小杰-大模型(one)——大模型的概念与历程。
1.了解大语言模型的基本知识
1.1日常可能会用到的大语言模型
下面这个网址汇集了比较经典的各种用途的大模型
https://hot.browser.miui.com/light/ai-tool-collection.html
也包括国外的大模型的网址
https://aigc520.com/
1.2大模型的作用:
使用实际模型生成演示一下(顺便解释一下联网和非联网大模型的不同):
1.文本生成
2.代码编写
3.多模态创作 文生成图像(DALL·E 3)、视频(Sora)、音乐(Suno AI)
4.知识整合与分析
核心价值:将人类从重复劳动中解放,专注于需要创造力、情感和战略思维的工作
2.大模型与人工智能关系
2.1.AIGC、LLM与深度学习等的关联

2.2.AIGC(AI生成内容)和LLM(Large Language Model,大语言模型)
2.1定义与范围
AIGC:指利用人工智能技术自动生成的各种形式的内容,包括文本、图像、音频、视频等。
LLM 特指基于大规模文本数据训练的、以生成自然语言文本为核心任务的模型。
AIGC涵盖多种AI技术,如扩散模型(Diffusion Models)、大语言模型(LLM)等。
LLM也不是全部属于AIGC,例如Google的Bert是大语言模型(3.4亿参数),但是擅长的是协助Google检索和情感分析而非生成。
