字符串字典树-依依的瓶中信
问题描述
依依是一个住在海边小镇的女孩,她的朋友们分散在世界的各个角落。他们有一个特殊的传递信息的方式,那就是通过海洋传递瓶中信。每个瓶中信里,都装着一串由小写英文字母组成的信息,代表一个友情的密码。
这个夏天,依依在海滩上捡到了 N 个瓶中信,每个瓶中信里都有一条由小写英文字符组成的信息,这些信息分别来自她的 N 个朋友。我们记第 ii 个朋友的信息为 Si,其中 i=1,2,...,N。
为了找出与自己最有缘分的朋友,依依决定比较这些信息的相似度。这里的"相似度"指的是两条信息从头开始,最长能够匹配的字符数量。
注意,依依并不想比较一条信息与它自身的相似度。
现在,依依希望你能帮助她找出对于每条信息 Si,哪条信息与其最相似,即从开头开始,最长能连续匹配的字符的数量是多少。
输入格式
输入的第一行包含一个整数 NN(1≤N≤104)。
接下来的 NN 行,每行包含一个由小写字符构成的字符串 SiSi,表示小蓝的一个朋友在信封里刻写的信息。保证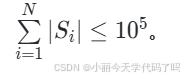 。
。
输出格式
输出共 N行,对于每条信息Si,输出一个整数,表示与 Si 最接近的信息的最长公共前缀的长度。
样例输入
3
abc
ab
bc
样例输出
2
2
0解题代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
string s[N];//存储n个信息s
int tire[N][27],idx=2,cnt[N];
void insert(string a){ //生成一个tire树,把所有s都插入到树中
int n=a.length()-1;//在 C++ 的 std::string 中,a[i] 不会自动包含 '\0'。
int x=1;
for(int i=1;i<=n;i++){
if(!tire[x][a[i]-'a']) tire[x][a[i]-'a']=idx++; //如果不存在的话就创建这个节点
x=tire[x][a[i]-'a']; //这个是让x指向当前节点
cnt[x]++;
//让每个走过当前节点都用cnt记录下来并自加
//这个是关键,当cnt[x]>1的时候说明这个节点至少有两个字符串是走过这里的
}
}
int check(string a){
int n=a.length()-1;
int x=1;
int ans=0;
for(int i=1;i<=n;i++){
x=tire[x][a[i]-'a'];
if(cnt[x]!=1){//当cnt[x]不等于1的时候说明此时的s[i]肯定有一个s的前s[t]和s[i]的前i是相同的
ans=i;//当存在s[t]和s[i]相同的时候就让ans=i,i是相同的字符的个数
}
else break;//如果cnt[x]==1说明没有与之匹配的串了,直接退出返回当前的ans就行
}
return ans;
}
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
cin>>s[i];
s[i]='0'+s[i];
insert(s[i]);
}
for(int i=1;i<=n;i++){
cout<<check(s[i])<<"\n";
}
return 0;
}解题思路:
-
字典树(Trie):
-
使用字典树存储所有字符串的前缀信息。
-
字典树的每个节点表示一个字符,从根节点到某个节点的路径表示一个前缀。
-
-
统计前缀出现次数:
-
在插入字符串时,记录每个节点被访问的次数(
cnt[x]++)。 -
如果某个节点的
cnt[x] > 1,说明至少有两个字符串共享这个前缀。
-
-
查询最长公共前缀:
-
对于每个字符串,从根节点开始遍历字典树,找到最深的满足
cnt[x] > 1的节点。 -
这个节点的深度就是该字符串与其他字符串的最长公共前缀长度。
-
为什么将 cnt[x]++ 写在 for 循环里面?
在字典树算法中,cnt[x]++ 的作用是记录每个节点被访问的次数。以下是详细解释:
1. cnt[x]++ 的作用
-
cnt[x]:表示从根节点到节点 xx 的路径所表示的前缀被多少个字符串共享。 -
cnt[x]++:每当一个字符串经过节点 x 时,cnt[x]增加 1。
2. 为什么写在 for 循环里面?
