【大模型:RAG】--CLIP模型实现多模态检索
解读OpenAI提出的多模态模型:CLIP(Contrastive Language-Image Pre-training:对比语言-图像预训练) 。它是多模态领域的经典之作,后续也作为基础模型,被广泛用在DALLE2,Stable Diffusion等重要文生图大模型中。话不多说,进入正文
论文:https://arxiv.org/pdf/2103.00020v1
github:https://github.com/OpenAI/CLIP
目录
1.CLIP--作用
2.CLIP--框架
2.1.训练数据
2.2.预训练
2.2.1.Text Encoder和Image Encoder
2.2.2.对比学习
3.CLIP--代码
3.1.零样本分类
3.2.文找图
3.3.图片相似度
3.4.图找图
4.CLIP--缺陷
1.CLIP--作用
在使用VIT做传统图像分类的过程中,我们的训练是“有标签的” 。如下图所示,每张输入数据都是<image, label>的形式,最终我们用MLP Head位置上对应的向量,来做图片的类别预测。
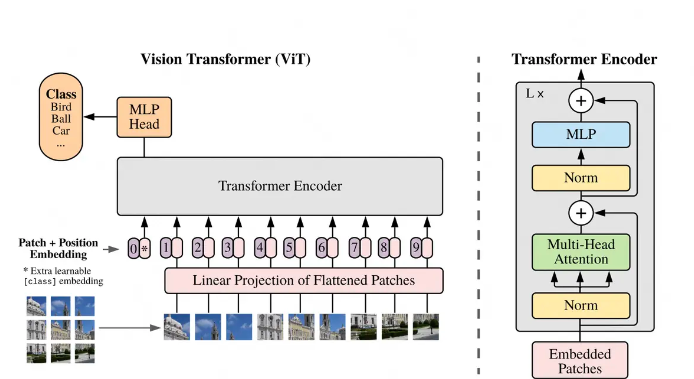
这样的设计有2个显著缺点:
缺点1:如果出现了一张图,其中包含模型从来没见过的类别,那么模型就不能输出正确的结果。(例如,训练时用的是动物图片,预测时给模型一张汽车图片)
缺点2:如果输入数据出现了分布偏移(distribution shift),那么模型可能也无法输出正确的结果。(例如,缺点1中描述的算一种偏移,另外训练时用的是正常的动物图片,预测时给的是毕加索风格的动物图片也算一种偏移)
解决这2个缺点的传统方法是:微调。但是多模态却想做一步到位的事情:不用做任何微调,也能实现zero-shot的图片分类。
✅ CLIP 的解决方案:将分类转化为图文匹配任务
不再把图像分类看作“从固定类别中选一个”,而是看作:“这张图更像哪段文字描述?”
实现方式:
-
训练阶段:
- 使用大量互联网图文对(image-caption pairs),例如来自社交媒体的图片及其标题。
- 图像编码器(如 ViT 或 ResNet)将图像映射为向量。
- 文本编码器(如 Transformer)将对应的文本描述编码为向量。
- 使用 对比学习(contrastive learning) 目标函数,拉近配对的图文向量距离,推远不匹配的图文对。
-
测试阶段(zero-shot):
- 给定一组候选标签,比如
<dog>, <cat>, <car> - 构造对应的文本提示(prompt),例如:
- “a photo of a {class}”
- “this is a picture of a {class}”
- 将这些 prompt 输入文本编码器,得到每个类别的文本向量。
- 将待测图像输入图像编码器,得到图像向量。
- 计算图像向量与各个文本向量的余弦相似度。
- 选择相似度最高的类别作为预测结果。
- 给定一组候选标签,比如
✅ 结果:哪怕训练时从未见过 <car> 这个类别的图像,只要文本中有“car”的语义表达,并且图像中出现了汽车的典型结构,模型就能将其匹配成功。
✅ CLIP 的优势:更强的语义泛化能力
为什么 CLIP 更鲁棒?
训练数据极度多样化
- CLIP 使用了数百 million 级别的真实世界图文对,涵盖各种风格、角度、光照、艺术形式。
- 包括新闻、博客、产品页、社交媒体等来源 → 天然包含多种分布。
- 所以它已经在训练中“见过了”很多种“毕加索风格”的动物图片!
