RAL-2025 | 北理工具身导航如何融入家居环境!OpenIN:动态家居环境中的开放词汇实例导向导航

作者:Yujie Tang, Meiling Wang, Yinan Deng, Zibo Zheng, Jingchuan Deng, Yufeng Yue
单位:北京理工大学,宁波诺丁汉大学
论文标题:OpenIN: Open-Vocabulary Instance-Oriented Navigation in Dynamic Domestic Environments
出版信息:IEEE Robotics and Automation Letters ( Volume: 10, Issue: 9, September 2025)
论文链接:https://ieeexplore.ieee.org/document/11091457
项目主页:https://openin-nav.github.io/
主要贡献
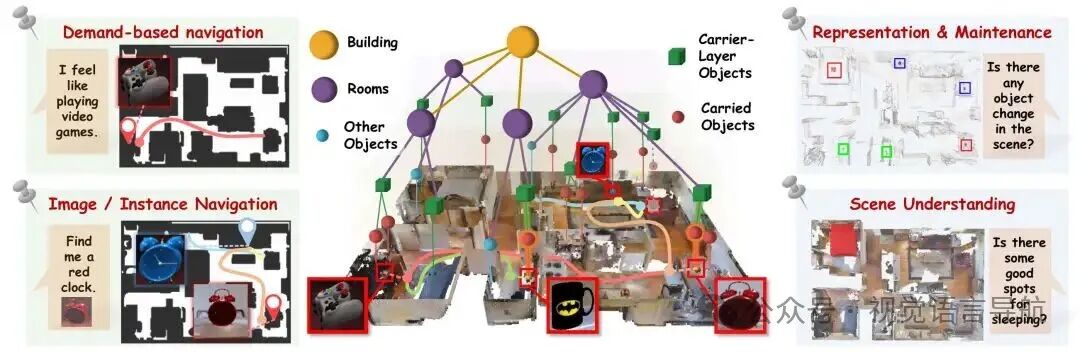
提出了开放词汇、实例导向的导航系统OpenIN,支持多模态(文本和图像)和多类型(需求、语义和实例级)对象导航指令,能够有效导航到位置可变的日常实例。
提出了可适应的载体关系场景图(CRSG),主要描述对象之间的动态承载关系,并在导航过程中动态更新,以维持场景信息的时效性和准确性。
设计了基于CRSG的导航策略,利用视觉语言特征和多模态大语言模型(MLLM)的常识知识来指导决策,提高导航效率和准确性。
