python数据分析项目之:房地产数据可视化分析
先回顾一下数据分析的四大步骤:
目录
一、数据导入
二、数据清洗
三、特征构造(核心)
四、可视化分析
下面就根据以上步骤进行房地产项目数据分析实战:
一、数据导入
# 1. 导入项目所用到的库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from matplotlib import rcParams
rcParams['font.sans-serif'] = ['SimHei'] #win电脑画图字体# 2. 导入数据
df = pd.read_csv(r'E:/project/data/house_sales.csv')# 3. 数据概览
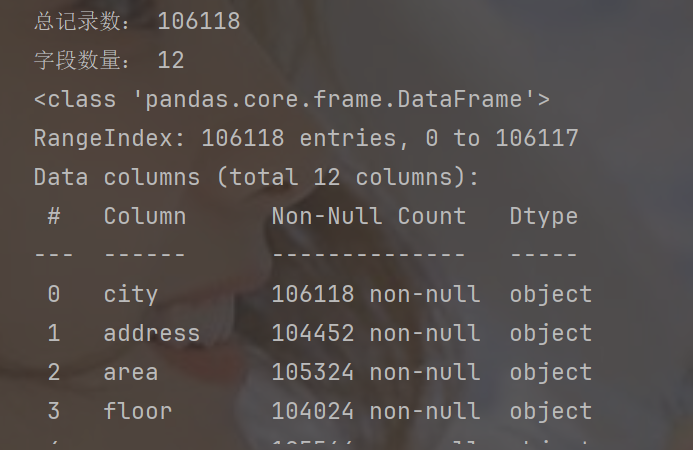
print('总记录数:', len(df))
print('字段数量:', len(df.columns))
df.head(5)
df.info()运行结果如下:
二、数据清洗
# 数据清洗
# 1、删除无用的数据列
df.drop(columns='origin_url',inplace=True)# 2、检查是否有缺失值
df.isna().sum()
# 删除缺失值
df.dropna(inplace=True)# 检查是否有重复值
df.duplicated().sum()
# 删除重复数据
df.drop_duplicates(inplace=True)# 查看数据
print(len(df))# 3、数据列处理
# 面积的数据类型转换
df['area'] = df['area'].str.replace('㎡','').astype(float)
# 售价的数据类型转换
df['price'] = df['price'].str.replace('万','').astype(float)
