【RAG架构】RAG架构概要
目录
概念
一、Naive RAG(最基础的RAG)的核心架构:两大阶段
架构图:
阶段一:离线数据处理与索引
阶段二:在线问答生成
RAG的优势与挑战
RAG的升级:从基础到高级
二、智能体中的RAG
智能体中RAG架构的核心变化
智能体中的RAG架构流程图
总结对比:基础RAG vs. 智能体中的RAG
概念
我们可以把RAG想象成一个开卷考试”的过程。
- 学生(大语言模型 LLM):本身很聪明,会推理、会写作,但脑子里的知识是固定的(训练数据截止日期),而且有时会“记错”或“编造”(幻觉)。
- 考试问题(用户查询):需要学生回答。
- 教科书/参考资料(外部知识库):包含了最新的、特定的、私有的知识。
- RAG架构:就是教会学生如何快速查阅教科书,找到相关章节,然后结合自己的理解来回答问题的整个流程。
一、Naive RAG(最基础的RAG)的核心架构:两大阶段
架构图:
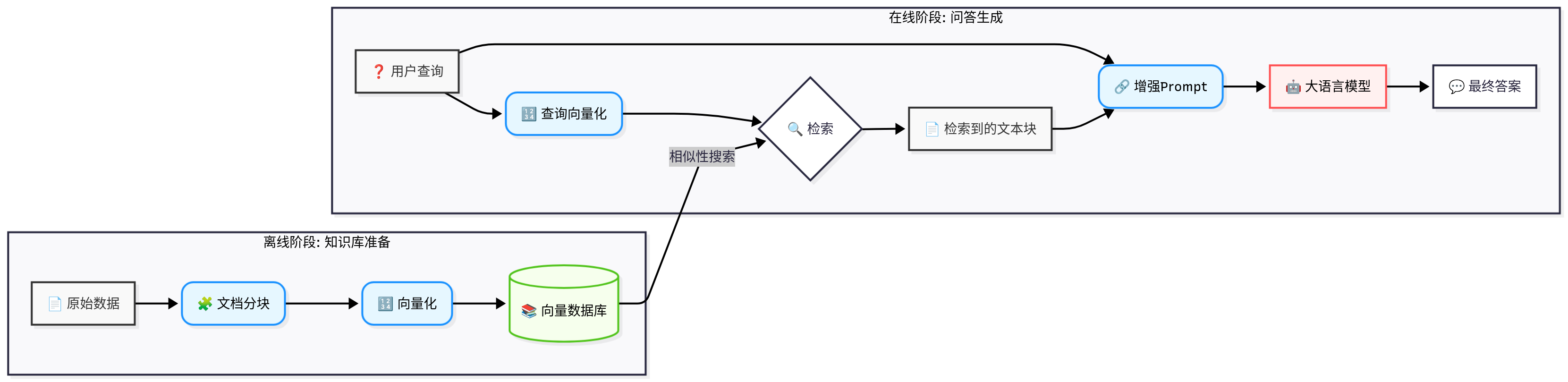
阶段一:离线数据处理与索引
这个阶段是“准备教科书”。
目标是将原始的、非结构化的数据(如PDF、Word、网页、API数据等)处理成可以被高效检索的结构。它只在数据更新时运行,不响应用户的实时请求。
流程如下:
1. 数据加载
- 做什么:从各种数据源(本地文件、数据库、网站等)读取原始数据。
- 工具:如
LangChain或LlamaIndex的Document Loaders,可以轻松加载不同格式的文件。
2. 文档分块
- 做什么:将长篇的文档切分成多个、大小适中的文本块。
- 为什么需要:因为LLM的上下文窗口(能一次性处理的文本长度)是有限的。把整本书都塞给它不现实,所以需要按章节、段落切分。
- 关键:分块的大小和策略非常关键,太大或太小都会影响检索效果。
3. 向量化
- 做什么:使用嵌入模型将每个文本块转换成一个高维的数学向量。
- 原理:这个向量可以看作是文本块在“语义空间”中的坐标。意思相近的文本,其向量在空间中的距离也相近。
- 模型:常用的嵌入模型有
OpenAI Embeddings、Cohere Embeddings、开源的M3E、BGE等。
4. 存入向量数据库
- 做什么:将生成的文本块及其对应的向量一同存入专门的数据库——向量数据库。
- 作用:向量数据库被专门优化用于高速的“相似性搜索”。当给它一个查询向量时,它能极快地找到与之最相似的文本块向量。
- 常用数据库:
Chroma、Pinecone、Weaviate、Milvus等。
离线阶段小结: 经过这个阶段,我们就拥有了一个“可以被快速检索的数字图书馆”。
阶段二:在线问答生成
这个阶段是“开卷考试”。
当用户提出一个问题时,这个阶段被触发,实时地生成答案。
流程如下:
1. 用户查询
- 用户输入一个问题,例如:“公司最新的报销政策是什么?”