对比学习鼓励学习语义一致性
- 对比损失迫使模型关注那些能稳定对应文本含义的视觉特征,而不是表面纹理或背景。
- 例如,“斑马”不管是在草原、动物园、还是黑白线条画中,只要具备条纹+四足+马形,就会被关联到“a photo of a zebra”。
语言提供了抽象归纳能力
- 文本本身是一种高度抽象的符号系统。
- 当模型学会将“斑马”这个词与各种形态的斑马图像对齐时,它实际上在学习一种跨模态的“概念绑定”。
- 这种绑定具有天然的抗扰动能力。
📊 实验证明:
CLIP 在 ImageNet 上虽未使用其训练数据,但在标准评估下达到了媲美甚至超越有监督训练的 ResNet-50 的性能。更重要的是,在其他 30+ 个下游分类任务上,CLIP 的 zero-shot 表现普遍优于专业微调模型,尤其是在非自然图像(sketches, cartoons)上的迁移能力显著更强。
2.CLIP--框架
2.1.训练数据
CLIP的训练数据是 <图像,文本> pair。如图所示,一个batch的数据里,有若干张图像,每张图像都配有相应的文字描述信息(prompt) ,比如:
-
一张小狗图片,prompt为
<dog>,或者为<A photo of a dog>
值得一提的是,CLIP的作者发现,prompt的设计也会影响模型最终的效果,比如:
- 把prompt从单词
<dog>换成句子<A photo of a dog>后,模型在ImageNet分类任务上的准确率直接提高了1.3% - 在OCR数据集上,作者发现如果把要识别的文字、数字用引号扩起来,能达到更好的效果
- 在卫星图分类数据集上,作者发现把prompt替换成
<A satellite photo of a house>,效果会更好 - 在设计到多语义的场景,比如crane既可以表示仙鹤,又可以表示起重机。这时如果把prompt写成
<A photo of a crane, a type of pet>,就能解决歧义问题。
在论文的3.1.4部分,还有关于prompt工程的详细讨论,感兴趣的朋友,可以详读。
在训练中,CLIP没有用前人已经做好的“图像-文本”数据集,因为一来这些数据集质量不高,二来数量太少。CLIP团队自己动手,制作了一个含4亿“图像-文本“对的数据集。制作的方法是,首先从Wikipedia上取出出现次数在100以上的词制作成一个query list,然后保证其中每个query都有约2w个“图像-文本”对。
2.2.预训练
CLIP预训练方法:对比学习
2.2.1.Text Encoder和Image Encoder
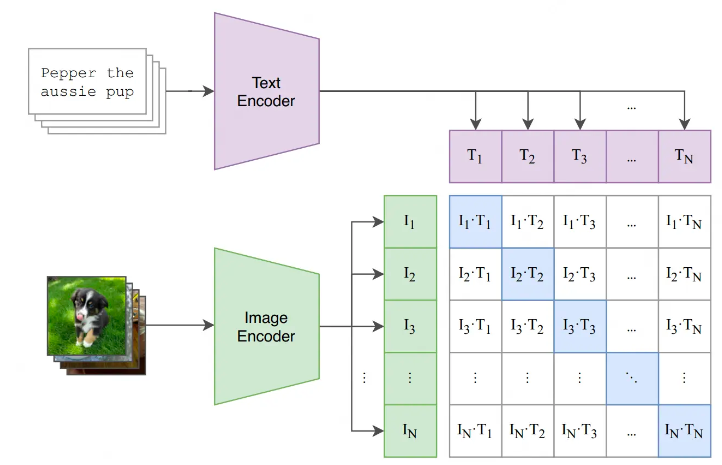
CLIP模型由两个主体部分组成:Text Encoder和Image Encoder。这两部分可以分别理解成文本和图像的特征提取器。
对于Text Encoder,CLIP借鉴的是GPT2(Radford et al.2019)的架构。对于每条prompt,在进入Text Encoder前,都会添加表示开始和结束的符号[SOS]与[EOS]。最终将最后一层[EOS]位置的向量作为该prompt的特征表示向量,也就是图中所绘的![]()
对于Image Encoder,CLIP则尝试过5种不同的ResNet架构和3种VIT架构,最终选用的是“ViT-L/14@336px”这个模型,也就是架构为Large,patch_size = 14的ViT,同时在整个CLIP预训练结束后,用更高分辨率(336*336)的图片做了一个epoch的fine-tune,目的是让CLIP能涌现出更好的效果。与Text Encoder类似,每张图片对应一个最终特征表示向量![]() 。但我猜测应该和Text Encoder差不多,可能来自分类头
。但我猜测应该和Text Encoder差不多,可能来自分类头[CLS]。
需要注意的是,CLIP是从头开始训练它的Text Encoder和Image Encoder的,没有借助其余预训练结果。
2.2.2.对比学习
假设一个batch中共有N对<图像,文字>对,那么它们过完各自的Encoder后,就会分别产生:
- 这两组向量,将会分别过一次多模态Embedding(multimodal embedding) ,也就是在图中代表文字的紫色向量下,还有一层参数
 ,文字向量需要先和做矩阵相乘后,才能得到最终的文字向量。对图片向量,同理也有个对应的
,文字向量需要先和做矩阵相乘后,才能得到最终的文字向量。对图片向量,同理也有个对应的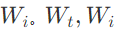 的作用可以理解成把文字、图片特征投影到多模态的特征空间中去。
的作用可以理解成把文字、图片特征投影到多模态的特征空间中去。 - 经过多模态Emebdding的处理,我们得到了最终的

接下来,我们就能通过“对比学习”,找到图像和文字的相似关系。做法也很简单,对于图中列出的N*N个格子,我们只需计算每个格子上对应的向量点积(余弦相似度)即可。由于对角线上的图片-文字对是真值,我们自然希望对角线上的相似度可以最大,据此我们可设置交叉熵函数,来求得每个batch下的Loss。
