C++学习记录(23)智能指针
一、为什么要设计出智能指针
1.场景复现
在学习异常时,我们遇到了这样的一段代码;
double Divide(int a, int b)
{try{// 当b == 0时抛出异常if (b == 0){string s("Divide by zero condition!");throw s;}else{return ((double)a / (double)b);}}catch (const int& s){cout << s << endl;}return 0;
}void Func()
{int* arr1 = new int[10];try{int len, time;cin >> len >> time;cout << Divide(len, time) << endl;}catch (...){cout << "delete []" << arr1 << endl;delete[] arr1;throw; // 异常重新抛出,捕获到什么抛出什么}cout << "delete []" << arr1 << endl;delete[] arr1;
}int main()
{try{Func();}catch (const string& str){cout << str << endl;}catch (...){cout << "未知异常" << endl;}return 0;
}这段代码的逻辑是这样的:
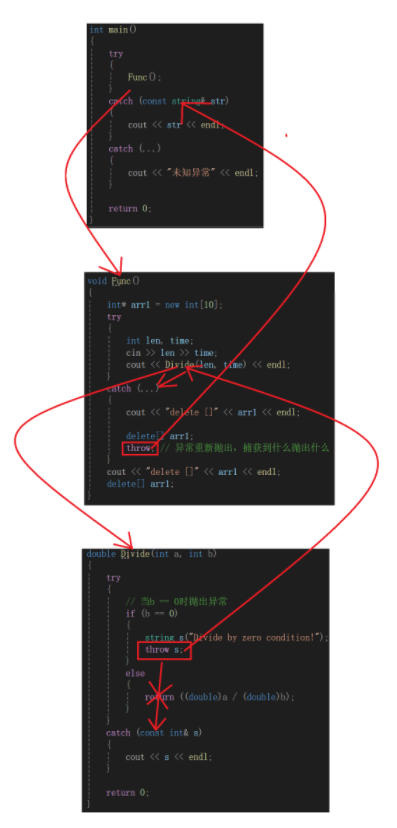
图左侧是函数调用链,右侧是抛出异常后的查找机制
当除数等于0时,运算是异常的,所以需要抛出异常,在Divide函数并没有找到匹配的catch语句,因此将会终止Divide函数,沿着调用链向上查找;
在Func函数中,基本逻辑是这样的,动态申请new了一个10个int的数组,随后才进行了Divide函数的调用,如果没有:

那么new出来的内存出了局部域并没有被delete,同时我们并没有说将它归给谁出了函数以后还能继续管理,那么这里就造成了内存的泄露,你又用不着又不释放。
之后重新抛出异常,继续去外层找catch语句。
在main函数中匹配到并进行了相应处理。
2.隐藏问题
void Func()
{int* arr1 = new int[10];int* arr2 = new int[10];try{int len, time;cin >> len >> time;cout << Divide(len, time) << endl;}catch (...){cout << "delete []" << arr1 << endl;delete[] arr1;cout << "delete []" << arr2 << endl;delete[] arr2;throw; // 异常重新抛出,捕获到什么抛出什么}cout << "delete []" << arr1 << endl;delete[] arr1;cout << "delete []" << arr2 << endl;delete[] arr2;
}如果多加一句new。
在学习C++内存管理时学习过:
/*operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间
失败,尝试执行空
间不足应对措施,如果改应对措施用户设置了,则继续申请,否
*/
void* __CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{// try to allocate size bytesvoid* p;while ((p = malloc(size)) == 0)if (_callnewh(size) == 0){// report no memory// 如果申请内存失败了,这里会抛出bad_alloc 类型异常static const std::bad_alloc nomem;_RAISE(nomem);}return (p);
}
可以知道,new操作符底层是调用operator new + 构造函数,int内置类型咱们就当没有构造函数来看,因为构造不是关键,那int的new就是operator new,operator new是对malloc的封装,如果malloc失败,将会抛出异常,那么我们上面的Func函数中出了Divide函数可能会抛出异常外,new也可能抛出异常。
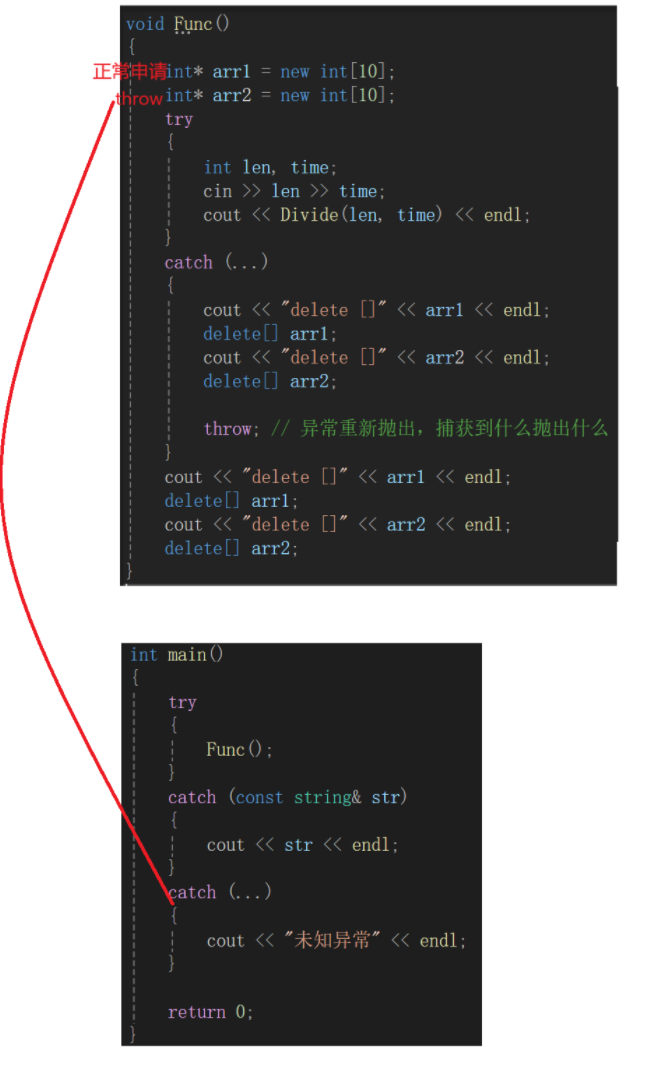
如果arr1正常申请,arr2刚好申请的时候内存干涸了,没的申请就得抛异常,但是这时候的new并没有被try-catch模块包裹,如果抛出异常,直接就干到外层main函数的catch了,这时候arr1又出现了,你既不释放,也用不到,又是内存泄露。
下意识的解决方法就是继续try-catch:
void Func()
{int* arr1 = new int[10];try{int* arr2 = new int[10];try{int len, time;cin >> len >> time;cout << Divide(len, time) << endl;}catch (...){cout << "delete []" << arr1 << endl;delete[] arr1;cout << "delete []" << arr2 << endl;delete[] arr2;throw; // 异常重新抛出,捕获到什么抛出什么}cout << "delete []" << arr1 << endl;delete[] arr1;cout << "delete []" << arr2 << endl;delete[] arr2;}catch (const exception& e){delete[]arr1;throw;}
}
那你new一层就try-catch一层呗,这样就可以释放已经申请的,并且最外层main:
int main()
{try{Func();}catch (const string& str){cout << str << endl;}catch (const exception& e){cout << e.what() << endl;}catch (...){cout << "未知异常" << endl;}return 0;
}
加一层捕捉。
但是这段代码看着真是招笑啊,如果按照这个思路,我再new一个arr3岂不是还得套try-catch,我闲的没事吗,再说,就算我真愿意这么写,搞个屎山,本来是我和上帝能看懂,说不准吃个饭就变成只有上帝能看懂了,可读性差的一。
我们渴求一种方便的问题来解决异常抛出,代码提前结束,导致的内存泄露问题。
二、RAII和智能指针
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是一种思想,核心是将资源的生命周期与对象的生命周期绑定,来实现资源的自动和安全管理。
资源包括但不限于内存、文件指针、网络连接、互斥锁等等。
RAII一旦获取到资源,就将资源委托给一个对象,接着控制对资源的访问,资源在对象生命周期内始终保持有效,对象生命周期结束触发析构函数的时候就释放资源,这样保证了资源正常释放,避免资源泄露问题。
1.智能指针的框架
根据RAII的思想,我们可以设计这样的类:
template<class T>
class SmartPtr
{
public:SmartPtr(const T*& ptr):_ptr(ptr){}~SmartPtr(){delete[] _ptr;}private:T* _ptr;
};
将指针委托给一个对象,这一点在构造中体现;
对象声明周期结束自动调用析构,它最大的作用就是把指针管理的资源释放。
于是Func函数的设计就可以简化成:
void Func()
{SmartPtr<int> sp1 = new int[10];SmartPtr<int> sp2 = new int[10];int len, time;cin >> len >> time;cout << Divide(len, time) << endl;
}沿着代码看智能指针的作用就十分明确的,new出来的指针,委托给智能指针类的对象,这样对象生命周期结束,就自动调用析构,也就替我们delete。
需要注意的是,在学习异常了以后,对象生命周期的结束可不仅仅是一个函数执行完,因为讲异常的时候我们提过,throw会直接跳转到最近最匹配的catch语句中,但是底层其实是顺着调用链一个一个函数找,如果找不到直接就结束函数栈帧,这个结束往往是函数提前结束。
智能指针牛就牛在这,不管是提前结束还是正常结束,总归函数栈帧销毁都会导致对象的销毁就都会使得对象去调用析构,就会释放对应资源。
2.智能指针的完善
智能指针的一大功能就是,申请好资源交由它的对象管理,释放资源交由它的对象释放。
但是人还是不能忘本啊,申请出来的指针直接被收走了,那岂不是没办法进行指针的常规操作了,比如*p、p[]等,所以还有以下操作符重载:
template<class T>
class SmartPtr
{
public:SmartPtr(const T*& ptr):_ptr(ptr){}~SmartPtr(){delete[] _ptr;}T& operator*(){return *_ptr;}T* operator->(){return _ptr;}T& operator[](size_t i){return _ptr[i];}
private:T* _ptr;
};我们这里就是大致实现一下,operator*返回底层指针的*_ptr,operator->其实是让底层指针_ptr去->,还有operator[],不用多解释。
三、C++标准库智能指针的使用
又要像学容器一样学习智能指针的使用,因为C++标准库对于只能指针搞了一个头文件<memory>:<memory> - C++ Reference
有这样几种指针,只学习实践中最实用的即可。
C++98
1.auto_ptr
这个指针读库里的文档真是给我看笑了,文档是这样的:

其实我也没太在意,就跟以前学习容器一样,大致读一读,重方法的调用,结果上来看见个:

还真没见过库里面哪个描述这么整的,我又不认识这个deprecated,结果一搜:

我得发,强烈反对,C++11以后就不赞成用了。
我本来还纳闷呢,中间的话大致就是智能指针的通用功能,什么你可以把指针给它,让它替你管理,当对象销毁是内存就释放啥的,感觉也就是正常智能指针,没看出来有什么特别。
最后一段我才明白为什么:

最近做六级题给我搞应激了,看见therefore下意识感觉有重要的事,结果一看,大致意思就是啥吧,两个auto_ptr不可能管理同一个_ptr,也就是:
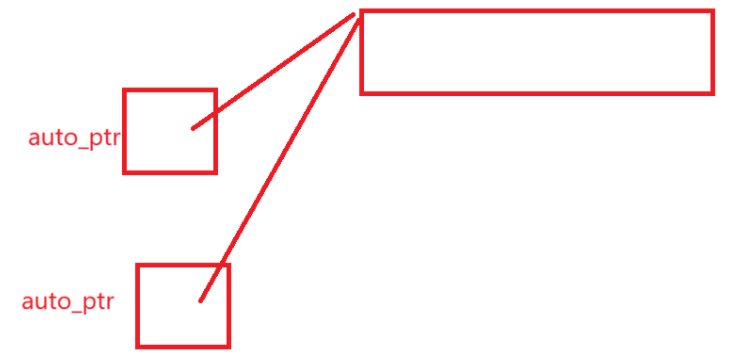
上图所示的,智能指针的管理是不被允许的。
读完我大致查了查,auto_ptr设计的时候对拷贝没有考虑,正常你用它* ->都没啥毛病,但是你一旦:
auto_ptr ap1(new int);
auto_ptr ap2(ap1);
到时候ap1销毁会对底层指针释放一次,ap2销毁会对底层指针释放一次,那这确实太扯了,一块空间被连续delete,或者说被连续free,这种行为定义了吗?
我们学的free可以释放动态申请的内存的指针,free可以释放空指针,只不过什么都不做,其它行为一概不知。
但是吧,还是语言设计的特点,一个语法标准设计出来,肯定编译器就会去实现,实现了就有人会用,所以不能随便删,可以说相当于一个污点留在标准库里了。
测试:

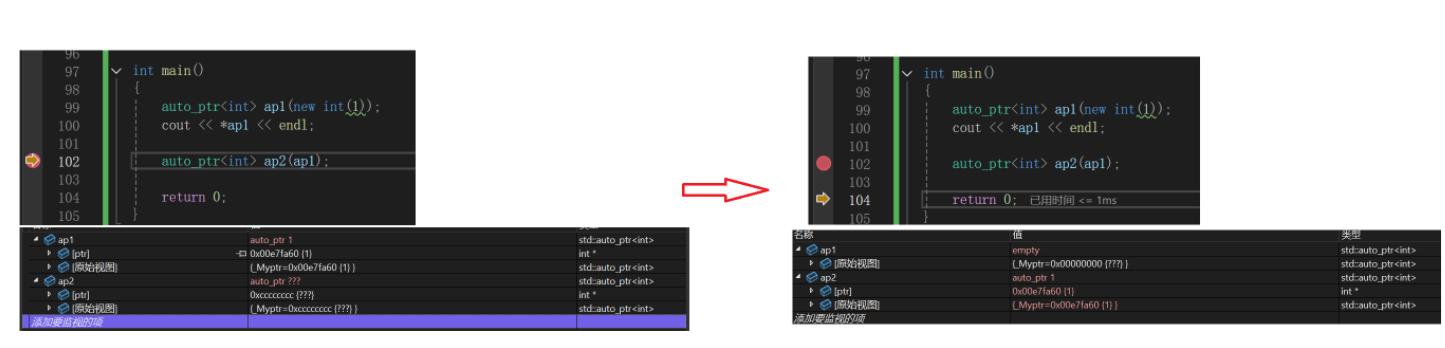
搞了点测试代码,正常自己用没毛病,但是一旦想给别人,可以看到原智能指针直接被置空了,其实也好想,如果有两份不就delete两次,但是这样搞拷贝构造,ap1岂不是直接废了,但是拷贝构造的理想应当是管理同一片啊,因为正常指针间赋值不就是同时管理同一片,这个时候用ap1就很危险了。
说这么多,大致了解auto_ptr为啥不让用就算了,其它没必要多学,一是用不上,二是智能指针好几种,接口设计的差不多,我们直接学用的多的智能指针接口就可以兼顾到了。
![]()
另外就是这个也不多说了,看一眼描述就不管了,auto_ptr的引用,引用相当于别名嘛,还是auto_ptr,我又不用,所以学了也没必要。
C++11
auto_ptr那两个都是C++98设计出来的,以下我们学习的指针都是C++11标准的产物。
2.unique_ptr
①特性
上面查auto_ptr的时候,大致也看了看C++11那几个指针,大致上感觉先说这个好一点。
unique_ptr最大的特点就是unique,说来也巧,今天刚好背了:
unique有独特的意思,也有唯一的意思,所以这里取的意思就是“唯一”,意味着它管理的指针只能有一份,别人拿不了。

库里面差不多也是这么描述的,只能让它自己管理其它智能指针谁都别想动。
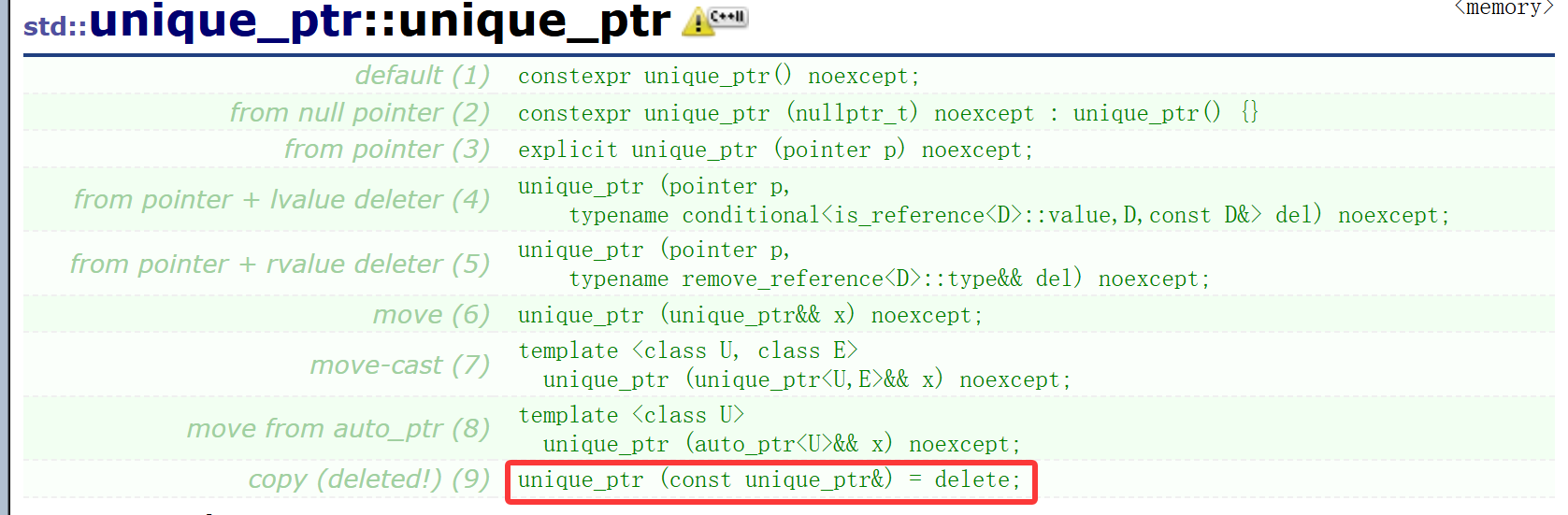
最明显的特点就是根本不让拷贝,谁都别想偷偷拿去。
这就从根上直接杜绝了问题,我们自己写的智能指针的拷贝很垃圾,会对一块空间释放两次;auto_ptr会转移走指针的管理权,空指针再被调用* ->很危险,直接会导致程序崩溃。
因为现在不让拷贝了。
unique_ptr的特性是不支持拷贝,只支持移动
②构造
其实大致上了解两个构造即可,原因如下:

搞个这默认构造有啥用,还有用nullptr,能搞出来智能指针那一定定的有资源需要管理,所以一定得:
![]()
不然闲的没事搞智能指针干嘛。
并且在auto_ptr我就注意到了这个:
![]()
不能搞隐式类型转换,所以搞unique_ptr只能:
unique_ptr<int> up(new int(1));
不能:
unique_ptr<int> up = new int(1);
因为不支持隐式类型转换,你这么搞过不去。
再来就是:
![]()
它不支持隐式类型转换的话,等于最多能用:
unique_ptr<int> up1(unique_ptr(new int(1)));
unique_ptr<int> up2(move(up1));
失去隐式类型转换,走不了临时对象右值构造就少灵魂了,上面这写的真拉,还不如直接构造。
③operator*、operator->、operator[]
关于operator*、operator->、operator[]就不演示了,没搞头。
④get

拿到底层的_ptr。
而且这个函数还有点小说法。
⑤release和reset
release

不是容器了,设置的接口还怪有意思。
release是什么呢?
释放所有权,不管底层存的指针了,但是呢会给你作为返回值返回,特别符合release的释放的意思,因为就好像不再拴着管着了,放养。
并且底层unique_ptr置为空。
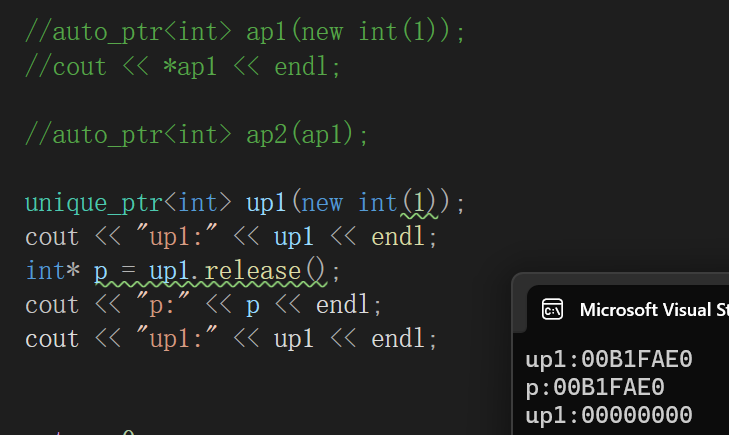
release的结果是这个我不多说了,主要研究这个cout。
我刚开始抱着试一试的心态去cout,结果直接cout给的就是底层指针,我下意识瞅了一眼库:
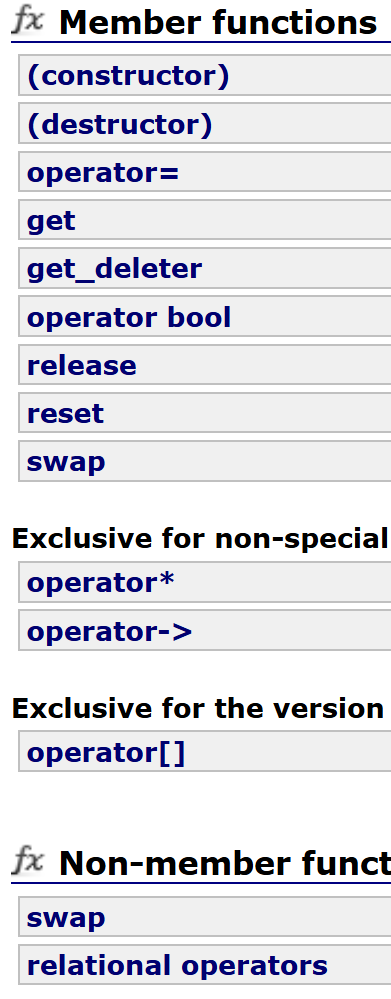
根本没有operator<<重载啊,为啥能进行,而且输出的还是底层的_ptr。
然后我就查了查,其实先问的ai,大致就是底层get方法不是没有explicit修饰嘛,所以支持隐式类型转换,底层operator<<重载了:operator<<(const void*)所以如果隐式类型转换成指针就能cout了。
我主要惊奇于这样的隐式类型转换,因为我们以前了解的大概是:
string(const char* c);
string = "Hello World";
如果跟构造函数对上且对应的构造函数没有explicit修饰就可以隐式类型转换成自定义对象。
但是这里相当于:
pointer get();
unique_ptr.get();
由自定义对象转换成内置类型对象了,奇奇怪怪的个人感觉。
reset
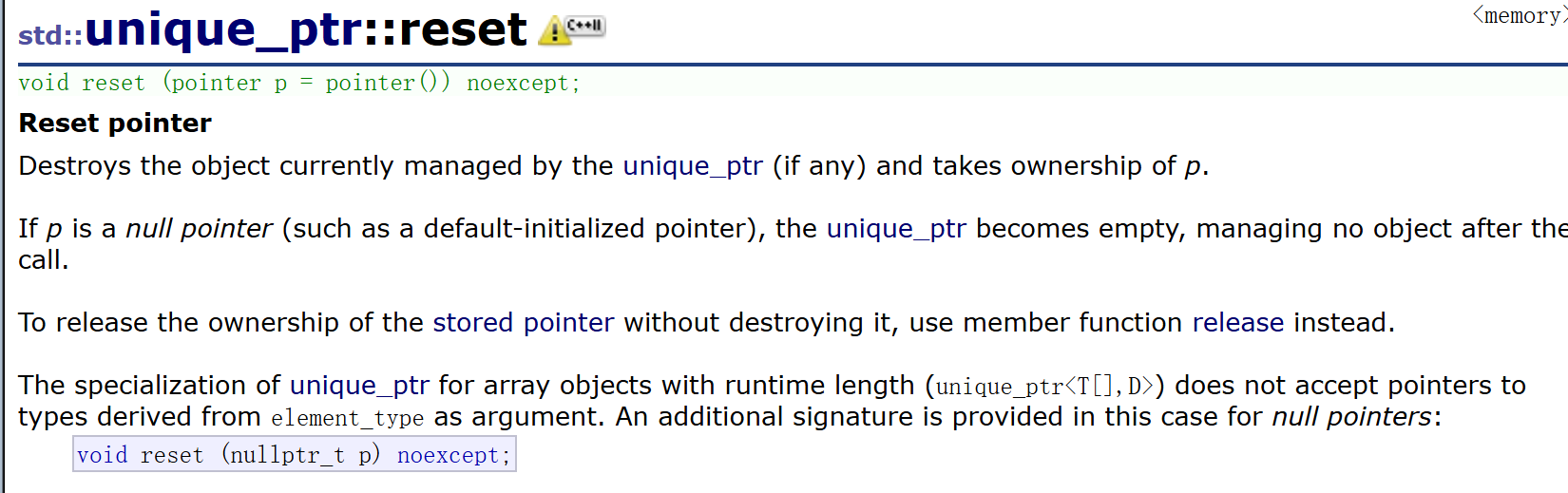
有点小区别吧,reset直接把底层指针管理的资源释放,并且把unique_ptr指向改变。
如果是:
reset();
reset(nullptr);
都是释放底层指针以后再搞成底层指针为空指针;
如果是:
reset(ptr);
那先释放原来的底层指针,再存ptr。
简单的测试代码可以看出:
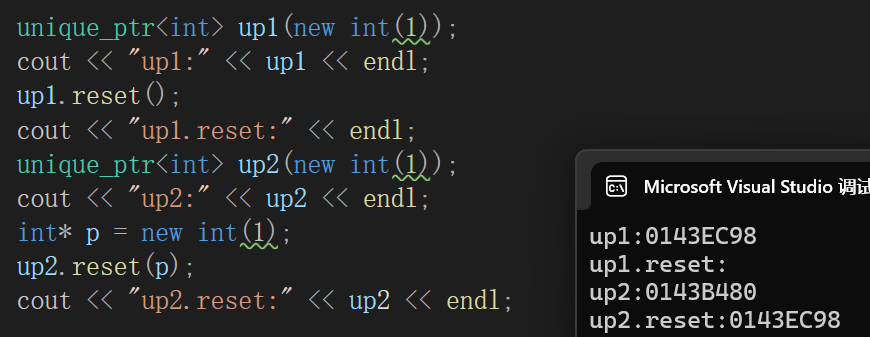
⑥operator bool
这个重载有点不一样,我们之前学习的operator*、operator->、operator[]、operator<<等等,都是运算符重载,也就是让我们写了重载的类型的对象可以用这个操作符实现操作,底层转换为成员函数的调用。
但是operator bool的作用不是重载运算符,而是类型的转变,当我们看到unique_ptr的对象时候,可以当成一个bool表达式看待,因为正常的指针,nullptr的布尔值为false,而非空指针的布尔值为true,所以呢operator bool就是为了智能指针能跟普通普通指针一样作为布尔表达式使用。