# 朝向的数据类型转换
df['toward'] = df['toward'].astype('category')
# 单价的数据类型转换
df['unit'] = df['unit'].str.replace('元/㎡','').astype(float)
# 建造年份的数据类型转换
df['year'] = df['year'].str.replace('年建','').astype(int)# 4、异常值的处理
# 房屋面积的异常处理
df = df[ (df['area']<600) & (df['area']>20)]# 房屋售价的异常处理 IQR
Q1 = df['price'].quantile(0.25)
Q3 = df['price'].quantile(0.75)
IQR = Q3 - Q1
low_price = Q1 - 1.5*IQR
high_price = Q3 + 1.5*IQR
df = df[ (df['price']<high_price) & (df['price']>low_price) ]三、数据特征构造
# 1. 新数据特征构造
# 地区district
df['district'] = df['address'].str.split('-').str[0]# 楼层的类型floor_type
df['floor_type'] = df['floor'].str.split('(').str[0].astype('category')
def fun1(str1):if pd.isna(str1):return '未知'elif '低' in str1:return '低楼层'elif '中' in str1:return '中楼层'elif '高' in str1:return '高楼层'else:return '未知'
df['floor_type2'] = df['floor'].apply(fun1).astype('category')# 是否是直辖市zxs
df['zxs'] = df['city'].apply(lambda x: 1 if x in ['北京','上海','天津','重庆'] else 0)# 卧室的数量bedrooms
df['bedrooms'] = df['rooms'].str.split('室').str[0].astype(int)# 客厅的数量livingrooms
# df['rooms'].str.split('室').str[1].str.split('厅').str[0].astype(int)
df['livingrooms'] = df['rooms'].str.extract(r'(\d+)厅').astype('int')# 楼龄building_age
df['building_age'] = 2025 - df['year']# 价格的分段price_labels
df['price_labels'] = pd.cut(df['price'],bins=4,labels=['低价','中价','高价','豪华'])四、可视化分析
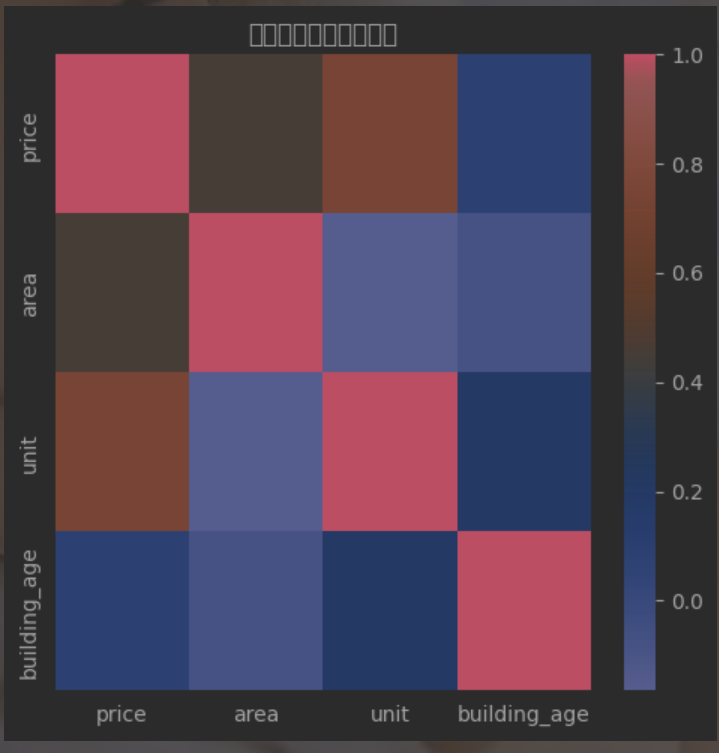
问题编号: A1 问题: 哪些变量最影响房价?面积、楼层、房间数哪个影响更大? 分析主题: 特征相关性 分析目标: 了解房屋各特征对房价的线性影响 分组字段: 无 指标/方法: 皮尔逊相关系数
# 选择数值型特征
a = df[['price','area','unit','building_age']].corr()#相关系数
# 对房价的影响最大的几个因素的排序
a['price'].sort_values(ascending=False)[1:]
