MIRE: Matched Implicit Neural Representations
Abstract
隐式神经表示(INRs)是针对传统数字信号表示的连续函数学习器。借助位置嵌入和/或经过精细调整的激活函数,INRs已经超越了传统离散表示的许多限制。然而,现有的工作只是通过在INR中单一地使用一个固定的激活函数来找到数字信号的连续表示,并且尚未探索将INR与给定信号相匹配。由于当前的INR并未与被其表示的信号相匹配,我们假设这种方法可能会限制INR的表示能力和泛化能力,从而限制了它们更广泛的应用。
一种将INR与被表示信号相匹配的方法是通过最小化均方误差来匹配每一层的激活。在本文中,我们引入了MIRE,这是一种通过字典学习为INR的每一层找到高度匹配的激活函数的方法。为了展示所提出方法的有效性,我们使用了一个包含七个激活原子的字典:升余弦(RC)、根升余弦(RRC)、椭球面波函数(PSWF)、Sinc、Gabor小波、高斯和正弦波。实验结果表明,MIRE不仅在各种任务中显著提升了INR的性能,例如图像表示、图像修复、3D形状表示、新视图合成、超分辨率和可靠的边缘检测,还消除了之前所需的对激活参数进行穷举搜索的需要,而这种搜索甚至在INR训练开始之前就必须进行。
1. Introduction
隐式神经表示(INRs),也被称为基于坐标的神经网络,通过学习一个连续的(隐式的)函数表示来工作,当提供明确信号表示的坐标时。一般来说,INR的结构是一个多层感知器(MLP),包含几个全连接层,其中明确信号的坐标作为输入。通过MLP的学习过程,明确的表示被编码到神经网络的权重和偏置中。INRs的一个显著特点是它们能够处理不同类型的信号,从二维图像到三维形状以及更复杂的信号。例如,在图像的背景下,INR利用二维网格的坐标来产生这些坐标处对应的颜色值,有效地为图像学习了一个连续的表示。
与传统的离散信号表示技术相比,INRs提供了一种更灵活、可能更有效的复杂信号表示手段。一旦通过INR将明确的信号表示转换为隐式表示,信号坐标与其值之间就建立了一个连续的函数关系。这种由INRs促成的已学习的连续隐式函数关系,作为底层信号的一个强大的表示机制,使其能够执行诸如对已学习表示的精确查询和微分等操作。相比之下,离散信号表示在执行查询等操作时会受到限制,因为它们受到量化插值的限制,而且由于离散的性质,微分可能无法产生期望的结果。因此,INRs的固有能力在准确表示和操纵信号方面与离散表示相比具有显著的优势。此外,尽管传统表示的内存需求随着信号分辨率的提高而呈指数增长,但INRs并不受分辨率的限制,使这种方法非常节省内存。
尽管使用INRs在上述应用中具有潜在的优势,但它们的性能在很大程度上取决于MLP的架构,特别是激活函数的选择。传统激活函数,如ReLU、Sigmoid和Tanh,这些在深度学习模型中常用的激活函数,在INRs中表现非常差。这种低效主要是因为它们无法有效地将信号的高频成分通过网络传递。为了解决这个问题,有人提出在训练之前进行固定的坐标变换,通常被称为位置嵌入,它将高频内容嵌入到INR的输入坐标中。尽管位置嵌入可以增强表示能力,但有研究发现它们的表示能力有限,难以有效地泛化。为了缓解这些问题,他们引入了正弦激活函数,并采用了特定的频率和精心设计的MLP权重初始化,从而避免了位置嵌入的需要。然而,正弦激活函数对精确的权重初始化和频率调整的依赖是一个显著的限制,尽管它们具有很强的泛化能力。在引入高斯和Gabor小波作为激活函数后,对非常特定的权重初始化的依赖已经最小化,这些激活函数利用了它们强大的时频定位能力。然而,这些非线性激活函数仍然需要针对每个信号和INR应用进行特定的参数调整,通常需要进行大量的网格搜索。在实践中,一个常见的变通方法是在将明确信号转换为隐式表示时重复使用之前确定的激活参数,但这限制了INRs适应和理解每个信号的独特特征的能力,最终阻碍了性能。此外,据我们所知,以前的研究只关注使用单一激活函数来提高INR的能力。这引发了以下问题:
- 使用多个激活函数是否可以自适应地增强INRs的表示能力和泛化能力?
- 我们如何减轻在训练任何INR之前确定激活参数的耗时且广泛的网格搜索过程的负担?
为了应对INRs中现有的这些问题,我们提出了“匹配隐式神经表示”(Matched Implicit Neural Representations,简称MIRE),这是一种根据输入信号来设计INR的创新方法。为了实现这一目标,我们提出了一种基于字典学习方法原理的技术,动态调整每一层的激活函数,从而为给定信号生成一个匹配的INR网络。为了动态调整并找到匹配的激活函数,我们采用了一种与匹配追踪算法紧密相关的方法。