通过广泛的定性和定量实验表明,更新CRSG有助于在涉及长序列移动实例的任务中实现高效导航。此外,在真实机器人上部署了该算法,验证了其实用性。
研究背景
在日常家庭环境中,机器人需要能够高效地导航到各种对象,包括位置不固定的常用物品(如杯子)。然而,现有的目标导航方法大多存在以下局限性:
多数方法局限于封闭集导航,对未知对象的性能较差。
很多方法仅支持一种预定义的指令类型,缺乏灵活性。
实例级导航需要精确的目标识别,但多数方法缺乏专门的目标识别模块,导致准确度较低。
在日常场景中,常用实例对象的位置是动态变化的,且其承载者也会改变,这对场景记忆和动态更新提出了挑战,而许多现有方法在这方面处理效果不佳。
本文提出OpenIN系统,通过构建和更新CRSG来捕捉常用物体与其静态载体之间的关系,并在导航过程中持续更新这些关系,从而更好地应对动态环境中的导航需求。
场景图构建与更新
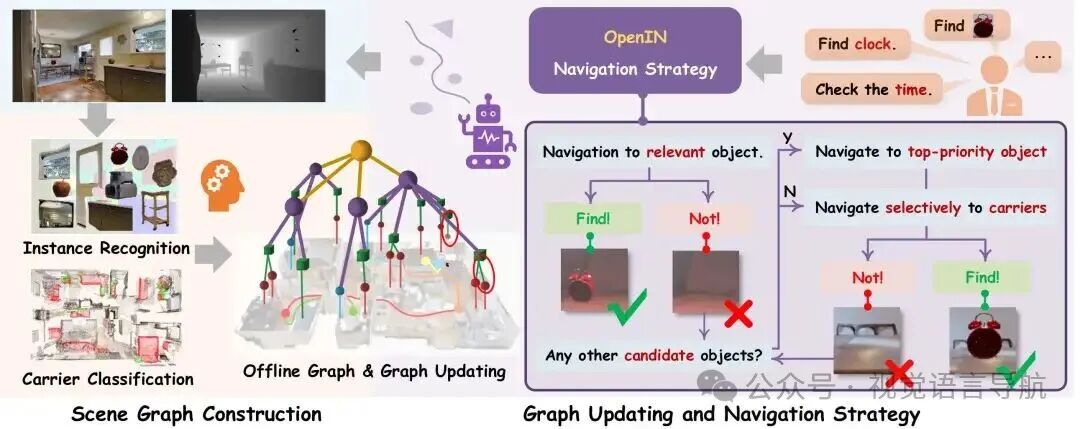
离线载体关系场景图构建
离线实例地图构建
使用预收集的场景RGB-D数据构建离线开放词汇实例地图。
与Conceptgraph不同,每个实例对象不仅用CLIP特征表示,还增加了使用Tokenize Anything模型生成的描述列表和使用SBERT模型编码的文本特征。
场景图构建
建筑和房间层:
通过将墙壁和门的点云投影到2D平面并加密,基于门的方向初始化边界追踪,沿墙壁进行顺时针搜索以检测闭合回路,从而定义各个房间。将每个回路内的对象分配给相应的房间,形成建筑层。
载体层:
计算每个对象的文本特征与“用于放置物体的家具”对应的SBERT编码文本特征之间的相似度。选择相似度分数超过特定阈值的对象作为候选载体对象。
