Redis(一)——数据类型一
这个数据类型相信大家都不陌生了,我们今天来看的数据类型其实很多大家也是经常使用的,所以学习起来还是非常容易的,但是再看数据类型之前,主包还是多嘴一句,也就是redis如何连接,毕竟我们使用中间件久了,如何连接可能都已经忘了。
# 1. 最简单连接(默认端口6379,无密码)
redis-cli# 2. 指定端口连接
redis-cli -p 6379# 3. 指定主机和端口,如果是远程连接就填对应的ip和端口
redis-cli -h 127.0.0.1 -p 6379# 4. 带密码连接
redis-cli -a yourpassword# 5. 连接后验证
redis-cli
127.0.0.1:6379> AUTH yourpassword
127.0.0.1:6379> PING # 测试连接string类型
这个类型是我们用的最多的类型,也是最简单的类型,这里要提一句的是不管值是什么类型的,key永远是string类型的,我们说的不同类型也只是针对值来说的而已,我们的key可以是如何字符他是一个二进制安全的,所以就算我们使用一个图片作为key都可以,当然我们一般不建议这么做,当然我们的value也是如此可以是任何的字符。命令太多了就不一个一个说了,如果想知道其他命令就上网搜索命令大全吧,这里只介绍set了。
SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL] [GET]这个是最基本的语法我们来一个一个看具体有什么用,EX - 秒级过期时间,PX - 毫秒级过期时间,EXAT/PXAT - 绝对时间过期也就是到对应的时间戳才过期,KEEPTTL - 保持原有TTL,TTL是剩余存活时间,KEEPTTL - 保持原有TTL,NX - 仅当键不存在时设置,XX - 仅当键存在时设置。GET 参数 - 原子性获取并设置如下:
# 获取旧值并设置新值(原子操作)
SET counter "100" GET # 返回nil,因为counter不存在
SET counter "200" # 先设置值
SET counter "300" GET # 返回"200",并设置为"300"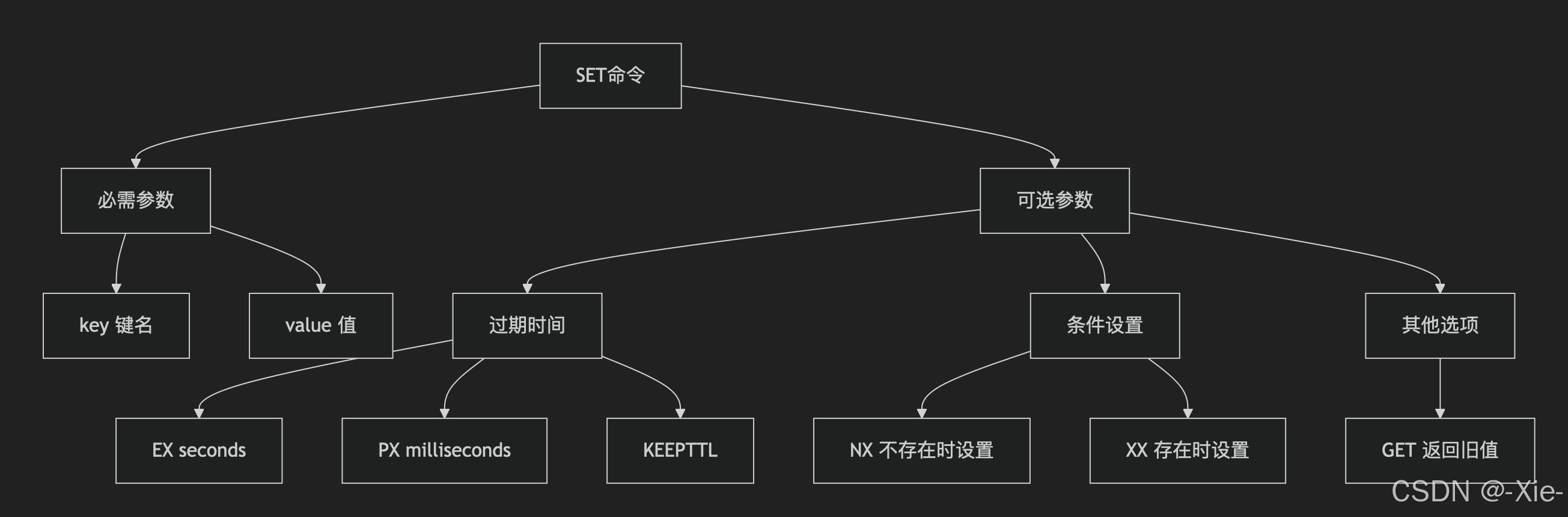
这个是不同的返回值:
