训练 FLUX LoRA模型安装与部署
在如今日新月异的 AI 辅助设计领域,LoRA(Low-Rank Adaptation)技术的应用愈发广泛,它为模型的个性化训练提供了强大助力。此前,我曾专门撰写文章,详细记录了如何快速训练 SDXL 模型的 LoRA,感兴趣的朋友不妨回顾一下:# 【AI 辅助设计】记一次图标风格 LoRA 训练。而近期,我一直密切关注着 FLUX LoRA 的训练技术和相关动态。毕竟,随着 AI 技术的不断演进,FLUX 已逐渐成为行业发展的大势所趋,曾经辉煌一时的 SD 时代正悄然远去。
令人欣喜的是,开源社区的蓬勃发展与众多技术大佬的不懈努力,为我们带来了诸多便利。如今,即便是配备 16G VRAM 的普通家用电脑,也能够轻松胜任 FLUX 的 LoRA 训练任务。今天,我将亲自使用 fluxgym 这一方法进行 LoRA 训练,并详尽记录整个过程,希望能为大家提供一些参考和帮助。
一、fluxgym:一款卓越的前端 LoRA 训练 web 应用
fluxgym 是由才华横溢的 cocktail peanut 整合开发的一款易于使用的前端 LoRA 训练 web 应用,其背后依托的是强大的 Kohya Scripts。这款应用具备两大显著优点,使其在众多训练工具中脱颖而出:
-
显著降低显存占用:fluxgym 对硬件的要求相对较低,能够支持 12GB、16GB、20GB 等不同显存容量的显卡。这意味着,即使您的电脑配置并非顶级,也有机会进行 FLUX LoRA 的训练,极大地降低了技术门槛,让更多的爱好者能够参与其中。
-
超级简单的用户界面和流程:该应用的用户界面设计简洁直观,操作流程清晰明了。无论是新手还是有一定经验的用户,都能够快速上手,轻松完成训练任务。
不过,需要注意的是,目前 fluxgym 仅支持 NVIDIA 的显卡。如果您想进一步了解或使用该应用,可以访问其项目地址:GitHub - cocktailpeanut/fluxgym: Dead simple FLUX LoRA training UI with LOW VRAM support 。凭借其出色的易用性,在 X 平台上,越来越多的推友开始使用 fluxgym 来训练 LoRA,这也从侧面证明了它的受欢迎程度。
二、安装 fluxgym:详细步骤解析
1. 克隆项目:首先,我们需要克隆 Fluxgym 和 kohya-ss/sd-scripts 这两个项目。具体操作如下:
git clone https://github.com/cocktailpeanut/fluxgym cd fluxgym git clone -b sd3 https://github.com/kohya-ss/sd-scripts
注意是sd3版本的。