进一步基于几何标准(如大小和与地面接触)过滤这些候选对象,得到最终的载体层对象。每个载体还被赋予一个置信度分数,表示其存在可能性,该分数会根据观察结果的一致性持续更新,用于优先探索。
被载体层和其他对象:
对于非载体层对象,通过定义一个基于空间关系的二元函数来确定它是否被载体层对象承载。
满足特定条件(如垂直位置、空间重叠、尺寸限制和三维空间接近度)时,。对于每个载体,其承载的对象集合由满足上述条件的对象组成。
所有被承载的对象构成被载体层,用对象集合表示。除了载体层对象和被载体层对象外,其余对象被视为其他对象,也可以通过SBERT特征进行查询。
其他对象关系:
由于CRSG基于几何感知的实例点云,利用MLLM(如GPT-4o)自动生成函数,以对象的几何属性为输入,确定常见的空间关系,从而丰富CRSG的语义边。
在线CRSG更新
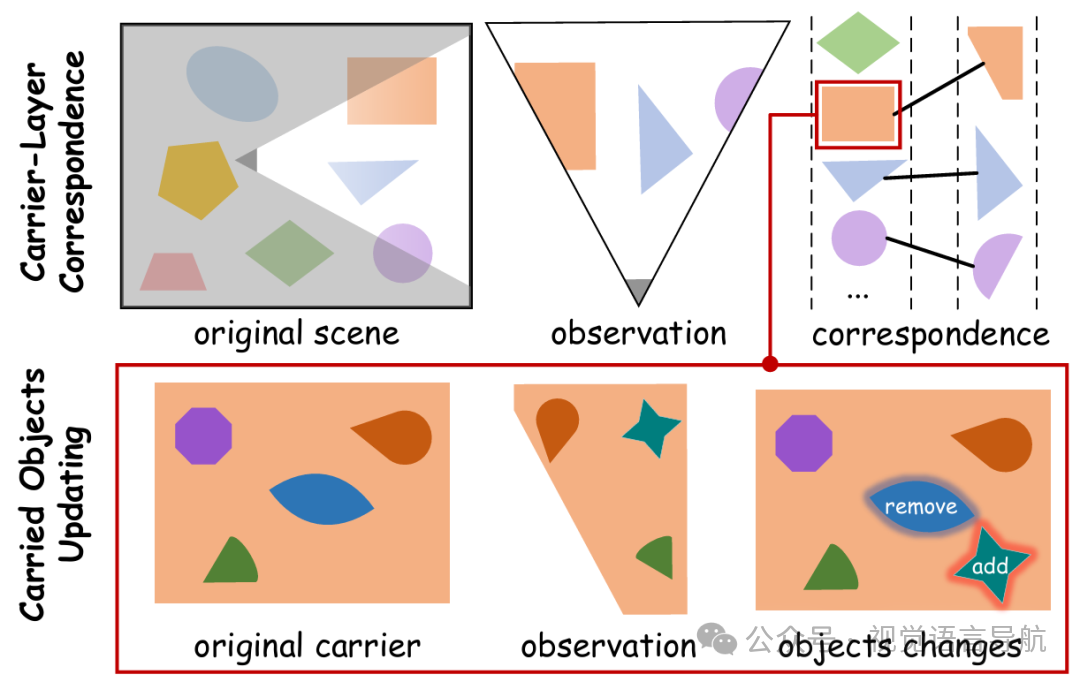
匹配和更新载体层对象
将观察到的RGB图像通过CropFormer、Tokenize Anything和SBERT处理,分别获得实例掩码、描述和SBERT特征。
机器人将每个新观察到的对象与现有的载体进行比较,考虑因素包括对象大小、中心位置之间的距离和SBERT特征相似度。
此外,如果新观察到的对象属于预收集的载体类别集合,且与CRSG中的任何现有载体不接近,并且满足载体的几何标准,则将其添加为新的载体层对象。
为了确定是否有载体消失,将每个载体的3D中心投影到RGB观察结果上,并将其类别与该位置检测到的边界框的描述进行匹配。
