linux 特殊符号
文章目录
- 特殊符号
- 面试题:'' "" `` 不加引号
- 四类符号对比表
- 单引号(''):强引用,完全不解析
- 双引号(" "):弱引用,部分解析
- 不加引号:完全解析,空格分割
- 反引号(``)与 $():命令替换
- 重定向符号
- tr命令
- 正则表达式
- 基础正则符号
- 取ip地址
- 扩展正则符号
- 换行后的>提示符
- 常见触发场景:
- awk取列与正则
- awk取行
- 总结
特殊符号
面试题:‘’ “” `` 不加引号
在 Linux Shell(如 Bash)中,单引号、双引号、不加引号和反引号(或 $())的核心作用是控制字符的解析方式,尤其是特殊字符(如 $、*、?、() 等)是否被 Shell 解释。理解它们的差异是编写正确 Shell 脚本和执行命令的关键,以下是详细解析:
四类符号对比表
| 符号类型 | 变量解析($VAR) | 命令解析($(cmd)) | 通配符解析(*) | 空格分割 | 适用场景 |
|---|---|---|---|---|---|
| 单引号(’ ') | ❌ 不解析 | ❌ 不解析 | ❌ 不解析 | ❌ 不分割 | 纯文本字符串(无任何替换) |
| 双引号(" ") | ✅ 解析 | ✅ 解析 | ❌ 不解析 | ❌ 不分割 | 需替换变量 / 命令,保留空格 |
| 不加引号 | ✅ 解析 | ✅ 解析 | ✅ 解析 | ✅ 分割 | 需解析通配符、分割参数 |
| 反引号 / $() | -(仅执行命令) | ✅ 执行并替换结果 | -(命令内解析) | - | 命令输出作为字符串 |
通过记住 “单引全不解析,双引部分解析,无引全解析,反引执行命令” 的核心规则,可快速判断不同场景下应使用的符号。
示例
#双引号解析一些变量和命令,{}通配符不解析
echo "oldboy `whoami` $(pwd) lidao{1..5} *"
oldboy root /root lidao{1..5} *
#单引号什么都不解析,写什么输出什么
echo 'oldboy `whoami` $(pwd) lidao{1..5} *'
oldboy `whoami` $(pwd) lidao{1..5} *
#不加引号,什么都解析包括变量和命令,通配符
echo oldboy `whoami` $(pwd) lidao{1..5} *
oldboy root /root lidao1 lidao2 lidao3 lidao4 lidao5 anaconda-ks.cfg initial-setup-ks.cfg nginx-1.28.0 openssh-9.9p2 openssh-9.9p2.tar.gz tar
单引号(‘’):强引用,完全不解析
单引号是最严格的引用方式,Shell 会将单引号内的所有字符(包括特殊字符)视为纯文本,不做任何解析或替换。
核心规则
- 禁止所有变量替换(如
$VAR)、命令替换(如$(date))、通配符匹配(如*)。 - 单引号内不能嵌套单引号(即使加转义符
\也无效,需用其他技巧绕过,如'hello'$'\''world'表示hello'world)。
示例
#命令不解析:$(date) 不执行 date 命令
echo '$(date)'
$(date)
#特殊字符不解析:* 不匹配当前目录文件,\n 不被视为换行
echo '*'
*
echo 'line1\line'
line1\line
#变量不解析:$USER 是当前用户名(如 root),但单引号内原样输出
var="linux"
echo '$var'
$var
双引号(" "):弱引用,部分解析
双引号是灵活的引用方式,Shell 会解析引号内的部分特殊字符,同时忽略大部分通配符和空格的分隔作用。
核心规则
- 会解析的内容(允许替换):
- 变量替换:
$VAR或${VAR}(取变量值)。 - 命令替换:
$(command)或command(执行命令并取输出结果)。 - 算术运算:
$((1+2))(计算数值)。
- 变量替换:
- 不解析的内容(视为纯文本):
