phpmysql网站开发项目式教程苏州网站seo优化
目录
1. LangGraph底层原理介绍
2. LangGraph底层源码解析
2.1 Graph基类
2.2 GraphState
2.3 Nodes
2.4 Edges
2.5 Graph 的调用方法
3. 使用LangGraph构建大模型的问答流程
1. LangGraph底层原理介绍
LangChain发展至现在,仍然是构建大语言模型应用程序的前沿框架之一。特别是在最新发布的v0.3版本中,已经基本完成了由传统类到表达式语言(LCEL)的重要过渡,给开发者带来的直接利好就是定义和执行分步操作序列(也称为链)更加简单。用更专业的术语来说,使用LangChain 构建的是 DAG(有向无环图)。而之所以会出现LangGraph框架,根本原因是在于随着AI应用(特别是AI Agent)的发展,对于大语言模型的使用不仅仅是作为执行工具,而更多作为推理引擎的需求在日益增长。这种转变带来的是更多的重复(循环)和复杂条件的交互需求,这就导致基于LCEL的线性序列构建方式在构建更复杂、更智能的系统时显示出了明显的局限性。如下所示的代码就是在LangChain中通过LECL表达式语言构建Chain的一种最简单的方式:
import getpass
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplateif not os.environ.get("OPENAI_API_KEY"):os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")llm = ChatOpenAI(model="gpt-4o")prompt = ChatPromptTemplate.from_messages([("system","You are a helpful assistant that translates {input_language} to {output_language}."),("human", "{input}"),]
)chain = prompt | llmchain.invoke({"input_language": "English","output_language": "Chinese","input": "I love programming.",}
) AIMessage(content='我爱编程。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 5, 'prompt_tokens': 26, 'total_tokens': 31, 'prompt_tokens_details': {'cached_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_6b68a8204b', 'finish_reason': 'stop', 'logprobs': None}, id='run-8ba80a92-49ea-46d9-a049-256ff2b590a8-0', usage_metadata={'input_tokens': 26, 'output_tokens': 5, 'total_tokens': 31, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
反观LangGraph,顾名思义,LangGraph 在图这个概念上有很大的侧重,它的出现就是要解决线性序列的局限性问题,而解决的方法就是循环图。在LangGraph框架中,用图取代了LangChain的AgentExecutor(代理执行器),用来管理代理的生命周期并在其状态内将暂存器作为消息进行跟踪,增加了以循环方式跨各种计算步骤协调多个链或参与者的功能。这就与 LangChain 将代理视为可以附加工具和插入某些提示的对象不同,对于图来说,意味着我们可以从任何可运行的功能或代理或链作为一个程序的起点。上面过于专业描述可能理解起来比较困难,所以这里我们通过一个简单直观的场景来详细解释。
在以图构建的框架中,任何可执行的功能都可以作为对话、代理或程序的启动点。这个启动点可以是大模型的 API 接口、基于大模型构建的 AI Agent,通过 LangChain 或其他技术建立的线性序列等等,即下图中的 "Start" 圆圈所示。无论哪种形式,它都首先处理用户的输入,并决定接下来要做什么。下图展示了在 LangGraph 概念下,最基本的一种代理模型:
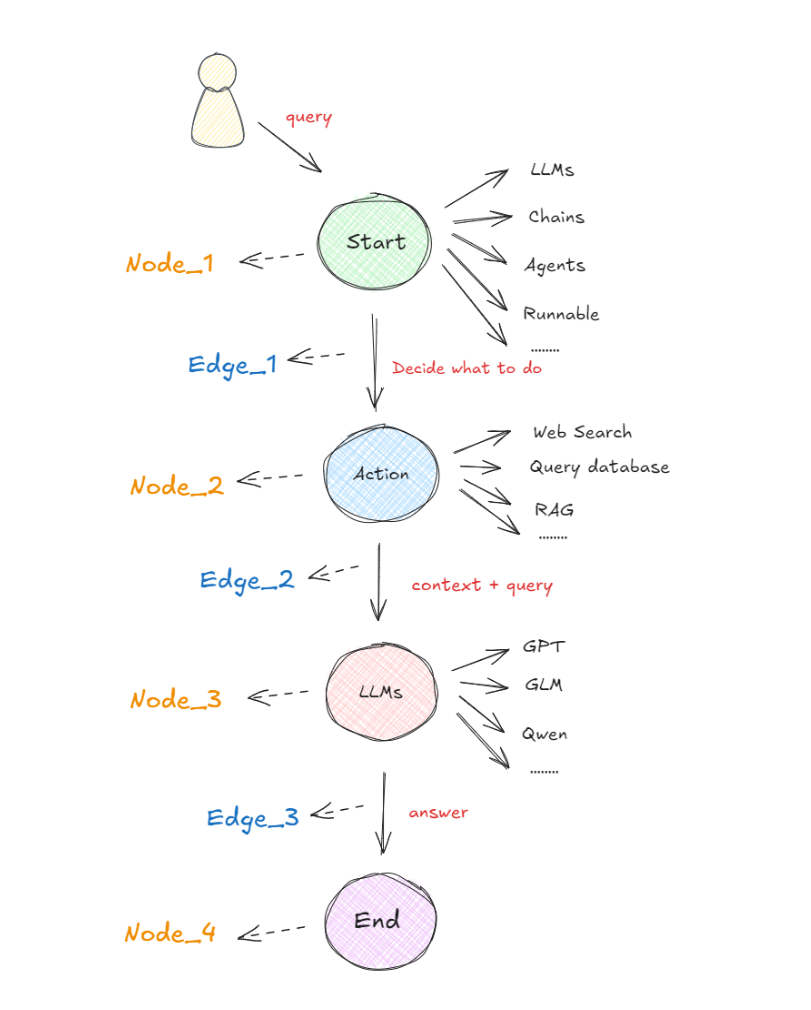