库里面的描述也代表了这一点。
测试:
确实跟普通指针一样。
3.shared_ptr
①特性
其他特性和只能指针一样,他最大的特点是:
shared_ptr不仅支持拷贝,还支持移动
那么到底为什么shared_ptr就可以拷贝数据呢?难道它就不怕对一个指针多次释放的问题吗?
shared_ptr底层原理是引用计数。
大致意思就是,有几个智能指针底层管理同一个指针,底层计数就有几个,析构的时候前几个都不释放指针,直到最后一个释放的时候才释放。
怎么引用计数呢?
你想吧,拷贝的时候引用计数++,赋值的时候引用计数++,移动的时候不变就行了呗。
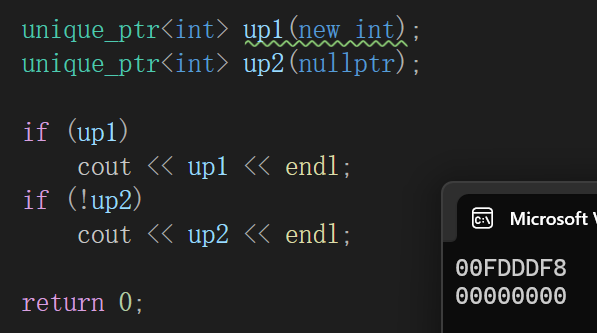
这玩意还会有个禁忌,因为底层拷贝和赋值的时候才能计数,所以就有:
如果不让他正经走拷贝和赋值,引用计数不会正常++,就还是会出现释放多次的问题。用的时候就算想让智能指针管理同一片也得:
②构造
还是说,记住想用谁的指针,直接传就行,其它的接口说实话,记住不记住没啥区别。
拷贝能用到但是不用记,其它一般也不用,因为智能指针最大作用就是委托指针,替我们释放。
③与unique_ptr相同接口不再讲述
reset、get、operator*、operator->、operator[]、operator bool
④use_count
这个接口返回的就是底层引用计数的个数:

⑤owner_before
这个接口比较麻烦,刚开始我读文档都不知道是干啥的,看了眼库里的例子:
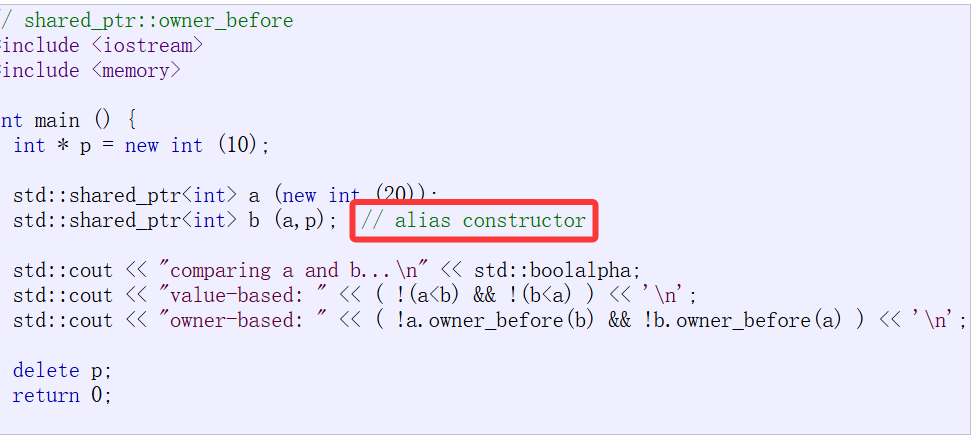
跟这个构造有关系,我就又返回头去找这个接口:
![]()
明确昂,x是个智能指针对象的左值引用,p是个指针。


这描述我真是看晕了,说什么除了参数p其它跟(6)相同,我一看(6)一个拷贝构造,能给我提供鸡毛线索。
索性又耐着性子去继续读,但是这描述真说难听点,神神叨叨的:
这个对象不拥有p也不管理p指向的空间。相反它相当于x对象的拷贝,你要用release就返回x。
我就奇了怪了,整篇描述跟p没鸡毛关系,那你给我整个p参数干鸡毛。
int main()
{shared_ptr<int> sp1(new int(1));int* p = new int(10);shared_ptr<int> sp2(sp1,p);cout << sp1 << endl;cout << sp2 << endl;cout << p << endl;cout << sp1.use_count() << endl;cout << sp2.use_count() << endl;cout << *sp1 << endl;cout << *sp2 << endl;return 0;
}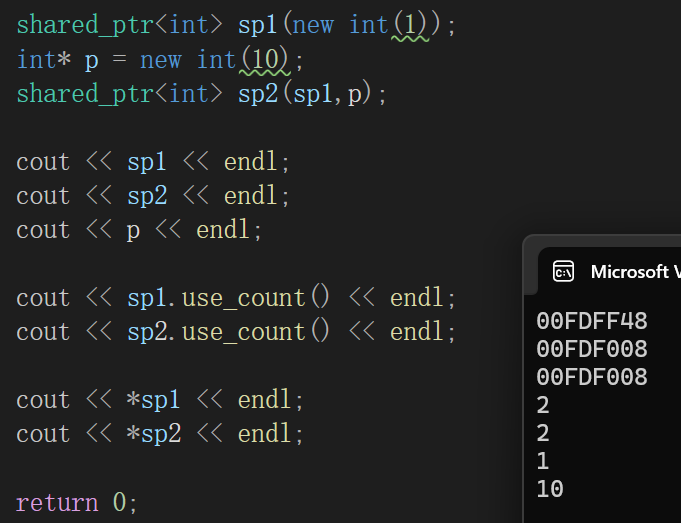
这段代码我写出来的思路是啥吧,本来我就想看看啥叫不是p也不管p的底层内存内容。
结果一cout,发现底层sp1存的是一个,sp2实质上存的是p,这一点可以从打印地址和打印底层指针指向数据看到。
问题难绷的是,sp2竟然算sp1的拷贝对象,因为引用计数++了,因为一旦把sp2的构造注释掉:
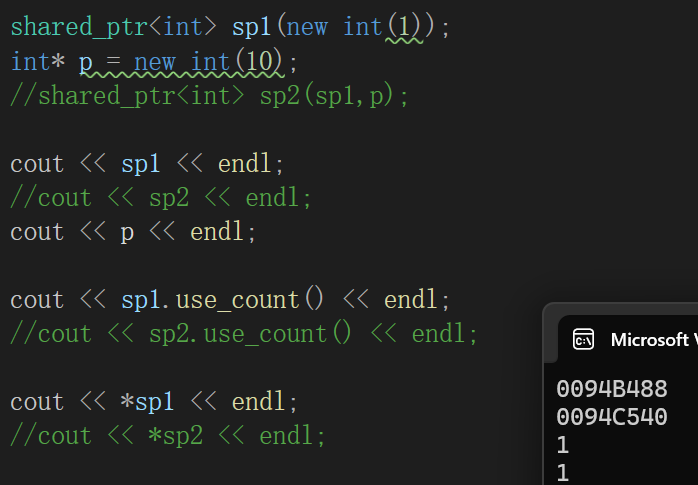
我反正是理清由上述构造函数构造出来的shared_ptr大致关系了,但是把我真想不到啥场景能用到这玩意,绕来绕去的,写出来bug都还乐呵呵的。
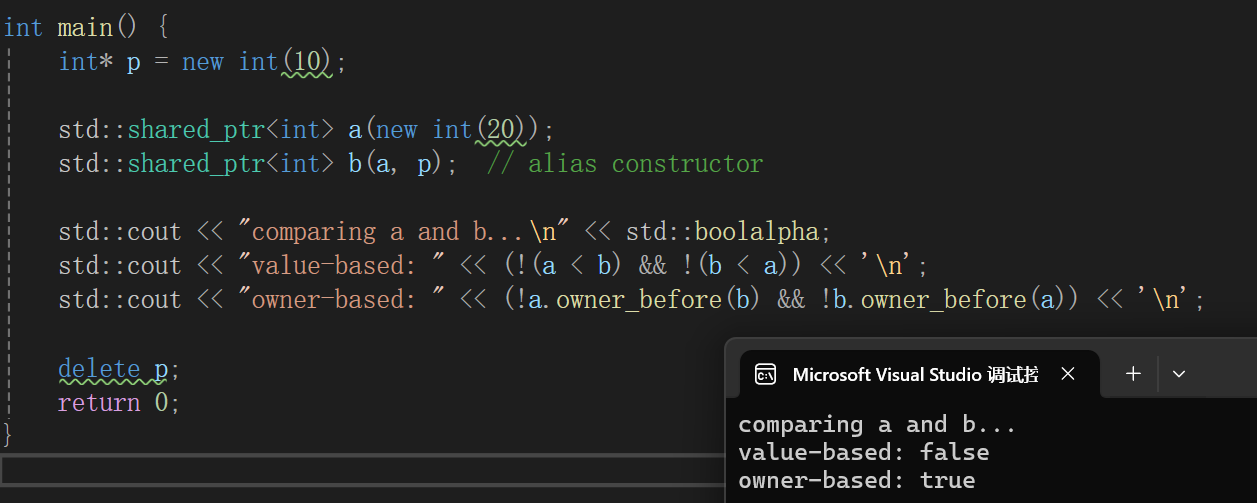
然后我拷过来库里面的测试代码,首先第一行有用的代码的意思我觉得他应该是想表达,a!=b的意思,因为a和b底层存储的指针是不一样的,假设a < b是true,取反肯定是false,另一个是false取反是true,反正不管咋样,&&以后肯定false。
第二行有用代码就是用了owner_before,再结合底层的描述昂,owner_before比较的是对象实际指向智能指针对象,毕竟有了b就让a的引用计数++了,那这样的话a < b和b < a一定是false,因为它俩相等最后结果分别取反再逻辑与就是true。
核心就是取出来实际指向的而不是存储的指针比较。
我吐槽几句,说实话,我真不知道这玩意有啥用,主要是b那个构造莫名其妙的,owner_before取的是真正指向的对象比较,其实也就是拷贝对象a,在参数确实a在前,p在后,a是实际指向的对象,p是实际存储的对象。理的我都头晕了奶奶的,太tm抽象了,了解了解,知道有这个接口算了。
4.new[]
我们上面举的例子都是new出来的,没有new[]出来的,如果是new[]出来的,得这么搞:
//unique_ptrunique_ptr<int[]> up1(new int[5]);
因为模板参数留好后门了,搞了个特化版本。
//shared_ptr
shared_ptr<int> sp1(new int[5], [](int* ptr) {delete[] ptr; });但是shared_ptr就有点抽象类,因为底层:

我还纳闷呢,为啥不能用new[],结果查了查,人家说,也支持,但是得用:

底层delete也是仿函数逻辑,所以你可以传new[],但是模板参数没留后门的情况下,你还得传底层delete[]作为delete的仿函数逻辑,这种割裂感太难受了,但是咱也没招,C++标准库这么写你能咋办。
四、模拟实现shared_ptr
1.基本框架
namespace xx
{template <class T>class shared_ptr{public:private:T* _ptr;int* _count;};
}底层_ptr就不说了,重点是怎么实现底层的引用计数呢?
我刚开始想的是就搞个整型存储,但是搞个整型我一想,到时候直接跟着对象的栈空间的,互相根本没啥关联;
再后来我就想static int,结果考虑了考虑,那岂不是整个类只能有一个智能指针了?
啥意思呢?shared_ptr<int>打着太累了,我就直接写成spi了
spi sp1(new int);
spi sp2(sp1);
spi sp3(new int);
很明显,sp1和sp2指向同一块空间,sp3自己指向一块空间,这么搞的话,他仨用的都是静态成员变量,按道理该一个2一个1,不过这么搞,到时候只能3了,所以我最后选择int*。
int*的好处在于,并不是绑死到对象上,只是在堆区找块空间计数而已,谁找他都能用,说这么多,可能不太理解,直接看我下面方法就理解了。
2.构造、析构
shared_ptr(T* ptr = nullptr):_ptr(ptr),_count(new int(1)){}~shared_ptr(){if (*_count == 1){delete _ptr;delete _count;}--(*_count);}构造就是根据实际情况写一写,搞个缺省值,兼顾默认构造又可以传值构造,不多说。
析构就有意思了,一检测底层引用计数是1再delete,其他情况就光--就行。
这么一看清晰多了吧。
3.拷贝、赋值
shared_ptr(const shared_ptr<T>& sp):_ptr(sp._ptr), _count(sp._count){++(*_count);}把东西一股脑拷贝过来,然后底层引用计数++,因为用指针存的,所以*count的变动可以使得任何与它相同的指向的智能指针的引用计数改变。
//sp1 = sp2shared_ptr<T>& operator=(const shared_ptr<T>& sp){release();_ptr = sp._ptr;_count = sp._count;(*_count)++;}private:void release(){if (*_count == 1){delete _ptr;delete _count;}--(*_count);}赋值的话,相当于把原来的指向变了,首先是原来的指向的引用计数--,现如今指向的引用计数++,又考虑到如果底层引用计数是1,被赋值以后还得释放,这段逻辑跟析构很像,所以就有以上代码。
先把原来的释放了,再赋值,引用计数也不能忘++。
4.其他操作
有了引用计数以后,最麻烦的成员函数都肝完了,我就不想废话了,因为也没啥可说的了其它的。
namespace xx
{template <class T>class shared_ptr{public:shared_ptr(T* ptr = nullptr):_ptr(ptr),_count(new int(1)){}shared_ptr(const shared_ptr<T>& sp):_ptr(sp._ptr), _count(sp._count){++(*_count);}//sp1 = sp2shared_ptr<T>& operator=(const shared_ptr<T>& sp){release();_ptr = sp._ptr;_count = sp._count;(*_count)++;}T& operator*(){return *_ptr;}T* operator->(){return get();}T* get()const{return _ptr;}int use_count(){return *_count;}T& operator[](int i){return _ptr[i];}~shared_ptr(){release();}private:void release(){if (*_count == 1){delete _ptr;delete _count;}--(*_count);}private:T* _ptr;int* _count;};
}5.测试代码
class Date
{
public:Date(int year = 1,int month = 1,int day = 1):_year(year),_month(month),_day(day){}~Date(){cout << "~Date()" << endl;}private:int _year;int _month;int _day;
};int main()
{xx::shared_ptr<Date> sp1(new Date);xx::shared_ptr<Date> sp2(sp1);xx::shared_ptr<Date> sp3(new Date);return 0;
}为了方便测试,我搞了个Date类,重点是看见析构的调用。
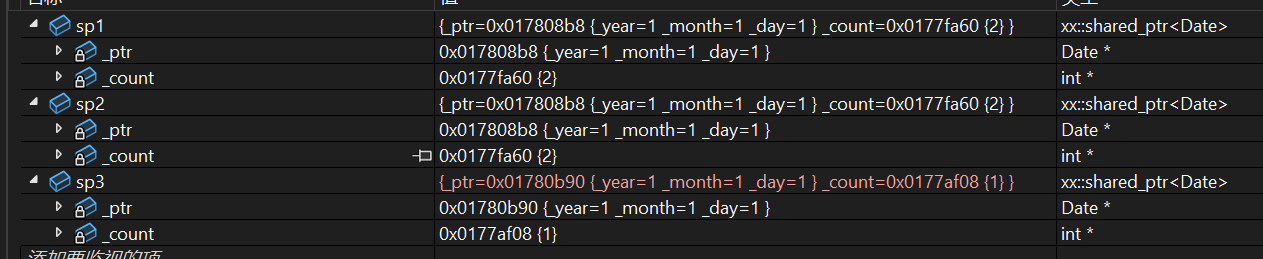
调试窗口看见的看起来没啥毛病。
并且最后确实没报错,只析构两次,因为毕竟底层只有两个真正的指针。
再来就是测试赋值:
sp1 = sp2;sp1 = sp3;sp2 = sp3;看着这测试代码,我忽然想起来,忘记如果管理的相同就不用拷贝了:
//sp1 = sp2shared_ptr<T>& operator=(const shared_ptr<T>& sp){if (_ptr != sp._ptr){release();_ptr = sp._ptr;_count = sp._count;(*_count)++;}return *this;}再来就是这个if不是拿对象比,因为拿对象比没用,必须拿底层指针比。
不仅如此,因为之前没实例化,编译器都没检查出来我没写返回值,真是的。
测试结果就不贴了,没啥毛病,第一行sp1 = sp2啥都没干,第二行第三行都进行了赋值,引用计数也改变了。
6.new[]
再来就是实现new[]版本,unique_ptr设计成模板参数可以理解,但是库里的shared_ptr不传模板参数,通过自己传仿函数实现咋弄的。
构造函数多加一个可以接受删除器,但是缺省值我给不上:
template<class D>shared_ptr(T* ptr = nullptr, D del): _ptr(ptr), _count(new int(1)), _del = del;{}缺省值给不上,那这函数就是错的,因为函数缺省值得从右往左写啊。
而且底层_del成员可给我难住了。
因为类型是函数模板的,不是整个类模板的,给我干晕了,实在没灵感,接着就学到解决方法:

直接搞个默认lambda做默认删除器就行,至于类型,直接用包装器,说实话,真是陌生。
此时构造:
template<class D>shared_ptr(T* ptr, D del): _ptr(ptr), _count(new int(1)),_del(del){}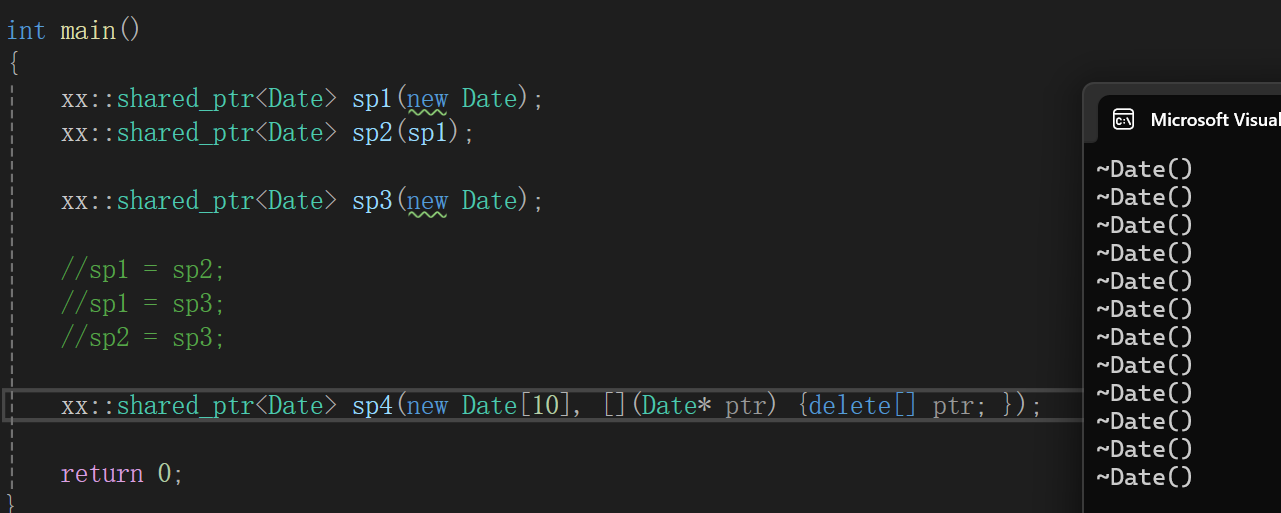
测试测试没毛病噢。
五、shared_ptr循环引用问题
shared_ptr想要安全使用,还必须知道什么是循环引用,怎么解决循环引用的问题?
1.循环引用场景
啥叫循环引用的问题呢?
看这样一个场景:
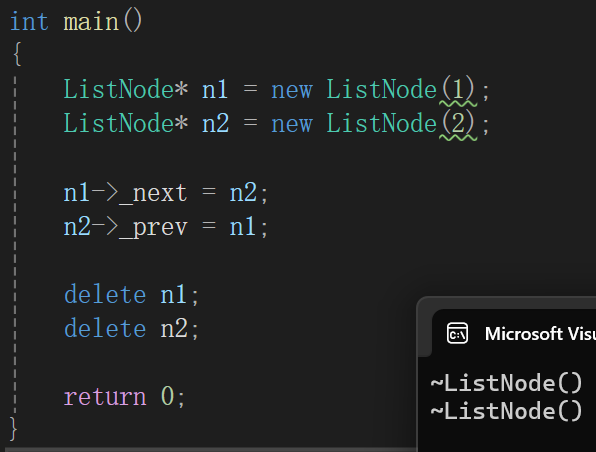
struct ListNode
{int _data;struct ListNode* _prev;struct ListNode* _next;ListNode(int data):_data(data),_prev(nullptr),_next(nullptr){}~ListNode(){cout << "~ListNode()" << endl;}
};int main()
{ListNode* n1 = new ListNode(1);ListNode* n2 = new ListNode(2);n1->_next = n2;n2->_prev = n1;delete n1;delete n2;return 0;
}这段代码的意思是链表结点,为了方便展示场景,直接写死成int的了,我们再手动链接一下,当然,只是部分链接,到下面就知道为啥只链接这俩了。
然后看到new+delete就会有一种想法,为什么不委托给智能指针管呢?
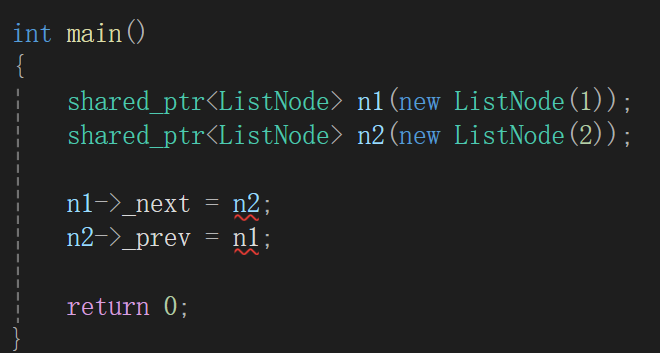
委托给智能指针管首先就得改改赋给谁,shared_ptr只能接受构造函数初始化,不能隐式类型转换。
当然,下面是有错误的,因为_next和_prev类型都是ListNode*,n1和n2都是shared_ptr,所以呢,ListNode内部也得搞成shared_ptr:
struct ListNode
{int _data;shared_ptr<ListNode> _prev;shared_ptr<ListNode> _next;ListNode(int data):_data(data),_prev(nullptr),_next(nullptr){}~ListNode(){cout << "~ListNode()" << endl;}