2. 查询向量花
- 系统使用与离线阶段相同的嵌入模型,将用户的查询也转换成一个向量。
3. 检索
- 系统将这个查询向量发送到向量数据库。
- 向量数据库执行相似性搜索,找到与查询向量最相似的
k个文本块(例如,最相关的3个段落)。 - 这
k个文本块就是从“教科书”里找到的“参考资料”。
4. 增强
- 这是RAG中“A”(Augmented,增强)的核心。
- 系统将原始的用户查询和检索到的相关文本块组合成一个全新的、更丰富的提示。
- 这个Prompt通常会遵循一个模板,例如:
请根据以下背景信息,回答用户的问题。如果信息不足,请说明无法回答。[背景信息]:{检索到的文本块1}{检索到的文本块2}{检索到的文本块3}[用户问题]:{用户原始查询}[回答]:
5. 生成
- 将这个精心构造的、包含上下文的Prompt发送给大语言模型(LLM)。
- LLM现在就像一个拿着参考答案的学生,它会基于提供的背景信息进行推理、总结,并生成最终的答案。
- 因为答案是基于提供的文本生成的,所以内容更准确、可追溯,并且大大减少了幻觉。
RAG的优势与挑战
优势:
- 知识更新:可以轻松更新知识库,而无需重新训练整个模型。
- 减少幻觉:模型回答有据可依,大大降低了编造信息的风险。
- 可解释性:可以展示答案来源的文本块,增加了透明度和可信度。
- 利用私有数据:可以让模型安全地访问和利用企业内部的私有数据。
- 成本效益高:相比于昂贵的模型微调,构建和维护RAG系统通常成本更低。
挑战:
- 检索质量决定上限:如果检索到的信息不相关或质量差,生成效果必然不好(“垃圾进,垃圾出”)。
- 分块策略敏感:如何切分文档对效果影响巨大。
- 处理复杂问题:对于需要跨多个文档进行复杂推理的问题,简单的RAG可能表现不佳。
- 延迟:检索和向量化过程会增加额外的响应时间。
RAG的升级:从基础到高级
我们上面讨论的是最基础的RAG架构,也被称为 Naive RAG。为了解决其挑战,RAG架构也在不断升级:
-
Advanced RAG(高级RAG):在检索前后增加了优化步骤。
- 查询优化:在检索前,对用户查询进行改写、扩展或分解,使其更容易匹配到相关文档。
- 结果重排:在检索后,使用一个更强大的模型对检索到的多个文档块进行重新排序,选出最相关的。
