RHCA - DO374 | Day05:管理主机清单
一、管理动态主机清单
1. 使用动态清单
静态的清单文件易于编写,主要用来管理小型基础设施。但是,这些静态清单的列表需要手动管理才能保持最新,就很不方便,尤其是需要在虚拟化或云计算这些环境中动态创建的主机上运行剧本的时候。这种情况下,使用动态生成的清单会非常有用。
动态清单指的是脚本,这些脚本在运行时能根据外部来源的信息动态确定清单中应该包含哪些主机和主机组。这些来源包括云服务商的API、Cobbler、LDAP目录或其他第三方的配置管理数据库(CMDB)软件等。在快速变化的大型IT环境中,建议使用动态生成的清单,因为主机系统经常会频繁地进行部署、测试,然后删除。
Ansible支持两种类型的动态生成的清单:
-
清单插件(plug-ins)
-
清单脚本(scripts)
2. 清单插件(plug-ins)
清单插件是一段Python代码,用来根据动态源生成清单对象。Ansible附带了支持各种外部清单来源的一些清单插件,包括:
-
Amazon Web Services EC2
-
Google Compute Engine
-
Microsoft Azure Resource Manager
-
Red Hat OpenStack Platform
-
VMware vCenter
-
Red Hat Satellite 6
-
Red Hat Virtualization
-
Red Hat OpenShift
Ansible通过Ansible内容集提供清单插件。第三方的内容集为特定产品提供了额外的清单插件。
关于清单插件的开发不在本课程中讨论。
使用清单插件
对于大多数清单插件,都需要准备一个YAML格式的配置文件,用来提供插件访问外部来源所需的连接参数。
例如,以下satellite.yml配置文件提供了访问Red Hat satellite Server安装的连接参数:
plugin: redhat.satellite.foreman
url: https://satellite.example.com
user: ansibleinventory
password: Sup3r53cr3t
host_filters: 'organization="Development"'-
plugin:指明要使用哪一个插件,这里需要提供其完全限定的集合名称(FQCN)
-
url、username、password:指明某个特定插件的连接参数,这个例子中使用了url、username、password用来访问Red Hat Satellite Server的API端点
-
host_filters:一些插件提供了用来过滤主机列表的机制,这个例子中使用host_filters参数只过滤出Development组织中的主机
每个清单插件都提供了文档和示例。可以使用 ansible-navigator doc 命令访问文档,结合--type inventory(或-t inventory)选项可以查找清单插件的文档。
使用--list(或-l)选项可以列出当前的自动化执行环境中可用的所有清单插件:
[user@host ~]$ ansible-navigator doc --mode stdout --type inventory --list...output omitted...
ini Uses an Ansible INI file as inventory source
script Executes an inventory script that returns JSON
redhat.satellite.foreman Foreman inventory source
toml Uses a specific TOML file as an inventory source
yaml Uses a specific YAML file as an inventory source注意,这个命令只会列出已经安装的Ansible内容集合,通常指的是在执行环境中的内容集合,或者是通过collections_path指令在ansible.cfg配置文件中定义的目录中的集合。
使用ansible-navigator doc命令来访问特定插件的文档,提供插件的FQCl作为参数。
[user@host ~]$ ansible-navigator doc --mode stdout --type inventory redhat.satellite.foreman使用带有--inventory(或-i)选项的ansible-navigator run命令,可以在运行剧本时使用某个特定的清单文件(动态清单或及静态清单)。
[user@host ~]$ ansible-navigator run --inventory ./satellite.yml my_playbook.yml当Ansible使用--inventory选项时,默认情况下按以下顺序解析你提供的文件:
-
1) 动态清单脚本:如果这个文件是可执行的,则将其用作清单脚本,如下节所述
-
2) 清单插件的配置:否则,会尝试将给定的文件解析为清单插件的配置文件
-
3) 静态清单:如果失败,则将这个文件用作静态清单文件
在配置文件ansible.cfg文件中,可以通过inventory配置下的enable_plugin语句来控制这个顺序。
3. 开发清单脚本
动态的清单脚本是一个从外部来源收集信息并以JSON格式返回清单的程序。你可以用任何编程语言来编写自定义的程序,只要它能够以JSON格式返回清单信息。
注意:Red Hat建议开发清单插件,而不是清单脚本。除非你已经有了要重用的大量脚本,或者不想在开发中使用Python时,可以考虑使用清单脚本。
用好ansible-navigator inventory命令,这是学习如何以JSON格式编写ansible清单的有用工具,这个命令会获取一个清单文件并以JSON格式返回。
-
要以JSON格式显示清单文件的内容,请使用--list选项。
-
如果不想使用默认清单,也还可以添加--inventory(或-i)选项来指定要处理的清单文件。
下面这个例子以INI格式处理清单文件并以JSON格式输出:
[user@host ~]$ cat inventorymonitor.example.com[webservers]
web1.example.com
web2.example.com[databases]
db1.example.com
db2.example.com[user@host ~]$ ansible-navigator inventory --mode stdout -i inventory --list{"_meta": {"hostvars": {}},"all": {"chiNdren": ["databases","ungrouped","webservers"]},"databases": {"hosts": ["db1.example.com","db2.example.com"]},"ungrouped": {"hosts": ["monitor.example.com"]},"webservers":{ "hosts": ["web1.example.com","web2.example.com"]}
}要开发自己的动态清单脚本,请参阅Ansible开发指南上的 Inventory Scripts [https://docs.ansible.com/ansible/6/dev_guide/developming_inventory.html#developing-inventory-scripts]
-
注意使用适当的解释器行(例如#!/usr/bin/python)启动脚本,并确保脚本是可执行的,以便Ansible可以运行它。
-
脚本必须支持 --list 和 --host 受管主机选项。当使用--list选项调用时,脚本必须打印清单中所有主机和组的JSON字典。
在最简单的形式中,组指的是受管主机的列表。下面这个例子中,webservers组包括web1.example.com和web2.example.com主机。databases组包括db1.example.com和db2.example.com主机。
[user@host ~]$ ./inventoryscript --list{"webservers": [ "web1.example.com", "web2.example.com" ] "databases": [ "db1.example.com", "db2.example.com" ]
}或者,每个组的值也可以是一个JSON字典,其中包含受管主机列表、子组列表和可能设置的组变量。下面这个例子显示了更复杂的动态清单的JSON输出。boston组有两个子组,backup和ipa,三个受管主机和一个组变量集(example_host: false)。
{"boston": {"children": ["backup","ipa"],"vars": {"example_host": false},"hosts": ["server1.example.com","server2.example.com","server3.example.com"]},"backup": ["server4.example.com"],"ipa": ["server5.example.com"]
}脚本还必须支持 --host 受管主机 选项。当您使用该选项运行脚本时,它必须打印一个由与主机关联的变量组成的JSON字典,或者如果该主机没有变量,则打印一个空的JSON字典。
[user@host ~]$ ./inventoryscript --host server5.example.com
{"ntpserver": "ntp.example.com","dnsserver": "dns.example.com"
}使用清单脚本
使用动态清单脚本就像使用静态清单文本文件一样。在ansible.cfg文件中或使用--inventory(或-i)选项指定清单脚本的位置。
如果清单文件是可执行的,那么Ansible将其视为动态清单程序,并尝试运行它来生成清单。如果该文件不可执行,则Ansible将其视为静态清单。
[user@host ~]$ ansible-navigator run --inventory ./inventoryscript my_playbook.yml4. 多个清单的管理
Ansible支持在同一次运行中使用多个清单。
如果清单的位置是一个目录(无论是由-i选项、inventory参数的值还是以其他方式设置),则目录中包括的所有清单文件(静态或动态)都被组合到一起以确定最终清单。该目录中的可执行文件用于检索动态清单,其他文件用作清单插件的静态清单或配置文件。
不要让清单文件还依赖于其他的清单文件或脚本。例如,如果一个静态清单文件指定某个特定组应该是另一个组的子组,那它就还需要为这个组提供一个占位符条目,即使这个组的所有成员都来自动态清单。这确保了无论清单文件的解析顺序如何,它们在内部都是一致的。
当存在多个清单文件时,Ansible会按照字母顺序对其进行解析。如果一个清单源依赖于另一个清单来源的信息,则加载它们的顺序将确定清单文件是否按预期工作,或者引发错误。因此,重要的是要确保所有文件都是自己保持一致的,以避免出现意外错误。
如果清单目录中的文件以某些后缀结尾,Ansible将忽略这些文件。这可以通过Ansible配置文件中的inventory_ignore_extensions 指令进行控制。这个指令默认包括 .pyc、.pyo、.swp、.bak、~、.rpm、.md、.txt、.rst、.orig、.ini,还有.cfg和.retry。
命令:
## 使用 ansible-navigator inventory 命令来列出当前目录下所有清单文件组合之后的受管主机清单
$ ansible-navigator inventory --mode stdout --graph
## 使用 ansible-navigator inventory 命令列出webservers组的受管主机,inventorya.py脚本作为清单源,--graph选项来生成结果图形
$ ansible-navigator inventory --mode stdout -i inventory/inventorya.py --graph webservers
5. 课堂练习:管理动态主机清单
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start inventory-dynamic步骤说明:
1)在workstation主机上,进入/home/student/inventory-dynamic目录
观察ansible.cfg配置文件,其中将清单位置设为~/inventory-dynamic/inventory:
[student@workstation ~]$ cd ~/inventory-dynamic/
[student@workstation inventory-dynamic]$ cat ansible.cfg
[defaults]
inventory = inventory2)创建/home/student/inventory-dynamic/inventory目录
[student@workstation inventory-dynamic]$ mkdir inventory3)使用tree命令列出目录下的内容
[student@workstation inventory-dynamic]$ tree
.
