深入Rust:Box、Rc、Arc智能指针机制解析与实践指南
本文章目录
- 深入Rust:Box、Rc、Arc智能指针机制解析与实践指南
- 一、先理清:智能指针到底是什么?
- 二、Box<T>:最“朴素”的智能指针,解决“单一所有权的堆存储”
- 1. Box的底层机制:栈指针+堆数据
- 2. Box的3个核心使用场景(必学!)
- 场景1:打破“递归类型的大小不确定性”
- 场景2:实现Trait Object的“动态分发”
- 场景3:把大类型移到堆上,减少栈占用
- 三、Rc<T>:单线程的“共享所有权”,解决“多组件共享只读数据”
- 1. Rc的底层机制:堆数据+引用计数
- 2. Rc的“死穴”:循环引用与Weak<T>的拯救
- 3. Rc的局限性:不能跨线程
- 四、Arc<T>:多线程的“共享所有权”,解决“跨线程共享只读数据”
- 1. Arc与Rc的核心区别:原子操作
- 2. Arc的实践:多线程共享不可变数据
- 3. Arc的扩展:共享可变数据?配合Mutex/RwLock
- 五、一张表理清:Box、Rc、Arc怎么选?
- 六、实战总结:3个高频场景的最佳实践
- 1. 场景1:单线程内的“树形结构”(如目录结构)
- 2. 场景2:多线程的“共享配置/缓存”(只读)
- 3. 场景3:多线程的“共享可变数据”(如计数器、任务队列)
- 七、常见误区与避坑指南
- 八、最后:智能指针的设计哲学
深入Rust:Box、Rc、Arc智能指针机制解析与实践指南
在Rust开发中,“所有权”是绕不开的核心规则——它保证了内存安全,但实际场景中总需要更灵活的内存管理:比如把大对象移到堆上、让多个组件共享同一份数据、在多线程间传递数据。这时候,智能指针就成了“所有权规则的补充工具”,而Box、Rc、Arc正是最基础也最常用的三款。今天咱们从“解决什么问题”“底层机制”“实践场景”三个维度,把这三个智能指针讲透,最后还会给可直接复用的代码案例,帮你真正用对、用好它们。
一、先理清:智能指针到底是什么?
在Rust里,“指针”只是个地址(比如&T是借用指针),而“智能指针”是“指针+额外逻辑”的封装——比如自动释放内存、记录引用次数。Box、Rc、Arc的本质,就是通过不同的“额外逻辑”,解决不同场景下的内存管理问题:
- Box:给“单一所有权”加个“堆存储”功能;
- Rc:给“单一所有权”加个“共享计数”功能(单线程);
- Arc:给“Rc”加个“线程安全”功能(多线程)。
先从最简单的Box说起。
二、Box:最“朴素”的智能指针,解决“单一所有权的堆存储”
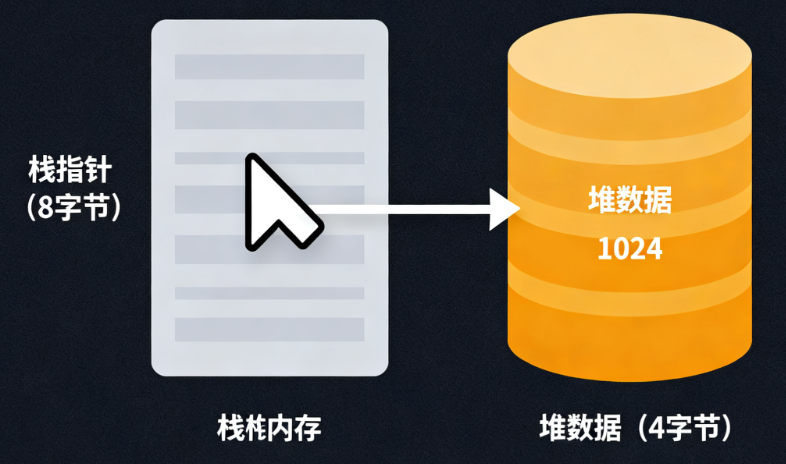
Box是Rust里最基础的智能指针,它的核心作用只有一个:把数据从栈移到堆上,栈上只留一个指向堆数据的指针。
1. Box的底层机制:栈指针+堆数据
Box的内存布局特别简单:
- 栈上:一个8字节的指针(64位系统),指向堆内存;
- 堆上:实际存储的数据(比如
i32、结构体等)。
举个例子:
fn main() {// x在栈上(4字节)let x = 1024;// 把x移到堆上,box_x是栈上的指针(8字节),指向堆上的1024let box_x = Box::new(x);println!("栈指针指向的堆数据:{}", box_x); // 自动解引用,不用手动*
}
// 当box_x离开作用域:先释放堆上的1024,再释放栈上的指针(自动执行Drop)