# 相关性的热力图
plt.figure(figsize = (5,5))
sns.heatmap(a,cmap='coolwarm')
plt.title('房屋特征相关性热力图')
plt.tight_layout()运行结果如下:
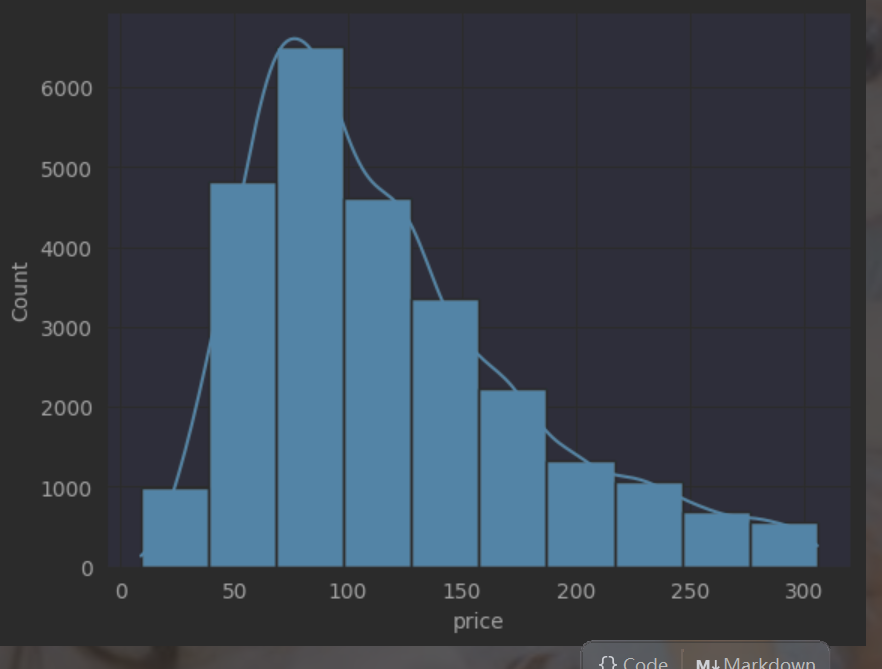
问题编号: A2 问题: 全国房价总体分布是怎样的?是否存在极端值? 分析主题: 描述性统计 分析目标: 概览数值型字段的分布特征 分组字段: 无 指标/方法: 平均数/中位数/四分位数/标准差
代码如下:
# 房价分布直方图
plt.subplot(111)
plt.hist(df['price'],bins=10)
df.head()
sns.histplot(data=df,x='price',bins=10,kde=True)运行结果如下;
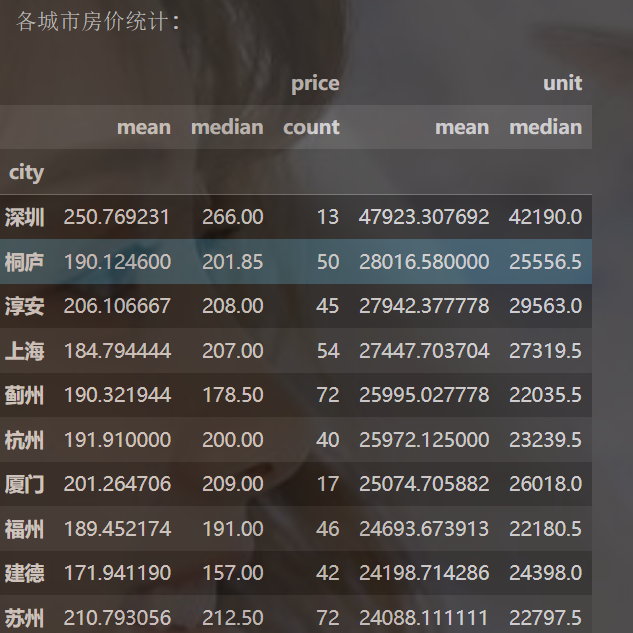
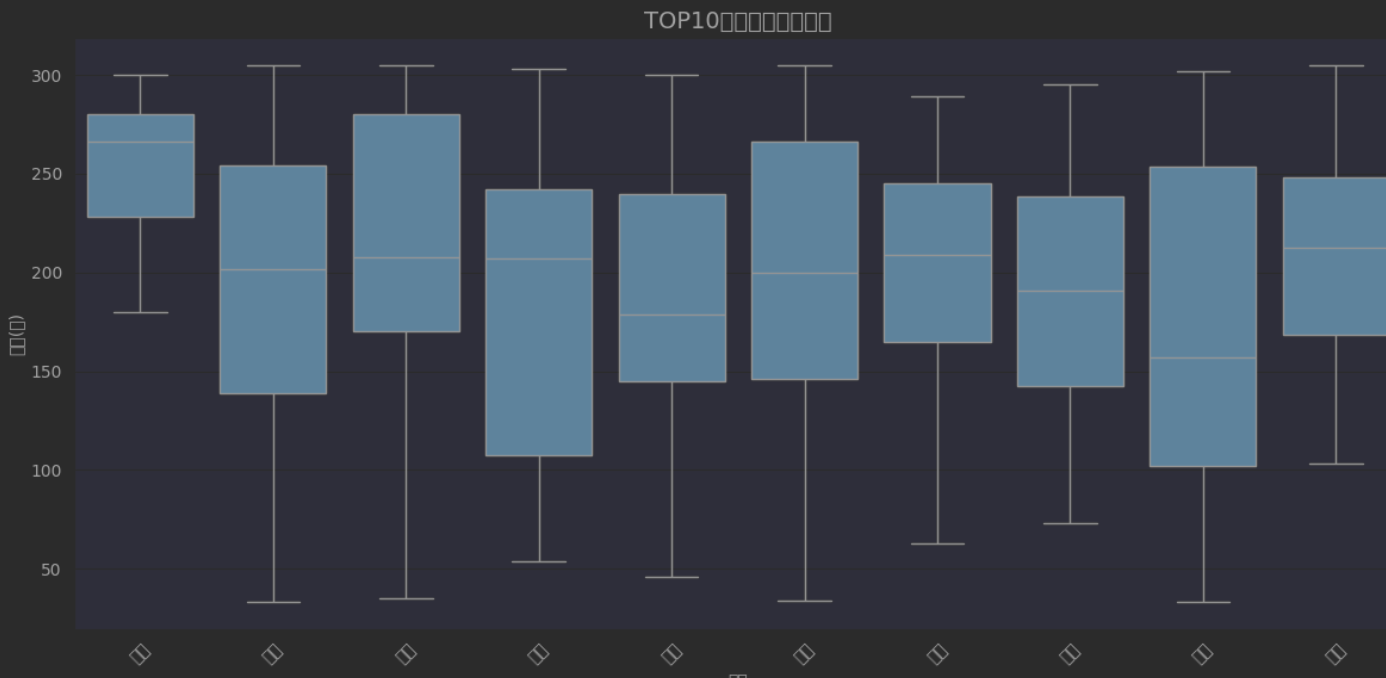
问题编号: A3 问题: 哪些城市房价最高?直辖市与非直辖市差异如何? 分析主题: 城市对比 分析目标: 比较不同城市房价水平 分组字段: city 指标/方法: 均价/单价中位数/箱线图
代码如下:
# 按城市统计
city_stats = df.groupby('city').agg({'price': ['mean', 'median', 'count'],'unit': ['mean', 'median']
})
print("\n各城市房价统计:")
display(city_stats.sort_values(('unit', 'mean'), ascending=False).head(10))# 可视化前10城市