总结:LLM与AIGC是交集关系。
3.大模型的基础原理
3.1大语言模型的基础 - 前向过程
大模型的前向过程和深度学习前向过程的基本法则一样。
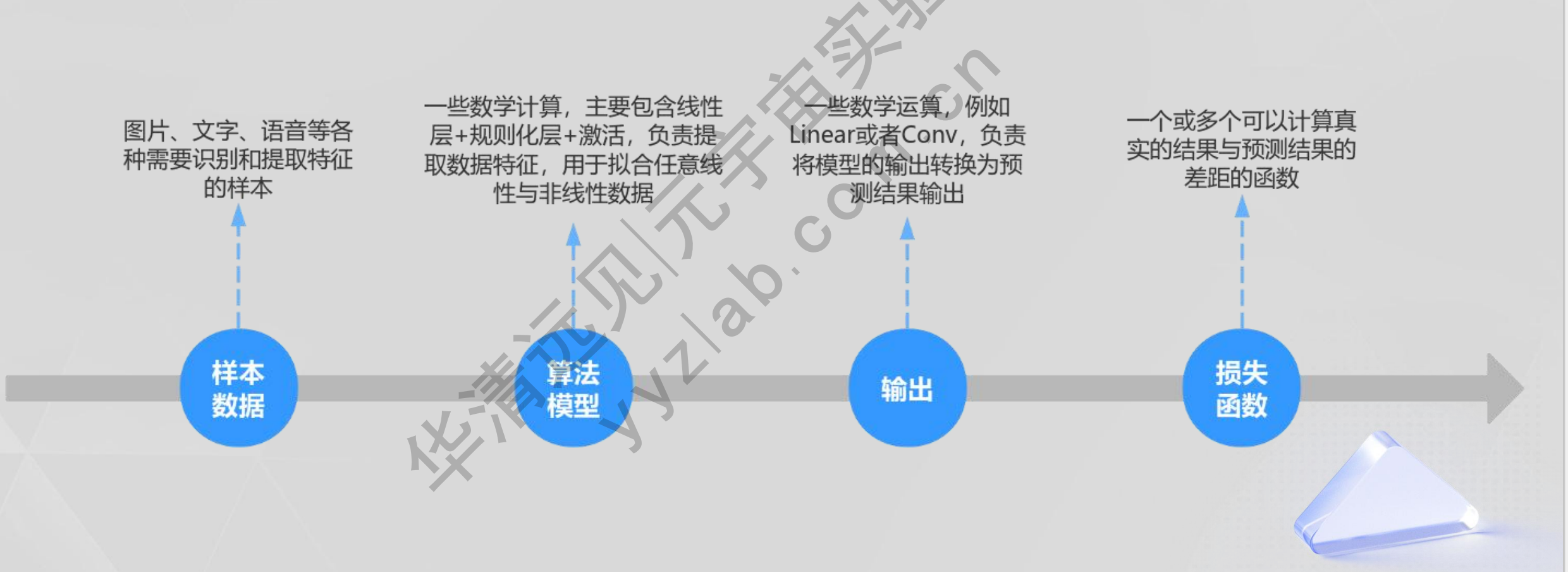
3.2大语言模型的基础 - 反向过程
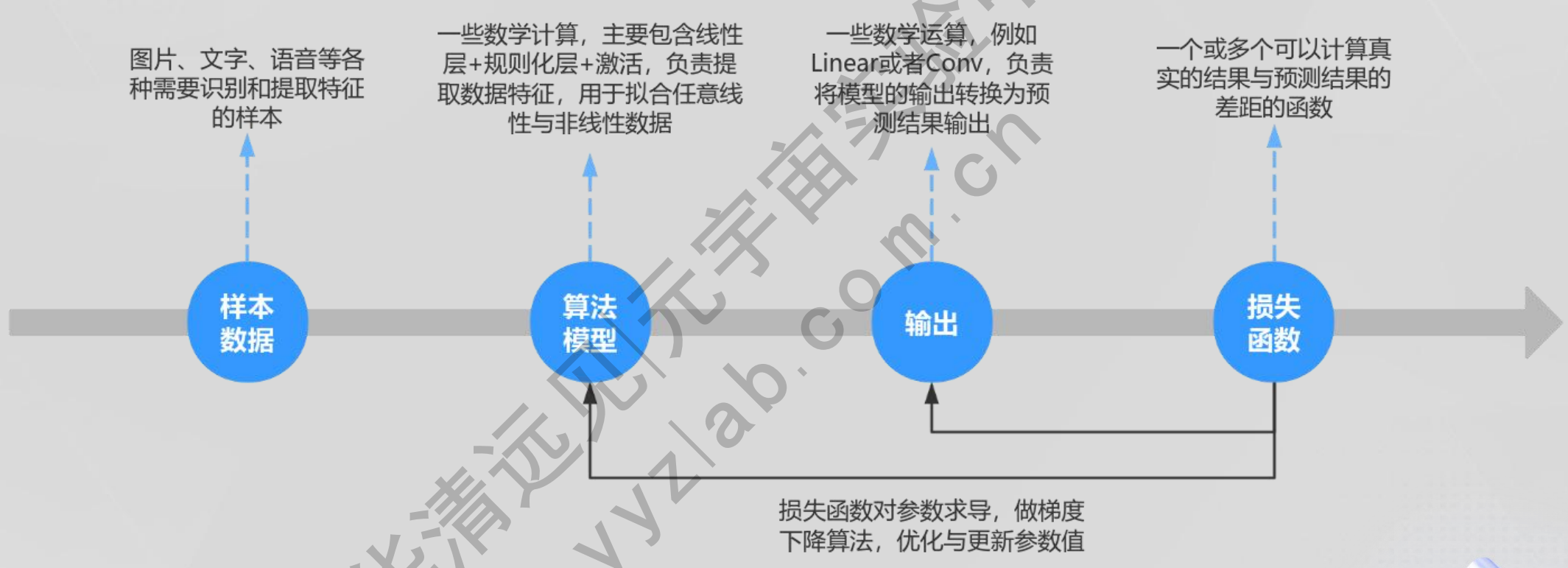
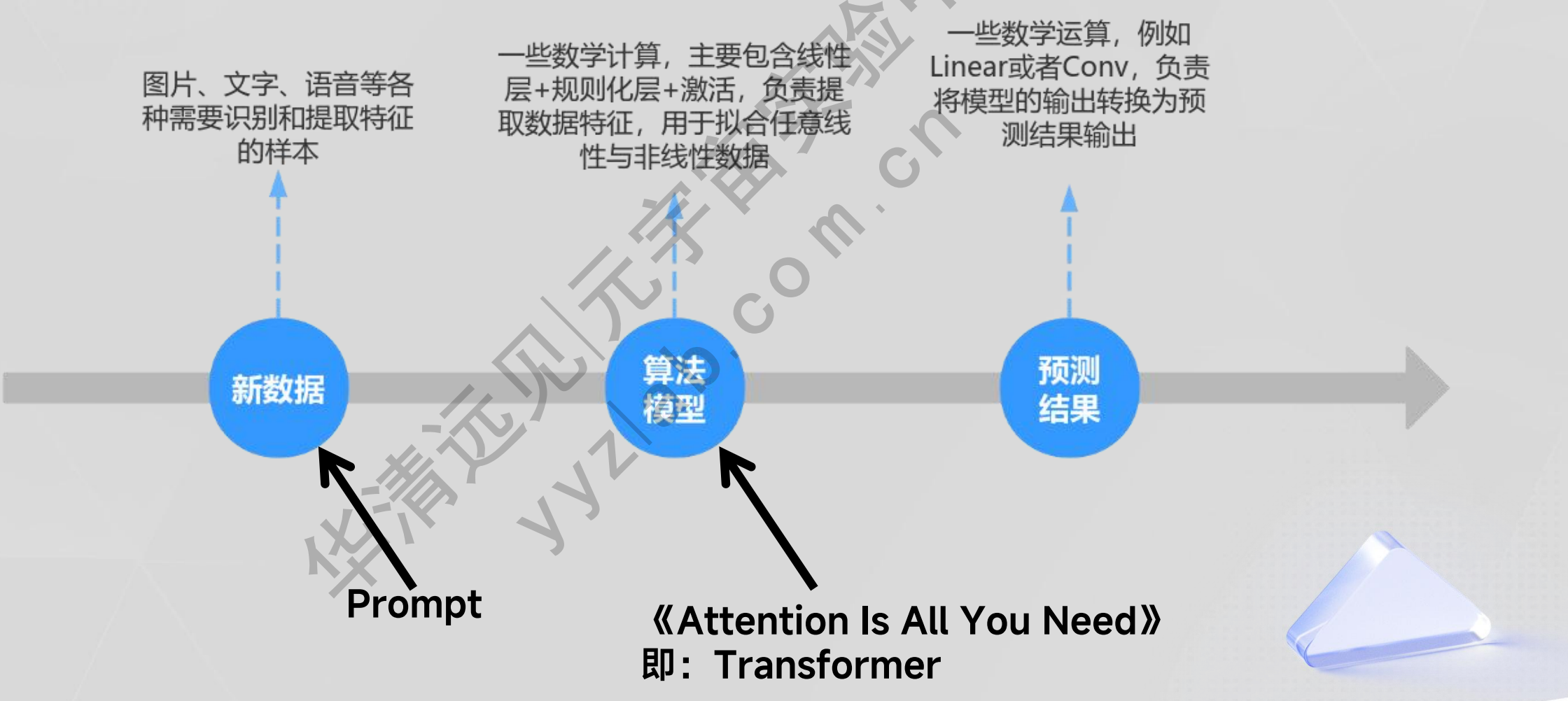
3.3大语言模型的基础 - 预测过程
3.4 自然语言的特点与RNN的简单原理
3.4.1文本特点-RNN的处理方式
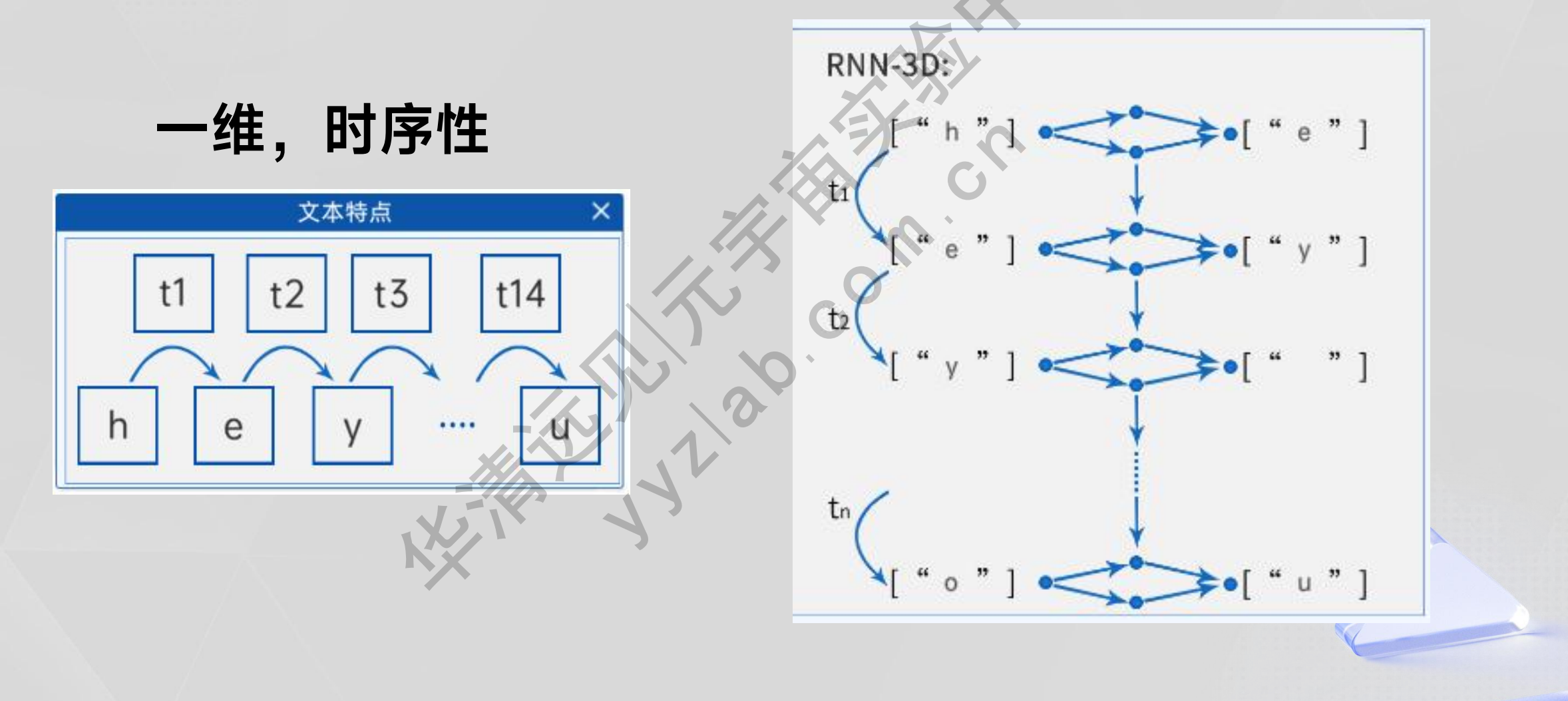
3.4.2 RNN的缺陷
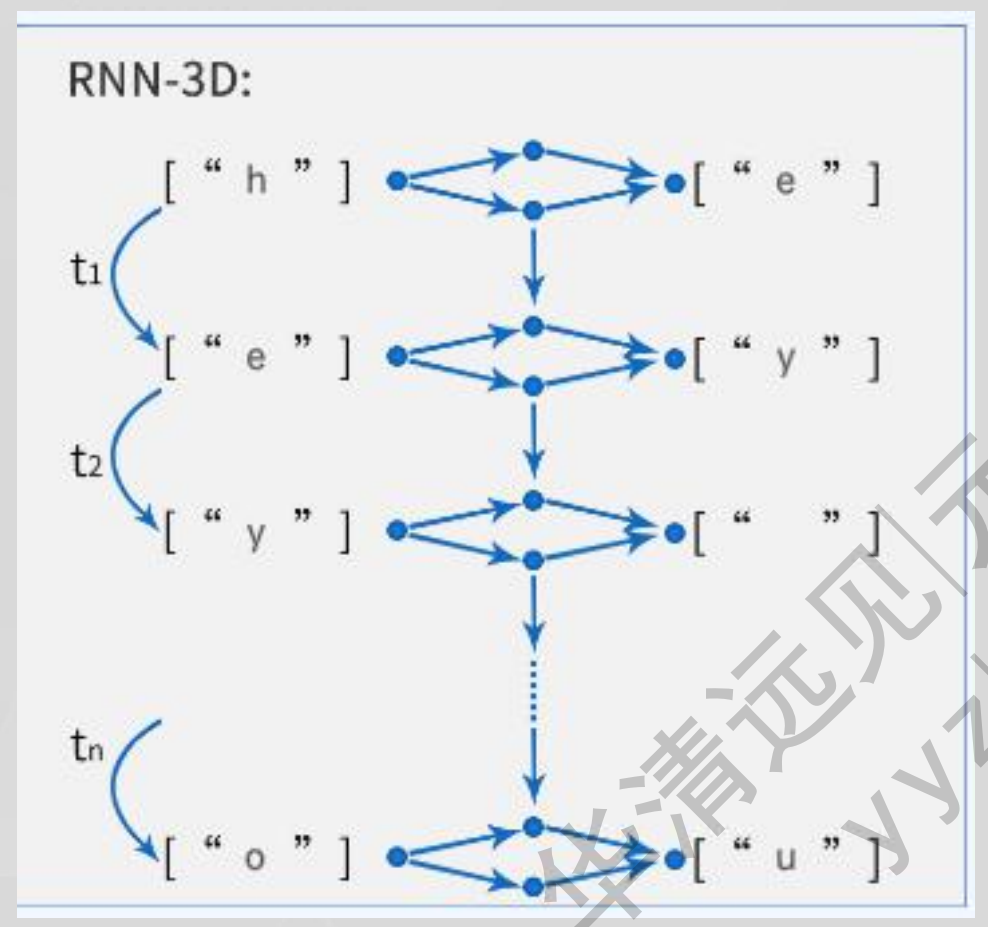
RNN网络的输出具有先后顺序性: 每一步运行输出取决于当前的输入与先前的隐藏状态,上一步执行完,才会执行下一步,无法并行计算。
RNN记忆丢失: 先前的隐藏状态越往后,越记不住更早的记忆,会造成记忆丢失,导致没办法处理长文本,无法捕获长距离的语义关系。
虽然LSTM/GRU的出现缓解了第二个问题,但在超长序列(如>1000步)中,信息仍会逐步衰减。
3.5 Transformer与RNN的核心优势对比
3.5.1 Transformer结构
目的:学习所有词的相关性和上下文 特征。
为什么能学习?
