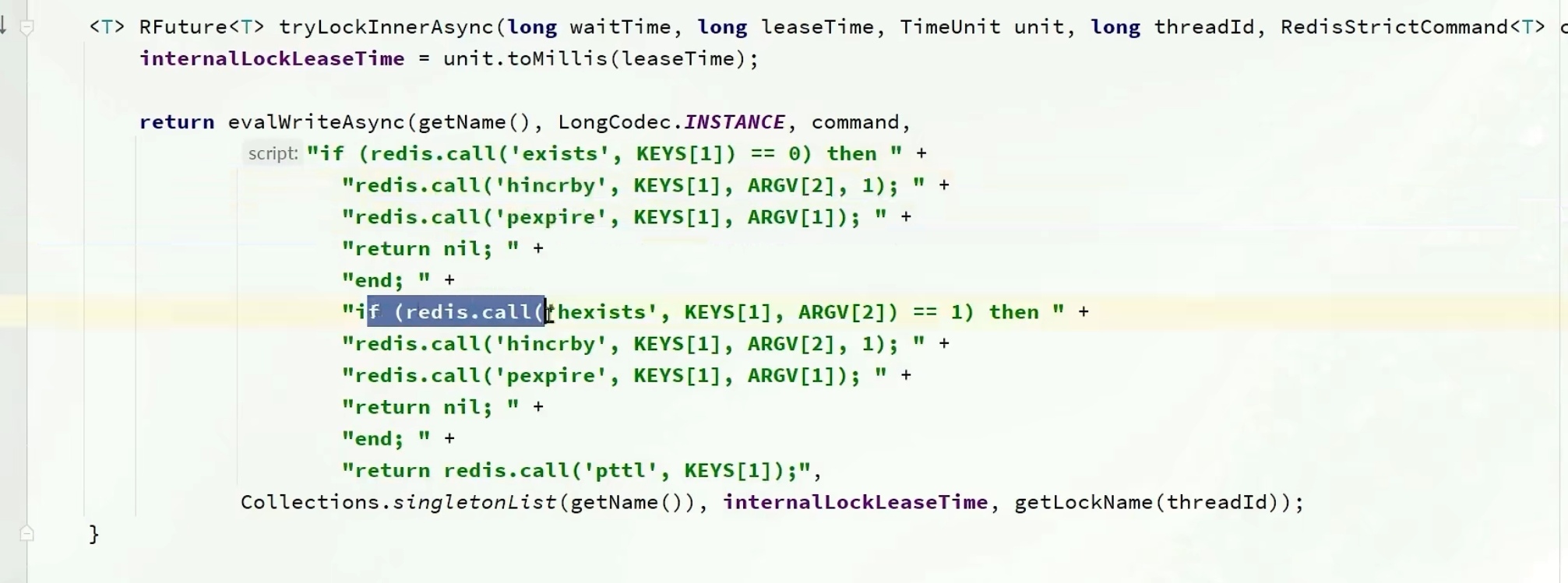
之后就可以获取锁了,上面重入讲过了
我们重点在下面的重试
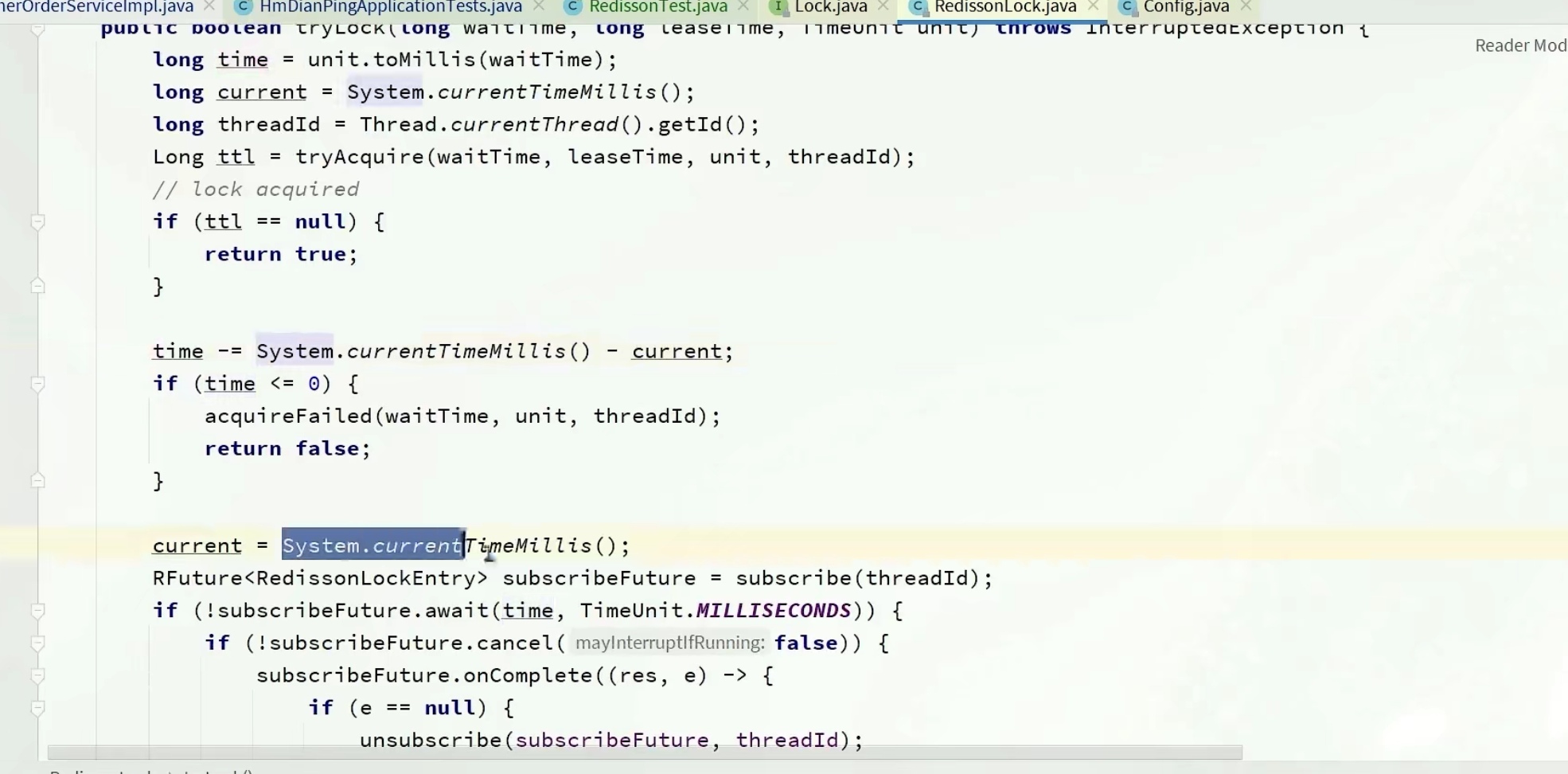
如果获取锁成功了,那么ttl就会为null,if语句成立,返回true
然后算一下我的等待时间还有没有,如果小于0了,就返回false代表过去锁失败
先严谨了一波,先判断下time结束了没,结束了就没必要等了
这里是不会立马去重试的,那样太傻了,这里利用subscrible订阅了别人释放锁的信号(在释放锁代码中有一个public,在释放后会发布一个消息通知)
后面会尝试等待,!subscribleFuture.await,会等待time的时间,如果上面的future在我指定的时间内完成,那么就会返回true,使得代码继续进行
但是如果超时等不到的话,就会返回false,进入if语句中,先unsubscrible取消订阅,在返回一个false,代表获取锁失败
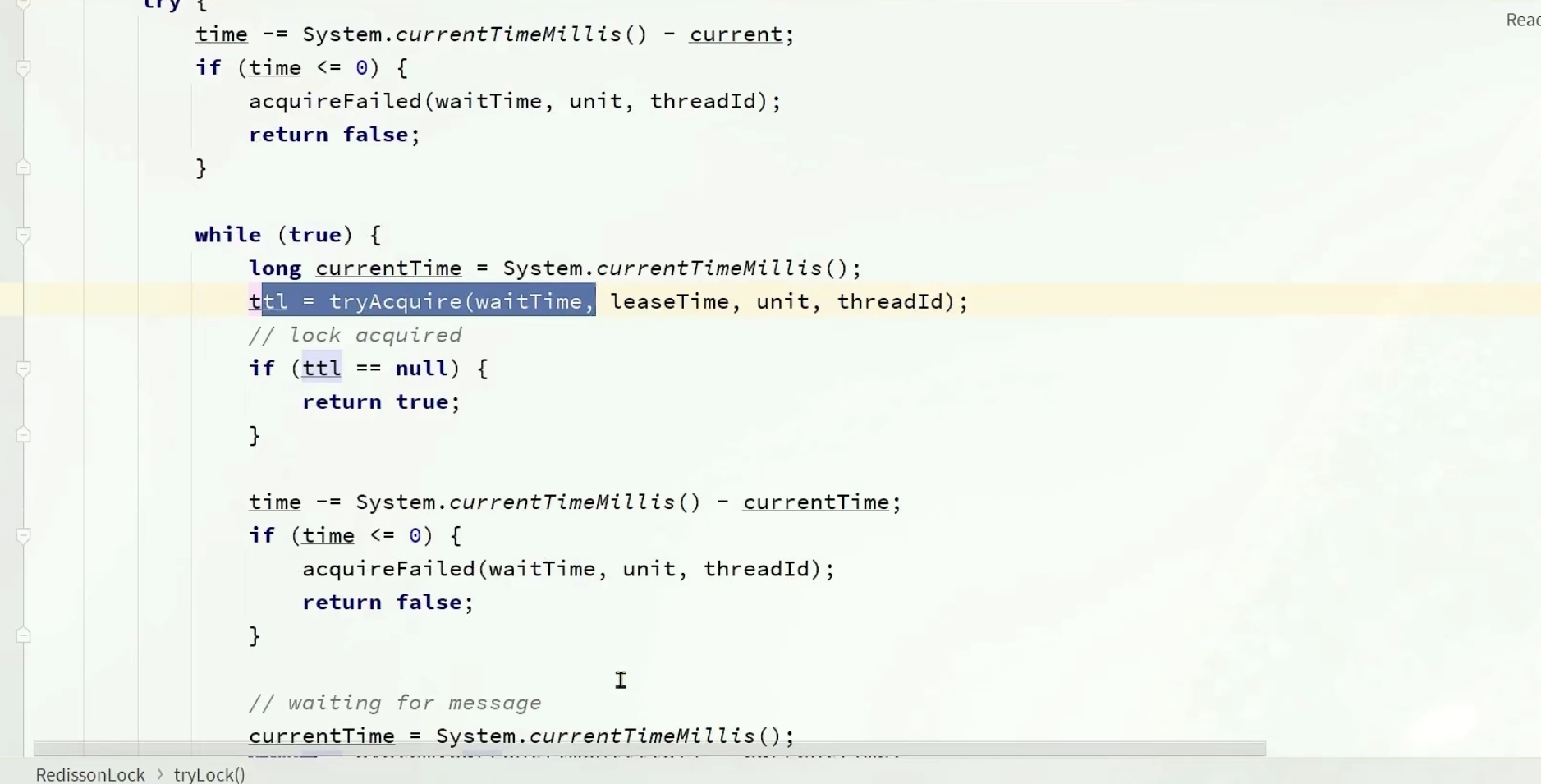
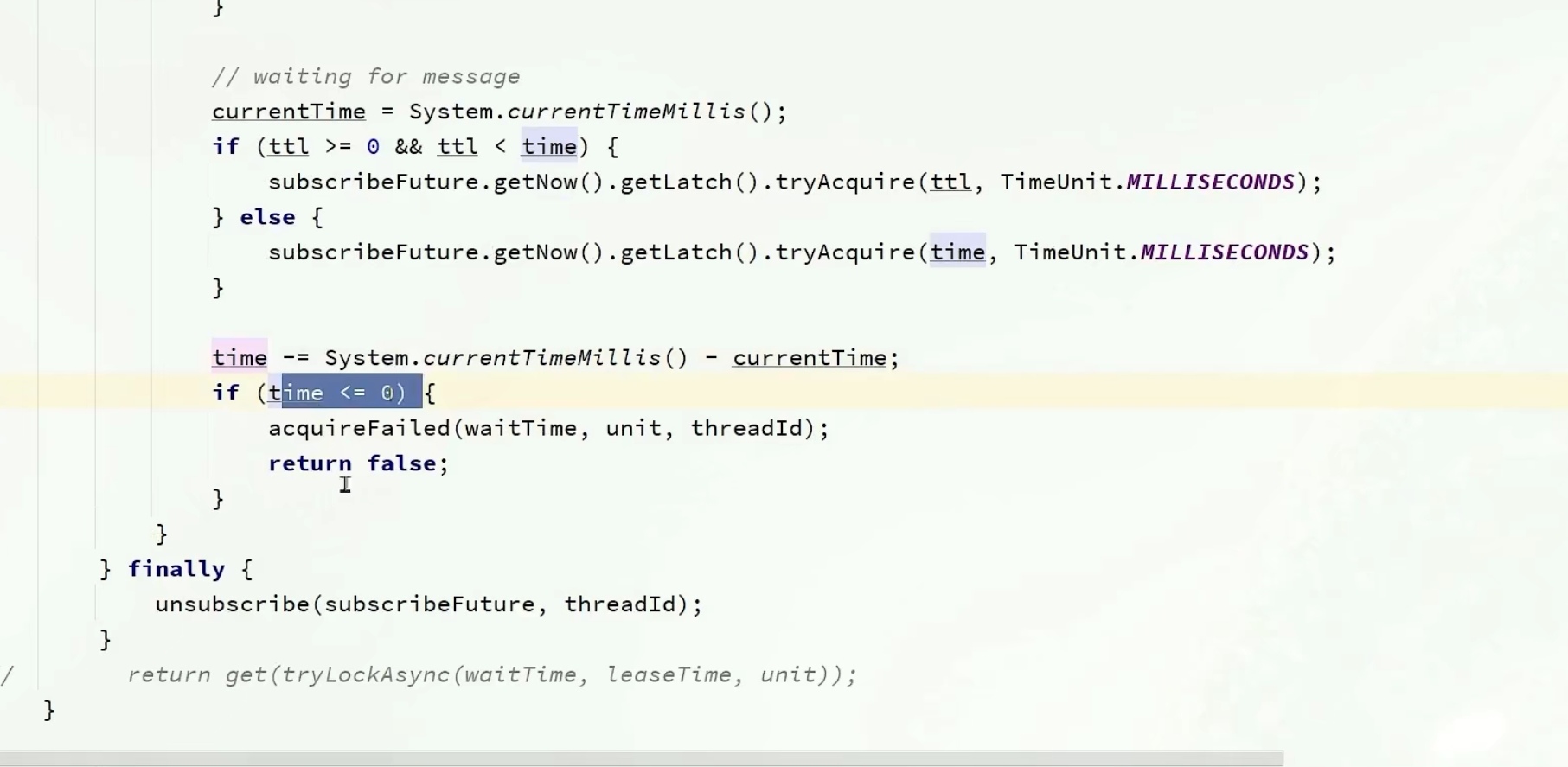
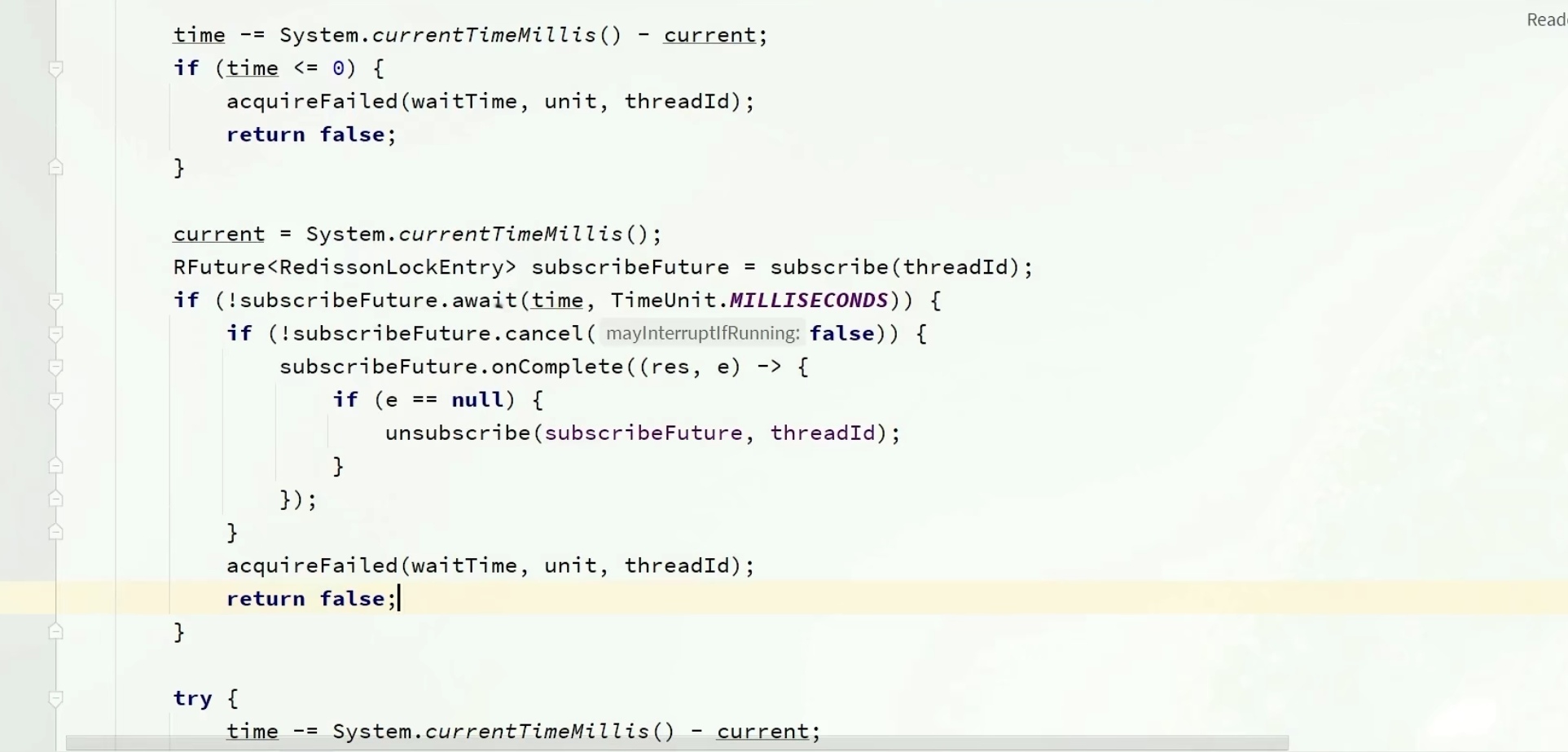
先严谨了一波,先判断下time结束了没,结束了就没必要等了
这时候就进去循环里面,开始第一次获取锁了,再返回一个ttl,如果ttl是null,说明获取锁成功了,不用管了,返回true
失败的话同样在判断一下time,
这时候我们也不会立马就重试,还是小判断一下
然后通过信号量的方式getLatch,释放锁的时候是会给一个信号的,在if中(如果经过规定的时间还没拿到就返回false,如果拿到了就返回true),根据ttl和time的大小,如果ttl小,没必要等太长时间,等个ttl,等他释放了就可以直接用了。
如果time小,那我就等个time时间,time到期了就没必要等了
等待对应时间后,time还有时间的话重新进去循环中(因为别的ttl到期后,我还需要和其他线程去抢锁,有可能我是抢不到的)
3.2看门狗机制
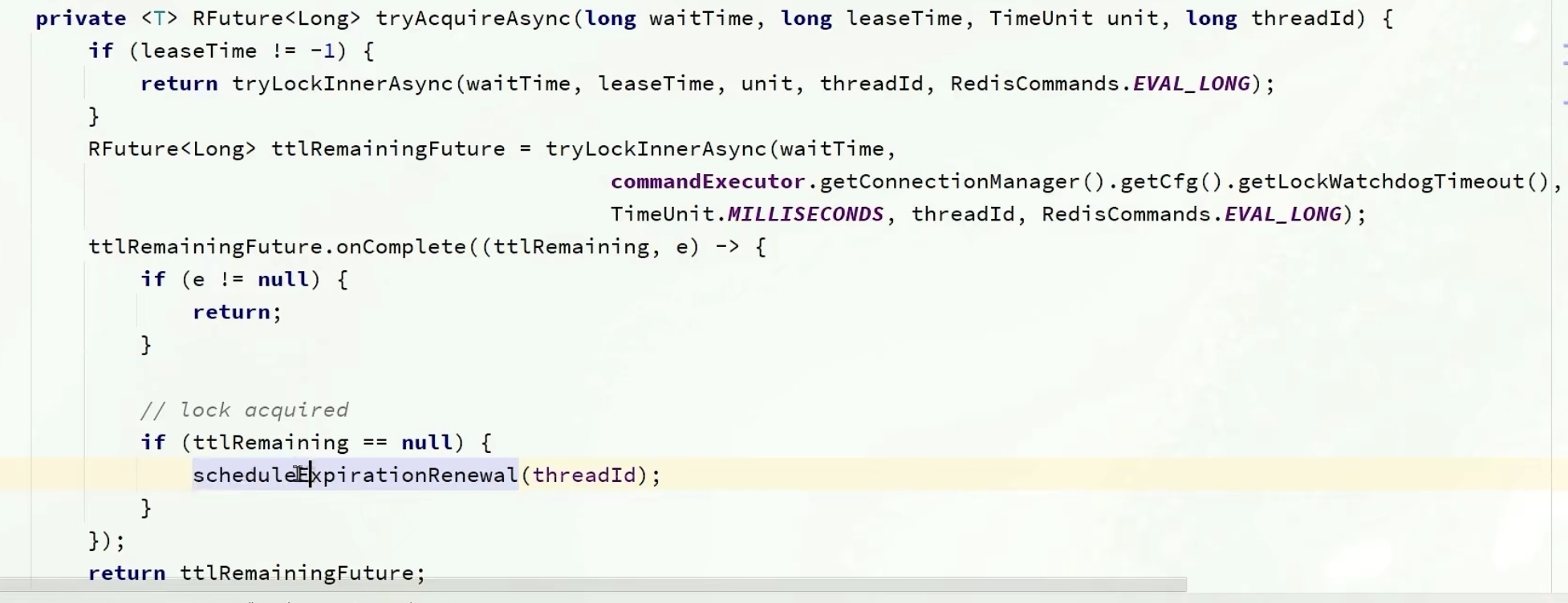
执行ttlRemainingFuture.onComplete方法中,e是异常,如果异常不是空,代表有异常,返回