在实验中,我们使用了一个包含四个新的激活“原子”的字典:升余弦(Raised Cosines)[2]、根升余弦(Root Raised Cosines)[12]、椭球面波函数(Prolate Spheroidal Wave Functions)[15, 16, 29–31]和Sinc函数[26],这些函数因其强大的时频定位能力而被选用,这一特性在信号和图像处理中常常被利用[5, 22, 33]。此外,我们还加入了三种在INR文献中广泛使用的激活函数:正弦函数(Sinusoids)[27]、Gabor小波(Gabor Wavelets)[9, 25]和高斯函数(Gaussians)[24]。
为了评估MIRE的性能,我们展示了多个应用场景,包括图像表示、图像修复、超分辨率、占用场表示、新视图合成、边缘检测和高频编码能力。我们对MIRE的全面评估表明,它明显超过了现有的最先进的INR解决方案。此外,我们广泛的消融实验揭示了MIRE有助于减少对特定激活函数参数确定的需求,而这种需求之前被认为是训练任何INR之前所必需的。
2. Related works
激活函数
神经网络的激活函数,也被称为传递函数,根据从前一层接收到的输入的加权和来确定每个神经元的输出。这些函数通常是非线性的,帮助神经网络用较少的节点捕捉非平凡的功能关系。与根据训练数据更新的网络权重和偏置不同,激活函数通常在训练之前选择,并在整个训练过程中保持不变。然而,最近提出了依赖于数据的激活函数,即可训练的激活函数,使用经典的Sigmoid函数。自那以后,又提出了几种其他的可训练激活函数。也有几项研究从频率的角度探讨了深度神经网络和激活函数之间的联系,为理解它们的行为及其对神经网络动态的影响提供了额外的见解。
紧支撑和带限信号
紧支撑和带限信号分别在其定义域或傅里叶变换域内只有有限范围的非零值。这种特性在信号处理、通信等领域通常是可取的,因为它具有高效的近似、传输和恢复特性。由于在数学上不可能同时具有紧支撑和带限性,因此下一个最佳特性是具有一些形式的时频集中性,即具有快速频率衰减的紧支撑,或具有快速空间衰减的带限性,或在两个域中都具有快速衰减。随着INRs的发展,已经证明,当激活函数具有良好的时频集中性时,它不仅显著提高了INR的性能,而且倾向于减少对特定INR权重初始化的需求。
隐式神经表示(INRs)最近受到了计算机视觉研究界的关注,这主要是因为它们简单的网络架构以及在各种视觉任务中相较于传统参数繁重的视觉模型所观察到的性能提升[6, 25, 27]。INRs的出现主要是在引入了带有ReLU激活函数的神经辐射场之后[20],这引发了多项后续研究[10, 21],并且使用正弦激活函数作为传统ReLU激活函数的替代品[27]。此后,[24]展示了适用于INRs的更广泛的激活函数类别。最近的一项工作[25]提出了Gabor小波,这种激活函数不仅具有紧支撑性,还受益于指数衰减,作为INRs的非线性激活函数,并且与之前的INR模型相比,展示了改进的INR性能。
3. Methodology
3.1. Formulation of an INR
考虑一个表示为 的隐式神经表示(INR),其中
代表神经网络参数。
从
维空间(记作
接收坐标,并将它们映射到
维信号(记作
)。因此,这个映射可以表示为:
![]()
如果 和
是第
层的权重和偏置矩阵,那么输入到第
层的值由
给出,其中
和
分别代表激活函数和第
层的输入。INR 的表示能力或学习动态由激活函数
决定。大多数研究都使用了单一激活类型来构建整个网络,即对于所有的
,
。通过广泛的实验,我们表明这种方法通常会导致INR的学习结果次优,因为将INR限制为单一激活函数可能会限制学习模型的表示能力。因此,当模型试图泛化到未见过或未训练的坐标时,模型会遇到困难,这削弱了INR的预期目的和功能。因此,这限制了INR的适应性和有效性,而鲁棒性和泛化能力是从一种表示转移到另一种表示时的重要方面。
3.2. Dictionary of activations for MIRE
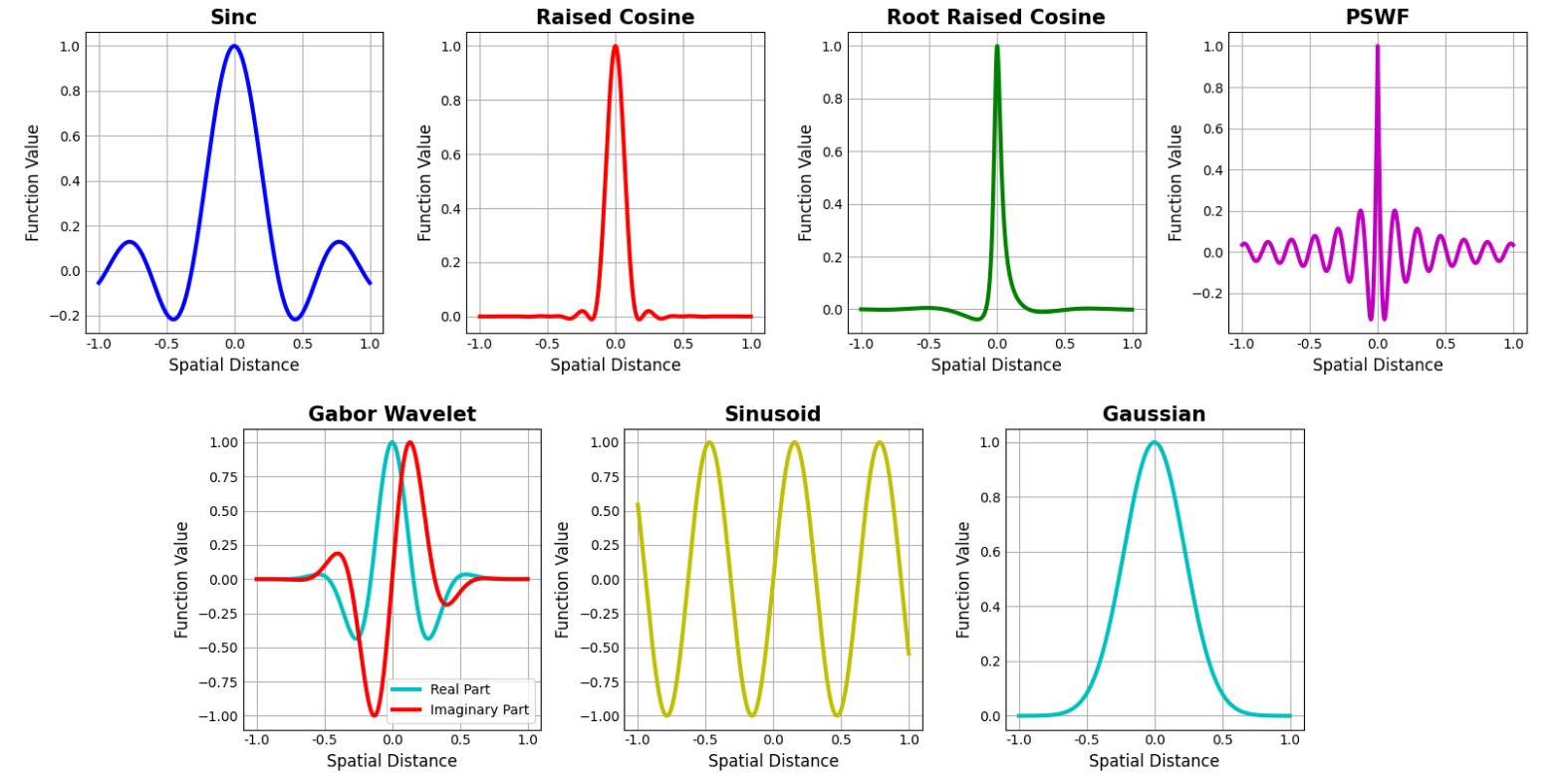
我们采用了一个包含七个激活函数的字典。这包括两个在空间和傅里叶域中都具有快速衰减的函数(复高斯小波和高斯函数)以及五个带限函数(Sinc、升余弦、根升余弦、正弦函数和PSWF)。
1. Sinc函数:Sinc函数是傅里叶域中矩形脉冲的傅里叶变换(在数字通信文献中,这也被称为Nyquist脉冲)。它定义为,并且随着
衰减,其中
是一个参数。
2. 升余弦(RC):这是另一个带限函数,其在空间域中的衰减阶数为,因此比Sinc衰减得更快。由参数
、
和
定义,升余弦的一般函数形式为:
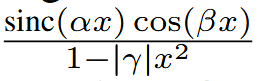
3. 根升余弦(RRC):这是通过取升余弦脉冲频率响应的平方根得到的升余弦的修改版本。这种修改改善了信号的衰减。以 、
、
、
和
为参数,根升余弦的一般函数形式为:
![]()
4. 长椭球波函数(PSWF):这些是长椭球坐标中的Helmholtz方程的解。在长椭球坐标中,Helmholtz方程可以转化为以下常微分方程,其中、
和
是参数,
是PSWFs:
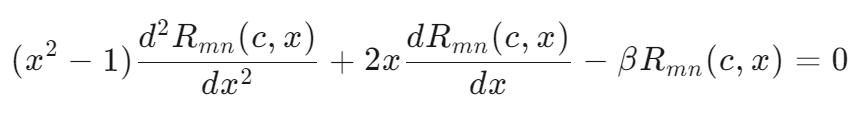