top_cities = city_stats.sort_values(('unit', 'mean'), ascending=False).head(10).index
df_top = df[df['city'].isin(top_cities)]plt.figure(figsize=(12, 6))
sns.boxplot(x='city', y='price', data=df_top, order=top_cities)
plt.title('TOP10城市房价分布对比', fontsize=14)
plt.xlabel('城市')
plt.ylabel('价格(元)')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()运行结果如下:
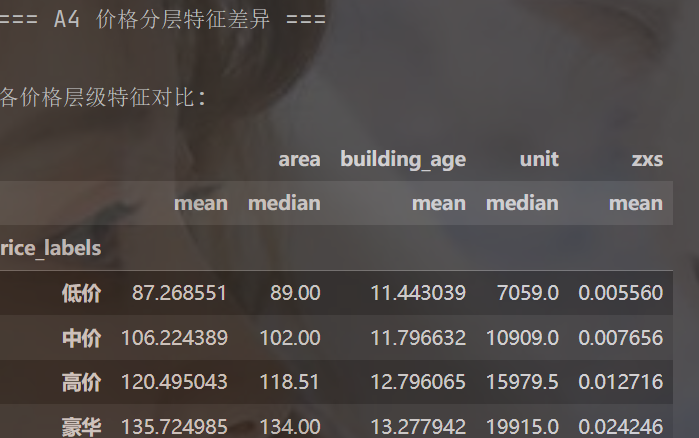
问题编号: A4 问题: 高价房在面积、楼层等方面有什么特征? 分析主题: 价格分层 分析目标: 识别不同价位房屋特征差异 分组字段: 价格分段(低中高) 指标/方法: 列联表/卡方检验
# 按价格分段分析特征
price_group = df.groupby('price_labels').agg({'area': ['mean', 'median'],'building_age': 'mean','unit': 'median','zxs': 'mean' # 直辖市占比
})print("\n各价格层级特征对比:")
display(price_group)# 可视化
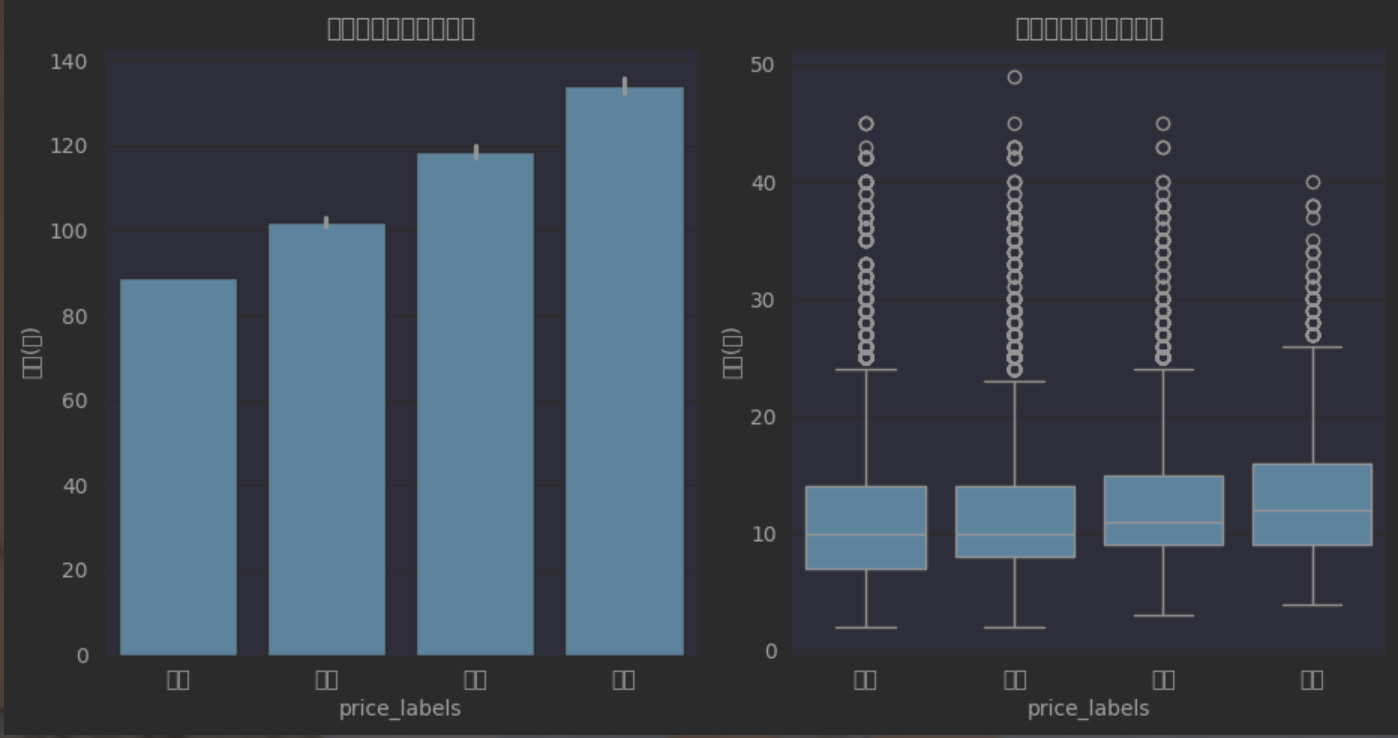
plt.figure(figsize=(14, 5))plt.subplot(131)
sns.barplot(x='price_labels', y='area', data=df, estimator=np.median)