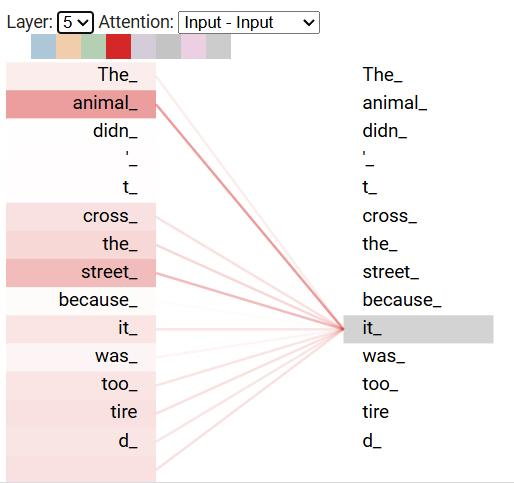
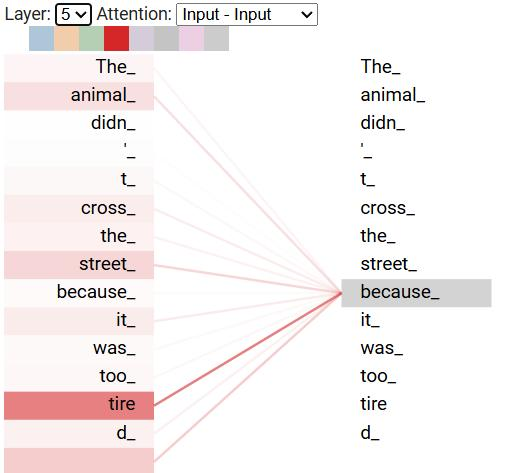
引入自注意力机制:Transformer在处理上下文的时候,不仅会注意到它自己的词和附近的词,还会注意到序列里其他的词,并为其赋予不同的权重。 所以能够拿到每一个词与其它所有词的相关性,所以与距离无关,如下图所示。
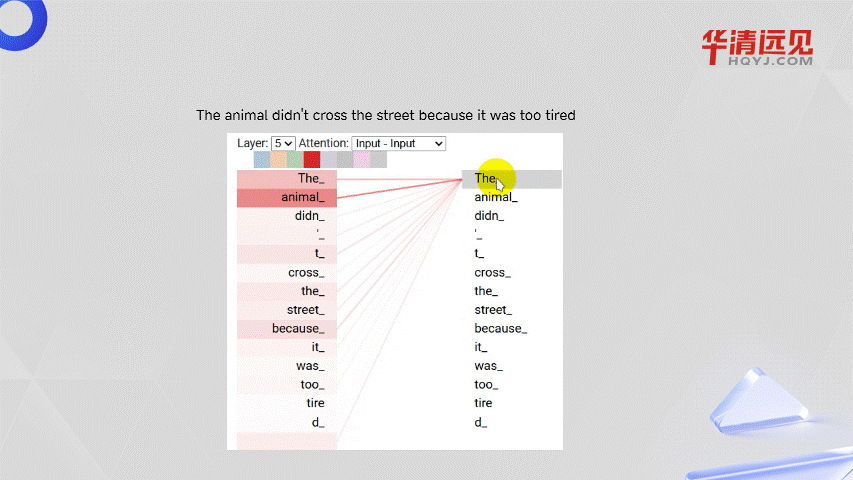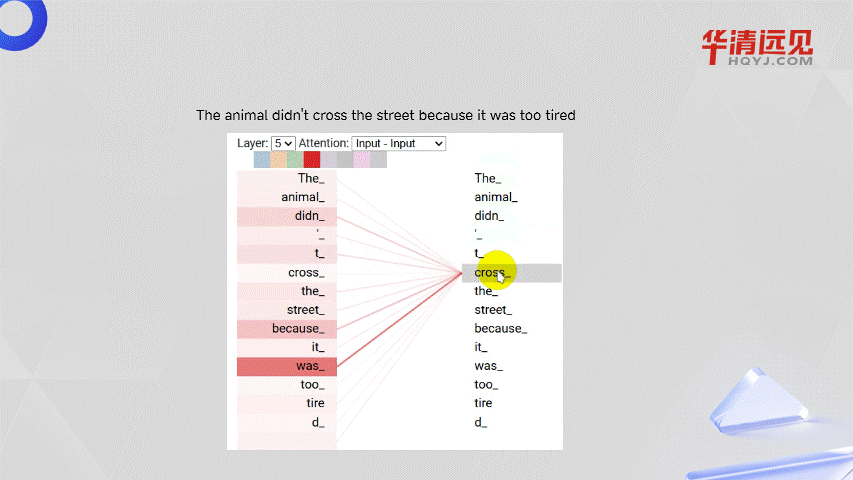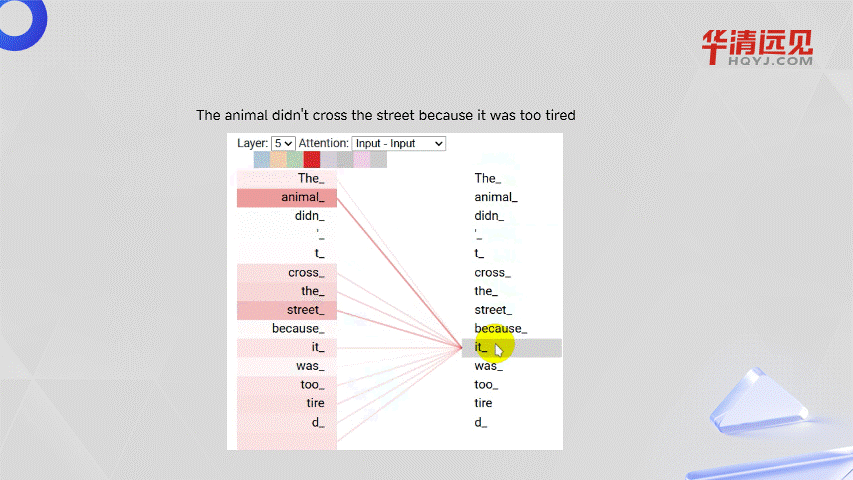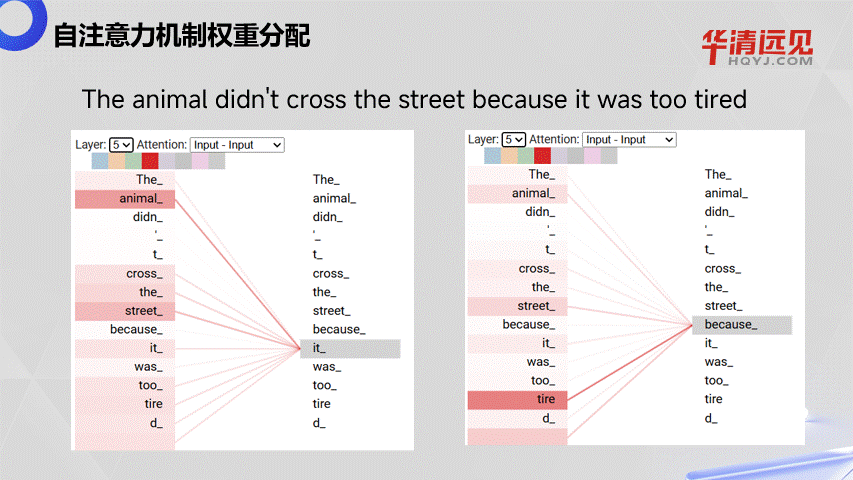
3.5.2 自注意力机制权重分配
The animal didn't cross the street because it was too tired
用更高维表示,比如三维:
所以7419可能是[1.2, 2.4, -0.1]:
[1.2, 2.4, -0.1]来源于神经网络的输出(y=wx+b)