如果听起来还是觉得抽象,我们再来看代码实现(大家详细看下注释):
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality# -------------------------------------------------
# 1、图像/文字数据过image/text encoder,提取单模态特征
# 每张图片对应一个基本特征I_i
# 每张文字对应一个基本特征T_i
# -------------------------------------------------
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]# -------------------------------------------------
# 2. 图像/文字的基本特征过多模态Embedding,提取多模态特征
# 同时对这两个多模态特征做Layer Norm
# -------------------------------------------------
I_e = l2_normalize(np.dot(I_f, W_i), axis=1) # [n, d_i] * [d_i, d_e] = [n, d_e]
T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # [n, d_t] * [d_t, d_e] = [n, d_e]# -------------------------------------------------
# 3、计算图片-文字向量的余弦相似度
# -------------------------------------------------
logits = np.dot(I_e, T_e.T) * np.exp(t) # [n, n]# -------------------------------------------------
# 4、计算Loss
# -------------------------------------------------
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
最后一步计算Loss有迷惑,搞不懂为什么要算两个Loss再取平均,这里解释一下:
-
CLIP分为按行计算Loss和按列计算Loss
-
按行计算Loss,在每一行范围内做softmax,然后计算cross_entropy(蓝色格子部分是真值)。这样计算Loss的意义是:对于每一张图片,我们都希望找到和它最相似的文字。
-
按列计算Loss,在每一列的范围内做softmax,然后计算cross_entropy(蓝色格子部分是真值)。这样计算Loss的意义是:对于每一段文字,我们都希望找到和它最相似的图片。
-
最后将这两个Loss相加取平均,代表我们在模型优化过程中考虑了“图片->文字”和“文字->图片”的双向关系。
3.CLIP--代码
这里放一个中文的clip训练模型地址,https://github.com/OFA-Sys/Chinese-CLIP
pip install cn_clip3.1.零样本分类

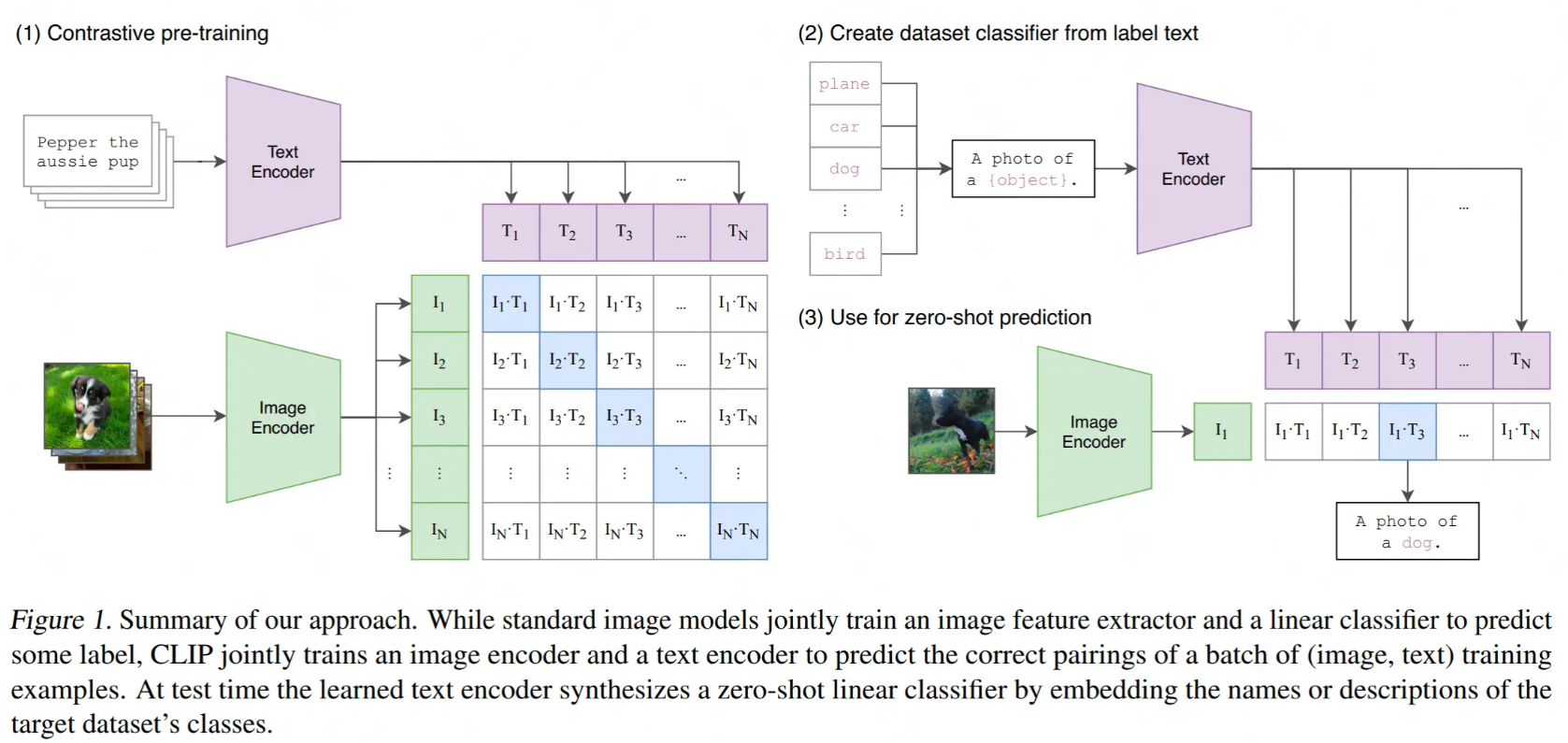
当我们做完模型的预训练后,就能用模型来做之前说的zero-shot预测了,方法也非常简单:
-
首先,我们创建一个标签全集,如图中(2)所示,并得到每一个标签的特征向量
-
然后,我们取一张图片,如图中(3)所示,过Image Encoder后得到该图片的特征向量
-
最后,计算图片向量和文字向量间的相似度,取相似度最高的那条label即可。
import torch
from PIL import Image
import cn_clip.clip as clip
from cn_clip.clip import load_from_name
import osdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using device:', device)# 模型加载
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./', use_modelscope=True)
model.eval()
#输出使用模型的地址# 图像路径
img_path = r"C:\Users\28986\Desktop\项目文件\项目十(多模态识图)\图片\2.16 断裂体系叠合图.png"
if not os.path.exists(img_path):raise FileNotFoundError(f"图像不存在: {img_path}")# 加载并预处理图像(确保是 RGB)