只要没有异常,只要ttkRemaining=null,代表我获取锁成功了,这时候解决有效期的问题
进入scheduleExpirationRenewal方法(任务调度,过期时间的续约)

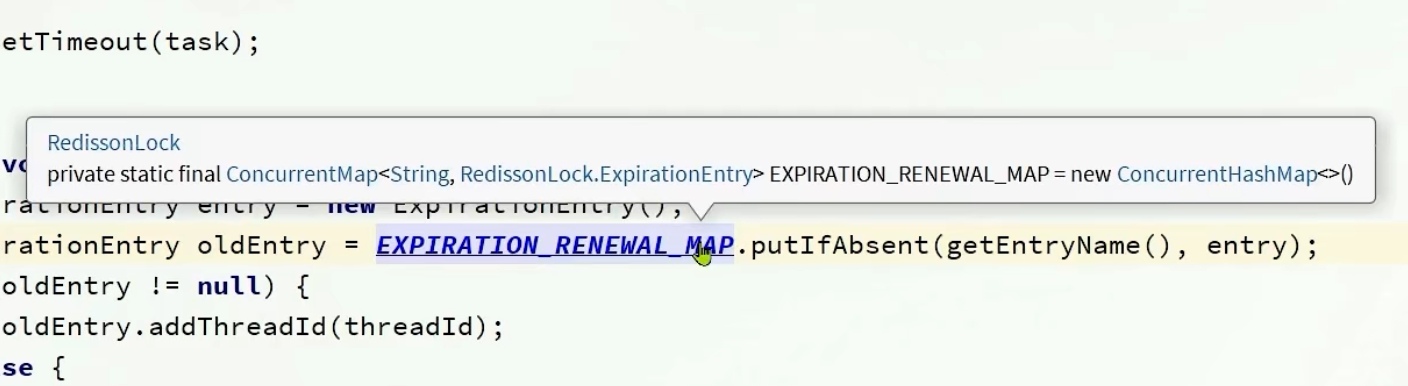
创建了一个静态的map,getEntryname()
相当于获取锁的名称,entryName=id➕":"+name
每个锁都有自己的名字,在map里面有着自己的名字和entry
putIfAbsent,如果不存在再放,放得就是全新的,如果存在的话就不会执行
oldEntry如果不是空,说明不是第一次来了把threadId加进去
如果oldEntry是空,说明我是第一次来,map.里面还没有对应的entry,不仅要加threadId,还要执行renewExpiration方法(续约)
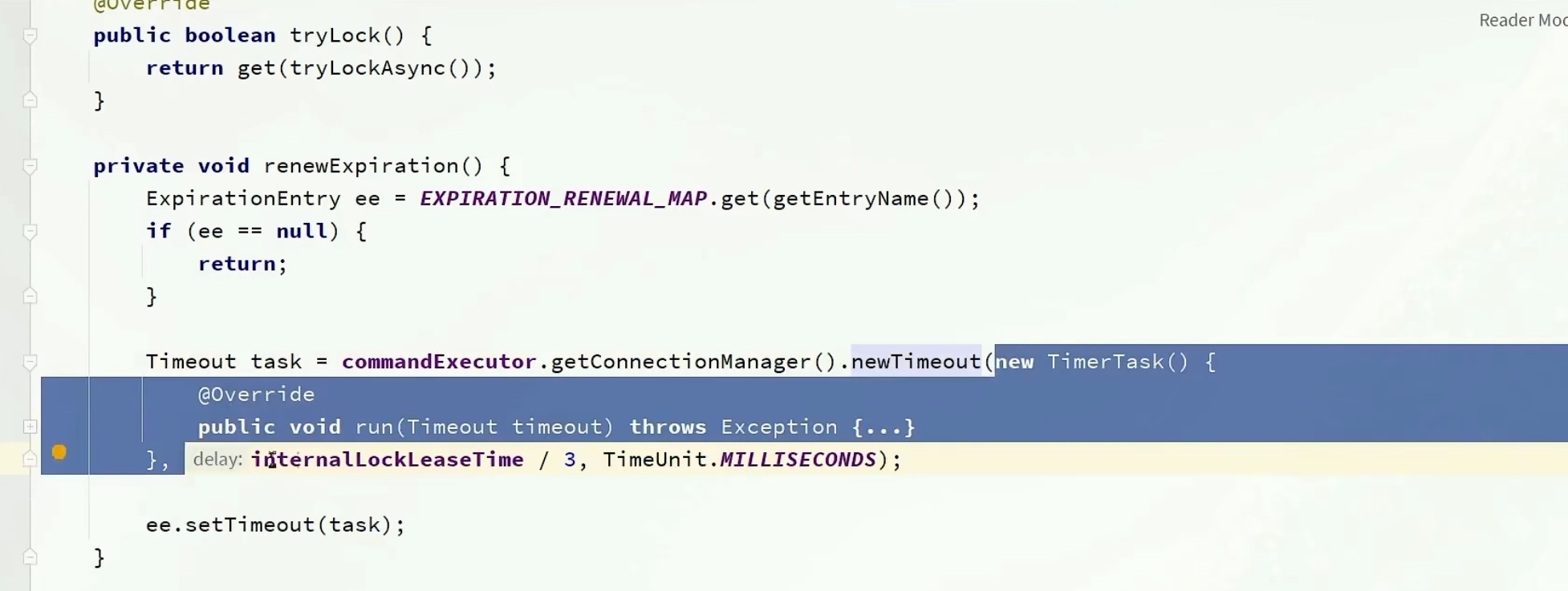
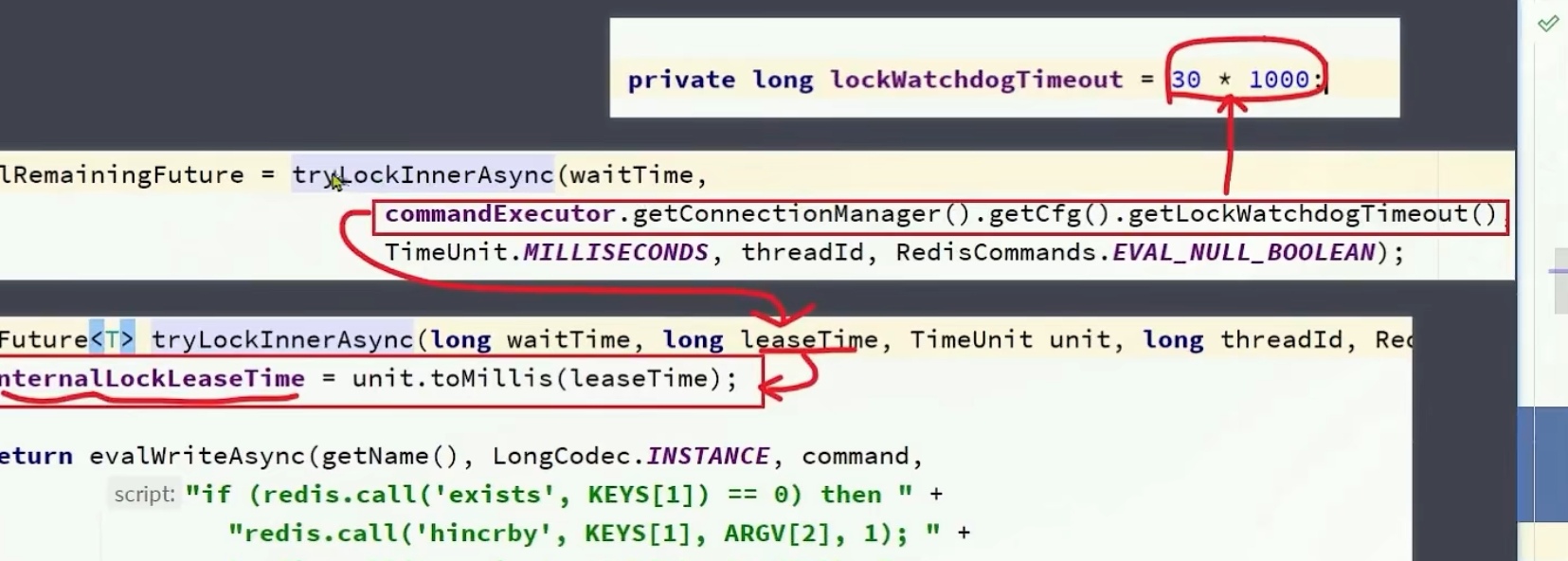
进入renewExpiration方法后,Timeout定义了一个定式任务,TimerTask有两个参数,一个是任务本身task,另一个是时间范围delay
在delay到期后执行这个延时任务
对于internalLockLeaseTime其实就是我们当时系统传进去的看门狗时间30s
所以每过10s,执行下这个任务
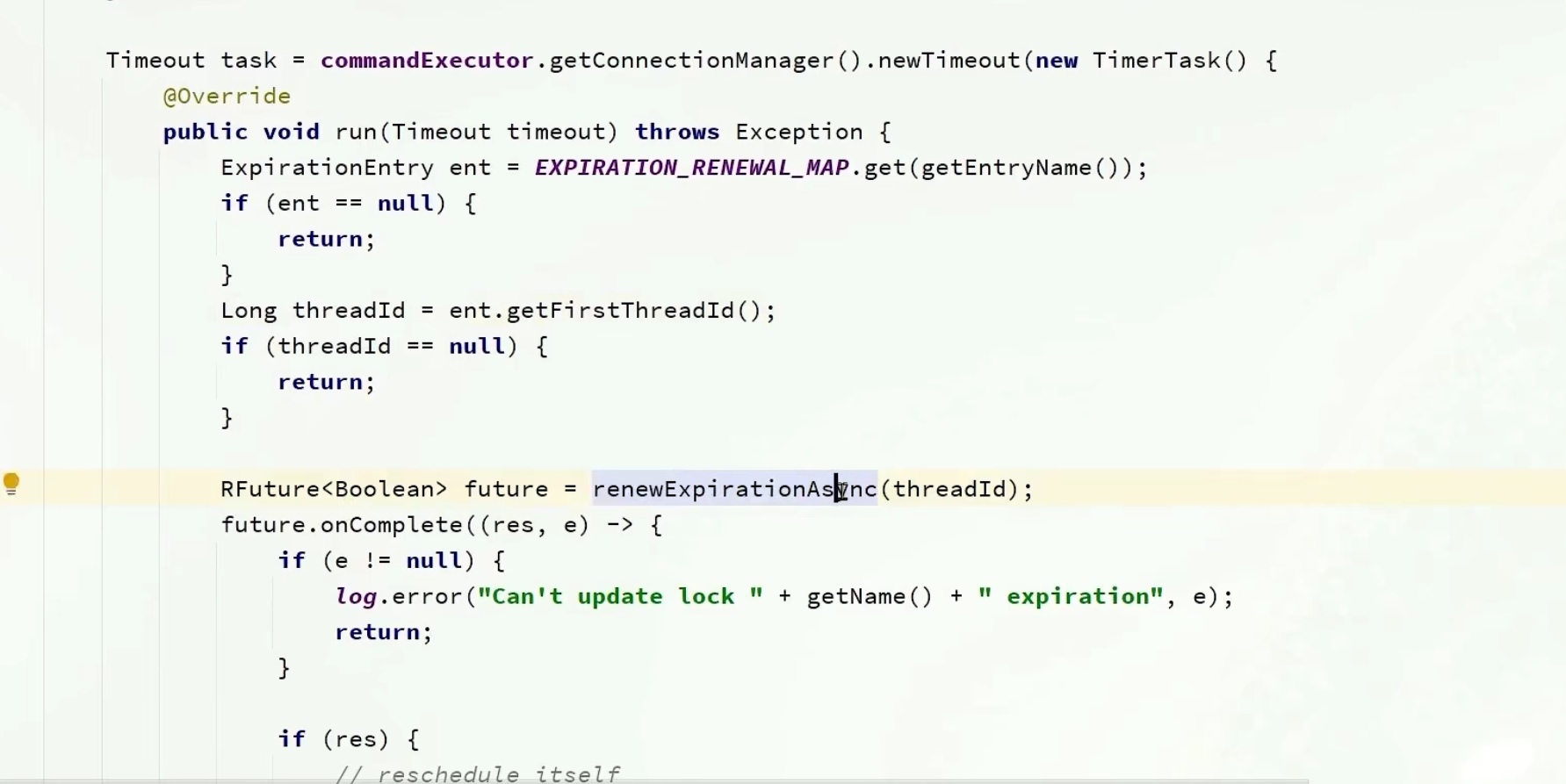
我们展开这个具体看看,先从map中拿出entry给ee,再从entry中拿出threadId,之后调用renewExpirationAsinc方法刷新

KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
ARGV[2]: id + ":" + threadId; 锁的小key
就是一段lua脚本去运行redis,先判断这个锁是不是我这个线程的(一般都是,因为就是从这里传进来的)
然后更新有效期
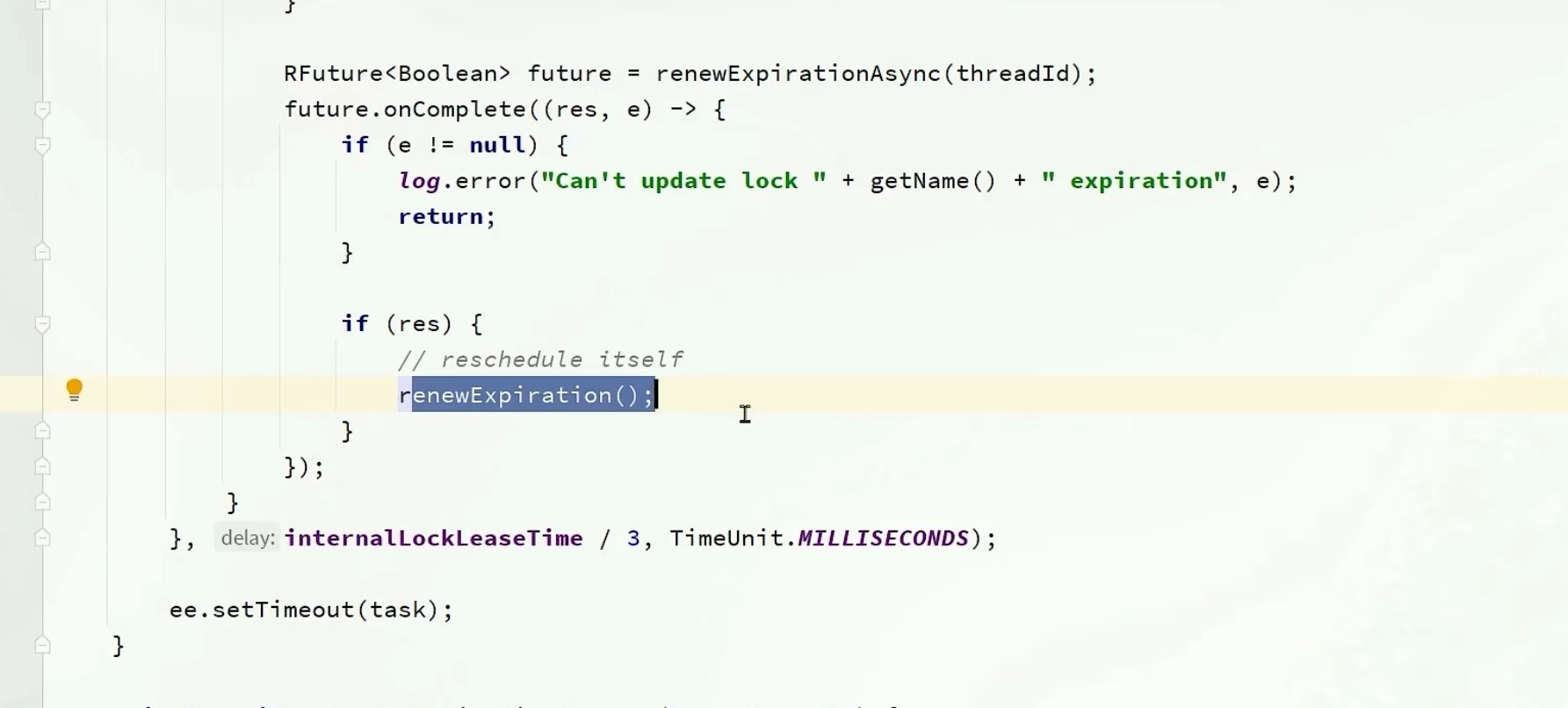
出来renewExpirationAsinc以后,下面我又调用了renewExpiration方法(自己)
最终把任务放到ee中,ee就是上面得到的entry,这样entry中还有任务