如果预期匹配的载体未匹配(即根据其投影位置和无遮挡,它应该可见),则相应降低其存在置信度。当载体的置信度低于预定义阈值时,将其从CRSG中移除。
添加和移除被承载对象
对于当前观察到的实例,使用确定它们是否被承载。然后将新识别的被承载对象与上之前记录的被承载对象进行比较,比较标准包括对象大小、中心位置之间的距离和SBERT特征相似度分数。比较后,相应地更新上的被承载对象:它们被添加、移除或保持不变。
值得注意的是,某些载体层对象通常只有部分被观察到。因此,对于每个观察到的载体层对象,计算其部分点云与CRSG中记录的被承载对象之间的距离;如果距离超过阈值,则不更新被承载对象的状态。上图展示了CRSG更新的示意图。此外,随着相关对象被添加或从场景图中移除,空间关系(如“旁边”、“下方”和“之间”)也会动态更新。
实例对象导航策略
导航策略概述
导航策略基于CRSG,将导航过程建模为一个固定策略的马尔可夫决策过程(MDP),通过动态更新CRSG来提高导航效率。目标是使机器人能够有效地找到特定实例对象,即使这些对象的位置发生变化。
导航前的初始化
CRSG初始化:在导航开始之前,假设已经构建了如第III部分所述的初始CRSG,它作为规划器的初始化状态。
目标对象输入:导航命令以文本、图像或两者的形式输入。对于仅图像输入,通过MLLM(如GPT-4o)将其转换为文本描述。然后,使用SBERT模型对文本进行编码,并与CRSG中每个对象的SBERT特征进行相似度比较,选择最相似的对象作为候选目标。
状态空间
在每个时间步,定义机器人的状态如下:
:机器人当前位置。
:未探索的载体层对象集合。
:在上的候选目标对象集合。
:是否找到目标的标志,。
初始状态,其中是机器人的初始位置,,。
动作空间
在每个时间步,智能体根据状态选择动作,遵循策略:
Explore():探索载体层对象。
Goto():导航到候选目标。
Stop:如果任务完成或失败,则结束任务。
策略
找到目标或未探索的载体层对象为空
或,则。
未找到目标但有候选目标
且,选择候选目标对象进行导航。具体步骤如下:
令,存储额外变量:
文本相似度:候选目标对象与目标文本的相似度。
距离:机器人当前位置与候选目标对象的距离。
平均深度值:候选目标对象被机器人相机观察时的平均深度值。
对于任何,其优先级评分计算如下:
其中,参数设置为,, m,,。
如果两个对象在同一房间内,;否则,。
机器人将导航到优先级评分最高的对象并进行探索。
未找到且无候选目标但有未探索的载体
,,且,MLLM选择一个载体对象进行探索。具体步骤如下:
提取中每个载体对象的描述,并将其与目标对象的图像或描述一起输入到MLLM中。利用MLLM对载体-被载体关系的常识理解(例如“杯子不太可能放在马桶上”),MLLM识别出最有可能的载体。
为了提高可靠性,每个未探索的载体还根据其存在置信度分数进行加权,偏向于既语义合适又可能存在的载体。
状态转移过程
当时:
机器人首先从中移除导航的载体对象,以及半径范围内没有候选目标的附近载体对象。
同时,通过添加新发现的候选目标(其SBERT特征与目标的相似度超过阈值)进行更新。
附近无候选的载体
新候选目标
当时:
的更新方式与(9a)相同。