};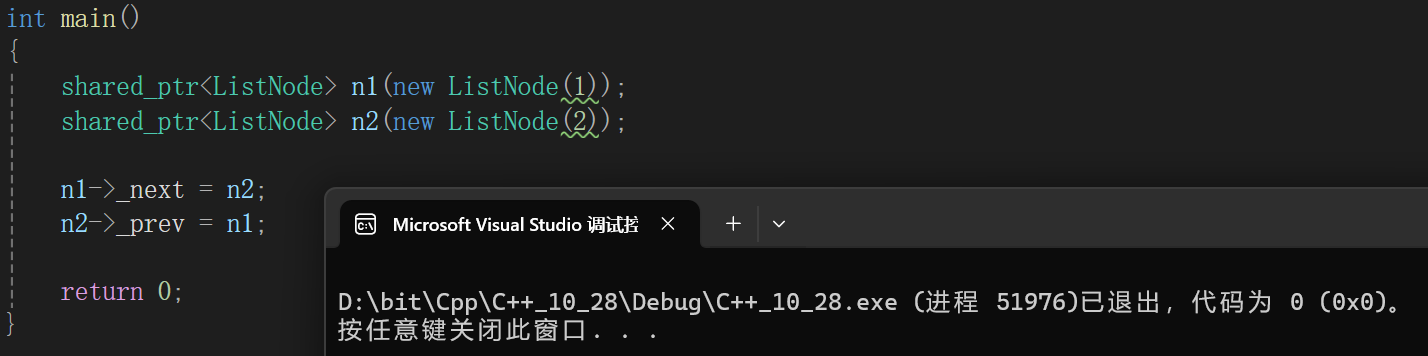
高高兴兴的写了,一运行就发现,内存泄露了,因为智能指针并没有析构,靠程序结束回收的内存,而且如果随便注释一个会发现:
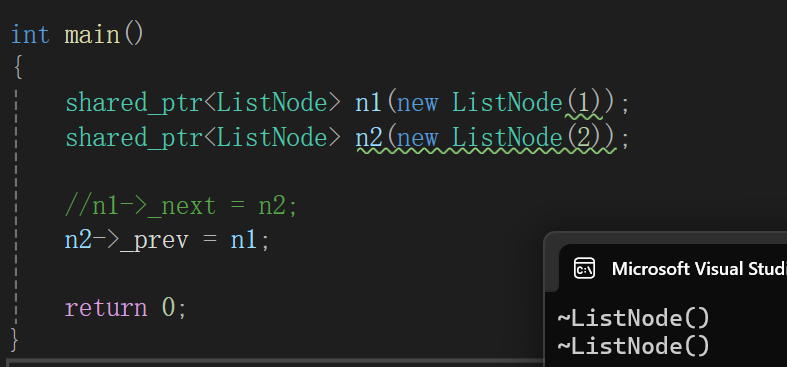
又没事了。
这就是循环引用问题,你会发现结点的结构是这样的:
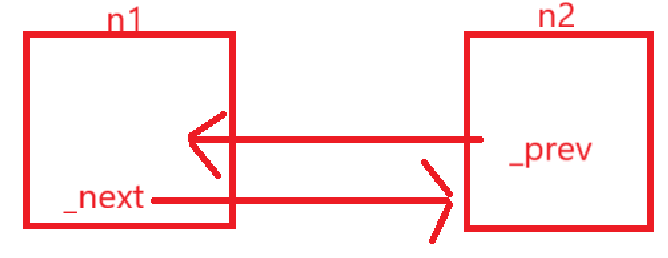
2.为什么互相指向就会无法正常释放
我又画了一个精致点的图:
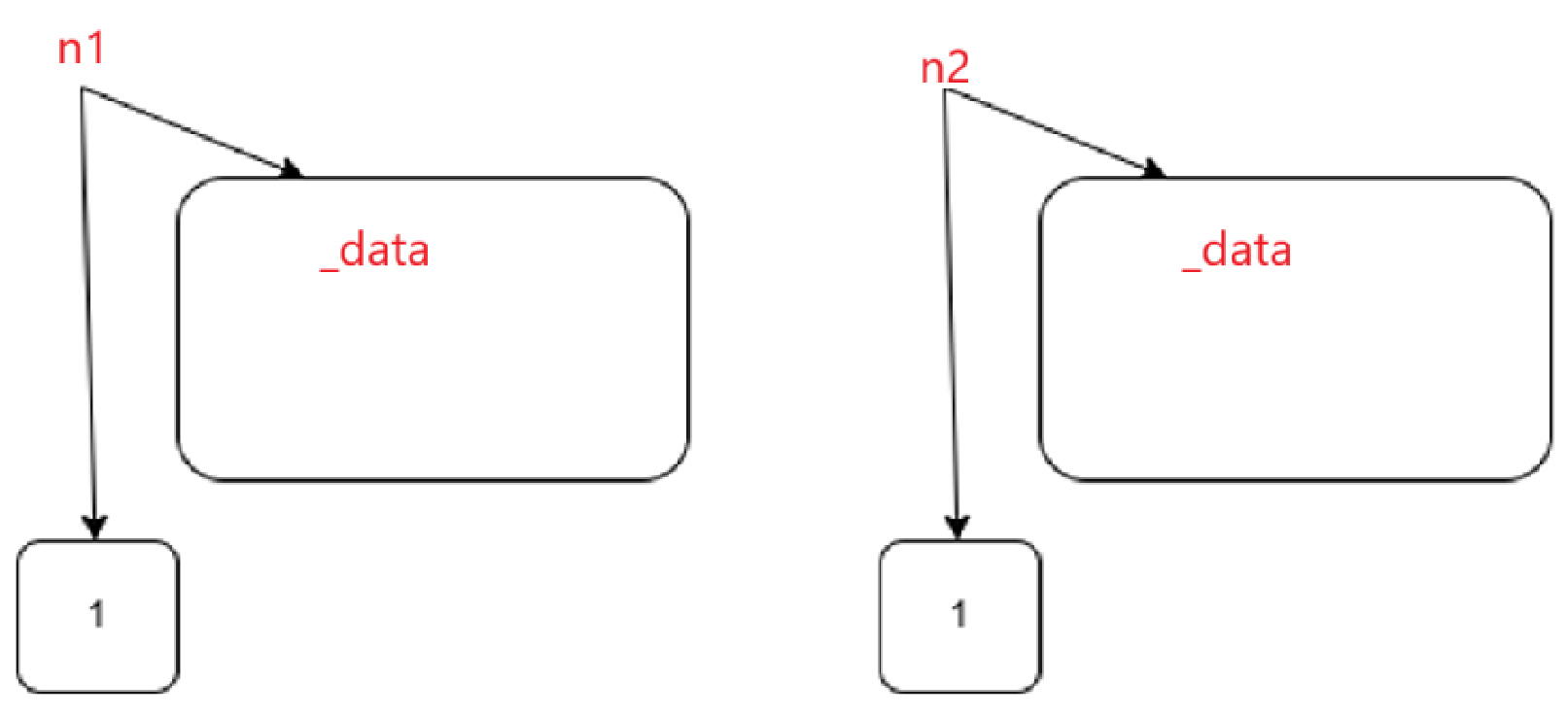
按照我们对shared_ptr的了解,底层大概就是这样的,不连接起来的话,到局部域结束的时候一看,引用计数为1:
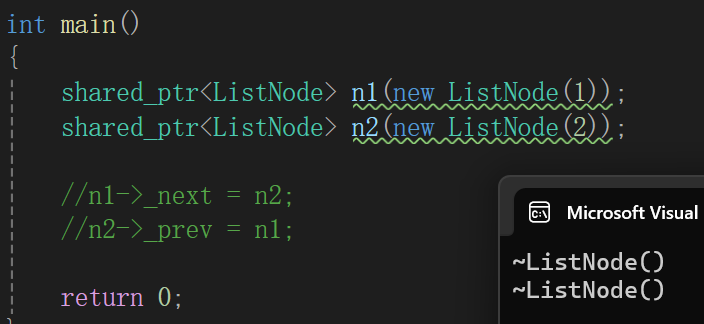
不过链表结点一定要链接起来才有意义:
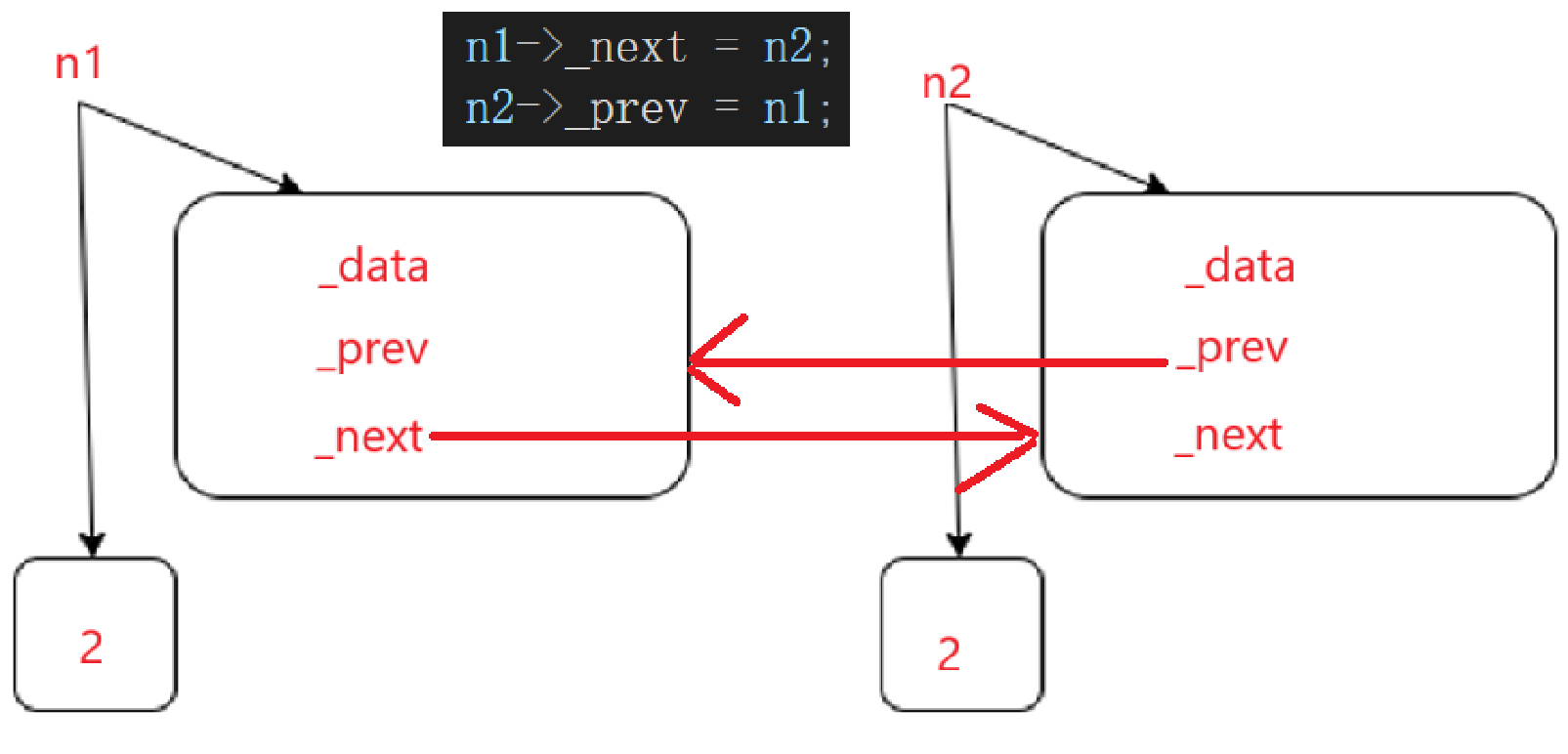
上述情况描述为:
由于上述所有指针都为shared_ptr,所以链接过程实质上是shared_ptr的赋值过程,那么对应的引用计数都需要++。
接着就到重点了:
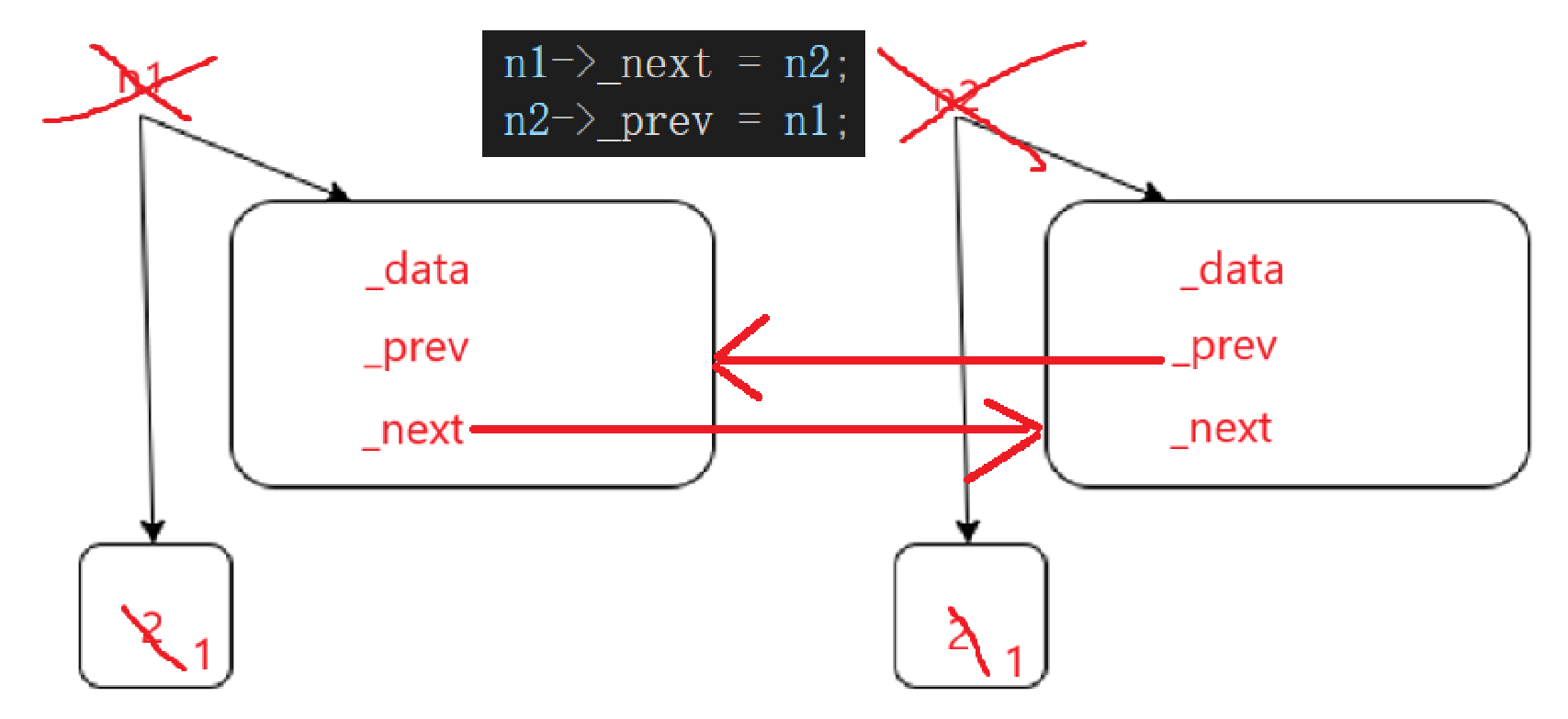
等到局部域结束,n1和n2都会被销毁,对象销毁会调用析构函数,它们析构底层大概率就是看看引用计数到底是几,只有降到1,只有一个智能指针指向才会析构,否则的话只会--引用计数。
这就抽象了,为啥说抽象呢?
左边的空间什么时候释放呢?右边的_prev管理着,直到右边的_prve析构才释放;
右边_prev什么时候析构呢?等到右边的空间释放,所有的成员都会被释放;
右边的空间什么时候释放呢?左边的_next管理着,知道左边的_next析构才释放;
左边的_next什么时候释放呢?等到左边的空间释放,所有的成员都会被释放。
有种俩人都不愿意吃亏,鱼死网破的感觉,太奇怪了。
这种问题怎么解决呢?
weak_ptr。
我们之前学习的unique_ptr不会给拷贝和赋值的机会,因此结点内_prev和_next不能弄成unique_ptr的;
shared_ptr已经用过了,会有循环引用的问题。
C++11里还有个智能指针,专门解决shared_ptr的循环引用问题。
3.weak_ptr解决循环引用问题

