深入浅出 Mysql 索引
深入浅出 Mysql 索引
索引的作用和实现选型
索引用来快速定位数据库中的数据,如果是主键索引,则主键和行数据待在一起,如果是非主键索引,则结构类似于一个 LinkedMap,其中 key 是该索引对应的字段,value 是行数据对应的主键,按照 key 的顺序进行排列。
如果要查询的字段不在非主键索引中,即使查询使用该索引,也需要在查到对应的主键后走主键索引拿到查询的字段值,这也被称为回表,有的时候走非主键索引查询速度比主键索引还快,原因可能是查询的字段刚好就是这个索引字段,此时不用回表。
业务上我们建立索引常用的选择有:hash 索引和树索引。hash 索引利用 hash 函数和数组对指定下标O(1)访问的特性,提供了极快的等值查询功能,但对于范围查找、模糊查找无法发挥作用;树有非常多的形态,搜索树、平衡树、红黑树、B树、B+树…,因此数据库在索引选择上一般选择树结构。
一般的二叉搜索树的建立,以首节点为根节点,后续的数据比当前数据小,则成为当前节点的左子树,否则右子树,对于序列(34,22,89,5,23,77,91)来说,创建出的二分查找树如下图:
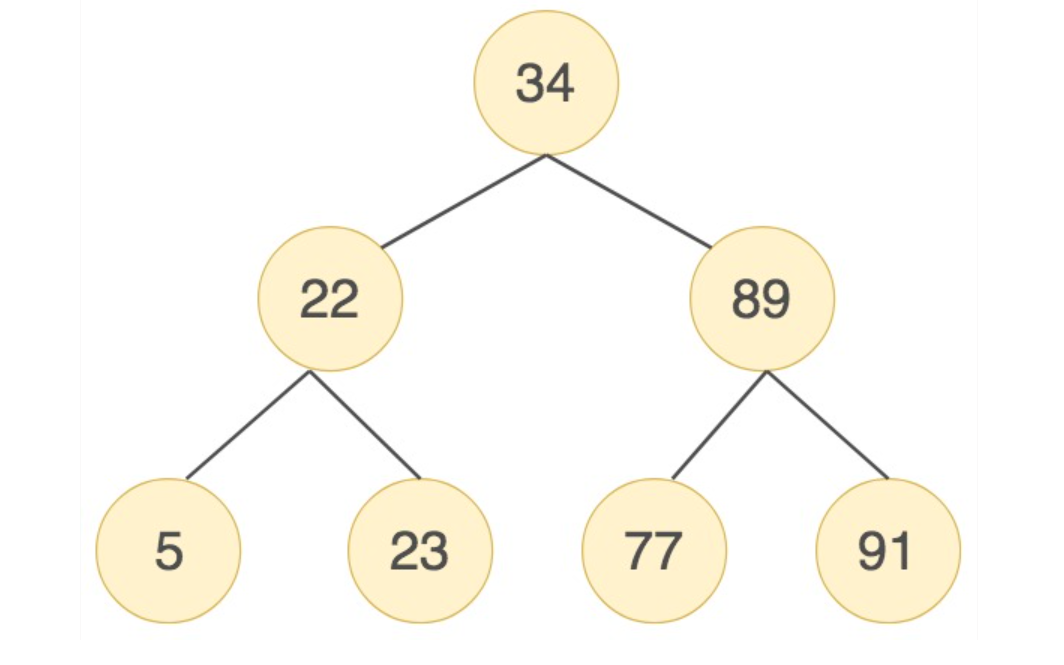
但是当数据比较极端,例如持续递增的一组序列,生成的二叉搜索树则会退化为链表,如下图:

为了避免极端数据情形导致查询恶化的情况,人们提出来平衡二叉搜索树(AVL树),它增加了每个节点左右子树高度差不能超过1的约束。
在平衡二叉搜索树中查找一个数据的时间复杂度近似为O(log2n),在数据量比较大的时候,由于每个节点只有2个子树,因此层高和查询耗时也会显著增加。
随后人们又发现如果不用二叉树,而是平衡M(M>2)叉树的情况下,以上问题可以得到较好的解决,M 的值在 Mysql 中约为 1200,当层高是 4 的时候最多已经可容纳 17 亿节点了。
B 树与 B+ 树
B树的英文是 Balance Tree,也就是平衡的多路搜索树,用来实现文件系统和某些数据库系统的索引,其结构如下图所示:
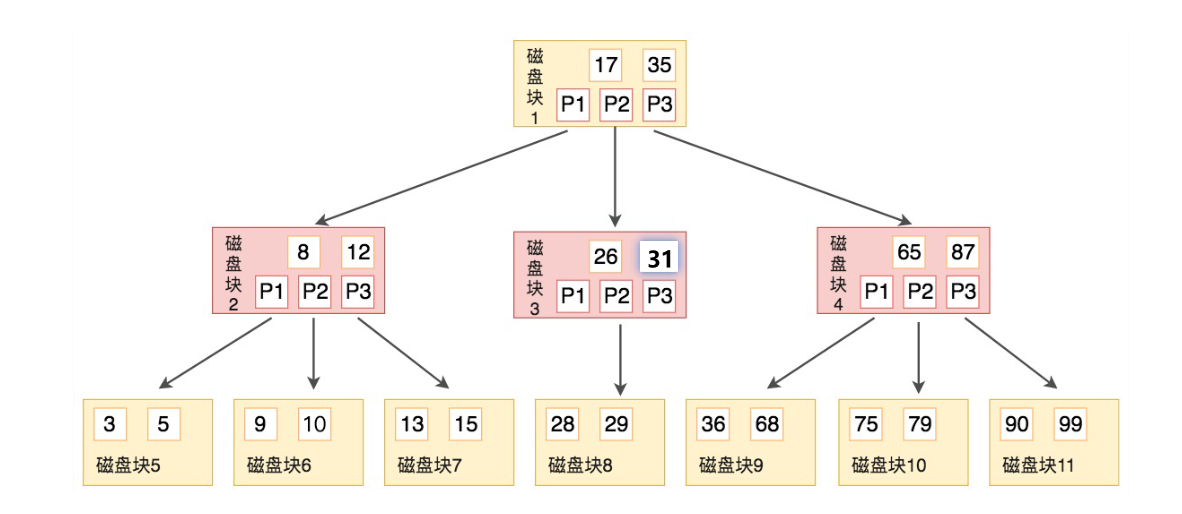
有两个需要注意的地方:
- 孩子的数量最多为当前节点的关键字数+1,即上述图中每个节点关键字2个,则孩子最多3个。
- 非叶子节点出现的关键字在子节点中不再出现。
这两个地方也是 B 树与 B+ 树的重要区别,同时由于这样的实现,因此 B 树的非叶子节点除了包含关键字,还包含关键字对应的数据(如果当前是非主键索引,那么数据就是主键ID)。
B 树其实对于单个查询和范围查找已经支持的比较好了,不过单个查询的耗时不稳定,如果这个关键字在上层,耗时就短;如果随着时间推移关键字移动到了下层,查询时间就长,同时范围查找需要对树进行中序遍历,需要根据上层节点去查询右子树。