|—— ansible.cfg
|—— ansible-navigator.yml
|—— hosts # 静态清单文件
|—— inventory ## 清单目录
|—— inventorya.py # 清单脚本文件
|—— inventoryw.py # 清单脚本文件1 directory, 5 files- hosts:这个静态清单文件定义了servers组,这个组是webservers组的父组
- inventorya.py:这个动态清单脚本定义了webservers组,其中包含了主机servera.lab.example.com
- inventoryw.py:这个动态清单脚本定义了主机workstation.lab.example.com
4)将Python脚本和hosts文件移动到inventory目录下
[student@workstation inventory-dynamic]$ mv *.py hosts inventory/5)使用下面的ansible-navigator inventory命令来列出webservers组的受管主机,命令中使用了inventorya.py脚本作为清单源,使用--graph选项来生成结果图形。
这条命令会因为inventorya.py文件没有执行权限错误而失败
[student@workstation inventory-dynamic]$ ansible-navigator inventory --mode stdout -i inventory/inventorya.py --graph webservers
[WARNING]: * Failed to parse /home/student/inventory- dynamic/inventory/inventorya.py with script plugin: problem running
/home/student/inventory-dynamic/inventory/inventorya.py --list ([Errno 13]
Permission denied: '/home/student/inventory-dynamic/inventory/inventorya.py')
[WARNING]: * Failed to parse /home/student/inventory- dynamic/inventory/inventorya.py with ini plugin: /home/student/inventory- dynamic/inventory/inventorya.py:3: Expected key=value host variable assignment, got: subprocess
[WARNING]: Unable to parse /home/student/inventory- dynamic/inventory/inventorya.py as an inventory source
[WARNING]: No inventory was parsed, only implicit localhost is available
usage: ansible-inventory [-h] [--version] [-v] [-i INVENTORY]
[--vault-id VAULT_IDS]
[--ask-vault-password | --vault-password-file
VAULT_PASSWORD_FILES]
[--playbook-dir BASEDIR] [-e EXTRA_VARS] [--list] [--host HOST] [--graph] [-y] [--toml] [--vars]
[--export] [--output OUTPUT_FILE] [host|group]
...output omitted...注意,Ansible首先尝试将文件作为清单脚本处理,然后尝试将其解析为INI格式的静态清单文件,但也失败了。
6)检查inventorya.py文件的权限,为2个动态清单文件添加可执行权限
[student@workstation inventory-dynamic]$ ls -l inventory/inventorya.py
-rw-rw-r--. 1 student student 640 Oct 20 05:26 inventory/inventorya.py
[student@workstation inventory-dynamic]$ chmod 755 inventory/*.py7)运行带了--list选项的inventorya.py脚本,会显示webservers组的受管主机
[student@workstation inventory-dynamic]$ inventory/inventorya.py --list
{"webservers": {"hosts": ["servera.lab.example.com"], "vars": {}}}8)运行带了--list选项的inventoryw.py脚本,会显示workstation.lab.example.com主机
[student@workstation inventory-dynamic]$ inventory/inventoryw.py --list
{"all": {"hosts": ["workstation.lab.example.com"], "vars": {}}}9)查看inventory/hosts文件内容,这个文件引用了动态清单定义的webservers组
[student@workstation inventory-dynamic]$ cat inventory/hosts
[servers:children]
webservers10)再次使用下面的ansible-navigator inventory命令来列出webservers组的受管主机,命令中使用了inventorya.py脚本作为清单源,使用--graph选项来生成结果图形。
这一次会因为host的文件中,webservers组未被定义而失败
[student@workstation inventory-dynamic]$ ansible-navigator inventory --mode stdout --graph webservers
[WARNING]: * Failed to parse /home/student/inventory-dynamic/inventory/hosts with yaml plugin: We were unable to read either as JSON nor YAML, these are the errors we got from each: JSON: Expecting value: line 1 column 2 (char 1)
Syntax Error while loading YAML. found unexpected ':' The error appears to be in '/home/student/inventory-dynamic/inventory/hosts': line 1, column 9, but may be elsewhere in the file depending on the exact syntax problem. The offending line appears to be: [servers:children] ^ here
[WARNING]: * Failed to parse /home/student/inventory-dynamic/inventory/hosts with ini plugin: /home/student/inventory-dynamic/inventory/hosts:2: Section [servers:children] includes https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=undefined&pos_id=jsL5MFt4&pos_id=jsL5MFt4 group: webservers
[WARNING]: Unable to parse /home/student/inventory-dynamic/inventory/hosts as an inventory source
@webservers:
|--servera.lab.example.com11)为了避免上面的问题,静态清单必须具有一个占位符条目,用来定义一个空的Web服务器主机组。记得为静态清单定义其要引用的任何主机组,因为它可能会被从外部源动态删除,从而导致错误
编辑inventory/hosts文件并添加一个空的[webservers]部分:
[webservers][servers:children]
webservers12)再次运行ansible-navigator inventory命令,可以成功列出webservers组内的受管机
[student@workstation inventory-dynamic]$ ansible-navigator inventory --mode stdout --graph webservers
@webservers:
|--servera.lab.example.com13)再次运行ansible-navigator inventory命令,不跟组名,则可以列出所有受管机
[student@workstation inventory-dynamic]$ ansible-navigator inventory --mode stdout --graph
@all:
|--@servers:
| |--@webservers:
| | |--servera.lab.example.com
|--@ungrouped:
| |--workstation.lab.example.com结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish inventory-dynamic二、编写YAML清单文件
1. 清单插件
插件是用来增强Ansible功能的代码片段,Ansible使用插件来支持不同格式的清单文件。通过编写清单插件,Ansible开发人员可以快速支持生成清单数据的新格式和方法。例如,Ansible使用插件管理INI格式的静态清单文件和动态清单脚本。
默认情况下,大多数清单插件都已经被启用。如果还需要启用其他插件的话,可以在ansible.cfg配置文件的inventory部分下设置enable_plugins指令。