其中。这个微分方程出现在带限信号的背景下,当信号在给定区间内具有最高可能的能量集中时。尽管找到PSWFs的闭式解是困难的,但本研究中采用了一种离散化近似。为了将其定义为激活原子,使用了自然立方样条近似。
5.高斯小波:高斯小波涉及高斯调制的余弦或正弦波。它们在空间和频率域中都提供快速衰减,并且已经准备好用于INRs,显示出比正弦激活更好的性能。以、
为参数,复高斯小波的一般函数形式为:
![]()
6. 高斯函数:与复高斯小波类似,高斯函数在空间和频率域中也提供快速衰减,并且已经在INRs中使用。高斯的一般函数形式为:
![]()
其中 是一个参数。
7. 正弦函数:正弦函数是带限的,并且在INRs中已经使用。正弦函数的一般函数形式为:
![]()
其中、
是参数。
从补充材料中提供的图中可以观察到每个激活函数的不同空间特征,其中描绘了激活函数值随空间距离的变化。
3.3. Premise of MIRE
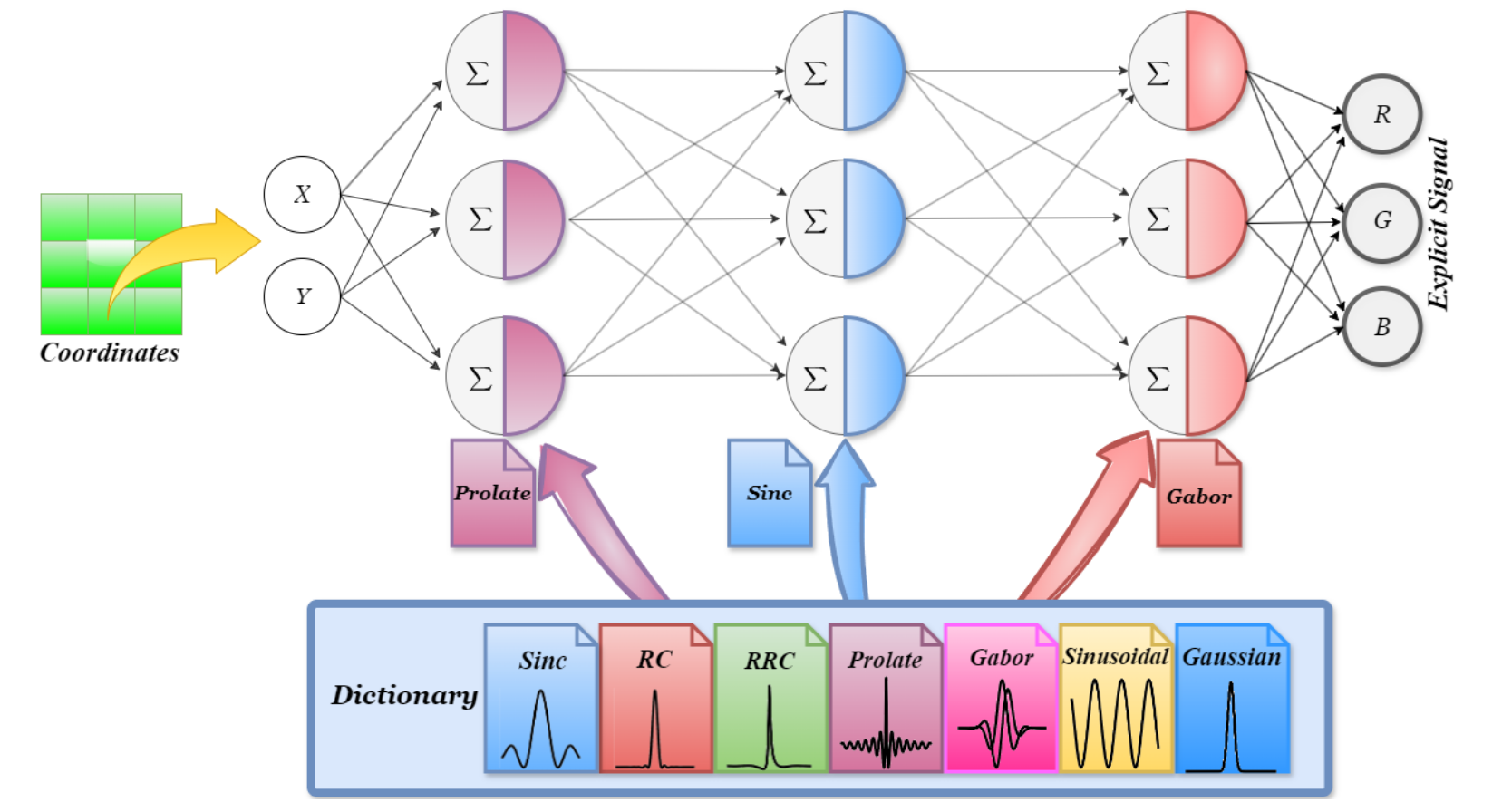
MIRE首先构建一个预定义激活函数的字典,如第3.2节所述,每个激活函数都配备了可训练的参数。这些激活原子的参数是随机初始化的,可以从均匀分布或正态分布中抽取。MIRE初始化为一个单层MLP(多层感知器),其输入和输出维度根据明确的信号表示进行定制。算法遍历字典中的每个激活函数,并将其作为隐藏层的非线性激活函数应用在指定数量的训练周期内,允许优化激活函数参数。在此过程中,算法通过计算两个表示之间的均方误差来跟踪每个激活函数的性能,保存实现最低损失的激活函数的参数。在评估完所有激活原子后,算法选择产生最小损失的第一层激活函数。一旦基于最小损失标准确定了第一隐藏层最合适的激活函数,就将其固定为第一隐藏层的非线性激活函数,并保留其相关参数。然后,MIRE继续添加第二隐藏层。它再次从头开始MLP训练过程,有一个关键区别:保留第一隐藏层的激活函数及其优化参数,这些参数在使用单隐藏层时最小化了损失。然后算法再次测试字典中的每个激活函数作为第二隐藏层的非线性激活函数,同样在预定数量的训练周期内。类似地,记录每个激活的性能。在这次扫描结束时,根据性能,选择产生最小损失的激活,并将其固定为第二层的非线性激活。这个过程对所有隐藏层继续进行。图1通过激活函数字典展示了MIRE为图像表示任务选择最优激活序列的过程。为了更好地理解MIRE的训练过程,请参阅提供的伪代码(见补充材料)以及第3.3节。
3.4. Activation function parameter initialization
带有参数化激活函数的INR的性能在很大程度上取决于激活参数的初始化,其中不良的初始化往往会降低各项任务的性能。以前的研究已经使用广泛的网格搜索来确定每个应用的激活参数[25],但这种方法的有效性高度依赖于信号的多样性,并且可能在与用于参数确定的信号不同的信号上表现不佳。相比之下,MIRE要么随机初始化激活函数参数,要么用它们的基础配置进行初始化,允许网络在优化过程中为每个应用和信号学习最优参数。这种适应性使MIRE能够根据信号的具体特征进行优化。实验结果表明,MIRE在各种任务中的性能和泛化能力方面都优于现有的INR,包括WIRE[25]、SIREN[27]、GAUSS[24]和MFN[9]。
4. Experimental results
4.1. Image representation
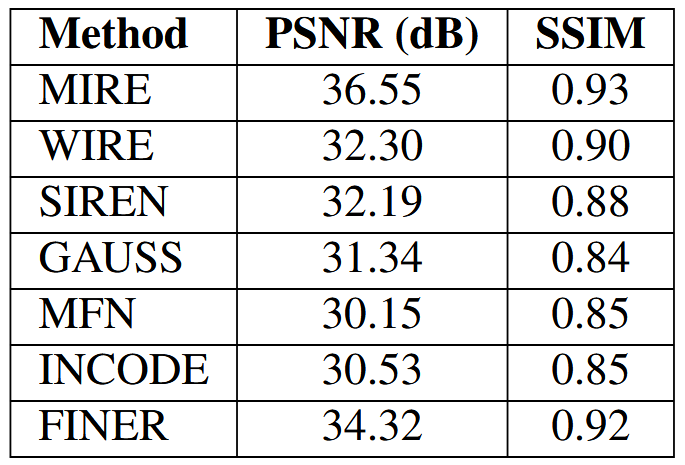
如前所述,MIRE的一个直接应用是学习图像的隐式表示,通常称为图像表示。为了清楚地说明MIRE的工作原理,我们选择了一张具有高空间变化和宽频率范围的图像(如图2顶部左侧所示)。在这里,网络被提供信号的归一化坐标,没有任何位置嵌入,MIRE被训练来预测相应的RGB值。然后,为了进行更全面的评估,MIRE的表示能力在Kodak数据集上进行了评估。图3显示了每张图像的PSNR结果以及基线结果。有关平均PSNR和每种方法的解码表示,请参阅补充材料。
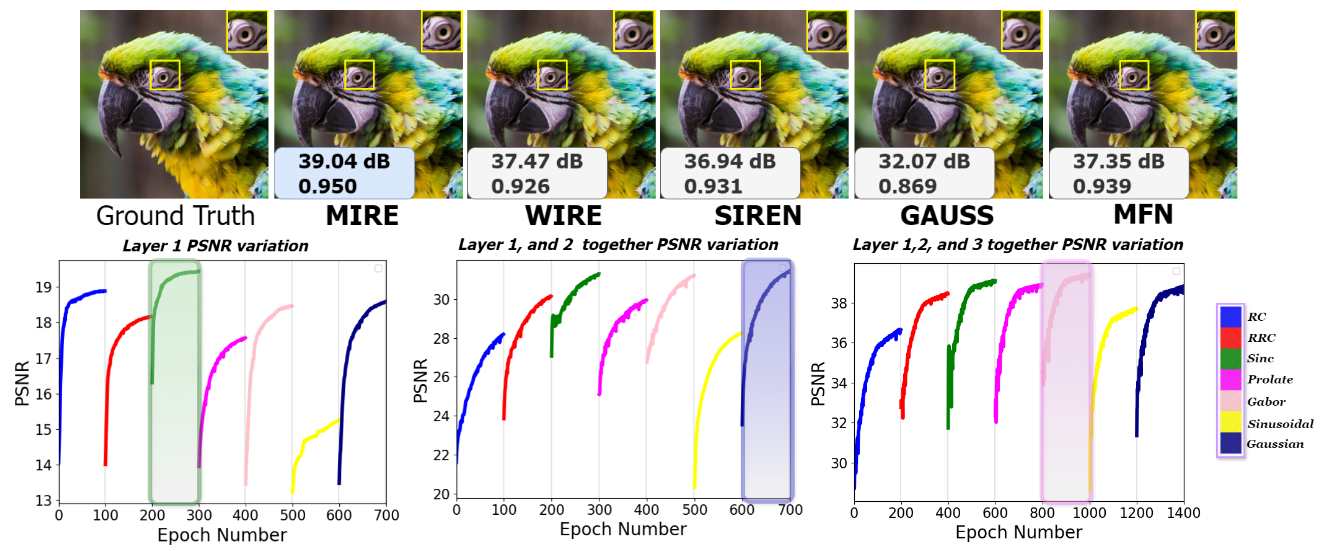
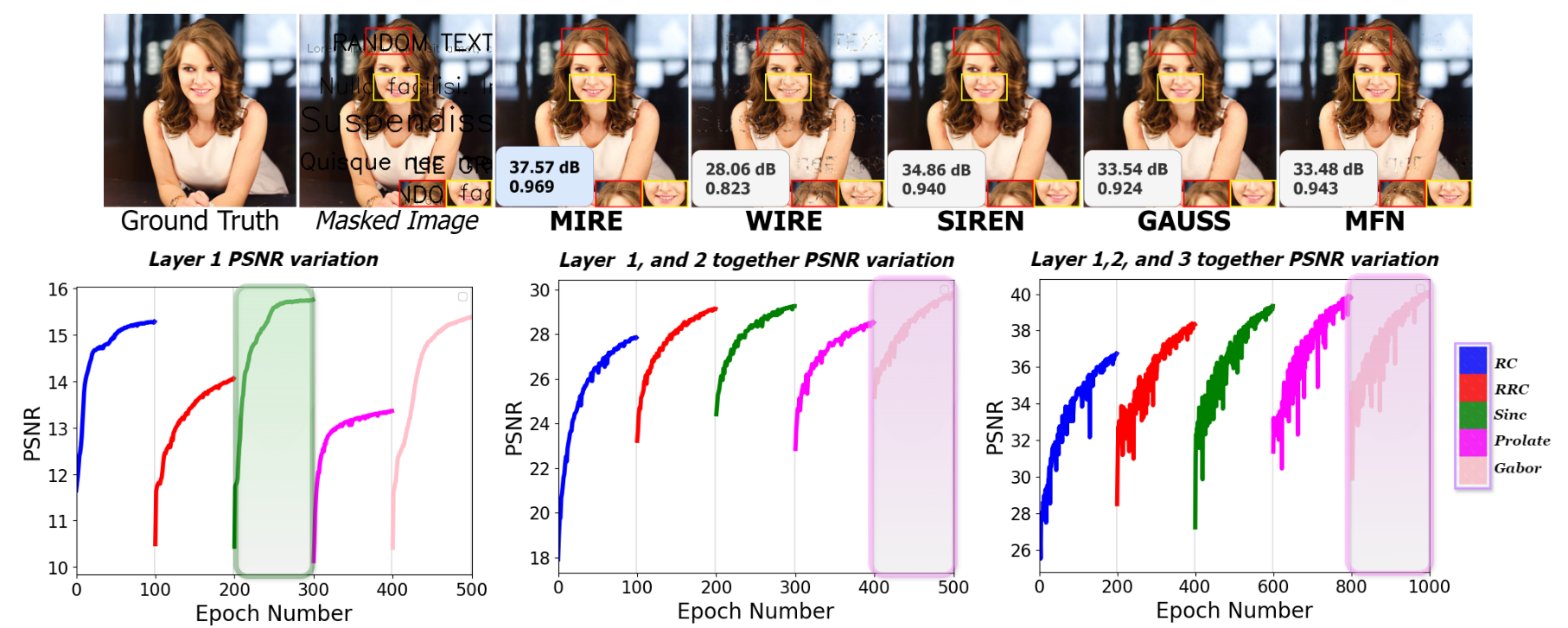
如图2顶部所示,MIRE实现了最高的PSNR和SSIM值,表明与现有的INR相比,它具有最低的失真和最佳的结构信息、纹理和对比度的保留。在这个实验中,我们使用了第3.2节中定义的所有激活函数。如第3.3节详细说明的,MIRE从单个隐藏层开始,并搜索字典以确定哪种激活产生最高的PSNR(或最低的损失)。对于字典中的每个激活原子,这个过程进行了100个周期。在根据损失标准确定与图像最匹配的激活后,本例中为Sinc,它将这种激活锁定在第一隐藏层(图2左下角)。随后,MIRE添加第二个隐藏层,并重新开始训练整个网络,同时保持第一层确定的最佳激活不变,每100个周期只调整第二隐藏层的激活。在这个阶段结束时,它确定了为第二隐藏层提供最高PSNR的激活,本例中为高斯(图2中下方中间)。接下来,MIRE引入第三个隐藏层,并重新开始训练网络,同时保持第一层和第二层的激活不变,这次每200个周期修改第三层的激活。训练完成后,MIRE确定了导致第三隐藏层最高PSNR的激活,本阶段为高斯小波(图2右下角)。因此,MIRE为鹦鹉图像确定的匹配激活序列是Sinc、高斯和高斯小波。请注意,尽管MIRE根据损失为每层确定最合适的激活,但PSNR图用于说明目的。