B+ 树针对上述场景做了优化,B+ 树把所有的数据都存放在了叶子节点,非叶子节点只存关键字,而且这个关键字一定是所指向子节点的最小值或最大值;B+ 树上所有的叶子节点间使用双向指针连接,在范围查找时可以从任意节点开始往 前/后 遍历。其结构如下图所示:
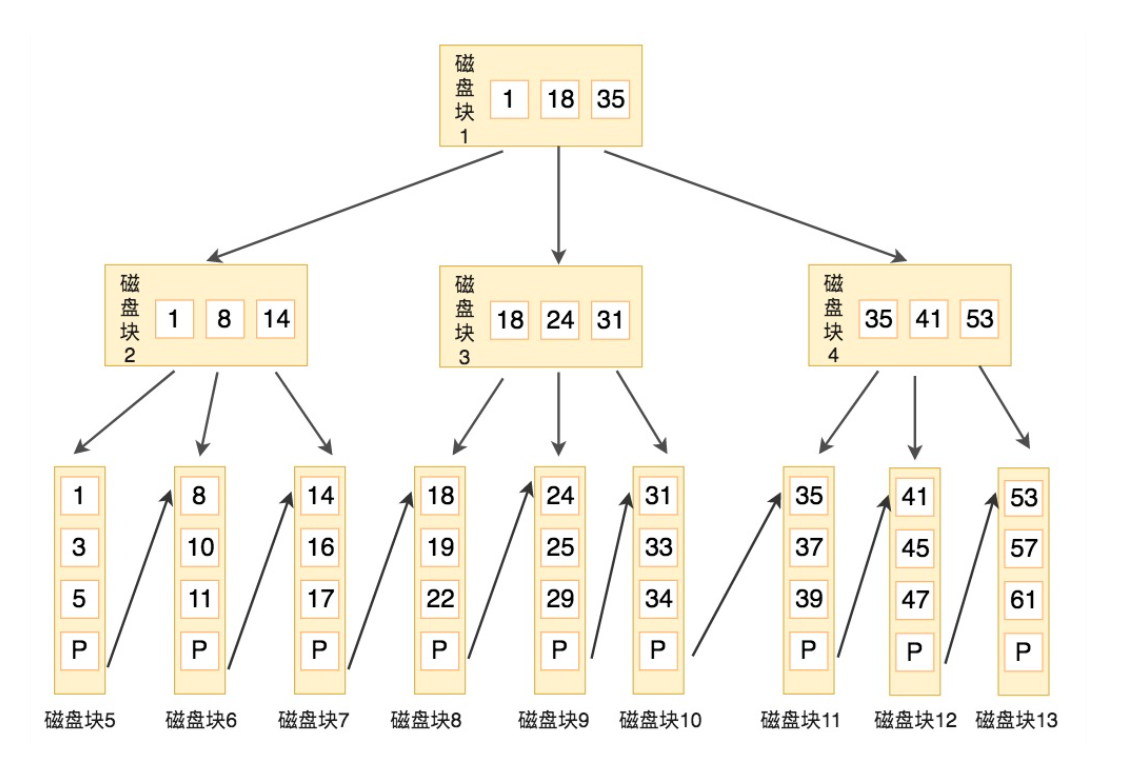
由于非叶子节点只存储关键字而不存储数据,因此 B+ 树比 B 树的非叶子节点能存下更多的关键字,同时由于数据都在叶子节点上,因此查询效率比较稳定。
索引中的节点到底是什么
数据库中的数据是一行一行的,但是数据库的读取是按页为单位的,否则每次 I/O 操作指只能处理一行数据,效率太低了。在数据库中,无论是操作一行还是多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页。
一个 B+ 树的基本结构如下图所示,其实其中的每一个叶节点就是一个数据页。
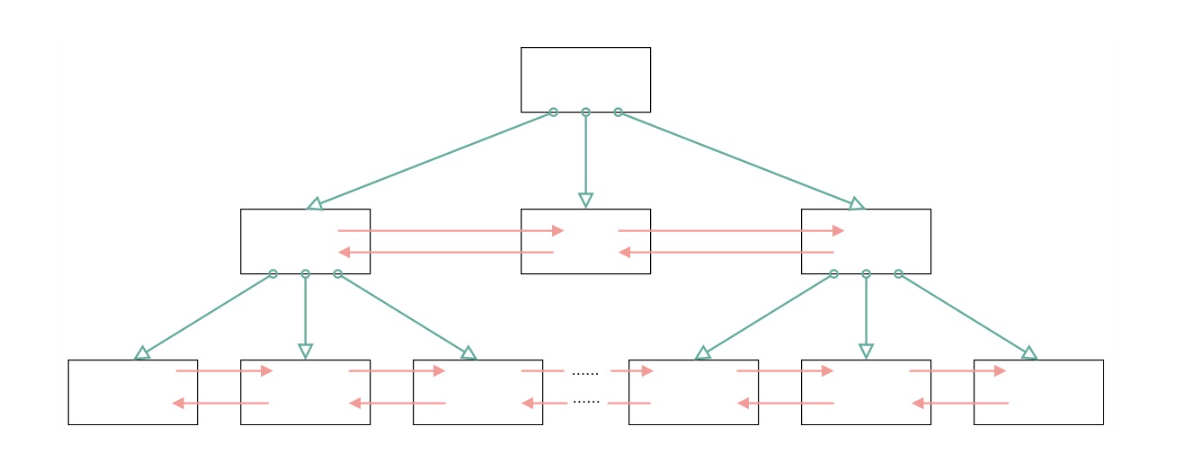
数据页的大小可以使用如下命令查找,Mysql 中默认 16KB
show variables like '%innodb_page_size%';
16 KB实际上仍然会存储上千条数据,如果仅依靠数据之间的链表指针查询仍然需要O(N)的复杂度,Mysql 在数据页的设计中利用槽(slot)进一步优化了这个过程。