在启动点定义的可运行功能会根据收到的输入决定是否进行检索以及如何响应。比如在执行过程中,如果需要检索信息,则可以利用搜索工具来实现,比如Web Search(网络搜索)、Query Database(查询数据库)、RAG等获取必要的信息(图中的 "Action" 圆圈)。接下来,再使用一个大语言模型(LLM)处理工具提供的信息,结合用户最初传入的初始查询,生成最终的响应(图中的 "LLMs" 圆圈)。最终,这个响应被传递至终点节点(图中的 "End" 圆圈)。
上图所示的流程就是在LangGraph概念中一个非常简单的代理构成形式。关键且必须清楚的概念是:在这里,每个圆圈代表一个“节点”(Nodes),每个箭头表示一条“边”(Edges)。因此,在 LangGraph 中,无论代理的构建是简单还是复杂,它最终都是由节点和边通过特定的组合形成的图。这样的构建形式形成的工作流原理就是:当每个节点完成工作后,通过边告诉下一步该做什么,所以也就得出了:LangGraph的底层图算法就是在使用消息传递来定义通用程序。当节点完成其操作时,它会沿着一条或多条边向其他节点发送消息。然后,这些接收节点执行其功能,将结果消息传递给下一组节点,然后该过程继续。如此循环往复。
这就是
LangGraph底层架构设计中图算法的根本思想。
接下来,我们再看一个更现实的复杂例子。
在这个示例中,我们将AI Agent定义为应用程序的起点。构建AI Agent代理通常涉及配置一个或多个工具,否则构建它就没有太大的意义,因为如果仅仅是针对用户的问题直接做响应,即使问题很复杂,我们也可以直接通过提示词来引导大模型进行推理。那么当AI Agent包含一些工具时,它是通过函数调用功能使用这些工具,而不是直接执行这些工具。所以当用户输入的原始问题经过AI Agent处理的时候,一般会出现以下两种情况:
- 如果不需要调用任何工具,
AI Agent会直接提供一个针对用户问题的自然语言响应。例如:- 用户:你好,请你介绍一下你自己。
- AI Agent:你好,我是一个人工智能助手,可以帮助你解决问题。
- 如果需要调用工具,则输出将是一个特定格式的 JSON 输出,指示进行特定的函数调用。例如:
- 输出示例:function': {'arguments': '{"query":"什么是快乐星球?"}','name': 'web_search'},'type': 'function'}
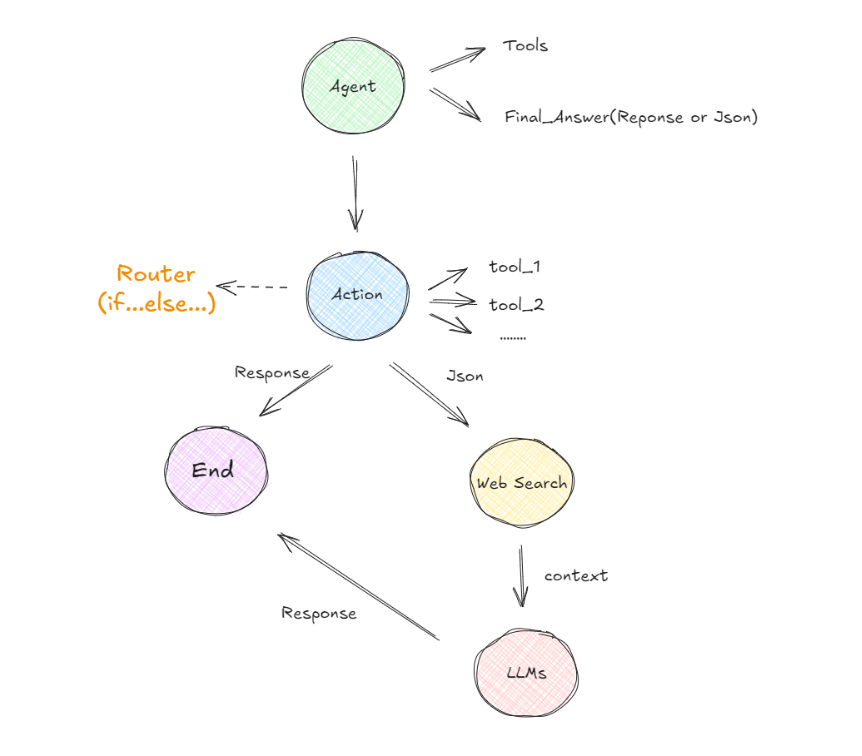
经过第一个节点后(Agent),如果AI Agent认为需要调用某个函数,它会确定使用哪个工具以及传递哪些参数。假设有多个工具可选的情况下,Action 节点将呈现多条可能的路径供选择。如何选择呢?这时候,LangGraph 引入了一个称为“条件边”的组件。条件边根据是否满足特定条件来决定走哪条路径,例如,代理可能需要决定是使用搜索工具还是直接生成最终答案。为了管理这些决策,则使用了一个类似于 if-else 语句的结构,称为Router。基于Router的决策,代理可能会导向“搜索节点”以执行搜索操作并返回原始文本,或者直接前往“最终答案节点”以获取格式化后的自然语言响应。如果选择了搜索路径,获取的答案文本还需通过另一个大语言模型进行处理,以生成用户可以理解的响应;若选择了直接回答,则可以使用一个专门的工具来格式化输出。
在 LangGraph 框架中,Router 使用 if..else 的形式来决定路径,主要通过以下三种方式实现:
- 提示工程:指示大模型以特定格式做出回应。
- 输出解析器:使用后处理从大模型响应中提取结构化数据。
- 工具调用:利用大模型的内置工具调用功能来生成结构化输出。
更进一步地,我们现在知道了LangGraph通过组合Nodes和Edges去创建复杂的循环工作流程,通过消息传递的方式串联所有的节点形成一个通路。那么维持消息能够及时的更新并向该去的地方传递,则依赖langGraph构建的State概念。 在LangGraph构建的流程中,每次执行都会启动一个状态,图中的节点在处理时会传递和修改该状态。这个状态不仅仅是一组静态数据,而是由每个节点的输出动态更新,然后影响循环内的后续操作。如下所示:
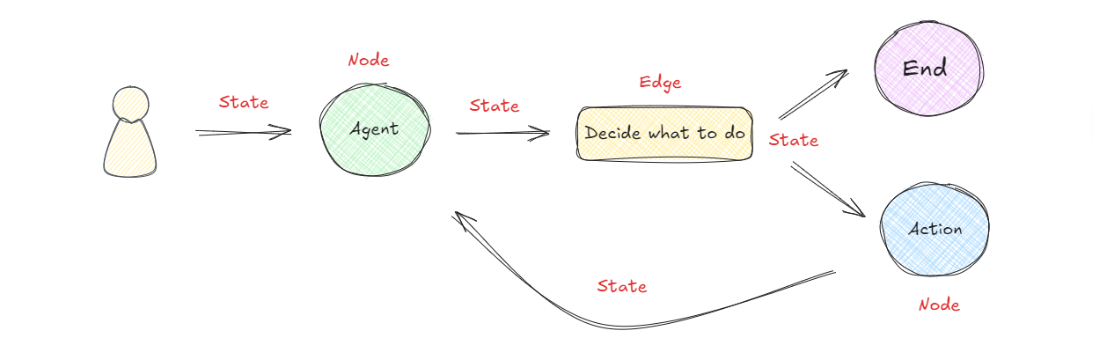
此谓共享状态。共享状态是指在执行期间在图内的节点之间传递的数据或信息。 LangGraph允许节点在图上执行时通过共享和更新此公共状态来进行交互。这种共享状态使节点能够根据它们共同维护的数据进行通信、交换信息并影响彼此的行为。通过利用共享状态, LangGraph才能够促进节点间操作的协调和同步,允许动态交互和创建复杂的工作流程,其中节点可以协作并根据可用的共享信息做出决策。