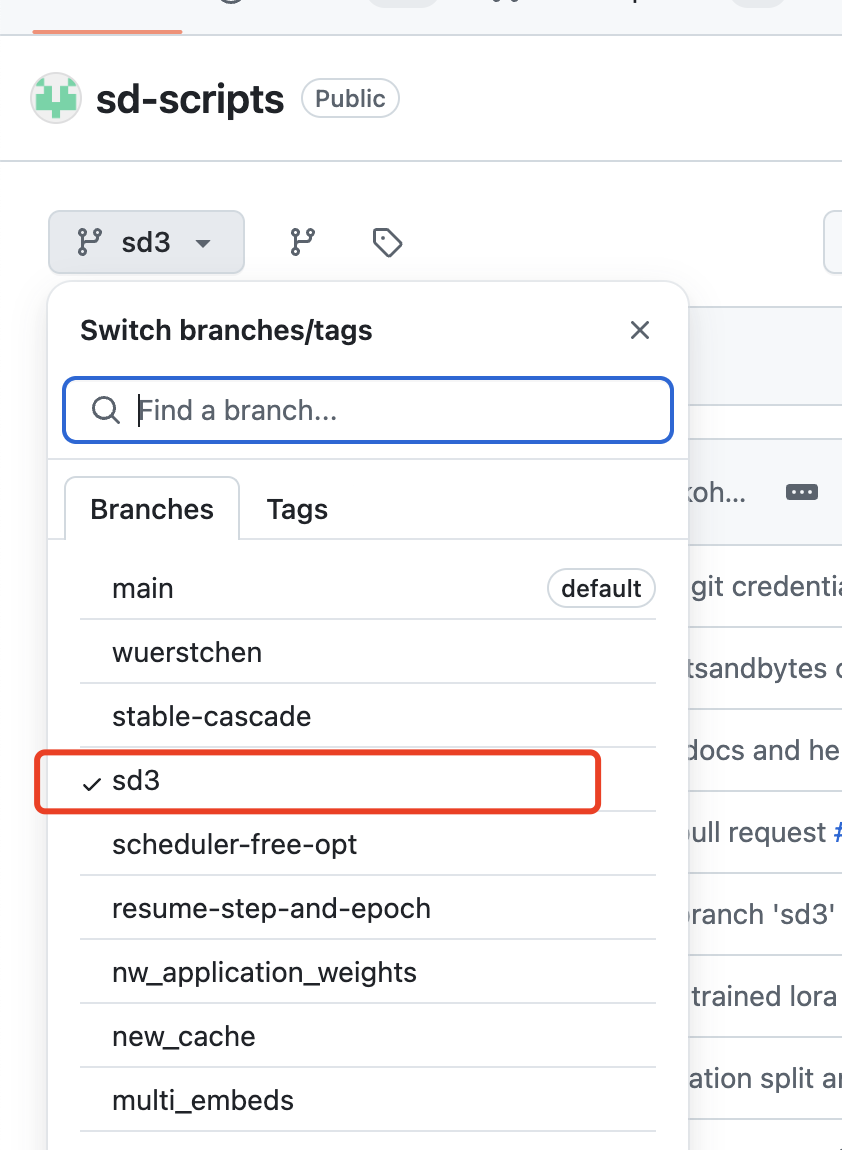
完成上述操作后,您的文件夹结构将呈现如下形式:
/fluxgym app.py requirements.txt /sd-scripts
2. 创建 conda 环境:官方推荐使用 venv 虚拟环境,但为了方便起见,我在这里选择直接使用 conda 环境进行安装。执行以下命令创建名为 fluxgym 的 conda 环境,并指定 Python 版本为 3.10:
conda create -n fluxgym python=3.10
3. 激活环境:环境创建完成后,使用以下命令激活 fluxgym 环境:
conda activate fluxgym
4. 进入 sd-scripts,并安装依赖:进入 sd-scripts 目录,并安装相应的依赖项:
cd sd-scripts pip install -r requirements.txt
5. 然后fluxgym目录下,在安装依赖:
cd .. pip install -r requirements.txt
6. 安装 pytorch:最后,安装 pytorch版本,以确保应用的正常运行(这是最关键的我的CUDA是11.2但是可以安装11.8的,因为是python3.10,所以torch的版本一定是2.0.0以上的,我的经验是尽量安装2.X.1的版本,我安装的是2.4.1+cu118)
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu118
在下面链接找到适合自己的版本的,
Previous PyTorch Versions | PyTorch
安装完后,大概率,部分用户界面会出现提示告诉你,有一些库版本与pytorch不兼容,我的经验是重点关注这三个库即可(transformers,accelerate ,platform)安装界面给你提示,安装合适版本去兼容就行
最后可以用如下代码去验证一下自己的安装是否成功:
import torch
import transformers
import accelerate
import platform
# 检查 CUDA 是否可用
def check_cuda():
if torch.cuda.is_available():
print("CUDA is available.")
print(f"Device name: {torch.cuda.get_device_name(0)}") print(f"CUDA version: {torch.version.cuda}")
print(f"Number of GPUs: {torch.cuda.device_count()}") else: print("CUDA is not available.")
