C++ primier plus 第七节 函数探幽第一部分
系列文章目录
C++ primer plus 第一节 步入C++-CSDN博客
C++ primer plus 第二节 hello world刨析-CSDN博客
C++ primer plus 第三节 数据处理-CSDN博客
C++ primer plus 第四节 复合类型-CSDN博客
C++ primer plus 第五节 循环-CSDN博客
目录
系列文章目录
前言
一 内联函数
二 引用变量
总结
前言
这一篇文章主要是讲解内联函数,引用的深入理解
尤其是引用,这个东西在类里面很经常见到和使用,基本都是,如果没有深入理解,后续学习很难
作者深有体会,之前是按照b站课上学的,结果还是一头雾水
一 内联函数
内联函数的出现
理解内联函数的时候,需要理解程序是在电脑里面怎么进行运转的,可以先看看这个,去底层知道电脑是如何运转的
C底层 函数栈帧-CSDN博客
我知道了电脑底层的运算逻辑之后,我们就知道当我们调用函数的时候,上面的汇编语言会告诉我们,我们是需要写这个汇编语言进行调用的,还有返回的时候,其实也是需要汇编语言进行书,把返回值进行保存,然后再进行赋值,那么这里就需要开销很多的时间,所以这个时候内联还是就诞生了
内联函数的介绍
首先内联函数就是语法十分简单就是在函数的前面加上inline,这可以告诉编译器这个是内联函数,
但是不是声明就是会变成内联函数的,但是C++编译器进行优化,也会自动把你的函数变成内联函数,以提高计算机的效率
首先内联函数就是不进行函数调用和返回等操作,直接进行函数的使用,这个是大大减少程序的开销的,所以我们在写程序的时候是需要考虑函数的效率的问题
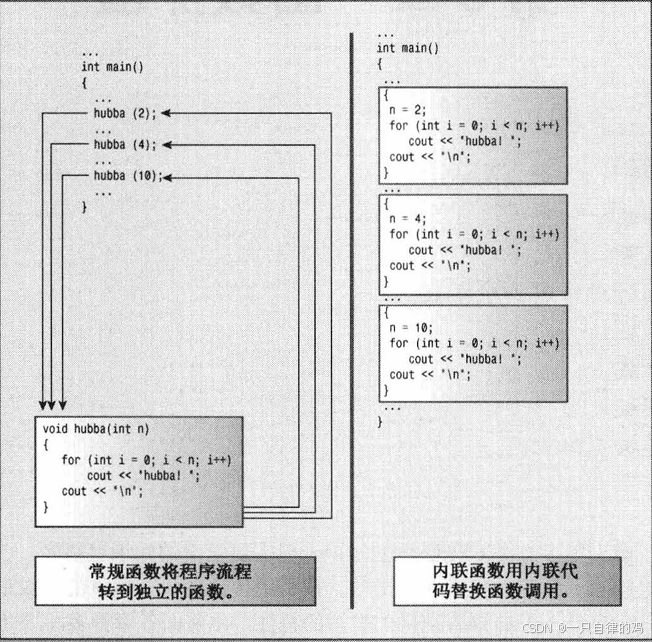
这个是内联还是得示意图,里面简述了内联函数和普通函数得区别
其实就是内联函数在编译的时候,直接把这个内联函数嵌套了进去,可以类似于宏,但是安全性,内联函数比宏还是高很多很多的
当我们知道内联函数的时候,就要考虑这个内联函数什么时候使用,什么时候不使用
我们就以一个很简单的例子
情况1:我们去吃饭,我们如果要走很远去吃饭,但是吃饭的重要性又没那么高,那么我们不如就直接把路程省掉,直接去最近的地方进行吃饭,那么就是内联函数,把路程的开销进行省掉了
情况2:我们去吃饭,如果饭局很重要,就是决定了自己的自己的工作啥的,又或者是谈合作,这个时候,吃饭的重要性远远大于自己过去的路程,那么这个时候就直接使用普通函数就好了
所以选择什么就是根据你的实际情况
如果调用函数的时间远远大于函数使用的时间的话,就是是使用内联函数
如果调用函数的时间远远小于函数使用的时间的话,那就是使用普通函数
内联函数与宏
内联函数的安全性是要比宏要高很多的
inline 工具是 C++新增的特性
C 语言使用预处理器语句#defme 来提供宏一一内联代码的原始实现
例如,下面是一个计算平方的宏
#define SQUARE (X) X*X