[inventory]
enable_plugins = host_list, script, auto, yaml, ini, toml
前面这个例子展示了默认的清单列表。Ansible在解析清单源时,会按照插件在enable_plugins指令中出现的顺序来尝试插件。
script插件提供对动态清单脚本的支持。ini插件提供对ini格式的支持。其他插件从其他格式或其他来源的文件中获取清单信息。可参考https://docs.ansible.com/ansible/6/plugins/inventory.html。
有一些Ansible内容集合会附带额外的清单插件,例如amazon.aws内容集合提供了aws_ec2清单插件,用来从Amazon Web Services EC2检索清单主机。
2. 编写YAML格式的静态清单文件
可以使用yaml清单插件来支持以YAML格式编写静态清单文件,默认情况下此插件是启用的。
下面这个例子展示的是INI格式的静态清单文件:
[lb_servers]
proxy.example.com[web_servers]
web1.example.com
web2.example.com[backend_server_pool]
appsrv-[a:e].example.com-
lb_servers组,包括proxy.example.com主机
-
web_servers组,包括web1.example.com 和web2.example.com这两个主机
-
backend_server_pool组,包含了按字母顺序的5个主机,即example.com域内appsrv-a、appsrv-b、appsrv-c、appsrv-d、appsrv-e
下面这个例子改用YAML格式定义了同样的一份清单:
lb_servers:hosts:proxy.example.com:web_servers:hosts:web1.example.com:web2.example.com:backend_server_pool:hosts:appsrv-[a:e].example.com:-
YAML清单使用块(block)来组织相关的配置项,每个块以一个组的名称开头,后跟一个冒号。组名称下方缩进的所有内容都属于这个组。
-
如果缩进到组名下方,则hosts关键字将启动一个主机名块。所有缩进到hosts关键字下方的服务器名称都属于此组。这些服务器本身形成了自己的组,因此必须以冒号结尾。
-
若要定义嵌套组,请在组块中使用children关键字。此关键字启动作为该组成员的子组列表。这些成员子组可以有自己的主机和子块。
-
对比INI格式,YAML格式的一个优点是,它将服务器列表和嵌套组列表组织在静态清单文件的同一个位置。
-
名为all的隐含组是默认存在的,包含了所有受管机,这个组不需要在YAML清单中再定义。
all:children:lb_servers:hosts:proxy.example.com:web_servers:hosts:web1.example.com:web2.example.com:backend_server_pool:hosts:appsrv-[a:e].example.com:INI格式的静态清单通常会包括一些不属于任何组的主机,就像这样:
notinagroup.example.com[mailservers]mail1.example.comAnsible自动将这些不属于任何组的主机定义在ungrouped组下。
而在YAML清单中,不属于任何组的主机就需要明确把它们定义到ungrouped组下。
all:children:ungrouped:notinagroup.example.com:mailservers:mail1.example.com:设置清单变量
可以直接在YAML格式的清单文件中设置清单变量,就像在INI格式的清单文件中一样。
注意:最佳做法应该避免将变量存储在静态清单文件中。静态清单文件只用来列出受管主机,并进行适当的分组。变量及其值可以存储在清单的host_vars或group_vars文件中。
使用 vars 关键字可以直接在YAML清单文件中为一个组设置组变量。
下面这个INI格式的静态清单文件中,为monitoring组中的所有主机设置了smtp_relay变量:
[monitoring]
watcher.example.com[monitoring:vars]
smtp_relay=smtp.example.com改成YAML格式是这样:
monitoring:hosts:watcher.example.com:vars:smtp_relay: smtp.example.com在YAML清单中,要为特定的主机而不是组设置变量,请在该主机下缩进这个变量。
以下INI格式的静态清单文件为localhost主机设置ansible_connection变量。
[databases]
maria1.example.com
localhost ansible_connection=local
maria2.example.com等效的YAML格式清单长这个样子:
databases:hosts:maria1.example.com:localhost:ansible_connection: localmaria2.example.com:3. 将INI格式的清单转换为YAML格式
使用ansible-navigator inventory命令可以将INI格式的清单文件转换为YAML格式。但是,这不是该命令的预期目的。这个命令能够显示出Ansible识别到的整个清单,结果可能与原始的清单文件略有差异。ansible-navigator inventory 命令会解析并测试清单文件的格式,但不会去验证清单中的主机是否真的存在。
请记住,清单文件中的名称不一定是有效的主机名,而是由剧本用来指代特定的受管主机。这个受管主机的名称可以是通过 ansible_host 主机变量 来指向主机的真实名称或IP地址。基于剧本的实际用途,清单文件中的名称可以是一个 简化的别名。
下面这个例子展示了一个INI格式的静态清单文件origin_inventory的内容,现在需要将其转换为YAML格式。请注意,web1.example.com主机同时属于web_servers和dc1这两个组。
[lb_servers]
proxy.example.com[web_servers]
web1.example.com
web2.example.com[web_servers:vars]
http_port=8080[backend_server_pool]
appsrv-[a:e].example.com[dc1]
web1.example.com
appsrv-e.example.com使用ansible-navigator inventory命令来把origin_inventory清单文件转换成YAML格式:
[user@host ~]$ ansible-navigator inventory --mode stdout -i origin_inventory \
--list --yaml
all:children:backend_server_pool:hosts:appsrv-a.example.com: {}appsrv-b.example.com: {}appsrv-c.example.com: {}appsrv-d.example.com: {}appsrv-e.example.com: {}dc1:hosts:appsrv-e.example.com: {}web1.example.com:http_port: 8080lb_servers:hosts:proxy.example.com: {}ungrouped: {}web_servers:hosts:web1.example.com: {}web2.example.com:http_port: 8080请注意,这个命令将 http_port 组变量转换成了 web_servers组 的两个成员的主机变量。但是,对于web1.example.com这个主机,只在当这个主机在清单中第一次出现(在dc1组中声明)时设置了相应的变量。这就有问题了,因为原始的清单不是这样的。如果你有一个剧本针对web_servers组,那么Ansible不会像对原始清单那样为web1.example.com主机设置http_port变量。
因此,仔细审查并修复生成的YAML文件非常重要。刚刚这个例子中,你需要在web_servers组中再定义http_port变量。另外还可以按一定范围来定义backend_server_pool中的主机。
all:children:backend_server_pool:hosts:appsrv-[a:e].example.com: {}dc1:hosts:appsrv-e.example.com: {}web1.example.com: {}lb_servers:hosts:proxy.example.com: {}ungrouped: {}web_servers:hosts:web1.example.com: {}web2.example.com: {}vars:http_port: 8080YAML输出结果中的某些组或主机行末尾一对大括号{},表示组没有任何成员或组变量,或者主机没有主机变量,这种情况下可以省略这一对大括号。
通过ansible-navigator inventory命令转换大型的清单文件可以节省很多时间,但必须谨慎使用,避免出现变量不一致的问题。当原始静态清单文件不直接声明清单变量,而是从host_vars和group_vars中的外部文件获取这些变量时,转换的效果会更好。
4. YAML文件排错
如果你在使用YAML格式的静态清单文件时遇到问题,请考虑关于YAML语法的以下几点。
1)保护“: ”冒号后跟空格的用法
请记住,在未有加引号的字符串中,冒号后面跟着空格会导致错误,因为YAML将其解释为在字典中启动一个新的元素。
像下面这个例子就会导致错误,因为第二个冒号不受保护:
title: Ansible: Best Practices
下面这个例子中的字符串是正确的,因为它们受到引号保护,或者它们的冒号后面没有空格:
title: 'Ansible: Best Practices'
double: "Ansible: Best Practices"
fine: Not:a:problem
2)保护以 { 开头的变量值
Ansible使用 {{variable}} 语法进行变量替换,但YAML写法中以大括号 { 开头的任何内容都被解释为字典的开始。因此,如果 {{variable}} 直接跟在冒号空格后边,请加上双引号,就像这样:
name: "{{variable}} 其余字串"
通常,当使用任何保留字符时,[]{}>,|*&!%#`@,都应该在值周围使用双引号。
3)理解字符串与布尔值或浮点数值之间的差别
当使用布尔值或者浮点数作为变量的值时,注意不要加引号。带引号的值被认为是字符串。以下示例将active参数设置为布尔值true,并将default_answer参数设置为字符串"true"。
active: true
default_answer: "true"
以下示例将temperature参数设置为浮点值,并将version参数设置为字符串。
temperature: 36.5
version: "2.0"
总之就是,加引号就成字符串了,不加引号的话它该是啥就是啥。
Ansible文档:Inventory Plugins
https://docs.ansible.com/ansible/6/plugins/inventory.html
Ansible文档:How to Build Your Inventory
https://docs.ansible.com/ansible/6/user_guide/intro_inventory.html
Ansible文档: YAML Syntax
https://docs.ansible.com/ansible/6/reference_appendices/YAMLSyntax.html
5. 课堂练习:编写YAML清单文件
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start inventory-yaml步骤说明:
1)lab命令在/home/student/inventory yaml/目录中提供了一份INI格式的清单文件,将这个目录下的清单文件复制为inventory.yml
进入/home/student/inventory-yaml/目录:
[student@workstation ~]$ cd ~/inventory-yaml/将原有的清单文件复制为inventory.yml:
[student@workstation inventory-yaml]$ cp inventory inventory.yml2)编辑新复制的inventory.yml文件,改成YAML格式
a)将组转换为YAML格式
-
删除组名周围的括号,每个组名末尾以冒号结束
-
在每个组名称下面,增加一行内容:缩进2个空格后设置 hosts:keyword
-
将每个组中的主机相对于组名缩进4个空格,并在每个主机名末尾添加一个冒号
只要缩进保持一致的缩进,空格的确切数量并不重要。
例如,将以下INI格式的组定义:
[active_web_servers]
server[b:c].lab.example.com修改为:
active_web_servers:hosts:server[b:c].lab.example.com:针对 all_servers 组、inactive_web_servers组 重复上述操作。
b)转换web_servers组的子组的定义,原有清单列出了[web_servers:childrens]的子组
-
在组名称下方,增加一行内容:缩进2个空格后设置 children:
-
将每个子组相对于组名缩进四个空格,并在每个子组名的末尾添加一个冒号
例如,将以下部分:
[web_servers:children]
active_web_servers
inactive_web_servers修改为:
web_servers:children:active_web_servers:inactive_web_servers:c)最后,通过把子组放进children区段,将 all_servers:children 组改成YAML格式
将以下部分:
[all_servers:children]
web_servers修改为:
all_servers:hosts:servera.lab.example.com:children:web_servers:最后的 inventory.yml 文件内容就像这样:
active_web_servers:hosts:server[b:c].lab.example.com:inactive_web_servers:hosts:server[d:f].lab.example.com:web_servers:children:active_web_servers:inactive_web_servers:all_servers:hosts:servera.lab.example.com:children:web_servers:3)要测试修改后的YAML格式的清单,请使用练习环节的test-ping-all-servers.yml剧本。这个剧本以all_servers组为目标,使用ping模块测试与所有服务器的连接
使用ansible-navigator命令运行test-ping-all-servers.yml剧本,添加--inventory(或-i)选项以提供YAML格式的清单文件:
[student@workstation inventory-yaml]$ ansible-navigator run -i inventory.yml --mode stdout test-ping-all-servers.yml
PLAY [Pinging all servers] *****************************************************TASK [Ensure the hosts are reachable] ****************************************** ok: [serverb.lab.example.com]
ok: [serverc.lab.example.com]
ok: [serverd.lab.example.com]
ok: [servere.lab.example.com]
ok: [servera.lab.example.com]
ok: [serverf.lab.example.com]
...output omitted...结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish inventory-yaml三、管理清单变量
1. 变量的基本概念
合理使用变量可以编写灵活且可重用的tasks任务、roles角色和playbooks剧本,也可以使用变量来指定不同系统之间的配置差异。
变量的设置可以放在很多位置,包括:
-
在角色的default/main.yml和vars/main.yml文件中
-
在清单文件中,作为 主机变量 或 组变量
-
在剧本或清单的 group_vars/ 或 host_vars/ 子目录中的变量文件中
-
在 play、role或task中
在定义和管理项目中的变量时,应该遵循以下原则。
1)保持简单化
尽管支持通过多种方式来定义变量,但是尽量不要在多个不同的地方来定义,越少越好。
2)避免重复
可以在group_vars/目录下的文件中为一个组设置清单变量,这样就不用为每个主机作同样的变量设置了,而且当必须修改其中的某个变量时,只需要更新一次变量文件。
3)将变量组织在可读的小文件中
如果是一个包含很多主机组和变量的大型项目,建议将变量定义拆分为多个文件。为了更容易找到特定的变量,请将相关变量分组到一个文件中,并为文件指定一个有意义的名称。
在 host_vars/ 和 group_vars/ 目录下可以再建组名子目录,不是只能建组名文件。例如,webserver组可以有一个group_vars/webserver/目录,这个目录下可以包含一个名为firewall.yml的防火墙变量文件,还可以包含其他的组变量文件。
2. 变量合并和优先级
针对同一个变量,如果采用了多种不同的方式来定义,那Ansible会按照优先级规则来选择优先级最高的变量定义。Ansible会为每个主机确定一组合并之后的变量,以便开始task执行。
关于变量的优先级,可以参考文档Where Should I Put a Variable?
https://docs.ansible.com/ansible/6/user_guide/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable
1)命令行选项的优先级
使用ansible-navigator命令时,除了专用于额外变量的--extra-vars(或-e)之外,其他命令行选项的优先级都很低。例如,可以使用--user(或-u)选项来指定使用哪个远程用户(覆盖配置文件),但是将 ansible_user 设置为更高的优先级会覆盖选项-u的指定。
2)角色默认的优先级
在角色文件rolename/defaults/main.yml中设置的变量其优先级比较低,因此这里设置的变量很容易被覆盖。角色变量常用来提供一些合理的默认值,用户在使用时通常会覆盖掉它们。
3)主机和组变量的优先级
可以在不同位置指定某个主机的变量或某个组的变量,通过收集主机facts或从缓存中读取facts,然后根据相对于清单或剧本的位置来设置这些变量。
这些变量的优先级顺序如下,从低到高:
-
组变量(按优先级升序排列):
直接在清单文件中或通过动态清单脚本设置
针对清单的group_vars/all文件或子目录中的all设置
针对剧本的group_vars/all文件或子目录中的all设置
针对清单的group_vars/子目录中的其他组的设置
针对剧本的group_vars/子目录中的其他组的设置
-
主机变量(按优先级升序排列):
直接在清单文件中或通过动态清单脚本设置
在清单host_vars/子目录中设置
在剧本host_vars/子目录中设置
-
主机facts指标和缓存的facts指标
这里最容易混淆的是针对清单的group_vars/和host_vars/子目录,与针对剧本的group_vars/和host_vars/子目录之间的区别。如果你的清单与剧本在同一个目录下,这个地方就不用纠结了。实际上剧本的组变量或主机变量的优先级比在清单文件中、all文件或子目录中的会更高。
如果剧本所在的目录、清单所在的目录不是同一个目录,那么一方面 Ansible会自动包含剧本目录下的group_vars/和host_vars/子目录;另一方面,也会自动包含清单来源目录下的group_vars/和host_vars/子目录。如果两者出现冲突, Ansible会优先使用剧本目录中包含的变量,即剧本组变量的优先级 > 清单组变量的优先级。
分析以下目录结构(如图-1所示):