通过移除并添加新候选目标进行更新。
新候选目标
此外,还结合新发现的载体,并移除消失的载体。相应地,结合新载体支持的候选目标,并丢弃与消失载体相关的候选目标。
目标确定标准
对于上承载的每个对象,首先计算其与目标文本的SBERT特征相似度。
如果输入包括图像,还会进行以下比较:
基于GPT-4o的图像到图像比较,得出相似度指标,判断对象是否相同。
输入图像与载体对象图像(记为)之间的RGB直方图特征相似度。对于每个通道(R、G、B),将像素值范围0到255分为个区间,并计算每个区间内的像素数量。然后对三个直方图进行归一化,得到输入图像和的最终直方图和,计算得到。
根据以下标准判断是否找到目标对象:
如果文本相似度或RGB相似度,则该对象不是目标对象,机器人继续探索。
否则,如果或,则认为该对象为目标对象,,表示任务完成。
实验结果
实验目的
通过一系列的模拟和现实世界实验,验证以下关键问题:
载体关系和文本描述特征是否提高了实例查询的准确性?
动态更新CRSG是否有助于更高效的实例导航?
基于CRSG的导航策略是否在导航到移动实例上表现出色?
评估指标
SR:机器人成功到达目标对象的比例。
SPL:通过比较机器人实际路径长度与最短路径长度来衡量导航效率。如果机器人失败,SPL为0;否则,SPL是最短路径长度与实际路径长度的比值,值越高表示性能越好。
实验结果
多类型查询在离线地图上的性能
实验设置:
在Gibson数据集的5个场景中进行实验,共85个查询,涵盖语义、实例和需求驱动三种类型的导航指令。
对比Vlmap和Conceptgraph方法。