从LangGraph官方的定义看,该框架是一个用于使用大模型构建有状态、多参与者应用程序的库,可以创建代理和多代理工作流程。而其官方自己总结的LangGraph的优势则是:
- 循环和分支:在应用程序中实现循环和条件。
- 持久性:在图中的每个步骤之后自动保存状态。随时暂停和恢复图形执行,以支持错误恢复、人机交互工作流程、时间旅行等。
- 人机交互:中断图形执行以批准或编辑代理计划的下一个操作。
- 流支持:流输出由每个节点生成(包括令牌流)。
- 与 LangChain 集成:LangGraph 与LangChain和LangSmith无缝集成(但不需要它们)。
LangGraph Github:https://github.com/langchain-ai/langgraph
LangGraph Docs:LangGraph
至此,当我们了解了上述的原理后,再来看LangGraph官方的介绍,就能够比较清楚的理解其独特优势究竟体现在何处。
2. LangGraph底层源码解析
在上一小节的原理介绍部分,我们在图中提到了节点、边、状态和路由四个概念,那在LangGraph框架中,各个组件是怎么实现,以及如何定义图结构呢? 我们将在这一小节展开详细的介绍和代码实践。首先我们来看图。
2.1 Graph基类
对于任意一个简单或者复杂的图来说,都是基于Graph类来构建和管理图结构的。在Graph类中允许添加节点、边,并定义节点间的动态流转逻辑。如下是Graph类的主要组成部分和功能:
from collections import defaultdict
from typing import Any, Callable, Dict, Optional, Set, Tuple, Union, Awaitable, Hashableclass Graph:def __init__(self) -> None:self.nodes: Dict[str, Any] = {} # 一个字典,用于存储图中的所有节点。每个节点可以是一个字符串标识或者是一个可调用对象self.edges: Set[Tuple[str, str]] = set() # 一个集合,用来存储图中所有的边,边由一对节点名称组成,表示从一个节点到另一个节点的直接连接。self.branches: defaultdict = defaultdict(dict) # 一个默认字典,用于存储条件分支,允许从一个节点根据特定条件转移到多个不同的节点。self.support_multiple_edges = False # 一个布尔值,指示图是否支持同一对节点间的多条边。self.compiled = False # 一个布尔值,表示图是否已经被编译。编译是指图的结构已经设置完毕,准备进行执行。@propertydef add_edges(self) -> Set[Tuple[str, str]]:"""添加一个新节点到图中。节点可以有附加的元数据,这些元数据存储在节点的字典中。"""return self.edgesdef add_node(self, node: Union[str, Callable], action: Optional[Callable] = None, *, metadata: Optional[Dict[str, Any]] = None) -> 'Graph':"""添加一个新节点到图中。节点可以有附加的元数据,这些元数据存储在节点的字典中。"""passdef add_edge(self, start_key: str, end_key: str) -> 'Graph':"""在图中添加一条边,连接两个指定的节点。"""passdef add_conditional_edges(self, source: str, path: Callable, path_map: Optional[Dict[Hashable, str]] = None, then: Optional[str] = None) -> 'Graph':"""添加一个条件边,允许在执行时根据某个条件从一个节点动态地转移到一个或多个节点。"""passdef set_entry_point(self, key: str) -> 'Graph':"""设置图的入口点,即定义图执行的起始节点。"""passdef set_conditional_entry_point(self, path: Callable, path_map: Optional[Dict[Hashable, str]] = None, then: Optional[str] = None) -> 'Graph':"""设置一个条件入口点,允许根据条件动态决定图的起始执行点。"""passdef set_finish_point(self, key: str) -> 'Graph':"""设置结束点,定义图执行到此节点时将停止。"""