image = preprocess(Image.open(img_path).convert("RGB")).unsqueeze(0).to(device)# 文本标签
labels = ["断裂体系叠合图", "构造图", "沉积图", "顶面构造图"]
text = clip.tokenize(labels).to(device)with torch.no_grad():image_features = model.encode_image(image)text_features = model.encode_text(text)# 归一化image_features /= image_features.norm(dim=-1, keepdim=True)text_features /= text_features.norm(dim=-1, keepdim=True)# 相似度logit_scale = model.logit_scale.exp()logits_per_image = logit_scale * (image_features @ text_features.t())probs = logits_per_image.softmax(dim=-1).cpu().numpy()[0] # [0] 提取 batch 中的第一个# 输出结果
for label, prob in zip(labels, probs):print(f"{label}: {prob:.4f}")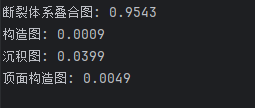
3.2.文找图
import torch
import clip
from PIL import Image
import os
import itertools
import torch.nn as nn
from tqdm import tqdm # 导入tqdm库device = "cuda" if torch.cuda.is_available() else "cpu"
print('Using device:', device)import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print("Available models:", available_models())# 如本地模型不存在,自动从ModelScope下载模型,需要提前安装`modelscope`包
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./', use_modelscope=True)dataset_folder = r'D:\pythonProject\大模型LLM\多模态检索\Chinese-CLIP-master\pretrained_weights\val2017(1)\val2017'
# 将所有图像加载到数组中
images = []
for root, dirs, files in os.walk(dataset_folder):for file in files:if file.lower().endswith('jpg'): # 使用lower()确保大小写不敏感images.append(os.path.join(root, file)) # 使用os.path.join更安全print(f"共找到 {len(images)} 张图像")text = clip.tokenize(['长颈鹿']).to(device)
text_features = model.encode_text(text)
result = {}cos = torch.nn.CosineSimilarity(dim=0)# 使用tqdm添加进度条
print("正在处理图像...")
for img in tqdm(images, desc="处理图像", unit="张"):try:with torch.no_grad():image = Image.open(img)image_preprocess = preprocess(image).unsqueeze(0).to(device)image_features = model.encode_image(image_preprocess)sim = cos(image_features[0], text_features[0]).item()sim = (sim + 1) / 2 # 将相似度从[-1,1]映射到[0,1]result[img] = simexcept Exception as e:print(f"处理图像 {img} 时出错: {e}")result[img] = 0.0 # 或者跳过该图像# 对字典进行排序并检索前3个值
sorted_value = sorted(result.items(), key=lambda x: x[1], reverse=True)
sorted_res = dict(sorted_value)
top_3 = dict(itertools.islice(sorted_res.items(), 3))