命令 | 条件 | 返回值 | 说明 |
|---|---|---|---|
| 成功 |
| 简单字符串回复 |
| key不存在 |
| 设置成功 |
| key已存在 |
| 设置失败 |
| key存在 |
| 设置成功 |
| key不存在 |
| 设置失败 |
| 任何情况 | 旧值或 | 返回设置前的值 |
list类型
这个和我们java的list是相同的,你可以相信成一个横放的水管,可以从左右两边放东西和拿东西,push是放,pop就是拿,L代表左,R代表右,他们是一个双向链表,两端插入/删除:O(1)时间复杂度,按索引访问:O(N)时间复杂度,同时也可以范围操作:获取、修剪列表片段,也和栈一样有阻塞操作:等待列表元素的弹出。
这个的命令咱们就不说了哈,比较简单一看就会的。
set类型
这个类型相信大家也不陌生了,天然的去重能手,底层使用hash表让时间复杂度为0(1),又快又好使,只是他是无序的,使用ADD进行添加,使用REM进行删除(remove删除),使用起来也是很简单的,所以这边也就是不介绍命令了。
SADD tags "redis" "cache" "memory" # redis已存在,不会重复添加zset类型
这个是集合了set集合去重的优点,增加了有序的特点。
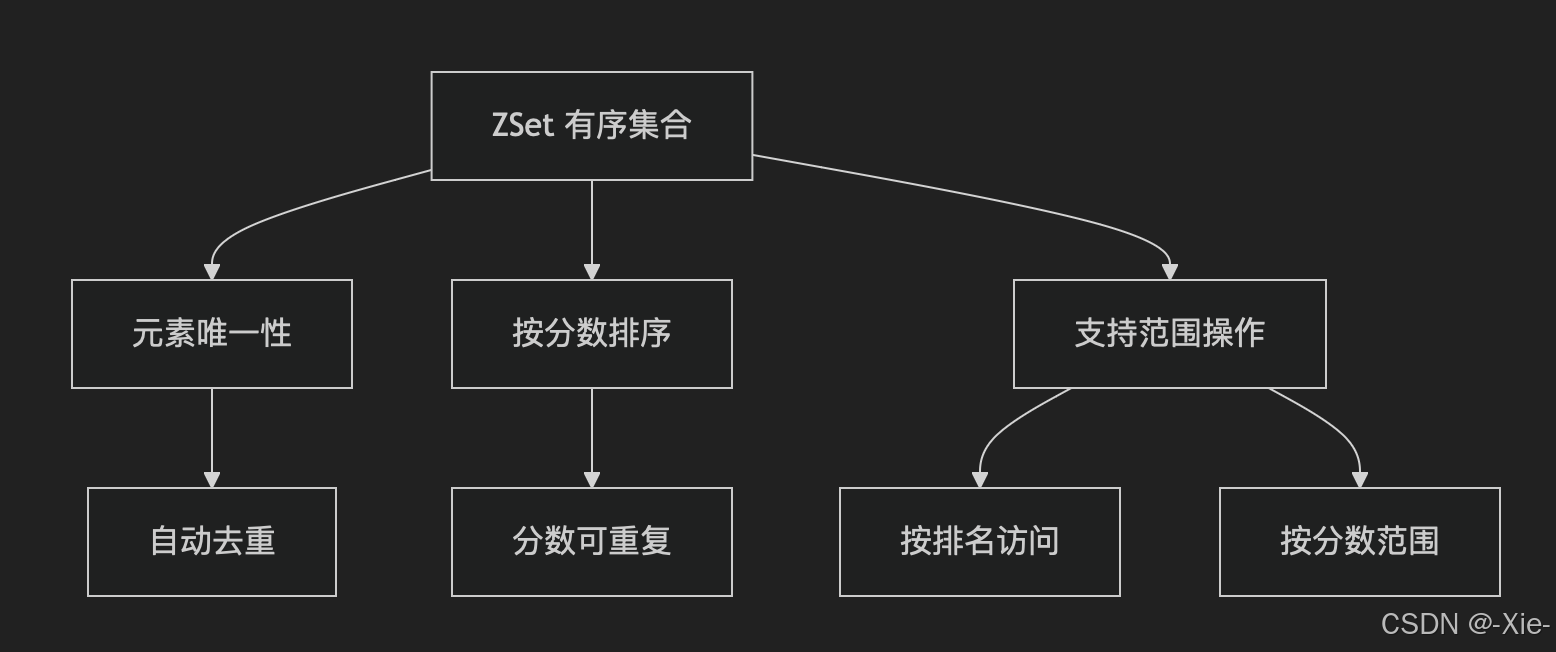
而这个排序通过分数(Score) 和成员(Member) 双重机制确保顺序如下图:
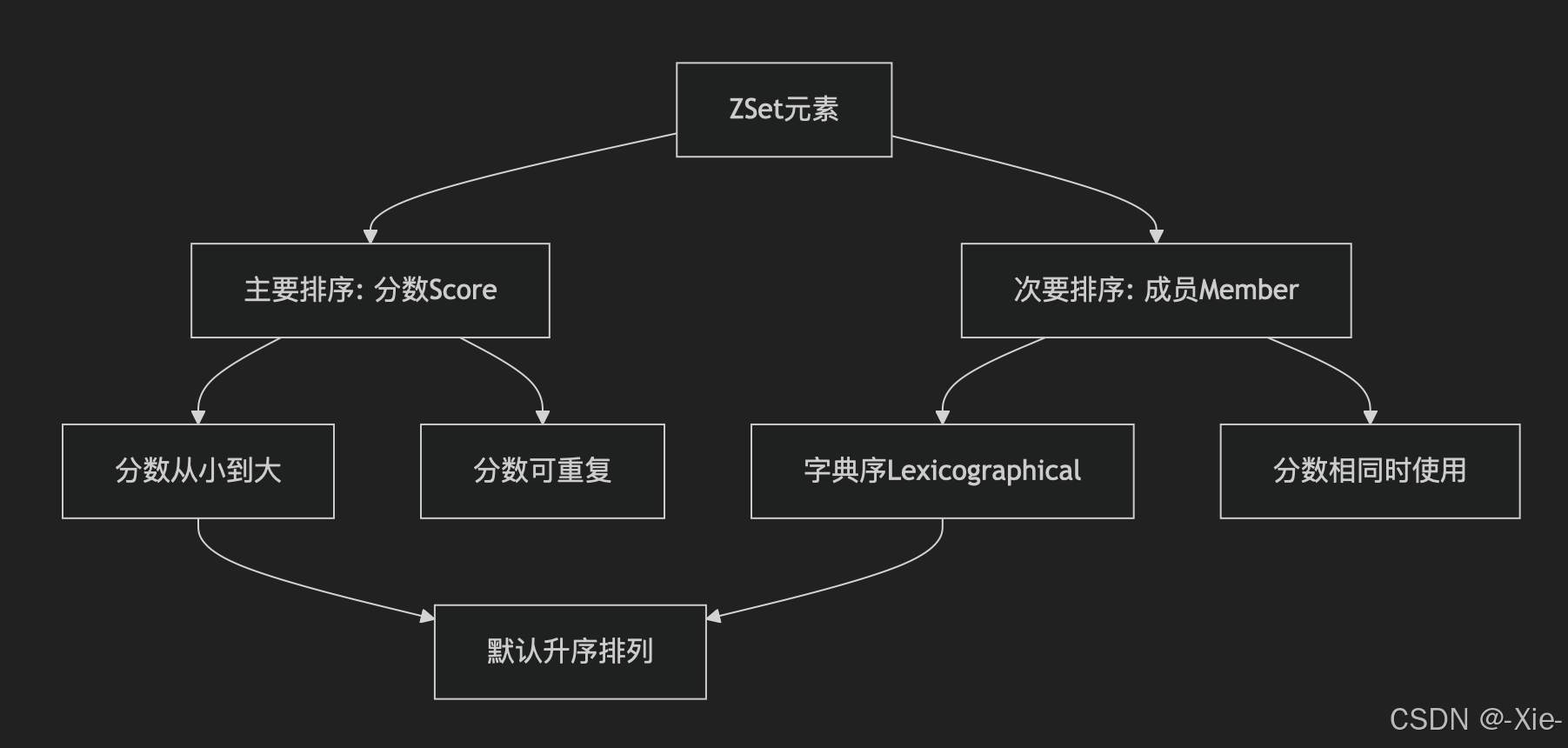
# 1. 基本排序规则:按分数升序
127.0.0.1:6379> ZADD leaderboard 100 "Alice" 85 "Bob" 92 "Charlie" 85 "David"
(integer) 4# 查看默认排序(升序)WITHSCORES这个字段表示同时打印分数。
127.0.0.1:6379> ZRANGE leaderboard 0 -1 WITHSCORES
1) "Bob" # 分数最低
2) "85"
3) "David" # 同分,按成员字典序
4) "85"
5) "Charlie" # 分数中等
6) "92"
7) "Alice" # 分数最高
8) "100"hash类型