passdef validate(self, interrupt: Optional[Set[str]] = None) -> 'Graph':"""验证图的结构是否正确,确保所有节点和边的定义都符合逻辑和图的规则。"""passdef compile(self, checkpointer=None, interrupt_before: Optional[Set[str]] = None, interrupt_after: Optional[Set[str]] = None, debug: bool = False) -> 'Graph':"""编译图,确认图的结构合法且可执行后,准备图以供执行。"""pass 从源码中可以看出,Graph该类提供了丰富的方法来控制图的编译和执行,使其适用于需要复杂逻辑和流程控制的应用场景。
2.2 GraphState
定义图时要做的第一件事是定义图的State。状态表示会随着图计算的进行而维护和更新上下文或记忆。它用来确保图中的每个步骤都可以访问先前步骤的相关信息,从而可以根据整个过程中积累的数据进行动态决策。这个过程通过状态图StateGraph类实现,它继承自 Graph 类,这意味着 StateGraph 会使用或扩展基类的属性和方法。
from collections import defaultdict
from typing import Any, Callable, Dict, Optional, Set, Tuple, Type, Unionclass StateGraph(Graph):"""StateGraph 是一个管理状态并通过定义的输入和输出架构支持状态转换的图。"""def __init__(self, state_schema: Optional[Type[Any]] = None, config_schema: Optional[Type[Any]] = None) -> None:super().__init__()self.state_schema = state_schema # 一个可选的类型参数,定义图状态的结构。这是用于定义和验证图中节点处理的状态数据的模式。self.config_schema = config_schema # 一个可选的类型参数,用于定义配置的结构。这可以用于定义和验证图的配置参数。self.nodes: Dict[str, Any] = {} # 一个字典,用于存储图中的节点。每个节点可以关联特定的动作和其他数据。self.edges: Set[Tuple[str, str]] = set() # 一个集合,存储图中所有的边。每条边由一对字符串组成,表示从一个节点到另一个节点的连接。self.branches: defaultdict = defaultdict(dict) # 一个默认字典,用于管理节点间的条件分支。这使得从一个节点基于某些条件跳转到不同的节点成为可能。def add_node(self, node: Union[str, Callable], action: Optional[Callable] = None, *, metadata: Optional[Dict[str, Any]] = None) -> 'StateGraph':"""向图中添加一个新节点。节点可以是一个具名字符串或一个可调用对象(如函数), 如果node是字符串,则action应为与节点关联的可调用动作。"""passdef add_edge(self, start_key: str, end_key: str) -> 'StateGraph':"""在图中添加一条边,连接两个节点。"""passdef compile(self) -> 'CompiledStateGraph':"""编译图,将其转换成可运行的形式。包括验证图的完整性、预处理数据等。"""pass- 什么是图的模式
默认情况下,StateGraph使用单模式运行,这意味着在图中的任意阶段都会读取和写入相同的状态通道,所有节点都使用该状态通道进行通信。除此之外,在某些情况下如果希望对图的状态有更多的控制,比如:
- 内部节点可以传递图的输入/输出中不需要的信息。
- 对图使用不同的输入/输出模式。例如,输出可能仅包含单个相关输出键。
LangGraph的底层实现上提供了多种不同图模式的支持,这可以通过state_schema来进行灵活的指定。
首先来看图的单模式。任何模式都包含输入和输出,输入模式需要确保提供的输入与预期结构匹配,而输出模式根据定义的输出模式过滤内部数据以仅返回相关信息。而这个预期结构的校验,由TypedDict工具来限定。
- TypeDict
