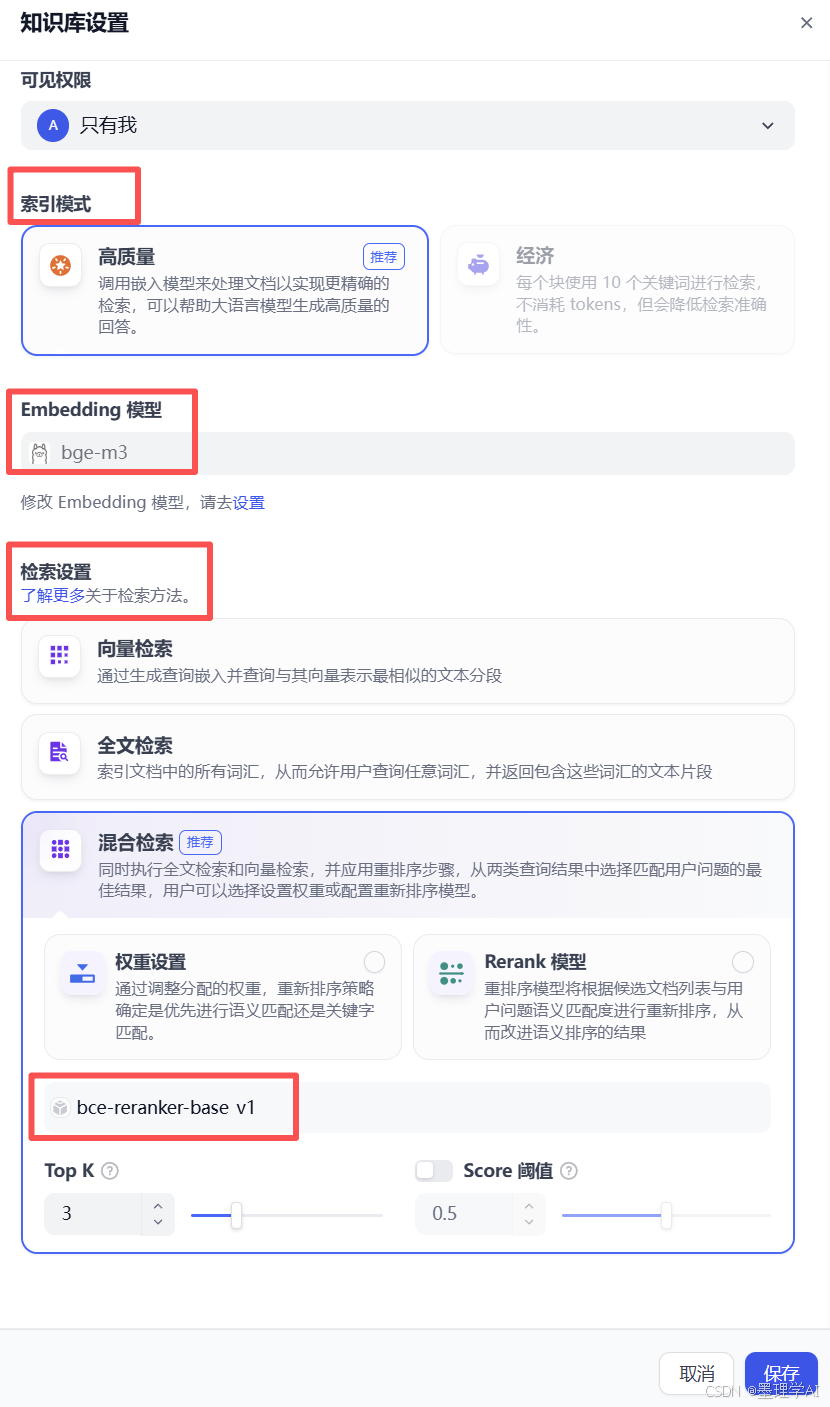
dify 中创建知识库:Embedding 模型 和 Rerank 模型作用分析
Dify 中为知识库模型选择:
- Embedding 模型:
BGE-M3 - Rerank 模型:
bce-reranker-base_v1
这是一个非常先进且合理的组合,尤其适合中文场景下的高精度语义检索。下面我为你详细解析这两个模型在知识库检索流程中的分工、作用与协同机制。
🔍 一、整体检索流程(RAG 架构)
在 Dify 的知识库中,一次典型的检索过程分为两个阶段:
用户提问↓
1️⃣ 【Embedding 阶段】 → 从向量库中快速召回 Top-K 相关文档片段(如 Top 10)↓
2️⃣ 【Rerank 阶段】 → 对这 Top-K 片段重新精细排序,选出最相关的 Top-N(如 Top 3)↓
送入 LLM 生成答案
✅ Embedding 负责“快而广”的初筛,Rerank 负责“准而精”的重排。
🧠 二、BGE-M3:Embedding 模型的作用
✅ 模型简介
- 全称:BGE-M3(BAAI General Embedding - Multi-Lingual, Multi-Function, Multi-Granularity)
- 由 智谱 AI(Zhipu AI)与北京智源 联合发布
- 支持 100+ 语言,特别优化了中文表现
- 同时支持 dense(稠密) + sparse(稀疏) + colbert(多向量) 三种检索模式
🔧 在知识库中的作用
-
文档向量化
- 当你上传 PDF/Word/Markdown 时,Dify 会将其切分为文本块(chunks)
- 每个 chunk 通过
BGE-M3转为一个 高维向量(embedding) - 存入向量数据库(如 Weaviate / Qdrant)
-
用户问题向量化
- 用户提问时,问题也通过
BGE-M3转为向量
- 用户提问时,问题也通过
-
相似度检索(ANN Search)
- 在向量库中快速查找与问题向量最相似的 Top-K 文档块
- 使用 余弦相似度 或 内积 计算
✅ 优势
- 中文理解极强:在 C-MTEB 中文榜单长期排名第一
- 多粒度支持:可处理短句、段落、长文档
- 高召回率:即使问题表述与原文差异大,也能召回相关片段
⚠️ 但 Embedding 检索是“近似匹配”,可能召回语义相关但不精准的内容(如主题相关但细节不符)。
🎯 三、bce-reranker-base_v1:Rerank 模型的作用
✅ 模型简介
- 全称:BCE Reranker Base v1
- 同样由 智谱 AI 开发,专为中文 RAG 优化
- 基于 Cross-Encoder 架构(比 Embedding 的 Bi-Encoder 更精准)
🔧 在知识库中的作用
- 接收 Embedding 阶段召回的 Top-K 文档(如 10 个)
- 对每个(问题, 文档)对进行精细打分