考虑到图2的底部行,我们可以得出结论,一旦网络确定了MIRE确定的匹配激活函数序列,INR就开始展示更快的收敛速度。在MIRE的情况下,当确定了前两层的激活函数时,它最多只需要200个周期就可以获得隐式和显式表示之间的最小损失。因此,与当前最先进的INR相比,显示出更快的收敛速度。从图2和图3可以看出,当INR的激活函数为特定信号定制时,而不是在整个INR中使用预先优化的、统一的激活序列时,INR实现了最高的准确性指标。这一全面评估证实了我们的假设,即设计一个与输入信号相匹配的INR显著提高了INR的性能,即使激活参数是随机初始化的。
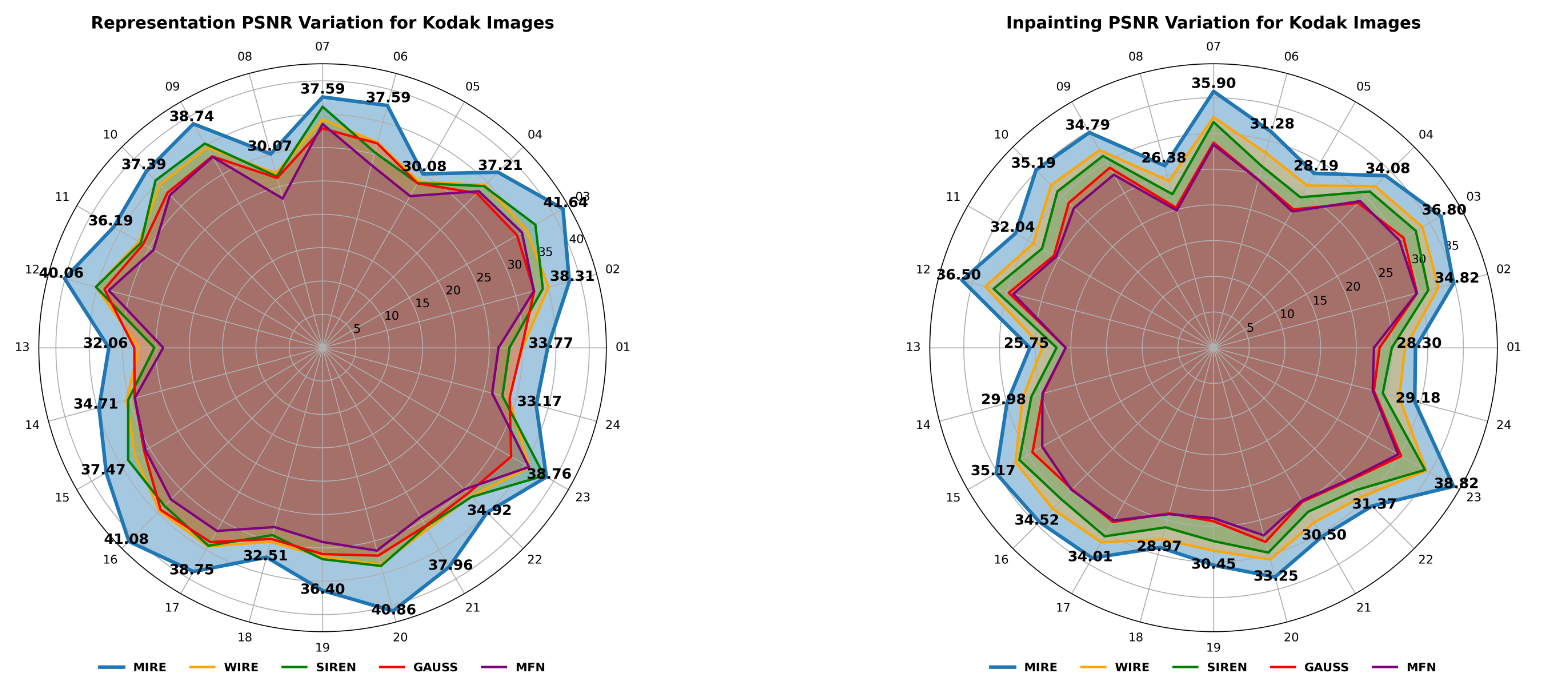
4.2. Image inpainting
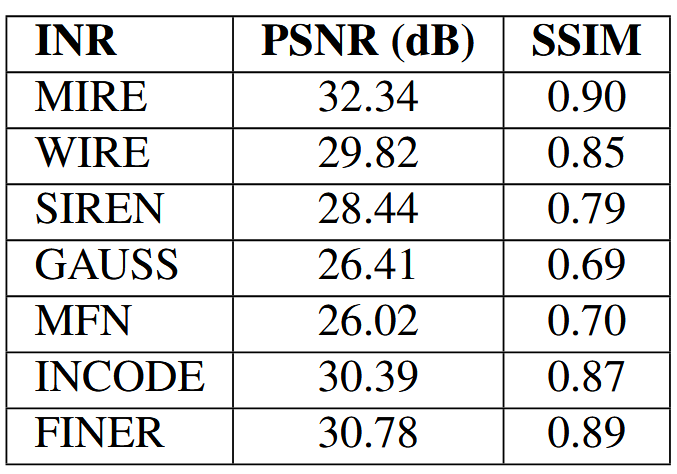
与显式的离散信号表示不同,INR通过MLP训练过程学习给定信号的连续隐式表示。因此,一旦相应的显式表示被编码到INR的权重和偏置中,就应该能够按需查询模型。图像修复任务是评估INR是否过拟合的好方法,因为采用新表示的主要目的是通过学习到的连续映射来泛化它。为了展示MIRE在图像修复方面的功能,我们选择了一张具有复杂细节的图像,如图5左上角所示。右侧相邻的图像显示了应用了文本掩模的相同图像。此外,我们还评估了MIRE在Kodak数据集上的图像修复性能,以提供更全面的评估。图4显示了每张图像的PSNR结果以及基线比较。有关修复图像和Kodak数据集上图像修复的平均性能指标,请参阅补充材料。在这个实验中,新引入的激活函数,即RC、RRC、Sinc、PSWF和Gabor小波,被用来展示这些激活函数的有效性。图5的底部行展示了在遵循第3.3节中的程序时每层观察到的PSNR性能。需要注意的是,在图像修复的情况下,决定激活的损失计算是基于部分图像数据的。结果清楚地表明,与所有现有的INR相比,MIRE提供了最干净、视觉上最连贯的图像修复结果。除了产生视觉上最连贯的图像外,MIRE在图像修复任务中还实现了最高的PSNR和SSIM值。
4.3. Occupancy field representation
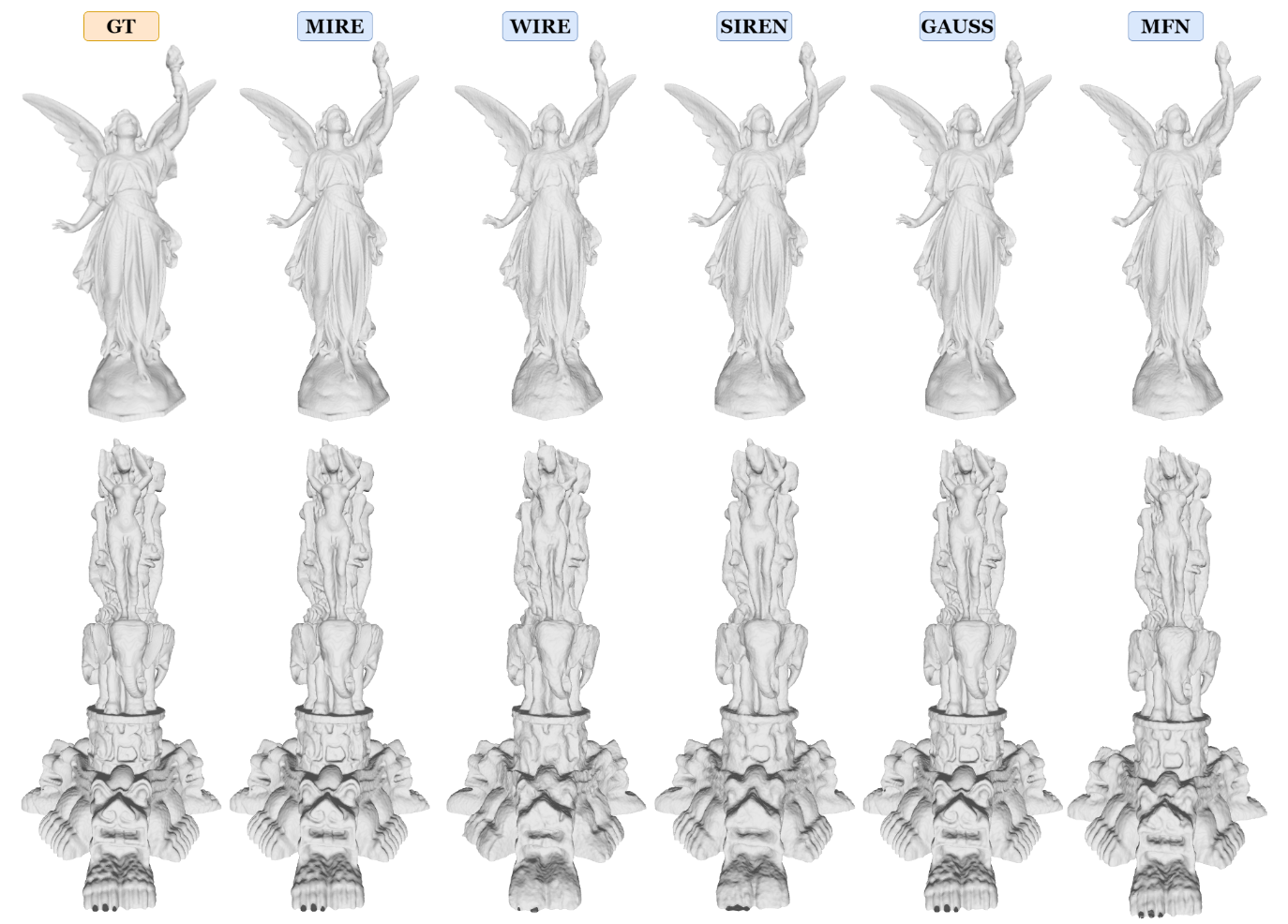
由于INRs提供了从低维坐标空间到信号空间的连续函数映射,它们可以有效地表示三维有符号距离场。在这种情况下,映射从三维空间扩展到一维空间,其中信号空间由二进制值表示:1或0。这里,1表示信号位于指定区域内,而0表示在给定区域内不存在信号。在这个实验中,从Stanford 3D数据集中获得了两个数据集,即泰国雕像和Stanford Lucy。采样过程遵循了[25]中描述的方法,使用了一个512 × 512 × 512的网格。体积内的体素被赋值为1,而体积外的体素被赋值为0。图6的第一列分别显示了Stanford Lucy和泰国雕像的部分采样体积。
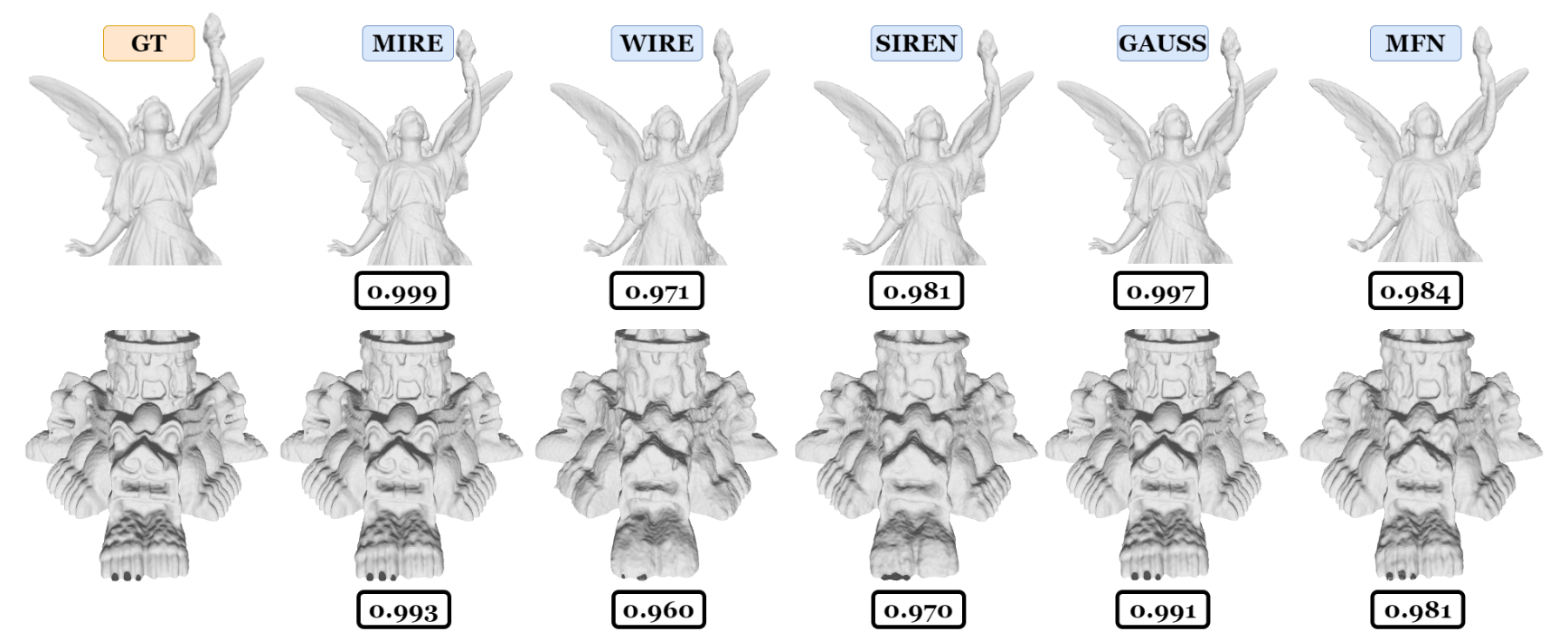
图6展示了每个INR的解码表示以及真实值。可以清楚地看到,MIRE实现了最高的交并比(IoU)指标,展示了所有现有INR中最大的表示能力,无论占用场如何。仔细观察解码的雕像揭示了MIRE精确编码复杂的高频细节。相比之下,像WIRE1和SIREN这样的INR倾向于收敛到低通表示,突出了在这些模型中编码快速变化的详细特征的挑战。这些发现清楚地表明,不仅对于图像,对于任何信号,当确定了匹配的激活序列时,INR可以准确地学习隐式表示。在这些实验中,MIRE为Stanford Lucy确定了第一、第二和第三层分别为Sinc、RRC和PSWFs的匹配激活序列。对于泰国雕像,各层的激活分别为RC、RRC和高斯小波。与图6相对应的完整占用场显示在补充材料的占用场部分。
4.4. Neural radiance fields
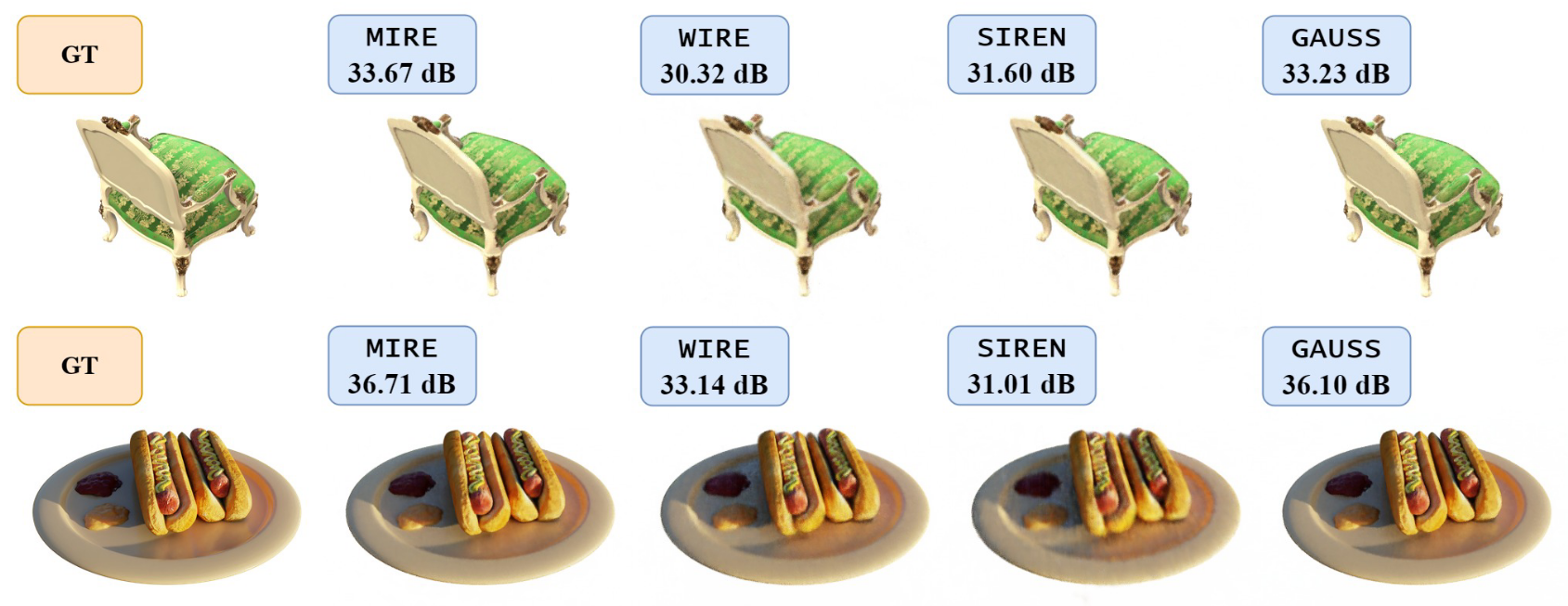
由于NeRFs(神经辐射场)的影响,INRs(隐式神经表示)在计算机视觉界已经变得非常流行。在这种方法中,通过输入观察者的空间坐标(x, y, z)和视角(θ, φ)到网络中,并借助围绕场景捕获的图像集合,将三维场景编码到INR中。INR的任务是预测这些位置的颜色和密度。当INR被训练后,它可以从新的空间位置和视角生成在训练数据中不存在的未见过的视角。在这个实验中,我们使用了带有Chair和Hotdog数据集的原始NeRF架构。图7的顶部和底部行分别展示了从训练好的INR模型在Chair和Hotdog数据集上生成的新视角。补充材料中提供了额外的新视角。