实际Embedding使用中会把特征转化成64维或者128维。
3.5.3 Transformer结构
1.Transformer结构组成:
1.位置编码
2.Embedding词嵌入
3.编码器Encoder
4.解码器Decoder
Attention Is All You Need 论文架构如下图
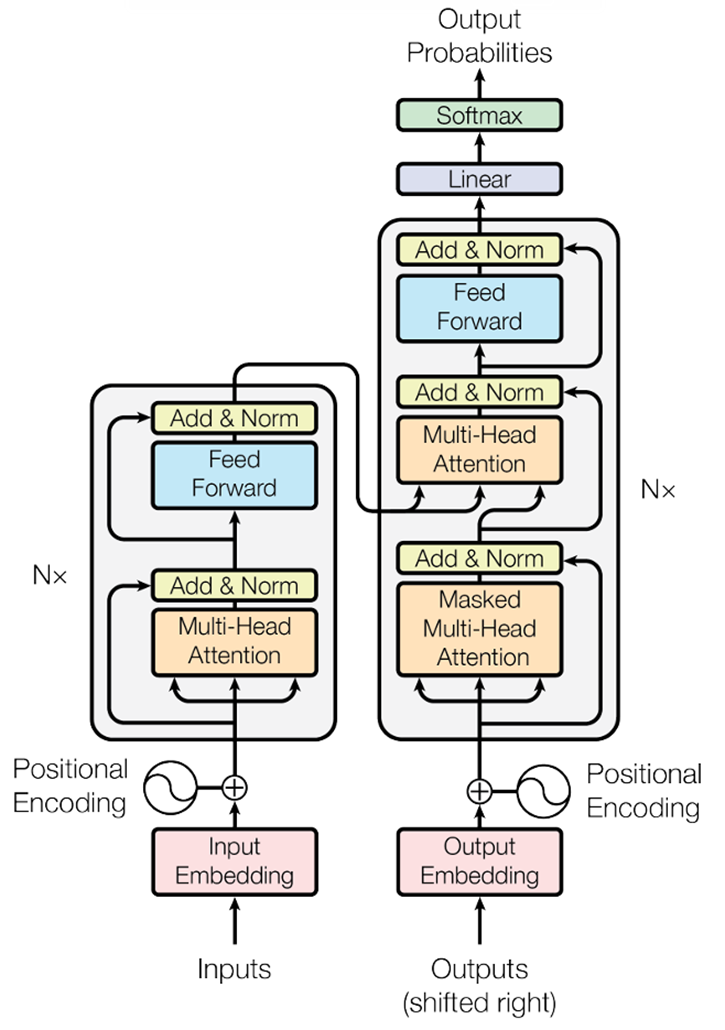
2.位置编码与Embedding词嵌入
为啥要添加位置编码?
当两段话中词一样,但是顺序不同,也会导致两句话表达信息完全不同。
我爱你们俩 VS 我们爱你俩
那么Transformer怎么处理这么问题的呢?
输入:文本 -> token -> token ID(数字) -> Embedding向量
Embedding是啥?
全称Word Embedding。
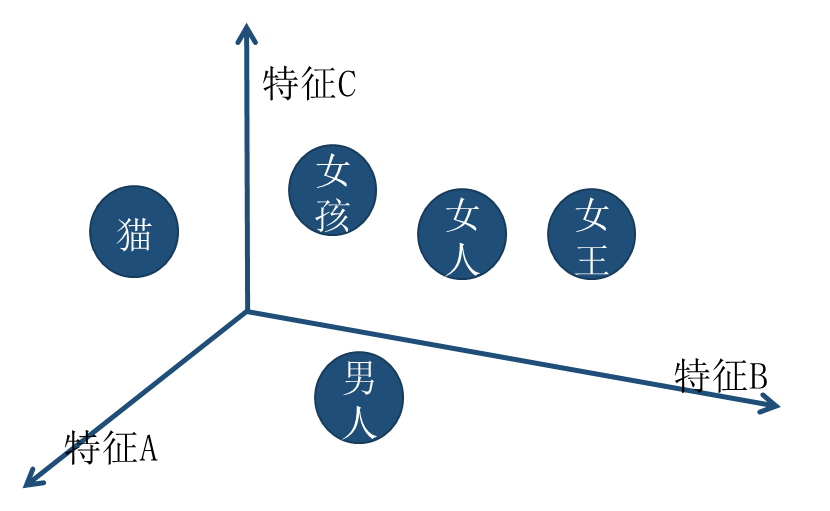
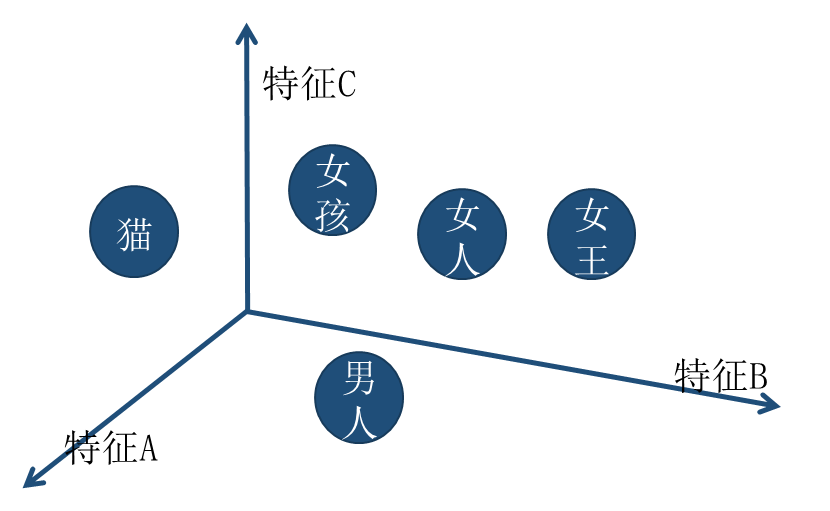
有两个词:男人(token ID:7419)、女人(token ID:1039)。
如果由数字表示(一维的坐标轴),那么他们的距离应该是近还是远?