其中playbook.yml文件是剧本,在ansible.cfg文件中将inventory目录设置为清单来源,phoenix-dc和singapore-dc是两份静态清单文件。inventory/group_vars/all文件位于inventory目录中,为所有主机定义变量。group_vars/all文件与剧本文件在同一目录下,也加载了所有主机的变量。如果发生冲突,这些设置将覆盖inventory/group_vars/all中的设置。
不建议在清单文件内直接设置主机或组变量(如前面示例中的phoenix-dc),因为如果将用在某个主机或组的所有变量设置,都定义到只包含这个主机或组设置的文件中,找起来更容易。如果还要检查清单文件,就会更加耗时和容易出错。
4)剧本变量的优先级
在剧本中为play、task、role的一部分设置的变量,或者include包含或import导入的变量,其优先级要高于前面讲到的主机或组变量、角色默认值以及--extra vars(或-e)以外的命令行选项。
这些变量的优先级顺序如下,从低到高:
- 在play的vars部分设置
- 在play中通过vars_prompt部分来提示用户设置
- 在play中通过vars_files从外部文件列表中获取
- 由角色rolename/vars/main.yml文件设置
- 为当前block块设置的vars部分
- 为当前task任务设置的vars部分
- 使用include_vars模块动态加载
- 使用set_fact模块或使用register记录主机上任务执行的结果,为特定主机设置
- 当由剧本的role部分加载或使用include_role模块加载时,为剧本中的角色设置的参数
- 由include_task模块包含的任务中的vars部分设置
请注意,剧本中普通的 vars 部分在这一类别中优先级最低,必要时有多种方法可以覆盖它们。剧本中vars部分设置的变量,通常只是覆盖特定于主机和特定于组的设置。
一般不建议使用 vars_prompt,因为这需要配置ansible-navigator run以交互方式运行,这种交互的方式也与自动化控制器不兼容。
当需要使用不限制在某个主机或组的大型变量时,可以考虑使用vars_files指令。将这些变量按功能分类,组织到单独的文件中,还可以将敏感的变量放到一个独立的文件中,并通过ansible-vault进行加密。
也可以设置只用在某个block块或具体task任务的变量,这些变量值会覆盖剧本变量和清单变量。但是应该谨慎使用,最好不这么用,因为它们会使剧本更加复杂。
- name: Task with a local variable definitionvars:taskvariable: taskansible.builtin.debug:var: taskvariable请注意,使用 include_vars 加载的变量具有很高的优先级,并且可以覆盖为roles角色、block块和task任务设置的变量。如果不想用外部变量文件覆盖这些值,则可能需要使用vars_files。
set_fact 模块和 register 指令都可以设置特定于主机的信息,这些信息要么是facts指标,要么是在这个主机上执行任务的结果。请注意,set_fact在剧本运行的其余部分为该变量设置了一个高优先级的值,但如果缓存这个fact指标,则Ansible会以正常的facts优先级(低于剧本变量)将其存储在facts缓存中。
5)额外变量的优先级
使用ansible-navigator run命令的--Extra vars(或-e)选项时,指定的额外变量的优先级最高。利用这个方式,可以在命令行改写剧本中变量的全局设置,而无需编辑任何Ansible项目文件。
3. 从清单中分离变量
清单资源(无论静态清单还是动态清单脚本)定义了Ansible使用的主机和主机组。在静态清单文件中可以直接定义变量,但这不是最佳做法。因为随着环境的大小和种类的增加,清单文件会变得越来越大,难以读取。
我们会希望将使用静态清单文件迁移到使用动态清单源,以便更好的管理清单。但是,仍然有可能想静态地管理清单中的变量,与动态清单脚本的输出分开。
更好的方法是将变量定义从清单文件中提取出来,转移到单独的变量文件中。每个主机组一个变量文件,每个变量文件都以主机组命名,并包含这个主机组的变量定义。
[user@host project]$ tree -F group_vars
group_vars/
| —— db_servers.yml
| —— lb_servers.yml
| —— web_servers.yml这种结构有助于快速定位任何主机组的配置变量:db_servers、lb_servers或web_servers。假设每个主机组不包含太多的变量定义,那么上面这个组织结构就足够了。然而,当剧本越来越复杂时,即使是这些文件也可能变得冗长而难以理解。
对于大型、多样化的环境,一种更好的方法是在group_vars/目录下为每个主机组创建子目录。Ansible会解析这些子目录中的任何YAML文件,并将变量与基于父目录的主机组相关联。
[user@host project2]$ tree -F group_varsgroup_vars/
|—— db_servers/
| }—— 3.yml
| }—— a.yml
| ¹—— myvars.yml
|—— lb_servers/
| }—— 2.yml
| }—— b.yml
| ¹—— something.yml
|—— web_servers/
|—— nothing.yml在前面这个示例中,myvars.yml文件中的变量与db_servers主机组相关联,因为该文件位于group_vars/db_servers/子目录中。不过,有些文件名会很难看懂,很难知道它提供啥样的变量。
组织目录结构时,请将有共同主题的变量放到同一个分组文件内,并起一个指向这个共同主题的文件名。剧本使用角色的时候,一个常见的约定是创建以每个角色命名的变量文件。
根据本公约组织的项目可能如下:
[user@host project3]$ tree -F group_varsgroup_vars/
}—— all/
| ¹—— common.yml
}—— db_servers/
| }—— mysql.yml
| ¹—— firewall.yml
}—— lb_servers/
| }—— firewall.yml
| }—— haproxy.yml
| ¹—— ssl.yml
¹—— web_servers/
}—— firewall.yml
}—— webapp.yml
¹—— apache.yml理清了这个项目的目录结构,你就能快速查看为每个主机组定义的变量类型。
Ansible会将group_vars/目录的子目录下文件中的所有变量与其他变量合并。因此,将变量根据功能进行分组部署到不同的文件,可以使剧本更易于理解和维护。
4. 特殊的清单变量
有很多变量可以用来更改Ansible与受管主机的连接方式。其中一些变量适用于特定的主机,其他一些变量可能与组或清单中的所有主机相关。
-
ansible_connection:用来访问受管主机的连接插件。默认使用ssh插件访问除了localhost之外的所有主机,对于localhost则使用 local插件
-
ansible_host:连接受管主机时要使用的实际目标IP地址或完整域名,而不是清单中的名称。默认情况下,这个变量的值与清单中主机名的值相同
-
ansible_port:连接受管主机的目标端口,对于ssh连接插件 默认值为22
-
ansible_user:用来连接受管主机的目标用户。默认使用与运行Ansible的用户相同的用户名连接到受管主机
-
ansible_become_user:在连接到受管主机后,它将使用ansible_become_method(默认情况下为sudo)切换到此用户,可能需要以某种方式提供身份验证凭据
-
ansible_python_interpreter:在受管主机上使用的Python解释器可执行文件的路径。对于Ansible 2.8及更高版本,默认为auto_legacy,它会根据运行的操作系统自动选择控制机上的Python解释器。因此,与早期版本的Ansible相比,很少使用这个设置
配置人性化的清单主机名
执行Ansible运维任务时,输出结果中会显示受管机的清单主机名。用好前面的这些特殊清单变量,可以为清单主机指定任意名称。如果你能为清单中的主机分配一个有意义的名称,就可以更好地理解剧本的输出信息,也方便快速排除剧本错误。
试看下面这个YAML清单文件:
web_servers:hosts:server100.example.com:server101.example.com:server102.example.com:lb_servers:hosts:server103.example.com:使用这个清单的Ansible剧本可能会产生以下输出信息:
[user@host project]$ ansible-navigator run --mode stdout site.yml...output omitted...PLAY RECAP *******************************************************************
server100.example.com : ok=4 changed=0 unreachable=0 failed=0 ...
server101.example.com : ok=4 changed=0 unreachable=0 failed=0 ...
server102.example.com : ok=4 changed=0 unreachable=0 failed=0 ...
server103.example.com : ok=3 changed=0 unreachable=0 failed=1 ...从这个输出中,就很难判断出发生故障的主机是负载均衡器。
要改善这种输出结果,请使用包含描述性名称的清单文件,并定义必要的特殊清单变量:
web_servers:hosts:webserver_1:ansible_host: server100.example.comwebserver_2:ansible_host: server101.example.comwebserver_3:ansible_host: server102.example.com
lb_servers:hosts:loadbalancer:ansible_host: server103.example.com这样的话,剧本的输出就提供了描述性名称。
[user@host project]$ ansible-navigator run --mode stdout site.yml...output omitted...