4.5. Effect of activation parameter initialization
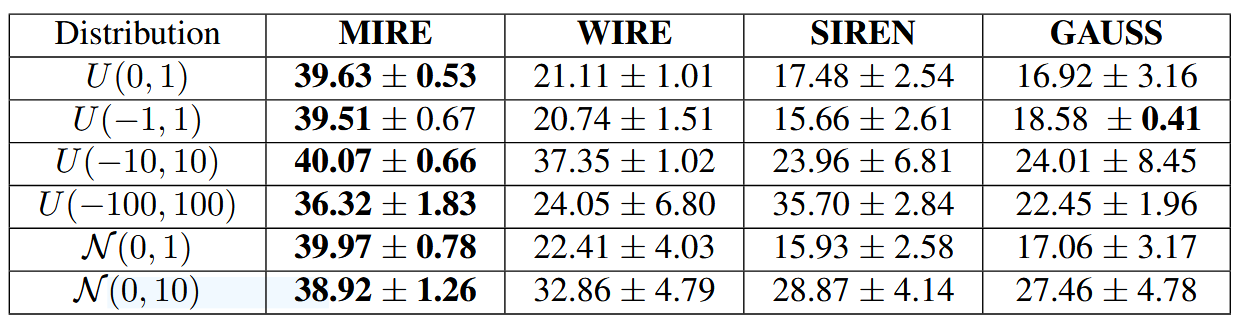
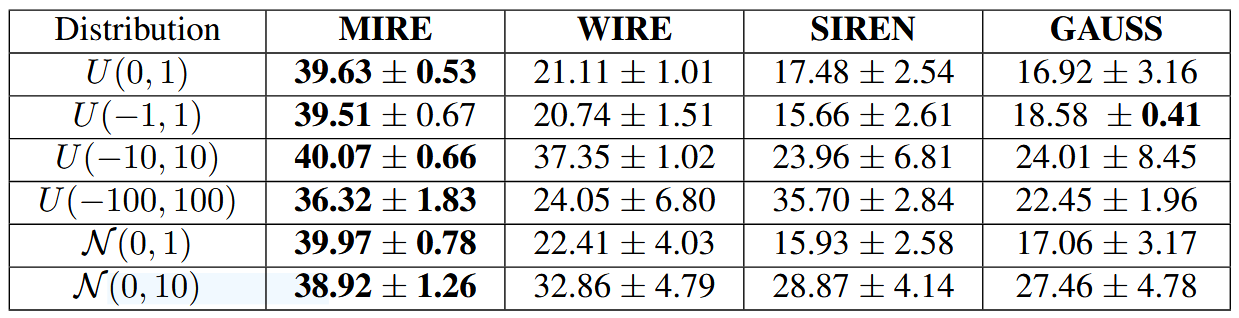
如第3.4节所述,传统INRs的性能在很大程度上取决于激活函数参数的初始化。相比之下,MIRE通过为特定任务匹配激活序列来设计INR,而不需要非常精确的初始化。为了证实这一说法,我们从均匀分布和正态分布中获取了激活函数参数。选择这些分布的主要原因是为了了解当参数来源于围绕均值值均匀分布或中心的范围内时,INRs的性能如何。均匀分布表示为,正态分布表示为
。补充材料中的表3显示了在图2中的鹦鹉图像上进行的五次试验的平均PSNR(以dB为单位),变异性以±符号旁边的标准差表示。粗体数字表示最高的PSNR,后面的数字表示最低的标准差。如补充材料中的表3所示,MIRE是唯一能够在各种分布中提供一致PSNR,同时在均值附近表现出最小变化的INR。MIRE不仅保持了PSNR的一致性,还记录了最高的PSNR值。相比之下,WIRE仅在
分布下表现出色,这表明其激活参数需要在测试的鹦鹉图像的狭窄范围(-10到10)内初始化。同样,SIREN在其激活参数从
分布中选择时表现出增强的性能。这些观察结果强调了现有INRs对其激活参数的特定初始条件的依赖性,以引导网络朝着收敛的方向发展。
4.6. Additional experiments and ablation Studies
在补充材料中,我们展示了关于图像超分辨率、边缘检测和高频编码的综合实验,其中还包括了与最近发布的最先进的INR方法,即INCODE[13]和FINER[18]的比较。提供了实验设置和消融研究的详细信息,评估了MIRE在隐藏神经元、层数、学习率、权重初始化和位置编码方面的性能。此外,我们还提供了训练曲线的解释,空间域内激活的变化,以及MIRE与基线方法的不同之处。
5. Conclusion
为了使用隐式神经表示(INR)学习数字信号的连续函数表示,通常需要进行详尽的网格搜索以优化激活函数参数。然而,由于缺乏对参数空间的洞察,找到最佳配置变得复杂,这导致了重用先前发现的参数的常见做法。这种变通方法限制了INR完全适应每个独特信号的能力,最终限制了其表达能力和泛化能力。在这项工作中,我们介绍了匹配隐式神经表示(MIRE),这是一种动态方法,它使用基于字典学习的方法将INR适应于每个输入信号,其中字典由非线性激活原子组成。通过动态地将激活函数与信号特征对齐,MIRE释放了在不同数据类型上泛化的巨大潜力。我们的方法通过七种不同的非线性(可扩展或可定制)进行了演示,显著提高了INR在各种表示和泛化任务中的性能,适用于所有数据模式。此外,它放宽了网格搜索和参数重用的限制,提供了一种更有效和适应性强的解决方案。
Supplementary Material
7. Additional experiments
7.1. Image super resolution
由于INR的学习过程能够发现从低维空间坐标到高维信号空间的连续函数映射,因此可以根据需要查询学习到的表示。因此,与基于网格的图像表示不同,这种表示与图像的空间分辨率解耦,允许通过插值学习到的表示来实现图像超分辨率。为了演示图像超分辨率,我们选择了两张具有不同细节复杂度的图像。第一张,称为Set 14数据集中的“男孩图像”,是一个动态图像,整个图像中都包含尖锐的频率内容,这可能会挑战超分辨率的细节检索能力。第二张图像是一位女性,尖锐的频率细节主要集中在面部特征周围,为超分辨率过程提供了一个局部化的测试(见图8)。这两张图像都被下采样了两倍,然后用于训练INR。训练好的INR不受空间分辨率的限制,然后用于推断高分辨率图像。图像超分辨率的性能展示了INR的泛化能力。从结果中可以看出,MIRE在两种情况下都一致地展现出不仅最佳的PSNR和SSIM值,而且无论图像的复杂度如何,都展现出最视觉上连贯的结果。在INR中,WIRE在测试期间推广到大量未见过的坐标集时表现出明显的不足,特别是在复杂图像中尤为明显。例如,在“男孩图像”的情况下,WIRE难以推广下尺度图像的隐式映射。在尝试超分辨率时,WIRE为未见过的坐标引入了大量的随机值,突显了它在处理不同复杂度级别的图像时的局限性。相反,在“女性图像”中,WIRE展示了一个更合理的表示。从GAUSS和MFN中也可以看到类似的情况。因此,表明WIRE、GAUSS和MFN的超分辨率能力依赖于图像的详细程度。这些方法倾向于在细节局部化的图像上表现出色,如“女性图像”,但在像“男孩图像”这样高度详细的图像上失败。仔细检查SIREN的超分辨率图像揭示了一种学习的低通表示,在解码的高分辨率图像中缺少高频成分。相比之下,MIRE在所有测试场景中展现出无与伦比的性能,证实了其学习到的表示的稳健性和可靠性。MIRE的性能在不同类型的图像中是一致的。这些发现进一步证实了我们的假设:配备适当序列化激活框架的INR比依赖于给定信号的固定激活序列学习到更优越的表示。