# 检查 PyTorch 版本
def check_torch_version():
print(f"PyTorch version: {torch.__version__}")
# 检查 transformers 版本
def check_transformers_version():
print(f"Transformers version: {transformers.__version__}")
# 检查 accelerate 版本
def check_accelerate_version():
print(f"Accelerate version: {accelerate.__version__}")
# 检查操作系统信息
def check_platform():
print(f"Operating System: {platform.system()}")
print(f"Platform Version: {platform.version()}")
print(f"Platform Architecture: {platform.architecture()}")
def main():
# 执行检查
check_platform()
check_cuda()
check_torch_version()
check_transformers_version()
check_accelerate_version()
if __name__ == "__main__":
main()三、下载模型:确保训练的基础
在进行训练之前,我们需要下载相关的模型文件。fluxgym 的模型下载要求与 fp16 的 FLUX 模型组一致,如果您之前已经下载过相关模型,只需将其复制到对应的目录即可。具体的下载步骤如下:
1. 在 models/clip 文件夹下下载以下模型:
https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors?download=true https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors?download=true
2. 在 models/vae 文件夹下下载以下模型:
https://huggingface.co/cocktailpeanut/xulf-dev/resolve/main/ae.sft?download=true
3. 在 models/unet 文件夹下下载以下模型:
https://huggingface.co/cocktailpeanut/xulf-dev/resolve/main/flux1-dev.sft?download=true
完成下载后,将模型放入如下结构中所示:
/models /clip clip_l.safetensors t5xxl_fp16.safetensors /unet flux1-dev.sft /vae ae.sft /sd-scripts /outputs /env app.py requirements.txt
启动服务之前,如果你用的是本地的部署的,可以跳过,如果用的是远程服务器需要修改 app.py 代码最后的部分如下:

四、运行:开启训练之旅
建议还是在前面增加外部连接HF_ENDPOINT=https://hf-mirror.com,后续训练过程会访问huggingface,正常没有代理访问huggingface,会连接超时。
HF_ENDPOINT=https://hf-mirror.com python app.py