- 通配符:
*(匹配所有文件)、?(匹配单个字符)。 - 空格:作为字符串的一部分,不分割参数。
- 通配符:
- 可通过转义符
\强制忽略特定字符的解析(如\$、\"、\\)。
# 1. 变量解析:$VAR 被替换为实际值
VAR="Linux"
echo "$VAR is cool" # 输出:Linux is cool(正确解析变量)# 2. 命令解析:$(date) 执行 date 命令并输出结果
echo "当前时间:$(date)" # 输出:当前时间:2024年 05月 20日 星期一 14:30:00 CST# 3. 算术运算解析:$((1+2)) 计算为 3
echo "1+2 = $((1+2))" # 输出:1+2 = 3# 4. 通配符不解析:* 不匹配文件,原样输出
echo "当前目录文件:*" # 输出:当前目录文件:*(与单引号此处效果一致)# 5. 转义符生效:\$ 不解析变量,\" 表示双引号本身
echo "变量 \$VAR 的值是 \"$VAR\"" # 输出:变量 $VAR 的值是 "Linux"
不加引号:完全解析,空格分割
不加引号时,Shell 会对字符串进行最彻底的解析,同时以空格(或 Tab、换行)作为参数分隔符。
核心规则
- 解析所有特殊字符:变量替换、命令替换、算术运算、通配符(
*、?)、空格分割。 - 多个连续的空格 / Tab/ 换行会被合并为一个空格。
示例
# 1. 通配符解析:* 匹配当前目录下的所有非隐藏文件
echo * # 输出:file1.txt file2.sh dir1(当前目录的文件/目录列表)# 2. 空格分割:字符串被拆分为多个参数
echo Hello World # 输出:Hello World(实际是 echo 接收两个参数:Hello 和 World)
echo "Hello World"# 输出:Hello World(echo 接收一个参数:"Hello World",效果看似一致但本质不同)# 3. 变量与通配符结合:若变量值含通配符,会被解析
FILES="*.txt"
echo $FILES # 输出:file1.txt file2.txt(解析 *.txt 为所有 txt 文件)
echo "$FILES"# 输出:*.txt(不解析通配符,原样输出)# 4. 连续空格合并:多个空格被视为一个分隔符
echo Hello World # 输出:Hello World(中间多个空格合并为一个)
反引号(``)与 $():命令替换
反引号( )和 $() 都用于命令替换:执行引号内的命令,并将输出结果作为字符串替换到当前位置。两者功能类似,但 $() 是更现代的写法,推荐优先使用。
核心差异
| 特性 | 反引号( ) | $() |
|---|---|---|
| 嵌套支持 | 不支持(或需复杂转义) | 支持嵌套(如 $(ls $(pwd))) |
| 特殊字符处理 | 需额外转义(如 \$) | 直接支持(与双引号规则一致) |
| 兼容性 | 所有 Shell 支持(包括老版本) | Bash、Zsh 等现代 Shell 支持 |
示例
# 1. 基本命令替换:获取当前目录路径
echo "当前目录:`pwd`" # 输出:当前目录:/home/user
echo "当前目录:$(pwd)" # 输出:当前目录:/home/user(效果一致)# 2. $() 支持嵌套:获取当前目录下的 txt 文件数
echo "txt 文件数:$(ls *.txt | wc -l)" # 输出:txt 文件数:2
# 反引号嵌套需转义,非常繁琐(不推荐):
echo "txt 文件数:`ls *.txt | wc -l`" # 单层可用,多层需 `ls \`pwd\` | wc -l`# 3. 与变量结合:将命令结果赋值给变量
CURRENT_DATE=$(date +"%Y-%m-%d")
echo "今天日期:$CURRENT_DATE" # 输出:今天日期:2024-05-20
重定向符号
在 Linux Shell 中,重定向符号用于改变命令的输入来源或输出目的地(默认是终端),是处理文件和命令交互的核心工具。常见的重定向符号及其功能如下:
| 符号 | 功能描述 | 使用 | 示例 |
|---|---|---|---|
>或1> | 覆盖重定向 标准输出 到文件 | 创建文件并写入内容 | echo "hi" > a.txt |
>>或1>> | 追加重定向 标准输出 到文件 | 修改配置 | echo "hi" >> a.txt |
2> | 覆盖重定向 标准错误输出 到文件 | 较少单独用 | ls /err 2> err.log |
2>> | 追加重定向 标准错误输出 到文件 | 较少单独用 | ls /err 2>> err.log |
&> | 覆盖重定向 标准输出和 标准错误输出 到文件 | 较少单独用 | command &> all.log |
&>> | 追加重定向 标准输出和 标准错误输出 到文件 | 较少单独用 | command &>> all.log |
2>&1 | 将 标准错误输出 合并到 标准输出 的目的地 | 经常使用(运行脚本,定时任务) | command > out.log 2>&1 |
< | 将文件内容作为 标准输入 输入 | 其他命令几乎不会用 | cat < a.txt |
<< DELIM | 多行输入(Here Document),直到 DELIM | 常用 | cat << EOF ... EOF |
2>/dev/null | 丢弃 标准错误输出 | 常用 | command > /dev/null |
示例
# > 覆盖并创建文件
echo 11111 > w.txt
[root@kylin-v10-shf /shf]#cat w.txt
11111
# >> 追加到文件末尾
echo 22222222 > w.txt
[root@kylin-v10-shf /shf]#cat w.txt
22222222
# 2> 覆盖并将错误输出输入到文件,也可以创建文件
car 2> w.txt
[root@kylin-v10-shf /shf]#cat w.txt
-bash: car:未找到命令
# 2>&1 将错误正确都输入到文件中
[root@kylin-v10-shf /shf]#whoami >> w.txt 2>&1 #输出正确
[root@kylin-v10-shf /shf]#whoai >> w.txt 2>&1 #输出错误
[root@kylin-v10-shf /shf]#cat w.txt
root
-bash: whoai:未找到命令
#两个都写进去了#进阶写法1-在脚本中替代echo命令实现输出
cat << EOF
内容
EOF
#进阶写法2-通过cat创建写入配置文件避免特殊符号解析使用
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
内容
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/7/$basearch/ #避免被解析
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOFtr命令
#字母基本/字符级别的替换(大写-->小写)
tr 'a-z' 'A-Z' < /etc/passwd | head -5
---------------------------------------------
ROOT:X:0:0:ROOT:/ROOT:/BIN/BASH
BIN:X:1:1:BIN:/BIN:/SBIN/NOLOGIN
DAEMON:X:2:2:DAEMON:/SBIN:/SBIN/NOLOGIN
ADM:X:3:4:ADM:/VAR/ADM:/SBIN/NOLOGIN
LP:X:4:7:LP:/VAR/SPOOL/LPD:/SBIN/NOLOGIN
xargs 参数转换,控制参数个数
[root@kylin-v10-shf ~]#seq 10
1
2
3
4
5
6
7
8
9
10
#xargs -n3 表示每次只处理3个参数
[root@kylin-v10-shf ~]#seq 10 | xargs -n3