- 混合检索:结合关键词搜索(如BM25)和向量搜索,取长补短。
-
Modular RAG(模块化RAG):将RAG设计成一个更灵活的、可插拔的模块化流程。可以加入搜索、总结、记忆、反思等多种模块,LLM甚至可以作为一个“控制器”,决定何时检索、检索什么、以及如何评估检索结果。
二、智能体中的RAG
当RAG从一个独立的问答系统,演变为智能体架构中的一个组件时,它的角色、触发方式和交互流程都发生了根本性的变化。
继续用之前的比喻来说就是:
- 基础RAG:像一个开卷考试的学生。他的任务很明确:回答试卷上的问题。他的流程是固定的:看到问题 -> 查书 -> 写答案。
- 智能体中的RAG:像一个正在破案的侦探。他有一个最终目标(破案),但需要自己规划步骤,主动搜集线索。查资料(使用RAG)只是他众多行动中的一种,而且他需要自己决定查什么、何时查、以及查到的信息如何与其他线索(如打电话、去现场勘查)结合。
智能体中RAG架构的核心变化
1. 角色转变:从“主角”到“工具箱里的一个工具”
在基础RAG中,RAG流程是整个系统的核心。但在智能体架构中,RAG只是智能体可以调用的众多工具之一。
- 智能体的工具箱可能包括:
- RAG工具:用于查询内部知识库。
- 搜索引擎工具:用于查询实时网络信息。
- 计算器工具:用于进行数学计算。
- API调用工具:用于与外部系统交互(如查询天气、发送邮件、操作CRM)。
- 代码执行器:用于运行代码并获取结果。
RAG不再是整个流程的起点和终点,而是被智能体的“大脑”(推理引擎)按需调用。
2. 触发方式转变:从“被动响应”到“主动调用”
- 基础RAG:由用户的查询直接触发。流程是线性的、一次性的。
- 智能体中的RAG:由智能体的规划决策触发。智能体在执行一个复杂任务时,可能会在中间的任何一步判断“我需要更多信息”,然后主动调用RAG工具。
这个过程是循环和迭代的,而不是线性的。
3. 查询来源转变:从“用户输入”到“智能体生成”
这是一个非常关键的区别。
- 基础RAG:用于向量检索的查询,就是用户的原始问题。
- 智能体中的RAG:用于检索的查询,往往是智能体根据当前任务状态和上下文,动态生成的。