用更高维表示,比如三维:
所以7419可能是[1.2, 2.4, -0.1]:
[1.2, 2.4, -0.1]来源于神经网络的输出(y=wx+b)
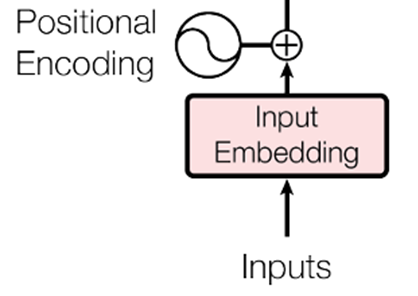
实际Embedding使用中会把特征转化成64维或者128维。
如下图,输入经过Embedding层转化成输出和位置编码进行融合
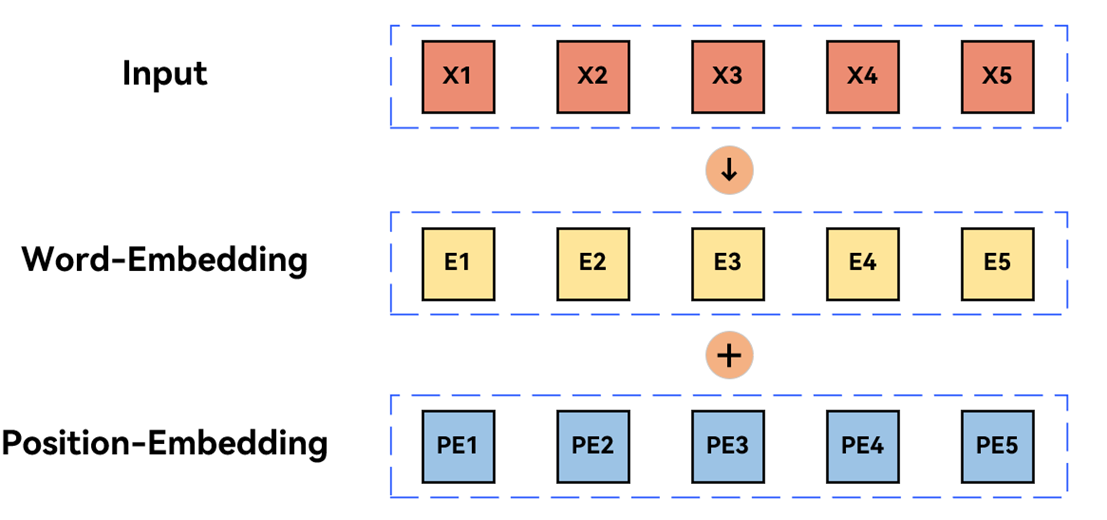
input 与RNN相比,不需要其它位置的计算结果,可以同时计算,类似并发操作。
并发操作实现方式:Embedding向量 + 位置的向量。
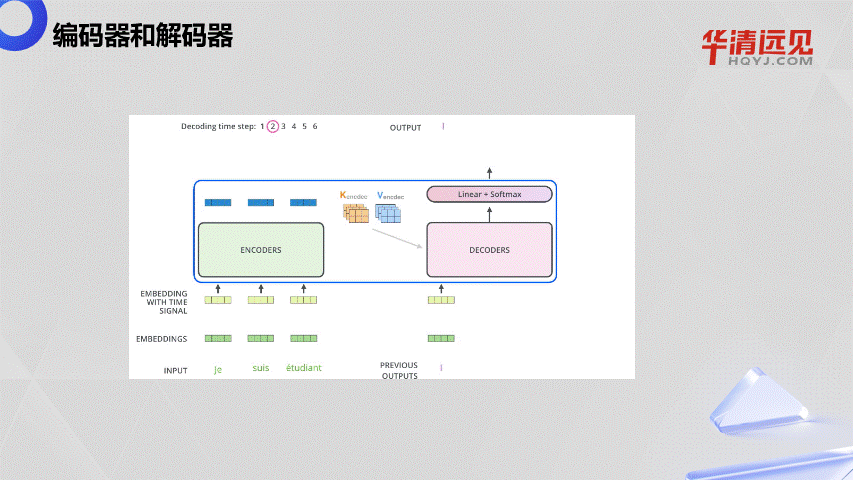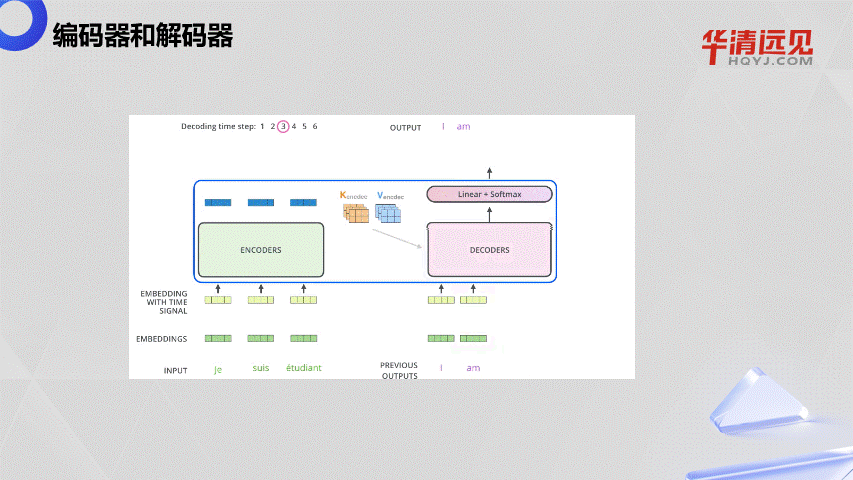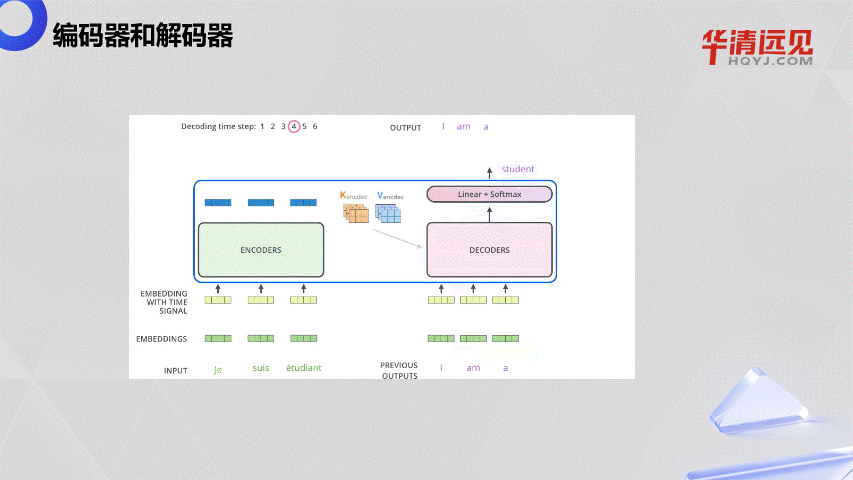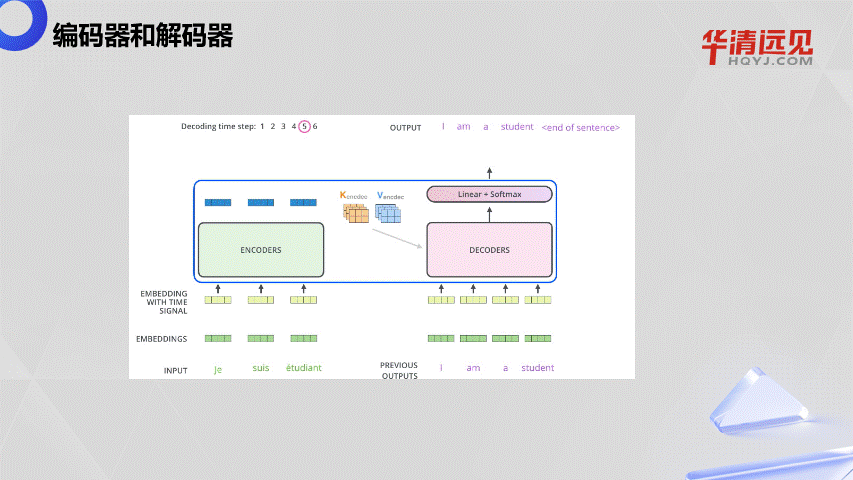
3.编码器Encoder与解码器Decoder
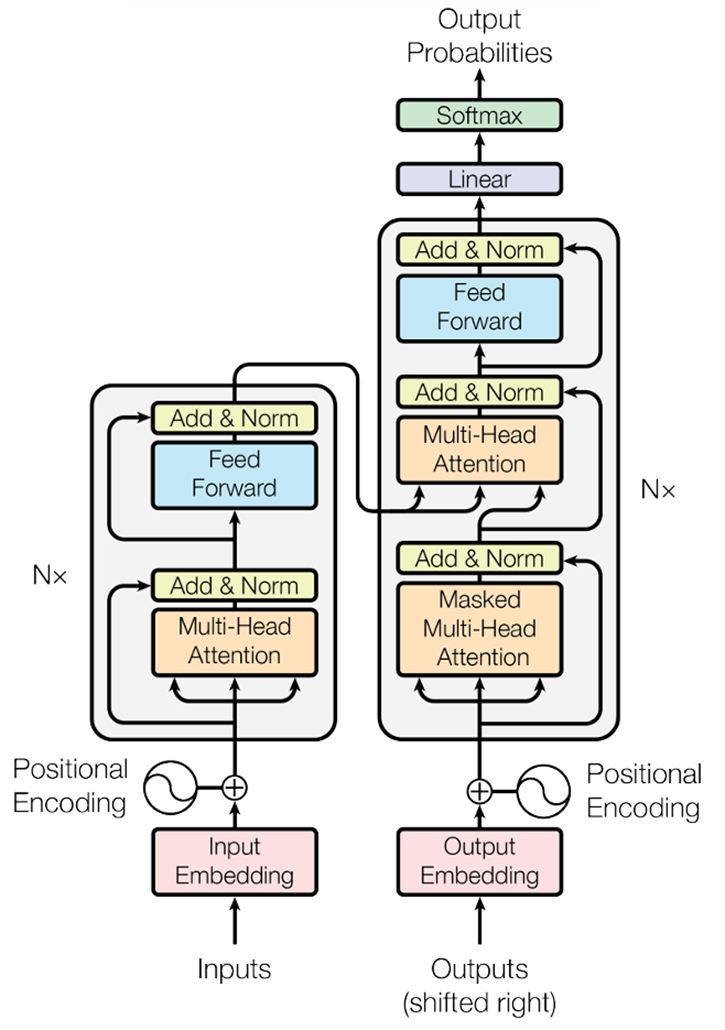
3.1以翻译为例解释 编码器和解码器
编码器Encoder:负责将输入序列(如句子)转换为包含上下文信息的特征表示。