1 2 3
4 5 6
7 8 9
10
正则表达式
基础正则符号
| 符号 | 描述 / 功能 | 示例及说明 |
|---|---|---|
^ | 匹配行首(字符串必须出现在一行的开头) | ^hello → 匹配以 “hello” 开头的行(如 “hello world”) |
$ | 匹配行尾(字符串必须出现在一行的结尾) | world$ → 匹配以 “world” 结尾的行(如 “hello world”) |
^$ | 匹配空行(行首和行尾之间无任何字符) | grep '^$' file.txt → 查找文件中的所有空行 |
. | 匹配除换行符(\n)外的任意单个字符 | h.t → 匹配 “hit”、“hot”、“h t”(h 和 t 之间是空格)、“h3t” 等 |
* | 匹配前一个字符0 次、1 次或多次(尽可能多匹配) | ab*c → 匹配 “ac”(b 出现 0 次)、“abc”(b 出现 1 次)、“abbc”(b 出现 2 次)等 |
[字符集] | 匹配括号内任意一个字符(支持范围表示) | [0-9] → 匹配任意数字;[a-zA-Z] → 匹配任意大小写字母;[abc] → 匹配 a、b、c |
[^字符集] | 匹配不在括号内的任意一个字符(取反) | [^0-9] → 匹配非数字字符;[^abc] → 匹配除 a、b、c 外的任意字符 |
\ | 转义符:将特殊字符转为普通字符,或普通字符转为特殊含义 | \. → 匹配实际的点号(如 IP 中的 “.”:192\.168\.1\.1);\* → 匹配实际的星号 |
\{n\} | 匹配前一个字符恰好 n 次(需转义) | a\{3\} → 匹配 “aaa”(a 连续出现 3 次) |
\{n,\} | 匹配前一个字符至少 n 次(需转义) | a\{2,\} → 匹配 “aa”、“aaa”、“aaaa” 等 |
\{n,m\} | 匹配前一个字符至少 n 次,最多 m 次(需转义) | a\{2,4\} → 匹配 “aa”、“aaa”、“aaaa” |
\(pattern\) | 将pattern视为一个整体(分组,需转义) | \(ab\)* → 匹配 “ab” 整体出现 0 次(空)、1 次(ab)、2 次(abab)等 |
\1 \2… | 引用第 1、2… 个分组匹配的内容(复用子串) | \(ab\)\1 → 引用第一个分组(ab),匹配 “abab” |
| ` | ` | 逻辑 “或”,匹配左边或右边的表达式(需转义) |
\+ | 匹配前一个字符至少 1 次(需转义) | a\+ → 匹配 “a”、“aa”、“aaa” 等(不匹配空) |
\? | 匹配前一个字符0 次或 1 次(需转义) | colou\?r → 匹配 “color”(u 出现 0 次)或 “colour”(u 出现 1 次) |
基础正则示例
案例内容
cat > re.txt << EOF
I am oldboy teacher!
I teach linux.I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.commy qq is 49000448
not 4900000448.my god ,i am not oldbey,but OLDBOY!
EOF
1.^ 以xxxx开头的行
#以I开头的行输出出来
[root@kylin-v10-shf /shf]#grep '^I' re.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
2.$以xxxx结尾的行
#以!为结尾的行输出出来
[root@kylin-v10-shf /shf]#grep '!$' re.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my god ,i am not oldbey,but OLDBOY!
cat -A 查看隐藏符号
[root@kylin-v10-shf /shf]#cat -A re.txt
I am oldboy teacher!$