这就是为什么之前,如果是oldentry如果map已经有了就不用再次更新了,因为已经有这个任务了
诶,所以,我每隔10s执行这个任务这个任务里面呢,我又刷新有效期,刷新完后又调用自己,再次刷新,每隔10s,刷新有效期到30s,所以一直是有效的,不会出现因为业务阻塞导致锁过期

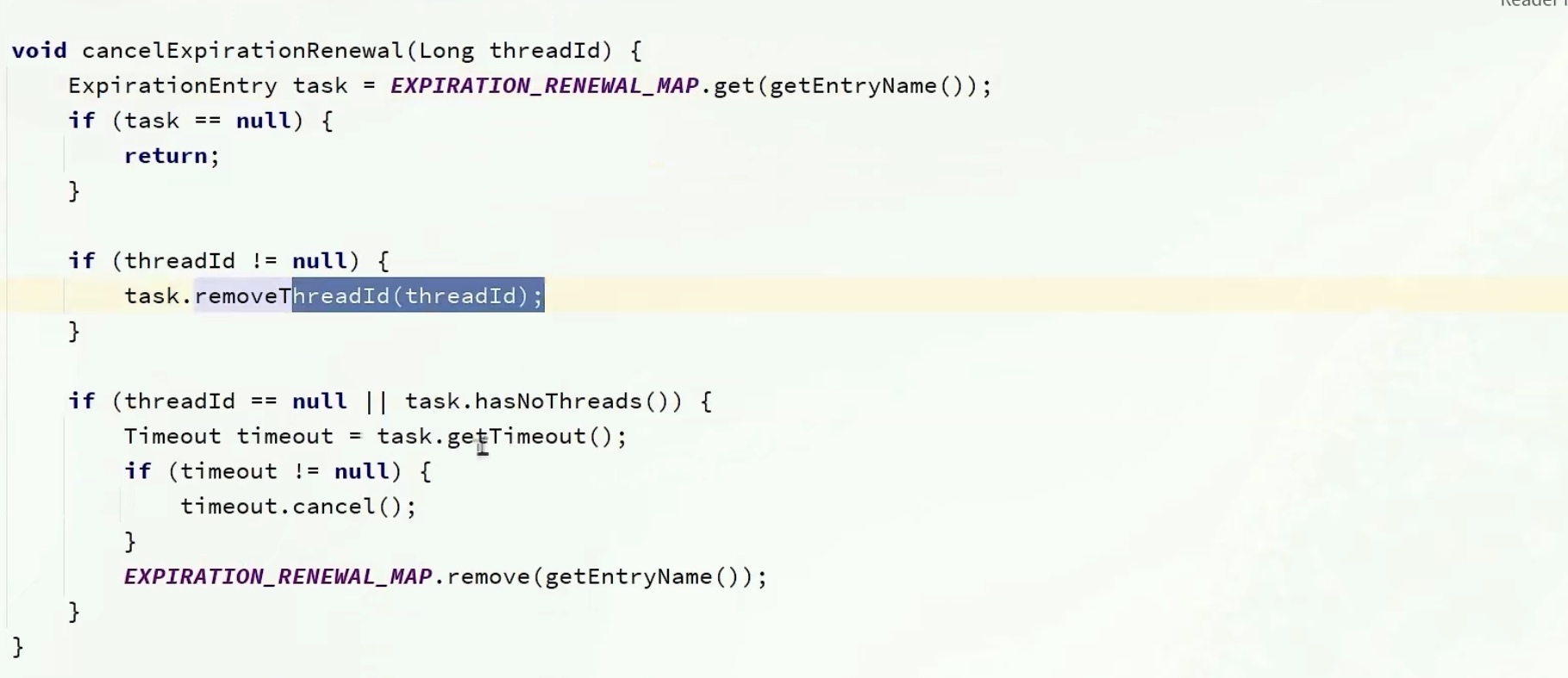
再释放锁方法中取消这些东西
先去除id
在cancel取消任务
在把对应entry从map删除
3.3redission锁的MutiLock原理
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。

为了解决这个问题,redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。 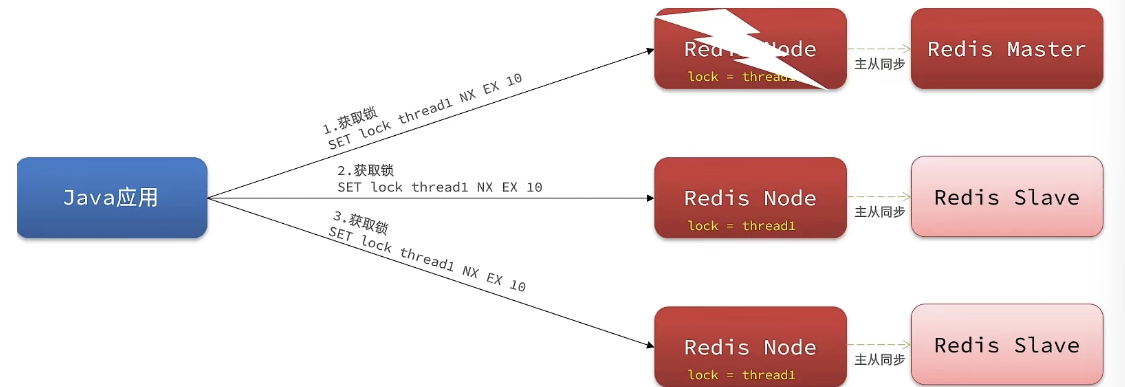
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {try {return tryLockAsync(waitTime, leaseTime, unit).get();} catch (ExecutionException e) {throw new IllegalStateException(e);}long newLeaseTime = -1;if (leaseTime != -1) {if (waitTime == -1) {newLeaseTime = unit.toMillis(leaseTime);} else {newLeaseTime = unit.toMillis(waitTime) * 2;}}long time = System.currentTimeMillis();long remainTime = -1;if (waitTime != -1) {remainTime = unit.toMillis(waitTime);}long lockWaitTime = calcLockWaitTime(remainTime);int failedLocksLimit = failedLocksLimit();List<RLock> acquiredLocks = new