解码器Decoder:解码器不仅需要理解输入序列的上下文,还要逐步生成输出序列。注意:1.刚开始是<sos>(Start of Sequence,序列开始标记)是一个特殊的控制符号,用于指示生成的开始。2.生成的token后面要输出的内容不能提前获取。3.<eos>(End of Sequence,序列结束标记)是一个关键的控制符号,用于表示序列的终止。
示意图如下图所示
4.大语言模型的“前世今生”与发展
4.1大语言模型的发展
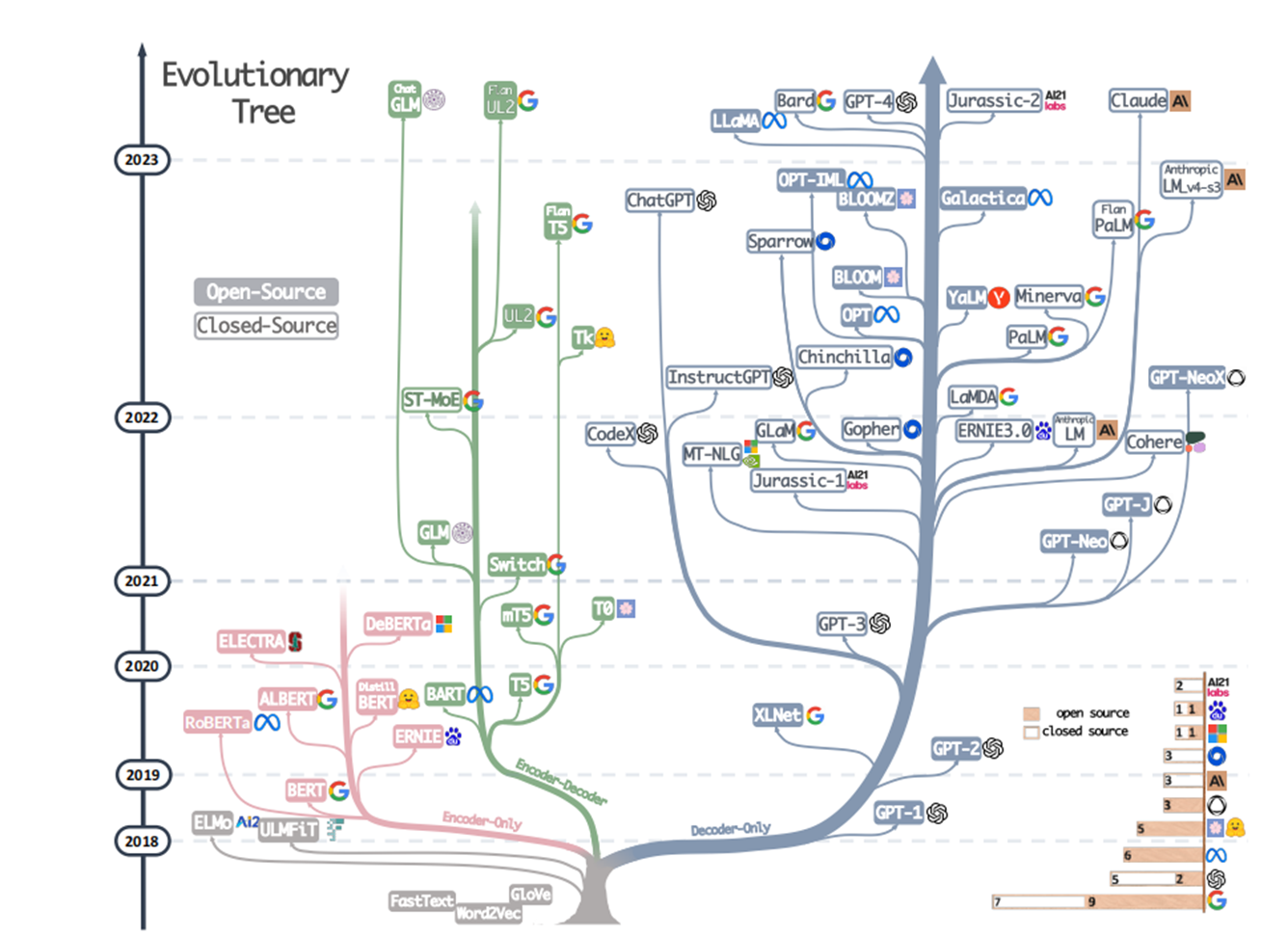
1.GLM(General Language Model)是由清华大学和智谱AI(Zhipu AI)联合研发的大规模预训练语言模。
2.BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的预训练语言模型
3.T5(Text-to-Text Transfer Transformer)是Google于2020年提出的统一文本生成框架
4.GPT(Generative Pre-trained Transformer)是由OpenAI研发的一系列自回归语言模型
4.2大模型的几个发展阶段
大模型发展包括以下5个阶段,前三个阶段确切不能说大模型,但解决任务是类似的:
1.基于规则的模型
2.基于统计的模型
3.神经网络的模型
4.基于预训练的模型
5.基于大规模的模型
1.基于规则的模型
原理:通过人工编写的语法规则和词典
缺点:只能处理少量数据和简单任务