例如,用户的目标是“分析我们公司第三季度的财报,并找出潜在风险”。智能体可能会这样规划:
- 第一步:我需要先拿到财报原文。 -> 调用RAG工具,查询“2024年第三季度财务报告全文”。
- 第二步:报告拿到了,我需要总结关键财务数据。 -> (可能用LLM内部能力,或再次调用RAG查询“关键财务指标”)。
- 第三步:报告提到了“供应链风险”,我需要了解公司主要供应商的近况。 -> 调用RAG工具,查询“主要供应商名单及合作情况”。
- 第四步:我还想看看外部新闻怎么说。 -> 调用搜索引擎工具,查询“[公司名] 供应链 新闻”。
你看,每一次RAG的查询,都是智能体为了完成子任务而主动构造的,而不是用户直接给出的。
4. 与“记忆”的深度融合
智能体通常需要记忆来维持上下文。RAG可以作为实现长期记忆的关键技术。
- 短期记忆:在当前对话的上下文窗口中。
- 长期记忆:将过去的对话、行动、结果、学到的知识等存入一个向量数据库。当智能体需要回忆时,就可以通过RAG机制来检索相关的“记忆片段”。
智能体中的RAG架构流程图
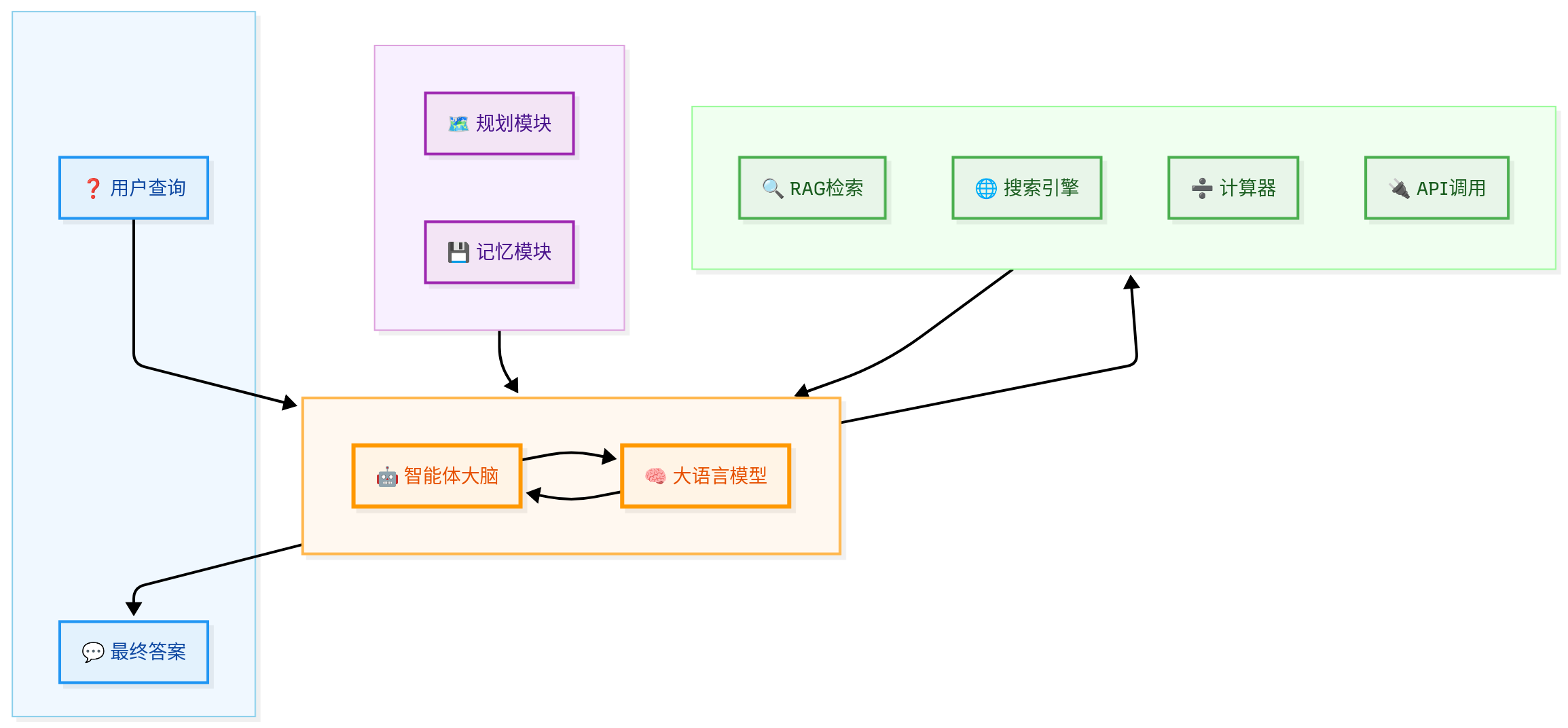
总结对比:基础RAG vs. 智能体中的RAG
| 特性 | 基础RAG | 智能体中的RAG |
|---|---|---|
| 核心角色 | 系统主角,完整流程 | 一个可被调用的工具 |
| 触发方式 | 被动响应,由用户查询触发 | 主动调用,由智能体规划触发 |
| 流程 | 线性、一次性 | 循环、迭代式 |
| 查询来源 | 用户的原始输入 | 智能体根据上下文动态生成 |
| 与LLM交互 | LLM在最后一步用于生成答案 | LLM作为大脑,决定何时及如何使用RAG |
| 目标 | 准确回答单个问题 | 完成复杂的、多步骤的目标任务 |
所以,当你为智能体搭建RAG结构时,你考虑的不仅仅是“如何检索和生成”,而是:
- 如何将RAG封装成一个标准化的工具接口?
- 如何让智能体学会在合适的时机生成高质量的查询来调用这个工具?
- 如何处理RAG返回的结果,并将其与其它工具的结果融合,以推进任务?
这要求我们从“构建一个问答系统”的思维,转变为“为智能体打造一个强大的知识查询模块”的思维。