I teach linux.$
$
I like badminton ball ,billiard ball and chinese chess!$
my blog is http://oldboy.blog.51cto.com $
our size is http://blog.oldboyedu.com $
$
my qq is 49000448$
not 4900000448.$
$
my god ,i am not oldbey,but OLDBOY!$
3.^$ 表示空行
#排除空行的行
[root@kylin-v10-shf /shf]#grep -v '^$' re.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
#排除sshd_config空行和包含井号的行
[root@kylin-v10-shf /shf]#grep -nEv '^$|#' /app/tools/openssh/etc/sshd_config
13:Port 52113
32:PermitRootLogin yes
41:AuthorizedKeysFile .ssh/authorized_keys
57:PasswordAuthentication yes
109:Subsystem sftp /app/tools/openssh-9.9p2/libexec/sftp-server
4 .表示任意一个字符
.表示以任意字符为结尾的行输出出来
加上\表示只是以.这个符号输出出来
grep '.$' re.txt
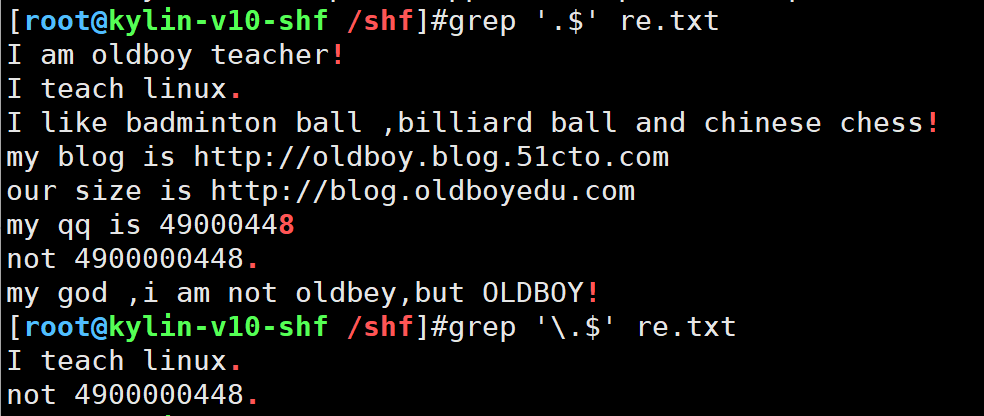
5.*前一个字符出现0次或多次
以0的字符输出出来
grep '0*' re.txt
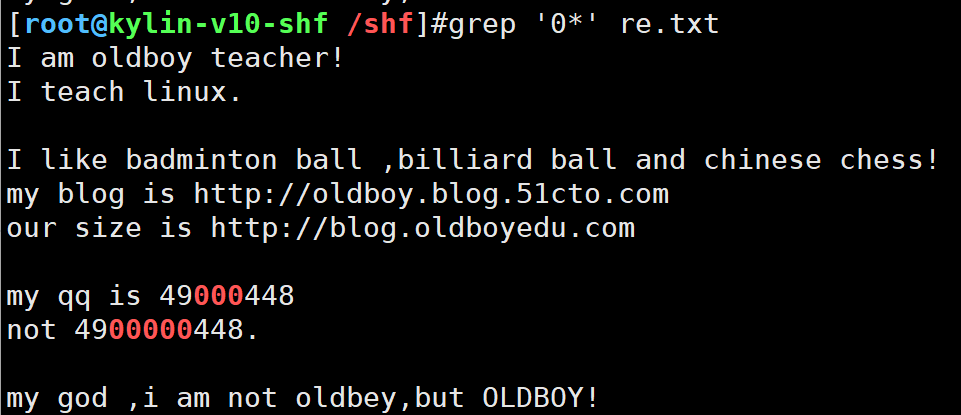
*最常用的表示 所有
练习
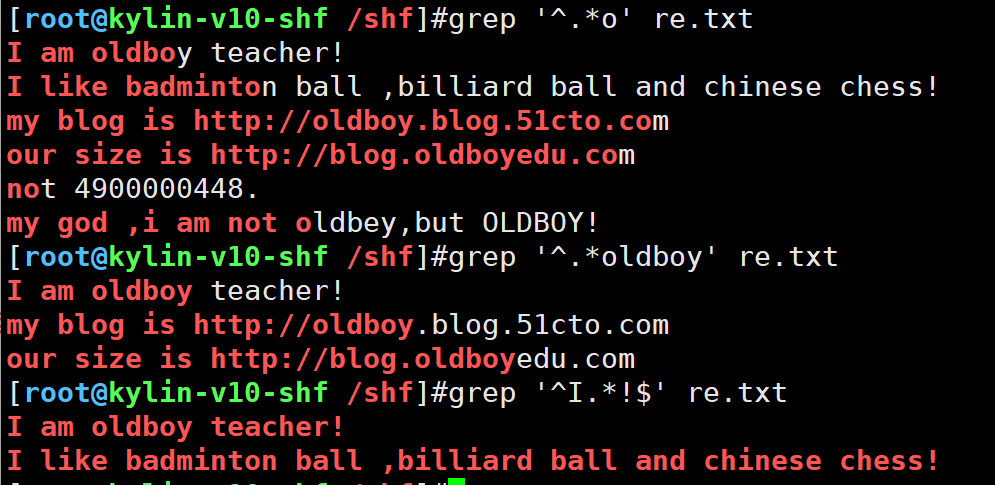
1.过滤从开头到0结尾的行,但是不是从第一个o结尾,而是最后一个o结尾的
grep '^.*o' re.txt
2.过滤从开头到oldboy结尾的行
grep '^.*oldboy' re.txt
3.过率从I开头,!结尾的行
grep '^I.*!$' re.txt
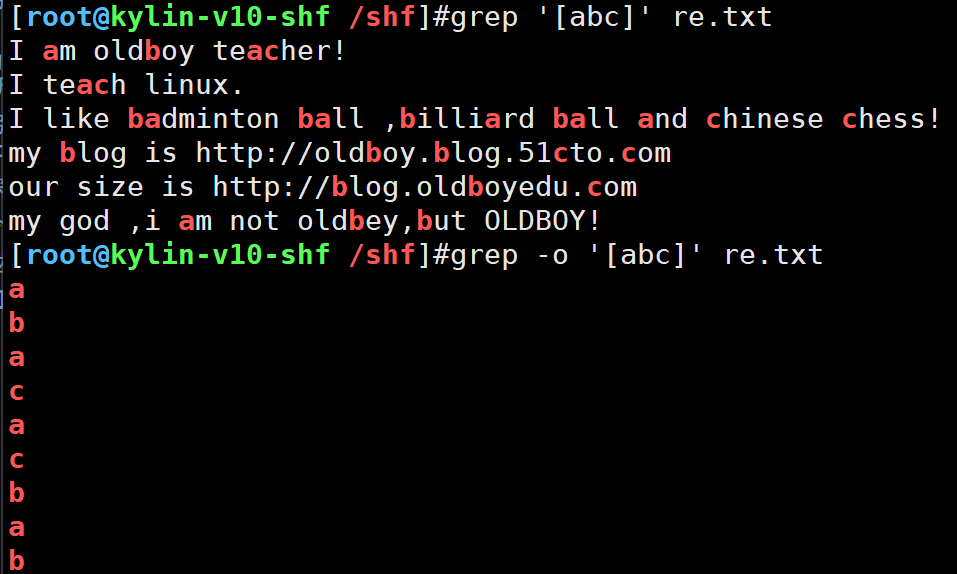
6.[] [abc]1个整体包含3个情况,匹配a或b或c
- 过滤包含a,b,c的行
- -0 表示精确输出
过滤小写字母
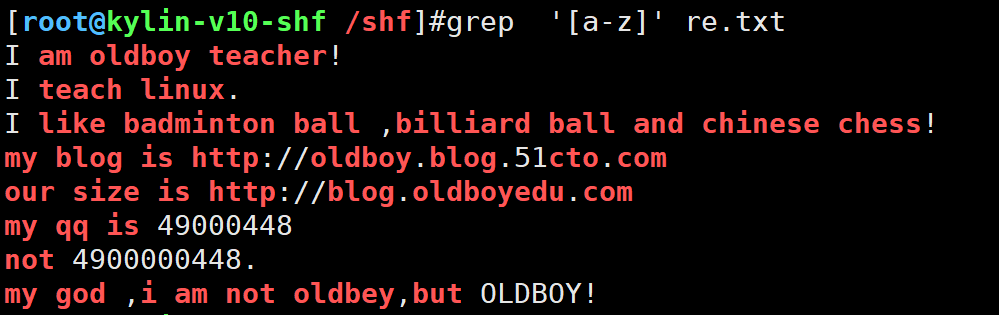
过滤大写字母
grep '[A-Z]' re.txt

过滤数字
grep '[0-9]' re.txt

过滤大小写字母
grep '[a-zA-Z]' re.txt
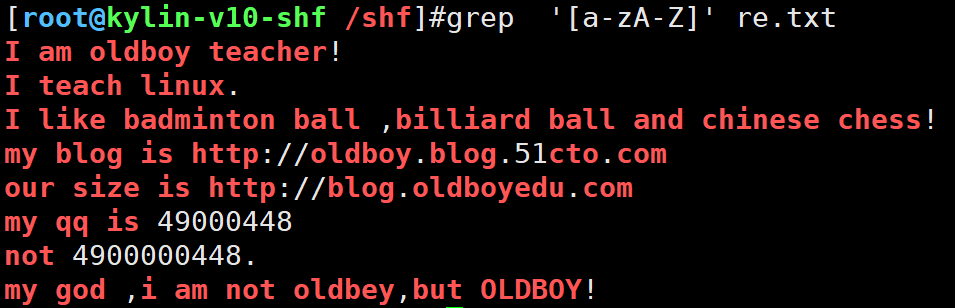
过滤大小写字母和数字
两种写法
[0-Z]精简写法但不通用
grep '[0-Z]' re.txt
grep '[a-zA-Z0-9]' re.txt
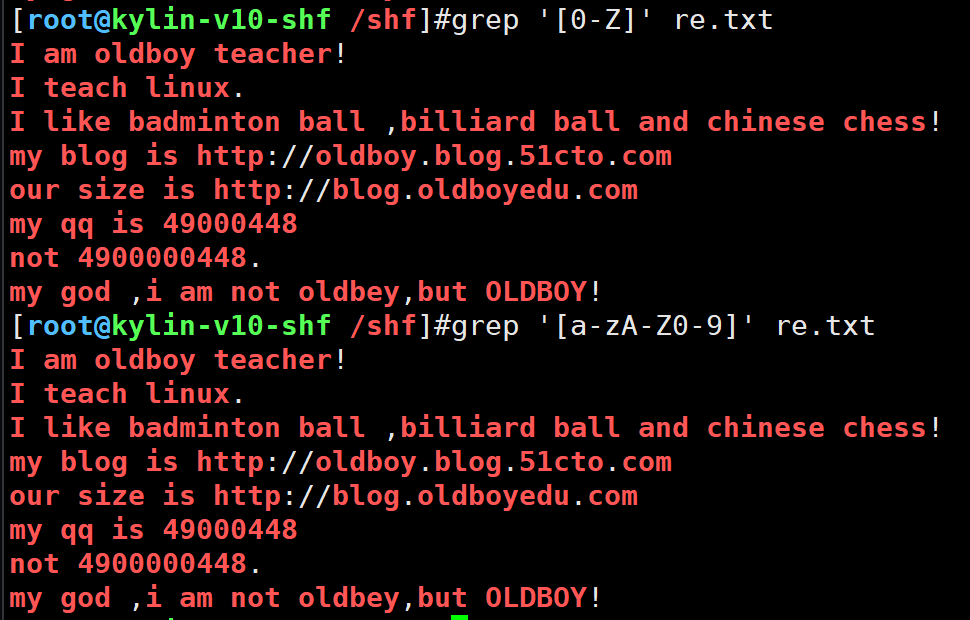
练习
过滤出文件中以I或m或n 开头的行
[root@kylin-v10-shf /shf]#grep -i '^[Imn]' re.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq is 49000448
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
过滤出文件中以I或m或n 开头的行,然后结尾是!或数字
[root@kylin-v10-shf /shf]#grep '^[Imn].*[0-9!]$' re.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my qq is 49000448
my god ,i am not oldbey,but OLDBOY!
