强化学习(RL)简介及其在大语言模型中的应用
看到huggingface上有个大模型课程,其中有个章节是讲如何构建推理大模型,下面是对应的学习内容。
接下来会用最通俗易懂的方式介绍RL,就算之前完全没接触过也能看懂。会拆解核心概念,看看为什么RL在大语言模型(LLMs)领域变得这么重要。
什么是强化学习(RL)?
想象一下训练一只狗。想教它坐下。可能会说"坐下!",如果狗坐下了,就给它零食和夸奖。如果没坐下,可能轻轻引导它或者再试一次。时间长了,狗就学会了把坐下这个动作和正面奖励(零食和夸奖)联系起来,下次听到"坐下!"就更可能照做。在强化学习里,这种反馈被称为奖励(reward)。
这就是强化学习的基本思路!只不过这里不是狗,而是语言模型(在强化学习中称为智能体 agent),也不是人在训练,而是**环境(environment)**在给反馈。

下面拆解一下RL的几个关键组成部分:
智能体(Agent)
这是学习者。在训狗的例子里,狗就是智能体。在大语言模型的场景下,LLM本身就成了要训练的智能体。智能体负责做决策,并从环境和奖励中学习。
环境(Environment)
这是智能体生存和互动的世界。对狗来说,环境就是家里还有主人。对LLM来说,环境就比较抽象了——可能是与它互动的用户,或者专门为它设置的模拟场景。环境会给智能体提供反馈。
动作(Action)
这是智能体在环境中可以做的选择。狗的动作包括"坐下"、“站立”、"叫"等等。对LLM来说,动作可能是生成句子中的单词、选择回答问题的答案,或者决定如何在对话中回应。
奖励(Reward)
这是环境在智能体执行动作后给出的反馈。奖励通常是数字。
正向奖励就像零食和夸奖——告诉智能体"干得好,做对了!"。
负向奖励(或惩罚)就像轻声说"不对"——告诉智能体"这不太对,试试别的"。对狗来说,零食就是奖励。
对LLM来说,奖励被设计成反映它在特定任务上的表现——比如回答是否有帮助、真实、或者无害。
策略(Policy)
这是智能体选择动作的策略。就像狗理解当听到"坐下!"时该做什么。在RL中,策略才是真正要学习和改进的东西。它是一套规则或函数,告诉智能体在不同情况下该采取什么动作。一开始,策略可能是随机的,但随着智能体学习,策略会越来越擅长选择能带来更高奖励的动作。
RL的过程:试错学习
强化学习通过试错过程进行:
| 步骤 | 过程 | 描述 |
|---|---|---|
| 1. 观察 | 智能体观察环境 | 智能体获取当前状态和周围环境的信息 |
| 2. 动作 | 智能体根据当前策略采取动作 | 使用已学习的策略,智能体决定下一步做什么 |
| 3. 反馈 | 环境给智能体一个奖励 | 智能体收到关于其动作好坏的反馈 |
| 4. 学习 | 智能体根据奖励更新策略 | 智能体调整策略——强化那些带来高奖励的动作,避免那些带来低奖励的动作 |
| 5. 迭代 | 重复这个过程 | 这个循环不断继续,让智能体持续改进决策能力 |
想想学骑自行车。一开始可能会摇摇晃晃摔倒(负向奖励!)。但当成功保持平衡并顺利踩踏板时,感觉很好(正向奖励!)。会根据这些反馈调整动作——稍微倾斜、蹬快一点等等——直到学会骑得很好。RL也类似——通过互动和反馈来学习。
RL在大语言模型(LLMs)中的作用
那么,为什么RL对大语言模型这么重要?