7.2. Edge detection
INRs(隐式神经表示)的特点是它们固有的能力以隐式方式编码信号,其中泛化INR的一个关键属性在于其能够执行通常为显式表示保留的任务。对于显式信号表示,特别是图像,空间滤波器如Sobel、高斯、Canny等,能够实现边缘提取。这一过程对于识别物体边界、检测文本或识别面部特征等活动至关重要,所有这些都在很大程度上依赖于精确的边缘检测。尽管可以通过INR的解码输出获得边缘图,但INR提供了学习和可微分的表示的好处。因此,INR不仅要精确捕捉信号,还要便于检索其梯度数据。为了有效地作为边缘检测器,INR需要在其权重和偏置中编码像素级关系。

当应用于具有清晰视觉边缘的图像,如Set 5数据集中的帝王蝶图片时,使用INR提取边缘图的能力变得明显。为了确定INR的边缘检测能力,最初通过训练INR学习图像表示。之后,利用学习到的模型和训练期间使用的坐标之间的梯度算子。图9展示了帝王蝶的RGB图像以及从INR派生的边缘图。MIRE通过提供最干净、定义最清晰的边缘图而脱颖而出,识别必要的边缘并最大限度地减少错误边缘识别。在其他INR中,尽管MFN能够识别边缘,但其边缘图通常包含过多的纹理内容,可能导致错误的边缘检测。另一方面,GAUSS产生了平滑的边缘图,这可能会减弱真实的边缘信号,并导致不太可靠的表示。相比之下,MIRE保留了复杂的图案,提供了更准确的蝴蝶自然标记的描绘。SIREN也展示了其作为边缘检测器的有效性,利用其内置的识别边缘的能力。然而,即使在没有这些固有优势的情况下,MIRE在检测边缘方面表现出色,突显了其捕捉复杂图案和提供精确表示的能力。因此,与现有的最先进的INR相比,MIRE展示了其作为可靠边缘检测器的有效性。
7.3. High frequency encoding capabilities
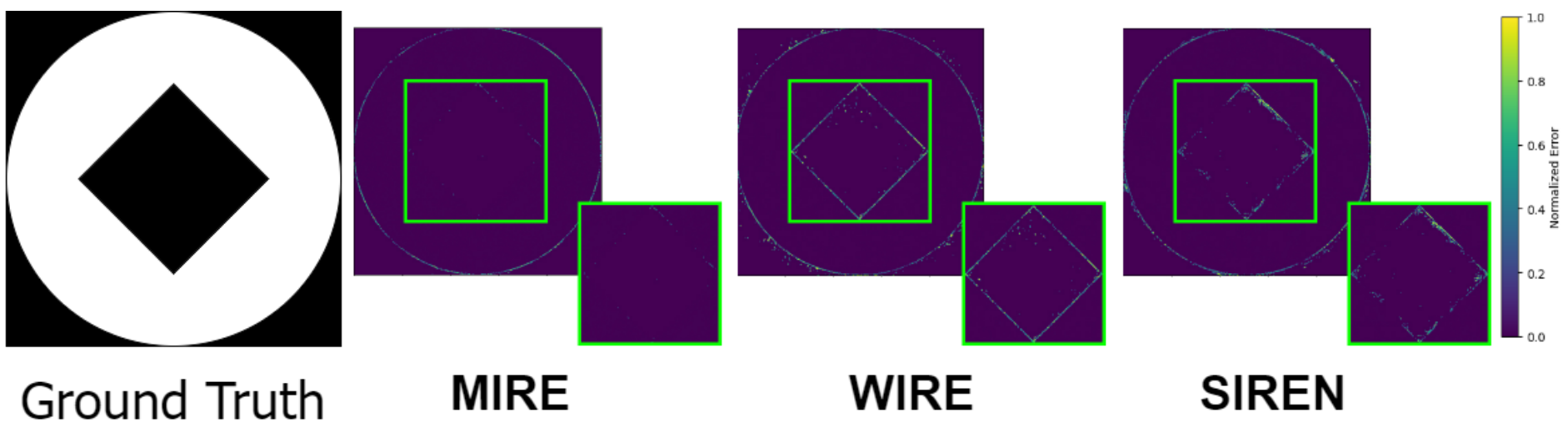
评估INRs(隐式神经表示)高频编码能力的一个简单方法是通过检验它们在表示尖锐频率方面的有效性。这可以通过检查一个仅由尖锐过渡组成的简单图像来实现,其中空间域中的突然颜色变化对应于频率域中的高频成分。在这个实验中,我们选择了图10左侧显示的图像。然后在该图像上训练INRs。一旦每个INR学习了隐式表示,就通过输入相应的坐标来解码它。随后,我们获得了将真实值与解码表示进行比较的归一化误差图。
如图10所示,与其他模型如SIREN和WIRE相比,MIRE在解码图像与真实值之间的误差幅度最小,这些模型即使在颜色均匀的区域也显示出明显的误差。这一结果明显突出了MIRE在准确编码高频成分方面的优越能力。这种表示的精确性也从频率域的角度验证了MIRE的潜在假设:INR中的激活序列应根据输入信号的特征进行调整。
8. Additional results
8.1. Image representation
与传统的 INR 不同,传统的 INR 在整个网络中使用相同的激活函数,但参数次优,对于给定信号来说可能并不理想,MIRE 提供了一个框架,允许网络调整其内部配置以更好地匹配信号,并产生与给定信号匹配的 INR。这种增加的灵活性使 MIRE 的性能始终优于现有的 INR 方法。这从我们在柯达图像数据集上对MIRE的全面评估中可以明显看出,如图3所示。此外,我们还提供了柯达数据集的解码表示,如图11所示。此外,表1总结了MIRE和整个数据集的基线模型的平均PSNR和SSIM指标。

8.2. Image inpainting
传统信号表示机制与隐式神经表示(INRs)的一个关键区别在于,INRs试图建立归一化坐标与信号值之间的连续隐式函数关系。这种关系的泛化能力在很大程度上取决于所使用的激活函数类型。MIRE通过探索其字典来寻找与给定信号和任务最匹配的激活原子,无论具体任务是什么,都始终优于所有INR基线。

我们在使用整个Kodak数据集进行图像修复任务的全面评估中清楚地证明了这一点。图4显示了所有方法的PSNR变化。如图所示,MIRE在数据集中的每张图像上都始终实现了最高的准确性指标。样本修复结果展示在图12中。第一列代表真实图像,而第二列显示了文本遮罩图像。使用的文本遮罩包含不同的字体和大小,且有重叠部分,并且这个遮罩被应用到了整个数据集。这给INRs恢复原始信号带来了重大挑战。然而,正如所见,MIRE以最高的准确性恢复了原始图像。此外,MIRE没有表现出过度拟合训练数据的倾向,也没有倾向于产生缺乏快速变化成分的低通信号表示。数据集的平均PSNR在表2中呈现。此外,还使用不同的文本遮罩进行了另一个图像修复实验,结果如图13所示。在这个实验中,使用了具有不同字体大小的随机生成文本遮罩。从结果中可以看出,MIRE是唯一实现最高PSNR和SSIM值的架构,表明与现有INRs相比,它具有最佳的恢复效果。