TypedDict 是 Python 类型注解系统中的一个工具,它允许为字典中的键指定期望的具体类型。在 Python 的 typing 模块中定义,通常用于增强代码的可读性和安全性,特别是在字典对象结构固定且明确时。示例代码如下:
from typing import TypedDictclass Contact(TypedDict):name: stremail: strphone: strdef send_email(contact: Contact) -> None:print(f"Sending email to {contact['name']} at {contact['email']}")# 使用定义好的 TypedDict 创建字典
contact_info: Contact = {'name': 'Alice','email': 'alice@example.com','phone': '123-456-7890'
}send_email(contact_info)Sending email to Alice at alice@example.com 在这个示例中,Contact 类型定义了三个必须的字段:name,email,和 phone,每个字段都是字符串(Str)形式。当创建 contact_info 字典时,必须提供所有这些字段。函数 send_email 则利用这个类型安全的字典进行操作。这样的 TypedDict 使用场景非常适合那些需要确保字典中具有特定字段和类型的应用场景,如处理从外部API返回的数据或者在内部各个模块间传递复杂的数据结构,因为在LangGraph图中,每个节点传递到下一个节点的数据,将直接影响到下一个节点能否顺利执行。
接下来我们在LangGraph中通过Typedict定义单输入输出模式。首先,需要安装所需的依赖包,代码如下:
pip install langgraph==0.2.35
from langgraph.graph import StateGraph
from typing_extensions import TypedDict# 定义输入的模式
class InputState(TypedDict):question: str# 定义输出的模式
class OutputState(TypedDict):answer: str# 将 InputState 和 OutputState 这两个 TypedDict 类型合并成一个字典类型。
class OverallState(InputState, OutputState):pass接下来,创建一个 StateGraph 对象,使用 OverallState 作为其状态定义,同时指定了输入和输出类型分别为 InputState 和 OutputState,代码如下:
# 明确指定它的输入和输出数据的结构或模式
builder = StateGraph(OverallState, input=InputState, output=OutputState)创建 builder 对象后,相当于构建了一个图结构的框架。接下来的步骤是向这个图中添加节点和边,完善和丰富图的内部执行逻辑。
2.3 Nodes
在 LangGraph 中,节点是一个 python 函数(sync 或async ),接收当前State作为输入,执行自定义的计算,并返回更新的State。所以其中第一个位置参数是state 。
def agent_node(state:InputState):print("我是一个AI Agent。")return def action_node(state:InputState):print("我现在是一个执行者。")return {"answer":"我现在执行成功了"}定义好了节点以后,我们需要使用add_node方法将这些节点添加到图中。在将节点添加到图中的时候,可以自定义节点的名称。而如果不指定名称,则会为自动指定一个与函数名称等效的默认名称。代码如下:
builder.add_node("agent_node", agent_node)
builder.add_node("action_node", action_node)现在有了图结构,并且图结构中也存在两个孤立的节点agent_node和action_node,接下来我们要做的事就是需要将图中的节点按照我们所期望的方式进行连接,这需要用到的就是Edges - 边。
2.4 Edges
Edges(边)用来定义逻辑如何路由以及图何时开始与停止。这是代理工作以及不同节点如何相互通信的重要组成部分。有几种关键的边类型:
- 普通边:直接从一个节点到下一个节点。
- 条件边:调用函数来确定下一个要转到的节点。
- 入口点:当用户输入到达时首先调用哪个节点。