7.[^] [^abc] 不匹配a或b或c
grep '[^abc]' re.txt
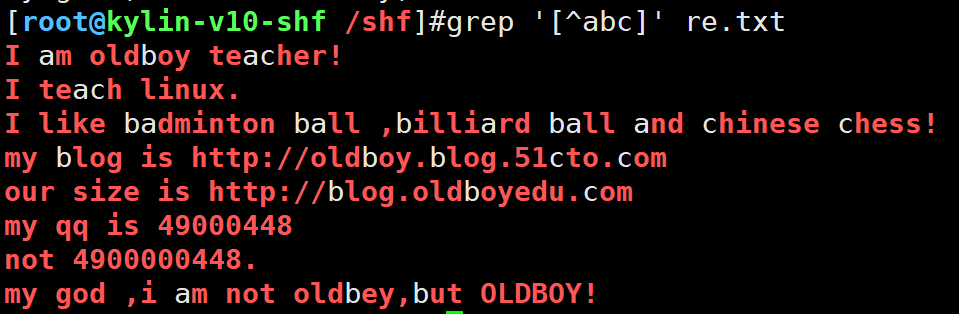
取ip地址
ip a |grep -E -o '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'
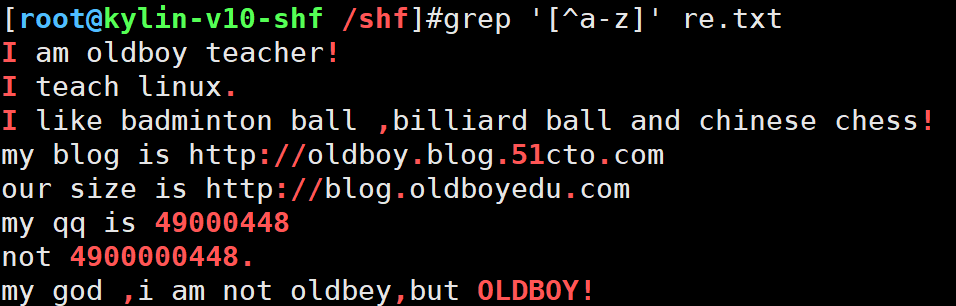
显示不是字母的字符
grep '[^a-z]' re.txt
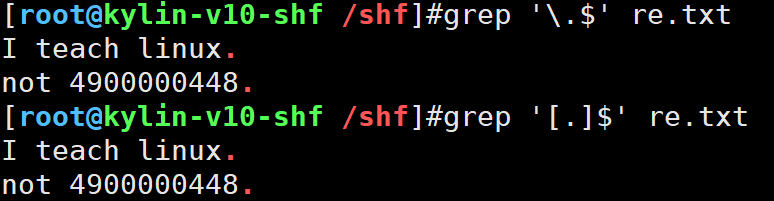
8.过滤出以.结尾的行
grep '[.]$' re.txt
grep '\.$' re.txt # \ 转义字符,回原形
扩展正则符号
以下是扩展正则表达式(ERE,Extended Regular Expressions) 核心符号的汇总表格,包含符号、描述、示例及与基础正则的差异对比,便于快速参考:
| 符号 | 描述 / 功能 | 示例及说明 |
|---|---|---|
^ | 匹配行首(字符串出现在一行开头) | ^ERROR → 匹配以 “ERROR” 开头的行(如日志错误行) |
$ | 匹配行尾(字符串出现在一行结尾) | done$ → 匹配以 “done” 结尾的行(如任务完成标记) |
^$ | 匹配空行(行首与行尾间无字符) | grep -E '^$' file.txt → 查找文件中的空行 |
. | 匹配除换行符(\n)外的任意单个字符 | h.y → 匹配 “hey”、“h3y”、“h y”(h 和 y 之间任意字符) |
* | 匹配前一个字符0 次、1 次或多次 | ab*c → 匹配 “ac”(b0 次)、“abc”(b1 次)、“abbc”(b2 次)等 |
[字符集] | 匹配括号内任意一个字符(支持范围) | [0-9] → 匹配任意数字;[a-zA-Z] → 匹配任意字母 |
[^字符集] | 匹配不在括号内的任意字符(取反) | [^0-9] → 匹配非数字字符;[^abc] → 匹配除 a、b、c 外的字符 |
+ | 匹配前一个字符至少 1 次(不允许 0 次) | a+ → 匹配 “a”、“aa”、“aaa” 等(不匹配空) |
? | 匹配前一个字符0 次或 1 次 |
示例
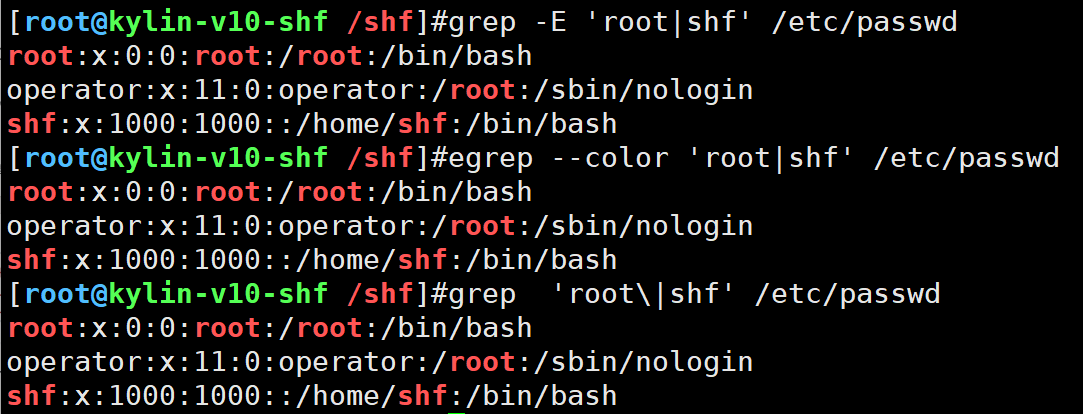
1.grep | 或者
筛选出root或shf的行
grep -E 'root|shf' /etc/passwd
egrep --color 'root|shf' /etc/passwd
grep 'root\|shf' /etc/passwd
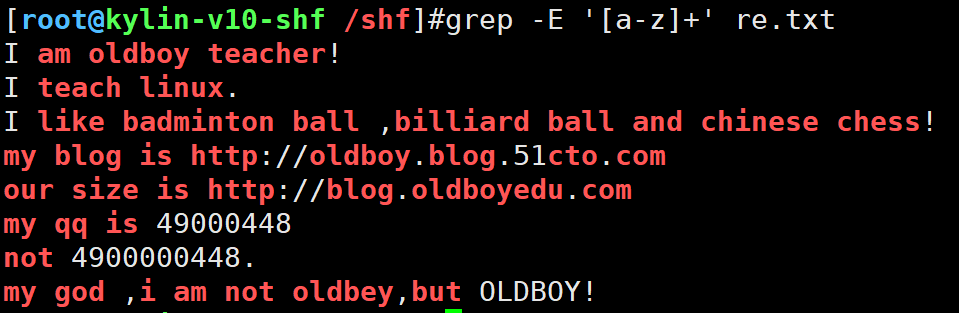
2.+前一个字符出现1次或1次以上
与[]搭配使用
grep -E '[a-z]+' re.txt
以单词形式表现
grep -Eo '[a-z]+' re.txt
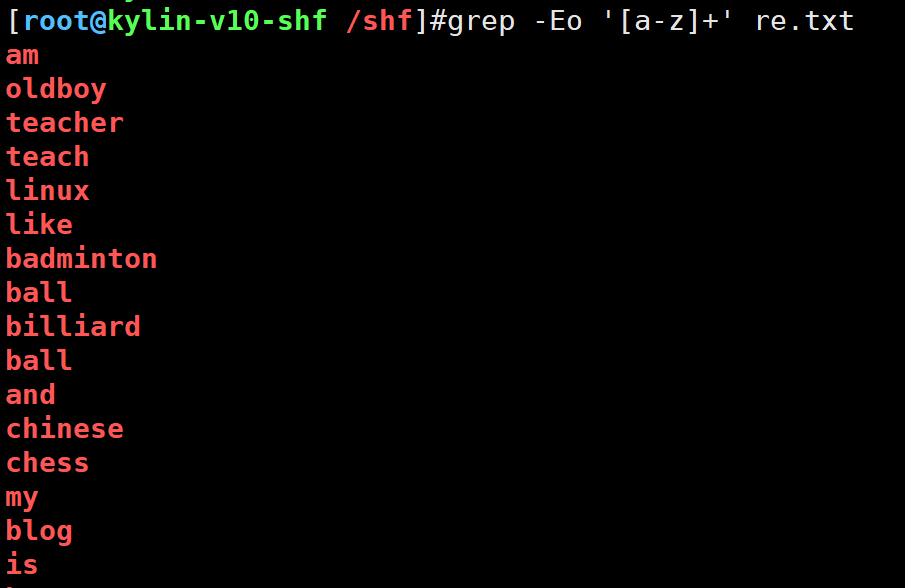
取出re.txt文件中连续出现的单词统计次数,取出前5
[root@kylin-v10-shf /shf]#cat re.txt | grep -Eo '[a-Z]+' | sort | uniq -c | sort -rnk1 | head -53 my3 is3 I3 blog2 oldboy