这并不是通过传递参数实现的,而是通过文本替换来实现的——x是"参数"的符号标记a = SQUARE(5.0); is replaced by a = 5.0*5.0; b = SQUARE(4. 5 + 7.5) ; is replaced by b = 4.5 + 7 .5 * 4.5 + 7.5; d = SQUARE(c++) ; is replaced by d = c++*c++;上述示例只有第一个能正常工作,可以通过使用括号来进行改进:
Udefine SQUARE (X) ((X) 舍 (X) )
但仍然存在这样的问题. 即宏不能按值传递。 即使使用新的定义. SQUARE ( C++ )仍将c递增两次,内联函数square( )计算 c 的结果,传递它,以计算其平方佳,然后将c递增一次。 这里的目的不是演示如何编写C宏,而是要指出,如果使用 C语言的宏执行了类似函数的功能,应考 虑将它们转换为 C++内联函数
二 引用变量
C++新增了一个复合类型——引用变量
如果将一个变量a作为element变量的引用,则可以交替使用a和element来表示该变量
这种别名有何作用呢? 是否能帮助那些不知道如何选择变量名的人呢?
其实引用变量的主要作用是用作函数的形参
通过将引用变量作为参数,函数直接使用原始的数据,而不是创建副本
所以这也跟指针很类似
创建一个引用变量#include<iostream> using namespace std; int main() { int res = 0; int& a = res; cout << res << endl; return 0; }对引用变量的理解
接下来我们就看看用引用变量写一个小的程序证明一下引用是对变量取别名和是否相同#include<iostream> using namespace std; int main() { int res = 0; int& a = res; cout << "res = "; cout << res << endl; cout << "a = "; cout << a << endl; a++; cout << "res = "; cout << res << endl; cout << "a = "; cout << a << endl; cout << "res address = "; cout << &res << endl; cout << "a address = "; cout << &a << endl; return 0; }
我们可以看到这个最最终的结果
我对这个引用变量进行操作的话,其实这个原来的变量也进行了改变
然后我们来判断他们是否是同一个东西,就是看他们的地址是否相同,这个是很普遍的方法
然后打印出来的地址也是相同的
但是为了进一步验证,我们这个时候使用变量来试试int res = 0; int& a = res; cout << "res = "; cout << res << endl; cout << "a = "; cout << a << endl; int b = 100; a = b; cout << b << endl; cout << a << endl;
我们可以看到这个a也变成100了,这个b也是100