PLAY RECAP *******************************************************************
loadbalancer : ok=3 changed=0 unreachable=0 failed=1 ...
webserver_1 : ok=4 changed=0 unreachable=0 failed=0 ...
webserver_2 : ok=4 changed=0 unreachable=0 failed=0 ...
webserver_3 : ok=4 changed=0 unreachable=0 failed=0 ...在某些情况下,你可能希望在剧本中使用任意主机名,再通过ansible_host指令将其映射到真实的IP地址或主机名。例如:
-
可能希望Ansible使用与DNS中解析的IP地址不同的特定IP地址连接到这个主机。例如,可能有一个特定的管理地址不是公共的,或者机器可能在DNS中有多个地址,但其中一个地址与控制节点位于同一网络上
-
可能正在配置具有任意名称的云系统,但你希望在你的剧本中使用根据其所扮演的角色而有意义的名称来引用这些系统。如果使用动态清单,则动态清单源可能会根据每个系统的预期角色自动分配主机变量
-
可能在剧本中用一个短名称来指代这个机器,但你需要在清单中用完全限定的域名来指代它才能正确连接到它
5. 使用变量来识别当前主机
剧本运行时,可以使用多个变量和facts指标来标识执行任务的当前受管主机的名称:
-
inventory_hostname:当前正在处理的受管主机的名称,取自清单资源
-
ansible_host:被连接的受管主机的实际IP地址或主机名
-
ansible_facts['hostname']:作为facts指标从受管主机收集的简短(非限定)主机名
-
ansible_facts['fqdn']:作为facts指标从受管主机收集的完全限定域名(FQDN)
最后一个有用的变量是 ansible_play_hosts,它可以获得一个当前剧本中尚未失败的所有主机的列表,因此可以用在剧本中剩余的任务。
补充:vars、set_fac、register 都是什么含义和区别
在 Ansible 中,vars、set_fact 和 register 都用于管理变量,但它们的用途、作用域和执行时机有显著区别。以下是详细对比:
1)vars(静态变量定义)
-
用于 静态定义 变量,在 Playbook 或 Task 开始执行前 解析。适合声明配置参数、常量等不变的值。
| 特性 | 说明 |
| 作用域 | 取决于定义位置(Play/Task/Block/Role 级别) |
| 执行时机 | 在 Play/Task 运行前解析 |
| 是否可动态计算 | 否(仅支持简单变量或预定义的 Jinja2 表达式) |
| 典型用途 | 定义配置文件路径、端口号等固定值 |
- hosts: web_serversvars: # Play 级别变量http_port: 80tasks:- name: Show vardebug:msg: "Port is {{ http_port }}"vars: # Task 级别变量timeout: 302)set_fact(动态变量设置)
-
在 Task 执行过程中 动态创建或修改变量。适合基于运行时条件生成变量(如计算结果、处理后的数据)。
| 特性 | 说明 |
| 作用域 | 当前主机在 后续所有 Task 中有效(除非被覆盖) |
| 执行时机 | 在 Task 运行时动态计算 |
| 是否可动态计算 | 是(支持复杂逻辑、过滤器、其他变量引用) |
| 典型用途 | 动态生成配置、合并数据结构、条件化变量赋值 |
- name: Set dynamic factansible.builtin.set_fact:max_connections: "{{ ansible_memtotal_mb // 128 }}"- name: Merge dictionariesansible.builtin.set_fact:merged_config: "{{ default_config | combine(user_config) }}"3)register(任务结果捕获)
-
将 Task 的执行结果(包括输出、返回值等)保存到变量中。仅用于捕获模块(如 command、shell、uri)的执行结果。
| 特性 | 说明 |
| 作用域 | 当前主机在 后续 Task 中有效 |
| 执行时机 | 在 Task 执行完成后捕获结果 |
| 是否可动态计算 | 否(直接存储模块返回的原始数据) |
| 典型用途 | 捕获命令输出、API 响应、错误处理 |
- name: Check service statusansible.builtin.command: systemctl is-active nginxregister: nginx_statusignore_errors: true- name: Handle resultdebug:msg: "Nginx is {{ 'running' if nginx_status.rc == 0 else 'stopped' }}"
4)核心区别对比
| 维度 | vars | set_fact | register |
| 定义时机 | Play/Task 开始前 | Task 执行过程中 | Task 执行完成后 |
| 数据来源 | 静态定义 | 动态计算 | 模块执行结果 |
| 作用域 | 取决于定义位置 | 当前主机后续所有 Task | 当前主机后续 Task |
| 是否可缓存 | 否 | 是(cacheable: true) | 否 |
| 典型场景 | 配置常量 | 动态生成变量 | 捕获命令/API 响应 |
5)如何选择?
用 vars 当:
需要定义静态配置(如端口号、文件路径)。
变量值在 Playbook 运行前即可确定。
用 set_fact 当:
需要基于其他变量或条件动态计算值。
需要合并、转换数据结构(如字典合并)。
用 register 当:
需要捕获模块的执行结果(如命令输出、HTTP 响应)。
需要根据前一个 Task 的结果决定后续操作。
使用示例:
- hosts: allvars:base_dir: "/opt/app" # 静态变量tasks:- name: Get free memorycommand: free -mregister: mem_result # 捕获命令输出- name: Set dynamic configansible.builtin.set_fact:mem_limit: "{{ mem_result.stdout_lines[1].split()[3] | int }}" # 动态计算- name: Deploy configtemplate:src: config.j2dest: "{{ base_dir }}/config.ini"when: mem_limit > 512 # 条件判断
通过理解这三者的区别,可以更精准地控制 Ansible Playbook 的变量管理逻辑。
6. 课堂练习:管理清单变量
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start inventory-variables步骤说明:
1)熟悉当前的Ansible项目
进入/home/student/inventory-variables/目录:
[student@workstation ~]$ cd ~/inventory-variables/查看lab命令准备的文件:
[student@workstation inventory-variables]$ tree -L 1 -F
.
├── ansible.cfg
├── ansible-navigator.yml
├── deploy_apache.yml
├── deploy_haproxy.yml
├── deploy_webapp.yml
├── inventory.yml
├── roles/
└── site.yml
1 directory, 7 files-
deploy_apache.yml剧本:为 web_servers 组中的主机安装Apache HTTP服务器,并配置防火墙
-
deploy_haproxy.yml剧本:为 lb_servers 组的主机(只包括servera)安装HAProxy,还配置了防火墙,并指定serverb和serverc主机作为HAProxy的后端
-
deploy_webapp.yml剧本:为 web_servers 组的主机部署初始web内容
-
inventory.yml文件:将 serverb 和 serverc 主机声明为相应主机组的成员
-
site.yml剧本:调用了前面的三个剧本
观察 inventory.yml 清单文件内容:
[student@workstation inventory-variables]$ cat inventory.yml
lb_servers:hosts:servera.lab.example.com:web_servers:hosts:server[b:c].lab.example.com:2)剧本deploy_haproxy.yml中定义了两个变量,可以将这两个变量转移到清单变量文件中
-
变量1:haproxy_appservers,用来指定haproxy代理配置(指向哪些后端应用)
-
变量2:定义防火墙配置的firewall_rules
检查 deploy_haproxy.yml 剧本:
[student@workstation inventory-variables]$ cat deploy_haproxy.yml
---
- name: Ensuring HAProxy is deployedhosts: lb_serversbecome: truegather_facts: falsetasks:- name: Ensure HAProxy is installed and configuredansible.builtin.include_role:name: haproxyvars: # 指定haproxy代理配置haproxy_appservers:- name: serverb.lab.example.comip: 172.25.250.11port: 80- name: serverc.lab.example.comip: 172.25.250.12port: 80- name: Ensure the firewall ports are openedansible.builtin.include_role:name: firewallvars: # 指定防火墙配置firewall_rules:- port: 80/tcp新建 group_vars/lb_servers/ 目录来存放lb_servers主机组的变量文件:
[student@workstation inventory-variables]$ mkdir -p group_vars/lb_servers创建 group_vars/lb_servers/haproxy.yml 变量文件,用来保存HAProxy配置,从剧本deploy_haproxy.yml 中将 haproxy_appservers变量的定义复制过来:
[student@workstation inventory-variables]$ vim group_vars/lb_servers/haproxy.yml
---
haproxy_appservers:
- name: serverb.lab.example.comip: 172.25.250.11port: 80
- name: serverc.lab.example.comip: 172.25.250.12port: 80创建 group_vars/lb_servers/firewall.yml 变量文件,用来保存防火墙配置,从剧本deploy_haproxy.yml 中将 firewall_rules 变量的定义复制过来:
[student@workstation inventory-variables]$ vim group_vars/lb_servers/firewall.yml
---
firewall_rules:- port: 80/tcp修改 deploy_haproxy.yml 剧本文件,删除已经移出的变量定义,结果像这样:
[student@workstation inventory-variables]$ vim deploy_haproxy.yml
---
- name: Ensuring HAProxy is deployedhosts: lb_serversbecome: truegather_facts: falsetasks:- name: Ensure HAProxy is installed and configuredansible.builtin.include_role:name: haproxy- name: Ensure the firewall ports are openedansible.builtin.include_role:name: firewall3)deploy_apache.yml剧本定义了firewall_rules变量,用来配置web服务器的防火墙。将这两个变量转移到清单变量文件中
检查deploy_apache.yml剧本:
[student@workstation inventory-variables]$ cat deploy_apache.yml
---
