机器学习日报08
目录
- 摘要
- Abstract
- 一、机器学习的迭代发展
- 1、例子:构建邮件垃圾信息分类器的例子
- 二、误差分析
- 三、添加数据
- 1、数据增强
- 2、数据合成
- 总结
摘要
今天的学习让我了解了机器学习系统开发的迭代过程。通过垃圾邮件分类器的例子,我明白了从选择模型架构到训练诊断的完整流程。误差分析教会我如何手动检查分类错误的样本,找出常见错误类型并确定优化优先级。数据增强和数据合成则展示了如何高效扩充训练集,特别是针对图像和语音任务。这些方法共同构成了一个系统的模型优化框架。
Abstract
Today’s lesson covered the iterative development of machine learning systems. Using a spam classifier example, I learned the complete workflow from model selection to performance diagnosis. Error analysis techniques helped identify common misclassification patterns and prioritize improvements. Data augmentation (distorting existing samples) and data synthesis (creating new samples) were introduced as effective ways to expand training datasets, especially for computer vision tasks. These methodologies form a comprehensive approach to ML system optimization.
一、机器学习的迭代发展
在这一节,老师跟我们分享了机器学习系统的开发过程是什么样的,这样当我们自己去尝试的时候,能够帮助我们在机器开发过程的许多阶段做出出色的决策
首先让我们看看机器学习开发的迭代循环,这通常是开发机器学习模型的感觉,首先我们需要决定系统的整体架构是什么,这意味着选择我们的机器学习模型,以及决定使用什么数据,然后基于这些决策,我们会实现并训练一个模型,就像我们之前提到的,当我们第一次训练模型,它几乎不会像我们期望的那样好用,接下来建议的是实现或查看一些诊断工具,比如观察算法的偏差和方差,以及我们将在下一个视频中看到的误差分析,并根据诊断的见解,选择是否要增大神经网络规模或更改λ正则化参数或者添加更多的数据,然后我们会用新的架构再次进行这个循环,通常需要迭代很多次才能达到我们需要的效果
1、例子:构建邮件垃圾信息分类器的例子

上图左边是垃圾邮件,我们看到它让我们在这周某天去买个劳力士或者是药物,仔细看我们会发现这些垃圾邮件会故意拼错一些单词来规避垃圾邮件检测模型,而右边是老师的弟弟给老师发的邮件
那么我们要如何构建一个分类器来识别垃圾邮件和非垃圾邮件

如上图所示,我们可以设定特征向量,把一系列跟垃圾邮件有关的特征值放入其中,并且用0和1来判断是否在文中出现,明显,我们可以看到andrew 、buy、deal等这些单词出现,这会帮助我们判断是否为垃圾邮件
另外一种方法是将这些数字设置为不仅仅是0或1,而是实际计算某个单词在邮件中出现的次数,如果buy出现两次,那么我们把这个特征设置为2,我们可以训练一个分类算法,比如逻辑回归模型或者神经网络来预测y
在训练初始模型后,可能模型效果没有达到我们的预期,我们可能有多个办法改进学习算法
例如,收集更多的信息、开发更复杂的特征,来自电子路由分析,电子邮件路由指的是电子邮件在全球范围内经过一系列计算服务器以此抵达用户的过程,而电子邮件有一个叫做电子邮件头部信息的东西,这些信息记录了电子邮件如何通过不同的服务器和网络传输找到了用户,有时电子邮件的路径可以判断它是否有垃圾邮件发送者
二、误差分析
在帮助我们进行诊断以选择下一步改进学习算法性能,第一重要的是偏差不变性,而错误分析是第二重要
具体来说,假设我们有500个交叉验证例子,但是我们的算法错误的分类了其中的100个,错误分析过程指的是手动查看这100个例子并尝试理解算法出错的地方,经常做的方法是找到一组算法错误分类的例子,并尝试将它们分组为共同的特征、共同的属性

