在线量化工具总结与实战(mqbench) -- 学习记录
在线量化工具总结与实战(mqbench)
- 一、在线量化工具整体设计结构
-
- 1.1、量化流程回顾
- 1.2、基于pytorch的训练流程
- 1.3、基于pytorch的QAT流程
- 1.4、基于pytorch+mqbench的QAT流程
- 二、在线量化工具代码解读
-
-
- 2.1、基于mqbench的QAT流程--详细步骤
-
- 基于mqbench的QAT流程--详细步骤1
- 基于mqbench的QAT流程--详细步骤2
- 基于mqbench的QAT流程--详细步骤3
- 基于mqbench的QAT流程--详细步骤4
- 基于mqbench的QAT流程--详细步骤5
- 基于mqbench的QAT流程--详细步骤6
- 基于mqbench的QAT流程--详细步骤7
-
- 三、在线量化实战
-
- 3.1、Installation
- 3.2、代码与数据集
-
- torch
- trt
- 3.3、实战注意事项
一、在线量化工具整体设计结构
1.1、量化流程回顾
当我们开始要做一个QAT任务的时候,需要确定好以下事项
1.硬件的量化setting
2.硬件的量化拓扑特性:
3.做好BN模拟fuse;
4.做好节点的插入
5.做好伪量化节点的梯度反传
6.先做一个PTQ(min-max /mse),存下来量化参数给QAT
7.设置好QAT的超参数,开始训练
8.导出模型和相应的量化参数。
注意
上述步骤中,1.2.3.4.8与硬件推理引擎相关
6.7是通用的QAT训练技巧5:12345
步骤5,往往就是QAT量化的精度损失所在,也是算法的可以改进的地方
1.2、基于pytorch的训练流程