那是不是等于一个变量就直接改变了别名,这个好像跟我们之前所想的不一样呀?我们进一步研究#include<iostream> using namespace std; int main() { int res = 0; int& a = res; cout << "res = "; cout << res << endl; cout << "a = "; cout << a << endl; int b = 100; a = b; cout << b << endl; cout << a << endl; cout << "res address = "; cout << &res << endl; cout << "a address = "; cout << &a << endl; cout << "b address" << endl; cout << &b << endl; return 0; }
我们不难看出这个结果,这个res的地址还是a的地址,并没有改变,所以又肯定了我们上面的想法,这是一直是那个变量别名
✅小结
好了了解上面的程序和知识点,我们来总结一下我们所学的
首先这个引用就是给别的变量取别名,从地址相同可以看出
我们是无法改动这个引用变量的,可以从第二个位置可以看出
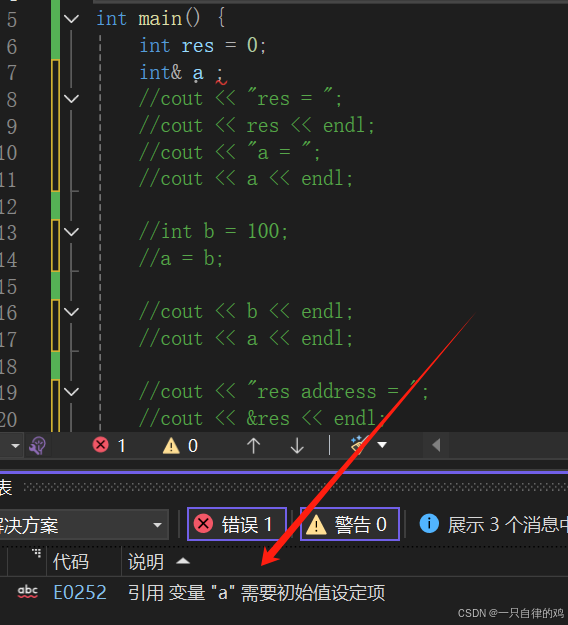
注意,我们在定义引用变量的时候就要初始化,不初始化会报错
上面这个图可以看到整个报错。就是你不给他初始化会报错,所以这个别名是在我们在定义的时候就已经决定了
引用与指针的理解
引用看上去很像伪装表示的指针(其中, *解除引用运算符被隐式理解〉。实际上,引用还是 不同于指针的。除了表示法不同外,还有其他的差别。例如,差别之一是,必须在声明引用时将其初始化, 而不能像指针那样,先声明,再赋值
引用更接近 const 指针,必须在创建时进行初始化, 一旦与某个变量关联起来,就将一直效忠于它。 也就是说: int & rodents = rats; 实际上是下述代码的伪装表示:
ìnt * const pr = &rats; 其中,引用rodents 扮演的角色与表达式*pr相同
接下来就引用用作函数参数
我们不难看出这个编程结果进行互换,即使没有指针也是进行了互换,这个叫引用传递
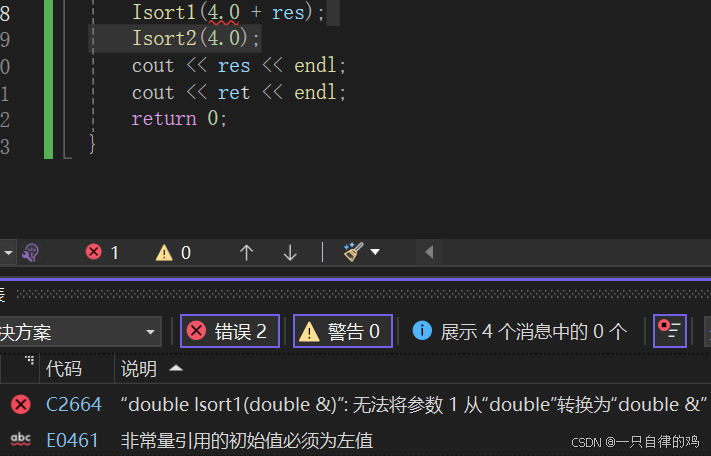
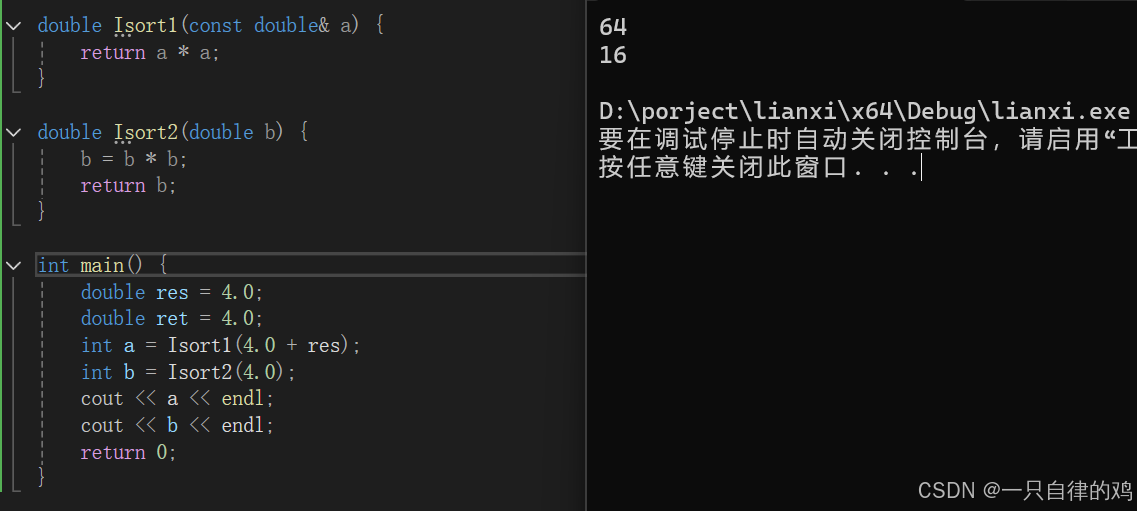
但是我们改动一下我们这个上面的代码#include<iostream> using namespace std; double Isort1(double& a) { a = a * a; return a; } double Isort2(double b) { b = b * b; return b; } int main() { double res = 4.0; double ret = 4.0; Isort1(res); Isort2(ret); cout << res << endl; cout << ret << endl; return 0; }我们把一个变量进行修改
