【赵渝强老师】TiDB PD集群存储的信息

TiDB是PingCAP公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理(Hybrid Transactional and Analytical Processing,HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时HTAP、云原生的分布式数据库、兼容MySQL协议和MySQL生态等重要特性。目标是为用户提供一站式OLTP(Online Transactional Processing)、OLAP(Online Analytical Processing)、HTAP解决方案。TiDB适合高可用、强一致要求较高、数据规模较大等各种应用场景。
一、 TiDB的体系架构
在内核设计上,TiDB分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的TiDB系统。对应的架构图如下:
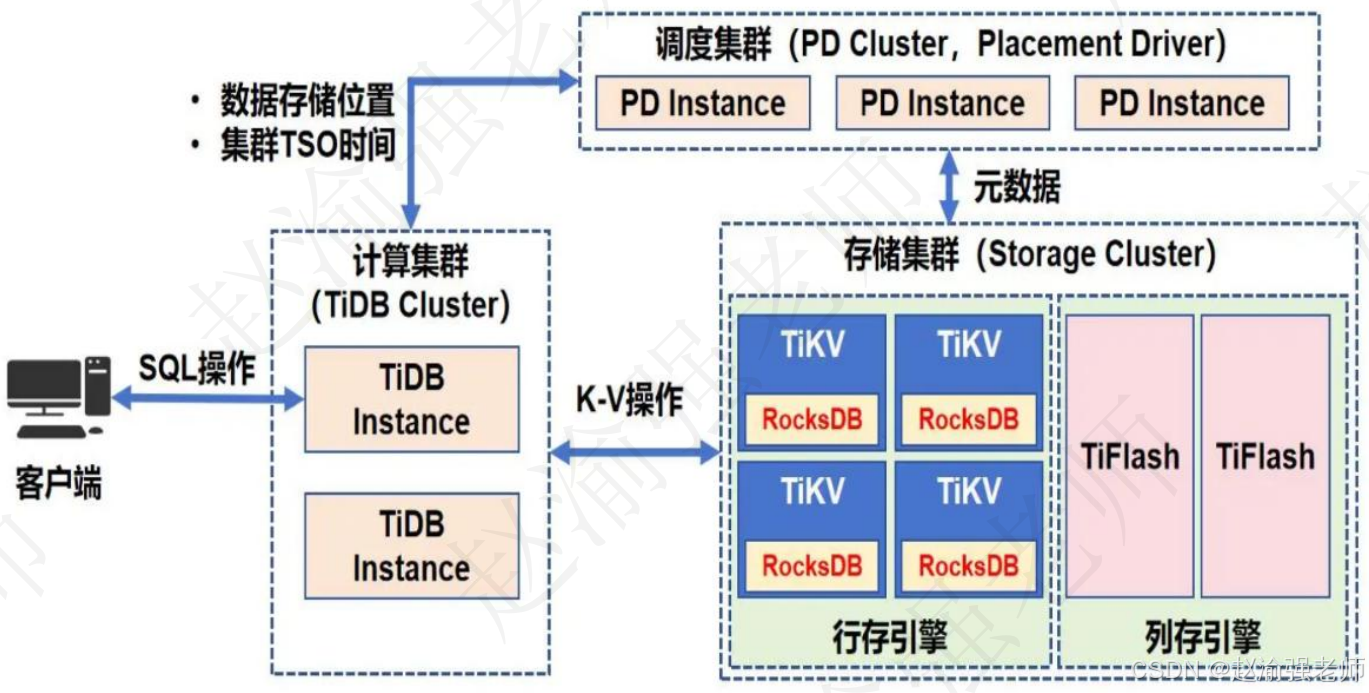
通过使用TiKV存储引擎支持OLTP的应用场景,而通过使用TiFlash存储引擎支持OLAP的应用场景。在TiDB数据库分布式集群中主要包含三个子集群:
- 1、存储集群:
该子集群负责数据的存储,其中又有行存引擎和列存引擎两种不同的存储方式:行存引擎指的是TiKV节点,它最终将数据存入底层的RocksDB中;列存引擎指的是TiFlash节点,它从TiKV节点中实时同步数据,这样的TiFlash节点也可以有多个。
- 2、调度集群:
调度集群中的每个节点叫做PD Instance,也叫做PD实例。存储集群会将数据存储位置等元信息存入调度集群中。
- 3、计算集群:
该子集群中可以包含多个TiDB Instance,即:TiDB实例。计算集群负责接收客户端发送的SQL语句,并访问PD集群获取数据存储位置和集群的时间戳TSO等信息,最终将SQL语句转换成Key-Value的键值操作,从而访问存储在存储集群中的数据。

二、 TiDB PD集群存储的信息
Placement Driver(简称PD)是TiDB里面全局中心总控节点,是整个集群的管理模块,负责整个集群的调度。TiDB作为一个分布式高可用存储系统,系统需要具备多副本容错,动态扩容、缩容,容忍节点掉线以及自动错误恢复的功能。为了满足这些功能,TiDB就需要收集足够的信息,比如每个节点的状态、每个Raft Group的信息等。PD根据这些信息以及调度的策略,制定出尽量满足这些需求的调度计划,并提供基本操作来完成这个计划。PD的主要工作体现在以下三个方面:
- 存储集群的元信息,例如:Region存储在哪个TiKV节点;
- 对TiKV集群进行调度和负载均衡,如:数据的迁移、Raft Group Leader的选举等;
- 分配全局唯一且递增的事务ID。
| 视频讲解如下 |
|---|
| 【赵渝强老师】TiDB PD集群存储的信息 |
PD的调度功能依赖于整个集群信息的收集,简单来说,PD需要知道每个TiKV节点的状态以及每个Region的状态。TiKV集群会向PD汇报以下两类消息:
- 每个TiKV节点会定期向PD汇报节点的状态信息
TiKV节点(也叫Store)与PD之间存在心跳包,一方面PD通过心跳包检测每个Store是否存活,以及是否有新加入的Store;另一方面,心跳包中也会携带这个Store的状态信息,主要包括:
(1)总磁盘容量
(2)可用磁盘容量
(3)承载的Region数量
(4)数据写入/读取速度
(5)发送/接受的Snapshot数量(副本之间可能会通过Snapshot同步数据)
(6)Store是否过载
(7)labels标签信息(标签是具备层级关系的一系列Tag,能够感知拓扑信息)
通过使用命令行工具pd-ctl可以查看到TiKV Store的状态信息。
- 每个Raft Group的Leader会定期向PD汇报Region的状态信息
每个Raft Group的Leader和PD之间存在心跳包,用于汇报这个Region的状态,主要包括下面几点信息:
(1)Leader的位置
(2)Followers的位置
(3)掉线副本的个数
(4)数据写入/读取的速度