五、训练过程:从准备到成果的蜕变
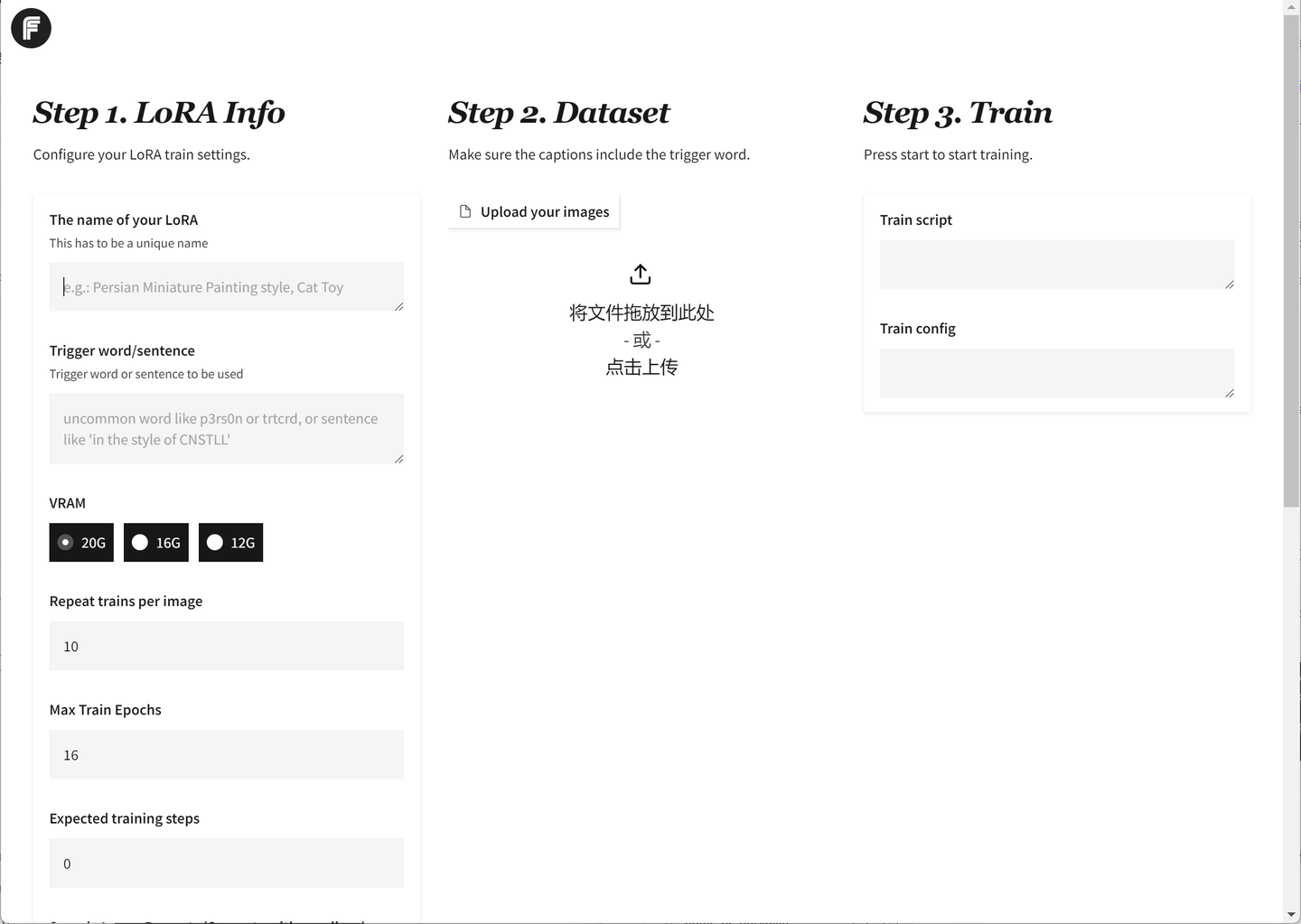
按照上面的步骤,依次进行就行了,下面我大概介绍一下,这些填的参数含义:
step 1
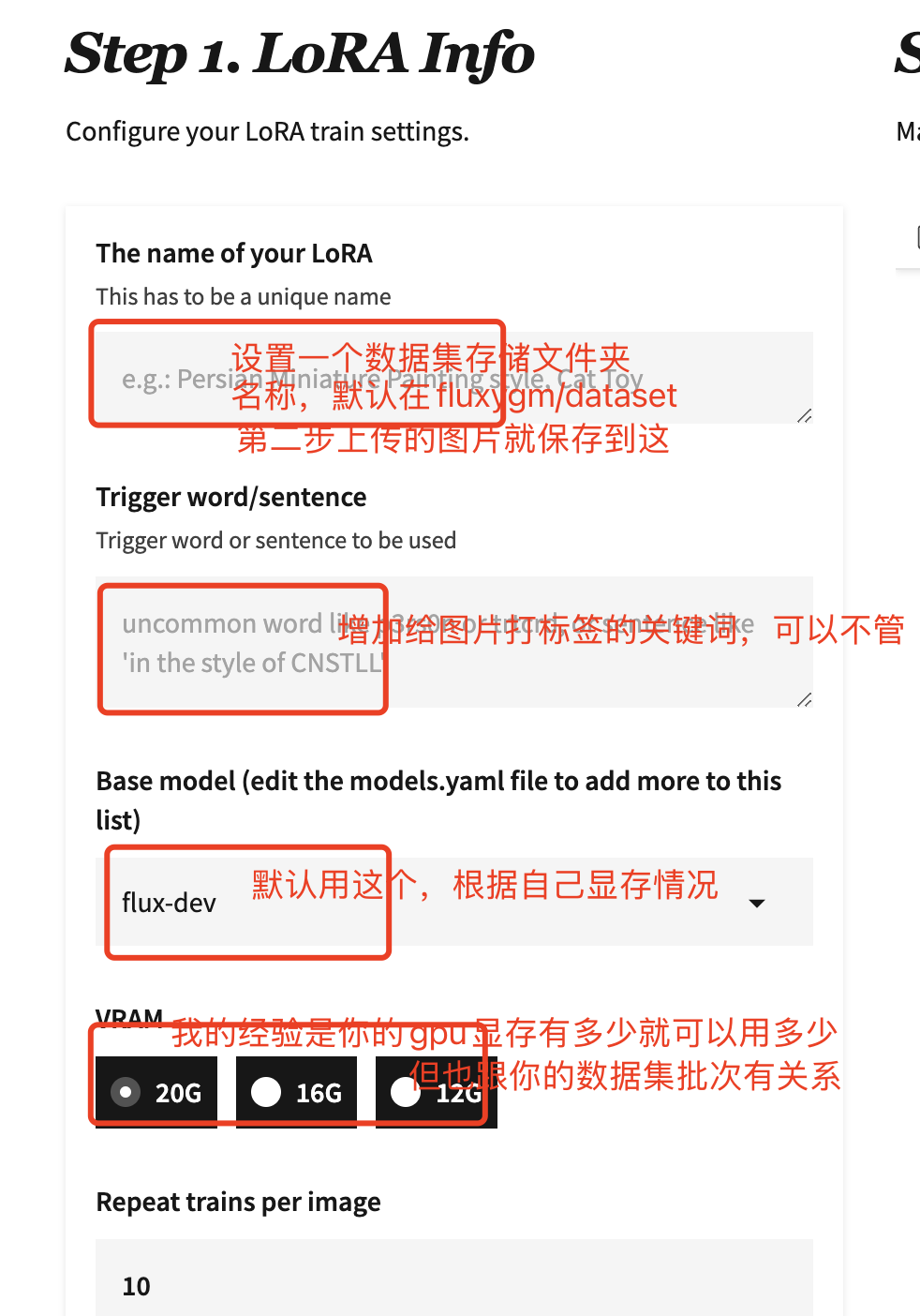
下面这个参数,和kohya_ss训练出现的参数是一个意思,“复制数据集几次”
step 2
上传自己的图片, 不必考虑图片之前尺寸问题。然后点击Florence反推打标。
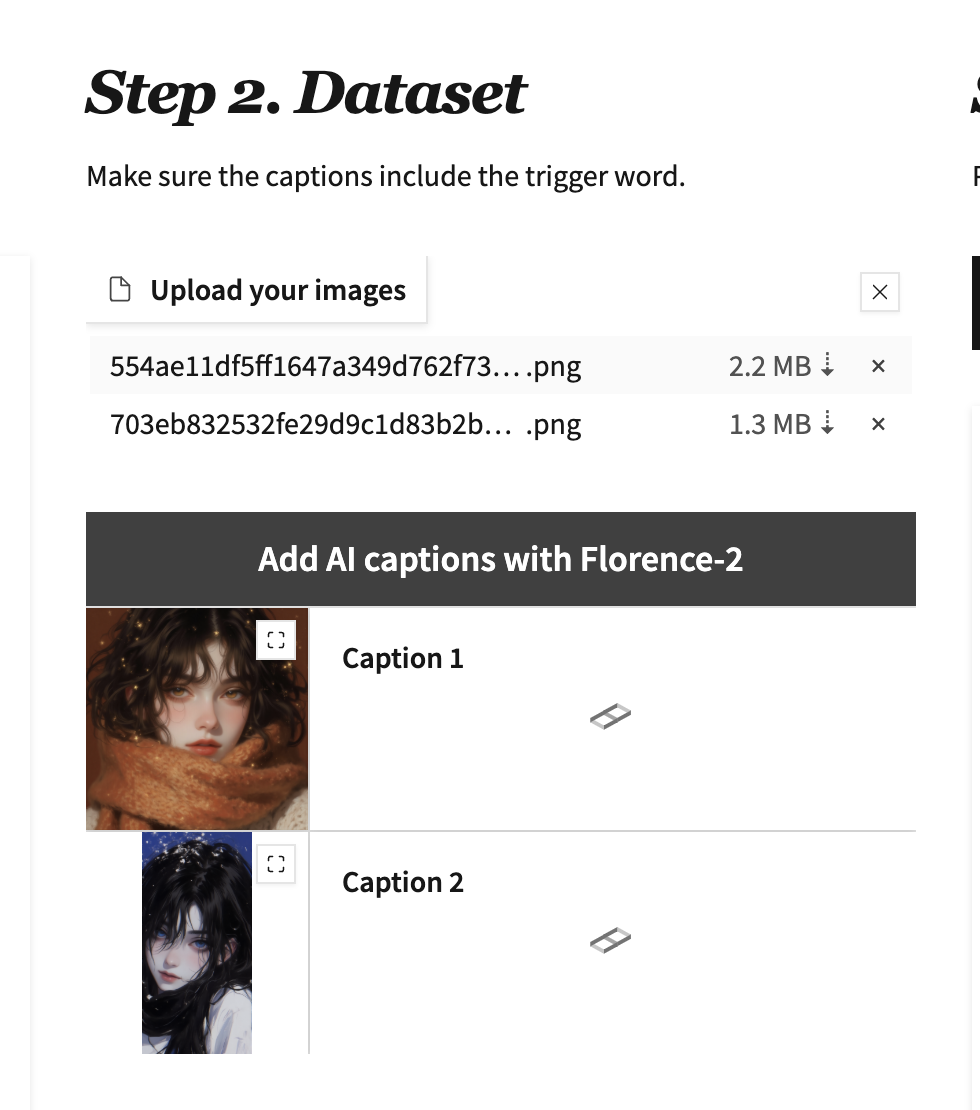
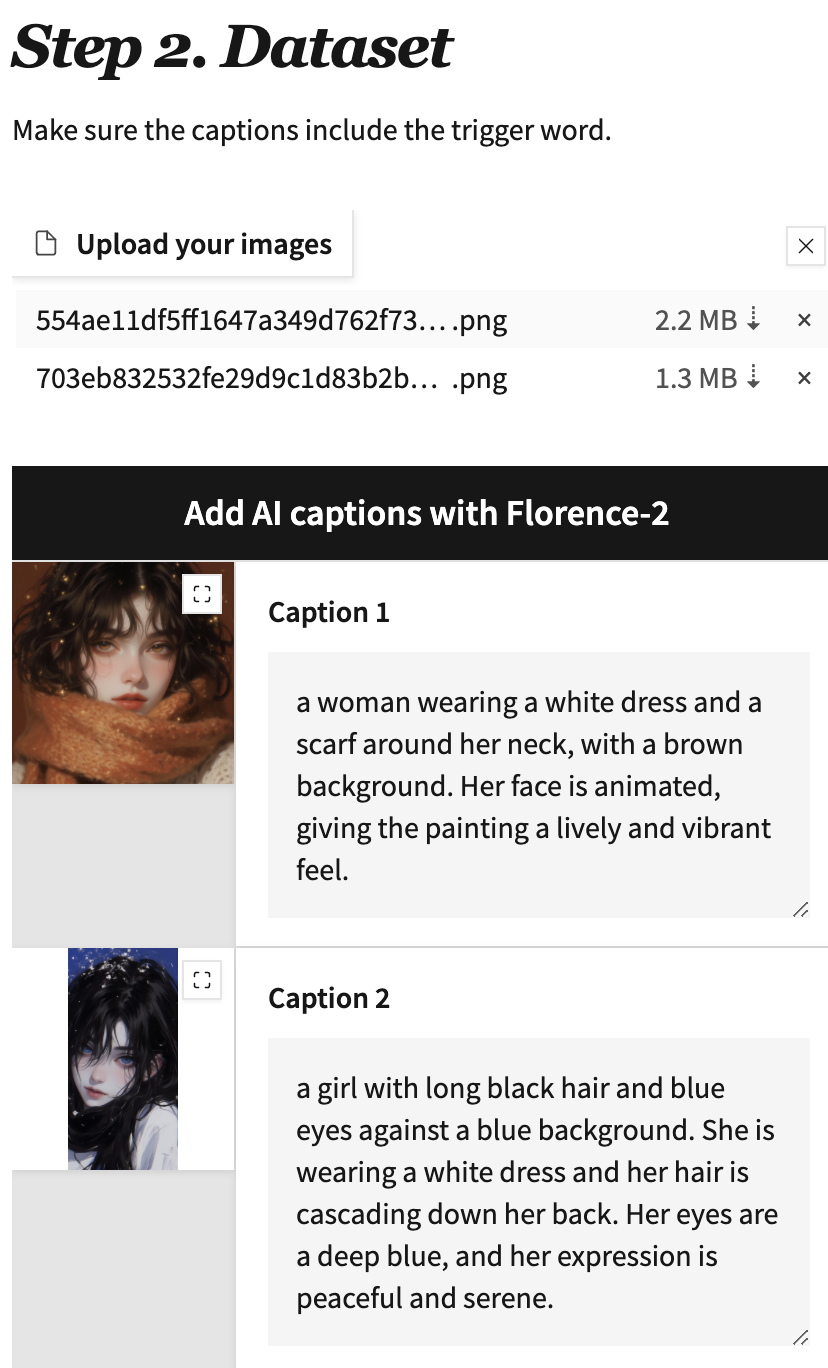
点击后可能会出现一些报错问题:
RuntimeError:"erfinv_vml_cpu"notimplementedfor'Half' :表示erfinv_()(计算反误差函数)操作不支持torch.float16(半精度)。模型在进行权重初始化时似乎使用了torch.float16精度,而这个特定操作erfinv_()在这种精度下不可用。(这个问题跟torch版本有关,按理说高版本应该可以适配,但我2.4.1也不行,可能2.6.1没这个问题吧)