Mysql 的页结构如下图所示,其中用户记录部分占了页结构的主要空间。
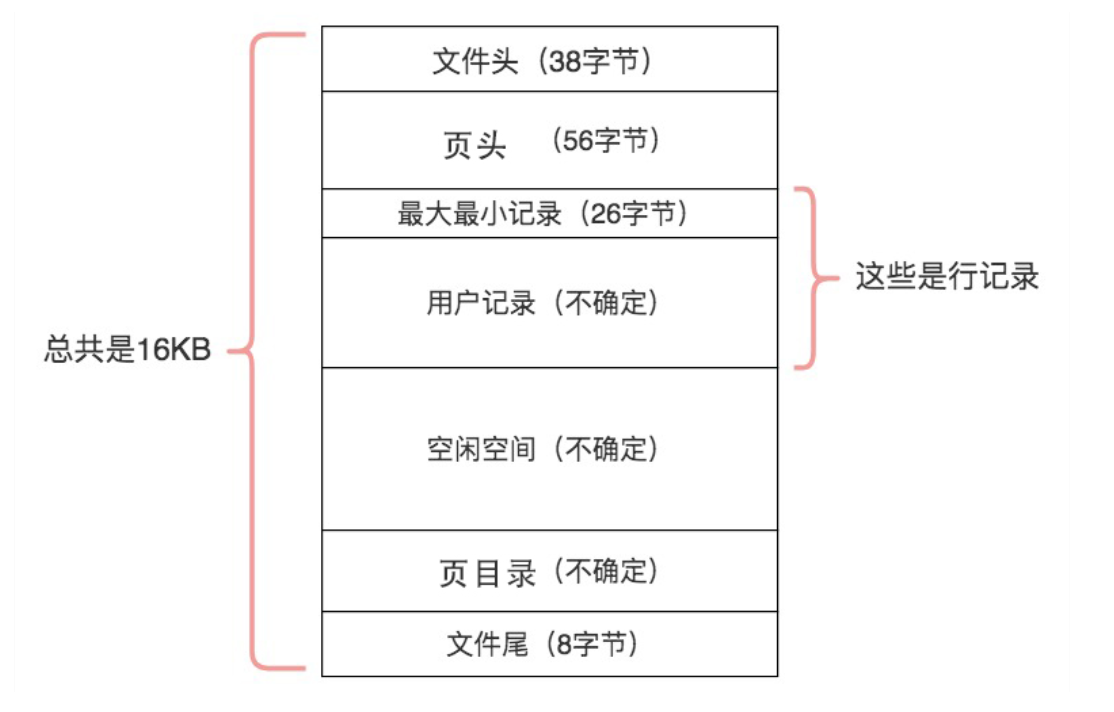
文件头中会有两个指针 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 用来指向上一个数据页和下一个数据页,链表的结构使得数据页之间不需要是物理上的连续。
数据页中的页目录部分,就是业内记录的索引,流程如下:
- 将所有的记录分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录。
- 第 1 组,也就是最小记录所在的分组只有 1 个记录;最后一组,就是最大记录所在的分组,会有 1-8 条记录;其余的组记录数量在 4-8 条之间。这样做的好处是,除了第 1 组(最小记录所在组)以外,其余组的记录数会尽量平分。
- 在每个组中最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段。
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。如下图所示:
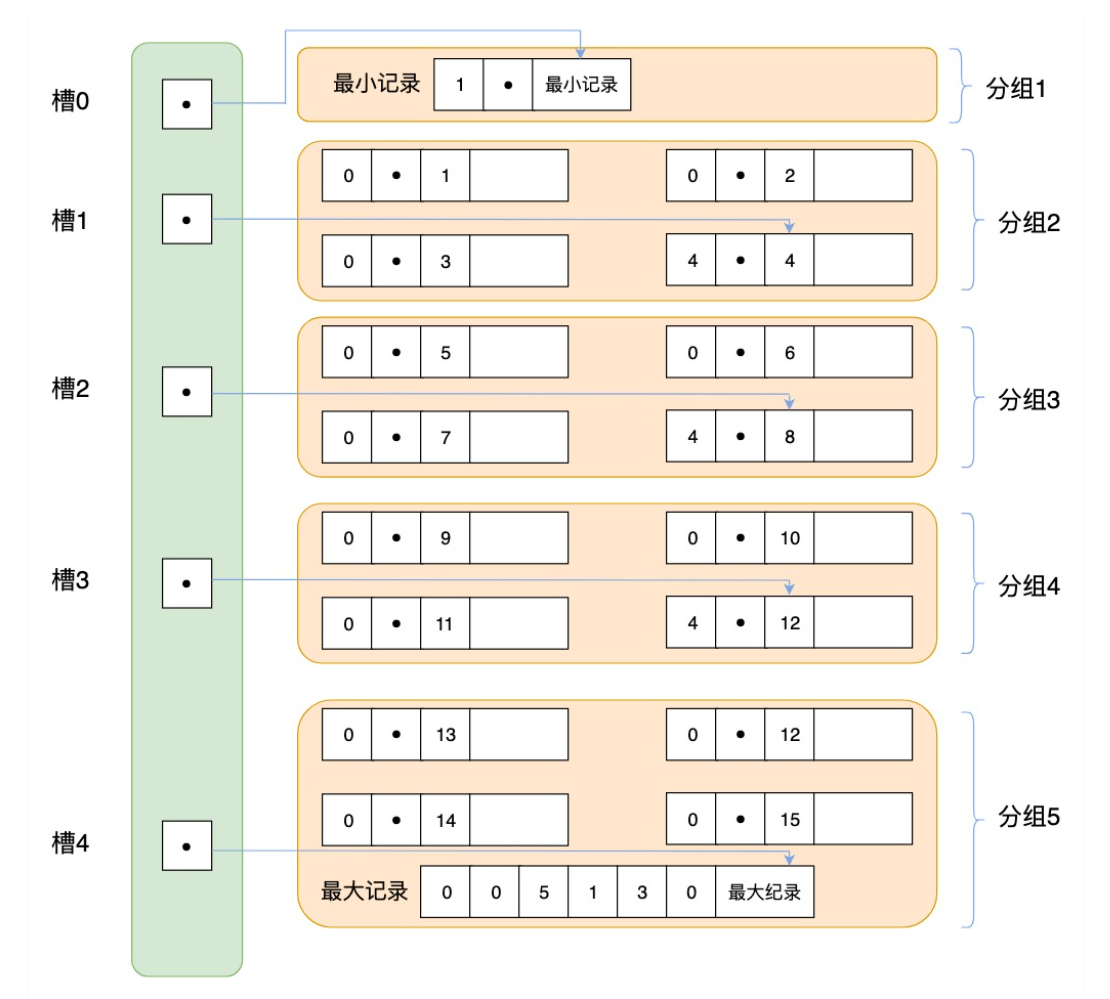