应用场景:机器翻译和信息检索
2.基于统计的模型
原理:使用数学统计的方法来预测词序列的概率
优势:可以处理更多的数据和复杂任务
缺点:存在数据稀疏和历史长度限制的问题
代表模型:N-gram
应用场景:语音识别和文本摘要
3.神经网络的模型
原理:使用神经网络的方法来学习词的分布式表示和语言的内部结构
优势:可以处理更大的数据和更难的任务
缺点:存在计算资源和训练数据的限制
代表模型:RNN、CNN、LSTM等
应用场景:情感分析和对话系统
4.基于预训练的模型
原理:利用海量的无标注文本进行自监督学习,然后在特定的任务上进行微调
优势:可以处理更多的任务和领域
缺点:存在泛化能力和安全性的问题
代表模型:BERT、GPT
应用场景:问答和知识图谱
5.基于大规模的模型
原理:使用大规模的方法来构建包含数百亿以上参数的深度神经网络模型,使用更多的无标注文本进行自监督学习
优势:可以处理更多的任务和领域
缺点:存在计算成本等问题
代表模型:GPT-3、PaLM(深度解析)
应用场景:生成和推理
5.巨头们的PK-国外
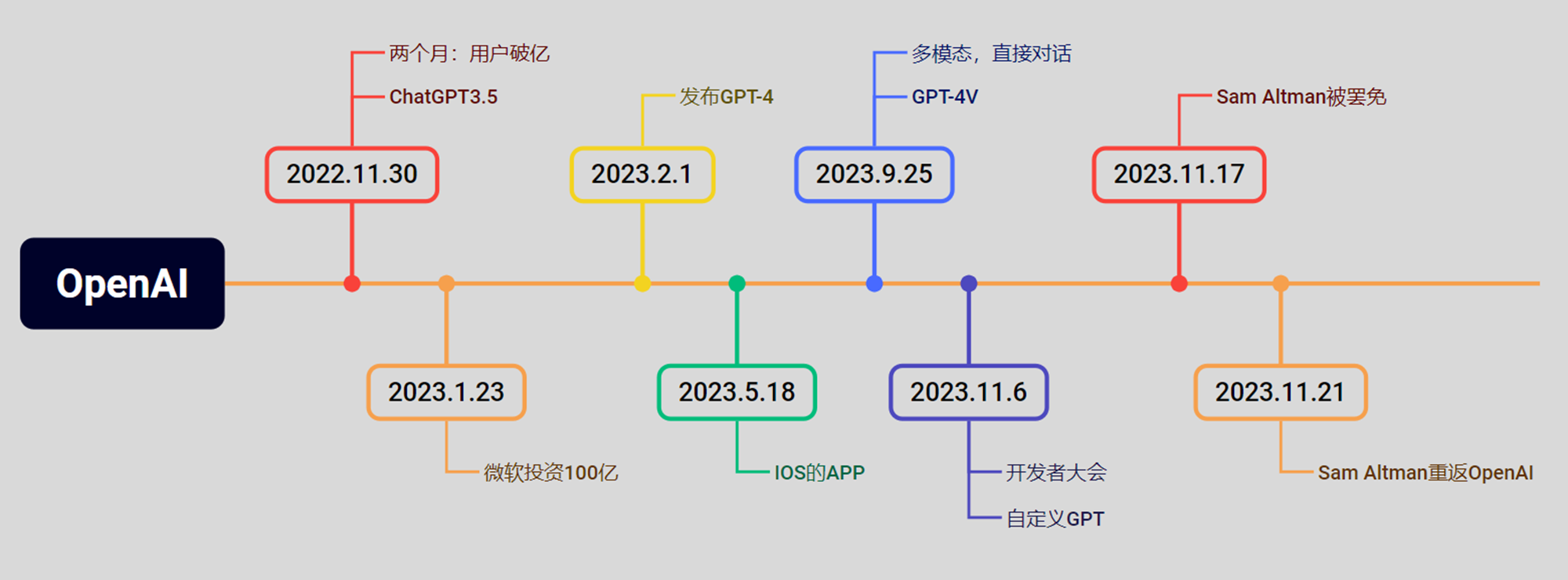
5.1 OpenAI
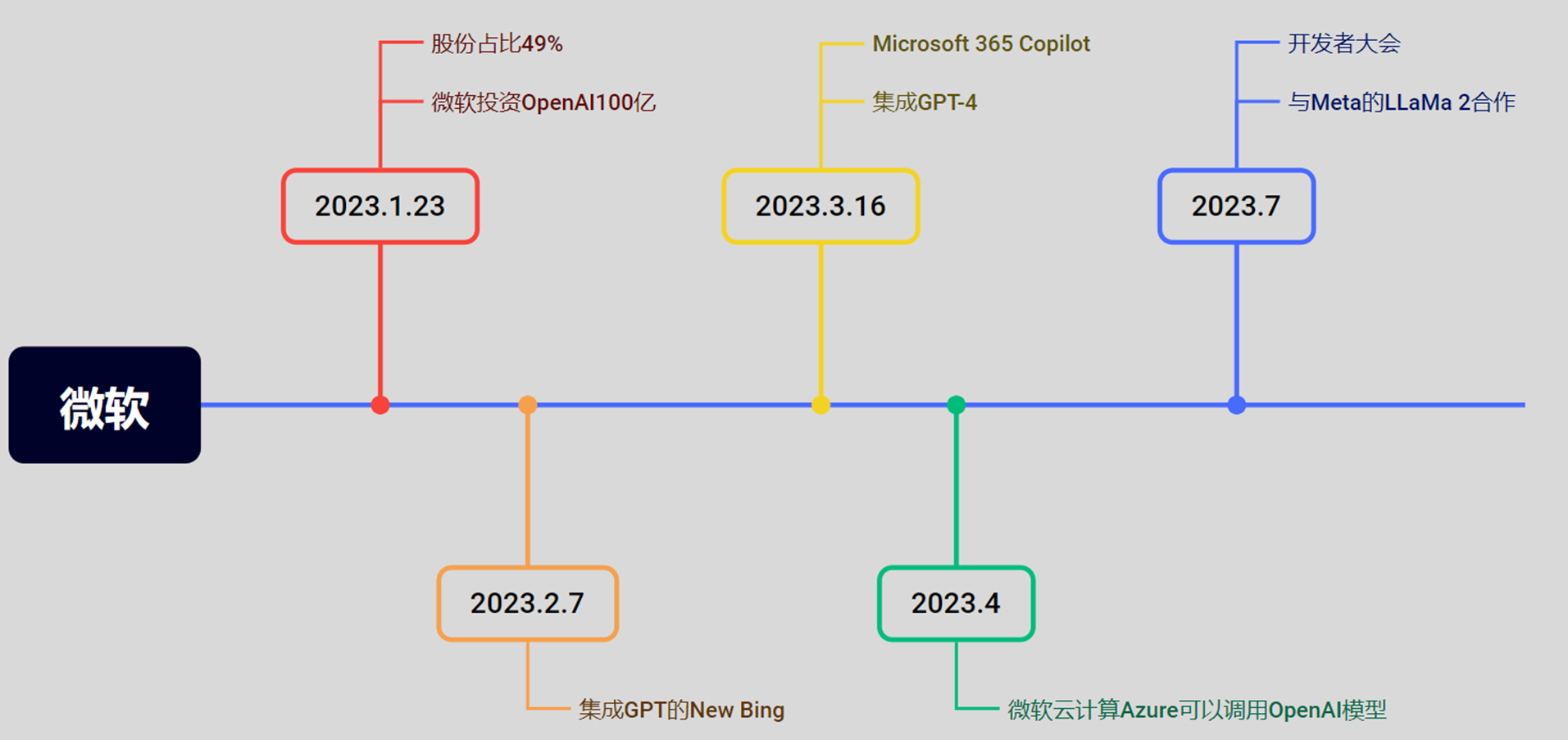
5.2 微软
5.3 谷歌
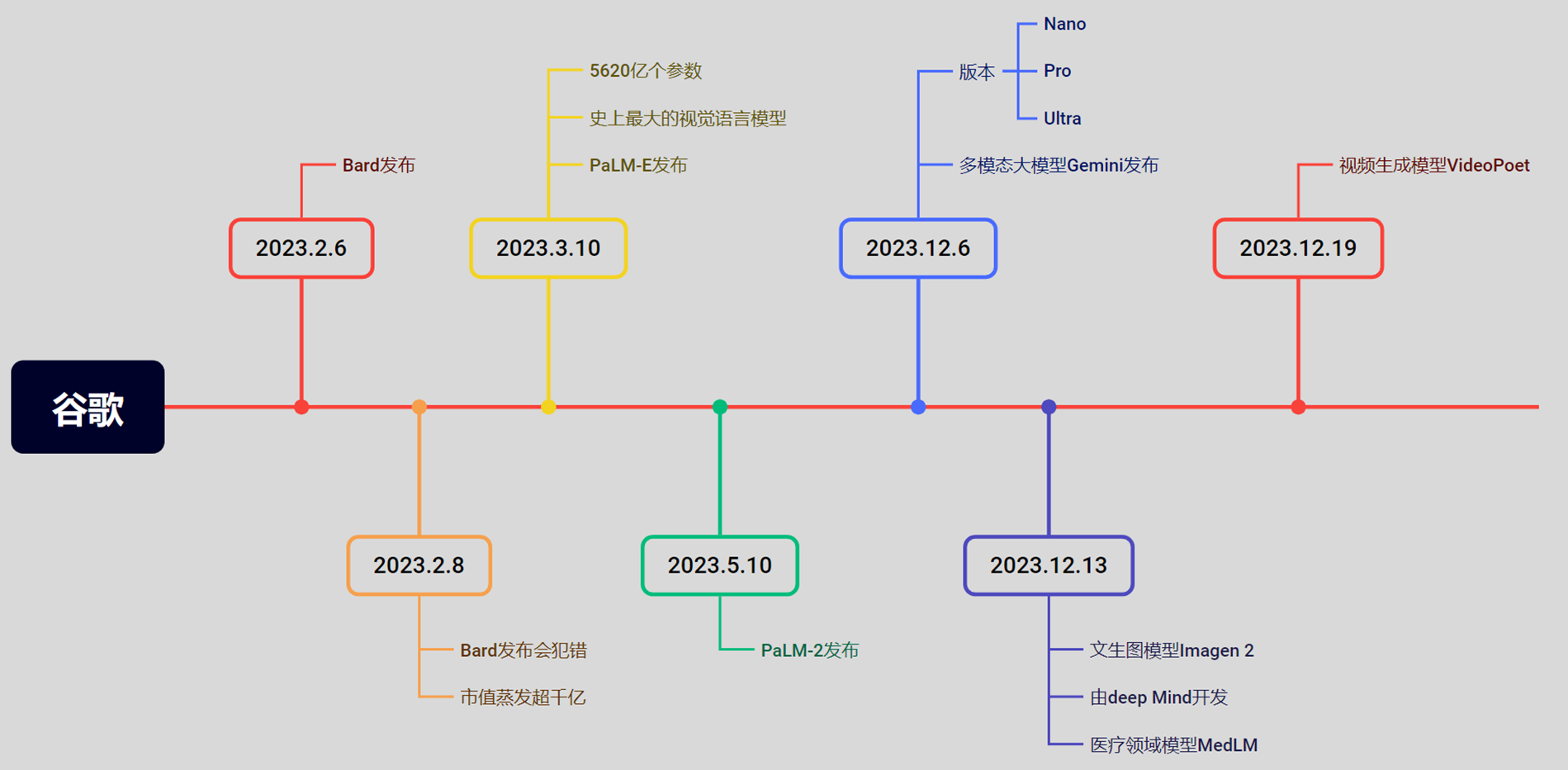