- name: Ensuring Apache HTTP Server is deployedhosts: web_serversbecome: truegather_facts: falsetasks:- name: Ensure Apache HTTP Server is installed and startedansible.builtin.include_role:name: apache- name: Ensure the firewall ports are openedansible.builtin.include_role:name: firewallvars: # 指定防火墙配置firewall_rules:# Allow HTTP requests from the load_balancer- zone: internalservice: http- zone: internalsource: "172.25.250.10"新建 group_vars/web_servers/ 目录来存放web_servers主机组的变量文件:
[student@workstation inventory-variables]$ mkdir -p group_vars/web_servers创建 group_vars/web_servers/firewall.yml 变量文件,用来保存防火墙配置,从剧本deploy_apache.yml中将firewall_rules变量的定义复制过来:
[student@workstation inventory-variables]$ vim group_vars/web_servers/firewall.yml
---
firewall_rules:# Allow HTTP requests from the load_balancer- zone: internalservice: http- zone: internalsource: "172.25.250.10"修改剧本文件 deploy_apache.yml,删除firewall_rules变量定义,结果像这样:
[student@workstation inventory-variables]$ vim deploy_apache.yml
---
- name: Ensuring Apache HTTP Server is deployedhosts: web_serversbecome: truegather_facts: falsetasks:- name: Ensure Apache HTTP Server is installed and startedansible.builtin.include_role:name: apache- name: Ensure the firewall ports are openedansible.builtin.include_role:name: firewall4)修改静态清单文件inventory.yml以使Ansible将主机servera.lab.example.com 显示为load_balancer,结果像这样
[student@workstation inventory-variables]$ vim inventory.yml
lb_servers:hosts:load_balancer: # 添加可识别的短主机名称ansible_host: servera.lab.example.comweb_servers:hosts:server[b:c].lab.example.com:5)运行site.yml剧本,确认网页内容能部署成功
使用ansible-navigator run命令来运行site.yml剧本:
[student@workstation inventory-variables]$ ansible-navigator run site.yml --mode stdoutPLAY [Ensuring HAProxy is deployed] ********************************************
TASK [Ensure HAProxy is installed and configured] ******************************
TASK [haproxy : Ensure the HAProxy packages are installed] *********************
changed: [load_balancer]TASK [haproxy : Ensure HAProxy is started and enabled] *************************
changed: [load_balancer]TASK [haproxy : Ensure HAProxy configuration is set] ***************************
changed: [load_balancer]
...output omitted...使用curl命令访问HAProxy,确认能成功将Web请求提交到2个Apache HTTP Servers:
[student@workstation inventory-variables]$ curl http://servera.lab.example.com
This is serverb.lab.example.com. (version v1.0)[student@workstation inventory-variables]$ curl http://servera.lab.example.com
This is serverc.lab.example.com. (version v1.0)结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish inventory-variables四、 综合实验:管理主机清单
开始实验(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start inventory-review解决方案:
1. 克隆Git项目
从https://git.lab.example.com/student/inventory-review.git克隆Git项目到/home/student/git-repos目录下,然后创建exercise分支
在~/git-repos/inventory-review/目录中,查看inventory文件,然后使用导航器运行site.yml剧本。
可以使用curl命令向servera发出至少两个web请求来验证是否将相同版本的web应用程序部署到两个后端web服务器。
1)创建/home/student/git-repos/目录,并进入此目录
[student@workstation ~]$ mkdir -p ~/git-repos/
[student@workstation ~]$ cd ~/git-repos/2)从https://git.lab.example.com/student/inventory-review.git克隆项目,进入此项目目录
[student@workstation git-repos]$ git clone https://git.lab.example.com/student/inventory-review.git
Cloning into 'inventory-review'...
...output omitted...
[student@workstation git-repos]$ cd inventory-review3)检出exercise分支
[student@workstation inventory-review]$ git checkout -b exercise
Switched to a new branch 'exercise'4)检查inventory清单文件
[student@workstation inventory-review]$ cat inventory
[lb_servers]
servera.lab.example.com
[web_servers]
[web_servers:children]
a_web_servers
b_web_serversGroup "A" of Web Servers
[a_web_servers]
serverb.lab.example.comGroup "B" of Web Servers
[b_web_servers]
serverc.lab.example.com这个项目中,主机组web_servers由另外两个组(a_web_servers 和b_web_servers)组成。
5)使用 ee-supported-rhel8 执行环境运行 site.yml剧本(如图-2所示)
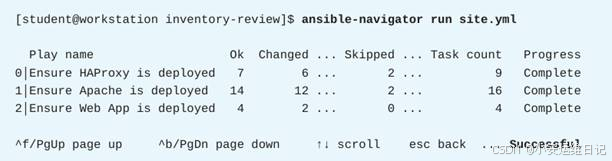
按Esc键退出ansible-navigator命令。
6)确认已经为2个后端的Web服务器部署了相同版本的Web应用
[student@workstation inventory-review]$ for x in 1 2; do curl servera; done
Hello from serverb.lab.example.com. (version v1.1)
Hello from serverc.lab.example.com. (version v1.1)2. 配置每个主机组中的web服务器,以报告web应用程序的不同版本号
-
为 a_web_servers 主机组创建一个目录,并在这个目录下创建一个名为webapp.yml的变量文件,将webapp_version变量的值设置为v1.1a。
-
为 b_web_servers 主机组创建另一个目录,并在这个目录下创建一个名为webapp.yml的变量文件,将webapp_version变量的值设置为v1.1b。
1)为两个组a_web_servers 、b_web_servers新建组变量文件目录
[student@workstation inventory-review]$ mkdir -pv group_vars/{a,b}_web_servers
mkdir: created directory 'group_vars/a_web_servers'
mkdir: created directory 'group_vars/b_web_servers'2)为a_web_servers 组新建webapp.yml文件,设置变量webapp_version 的值为v1.1a
[student@workstation inventory-review]$ echo "webapp_version: v1.1a" > group_vars/a_web_servers/webapp.yml3)为b_web_servers 组新建webapp.yml文件,设置变量webapp_version 的值为v1.1b
[student@workstation inventory-review]$ echo "webapp_version: v1.1b" > group_vars/b_web_servers/webapp.yml3. 使用导航器运行剧本,来更新web应用程序显示的版本信息
使用 curl命令 确认发送到servera的网页请求是否会生成两个不同版本的web应用程序。将你创建的文件提交到本地Git存储库。
1)运行deploy_webapp.yml剧本
[student@workstation inventory-review]$ ansible-navigator run deploy_webapp.yml
Play name Ok Changed ... Failed ... Task count Progress
0|Ensure Web App is deployed 4 2 ... 0 ... 4 Complete运行成功后按Esc键退出ansible-navigator命令。
2)确认访问servera时能获得两个不同版本的后端应用
[student@workstation inventory-review]$ for x in 1 2; do curl servera; done
Hello from serverb.lab.example.com. (version v1.1a)
Hello from serverc.lab.example.com. (version v1.1b)3)确认本地Git库的变化,提交、推送Git更改
Git密码为Student@123
[student@workstation inventory-review]$ git status
On branch exercise Untracked files:
(use "git add <file>..." to include in what will be committed)group_vars/a_web_servers/
group_vars/b_web_servers/nothing added to commit but untracked files present (use "git add" to track)[student@workstation inventory-review]$ git add group_vars/{a,b}_web_servers
[student@workstation inventory-review]$ git status
On branch exercise Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: group_vars/a_web_servers/webapp.yml
new file: group_vars/b_web_servers/webapp.yml[student@workstation inventory-review]$ git commit -m "Created variable files for the A and B groups."
