改进 shell 搜索
大家好!我是大聪明-PLUS!
想想我每天在 Unix 终端上工作和执行 Shell 命令的时间,真是令人毛骨悚然。不知何故,每个人 Shell 的熟练程度差异很大。我认识一些人,他们甚至比我强。同时,我曾经遇到过一位付费专业人士,他不知道只需按向上箭头键就可以显示上一个命令。
我举这个例子并非巧合:我们通常在 Shell 中运行的命令都是重复的。我通常一个工作日会遇到 50 到 100 个不同的(即语法不相同的)Shell 命令。但在这些命令中,有一小部分(例如 cargo test)我每天都会用到数百次。
例如,我可以使用 fc 命令获取这些精确的统计数据,但在跨平台方面存在一些与日期格式相关的不便。为了快速分析 Shell 历史记录,我尝试了以下 Python 代码的各种变体:
from datetime import datetime
days = {}
for l in open(".zsh_history"):if len(l.split(":")) < 3: continue_, t, cmd = [x.strip() for x in l.split(":", 2)]d = datetime.fromtimestamp(int(t)).strftime("%Y-%m-%d")cmd = cmd.split(";")[1]cmds = days[d] = days.get(d, set())cmds.add(cmd)
print(len(days["2025-03-19"]))由于许多命令行工具的选项难以记住,因此有一个技巧不仅可以节省大量时间,还可以降低出错的可能性。学习搜索 Shell 历史记录,以便快速准确地检查上次使用命令时的语句。在这篇文章中,我将向您展示如何轻松掌握这项技能。
在 shell 历史记录中搜索
在相对较大的 Unix shell 中,例如 Bash,用户长期以来一直能够通过按下Ctrl-r 并输入感兴趣的子字符串来查看他们的 shell 历史记录。如果我按顺序执行命令 cat /etc/motd,然后 cat /etc/rc.conf,然后, Ctrl-r 然后“cat”,我找到的第一个匹配项将是cat /etc/rc.conf。然后,如果我再次按下 Ctrl-r,循环将倒回到下一个最接近的匹配项,即 cat /etc/motd 。我很少使用这个功能,因为搜索子字符串匹配是一种太粗糙的方法。例如,我可能知道我需要命令 cat,并且我也对工作表感兴趣motd,但我不记得要在哪个目录中查找。在这种情况下,搜索子字符串匹配对我没有帮助。相反,我会不断地在我的 shell 历史文件中搜索某些内容,为此我使用 grep (使用通配符)。
自从我学会了如何Ctrl-r 与 fzf 组合后,一切都改变了。这立即带来了两个重要的变化。首先,不再需要精确匹配,我只需输入[ ] 即可找到“c mo”匹配项 。其次,如果有多个匹配选项,它们现在会一次性全部输出。我输入并收到了几个 cat 命令,我可以从中选择最佳的选项(顺便说一句,这可能不是最新的)。cat /etc/motd“cat”
我认为很难夸大这个功能的强大。很少有比按下ctrl-R,然后按 Enter 键更强大的功能“l1”了——你只需在命令行中写入一个包含 100 个字符的序列,它就会启动一个复杂的调试工具,其中许多环境变量都已正确设置。该命令的输出会立即显示/tmp/l1 在我的终端中。