这里要注意:Box是单一所有权——和普通变量一样,所有权会随着赋值/传递转移,且克隆Box时会做“深拷贝”(复制堆上的数据),所以它不适合“共享数据”场景。
2. Box的3个核心使用场景(必学!)
Box看似简单,但有三个场景是“非它不可”:
场景1:打破“递归类型的大小不确定性”
Rust编译器需要在编译时确定每个类型的大小,但递归类型(比如链表节点)会让大小“无限嵌套”。比如下面的代码会编译报错:
// 错误:递归类型`List`没有确定的大小
enum List {Cons(i32, List), // 每个Cons包含一个List,大小无限Nil,
}
这时候Box就能救场:因为Box是“指针”,指针大小是固定的(8字节),把List换成Box<List>,类型大小就确定了:
// 正确:Box<List>是指针,大小固定
enum List {Cons(i32, Box<List>),Nil,
}fn main() {// 构建链表:1 -> 2 -> 3 -> Nillet list = List::Cons(1, Box::new(List::Cons(2, Box::new(List::Cons(3, Box::new(List::Nil))))));
}
这是Box最经典的用法之一,也是理解“递归数据结构”的关键。
场景2:实现Trait Object的“动态分发”
当需要存储“不同类型但实现同一Trait”的值时(比如不同形状的图形),可以用Box<dyn Trait>实现动态分发:
// 定义Trait
trait Shape {fn area(&self) -> f64;
}// 实现Trait的具体类型
struct Circle(f64); // 半径
struct Square(f64); // 边长impl Shape for Circle {fn area(&self) -> f64 {std::f64::consts::PI * self.0 * self.0}
}impl Shape for Square {fn area(&self) -> f64 {self.0 * self.0}
}fn main() {// 用Box<dyn Shape>存储不同类型的Shapelet shapes: Vec<Box<dyn Shape>> = vec![Box::new(Circle(2.0)),Box::new(Square(3.0)),];// 遍历调用area,动态确定执行哪个实现for shape in shapes {println!("面积:{:.2}", shape.area()); // 输出:6.28、9.00}
}
这里Box<dyn Shape>的作用是“擦除具体类型”,让不同类型能存进同一个集合,运行时再根据实际类型调用方法。
场景3:把大类型移到堆上,减少栈占用
栈空间有限(通常几MB),如果有大类型(比如几百KB的结构体),直接放栈上可能导致栈溢出。用Box把它移到堆上,栈上只留一个指针:
// 大结构体(假设每个字段占1KB,总大小4KB)
struct BigData {a: [u8; 1024],b: [u8; 1024],c: [u8; 1024],d: [u8; 1024],
}fn main() {// 直接创建:BigData在栈上(4KB)// let big = BigData { a: [0;1024], b: [0;1024], c: [0;1024], d: [0;1024] };// 用Box创建:BigData在堆上,栈上只占8字节指针let big = Box::new(BigData { a: [0;1024], b: [0;1024], c: [0;1024], d: [0;1024] });
}
这在函数参数传递、集合存储大类型时特别有用。
三、Rc:单线程的“共享所有权”,解决“多组件共享只读数据”