训练真正优秀的LLM其实挺棘手的。可以用互联网上的海量文本训练它们,让它们很擅长预测句子中的下一个词。这样它们就学会了生成流畅且语法正确的文本,这在第2章中有讲到。
但是,仅仅流畅是不够的。大家希望LLM不只是会把词串在一起。还希望它们能够:
- 有帮助: 提供有用且相关的信息。
- 无害: 避免生成有毒、有偏见或有害的内容。
- 符合人类偏好: 以人类觉得自然、有帮助且吸引人的方式回应。
主要依靠从文本数据预测下一个词的预训练LLM方法,在这些方面有时会达不到要求。
虽然监督训练在生成结构化输出方面很出色,但在生成有帮助、无害且符合偏好的响应方面效果可能不太好。这部分在第11章有探讨。
微调后的模型可能会生成流畅且结构化的文本,但这些文本仍然可能存在事实错误、带有偏见,或者没有真正以有帮助的方式回答用户的问题。
强化学习就派上用场了! RL提供了一种方法来微调这些预训练的LLM,让它们更好地达成这些期望的品质。就像给LLM这只狗进行额外训练,让它成为一个表现良好且有帮助的伙伴,而不只是一只会流畅叫唤的狗!
基于人类反馈的强化学习(RLHF)
一种非常流行的对齐语言模型的技术叫做基于人类反馈的强化学习(RLHF)。在RLHF中,人类反馈被用作RL中"奖励"信号的代理。工作原理如下:
-
获取人类偏好: 可能会让人类比较LLM对同一输入提示生成的不同响应,并告诉哪个响应更好。比如,可能会给人类展示"法国的首都是什么?“这个问题的两个不同答案,然后问"哪个答案更好?”。
-
训练奖励模型: 使用这些人类偏好数据来训练一个单独的模型,叫做奖励模型。这个奖励模型学习预测人类会偏好哪种响应。它学会根据有帮助性、无害性以及与人类偏好的对齐程度来给响应打分。
-
用RL微调LLM: 现在把奖励模型当作LLM智能体的环境。LLM生成响应(动作),奖励模型给这些响应打分(提供奖励)。本质上,是在训练LLM生成奖励模型(它从人类偏好中学习)认为好的文本。
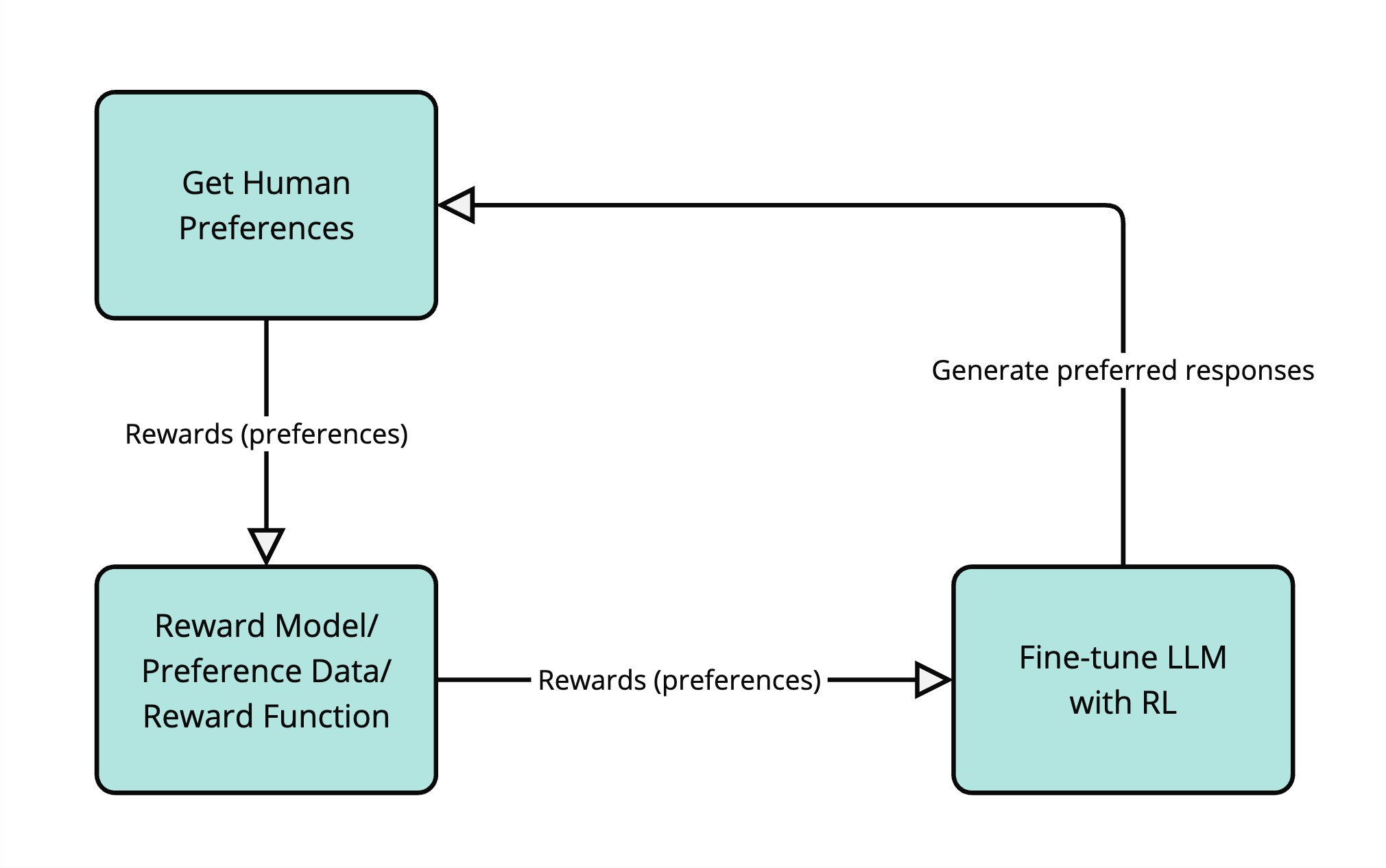
从整体角度看,在LLM中使用RL的好处:
| 好处 | 描述 |
|---|---|
| 更好的控制 | RL让大家对LLM生成的文本类型有更多控制。可以引导它们生成更符合特定目标的文本,比如更有帮助、更有创意或更简洁。 |