有了 Ctrl-r fzf,我的 Shell 效率瞬间提升了一倍。有趣的是,长期效果更加显著:我对使用 Shell 命令更加热情,因为 fzf 极大地解放了我的思维。例如,由于现在更容易回忆起以前用过的命令,我不再设置全局环境变量——尽管忘记它们曾经非常痛苦。事实上,如果有人的 Shell 出现问题,我建议他们做的第一件事就是检查他们设置了哪些全局环境变量。
Ctrl-r 现在我为每个命令分别设置环境变量,因为使用fzf很容易“记住”它们。
多年来,我一直更喜欢使用 zsh shell。后来,我从 zsh 切换到 fish,在新 shell 中做的第一件事就是配置 Ctrl-r fzf。之后,当我切换回 zsh 并从头开始重建配置时,我再次先设置了 Ctrl-r 和 fzf。
我喜欢 fish 的开箱即用方式,但出于两个原因我不得不放弃它。首先,它与 POSIX shell 的差异显然没有任何好处,但在使用它时,我不得不在脑子里拨动开关来编写“正常”的脚本。其次,fish 中的一些默认设置(例如路径修正)最终变成了全局和永久的。我曾劝说人们尝试 fish,但他们每个人(真的)都开始犯和我一样不安全的错误。所以我不再向任何人推荐它了,甚至一度怀疑自己为什么还在用它。这就是生活。
简而言之,如果您至少从这篇文章中了解到Ctrl-r fzf 在使用 Unix 时显著提高了生产力,那么我写这篇文章是有原因的。
当然,没有完美的工具。几个月前,我偶然发现了 skim,一个类似 fzf 的工具,我认为它的开箱即用性比 fzf 更好一些。它们之间的区别很小,而且都能避免犯严重的错误。我还发现 skim 的模式搜索功能能更频繁、更快地找到我需要的命令。我也喜欢 skim 的用户界面,而且我认为 skim 在任何系统上都更容易安装。skim 的优势并不明显,但足以让我转而使用它。
如何让它变得更好
发现 Skim 之后,我深受启发,决定探索这个领域——或许这里有一些工具可以让我更高效地工作。很快,我就发现了 Atuin,它拥有更复杂的 Shell 历史记录机制。它的介绍视频展示了一个比我想象中更友好的用户界面。
然而,我很快意识到 Atuin 并不适合我,或者至少它很难用。最近,我经常通过 ssh 连接到各种服务器:随着时间的推移,我精简了配置中所有不必要的细节,并将其精简为一个 .zshrc 文件。使用 scp 传输到新机器很容易,这自然会立即加快我的工作速度。Atuin(顺便说一句,我并不是在批评它,因为它是一个更强大的工具)的安装和配置更困难。我也不确定 Atuin 能否在处理“模糊”信息方面胜过它。我必须承认, Atuin 的安装脚本之长让我立刻感到惊讶 。Atuin 目前还缺少用于连接到 OpenBSD 端口(即相应的“软件包”)的端口。最后一点不是 Atuin 的错,而且它当然也没什么区别。后来我为 Skim 编写了自己的 OpenBSD 端口。但当我需要快速尝试一个新程序时,它就成了一个明显的障碍。Atuin 的网络功能也让我毛骨悚然,不过俗话说,人各有志……
我仍然认为一些读者可能想仔细研究一下这个工具,也许会发现它很有用。
然而,在观看了 Atuin 的视频演示后,我立即意识到如果我的模糊匹配引擎能够告诉我更多有关它所匹配的命令的信息,那将是多么棒。
特别是,fzf 和 skim 默认都会在我要搜索的命令前显示一个毫无意义的整数。这总是让我有点不安,但我一直没时间弄清楚这个数字是什么意思。例如,当我使用 zsh + fzf + Ctrl-r 时,我看到的是:
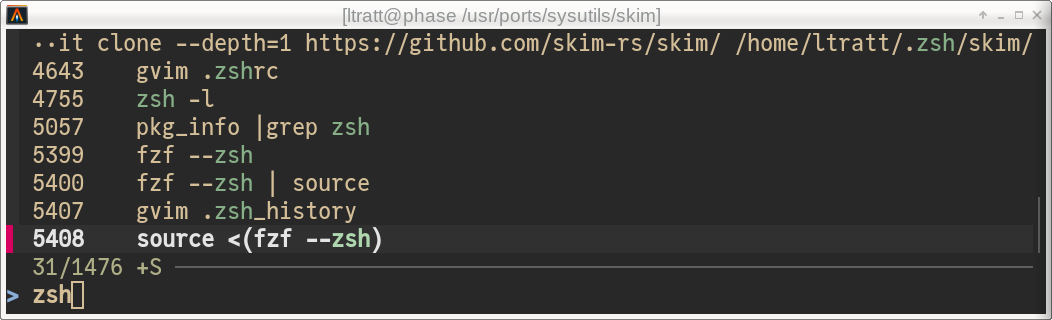
这里的 5408 是什么意思?为什么它会占用宝贵的屏幕空间?Skim 尝试更加谨慎:它会显示 5408 today'21:26,但这会占用更多的屏幕空间!