解决方法:
在app.py 279行:torch_dtype = torch.float16 改成 torch_dtype = torch.bfloat16
Step 3
就可以直接点击training

添加图片注释,不超过 140 字(可选)
但你如果跟我一样是低版本的CUDA,需要修改一个参数 在app.py 475行
将bf16改成fp16
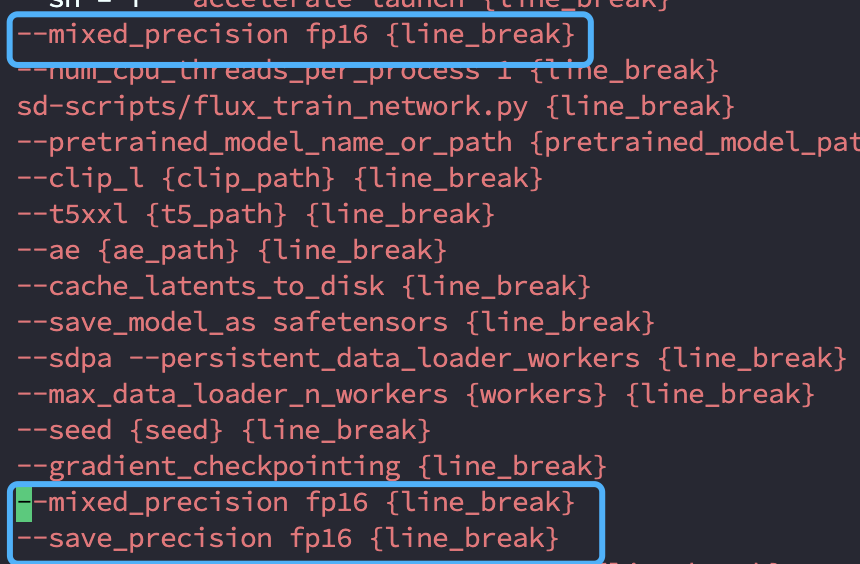
运行后报错问题:
RuntimeError: GET was unable to find an engine to execute this computation
通常会认为是torch版本不兼容的问题,但如果是按照前面步骤去验证的话,torch能用cuda,并且torch和torchvision版本是兼容的,就没这个问题的,经过我的盘查发现是transformer版本不兼容的原因,
这个需要结合自己的CUDA版本,去调整是升级版本还是降低,我的CUDA11.2用的是transformers==4.37.0