取出re.txt文件中出现的字母统计次数,取出前5
[root@kylin-v10-shf /shf]#cat re.txt | grep -Eo '[a-Z]' | sort | uniq -c | sort -rnk1 | head -518 o15 l12 b11 t11 i
3.{} o{n,m} 前一个字符o,出现至少n次,最多出现m次
表示范围的匹配,出现1位数字到3位数字
匹配 “1 到 3 个连续数字
grep -E '[0-9]{1,3}' re.txt

显示过程
grep -Eo '[0-9]{1,3}' re.txt
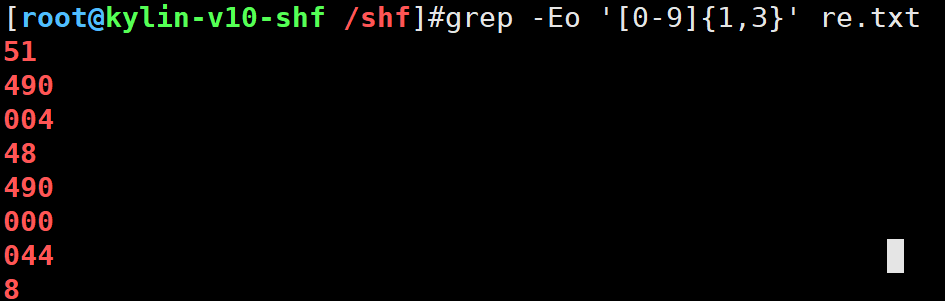
表示仅匹配“正好3个连续数字”
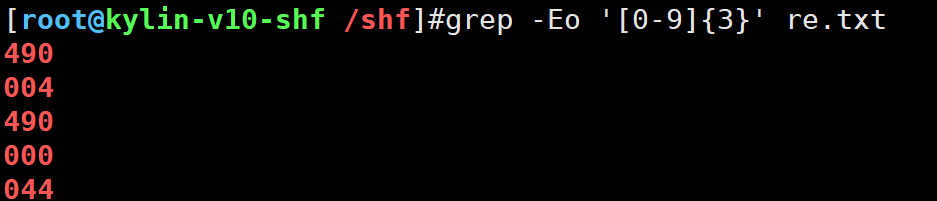
grep -E '[0-9]{3}' re.txt

显示过程
grep -Eo '[0-9]{3}' re.txt
书写一个简易的正则匹配ip地址
#只显示ip地址
ip a s ens33 | grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'

4.() 1个整体(sed命令中表示反向引用)
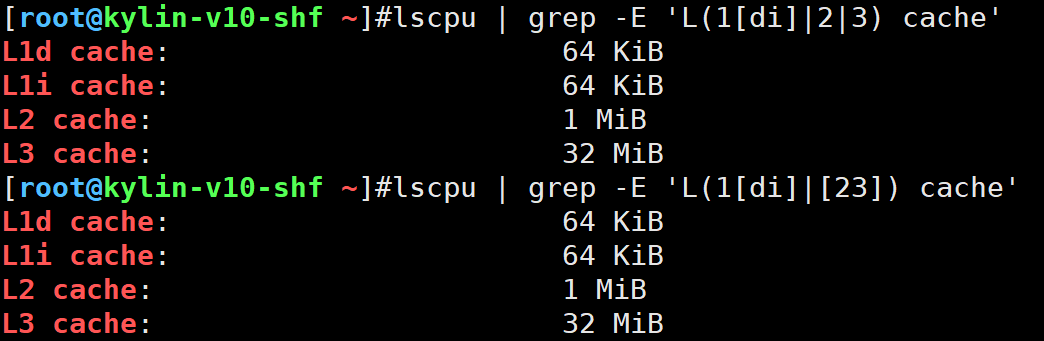
只取这4列,用lscpu命令
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 1 MiB
L3 cache: 32 MiB
- 一个一个取
lscpu | grep -E 'L1d cache|L1i cache|L2 cache|L3 cache'

()括起来,这样更简便
lscpu | grep -E 'L(1d|1i|2|3) cache'

- 更精简的写法
lscpu | grep -E 'L(1[di]|2|3) cache'
lscpu | grep -E 'L(1[di]|[23]) cache'
5.?前一个字符出现0次或1次
cat >test.txt << EOF
good
goooood
gd
god
EOF[root@kylin-v10-shf /shf]#grep -E 'gd|god' test.txt
gd
god
[root@kylin-v10-shf /shf]#grep -E 'go?d' test.txt
gd
god
[root@kylin-v10-shf /shf]#grep -E 'go+d' test.txt
good
goooood
god
[root@kylin-v10-shf /shf]#grep -E 'go*d' test.txt
good
goooood
gd
god
换行后的>提示符
在 Linux/macOS 终端或类 Unix shell 环境中,当输入的命令未完成(需要换行继续输入)时,会出现 > 提示符(称为 “二级提示符” 或 “继续提示符”),表示 shell 正在等待你输入命令的剩余部分。
常见触发场景:
引号未闭合(单引号'、双引号"、反引号 ```)
当输入引号但未闭合时,shell 会认为命令还在继续,显示>等待补全:
# 输入了双引号但未闭合
echo "Hello, world
> # 这里会出现>提示符,等待输入闭合的"
> " # 补全引号后按回车,命令才会执行
Hello, world
反斜杠\强制换行