Box是单一所有权,但实际开发中经常需要“多个组件共享同一份数据”(比如多个页面共享应用配置)。Rc(Reference Counting,引用计数)就是为这个场景设计的——它让多个所有者共享同一份堆数据,通过“计数”确保数据在最后一个所有者离开时才释放。
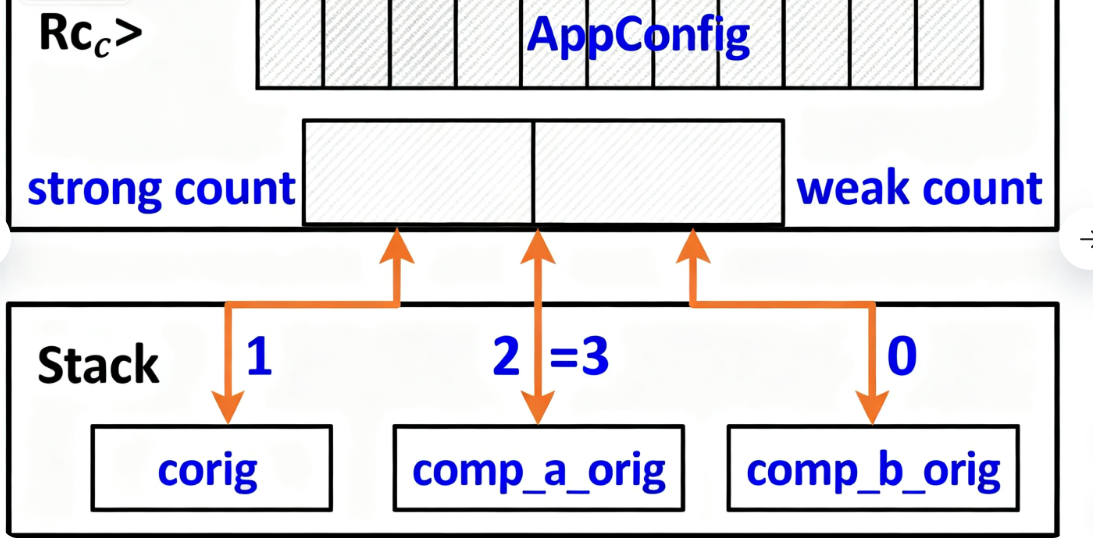
1. Rc的底层机制:堆数据+引用计数
Rc的内存布局比Box多了“引用计数”:
- 栈上:多个Rc指针,都指向同一块堆内存;
- 堆上:存储两部分——实际数据、两个计数器(
strong_count强引用计数、weak_count弱引用计数)。
核心规则:
- 每次克隆Rc(
Rc::clone(&rc)),strong_count加1(浅拷贝,不复制数据); - 每次Rc离开作用域,
strong_count减1; - 当
strong_count降到0时,释放堆上的实际数据; weak_count用于解决“循环引用”(后面讲),不影响数据释放。
举个“多组件共享配置”的例子:
use std::rc::Rc;// 共享的配置数据
struct AppConfig {app_name: String,max_conn: u32,
}// 组件A:需要使用配置
struct ComponentA {config: Rc<AppConfig>,
}// 组件B:也需要使用配置
struct ComponentB {config: Rc<AppConfig>,
}fn main() {// 创建配置,用Rc包裹let config = Rc::new(AppConfig {app_name: "Rust App".to_string(),max_conn: 100,});// 打印初始强引用计数:1println!("初始strong_count: {}", Rc::strong_count(&config));// 组件A和B共享配置:克隆Rc,强引用计数加1let comp_a = ComponentA { config: Rc::clone(&config) };let comp_b = ComponentB { config: Rc::clone(&config) };// 此时strong_count: 3(config本身+comp_a+comp_b)println!("共享后strong_count: {}", Rc::strong_count(&config));// 访问共享配置println!("ComponentA读取配置:{}", comp_a.config.app_name);println!("ComponentB读取配置:{}", comp_b.config.max_conn);
}// 离开main作用域时:
// 1. comp_b先销毁,strong_count→2;
// 2. comp_a再销毁,strong_count→1;
// 3. config最后销毁,strong_count→0,释放堆上的AppConfig。
这个例子里,三个Rc(config、comp_a.config、comp_b.config)共享同一份AppConfig,且克隆时只加计数,不复制数据——这是Rc比Box高效的核心场景。
2. Rc的“死穴”:循环引用与Weak的拯救
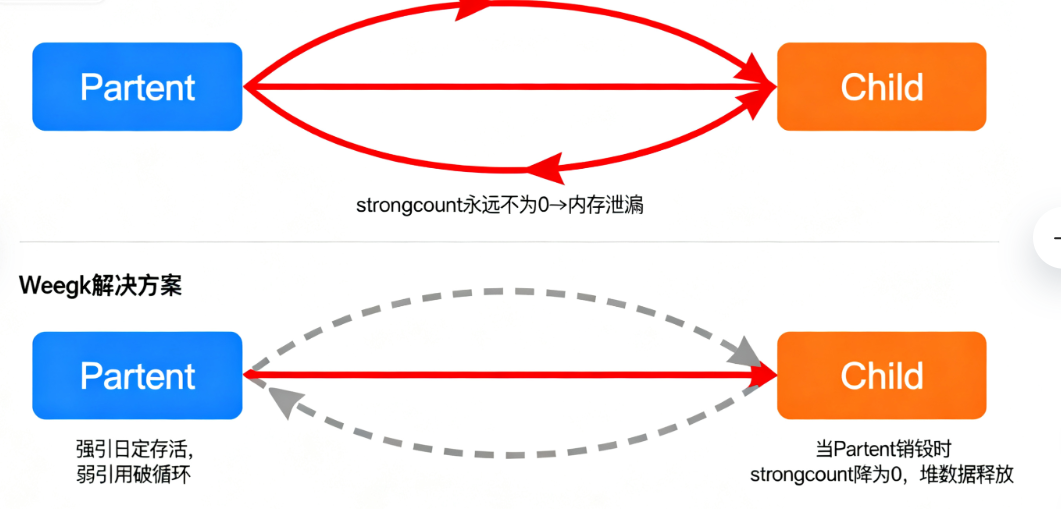
Rc有个致命问题:如果两个Rc互相引用(循环引用),会导致strong_count永远无法降到0,数据永远不释放,造成内存泄漏。比如:
use std::rc::Rc;
use std::cell::RefCell; // 用于内部可变性,后面会用到// 父子节点互相引用
struct Parent {name: String,child: RefCell<Option<Rc<Child>>>, // 父引用子(强引用)
}struct Child {name: String,parent: RefCell<Option<Rc<Parent>>>, // 子引用父(强引用)