ArrayList<>(locks.size());for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {RLock lock = iterator.next();boolean lockAcquired;try {if (waitTime == -1 && leaseTime == -1) {lockAcquired = lock.tryLock();} else {long awaitTime = Math.min(lockWaitTime, remainTime);lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);}} catch (RedisResponseTimeoutException e) {unlockInner(Arrays.asList(lock));lockAcquired = false;} catch (Exception e) {lockAcquired = false;}if (lockAcquired) {acquiredLocks.add(lock);} else {if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {break;}if (failedLocksLimit == 0) {unlockInner(acquiredLocks);if (waitTime == -1) {return false;}failedLocksLimit = failedLocksLimit();acquiredLocks.clear();// reset iteratorwhile (iterator.hasPrevious()) {iterator.previous();}} else {failedLocksLimit--;}}if (remainTime != -1) {remainTime -= System.currentTimeMillis() - time;time = System.currentTimeMillis();if (remainTime <= 0) {unlockInner(acquiredLocks);return false;}}}if (leaseTime != -1) {List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size());for (RLock rLock : acquiredLocks) {RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);futures.add(future);}for (RFuture<Boolean> rFuture : futures) {rFuture.syncUninterruptibly();}}return true;
}waitTime是等待获取锁的最长时间,主要作用包括:
-
控制获取锁的等待时长 - 如果在waitTime时间内无法获取所有锁,就放弃
-
作为重试的时间窗口 - 在这个时间范围内会不断尝试获取锁
-
避免无限等待 - 防止线程因为无法获取锁而永久阻塞
完整代码逐行解析
java
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {// 方法签名:支持等待时间、租约时间和时间单位// 可能会抛出InterruptedException(线程中断异常)try {// 调用异步版本,然后通过.get()同步等待结果return tryLockAsync(waitTime, leaseTime, unit).get();} catch (ExecutionException e) {// 如果异步执行过程中出现异常,包装后抛出throw new IllegalStateException(e);}// 注意:上面的return语句已经返回了,所以下面的代码实际上不会执行// 这可能是因为代码片段不完整或者有误// 但为了完整理解,我们继续分析下面的逻辑
参数处理和初始化
java
// 计算新的租约时间
long newLeaseTime = -1; // 默认-1表示无限期
if (leaseTime != -1) { // 如果用户指定了租约时间
if (waitTime == -1) {
// 情况1:无限等待,使用用户指定的租约时间
newLeaseTime = unit.toMillis(leaseTime);
} else {
// 情况2:有限等待,租约时间 = 等待时间 * 2
// 为什么是2倍?确保在重试过程中已获取的锁不会过期
newLeaseTime = unit.toMillis(waitTime) * 2;