- 条件入口点:调用函数来确定当用户输入到达时首先调用哪个节点。
同样,我们先看普通边。如果直接想从节点A到节点B,可以直接使用add_edge方法。注意:LangGraph有两个特殊的节点:START和END。START表示将用户输入发送到图的节点。使用该节点的主要目的是确定应该首先调用哪些节点。END节点是代表终端节点的特殊节点。当想要指示哪些边完成后没有任何操作时,将使用该节点。因此,一个完整的图就可以使用如下代码进行定义:
from langgraph.graph import START, ENDbuilder.add_edge(START, "agent_node")
builder.add_edge("agent_node", "action_node")
builder.add_edge("action_node", END)最后,通过compile编译图。在编译过程中,会对图结构执行一些基本检查(如有没有孤立节点等)。代码如下:
graph = builder.compile()至此,我们已经成功构建了一个完整的图结构,并准备好接收用户的请求。
2.5 Graph 的调用方法
要调用图中的方法,可以使用 invoke 方法。示例代码如下:
graph.invoke({"question":"你好"})我是一个AI Agent。
我现在是一个执行者。
{'answer': '我现在执行成功了'}
graph.invoke({"question":"今天的天气怎么样?"})我是一个AI Agent。
我现在是一个执行者。
{'answer': '我现在执行成功了'}
在这个过程中,我们将state: InputState作为输入模式传递给agent_node,在传递到action_node,最后由action_node传递到END节点。节点之间通过边是已经构建了完整的通路,那么如果我们想要传递每个节点的状态信息,则可以稍加修改即可实现。对于图模式,我们的定义方法如下:
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
from langgraph.graph import START, END# 定义输入的模式
class InputState(TypedDict):question: str# 定义输出的模式
class OutputState(TypedDict):answer: str# 将 InputState 和 OutputState 这两个 TypedDict 类型合并成一个更全面的字典类型。
class OverallState(InputState, OutputState):passdef agent_node(state: InputState):print("我是一个AI Agent。")return {"question": state["question"]}def action_node(state: InputState):print("我现在是一个执行者。")step = state["question"]return {"answer": f"我接收到的问题是:{step},读取成功了!"}# 明确指定它的输入和输出数据的结构或模式
builder = StateGraph(OverallState, input=InputState, output=OutputState)# 添加节点
builder.add_node("agent_node", agent_node)
builder.add_node("action_node", action_node)# 添加便
builder.add_edge(START, "agent_node")
builder.add_edge("agent_node", "action_node")
builder.add_edge("action_node", END)# 编译图
graph = builder.compile()执行调用:
graph.invoke({"question":"今天的天气怎么样?"})我是一个AI Agent。
我现在是一个执行者。
{'answer': '我接收到的问题是:今天的天气怎么样?,读取成功了!'}
graph.invoke({"question":"你好,我用来测试"})我是一个AI Agent。
我现在是一个执行者。
{'answer': '我接收到的问题是:你好,我用来测试,读取成功了!'}
不同节点间能够传递信息的原因是因为节点可以写入图状态中的任何状态通道。图状态是初始化时定义的状态通道的并集,而我们定义的状态通道包含了OverallState以及过滤器InputState和OutputState 。