}fn main() {let parent = Rc::new(Parent {name: "Parent".to_string(),child: RefCell::new(None),});let child = Rc::new(Child {name: "Child".to_string(),parent: RefCell::new(Some(Rc::clone(&parent))),});// 父引用子,形成循环*parent.child.borrow_mut() = Some(Rc::clone(&child));// 此时:parent的strong_count=2(自身+child.parent)// child的strong_count=2(自身+parent.child)println!("parent strong_count: {}", Rc::strong_count(&parent));println!("child strong_count: {}", Rc::strong_count(&child));
}// 离开main作用域时:
// parent销毁→strong_count=1(child.parent还在);
// child销毁→strong_count=1(parent.child还在);
// 堆上的Parent和Child永远不释放,内存泄漏!
解决这个问题的关键是Weak<T>——它是Rc的“弱引用”,克隆时只增加weak_count,不影响strong_count,也不阻止数据释放。修改上面的代码,把“子引用父”改成Weak:
use std::rc::{Rc, Weak};
use std::cell::RefCell;struct Parent {name: String,child: RefCell<Option<Rc<Child>>>, // 父→子:强引用
}struct Child {name: String,parent: RefCell<Option<Weak<Parent>>>, // 子→父:弱引用
}fn main() {let parent = Rc::new(Parent {name: "Parent".to_string(),child: RefCell::new(None),});let child = Rc::new(Child {name: "Child".to_string(),parent: RefCell::new(Some(Rc::downgrade(&parent))), // Rc→Weak:downgrade方法});*parent.child.borrow_mut() = Some(Rc::clone(&child));// 此时:parent的strong_count=1(自身),weak_count=1(child.parent)// child的strong_count=2(自身+parent.child)println!("parent strong_count: {}", Rc::strong_count(&parent));println!("parent weak_count: {}", Rc::weak_count(&parent));// 通过Weak获取父节点:需要upgrade(),返回Option<Rc<Parent>>(可能失败)if let Some(p) = child.parent.borrow().as_ref().and_then(|w| w.upgrade()) {println!("Child's parent: {}", p.name); // 输出:Child's parent: Parent}
}// 离开main作用域时:
// 1. parent销毁→strong_count=0,释放堆上的Parent;
// 2. child的strong_count=1(parent.child已随Parent释放),child销毁→strong_count=0,释放堆上的Child;
// 3. 无内存泄漏!