plt.title('不同价格层级面积对比')
plt.ylabel('面积(㎡)')plt.subplot(132)
sns.boxplot(x='price_labels', y='building_age', data=df)
plt.title('不同价格层级楼龄分布')
plt.ylabel('楼龄(年)')plt.tight_layout()
plt.show()运行结果如下:
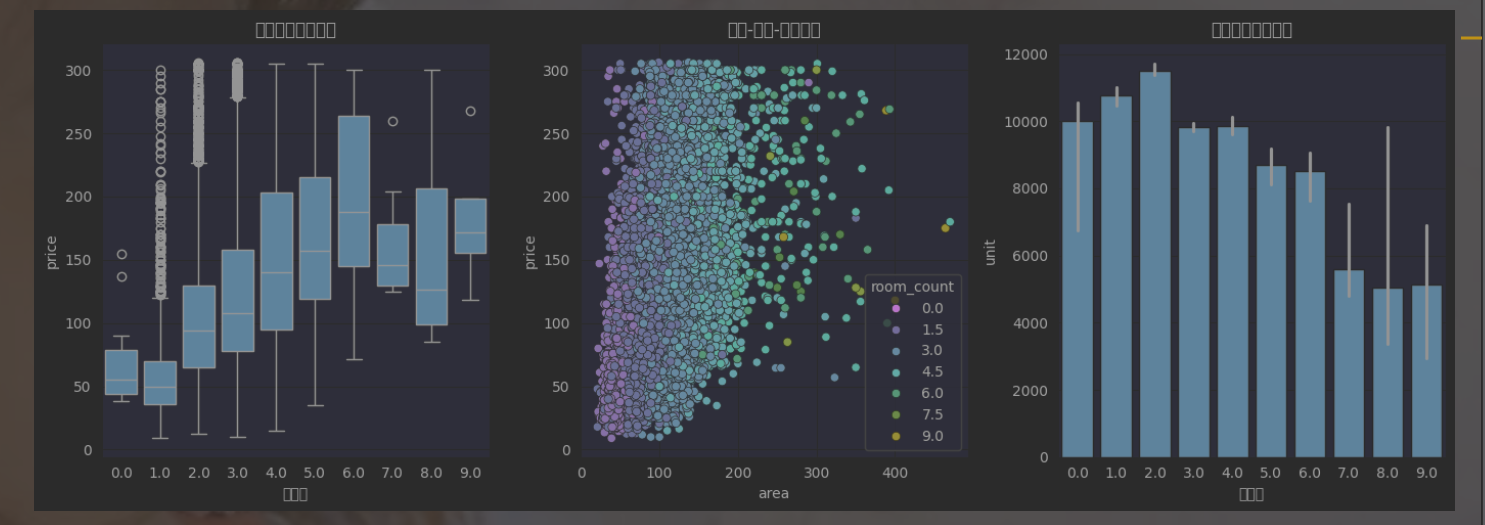
问题编号: A5 问题: 哪种户型最受欢迎?三室比两室贵多少? 分析主题: 户型分析 分析目标: 分析不同户型的市场表现 分组字段: rooms 指标/方法: 占比/平均单价/溢价率
print("\n=== A5 户型分析 ===")# 提取房间数(示例:"3室2厅" -> 3)
df['room_count'] = df['rooms'].str.extract('(\d+)室').astype(float)# 按户型统计
room_stats = df.groupby('room_count').agg({'price': ['mean', 'median'],'unit': 'median','area': 'median','city': 'nunique'
}).sort_values(('price', 'mean'))print("\n各户型市场表现:")
display(room_stats)# 可视化
plt.figure(figsize=(14, 5))plt.subplot(131)
sns.boxplot(x='room_count', y='price', data=df)
plt.title('不同户型总价分布')
plt.xlabel('房间数')plt.subplot(132)