这玩意也是必学的,但是吧如果没有这个循环引用的场景,咱们光说它有啥用有啥用,肯定没意义。
最鲜明的特点就是:

weak_ptr的构造拢共没多少接口,默认构造和拷贝构造没啥可说的;第三个表明了weak_ptr可以接收shared_ptr初始化,赋值也就也允许了:

weak_ptr的核心特点就是解决share_ptr的循环引用问题,当shared_ptr的值拷贝给shared_ptr时,会使底层引用计数++,weak_ptr接受拷贝或赋值不会。
struct ListNode
{int _data;weak_ptr<ListNode> _prev;weak_ptr<ListNode> _next;ListNode(int data):_data(data){}~ListNode(){cout << "~ListNode()" << endl;}
};
六、weak_ptr
对weak_ptr还没有详细说明:
- weak_ptr并不是RAII的思想构建出来的智能指针,换句话说,想要让它给你管理资源你就做梦吧,这样的话既丧失了operator*、operato->等访问的权利,也没有了析构释放资源的功能。因为它的核心特点就是存起来指针,替shared_ptr,防止循环引用
可不要小看最后的存起来指针的这个“存”字,支持拷贝和赋值的,才能存同一块资源,不然就跟unique_ptr一样,一人吃饱全家不饿。
- 另外由于weak_ptr与shared_ptr的关系,还需要了解以下接口:expired、use_count、lock
1.expired和use_count
这俩函数接口底层逻辑有点相像。

由于weak_ptr是替shared_ptr管理资源的,那要是底层shared_ptr都没了,那还管屁资源啊,所以这个接口的作用类似于vector的operator[]里的assert(n < _size)。
总得安全才能用吧,这里其实也就是看看底层管理资源shared_ptr的use_count。
而weak_ptr实际指向的是当初赋值给它的shared_ptr,因此调用它的use_count相当于调用对应shared_ptr的use_count。
测试代码:
int main()
{shared_ptr<string> sp1(new string("xxxxxxx"));shared_ptr<string> sp2(sp1);weak_ptr<string> wp1 = sp1;cout << wp1.expired() << endl;cout << wp1.use_count() << endl;cout << "-------------" << endl;sp1 = shared_ptr<string>(new string("yyyyy"));cout << wp1.expired() << endl;cout << wp1.use_count() << endl;cout << "-------------" << endl;sp2 = shared_ptr<string>(new string("zzzzzzzz"));cout << wp1.expired() << endl;cout << wp1.use_count() << endl;cout << "-------------" << endl;return 0;
}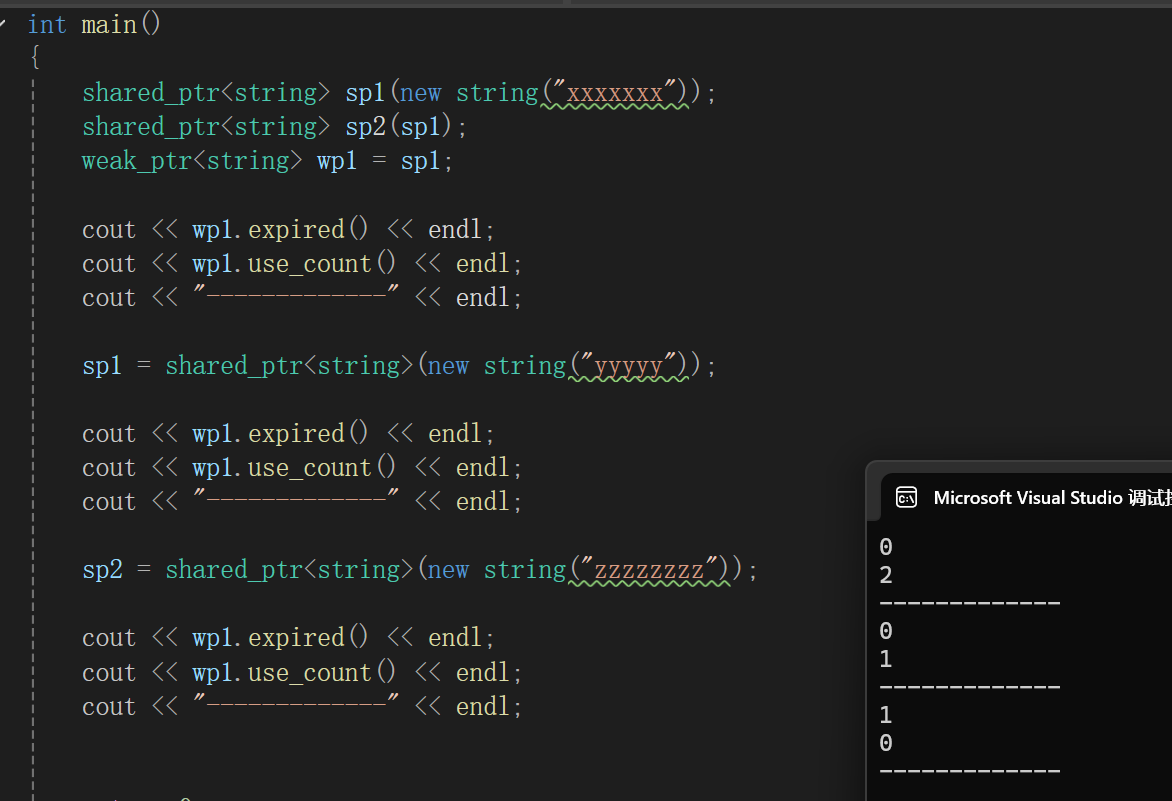
大概意思是啥吧,搞一块资源,让sp1和sp2都管着,再让wp1管着,再慢慢的把sp1和sp2管的都换了,可以看到当管理的资源没了的时候wp1的expired返回值就是true,说明管理的资源“过期”了;并且不难观察到,wp1的use_count就是指向底层资源的shared_ptr的引用计数。
2.lock

名字起的怪高级,其实就是把底层的资源弄成shared_ptr返回回来,因为weak_ptr不是不能解引用啥的嘛。
所以也没必要再多解释了。
3.模拟实现
底层它的这些expired啥的咱实现不了,但是实现个大体结构,让上面的引用循环解决一下还是简单的:
template<class T>class weak_ptr{public:weak_ptr():_ptr(nullptr){}//copyweak_ptr(const shared_ptr<T>& sp):_ptr(sp.get()){}//=weak_ptr<T>& operator=(const shared_ptr<T>& sp){_ptr = sp.get();return *this;}private:T* _ptr;};测试:
OK了。
七、内存泄露
1.什么是内存泄露
可不可能说闲着没事扔着内存玩呗,多弄几个内存条不完了,我们平常聊到的内存泄露是特定场景下的。
一般是疏忽或程序异常导致申请的内存未能正常释放,申请的内存不能再被申请,而且也不能被其他操作使用,如果这样的操作反复出现,将会对内存一点点蚕食,这样再有申请内存的动作将会非常缓慢甚至不能申请直接崩溃。
我们在异常那一节就了解过,为什么要有异常,因为我们平常用的软件甚至我们手机、电脑的操作系统,如果某个操作底层一直内存泄露,比如打个车,会造成2m内存泄露,一个人打还能受的住,时间长了不就炸了;有时候电脑用的时间长了,需要重启一下,大概率也是这个问题,内存泄露导致操作系统这个巨大的软件速度变慢,重启一下相当于我们不让他继续运行,而是走main函数的return 0,那么内存就都还回去了,就不卡了。
看完描述就知道为什么不是加几个内存条就可以了,你能加的内存条是有限的,但是程序一直运行下去总能消耗完。
2.如何避免内存泄露
我们C++避免内存泄露说难也不难,直接把资源甩给智能指针就行;但是用起来也不是那么好用的,因为我们上面看的时候auto_ptr拷贝构造其实跟移动构造效果一样,会有指针悬空问题;shared_ptr如果不是拷贝/赋值共同管理资源,走后门引用计数可不对,到时候对一块空间释放多了程序还得炸;shared_ptr还有循环引用问题。
另外就是事后,可以借助:
Linux下几款C++程序中的内存泄露检查工具_c++内存泄露工具分析-CSDN博客
windows下的内存泄露检测工具VLD使用_windows内存泄漏检测工具-CSDN博客
当然,将心比心,肯定你认认真真写代码,滤清思路减少甚至杜绝内存泄露最后,上面的工具毕竟是事后检测,代码几亿行你让它编译都得好久,运行起来出bug还得调试啥的,小心驶得万年船。