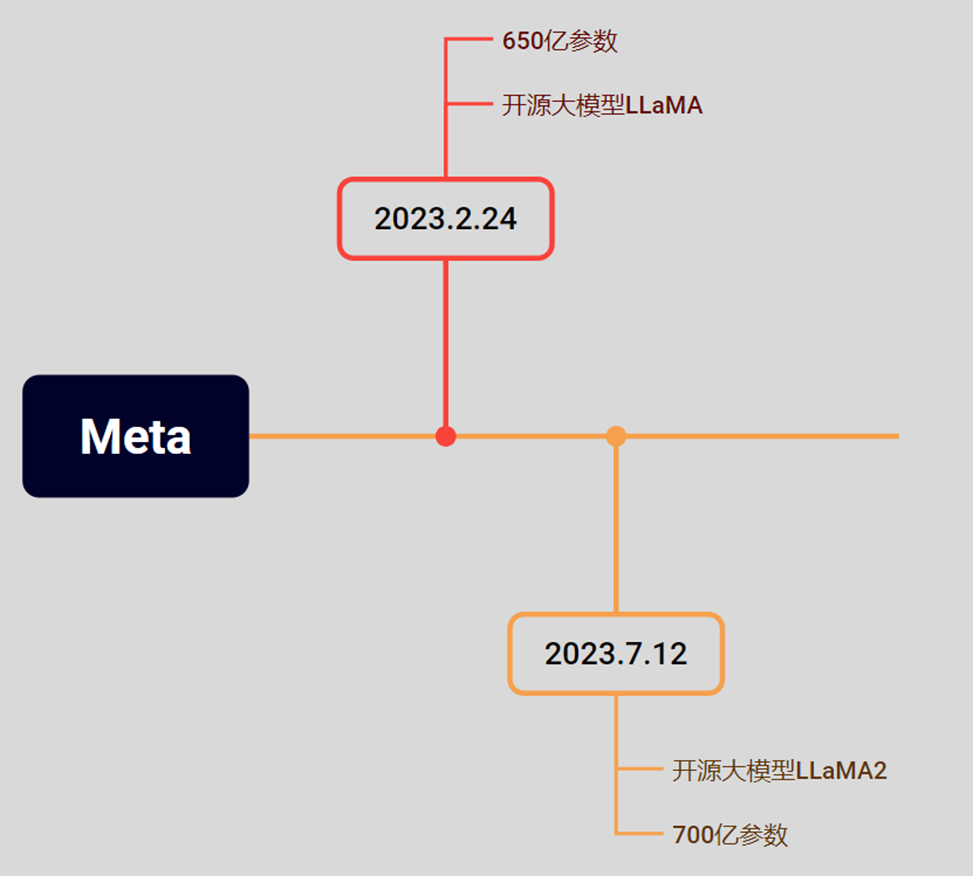
5.4Meta
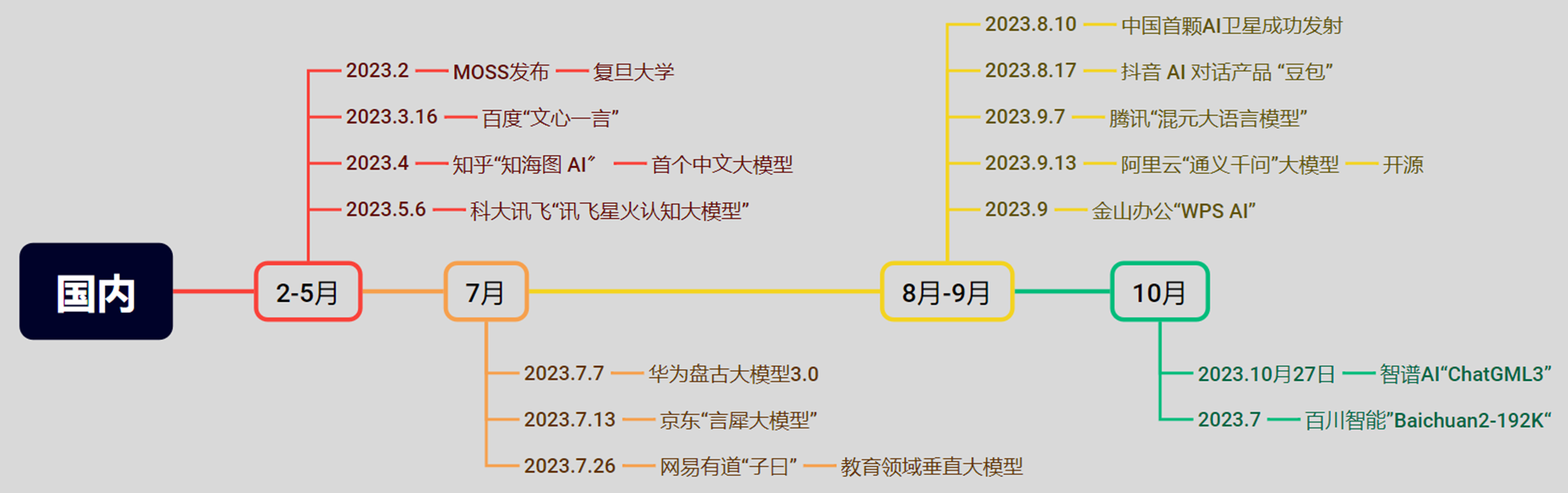
6.巨头们的PK-国内
当然现在还有deepseek
7.AI时代的最大赢家


8.LLM中预测过程与提示工程
Chain-of-thought prompt: 思维链Prompt
大模型(在2023年12月前)在数学上表现的并不是非常优异,但是在展示了推理步骤后,AI模仿推理步骤,从而加强结果准确性。
问题:小明有5个苹果,吃了2个,又买了8个,现在有多少个苹果?
分步解答:
1. 初始数量:5个
2. 吃掉后剩余:5 - 2 = 3个
3. 购买后总数:3 + 8 = 11个
答案:11 1.4思维链Prompt简化
通过让大模型“Let's think step by step”来逐步解决较难的推理问题。
→ 计算距离 = 速度 × 时间
→ 120 × 2.5 = 300
→ 答案:300公里
1.5“角色扮演”Prompt
Role prompt: 与大模型玩“角色扮演”游戏。
比如:
格式:你是一位[职业],具有[年限]经验,擅长[领域]。请以[风格]回答以下问题:[问题]
示例:你是一位资深中医师,有20年临床经验,擅长食疗养生。请以通俗易懂的方式回答:
"秋冬季容易咳嗽,有哪些润肺的日常食物推荐?"
输出:梨、银耳、百合、白萝卜等。