sns.scatterplot(x='area', y='price', hue='room_count', data=df, palette='viridis')
plt.title('面积-价格-户型关系')plt.subplot(133)
sns.barplot(x='room_count', y='unit', data=df, estimator=np.median)
plt.title('不同户型单价对比')
plt.xlabel('房间数')plt.tight_layout()
plt.show()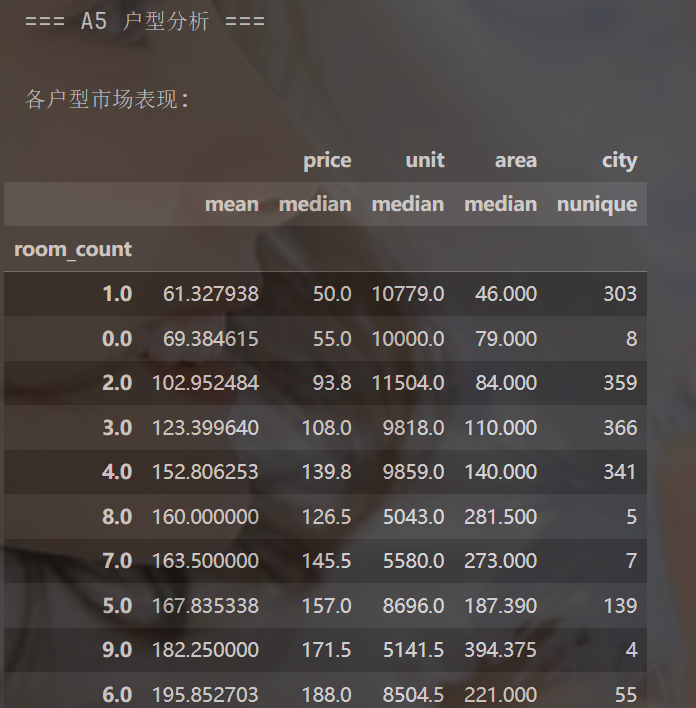
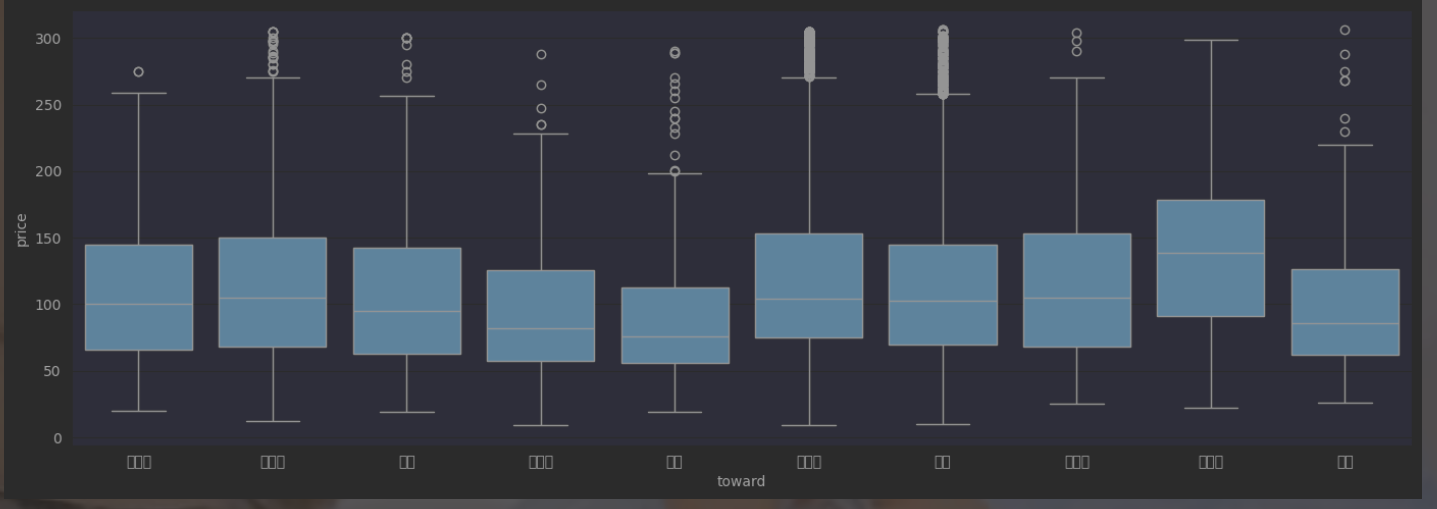
问题编号: A6 问题: 南北向是否真比单一朝向贵?贵多少? 分析主题: 朝向溢价 分析目标: 评估不同朝向的价格差异 分组字段: toward 指标/方法: 方差分析/多重比较
df['toward'].value_counts()
df.groupby('toward').agg({'price':['mean','median'],'unit':'median','building_age':'mean',
})
# 数据可视化
plt.figure(figsize=(14, 5))
sns.boxplot(x='toward', y='price', data=df)
plt.tight_layout()运行结果如下:
以上就是通过项目来加强学习的整体内容,有兴趣也可是看看视频教程:
https://www.bilibili.com/video/BV1D9GLzyEL6?spm_id_from=333.788.videopod.episodes&vd_source=2fabb5d4151ae7af2ad1f5a9905c5bbe&p=63