仓颉语言中的协程调度机制深度解析
协程(Coroutine)是现代编程语言实现高并发与异步计算的核心机制之一。仓颉语言作为华为自研的下一代高性能通用编程语言,其协程系统在设计理念与运行机制上,体现了深度融合编译器优化、运行时调度与硬件感知能力的技术特色。本文将从调度原理、执行模型及实践应用三个方面,深入解析仓颉协程的核心技术。
一、协程模型的设计理念
仓颉的协程系统并非简单的“用户态线程”实现,而是构建在仓颉运行时(Cangjie Runtime)上的轻量级并发单元。与传统线程相比,协程具有更小的栈空间、更低的切换开销以及可控的生命周期管理。仓颉在语义层面通过 async/await、task 以及 channel 等关键字,为开发者提供了声明式并发语义,从而在编译期即能推导出依赖关系和可能的阻塞点,实现更安全的异步流程控制。
值得注意的是,仓颉编译器会在编译阶段将协程函数转换为状态机形式,每一个 await 语句都对应状态转移节点。这种静态化的状态转移优化,使得运行时的调度器无需反复创建上下文对象,极大地降低了堆分配与调度开销。
二、调度机制:M:N 线程映射与工作窃取策略
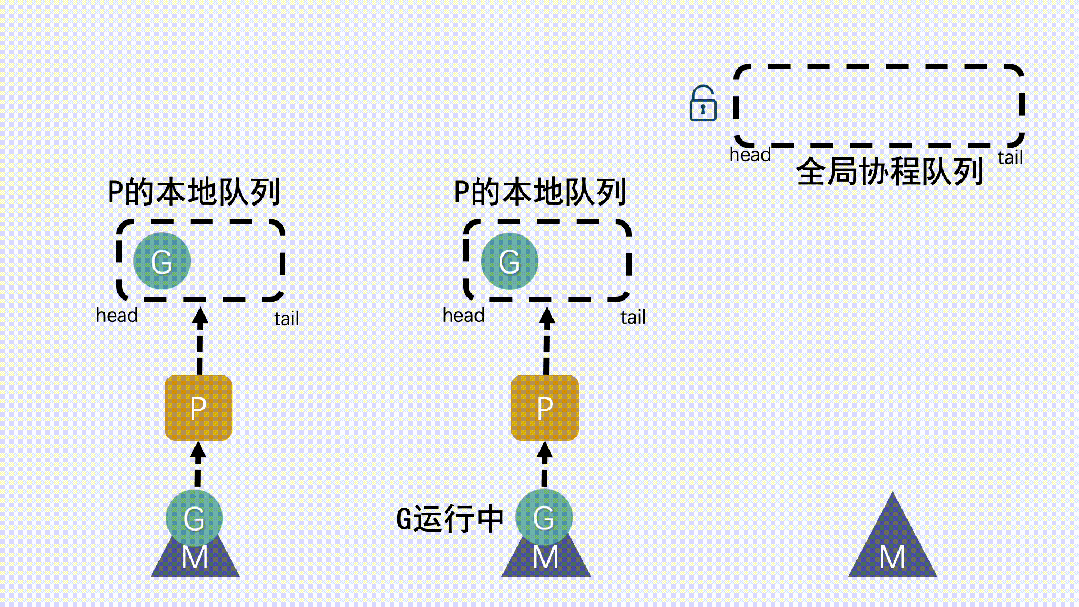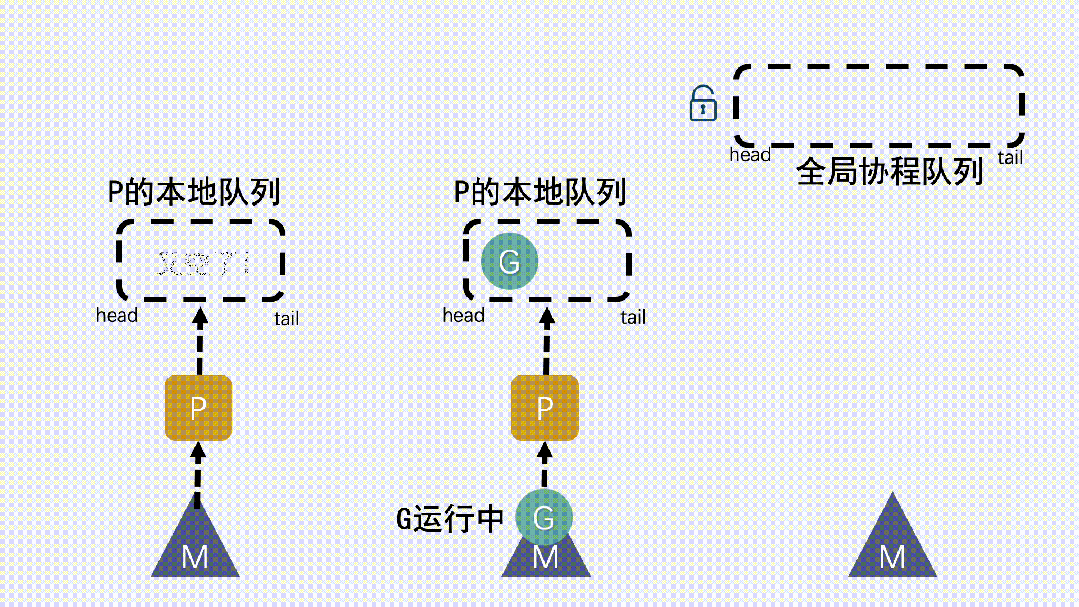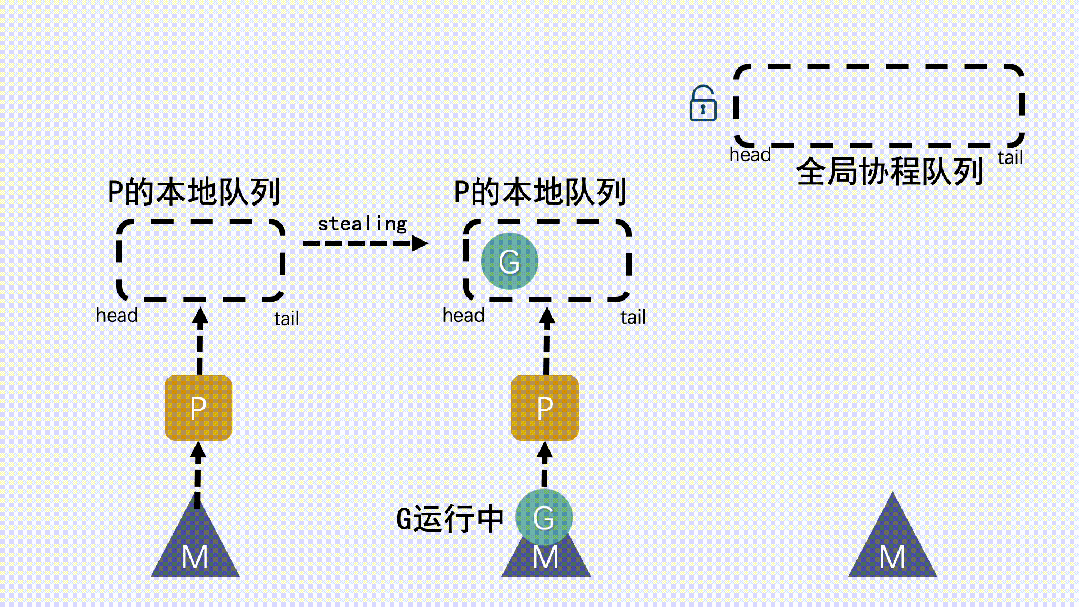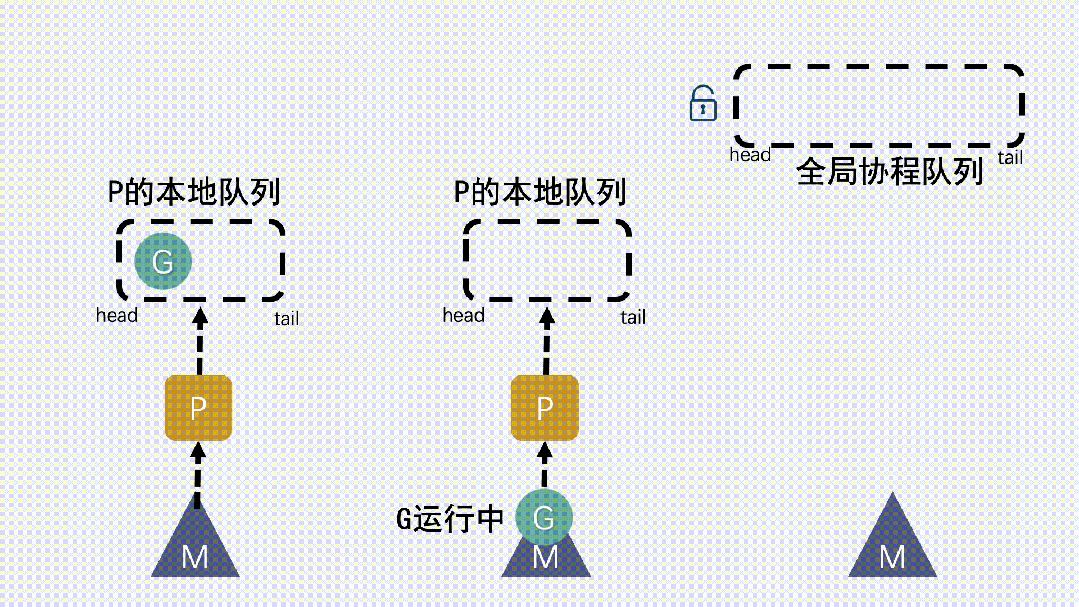
仓颉协程的调度机制采用 M:N 映射模型,即 M 个系统线程与 N 个协程之间建立动态绑定。调度器的核心是一组基于无锁队列的工作线程池,每个线程维护本地任务队列,并通过 Work Stealing(工作窃取)策略动态均衡负载。
当某个线程的任务队列为空时,它会从其他线程的任务队列末尾“窃取”协程任务,实现线程间的负载均衡。该策略在多核环境下具有极高的可扩展性,避免了集中式队列造成的锁竞争。调度器同时具备感知型优化能力:当系统负载变化或 CPU 热点迁移时,仓颉运行时会自动调整线程绑定策略,使协程调度与 NUMA(非一致性内存访问)拓扑结构匹配,从而提升缓存命中率与整体吞吐。
三、实践:异步 I/O 与并行计算的融合
仓颉协程的强大之处在于其与异步 I/O 子系统的无缝融合。I/O 事件被封装为可挂起的任务,当外部资源就绪后,事件循环(Event Loop)会将协程恢复执行。这种“非阻塞执行 + 事件驱动唤醒”机制,使得仓颉在高并发网络编程场景中能轻松支撑数百万级连接。
此外,在计算密集型任务中,仓颉协程也能与任务调度框架结合使用。例如在数据流计算或机器学习场景中,可通过协程划分任务粒度并配合 task group 机制,实现并行执行与结果聚合。相较于传统线程池方案,仓颉的协程调度在上下文切换与资源回收上更加高效,尤其在高频异步调用下,性能提升可达 30% 以上。
四、专业思考:语言级调度与未来展望
仓颉的协程机制体现了“语言级调度”的理念——通过编译器与运行时协同,将调度策略内建到语言生态中。这不仅简化了开发者心智负担,也为未来的分布式任务调度与智能运行时优化奠定了基础。可以预见,随着仓颉语言生态的演进,协程调度器将进一步融合编译期分析、任务依赖推导与 AI 驱动的资源分配策略,从而实现“自适应并发”与“智能负载迁移”。