这里的核心是“强弱引用分离”:父对儿用强引用(确保子不被提前释放),子对父用弱引用(不阻止父释放)。实际开发中,只要涉及Rc的循环场景(比如树形结构、双向链表),都要用Weak来打破循环。
3. Rc的局限性:不能跨线程
Rc的引用计数是普通的usize,多线程下修改会有“数据竞争”(两个线程同时改计数,导致计数错误),所以Rust直接禁止Rc跨线程——编译时就会报错:
use std::rc::Rc;
use std::thread;fn main() {let rc_data = Rc::new("不能跨线程的Rc数据".to_string());// 错误:`Rc<String>` cannot be sent between threads safelylet handle = thread::spawn(move || {println!("线程中访问:{}", rc_data);});handle.join().unwrap();
}
这时候,就需要Arc出场了。
四、Arc:多线程的“共享所有权”,解决“跨线程共享只读数据”
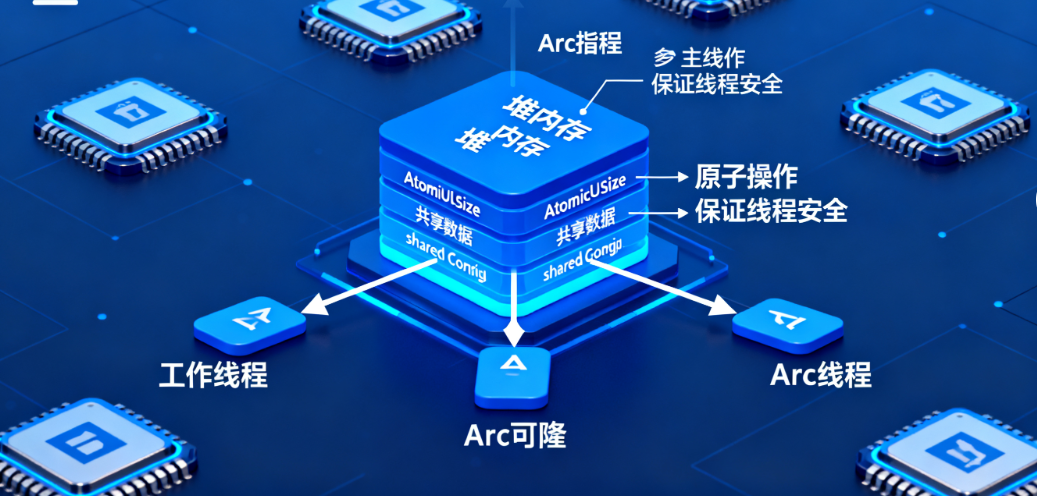
Arc(Atomic Reference Counting,原子引用计数)是Rc的“线程安全版”——它把Rc的普通计数换成了“原子类型”(AtomicUsize),通过原子操作保证多线程下计数的安全性。
1. Arc与Rc的核心区别:原子操作
原子操作是“不可中断的操作”,多线程下修改原子类型不会出现数据竞争。Arc的内存布局和Rc几乎一样,唯一区别是“计数类型”:
- Rc:
strong_count: usize(普通整数,非线程安全); - Arc:
strong_count: AtomicUsize(原子整数,线程安全)。
正因为原子操作有额外开销,所以单线程场景用Rc,多线程场景才用Arc——不要为了“线程安全”而浪费性能。
2. Arc的实践:多线程共享不可变数据
下面的例子展示了多线程共享配置数据,Arc保证了线程安全:
use std::sync::Arc; // Arc在std::sync模块下
use std::thread;
use std::time::Duration;fn main() {// 创建Arc包裹的共享数据(不可变)let shared_config = Arc::new(serde_json::json!({"app_name": "Multi-thread App","log_level": "info","max_workers": 4}));let mut handles = vec![];// 启动3个线程,共享configfor worker_id in 0..3 {// 克隆Arc:原子操作,增加引用计数(浅拷贝)let config_clone = Arc::clone(&shared_config);let handle = thread::spawn(move || {// 线程中读取共享配置println!("工作线程{}:应用名={}, 日志级别={}",worker_id,config_clone["app_name"],config_clone["log_level"]);// 模拟工作thread::sleep(Duration::millis(200));});handles.push(handle);}// 等待所有线程结束for handle in handles {handle.join().unwrap();}// 所有线程结束后,shared_config的引用计数降为1,离开作用域时释放println!("主线程:所有线程已结束,共享配置即将释放");
}
运行这个代码,会看到3个线程都能安全读取共享配置,且没有数据竞争——这就是Arc的核心价值。
3. Arc的扩展:共享可变数据?配合Mutex/RwLock
Arc本身只能共享“不可变数据”(因为多线程下可变数据会有安全问题),如果需要共享“可变数据”,必须配合“同步原语”(比如Mutex或RwLock):
Mutex:互斥锁,同一时间只有一个线程能修改数据(写优先);RwLock:读写锁,多个线程可同时读,同一时间只有一个线程能写(读优先)。
下面是“多线程共享可变计数器”的例子(Arc+Mutex):
use std::sync::{Arc, Mutex};
use std::thread;fn main() {// Arc包裹Mutex,Mutex包裹可变数据(i32)let counter = Arc::new(Mutex::new(0));let mut handles = vec![];for _ in 0..5 {let counter_clone = Arc::clone(&counter);let handle = thread::spawn(move || {// 锁定Mutex:lock()返回Result,unwrap()简化处理let mut num = counter_clone.lock().unwrap();// 修改数据(此时其他线程会阻塞,直到解锁)*num += 1;println!("当前计数:{}", num);// 离开作用域时,num自动解锁(MutexGuard的Drop实现)});handles.push(handle);}for handle in handles {handle.join().unwrap();}// 最终计数:5println!("最终计数:{}", *counter.lock().unwrap());
}
这里的关键是Arc<Mutex<T>>:Arc负责跨线程共享,Mutex负责保证数据修改的线程安全。如果是“多读少写”场景,把Mutex换成RwLock性能会更好。
五、一张表理清:Box、Rc、Arc怎么选?