zsh 和 fzf/skim 的适配
幸运的是,改进 Ctrl-r 功能和 fzf/skim 用户界面其实很容易。与其浪费精力在一个(对我来说)毫无意义的数字上,不如直接使用下面的代码(其中 [ 11d ] 表示“回溯 11 天”等等):
我将向您展示我如何为此调整 zsh 和 skim。我相信其他 shell 也可以用同样的方式进行调整,而无需进行太多修改(要将此配置适配到 fzf,通常只需将命令替换 sk 为 即可fzf)。
我第一次需要这个是为了 在 执行命令 时~/.zshrc录制 zsh。我在目录中添加了以下代码:
setopt EXTENDED_HISTORY
setopt inc_append_history_time这 EXTENDED_HISTORY 会强制记录 .zsh_history 命令的执行时间(以 Unix 纪元以来的秒数为单位),以及执行 inc_append_history_time耗时(如果附加了 )。这些选项的优点在于,它们自然允许传输“以传统方式格式化”的历史文件:任何非扩展的历史命令都会接受当前日期,因此所有内容都 .zsh_history 将以相同的格式写入。
然后我需要弄清楚 zsh 如何检索这些历史记录,并在我按下 时显示它 Ctrl-r。fzf 和 skim 在这里使用的代码几乎相同:我将以 skim 为例,展示它如何组织 zsh功能键绑定。本质上,这两个工具都定义了一个函数history-widget,然后为其分配一个组合键 Ctrl-r:
history-widget() { ... }
zle -N history-widget
bindkey '^R' history-widget您可以通过指定自己的版本来覆盖 fzf 和 skim 提供的版本。为此,请将上述代码放在目录中~/.zshrc 导入常用热键组合之后。
让我们看看 skim 中的情况 history-widget:
skim-history-widget() {local selected numsetopt localoptions noglobsubst noposixbuiltins pipefail no_aliases 2> /dev/nulllocal awk_filter='{ cmd=$0; sub(/^\s*[0-9]+\**\s+/, "", cmd); if (!seen[cmd]++) print $0 }' # отфильтровываем дублиlocal n=2 fc_opts=''if [[ -o extended_history ]]; thenlocal today=$(date +%Y-%m-%d)awk_filter='{if ($2 == "'$today'") sub($2 " ", "today'\''")else sub($3, "")line=$0; $1=""; $2=""; $3=""if (!seen[$0]++) print line}'fc_opts='-i'n=3fiselected=( $(fc -rl $fc_opts 1 | awk "$awk_filter" |SKIM_DEFAULT_OPTIONS="--height ${SKIM_TMUX_HEIGHT:-40%} $SKIM_DEFAULT_OPTIONS -n$n..,.. --bind=ctrl-r:toggle-sort $SKIM_CTRL_R_OPTS --query=${(qqq)LBUFFER} --no-multi" $(__skimcmd)) )...我要注意的第一件事是 – 感谢 EXTENDED_HISTORY – 在这里描述的上下文中,测试-o extended_history 总是计算为 true,因此 if 语句的主体总是被执行。
现在让我们进一步:使用这个, fc -rli 1 我们将强制 zsh 以比直接通过以下方式更易于理解的形式输出 shell 历史记录 .zsh_history:
$ fc -rli 14 2025-02-07 15:05 pizauth status3 2025-02-07 15:03 cargo run --release server2 2025-02-07 15:03 email quick1 2025-02-07 14:59 rsync_cmd bencher16 ./build.sh cargo test nested_tracing现在,前面提到的那些神秘数字的含义也清晰了:它们是来自 的行号fc,其中 1 是我在 中最旧的命令 ~/.zsh_history!有时它们被用作标识符,因为你可以告诉 zsh“将命令 5408 返回给我”。
awk 代码将此输出流化,用字符串文字替换今天的日期today。它删除了前几天的小时和分钟信息,并消除了重复项。
虽然很容易忽略,但我还是想指出最后一行代码:-n$n..,..。这告诉 skim 哪些空格分隔的列需要进行模糊匹配,然后输出。
此时,我们需要决定如何调整系统以满足我们的需求。首先,我们需要解析输出fc并将时间转换为自 Unix 纪元以来经过的秒数。我们可以通过设置 来强制 fc 执行此操作 。现在,我们得到的不是 2025-03-21 22:10,而是 1742595052。注意,现在只剩下一个字段来代替之前的两个字段!fc 命令会在行号前添加一个空格,我们将通过管道 -t '%s'将输出传递到 来删除它。fcsed -E "s/^ *//"