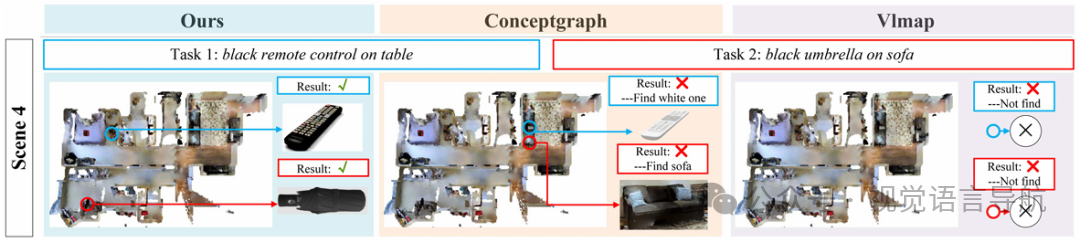

实验结果:
OpenIN的平均查询成功率最高(82.4%),如表所示。
OpenIN通过CRSG记录载体和被载体之间的关系,能够更精准地定位实例(例如“桌上的杯子”)。
在实例查询(如“黑色杯子”)中,OpenIN的CRSG利用SBERT文本特征,能够区分颜色相同的杯子,表现出色。
长期导航对日常实例的性能
实验设置:
在Gibson数据集的4个日常环境场景中,使用Habitat模拟器进行长期导航实验。
每个任务包含5个顺序的实例目标,目标物体的位置会随机改变。
对比Vlfm和Ofm方法,Ofm在不同置信度阈值下进行了实验。
另一个对比方法是OpenIN的变体Ours-w/o-u,不更新CRSG。
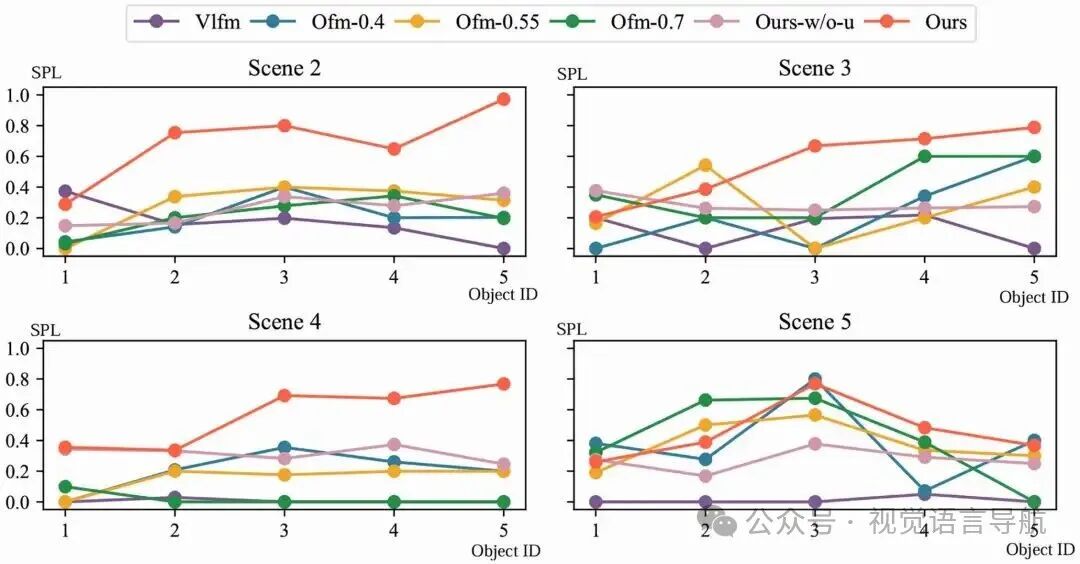
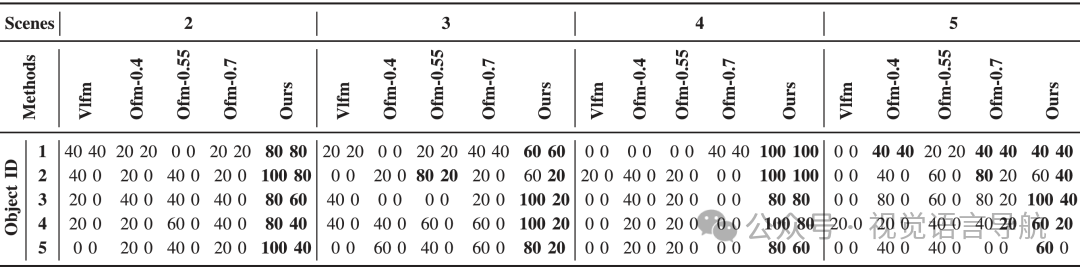
实验结果:
OpenIN在所有场景中均取得了最高的SR和Tasks_SR(i),如图表所示。
在长期导航任务中,OpenIN的SPL随着目标ID的增加而稳步提高,表明CRSG的动态更新对导航效率的积极影响。
Ours-w/o-u由于不更新CRSG,需要频繁探索每个目标的位置,导致SPL较低。
Vlfm和Ofm由于缺乏场景维护能力和实例级目标识别能力,表现不佳。
消融研究
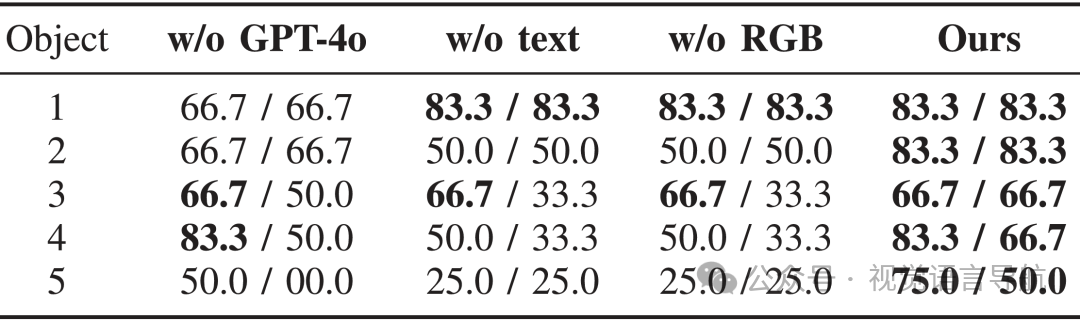
不同目标确定标准:
在场景4中进行消融实验,评估GPT-4o、文本特征和RGB直方图特征对目标确定的重要性。