用\结尾表示命令未结束,换行后会出现>提示符,继续输入:
# 用\换行,继续输入命令
echo "Line 1" \
> "Line 2" # >提示符处继续输入
Line 1 Line 2 # 执行结果
管道 / 逻辑运算符未完成
若命令以管道|、逻辑运算符&&/||等结尾,shell 会等待后续命令:
# 以|结尾,等待后续命令
ls -l | grep ".txt" \
> | wc -l # >提示符处继续输入
awk取列与正则
awk -F 选项的作用是修改/指定awk的分隔符
1.取出/etc/passwd第一列,第二列,最后一列
[root@kylin-v10-shf /shf]#awk -F: '{print $1,$2,$NF}' /etc/passwd | head -5
root x /bin/bash
bin x /sbin/nologin
daemon x /sbin/nologin
adm x /sbin/nologin
lp x /sbin/nologin
运行ip a命令取出网卡ip地址
[root@kylin-v10-shf /shf]#ip a s ens33 |awk -F'inet |/' 'NR==3{print $2}'
10.0.0.200
w命令结果中获取运行时间
[root@kylin-v10-shf /shf]#cat w.txt | awk -F'up |, +[0-9]+ user' '{print $2}'
83 days, 7:42
18:42
awk取行
- awk
NR==3指定行号 - awk
NR>=3 - awk
NR>=3&&NR<=10
#取第3行
[root@kylin-v10-shf /shf]#seq 20 | awk 'NR==3'
3
#取大于3的行
[root@kylin-v10-shf /shf]#seq 20 | awk 'NR>=3'
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#取大于3小于10的行
[root@kylin-v10-shf /shf]#seq 20 | awk 'NR>=3 && NR<=10'
3
4
5
6
7
8
9
10
在/etc/passwd文件进行操作
#过滤root和shf的行
[root@kylin-v10-shf /shf]#awk '/root|shf/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
shf:x:1000:1000::/home/shf:/bin/bash
#过滤root开头的行
[root@kylin-v10-shf /shf]#awk '/^root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
#过滤bash结尾的行
[root@kylin-v10-shf /shf]#awk '/bash$/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
shf:x:1000:1000::/home/shf:/bin/bash
song:x:1003:1003::/home/song:/bin/bash
总结
- 单引号,双引号,不加引号,反引号
- 重定向符号
> >> 2>&1 - 基础正则l扩展表达式
^ $ ^$ .* [] | + - awk取行和取列