1.3、基于pytorch的QAT流程

微调的时候的 learning rate 可以比平时低一些
1.4、基于pytorch+mqbench的QAT流程
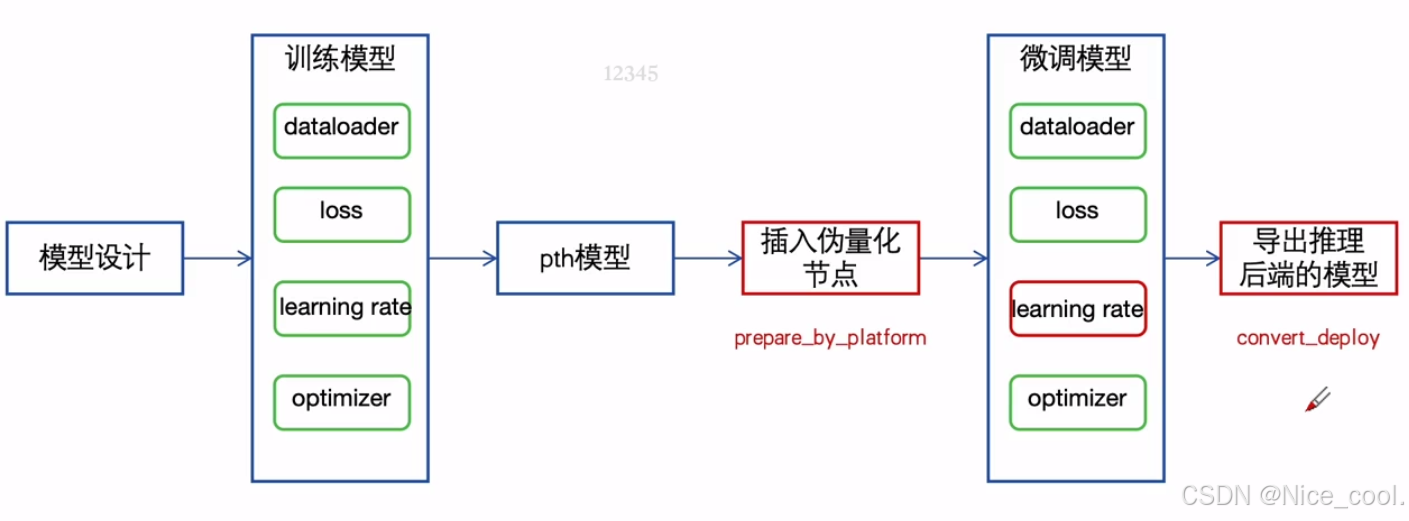
网址:https://github.com/modeltc/mqbench
使用 mqbench 可以自动插入节点和导出模型
mqbench提供了两个最顶层qat量化接口的入口:prepare_by_platform和convert_deploy
-
prepare_by_platform:用于插入伪量化节点
-
convert_deploy:用于转换成对应推理后端的模型
其余有关qat的接口,都是在这两个顶层函数中被调用
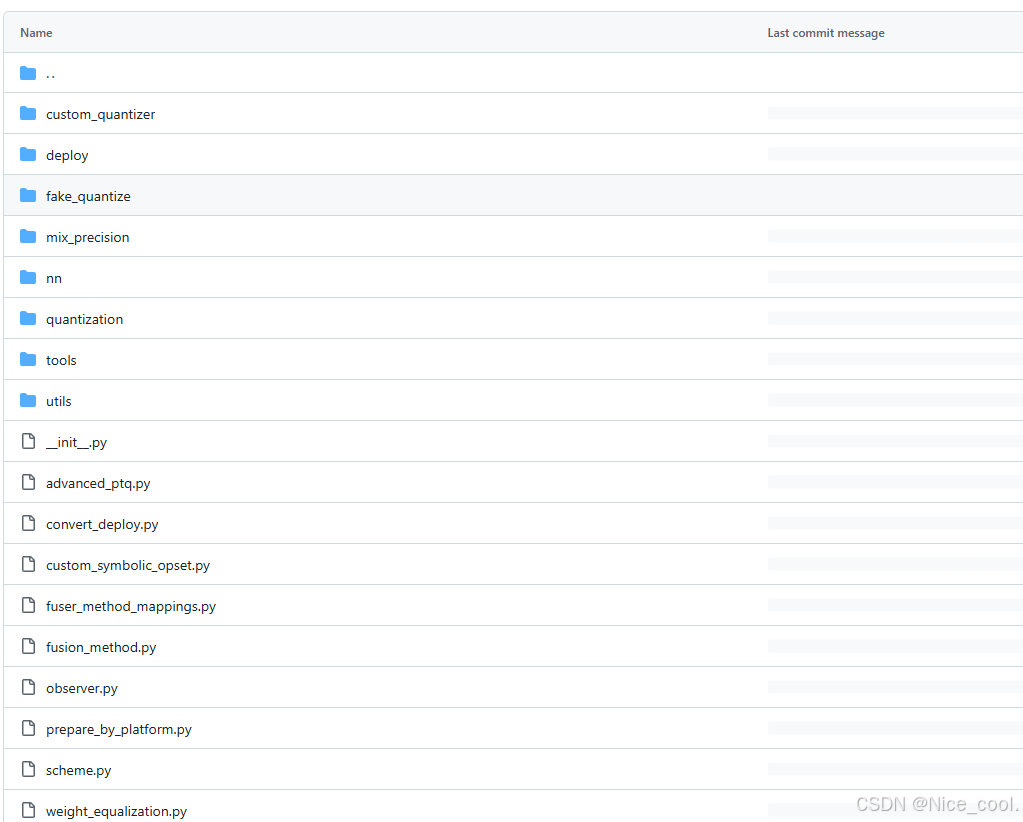
- scheme:定义量化setting
- observer:用统计的方式计算量化参数,即PTO,可作为QAT的初始化
- custom_quantizer:不同推理后端的插入量化节点的逻辑
- nn:定义一些fuse在一起的module.用于模拟BN Fuse
- fake_quantize:不同的梯度反传的量化算法
- deploy:用于删除量化节点,获取量化参数
- mqbench还提供了一些别的功能:高阶PTQ算法,替换sync bn,混合精度分析等
二、在线量化工具代码解读
2.1、基于mqbench的QAT流程–详细步骤