结果表明,缺少任何一种特征都会降低成功率,证明了多模态特征融合的重要性。

不同导航策略:
在三个场景中进行单实例导航实验,比较“随机选择载体”、“基于MLLM选择载体”和OpenIN的导航策略。
OpenIN的SPL最高,表明其导航策略更高效。
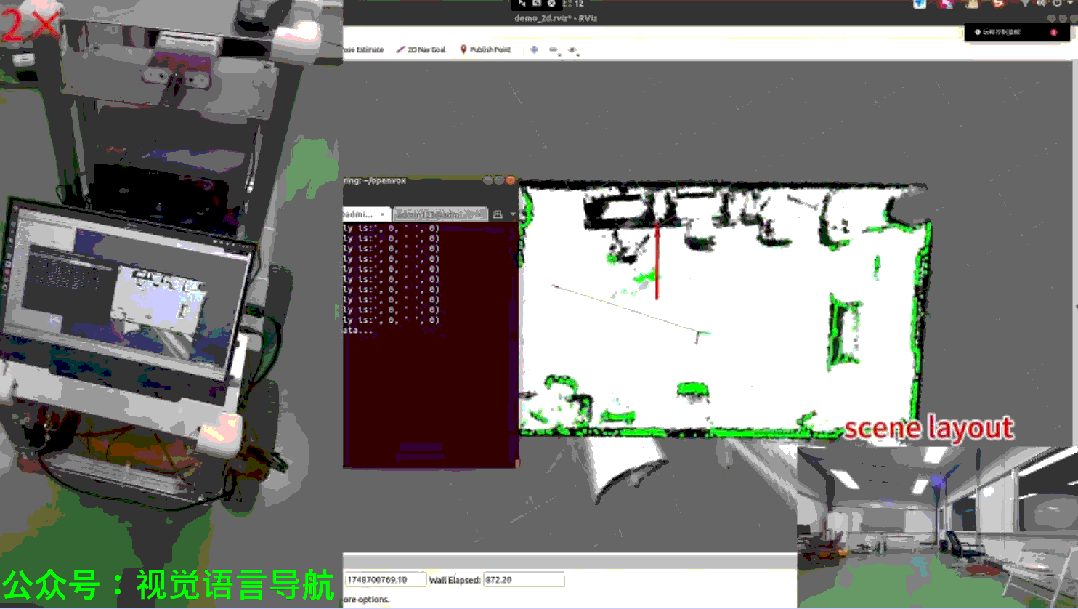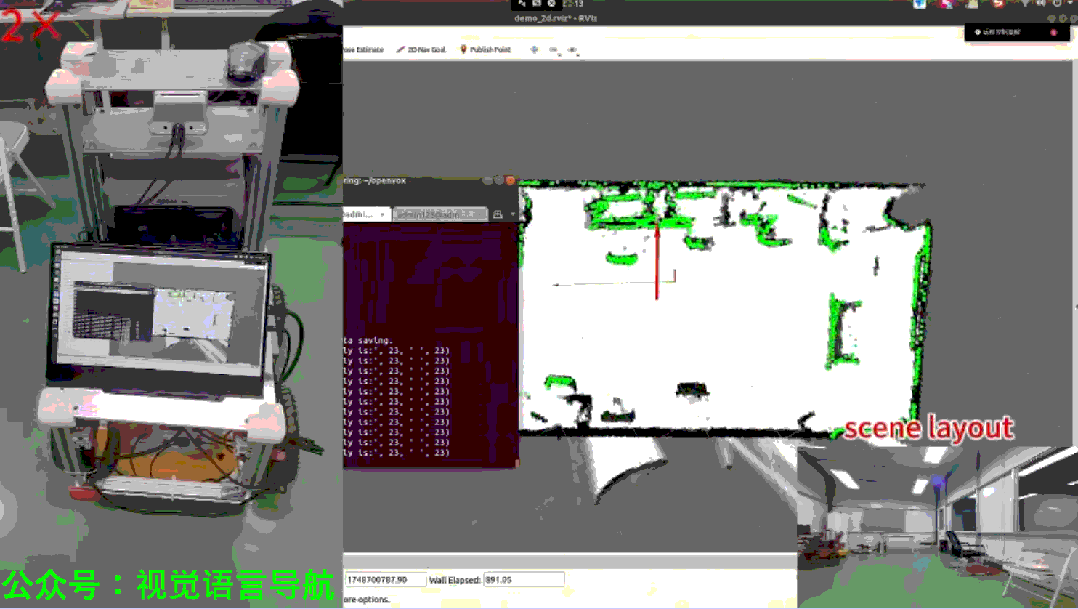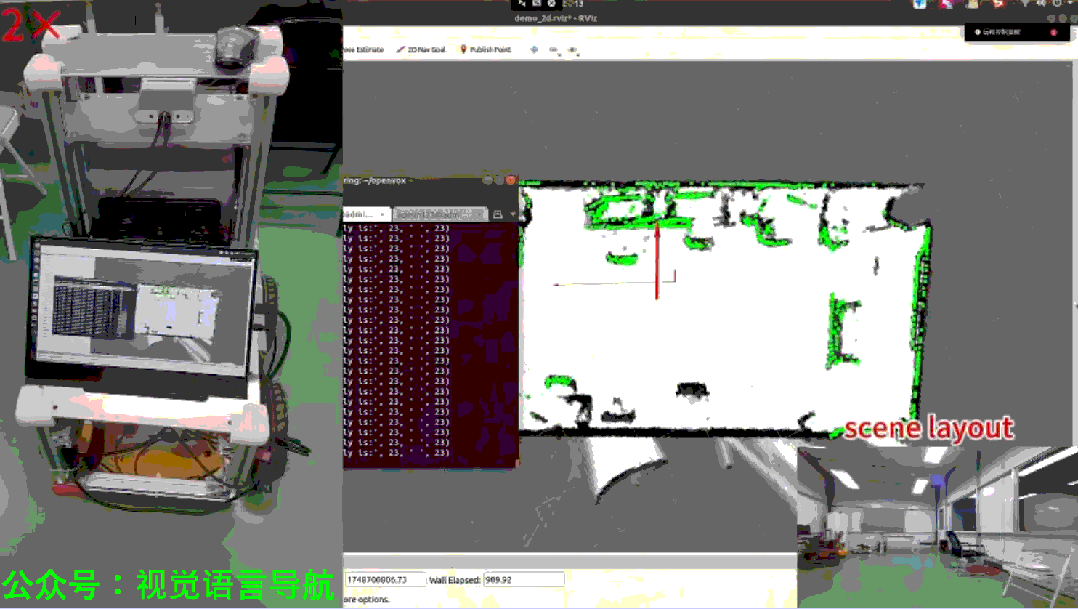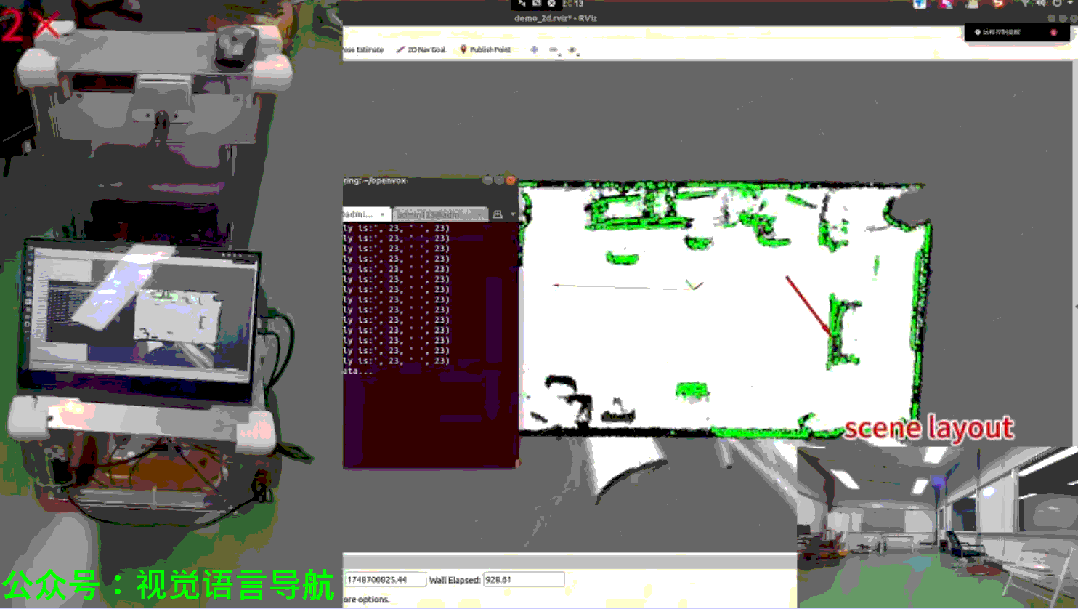
现实世界实验

实验设置:
在两个不同场景中进行实验,涉及不同的承载表面和目标实例。
使用Autolabor机器人,配备Livox Mid-360激光雷达进行SLAM定位和Azure Kinect DK获取RGB-D数据。


实验结果:
尽管存在一些失败模式(如低反射率表面导致的深度数据缺失、运动模糊导致的识别问题、遮挡或盲点),OpenIN系统在多种测试案例中均取得了成功。
上图展示了成功导航到两个连续目标实例的示例,证明了实时CRSG更新显著提高了导航效率。
结论与未来工作
结论:
OpenIN通过构建动态CRSG并利用视觉 - 语言特征和LLM的常识知识,能够有效导航到位置可变的日常实例,即使在存在干扰对象的情况下也能表现良好。
实验结果表明,CRSG的动态更新对于提高导航效率至关重要。
未来工作:
计划引入主动探索和建图模块,以进一步提高系统的性能和适应性。