接下来,我需要弄清楚如何表达“这条命令执行了多久”这个概念。通过反复试验,我发现, hour:minute 对于过去 20 小时内执行的命令,指定绝对时间效果很好,而 对于一天或多天前执行的命令,则以1d, 2d (以此类推)表示。为什么是 20 小时?因为如果我早上 8:00 开始工作,按下 Ctrl-r,看到 8:01 AM 的记录,我甚至没有意识到它是昨天 8:01 AM 执行的。这仍然比今天 8:01 AM 早了大约 60 秒。通过选择 20 小时的间隔,我们解决了这个问题:那么在早上 8:00,昨天下午执行的命令将显示为 4:33 PM,而昨天早上执行的命令将显示为 1 天。
现在我们需要切换到 awk。我承认,一开始我很犹豫,因为我以前从未使用过它。我快速浏览了其他选择,然后意识到为什么代码中使用 awk:每台 Unix 机器上都安装了 awk。对于那些不熟悉 awk 的人,让我解释一下:我们正在编写的程序逐行遍历输入,将行从一个空格拆分到另一个空格,并将结果字段放入变量 $1( $2 ,等等)。我们将保留之前 awk 代码中的重复检测函数,但几乎其他所有部分都会更改。
在 bawk 中,我们首先需要将特定命令的 Unix 纪元时间(字段/变量类型$2)转换为整数,并计算该命令执行的时间(秒数)。此操作使用以下命令完成systime(返回相对于 Unix 纪元的当前时间):
ts = int($2)
delta = systime() - ts接下来,您可以将增量秒数除以 86,400(24 小时 60 分 60 秒 = 86,400 秒)转换为天数。接下来是一个简单的 if/else 语句,用于整齐地格式化所有内容。请记住:
1. 20h == 72,000 秒
2. awk 中的字符串连接和整数到字符串的转换是隐式完成的
转换过程如下:
delta_days = int(delta / 86400)
if (delta_days < 1 && delta < 72000) { $2=strftime("%H:%M", ts) }
else if (delta_days == 0) { $2="1d" }
else { $2=delta_days "d" }当然,我可以尝试继续这种碎片化方案。比如,我可以把超过一周的团队标记为“ 1w”,等等;我还没时间这么做。
不过,这里有一个小问题:时钟不同步。这会导致某些命令看起来像是在未来执行的。我还没有在实践中遇到过这种情况,但在处理计算机及其时钟时,我曾多次遇到麻烦。所以我会避免这种不可避免的情况,因此,我使用了前缀+ :
delta_days = int(delta / 86400)
if (delta < 0) { $2="+" (-delta_days) "d" }
else ...请注意,我必须 (-delta_days) 在其周围加上括号,因为如果不这样做(出于我懒得去研究的原因),awk 就不会按照我想要的方式连接整数。
由于我们比以前少了一个字段,我们可以稍微简化一下输出:
line=$0; $1=""; $2=""
if (!seen[$0]++) print lineawk 代码已经准备好了。接下来,我们需要稍微调整一下带有selected=..."" 的行,-n$n..,.. 改为 " --with-nth $n.." 。这会告诉 fzf 和 skim 不要在输出中显示行号,并且在执行模糊匹配时也不要考虑此信息。
总而言之,更新后的片段history-widget 将如下所示:
local n=1 fc_opts=''if [[ -o extended_history ]]; thenawk_filter='
{ts = int($2)delta = systime() - tsdelta_days = int(delta / 86400)if (delta < 0) { $2="+" (-delta_days) "d" }else if (delta_days < 1 && delta < 72000) { $2=strftime("%H:%M", ts) }else if (delta_days == 0) { $2="1d" }else { $2=delta_days "d" }line=$0; $1=""; $2=""if (!seen[$0]++) print line
}'fc_opts='-i'n=2fiselected=( $(fc -rl $fc_opts -t '%s' 1 | sed -E "s/^ *//" | awk "$awk_filter" |SKIM_DEFAULT_OPTIONS="--height ${SKIM_TMUX_HEIGHT:-40%} $SKIM_DEFAULT_OPTIONS --with-nth $n.. --bind=ctrl-r:toggle-sort $SKIM_CTRL_R_OPTS --query=${(qqq)LBUFFER} --no-multi" $(__skimcmd)) )这些简单的更改足以让我在单击Ctrl-r 并开始输入时立即获得以下输出:
结果
我使用这个修改后的配置大约一个半月,发现效率大大提升。事实证明,一旦我了解了某个命令的使用时间,就能回忆起很多相关信息。例如,如果我看到一个标记为“ 1d”或“ 7d”的匹配项,就足以让我将其排除或跳过整个搜索。有时我对时间增量本身很感兴趣。如果我开始查找标记为“ 2d”的匹配项,那么 fzf 或 skim 当然只会考虑两天前的命令。
但或许本文还能给你带来更普遍的启示。如果你像我一样,一生中的大部分时间都在使用 Unix 命令行,那么你完全有可能重新发明了一些技术,而这些技术对于 20 世纪 70 年代使用 Shell 的用户来说,可能非常熟悉。但你不仅可以改进,而且难度也更低,你会发现自己的效率提高了多少!