3. 使用LangGraph构建大模型的问答流程
在上面的示例中,我们通过使用打印函数来初步了解LangGraph构建图的基本方法和机制。接下来,我们将探索如何将大模型集成至LangGraph框架中,从而构建一个更具实际应用价值的用于问答流程的图模式。
首先,LangGraph对目前主流的在线或者开源模型均支持接入,所以大家可以在该框架下非常便捷的应用到自己偏爱的大模型来进行问答流程的构建。这下面的示例中,我们选择比较方便且高效的LangChain框架,同时使用OpenAI的GPT模型来进行案例实现。而关于LangChain支持接入的模型列表及方式,大家可以在LangChain Docs中查阅:Chat models | 🦜️🔗 LangChain 或者 LLMs | 🦜️🔗 LangChain 。
这里仍然需要首先定义图模式,代码如下:
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
from langgraph.graph import START, END# 定义输入的模式
class InputState(TypedDict):question: str# 定义输出的模式
class OutputState(TypedDict):answer: str# 将 InputState 和 OutputState 这两个 TypedDict 类型合并成一个更全面的字典类型。
class OverallState(InputState, OutputState):pass使用OpenAI的GPT模型需要使用到ChatOpenAI方法,我们需要将其定义到Agent节点中,用来接收用户输入的问题,调用GPT模型来根据用户的问题生成自然语言的回复响应。代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplateimport getpass
import osif not os.environ.get("OPENAI_API_KEY"):os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")def llm_node(state: InputState):messages = [("system","你是一位乐于助人的智能小助理",),("human", state["question"])]llm = ChatOpenAI(model="gpt-4o",temperature=0,)response = llm.invoke(messages) return {"answer": response.content}构建图,添加节点和边,并进行图结构的编译。完整代码如下所示:
# 明确指定它的输入和输出数据的结构或模式
builder = StateGraph(OverallState, input=InputState, output=OutputState)# 添加节点
builder.add_node("llm_node", llm_node)# 添加便
builder.add_edge(START, "llm_node")
builder.add_edge("llm_node", END)# 编译图
graph = builder.compile()进行测试:
graph.invoke({"question":"你好,我用来测试"}){'answer': '你好!如果你有任何问题或需要帮助,请随时告诉我。'}
final_answer = graph.invoke({"question":"你好,我用来测试"})print(final_answer["answer"])你好!如果你有任何问题或需要帮助的地方,请随时告诉我。
final_answer = graph.invoke({"question":"你好,请你详细的介绍一下你自己"})print(final_answer["answer"])你好!我是一个由人工智能驱动的虚拟助手,旨在帮助你获取信息、回答问题和提供建议。我可以处理各种主题,包括但不限于科技、科学、历史、文化、日常生活等。我通过自然语言处理技术理解和生成文本,以便与你进行交流。 我的设计目标是提供准确、有用的信息,并尽量以清晰、简洁的方式呈现。我没有个人意识或情感,但我会尽力理解你的需求并提供帮助。 如果你有任何问题或需要帮助的地方,请随时告诉我!
更进一步地,如果想在原有的图结构中构建更复杂的功能,则只需要新定义一个Python函数,并按照自己的预期流程用边来建立连接,如下代码所示:
from langgraph.graph import StateGraph