很多同学用智能指针时会“选错”,核心是没理清它们的适用边界。下面这张对比表,帮你快速定位场景:
| 维度 | Box | Rc | Arc |
|---|---|---|---|
| 所有权模型 | 单一所有权(不可共享) | 共享所有权(多所有者) | 共享所有权(多所有者) |
| 线程安全 | 不涉及(单一线程内使用) | 否(禁止跨线程) | 是(原子操作,支持跨线程) |
| 引用计数 | 无 | 有(普通usize,无开销) | 有(AtomicUsize,有原子开销) |
| 克隆行为 | 深拷贝(复制堆数据,开销大) | 浅拷贝(只加计数,开销小) | 浅拷贝(只加原子计数,开销中) |
| 核心作用 | 堆存储、打破递归、动态分发 | 单线程共享只读数据 | 多线程共享只读/可变数据(需配合同步原语) |
| 适用场景 | 单一所有者的堆数据、大类型、Trait Object | 单线程多组件共享配置、不可变状态 | 多线程共享配置、缓存、可变计数器 |
六、实战总结:3个高频场景的最佳实践
最后,结合实际开发中的高频场景,给你可直接复用的最佳实践:
1. 场景1:单线程内的“树形结构”(如目录结构)
- 选择:
Rc<Node>(父对儿强引用)+Weak<Node>(子对父弱引用); - 理由:避免循环引用,单线程下无原子开销;
- 代码模板:参考前面“Parent-Child”的Weak案例。
2. 场景2:多线程的“共享配置/缓存”(只读)
- 选择:
Arc<T>(T是不可变类型,如Config、Json); - 理由:跨线程安全,只读场景无需同步原语,性能高;
- 代码模板:参考前面“多线程共享配置”的Arc案例。
3. 场景3:多线程的“共享可变数据”(如计数器、任务队列)
- 选择:
Arc<Mutex<T>>(写多)或Arc<RwLock<T>>(读多); - 理由:Arc负责跨线程,Mutex/RwLock负责数据安全;
- 代码模板:参考前面“多线程计数器”的Arc+Mutex案例。
七、常见误区与避坑指南
- 滥用Box:把小类型(如
i32、bool)放到Box里——没必要,堆分配开销比栈访问大; - 用Rc跨线程:编译报错后才想起换Arc——记住“单线程Rc,多线程Arc”;
- 忽略Arc的原子开销:单线程场景用Arc代替Rc——原子操作比普通计数慢2-3倍,别浪费性能;
- Arc直接共享可变数据:以为Arc能直接改数据——必须配合Mutex/RwLock,否则编译报错;
- 忘记Rc的循环引用:用Rc做双向结构时不写Weak——必然内存泄漏,记住“强引用定存活,弱引用破循环”。
八、最后:智能指针的设计哲学
Rust的智能指针,不是“绕过所有权”,而是“在所有权规则下提供灵活的内存管理工具”。Box解决“堆存储”,Rc解决“单线程共享”,Arc解决“多线程共享”——每个指针都有明确的适用场景,没有“万能指针”。
理解它们的底层机制(内存布局、引用计数、原子操作),再结合实际场景选择,才能写出“安全又高效”的Rust代码。
喜欢就请点个关注,谢谢!!!!