8.3. Occupancy fields
图14展示了完整的解码占用场以及真实占用场。MIRE始终能够生成与真实占用场最为接近的占用场。这一能力归功于MIRE能够为每个给定的信号找到最优的激活序列。
8.4. Neural radiance fields
除了第4.4节中提供的新颖视图外,图15和图16中还分别提供了来自不同视角和位置的新颖视图,适用于Chair和Hotdog数据集。
9. Explanations
9.1. Pseudo code of MIRE
为了更好地理解 MIRE,我们在算法 1 中提供了其伪代码。需要强调的是,MIRE 提供了扩展和压缩其字典的灵活性。这意味着可以根据需要在 MIRE 字典中添加或删除元素。例如,如果我们删除除 Gabor 小波之外的所有激活原子,MIRE 会转换为 WIRE,但需要进行层级训练。

9.2. Spatial domain variation
在图17中,展示了MIRE中使用的七个激活原子,它们展示了空间域的变化。这些激活函数包括Sinc、Raised Cosine、Root Raised Cosine、Prolate Spheroidal Wave Function (PSWF)、Gabor小波、正弦波和高斯函数。这些滤波器的多样性使得MIRE框架能够捕捉从锐利边缘到平滑过渡、周期性模式和局部细节的广泛特征。这种多样性确保了网络能够有效地表示不同的结构,使该方法具有高度的适应性。
9.3. How does MIRE differ from baselines?
MIRE的字典由七个激活函数组成,其中三个,即正弦波、高斯和Gabor小波,在其他研究中已经介绍过。这自然引发了MIRE与这些基线方法的区别在哪里的问题。关键区别在于激活函数参数的初始化。尽管早期的研究使用了这些相同的激活函数,但它们的参数(例如正弦函数中的α和β,如主论文第3.2节所述)通常是通过为每个特定的INR应用进行穷举网格搜索来微调的。相比之下,MIRE将每个激活函数的参数初始化为随机值或其基本配置(例如,对于正弦波,α = 1和β = 0)。正如主论文第4.5节所示,当基线模型(在整个网络中使用单一激活函数)使用这些配置进行初始化时,它们通常无法达到相当的性能。因此,与这些基线方法不同,MIRE不依赖任何预优化的激活函数参数,提供了一种更灵活和稳健的方法。
9.4. Robustness of MIRE to random initializations
这一节直接与第4.6节相关,该节详细讨论了额外的参数。此外,我们还提供了一个偏向数学的解释,说明为什么MIRE对随机初始化具有鲁棒性。相应的结果如表3所示。我们这样解释鲁棒性:
更大的解空间:对于传统的INR(如SIREN),精心初始化是必要的,这限制了INR的表达能力。为每一层选择适应性的激活函数可以克服这一限制,因为优化过程将自动从可用的字典中为每个阶段选择最合适的激活函数,无论初始条件如何。
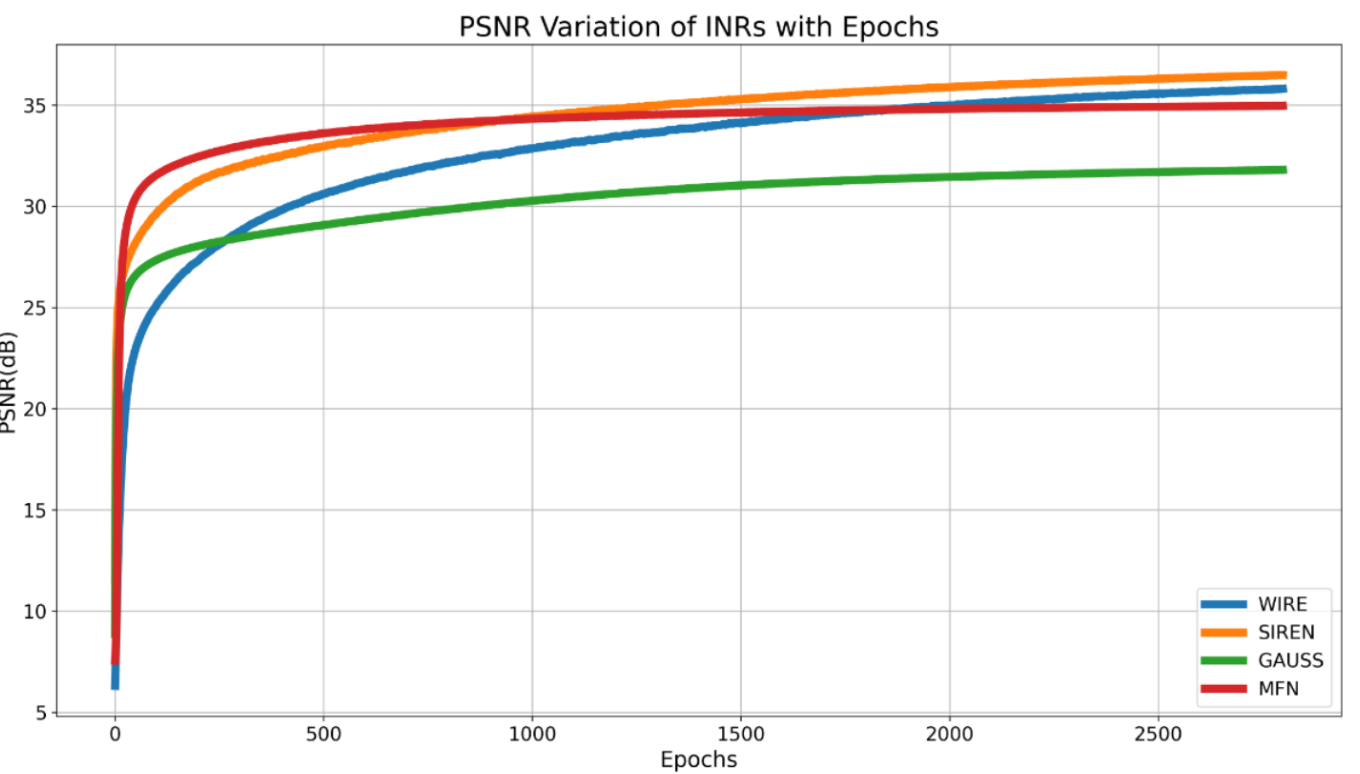
9.5. Total and effective number of epochs and learning curves
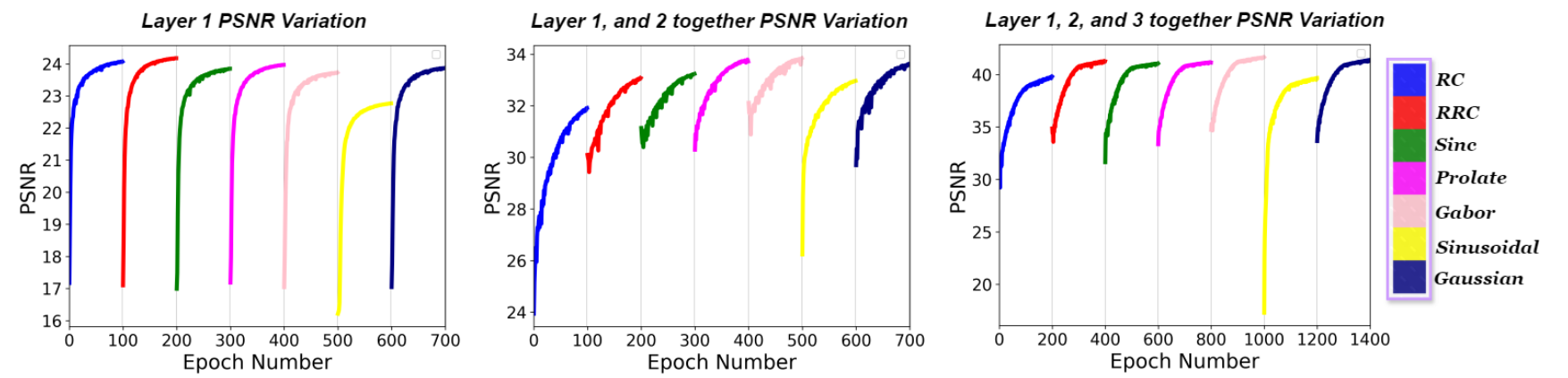
与其他隐式神经表示(INRs)相比,MIRE的总训练周期数由字典的大小决定。由于MIRE可以适应任何字典大小,让我们假设字典包含k个激活函数。为了简化,考虑一个具有三个隐藏层的模型。如果每个激活函数在第一、第二和第三层分别训练x1、x2和x3个周期,那么总搜索周期数由k × x1 + k × x2 + k × x3给出。在我们的表示实验中,我们设置x1 = 100,x2 = 100,x3 = 200。图18显示了Kodak数据集中第三张图像的训练图。对于图像表示任务,我们使用了七种不同的激活函数,总共2800个周期。为了确保公平比较,所有其他基线模型都训练了k × (x1 + x2 + x3)个周期。基线模型的收敛图显示在图19中。当涉及到MIRE时,假设字典大小为k个原子和n层,让我们假设在第i层,MIRE训练了x_i个周期。从完整的周期集合 中,MIRE仅使用
个有效周期提取特定于信号的激活序列,因为每层只需要一个激活函数,无需对激活函数参数进行详尽的网格搜索。
10. Ablation studies
10.1. Effect of network hyperparameters
已经进行了一项研究,以调查隐藏节点数量、层数和学习率变化对性能的影响。图20左侧的图表显示了隐藏节点数量变化的结果。显然,无论使用多少隐藏神经元,MIRE都超过了所有现有的隐式神经表示(INRs)。这种优越性归因于MIRE基于输入信号自我优化的能力,确保最优的激活序列产生比预先优化的INRs更优越的结果。
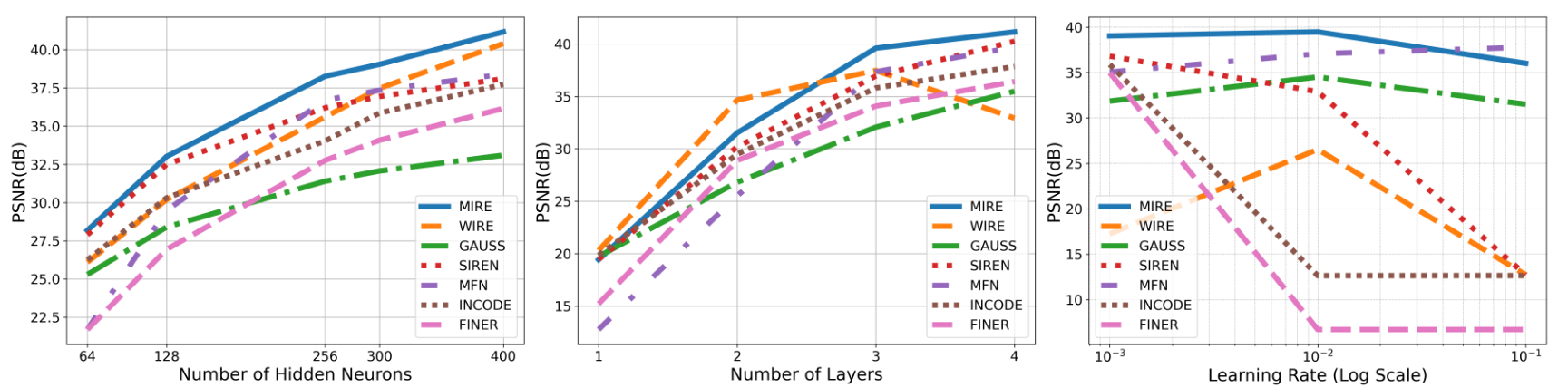