这个其实我们java开发过程中也使用非常多,就是map嘛,通过hset设置值,hget获取值。下面是一些演示代码:
# 1. 批量设置字段
127.0.0.1:6379> HMSET product:1001 name "iPhone" price "5999" stock "100" category "phone"
OK# 2. 批量获取字段
127.0.0.1:6379> HMGET product:1001 name price stock
1) "iPhone"
2) "5999"
3) "100"# 3. 获取所有字段和值
127.0.0.1:6379> HGETALL product:1001
1) "name" # 字段
2) "iPhone" # 值
3) "price"
4) "5999"
5) "stock"
6) "100"
7) "category"
8) "phone"# 4. 获取所有字段名
127.0.0.1:6379> HKEYS product:1001
1) "name"
2) "price"
3) "stock"
4) "category"# 5. 获取所有字段值
127.0.0.1:6379> HVALS product:1001
1) "iPhone"
2) "5999"
3) "100"
4) "phone"Bitmaps类型(位图)
这个类型就十分的有趣了,java开发过程中用的应该非常少,因为我们java最小的数据类型也是1个大B=一个字节=8bit,搞不懂这么多别名很容易搞混,最简单的就是我们常常使用的boolean类型他就是一个字节的,只是为了表示true和false,因为永远只有这两种结果使用我们二进制的01其实更加的恰当和节省空间,而我们的位图就是一堆bit组合而成的数组,每一位都可以使用一个boolean类型的功能,是不是十分的强大。
# 位图在内存中的表示
# 一个字节(8位)可以表示8个布尔值# 普通布尔数组(浪费内存):
[True, False, True, False, False, True, False, True] # 占用8个布尔值(至少8字节)# 位图表示(节省内存):