图为100件邮件中错误分类的各种情况,第一个是我们错误分类了带有药物销售或购买药品的邮件,我们在100件中发现了21个,第二个是垃圾邮件故意拼写错误来误导判断模型进而将其认定为正常邮件,在100件我们发现了3个,第三个是非正常电子邮件弟子,我们在100件中发现了7个,第四个是钓鱼邮件,用于窃取用户密码,我们在100件中发现了18个,最后一个图片嵌入式垃圾邮件,把垃圾信息嵌入到图片中,导致判断模型无法正常判断,我们在100件中发现了5个
我们发现,医药垃圾邮件和试图窃取密码或钓鱼邮件似乎非常多,而拼写错误,虽然是一个问题,但它相比于前者,优先级并没有那么高,不是说不考虑,而是我们需要优先处理这些量大的情况
此外,这些列出来的情况并非相互独立的,相反,一个药物售卖的垃圾邮件可能会带有拼写错误也可能会有异常电子邮件地址,所以一封邮件可能会被归入多个类别
现在让我们加大难度,将错误分类的数量提高到5000件,这是一个大数目,我们人工一件一件再去判断是非常耗时耗力,得不偿失,这时,我们刚才100样本的判断结果就派上用场了,我们可以把100样本分析结果交给计算机,让他知道哪些是我们容易忽略的,碰到错误分类的邮件我们应该如何把它归类,这样计算机处理是很快的
回到我们的主题,偏差-方差分析应告诉我们收集更多数据是否有帮助,根据我们刚刚进行的示例中的错误分析,看起来更复杂的电子邮件特征可能会有帮助,更复杂的特征来检测制药垃圾邮件或钓鱼邮件可能会有很大的帮助,而更复杂的特征对于拼写错误几乎没那么多帮助
所以总的来说,我们发现偏差-方差诊断以及进行这种形式的错误分析,对筛选或决定哪些模型的变化更有希望尝试是非常有帮助的,现在错误分析的一个局限性是,对于人类不擅长的问题,它要做起来并不是很容易,例如,我们想要预测某人在网站上点击哪些广告,其实我们自己都不知道,对于一个网站上的匿名用户,他会点击哪个广告,所以在这种情况下,错误分析往往发挥不了作用,但我们将错误分析应用于我们能够解决的问题,它可以极大地帮助我们聚焦在更有希望的事情上去尝试,这反过来可以为我们节省几个月本来无果的工作
三、添加数据
在本节中,会分享一些添加数据,收集更多数据的技巧,有时甚至是创建数据的方法。
在训练机器模型时,我们总是会忍不住想要添加更多数据,好像这样能够让模型更加准确,但尝试获取更多类型的数据可能会很慢很昂贵,相反,一种替代的添加数据的方法是专注于增加那些错误分析,指出可能会帮助的数据类型,在上一节,我们了解错误分析在显示电子垃圾邮件上的应用,那么我们可以决定做出更有针对性的努力,而不是获取所有类型的数据,这样以较低的成本,我们只需要添加我们需要的邮件,从而帮助我们的学习算法更智能地识别垃圾邮件
更普遍的情况下,如果我们有一些方法可以为所有内容添加更多数据,那没问题,这样也行,但如果错误分析表明算法在某些数据子集上的表现很特别、表现不佳,并且希望提升在这些方面的表现,那么只获取我们希望其表现更好的类型的数据,无论是更多药物垃圾邮件的例子,还是更多网络钓鱼垃圾邮件的例子,或者其他类型的例子,这可能是一种更有效的方法,只需添加少量数据,但却能大幅度提升我们的算法性能
1、数据增强
还有另一个广泛应用的技术,尤其是对图像和音频数据,能够增加我们的训练集,这种技术叫做数据增强,我们要做的是拿一个现有的训练例子来创建一个新的训练样本
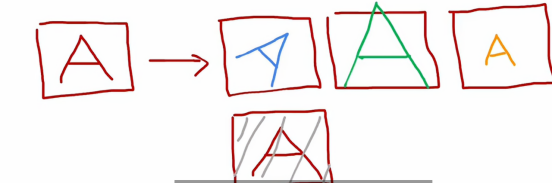
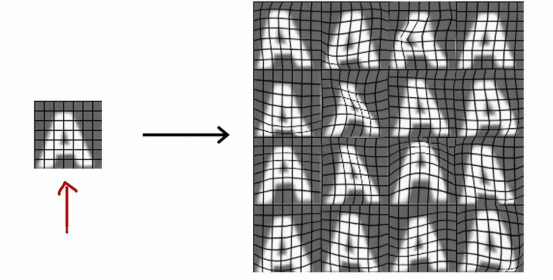
比如我们要识别字母A,那么除了给与最标准版的A,我们还有很多形状的A,如图中右侧所示,这些变形不会改变这个字母是A的根本属性,创建这些额外实例,有助于学习算法更好地学习如何识别,对于数据增强的更高级示例,我们可以将字母A放置在网格上,通过引入网格的随机扭曲,强化对A字母的识别
同样的思路,对于语音识别,我们可以增加声音周围的噪音来加强模型的识别能力
值得注意的是,我们对数据所做的更改或失真应该在训练集里存在
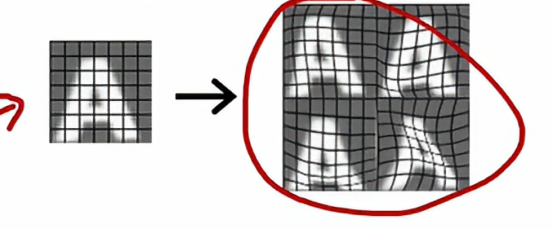
我们现在将A扭曲成右边的样子,它看起来还是例子中的字母,又比如将音频加入我们训练集中有的噪音,这样还是会被识别出来,但是相反,如果我们加入那些完全随机的变化是完全没有意义的,请记住,数据增强是对现有的训练样本进行修改以创建另一个训练样本
2、数据合成
数据合成是从0开始编造全新的样本,而不是修改原有的样本
照片OCR就是照片光学字符识别,指的是识别这样的图像并且使计算机自动读取其中出现的文本,一般图片上有很多文字,我们如何训练一个OCR算法来读取这种图像的文本呢,首先创建一个多个字母组成的字母集,然后不断提取图片的出现字母,照片OCR的一个内容就是根据图片中出现的字母,在字母集中搜取

左边的图是真实的数据,是全世界实地拍摄的图片,而右边是计算机合成的图片,所以通过这样的合成数据生成,我们可以为我们的照片OCR任务生成大量的图像或示例,为特定的应用生成看起来逼真的合成数据可能需要大量的编码工作,但是这些时间的投入是值得的,因为它会帮助我们为我们的应用生产大量的数据,并大大提升我们的平均表现,合成数据一般都是用于计算机视觉任务,很少用于其他方面
总结
今天的学习让我对机器学习项目开发有了更完整的认识。垃圾邮件分类器的例子生动展示了从特征设计到模型训练的整个过程。误差分析这个工具特别实用,通过人工检查100个错误样本,我发现医药类和钓鱼类垃圾邮件是主要问题,这比盲目优化更有针对性。数据增强的技巧很巧妙,通过对图像进行合理变形或给语音加噪,就能有效扩充数据集。而数据合成虽然需要更多编码工作,但能创造大量逼真的训练样本。这些知识让我明白,成功的机器学习项目需要系统性的迭代优化,而不是一次性的建模。下次做项目时,我会先快速建立基线模型,然后通过误差分析找到重点改进方向,再考虑用数据增强等技术提升性能。