print("相似度最高的前3张图像:")
for img_path, similarity in top_3.items():print(f"图像: {img_path}")print(f"相似度: {similarity:.4f}")print("-" * 50)

3.3.图片相似度
import torch
import clip
from PIL import Image
import os
import itertools
import torch.nn as nn# model, preprocess = clip.load("ViT-B/32", device=device)
device = "cuda" if torch.cuda.is_available() else "cpu"
# model, preprocess = clip.load("ViT-B/32", device=device)
print('Using device:', device)import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50']# 如本地模型不存在,自动从ModelScope下载模型,需要提前安装`modelscope`包
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./', use_modelscope=True)img1 = r"C:\Users\28986\Desktop\项目文件\项目十(多模态识图)\图片\N2.1.png"
img2 = r"C:\Users\28986\Desktop\项目文件\项目十(多模态识图)\图片\N2.2.png"
cos = nn.CosineSimilarity(dim=0)img1_process = preprocess(Image.open(img1)).unsqueeze(0).to(device)
img2_process = preprocess(Image.open(img2)).unsqueeze(0).to(device)img1_feature = model.encode_image(img1_process)
img2_feature = model.encode_image(img2_process)sim = cos(img1_feature[0], img2_feature[0]).item()
sim = (sim+1)/2
print("similarity: ", sim)
#output: similarity: 0.844970703125
![]()
3.4.图找图
import torch
import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
from PIL import Image
import os
import itertools
import matplotlib.pyplot as plt# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Available models:", available_models())
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./', use_modelscope=True)# 数据集文件夹和目标图像
dataset_folder = r'C:\Users\28986\Desktop\项目文件\项目十(多模态识图)\图片'
target_img_path = r"C:\Users\28986\Desktop\项目文件\项目十(多模态识图)\图片\2.19 本一段沉积相图.png"# 预处理目标图像
input_image = preprocess(Image.open(target_img_path)).unsqueeze(0).to(device)
input_image_features = model.encode_image(input_image)# 收集所有 .png 图像
images = []
for root, dirs, files in os.walk(dataset_folder):for file in files:if file.lower().endswith('.png'): # 忽略大小写images.append(os.path.join(root, file))# 计算相似度
result = {}
cos_sim = torch.nn.CosineSimilarity(dim=0)