字节值: 10100101 # 1个字节表示8个状态# Redis中,每个位代表一个状态(是/否,存在/不存在)我们看这个最简单的设置命令,其中user:online这个是key,这个1000值的是这个key指向的数组的第1000位,后面的1表示把这个1000位上的值设置为1。我们都知道1字节等于8位,1000/8=125,也就是这个user:online分配了125个字节的大小。所以我们使用位图的时候还是尽量从小到大写吧,别浪费了。
# 设置第1000位为1
127.0.0.1:6379> SETBIT user:online 1000 1下面是对位图的命令的总结,实际如何使用或者如何更加详细的使用还是要请各位自行查找了,因为命令一个一个讲解实在是篇幅太长了。
命令 | 语法 | 作用 | 时间复杂度 | 使用场景 | 示例 |
|---|---|---|---|---|---|
SETBIT |
| 设置位的值 | O(1) | 用户状态标记、签到 |
|
GETBIT |
| 获取位的值 | O(1) | 检查状态、验证存在 |
|
BITCOUNT |
| 统计设置位数 | O(N) | 用户统计、计数 |
|
BITOP |
| 位运算 | O(N) | 集合运算、标签组合 |
|
BITPOS |
| 查找第一个设置位 | O(N) | 查找第一个满足条件的位 |
|
BITFIELD |
| 位域操作 | O(1) per subcmd | 紧凑存储多个整数字段 |
|
HyperLogLogs类型
这个类型是Redis中用于基数统计(去重计数)的特殊数据结构,特点如下:
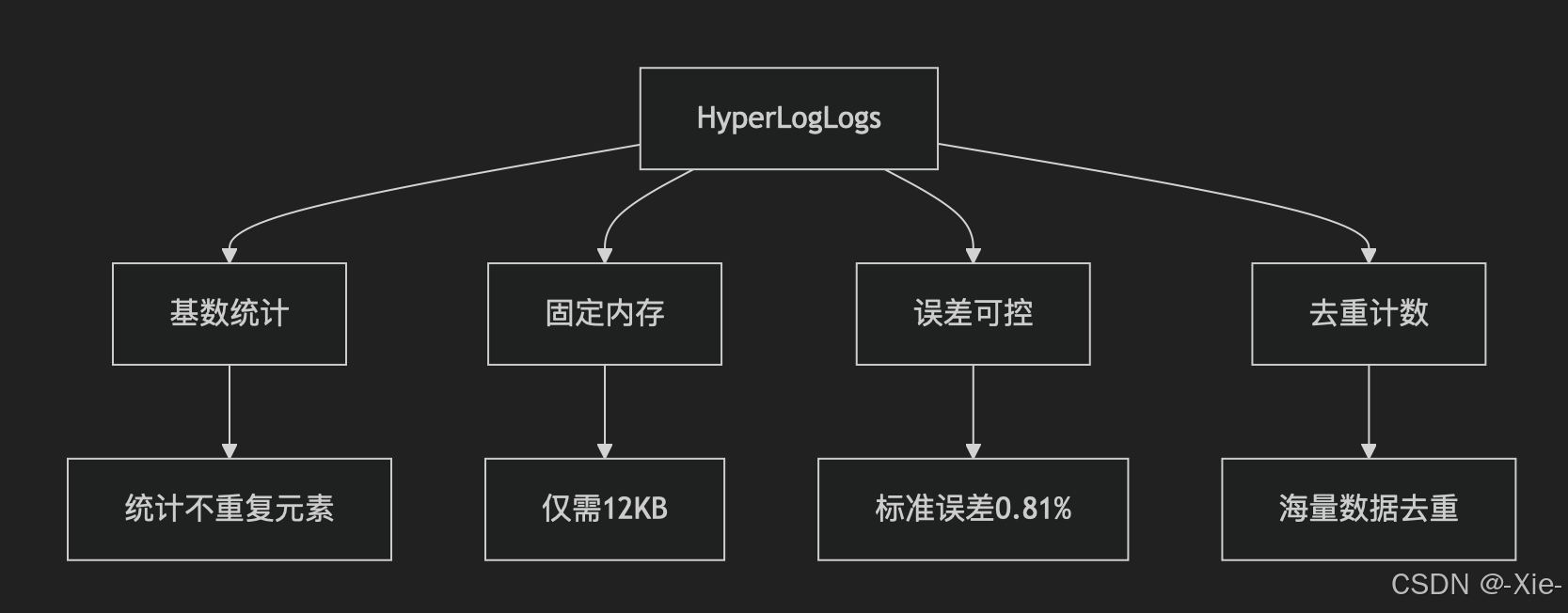
这个数据类型就是拿来统计的,而且占用小当然这个是同样的数据相对于其他类型来说的,而且误差小,也是去重的数据类型。下面这个是使用场景推荐:
场景 | 推荐方案 | 内存占用 | 精度 | 示例 |
|---|---|---|---|---|
小规模精确统计 | Set | O(n) | 100% | 用户数<1万 |
中等规模去重 | Bitmaps | O(n)可压缩 | 100% | 用户数<100万 |
海量数据统计 | HyperLogLog | O(1)固定12KB | 99.19% | UV统计、大数据分析 |
需要元素详情 | Set | O(n) | 100% | 需要具体用户列表 |
仅需计数 | HyperLogLog | O(1)固定12KB | 99.19% | 只需要数量不要详情 |