我们可以看这两个例子我们分别改为表达式和常量的话是会进行报错的
左值是什么呢?左值参数是可被引用的数据对象,例如,变量、数组元素、结构成员、引用和解除引 用的指针都是左值
现在考虑如下代码double side = 3.0; double * pd = &side; double & rd = side; long edge = 5L; double lens [4J = { 2.0, 5.0, 10.0, 12.0}; double c1 = refcube(side); double c2 = refcube(lens[2J); double c3 = refcube(rd); double c4 = refcube(*pd); double c5 = refcube(edge); double c6 = refcube(7.0); double c7 = refcube(side + 10.0) ;参数side、 lens[2]、 rd 和*pd 都是有名称的、 double 类型的数据对象,因此可以为其创建引用,而不需 要临时变量(还记得吗,数组元素的行为与同类型的变量类似)。然而, edge虽然是变量,类型却不正确, double 引用不能指向 long。另一方面,参数 7.0和 side+ 10.0 的类型都正确,但没有名称,在这些情况下, 编译器都将生成一个临时匿名变量,并让ra指向它。这些临时变量只在函数调用期间存在,此后编译器便可以随意将其删除
通过这个我们可以知道,在我们没有确定具体的变量的时候吗,是会有一个临时的变量进行存储我们的值的,所以我们就要考虑这个C++的引用会不会也有这个功能,答案是有的
我们只需要在上面加上这个const就可以了,什么意思呢?就是这个我们输入的表达式,没有具体的一个变量名称,那么编译器就会给这个表达式创建一个临时变量进行存储,那么这个引用就可以进行指向了
但是为什么一定要加const呢?你可以这这么理解就是这个常量是无法修改的,但是不加const是可以对原来的值进行修改的,所以为了严谨性,就要加
应尽可能使用 const
将引用参数声明为常量数据的引用的理由有三个:
• 使用 const 可以避免无意中修改数据的编程错误
• 使用 const使函数能够处理 const和非 const 实参,否则将只能接受非 const数据
• 使用 const 引用使函数能够正确生成并使用临时变量。 因此,应尽可能将引用形参声明为 const
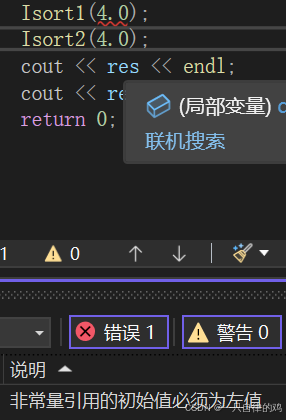
为什么会有无意间修改值呢?
下面就是例子

总结
我们学习了内联函数的诞生和内联函数的用法和对比与宏的优点
其实内联函数相比较普通函数中间的过程都有,比如传值,但是宏是简单的替换
还有就是引用的定义
就是引用,我们在使用的时候,这个就是给一个变量进行取别名,然后可以不用创建副本直接对原型进行修改,在创建引用的时候就需要进行初始化,要不然会报错
然后学习了指针与引用的区别
最后学习引用的传值,就是在传常量和表达式的时候,是需要加上const的,const的包容性很强,无论const与非const都可以进行操作,而且安全性质很高