图20中间的图表描绘了层数对峰值信噪比(PSNR)的影响。可以看出,MIRE仅用一到两个隐藏层就表现出异常有竞争力的PSNR指标。这种性能与其他INRs形成鲜明对比,后者从一开始就已经为收敛量身定制了激活参数。然而,MIRE从随机参数初始化开始,突出了其在自我优化以减少显式和隐式表示之间损失方面的效率。当模型配置扩展到包括三个隐藏层时,MIRE适应和定制其方法以适应特定信号的能力使其能够超越所有现有的INRs,展示了其强大的优化能力。
最后,图20右侧的图表展示了MIRE在对数刻度学习率下的性能。可以看出,MIRE表现出强劲的性能,在低至10^-3的学习率下保持约40分贝的高PSNR。即使学习率提高一个数量级到10^-2,MIRE也能够维持相对较高的PSNR。然而,当学习率进一步增加到10^-1时,PSNR明显下降,尽管它仍然比除MFN外的每个基线性能更好。另一方面,WIRE对学习率表现出显著的敏感性。它在10^-2的学习率下达到峰值PSNR,但随着学习率的进一步增加,其性能急剧下降。这表明WIRE的最佳学习率范围较窄,其性能在这个范围之外迅速恶化。SIREN也表现出性能下降,但与WIRE相比,其行为更为稳定。随着学习率的增加,SIREN的PSNR持续下降,从未达到MIRE或甚至WIRE观察到的峰值。可以得出结论,MIRE在更广泛的学习率范围内保持高PSNR值的能力突出,突显了其鲁棒性。
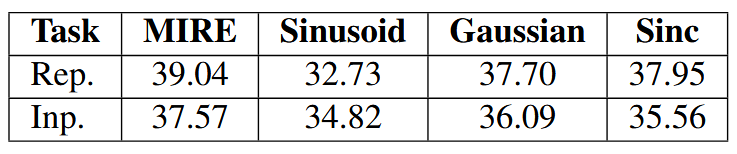
10.2. Effect of restricting the dictionary to one atom
通过将字典限制为仅包含单个原子(即 k = 1)来进行进一步的消融。观察结果如表4所示。
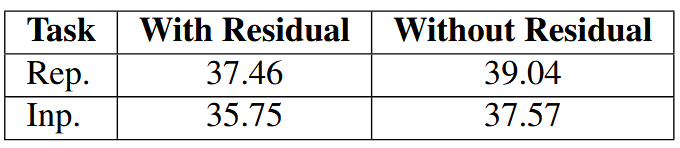
10.3. Effect of residual connections
还研究了残余连接的影响。结果见表5
10.4. Effect of weight initialization
在最近的隐式神经表示(INR)文献中,已经有人提出,配备空间频率紧凑激活函数的INR通常对权重初始化机制不太敏感,这与使用正弦激活函数的情况不同。本研究中呈现的所有实验结果都是通过Pytorch的默认权重初始化方案获得的。在这个权重初始化过程中,标准差(stdv)被定义为输入单元数的平方根的倒数。具体来说,stdv =
,其中
代表线性层中的特征数或输入维度。然后,层的权重通过从范围[-stdv, stdv]内的均匀分布中抽取权重矩阵W的每个元素来初始化,即,
![]()
这种初始化策略有助于通过防止训练早期阶段出现大梯度来保持权重足够小,从而确保稳定的学习。然而,由于不同的权重初始化往往导致网络的不同训练动态,我们检查了MIRE在不同权重初始化方案下的性能和获得的激活序列。为了这个实验,我们使用了主论文中的Parrot图像。获得的结果如表6所示。
如表6所示,当网络的权重初始化机制改变时,激活序列会发生变化。这可以归因于MIRE从给定的权重初始化方案开始优化网络,试图向损失景观中的局部最小值导航。当初始权重的分布发生显著变化时,它会影响优化轨迹。网络的参数是基于从这个起点计算的梯度进行调整的,训练动态根据初始条件遵循不同的路径。由于损失景观可能包含多个局部最小值,网络采取的优化路径可能会有所不同。这解释了为什么不同的激活函数序列对于不同的权重初始化是最优的——每种初始化都导致网络探索损失景观的不同部分,网络相应地调整其激活以最小化损失。因此,可以得出结论,Pytorch的默认权重初始化对于MIRE来说是最有效的。
10.5. Effect of positional encoding
位置嵌入方案通常在隐式神经表示(INRs)中用作坐标变换的方法。这种技术类似于频率调制机制,能够在信号中嵌入高频。在我们的研究中,我们评估了在MIRE中加入这种坐标变换时的性能。图21的左侧显示了使用位置嵌入的MIRE获得的解码表示,而右侧显示了没有位置嵌入的MIRE的结果。鉴于MIRE采用了第9.1节中概述的顺序训练方法,它允许观察每一层的解码图像。这些图像在图21中被称为“第1层”、“第2层”和“第3层”,展示了每个阶段的结果。对选定图像的比较显示,将位置嵌入整合到MIRE中,对于第一层和第二层都比没有位置嵌入的标准MIRE有改进。然而,在确定了前两层的最佳激活后,引入第三层表明,没有位置嵌入的标准MIRE优化了多层感知机(MLP),使其在该图像上的表现优于使用位置嵌入的MIRE。

11. Experimental setup
我们的数值实现使用了PyTorch框架和Adam优化器,基础学习率为0.001,每个训练周期后衰减0.1。所呈现的结果是通过使用具有三个隐藏层的MLP获得的,每层包含300个隐藏节点,激活参数从0到1之间的均匀分布中抽取,或从每个激活的基本配置中抽取。为了性能评估,我们对图像使用了峰值信噪比(PSNR)和结构相似性指数测量(SSIM),对占用场使用了交并比(IoU)。