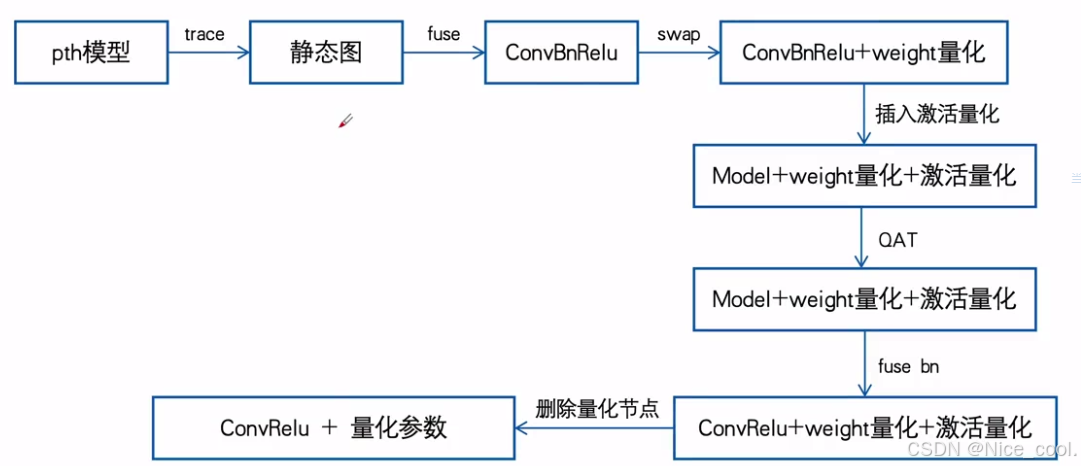
基于mqbench的QAT流程–详细步骤1
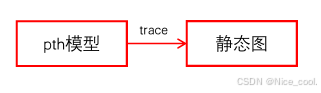
- 使用torch.fx工具,将动态图转换成静态图
- 动态图:纯代码形式的模型定义,方便快速用代码实现想要的功能
- 静态图:有着拓扑结构的有向图定义,可以从图上获取tensor的流向,以及节点与节点的拓扑关系
- pytorch属于动态图框架,tensorflow属于静态图框架
- 动态图转静态图的原因:
获取模型的拓扑结构,便于插入量化节点等操作 - fx的演示用例:L5/t01.py: L5/t02.py: L5/t03.py
- mgbench 代码:MBench/mgbench/prepare_by_platform.py: graph=
tracer.trace(model, concrete_args)
基于mqbench的QAT流程–详细步骤2
- 使用torch.quantization.quantize_fx._fuse_fx接口,找到可以fuse的module
- fuse之后,模型里面的conv-bn-relu三个分离的op,会变成如下一个module
- module来自于torch.nn.intrinsic.modules.fused.ConvBnReLU2d,本质其实一个nn.Sequential
基于mqbench的QAT流程–详细步骤3