| 更好地与人类价值观对齐 | 特别是RLHF,帮助让LLM与复杂且往往主观的人类偏好对齐。很难写出"什么是好答案"的规则,但人类可以轻松判断和比较响应。RLHF让模型从这些人类判断中学习。 |
| 减少不良行为 | RL可以用来减少LLM的负面行为,比如生成有毒语言、传播错误信息或表现出偏见。通过设计惩罚这些行为的奖励,可以促使模型避免它们。 |
基于人类反馈的强化学习已经被用于训练当今许多最流行的LLM,比如OpenAI的GPT-4、谷歌的Gemini和DeepSeek的R1。RLHF有很多种技术,复杂程度和精细度各不相同。在这一章节中,会重点介绍群组相对策略优化(GRPO),这是一种RLHF技术,已被证明能有效训练出有帮助、无害且与人类偏好对齐的LLM。
为什么要关注GRPO(群组相对策略优化)?
RLHF有很多技术,但这门课程聚焦于GRPO,因为它代表了语言模型强化学习的重大进步。
简单看看另外两种流行的RLHF技术:
- 近端策略优化(PPO)
- 直接偏好优化(DPO)
近端策略优化(PPO)是最早的高效RLHF技术之一。它使用策略梯度方法,根据单独的奖励模型给出的奖励来更新策略。
直接偏好优化(DPO)后来作为一种更简单的技术被开发出来,它直接使用偏好数据,不需要单独的奖励模型。本质上,把问题框架化为在被选择和被拒绝的响应之间的分类任务。
DPO和PPO本身是复杂的强化学习算法,这门课程不会涉及。如果想深入了解,可以看看以下资源:
- 近端策略优化
- 直接偏好优化
与DPO和PPO不同,GRPO把相似的样本分组在一起,作为一个组进行比较。这种基于组的方法与其他方法相比,提供了更稳定的梯度和更好的收敛特性。
GRPO不像DPO那样使用偏好数据,而是使用来自模型或函数的奖励信号来比较相似样本的组。
GRPO在获取奖励信号方面很灵活——它可以像PPO那样使用奖励模型,但并不严格要求必须有奖励模型。这是因为GRPO可以整合来自任何能够评估响应质量的函数或模型的奖励信号。
比如,可以使用长度函数来奖励更短的响应,用数学求解器来验证解决方案的正确性,或者用事实正确性函数来奖励更准确的响应。这种灵活性使得GRPO特别适合不同类型的对齐任务。