from typing_extensions import TypedDict, Optional
from langgraph.graph import START, END# 定义输入的模式
class InputState(TypedDict):question: strllm_answer: Optional[str] # 表示 answer 可以是 str 类型,也可以是 None# 定义输出的模式
class OutputState(TypedDict):answer: str# 将 InputState 和 OutputState 这两个 TypedDict 类型合并成一个更全面的字典类型。
class OverallState(InputState, OutputState):pass我们定义了一个action_node节点,用来接收llm_node的输出,将其翻译成中文,如下代码所示:
def llm_node(state: InputState):messages = [("system","你是一位乐于助人的智能小助理",),("human", state["question"])]llm = ChatOpenAI(model="gpt-4o",temperature=0,)response = llm.invoke(messages) return {"llm_answer": response.content}def action_node(state: InputState):messages = [("system","无论你接收到什么语言的文本,请翻译成法语",),("human", state["llm_answer"])]llm = ChatOpenAI(model="gpt-4o",temperature=0,)response = llm.invoke(messages) return {"answer": response.content}构建图,添加节点和边,并进行图结构的编译。
# 明确指定它的输入和输出数据的结构或模式
builder = StateGraph(OverallState, input=InputState, output=OutputState)# 添加节点
builder.add_node("llm_node", llm_node)
builder.add_node("action_node", action_node)# 添加便
builder.add_edge(START, "llm_node")
builder.add_edge("llm_node", "action_node")
builder.add_edge("action_node", END)# 编译图
graph = builder.compile()final_answer = graph.invoke({"question":"你好,请你详细的介绍一下你自己"})print(final_answer["answer"])Bonjour ! Je suis un assistant virtuel alimenté par l'intelligence artificielle, conçu pour vous aider à obtenir des informations, répondre à vos questions et fournir des conseils. Je peux vous assister dans diverses tâches, telles que la recherche d'informations, la résolution de problèmes, la fourniture de ressources d'apprentissage, l'aide à la planification de votre emploi du temps, etc. Mon objectif est d'améliorer votre efficacité et votre commodité.
当深入理解了LangGraph的底层原理及其图结构构建的逻辑后,我们是可以明显感受到其相较于LangChain中的AI Agent架构,展现出了更高的灵活性和扩展性。在LangGraph中,我们可以在各个Python函数中定义节点的核心逻辑,并通过边来确定输入与输出模式。此外,节点函数在定义时还可以自主构建中间状态的信息。尽管在本示例中我们使用LangChain来接入大模型,但通过节点函数的定义逻辑来看,我们当然也可以完全不依赖LangChain,而采用原生方法进行接入。
由此可见,虽然LangGraph是基于LangChain的表达式语言构建的,但它完全可以脱离LangChain而独立运行。