这个是演示:
# 清空测试数据
127.0.0.1:6379> FLUSHDB
OK# 1. 添加元素到HyperLogLog
127.0.0.1:6379> PFADD uv:daily:20231201 "user1" "user2" "user3"
(integer) 1 # 1表示有至少一个元素是新的# 2. 统计基数(不重复元素数)
127.0.0.1:6379> PFCOUNT uv:daily:20231201
(integer) 3# 3. 添加重复元素
127.0.0.1:6379> PFADD uv:daily:20231201 "user1" "user4" "user5"
(integer) 1 # user4和user5是新的# 4. 再次统计(自动去重)
127.0.0.1:6379> PFCOUNT uv:daily:20231201
(integer) 5 # user1只算一次# 5. 合并多个HyperLogLog
127.0.0.1:6379> PFADD uv:daily:20231202 "user3" "user6" "user7"
(integer) 1
127.0.0.1:6379> PFMERGE uv:weekly:20231201_07 uv:daily:20231201 uv:daily:20231202
OK
127.0.0.1:6379> PFCOUNT uv:weekly:20231201_07
(integer) 7 # 合并去重后的总数命令 | 语法 | 作用 | 返回值 | 时间复杂度 | 使用场景 |
|---|---|---|---|---|---|
PFADD |
| 添加元素到HyperLogLog | 1: 有新增元素 | O(1) | 实时数据录入、用户访问记录 |
PFCOUNT |
| 统计基数(不重复元素数) | 估算的基数数量 | O(1) | UV统计、独立用户数查询 |
PFMERGE |
| 合并多个HyperLogLog | OK: 成功 | O(N) | 数据汇总、分布式统计合并 |
总结
本篇主要对Redis常用数据类型就行介绍,下篇对不常用的数据类型进行介绍,这边再说一下,把redis中的key当成一个变量,value就是对应的数据类型,会更加好理解。