- 使用torch.quantization.propagate_qconfig_和torch.quantization.swap_module,进行module的替换
- 将ConvBnRelu替换成带有weight伪量化节点的module,并且该module会进行BN的模拟fuse
- propagate_qconfig-:将量化的各种设置信息挂在module上
- swap_module:替换module
基于mqbench的QAT流程–详细步骤4

- 对模型对拓扑图进行操作,给激活插入伪量化节点
- torch.fx中的各种对graph的增删查改操作
- mgbench代码:MQBench/mgbench/custom_quantizer/model_quantizer.py:insert.fake_quantize_for_.act_quant
基于mqbench的QAT流程–详细步骤5

- 先用0bserver,以统计的方式计算量化参数,即PTQ,可作为QAT的初始化
- 再用Quantize,做伪量化节点的梯度反传
- 通过一个开关操作,进行PTQ和QAT模式的切换
基于mqbench的QAT流程–详细步骤6

- QAT训练结束,进入部署流程
- 步骤1:torch.nn.utils.fusion.fuse_conv_bn_eval,
torch.nn.utils.fusion.fuse_linear_bn_eval,将BN fuse掉 - 步骤2:转换onnx,此时量化节点还在模型上
基于mqbench的QAT流程–详细步骤7

- 步骤3.1:删除weight伪量化节点,将weight和weight量化参数融合在一起,得到新的weight
(走min-max) - 步骤3.2:删除激活伪量化节点,将激活量化参数提取出来,写入文件中
三、在线量化实战
基于mqbench,实现对 mobilenet-v2 网络的 QAT 和 TensorRT 部署的全流程演示
3.1、Installation
# 创建环境
conda create -n mqb python=3.8
# 切换/激活环境
conda activate mqb
git clone git@github.com:ModelTC/MQBench.git
cd MQBench
# 请根据自己的 cuda版本、python版本、服务器类型 前往https://download.pytorch.org/whl/torch/选择下载连接
# 注:torch安装不可直接使用 pip install torch==1.10.0
# 注:下面是推荐的下载与安装代码
wget https://download.pytorch.org/whl/cu113/torch-1.10.0%2Bcu113-cp38-cp38-linux_x86_64.whl#sha256=cccddc32b8941bd03ede29ff0a1cce2f2b51113a5ee23bb8b979316ac2114183
pip install torch-1.10.0+cu113-cp38-cp38-linux_x86_64.whl
pip install pandas==1.3.5
pip install scikit-learn==0.24.2
pip install numpy==1.19.0
pip install scipy==1.6.2
pip install -v -e .
附:https://download.pytorch.org/whl/torchvision/,供 pip install torchvision==0.11.1 造成程序运行不了的同学使用
3.2、代码与数据集
tiny-imagenet-200 数据集下载地址:http://cs231n.stanford.edu/tiny-imagenet-200.zip
torch
train_torch.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import time
import copy
from mbv2 import mobilenet_v2
from dataset import get_dataset
def train_model(
model, dataloaders, dataset_sizes, criterion, optimizer, scheduler, num_epochs=25
):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
since = time.time()
# liveloss = PlotLosses()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch + 1, num_epochs), flush=True)
print("-" * 10, flush=True)
# Each epoch has a training and validation phase
for phase in ["train", "val"]:
if phase == "train":
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
print(f"\n--- phase : {
phase} ---\n", flush=True)
for i, (inputs, labels) in enumerate(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == "train":
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if i % 10 == 0:
print(
"\rIteration: {}/{}, Loss: {}, LR: {} ".format(
i + 1, len(dataloaders[phase]), loss.item() * inputs.size(0),
optimizer.param_groups[0]['lr']
), flush=True
)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
if phase == "train":
avg_loss = epoch_loss
t_acc = epoch_acc
else:
val_loss = epoch_loss
val_acc = epoch_acc
if phase == "val" and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print("Train Loss: {:.4f} Acc: {:.4f}".format(avg_loss, t_acc), flush=True)
print("Val Loss: {:.4f} Acc: {:.4f}".format(val_loss, val_acc), flush=True)
print("Best Val Accuracy: {}".format(best_acc), flush=True)
print()
time_elapsed = time.time() - since
print(
"Training complete in {:.0f}m {:.0f}s".format(
time_elapsed // 60, time_elapsed % 60
), flush=True
)
print("Best val Acc: {:4f}".format(best_acc), flush=True)
# load best model weights
model.load_state_dict(best_model_wts)
return model
model = mobilenet_v2(num_classes=200)
weight_imagenet = torch.load("mobilenet_v2-b0353104.pth")
weight_imagenet.pop("classifier.1.weight")
weight_imagenet.pop("classifier.1.bias")
model.load_state_dict(weight_imagenet, strict=False)
model.train()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# Multi GPU
model = torch.nn.DataParallel(model, device_ids=[0, 1])
# Loss Function
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
train_dataset, val_dataset, _ = get_dataset()
train_loaders = torch.utils.data.DataLoader(
train_dataset, batch_size=256, shuffle=True, num_workers=8
)
val_loaders = torch.utils.data.DataLoader(
val_dataset, batch_size=128, shuffle=True, num_workers=8
)
dataloaders = {
}
dataloaders["train"] = train_loaders
dataloaders["val"] = val_loaders
dataset_sizes = {
}
dataset_sizes["train"] = len(train_dataset)
dataset_sizes["val"] = len(val_dataset)
model = train_model(
model,
dataloaders,
dataset_sizes,
criterion,
optimizer_ft,
exp_lr_scheduler,
num_epochs=15,
)
model.eval()
torch.save(model.state_dict(), "models/mbv2_fp16.pth")
test_torch.py
import torch, torchvision
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision.datasets as datasets
import torch.utils.data as data
import torchvision.transforms as transforms
from torch.autograd import Variable
import torchvision.models as models
import matplotlib.pyplot as plt
import time, os, copy, numpy as np
from dataset import get_dataset
model = torch.load("models/mobilev2_model.pth")
_, val_dataset, _ = get_dataset()
dataloaders = torch.utils.data.DataLoader(
val_dataset, batch_size=128, shuffle=True, num_workers=8
)
running_corrects = 0.0
for i, (inputs, labels) in enumerate(dataloaders):
inputs = inputs.cuda()
labels = labels.cuda()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
running_corrects += torch.sum(preds == labels.data)
print(f"Accuracy : {
running_corrects / len(val_dataset) * 100}%")
# convert to onnx
if isinstance(model, torch.nn.DataParallel):
model = model.module
x