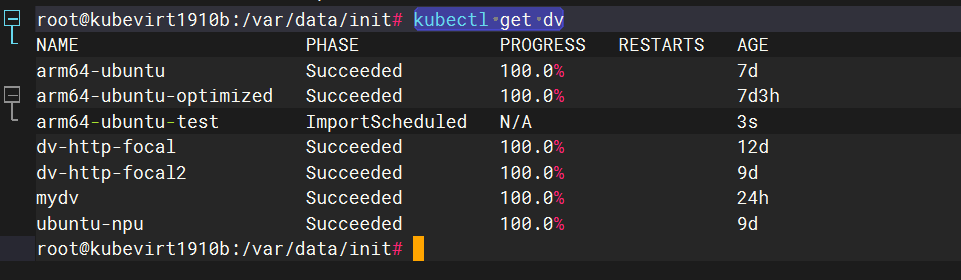
Kubevirt部署好后系统镜像的dv存储创建
什么是DV?
DataVolume 是 Kubevirt 用于管理虚拟机磁盘镜像的资源,支持从 HTTP、容器镜像、S3 等源导入镜像,自动创建对应的PersistentVolumeClaim(PVC)。
DV创建流程
首先要有镜像,把镜像放到某个目录下之后,执行nohup python3 -m http.server 8000 & 后台运行个http
nohup python3 -m http.server 8000 &
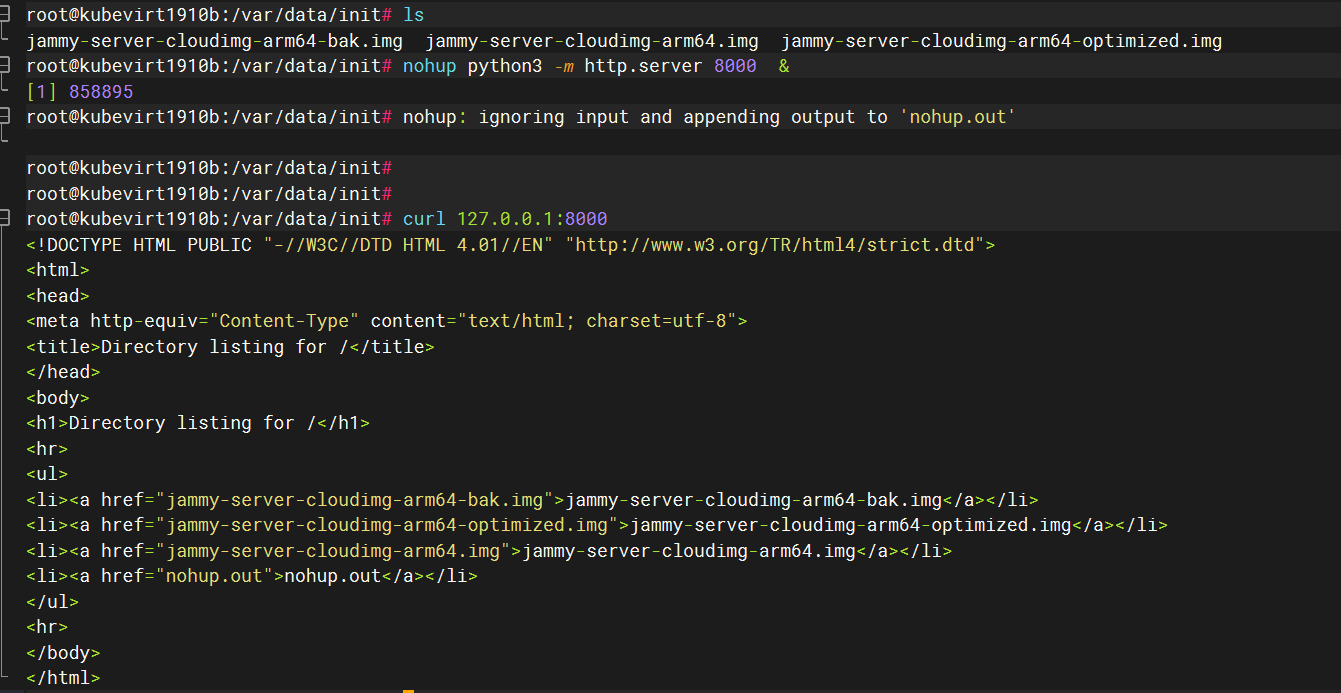
起这个服务就相当于是个下载链接,把需要的镜像复制到这里之后,再导入到dv中,接下来我们创建dv文件
模版文件,集群内已有 PVC(克隆)
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:name: my-dv-clone
spec:pvc:accessModes:- ReadWriteOnceresources:requests:storage: 10GistorageClassName: <你的存储类名称>volumeMode: Filesystemsource:pvc:name: existing-pvc # 已有PVC的名称namespace: default # 已有PVC的命名空间
案例文件,外部 HTTP 服务器(下载导入)
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:name: arm64-ubuntunamespace: default
spec:source:http:url: http://192.168.0.115:8081/jammy-server-cloudimg-arm64-bak.imgstorage:resources:requests:storage: 20GivolumeMode: Block
解读:
-
apiVersion: cdi.kubevirt.io/v1beta1
说明该资源属于 Containerized Data Importer (CDI) 项目的 v1beta1 版本 API。CDI 是 Kubevirt 生态中用于管理虚拟机磁盘镜像导入的工具,支持从 HTTP、容器镜像、S3 等源导入镜像,并自动创建对应的PersistentVolumeClaim(PVC)。 -
kind: DataVolume
明确资源类型为 DataVolume(简称 DV)。DV 是 CDI 的核心资源,用于声明 “从哪里导入镜像、需要多少存储、存储以什么模式呈现”,最终会自动生成一个 PVC 供 Kubevirt 虚拟机使用。 -
metadata 段
name: arm64-ubuntu:该 DV 的名称,用于在 Kubernetes 中标识这个资源。
namespace: default:该 DV 部署在default命名空间下,Kubernetes 资源的隔离和管理基于命名空间。 -
spec 段(核心配置)
(1)source.http.url
定义镜像的导入源:通过 HTTP 协议从 http://192.168.0.115:8081/jammy-server-cloudimg-arm64-bak.img 下载磁盘镜像。
镜像类型:从文件名 jammy-server-cloudimg-arm64-bak.img 可判断,这是一个ARM64 架构的 Ubuntu Jammy(22.04)服务器版云镜像(适合虚拟机部署)。
(2)storage.resources.requests.storage: 20Gi
声明该 DV 对应的 PVC 需要请求 20Gi 的存储容量。需注意:请求的存储容量必须大于镜像实际大小,否则镜像导入会失败。
(3)storage.volumeMode: Block
定义存储的卷模式为Block(块设备模式)。
Block模式:卷以 “块设备” 形式呈现,适合直接作为虚拟机的块设备磁盘(如虚拟机的根磁盘),性能更接近物理磁盘。
对比Filesystem模式(文件系统卷,适合挂载为目录),Block更契合虚拟机 “磁盘设备” 的使用场景。
整体作用
这段配置的核心目的是:在default命名空间下创建一个 DataVolume,从指定 HTTP 地址下载 ARM64 架构的 Ubuntu Jammy 云镜像,请求 20Gi 的块设备存储,最终生成一个 PVC,供 Kubevirt 虚拟机作为磁盘使用。
测验
创建个arm64-ubuntu-test的dv进行测试
kubectl get dv