for img_path in images:try:image_pil = Image.open(img_path)image_tensor = preprocess(image_pil).unsqueeze(0).to(device)with torch.no_grad():features = model.encode_image(image_tensor)sim = cos_sim(features[0], input_image_features[0]).item()sim = (sim + 1) / 2 # 映射到 [0,1]result[img_path] = simexcept Exception as e:print(f"Error processing {img_path}: {e}")# 排序取 top-3(排除自己可能重复的情况)
sorted_result = sorted(result.items(), key=lambda x: x[1], reverse=True)
top_3 = sorted_result[:3]print("Top 3 most similar images:")
for path, score in top_3:print(f"{score:.4f}: {os.path.basename(path)}")# === 显示图像 ===
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
fig.suptitle("Top 3 Similar Images", fontsize=16)# 显示原始图像
original_img = Image.open(target_img_path)
axes[0, 0].imshow(original_img)
axes[0, 0].set_title("Query Image\n(Original)", fontsize=12, color='blue')
axes[0, 0].axis('off')# 显示 top-3 相似图像
for idx, (img_path, score) in enumerate(top_3):row, col = divmod(idx + 1, 2)img = Image.open(img_path)axes[row, col].imshow(img)axes[row, col].set_title(f"Rank {idx+1}\nScore: {score:.3f}", fontsize=12, color='green' if idx == 0 else 'black')axes[row, col].axis('off')plt.tight_layout()
plt.show()
4.CLIP--缺陷
到目前为止,我们已经把CLIP技术部分讲完了,怎么样,是不是比想象中的简单多了?虽然技术简单,但CLIP的论文肝了48页,来分析各种实验效果和其训练代价(CLIP训起来也是很贵)。因此,我这里就不花篇幅去介绍这两块了,感兴趣的朋友可以看看论文。
在这里我们想讨论的,是CLIP这个厉害的模型,到底存在哪些缺陷。
缺陷一:Zero-shot的能力很强,但不是最强的。
根据实验结果,CLIP从来没有用ImageNet的数据训练过,但它在ImageNet上的预测效果可以达到76.2%,和用ImageNet做训练集的ResNet50基本一致。乍看之下,CLIP的表现很不错了。但其实,ResNet50并不是在ImageNet分类任务上表现最SOTA的模型,例如MAE之类在ImageNet上可以达到80%+。虽然CLIP同样具有涌现能力,即当模型变大时,模型的效果会更好,但是因为CLIP训练昂贵的原因,为了提升预测百分点而需要的代价是巨大的。因此这也是CLIP当前的限制之一。
缺陷二:CLIP无法处理更抽象的任务。
抽象的任务指:输出图片中物体的个数等需要一定逻辑思维推理的任务。在论文的实验中也有给出一些说明,下图中刻画了CLIP和ResNet在不同数据集任务上的表现情况。绿色表示CLIP表现更好的数据集,蓝色表示ResNet表现更好的数据集。注意到蓝色部分的DTD(纹理分类)和CLEVRCountS(给图中物体计数)这两个数据集,都是相对抽象的任务,在这方面CLIP的表现明显不如ResNet。

缺陷三:当测试数据集分布严重偏移时,CLIP也束手无策。
虽然CLIP以Zero-shot标榜,但是如果测试数据集分布相对训练数据集分布存在严重偏移情况时,CLIP的表现也不理想。论文中提出了一个很有代表性的例子:MNIST(手写数字数据集)。这样一个简单的数据集,可能用SVM都能做到90%以上的准确率了,但CLIP在上面的表现只有88%,原因就是在CLIP的训练数据集里,可能还真没见过和MNIST相似的图片数据。
缺陷四:文字标签是个闭集。
前文说过,在对CLIP做zero-shot预测时,我们的文字标签是一个闭集,模型吃一张可能没有见过的图片,然后从这个闭集中找出最匹配的标签,而不是去预测出一个新的文字标签。从这一点上说,CLIP依然不够自动化。
缺陷五:受限于计算资源,无法做图像-文本的生成式网络。
这个在CLIP看来是缺陷的问题,不久之后已经被我们熟知的DALLE2,Stable Diffusion解决了(没错,正是采在CLIP的肩膀上)。因此这是CLIP的限制,但也是后人研究的启发点。