}
}
// 记录开始时间,用于计算剩余时间
long time = System.currentTimeMillis();
// 剩余时间初始化
long remainTime = -1; // -1表示无限等待
if (waitTime != -1) {
// 将用户指定的等待时间转换为毫秒
remainTime = unit.toMillis(waitTime);
}
// 计算每次获取单个锁的最大等待时间
long lockWaitTime = calcLockWaitTime(remainTime);
// 这个方法通常会返回一个合理的值,比如剩余时间的一部分
// 获取失败锁的限制数量
int failedLocksLimit = failedLocksLimit();
// 这个方法通常返回0,表示不允许任何锁获取失败
// 创建列表来保存成功获取的锁
List<RLock> acquiredLocks = new ArrayList<>(locks.size());
// 预先分配足够容量,避免扩容开销
核心锁获取循环
java
// 使用ListIterator遍历所有需要获取的锁// ListIterator支持向前和向后移动,这在重置时很重要for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {// 获取下一个锁RLock lock = iterator.next();boolean lockAcquired; // 标记是否成功获取当前锁try {// 根据参数选择不同的获取策略if (waitTime == -1 && leaseTime == -1) {// 情况1:无限等待 + 无限租约,使用最简单的tryLocklockAcquired = lock.tryLock();} else {// 情况2:有限等待或有限租约// 计算本次获取锁的等待时间,取lockWaitTime和remainTime的较小值long awaitTime = Math.min(lockWaitTime, remainTime);// 尝试获取单个锁,使用计算出的等待时间和租约时间lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);}} catch (RedisResponseTimeoutException e) {// Redis响应超时异常处理unlockInner(Arrays.asList(lock)); // 释放当前锁(如果已获取)lockAcquired = false; // 标记获取失败} catch (Exception e) {// 其他异常处理lockAcquired = false; // 标记获取失败,但不释放(因为可能根本没获取到)}
获取结果处理
java
if (lockAcquired) {// 成功获取锁,添加到已获取列表acquiredLocks.add(lock);} else {// 获取当前锁失败// 检查剩余未获取的锁数量是否已达到失败限制if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {break; // 达到失败限制,跳出循环}// 处理失败情况if (failedLocksLimit == 0) {// 失败限制为0,表示不允许任何失败// 释放所有已经成功获取的锁unlockInner(acquiredLocks);if (waitTime == -1) {// 如果是无限等待,直接返回失败return false;}// 重置失败限制计数器failedLocksLimit = failedLocksLimit();// 清空已获取锁列表acquiredLocks.clear();// 重置迭代器到开始位置,准备重新尝试// 这是关键步骤:回到起点重新获取所有锁while (iterator.hasPrevious()) {iterator.previous();}} else {// 失败限制不为0,减少失败计数failedLocksLimit--;}}
时间管理和超时检查
java
// 如果设置了等待时间,需要更新剩余时间if (remainTime != -1) {// 计算从循环开始到现在经过的时间long elapsed = System.currentTimeMillis() - time;// 更新剩余时间remainTime -= elapsed;// 更新时间戳,用于下一次计算time = System.currentTimeMillis();// 检查是否超时if (remainTime <= 0) {// 超时,释放所有已获取的锁unlockInner(acquiredLocks);// 返回获取失败return false;}}} // 结束for循环