-
插入字符串时:
-
在插入字符串的过程中,每经过一个节点 x,都需要更新
cnt[x]。 -
这是因为每个节点都代表一个前缀,
cnt[x]记录了有多少个字符串共享这个前缀。
-
-
查询最长公共前缀时:
-
在查询过程中,
cnt[x]用于判断当前前缀是否被多个字符串共享。 -
如果
cnt[x] > 1,说明当前前缀被至少两个字符串共享。
-
3. 示例分析
假设有以下字符串:
abc
ab
a
插入过程:
-
插入
abc:-
经过节点
a,cnt[a] = 1。 -
经过节点
b,cnt[ab] = 1。 -
经过节点
c,cnt[abc] = 1。
-
-
插入
ab:-
经过节点
a,cnt[a] = 2。 -
经过节点
b,cnt[ab] = 2。
-
-
插入
a:-
经过节点
a,cnt[a] = 3。
-
查询过程:
-
查询
abc:-
节点
a:cnt[a] = 3 > 1,匹配长度 = 1。 -
节点
b:cnt[ab] = 2 > 1,匹配长度 = 2。 -
节点
c:cnt[abc] = 1,停止。 -
最长公共前缀长度 = 2。
-
-
查询
ab:-
节点
a:cnt[a] = 3 > 1,匹配长度 = 1。 -
节点
b:cnt[ab] = 2 > 1,匹配长度 = 2。 -
最长公共前缀长度 = 2。
-
-
查询
a:-
节点
a:cnt[a] = 3 > 1,匹配长度 = 1。 -
最长公共前缀长度 = 1。
-
代码说明:
第一种实现
void insert(string a) {
int n = a.length() - 1;
int x = 1;
for (int i = 1; i <= n; i++) {
if (!tire[x][a[i] - 'a']) tire[x][a[i] - 'a'] = idx++;
x = tire[x][a[i] - 'a'];
cnt[x]++;
}
}特点:
-
字符串下标从 1 开始:
-
字符串
a的下标从 1 开始,a[0]被忽略。 -
这是因为在主函数中,字符串被修改为
s[i] = '0' + s[i],即在字符串前面添加了一个字符'0',使得有效字符从下标 1 开始。
-
-
循环范围:
-
循环从
i = 1到i = n,其中n = a.length() - 1。 -
这样可以正确处理字符串的有效部分。
-
第二种实现
void insert(string a) {
int x = 1;
for (int i = 0; a[i]; i++) {
if (!tire[x][a[i] - 'a']) tire[x][a[i] - 'a'] = idx++;
x = tire[x][a[i] - 'a'];
cnt[x]++;
}
}特点:
-
字符串下标从 0 开始:
-
字符串
a的下标从 0 开始,a[0]是第一个字符。 -
这与主函数中对字符串的处理方式不一致。
-
-
循环范围:
-
循环从
i = 0开始,直到a[i]为'\0'(字符串结束符)。 -
这种写法适用于标准的 C 风格字符串(以
'\0'结尾),但在 C++ 的std::string中,a[i]不会自动包含'\0'。
-
为什么不能使用第二种实现?
-
字符串下标不一致:
-
在主函数中,字符串被修改为
s[i] = '0' + s[i],即在字符串前面添加了一个字符'0',使得有效字符从下标 1 开始。 -
如果使用第二种实现,
a[0]会被错误地当作有效字符处理,导致 Trie 树插入错误。
-
-
循环范围问题:
-
第二种实现假设字符串以
'\0'结尾,但在 C++ 的std::string中,a[i]不会自动包含'\0'。 -
如果字符串中没有
'\0',循环会越界访问,导致未定义行为。
-
-
逻辑错误:
-
第二种实现无法正确处理主函数中对字符串的修改(添加了前缀字符
'0')。 -
这会导致 Trie 树中插入的字符串与实际字符串不一致,影响后续的查询操作。
-
字典树(Trie)来解决问题,但它们的应用场景和具体实现有所不同。以下是详细对比:
题目 1:最长公共前缀问题(依依的瓶中信)
问题描述:
-
给定 N 个字符串,对于每个字符串 Si,找到与其他字符串的最长公共前缀的长度。
代码特点:
-
cnt[x]++写在for循环里面:-
在插入字符串时,每经过一个节点 x,都会更新
cnt[x]。 -
目的是记录每个节点被多少个字符串共享,从而在查询时判断当前前缀是否被多个字符串共享。
-
核心逻辑:
-
插入时:
-
每经过一个节点 x,
cnt[x]++,表示当前前缀被一个字符串共享。
-
-
查询时:
-
遍历字符串的每个字符,找到最深的满足
cnt[x] > 1的节点,其深度就是最长公共前缀的长度。
-
题目 2:判断是否有重复字符串
问题描述:
-
给定 N 个字符串,判断是否存在两个相同的字符串。
代码特点:
-
cnt[x]++写在for循环外面:-
在插入字符串时,
cnt[x]++只在字符串的末尾节点执行。 -
目的是记录每个字符串的末尾节点被访问的次数。
-
核心逻辑:
-
插入时:
-
在字符串的末尾节点 x,
cnt[x]++,表示当前字符串被插入了一次。
-
-
查询时:
-
遍历字符串的每个字符,找到末尾节点 x。
-
如果
cnt[x] > 1,说明当前字符串被插入了多次,即存在重复字符串。
-
为什么 cnt[x]++ 的位置不同?
题目 1:最长公共前缀问题
-
目标:统计每个前缀被多少个字符串共享。
-
实现:
-
在插入时,每经过一个节点 x,
cnt[x]++,表示当前前缀被一个字符串共享。 -
这样可以在查询时,通过
cnt[x]判断当前前缀是否被多个字符串共享。
-
题目 2:判断是否有重复字符串
-
目标:判断是否存在两个相同的字符串。
-
实现:
-
在插入时,只在字符串的末尾节点 x,
cnt[x]++,表示当前字符串被插入了一次。 -
这样可以在查询时,通过
cnt[x]判断当前字符串是否被插入了多次。
-
总结
| 题目 | 目标 | cnt[x]++ 位置 | 作用 |
|---|---|---|---|
| 最长公共前缀问题 | 找到与其他字符串的最长公共前缀 | for 循环里面 | 记录每个前缀被多少个字符串共享 |
| 判断是否有重复字符串 | 判断是否存在两个相同的字符串 | for 循环外面 | 记录每个字符串的末尾节点被访问的次数 |
通过调整 cnt[x]++ 的位置,可以灵活地实现不同的功能。