- 不是单独编码问题和文档,而是联合输入到模型中:
[CLS] 用户问题 [SEP] 候选文档片段 [SEP] - 模型输出一个 相关性分数(0~1)
- 不是单独编码问题和文档,而是联合输入到模型中:
- 按分数重新排序,选出 Top-N(如 3 个)最相关的片段送入 LLM
✅ 优势
- 精度大幅提升:能识别细微语义差异(如“灭火” vs “防火”)
- 抑制噪声:过滤掉 Embedding 阶段误召回的“伪相关”内容
- 提升问答准确性:LLM 只看到最相关的上下文,减少幻觉
💡 举例:
用户问:“机舱油类火灾用什么灭火器?”
- Embedding 可能召回:
- A. “机舱火灾处理流程”(泛泛而谈)
- B. “泡沫灭火器适用于油类火灾”(精准)
- Rerank 会给 B 更高分,确保 LLM 优先使用 B 生成答案。
🤝 四、两者协同:为什么需要“Embedding + Rerank”?
| 对比项 | 仅用 Embedding | Embedding + Rerank |
|---|---|---|
| 速度 | ⚡ 极快(毫秒级) | 稍慢(需额外推理) |
| 精度 | 中等(可能误召) | ✅ 高(精细排序) |
| 资源消耗 | 低 | 中(Rerank 需 GPU/CPU 推理) |
| 适用场景 | 简单问答、高并发 | 专业问答、高准确率要求 |
✅ 你的选择(BGE-M3 + BCE Reranker)是目前中文 RAG 的 SOTA(State-of-the-Art)组合,兼顾广度与精度。
⚙️ 五、在 Dify 中的配置建议
- Embedding Top-K:建议设为 5~10(给 Rerank 足够候选)
- Rerank Top-N:建议设为 2~3(避免 LLM 上下文过长)
- 模型部署:
- 如果本地有 GPU,可将两个模型都本地部署(通过 Ollama / vLLM / Dify 内置支持)
- 若无 GPU,Dify 也支持调用云端 API(如硅基流动、智谱 API)
📊 性能参考(C-MTEB 中文榜单)
| 模型 | 类型 | MTEB-CN 排名 |
|---|---|---|
| BGE-M3 | Embedding | 🥇 第 1 名 |
| bce-reranker-base_v1 | Reranker | 🥇 第 1 名 |
数据来源:C-MTEB Leaderboard
✅ 总结
| 模型 | 角色 | 核心价值 |
|---|---|---|
| BGE-M3 | 初筛召回 | 快速从海量文档中找出“可能相关”的内容 |
| bce-reranker-base_v1 | 精排重排 | 从候选中精准选出“真正相关”的内容 |
🎯 你的配置 = 中文知识库检索的黄金组合,特别适合船舶消防、技术手册、制度文档等专业领域问答。
知识库 - 索引模式 和 检索设置
一起学AI
-
❤️ 如果文章对你有些许帮助、蟹蟹各位读者大大点赞、评论鼓励博主的每一分认真创作