...output omitted...4. 使用INI格式清单文件中的数据创建一个名为inventory.yml的YAML格式清单文件,保留原始清单文件不要删除;使用新的inventory.yml文件运行site.yml剧本
1)利用INI格式的inventory清单文件,转换出YAML格式的inventory.yml清单文件
[student@workstation inventory-review]$ ansible-navigator inventory -i inventory --list --yaml -m stdout > inventory.yml2)确保 inventory.yml 清单文件中没有包含任何主机变量(删除多余的变量定义)
lb_servers:hosts:servera.lab.example.com:
web_servers:children:a_web_servers:hosts:serverb.lab.example.com:b_web_servers:hosts:serverc.lab.example.com:3)测试新的inventory.yml清单文件(如图-3所示)
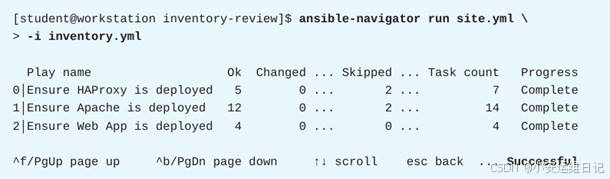
5. 修改你的YAML清单,以便使用更合理的清单主机名,而不是实际主机名
按以下方式修改inventory.yml文件:
-
在lb_servers主机组中,将servera.lab.example.com更改为loadbalancer_1。
-
为loadbalancer_1分配一个ansible_host变量,该变量将其实际主机名配置为servera.lab.example.com。
-
在a_web_servers主机组中,将serverb.lab.example.com更改为backend_a1。
-
为backend_a1分配一个ansible_host变量,该变量将其实际主机名配置为serverb.lab.example.com。
-
在b_web_servers主机组中,将serverc.lab.example.com更改为backend_b1。
-
为backend_b1分配一个ansible_host变量,该变量将其实际主机名配置为serverc.lab.example.com。
1)修改inventory.yml文件,使每个服务器都遵守上面的命名约定
lb_servers:hosts:loadbalancer_1:ansible_host: servera.lab.example.comweb_servers:children:a_web_servers:hosts:backend_a1:ansible_host: serverb.lab.example.comb_web_servers:hosts:backend_b1:ansible_host: serverc.lab.example.com6. 验证在使用新的inventory.yml清单文件时,site.yml剧本仍然能够成功运行,可以使用curl命令再次测试负载均衡器
在剧本运行无错误后,将新的inventory.yml文件提交到本地Git存储库。如果出现提示,则使用Student@123作为Git密码。提交所有项目更改后,将本地提交推送到远程存储库。
1)确认剧本site.yml能够成功运行,输出结果中显示的主机名称符合前述约定
注意添加 -i inventory.yml 指定使用新的清单文件(如图-4所示)。
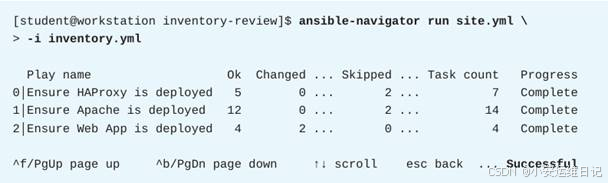
按Esc键退出ansible-navigator命令。
2)确认访问servera时能获得两个不同版本(分别对应backend_a1、backend_a2)的后端应用
[student@workstation inventory-review]$ for x in 1 2; do curl servera; done
Hello from backend_a1. (version v1.1a)
Hello from backend_b1. (version v1.1b)3)提交新的Git更改
[student@workstation inventory-review]$ git add inventory.yml
[student@workstation inventory-review]$ git commit -m "Added YAML inventory"
...output omitted...4)推送Git项目更改(密码为Student@123)
[student@workstation inventory-review]$ git status
On branch exercise
Your branch is ahead of 'origin/exercise' by 2 commits.(use "git push" to publish your local commits)nothing to commit, working tree clean[student@workstation inventory-review]$ git push -u origin exercise
Password for 'https://student@git.lab.example.com': Student@123
...output omitted...结束实验(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
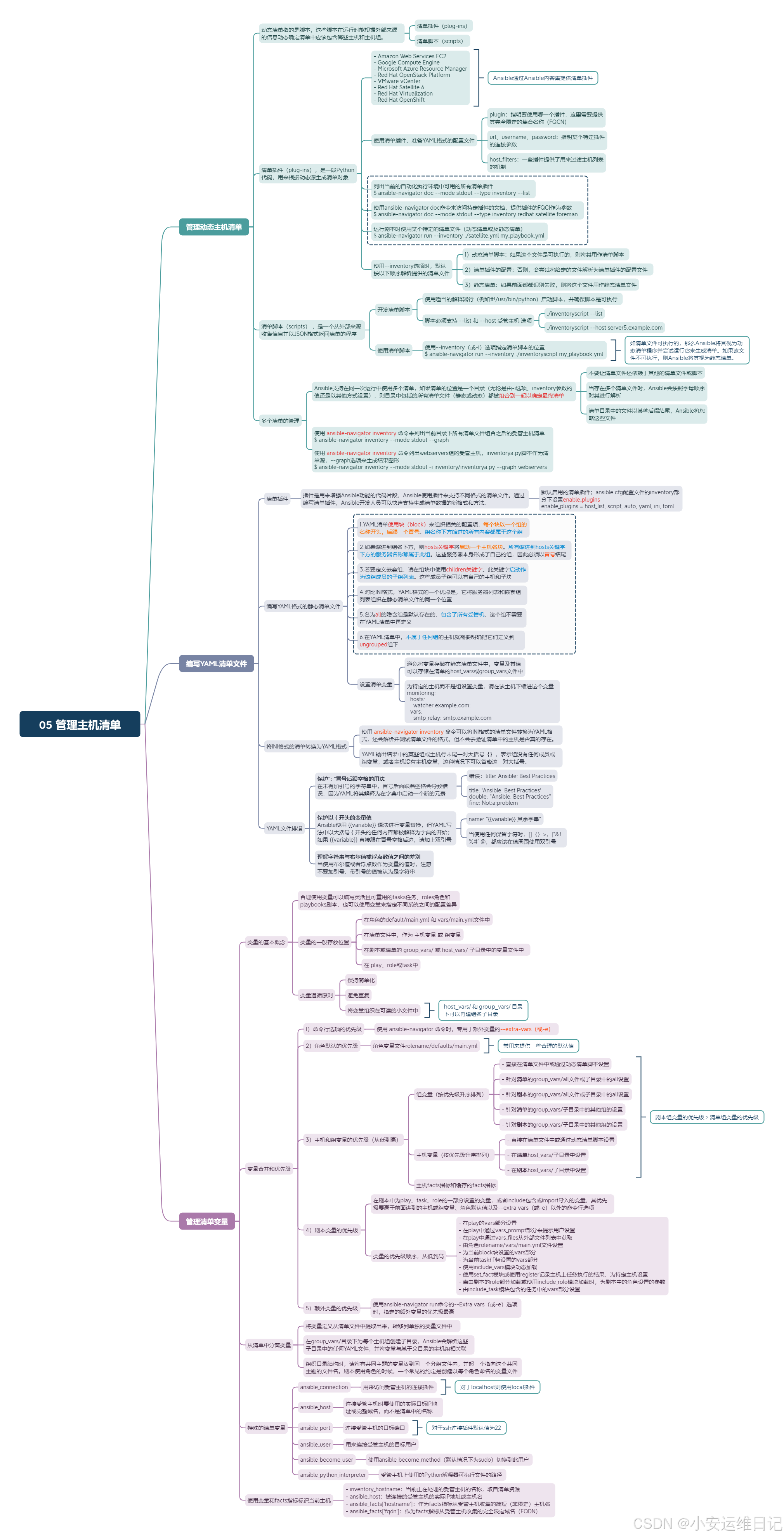
[student@workstation ~]$ lab finish inventory-review思维导图:
 小结:
小结:
本篇为 【RHCA认证 - DO374 | Day05:管理主机清单】的学习笔记,希望这篇笔记可以让您初步了解管理动态主机清单、如何编写YAML清单文件、管理清单变量、综合实验:管理主机清单等,不妨跟着我的笔记步伐亲自实践一下吧
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关环境、视频,可评论666并私信小安,请放下你的羞涩,花点时间直到你真正的理解。