成功获取后的处理
java
// 如果执行到这里,说明成功获取了所有需要的锁// 如果用户指定了租约时间,需要为所有锁设置统一的租约时间if (leaseTime != -1) {List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size());// 为每个已获取的锁设置过期时间for (RLock rLock : acquiredLocks) {// 转换为RedissonLock类型,调用异步过期方法RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), // 用户指定的租约时间TimeUnit.MILLISECONDS);futures.add(future);}// 等待所有过期设置操作完成for (RFuture<Boolean> rFuture : futures) {rFuture.syncUninterruptibly(); // 同步等待,不可中断}}// 返回成功return true;
}
完整流程示例(获取3个锁)
假设我们要获取lockA、lockB、lockC,waitTime=10秒,leaseTime=30秒:
第一次尝试:
-
获取lockA:成功 →
acquiredLocks = [lockA] -
获取lockB:成功 →
acquiredLocks = [lockA, lockB] -
获取lockC:失败(被占用)
-
处理失败:
-
failedLocksLimit = 0,所以释放lockA和lockB -
清空
acquiredLocks -
重置迭代器到开始位置
-
更新剩余时间(假设已用2秒,
remainTime = 8秒)
-
第二次尝试:
-
获取lockA:成功 →
acquiredLocks = [lockA] -
获取lockB:成功 →
acquiredLocks = [lockA, lockB] -
获取lockC:成功 →
acquiredLocks = [lockA, lockB, lockC]
成功完成:
-
为lockA、lockB、lockC统一设置30秒过期时间
-
返回
true