所以查询的全流程是:从 B+ 树的根开始,逐层检索,直到找到对应的叶子结点(即数据页),将数据页加载到内存,再借助页目录内的槽(slot)进行二分查找到一个记录分组,最后在分组中链表遍历查找记录。
一些常见的问题
唯一索引和普通索引对查询效率的影响
唯一索引在最后数据页中找到了一个就直接返回,而普通索引需要向下遍历到第一个不是该关键字的记录,在内存中这样的遍历对性能的影响微乎其微,效率基本没有差别。
索引覆盖
文中提到,非主键索引其实存储了对应的主键,如果最终查询的字段无法在这个非主键索引中得到,需要进行回表(即拿着对应的主键走主键索引查询),而如果查询的字段能拿到,那么就可以直接返回,减少了回表的操作,这就是索引覆盖。例如根据非主键索引查询主键的值就满足索引覆盖。
最左前缀
索引中的联合索引是按照索引字段的顺序建立的,例如联合索引(a,b)在进行 select * from table where b = #{value} 时是没办法使用的,模糊查询也可以用到最左前缀;另外,如果有了(a,b)索引,一般也不需要在 a 上再单独建索引了,所以该原则还可以用来减少索引的数量。
索引下推
例如有一个联合索引(name,age)需要查询 select * from tuser where name like ‘张 %’ and age=10,在 Mysql 5.7 之后,由于联合索引中存在 age,会先根据 age 判断是否 = 10,再进行回表,能够直接过滤出不满足条件的记录,减少回表次数。