Swift-Mapping: Online Neural Implicit Dense Mapping in Urban Scenes 论文学习记录
这篇论文的主要创新点是:
- 提出使用神经隐式八叉树来高效的表示城市场景
- 设计了建图框架来高效的管理八叉树
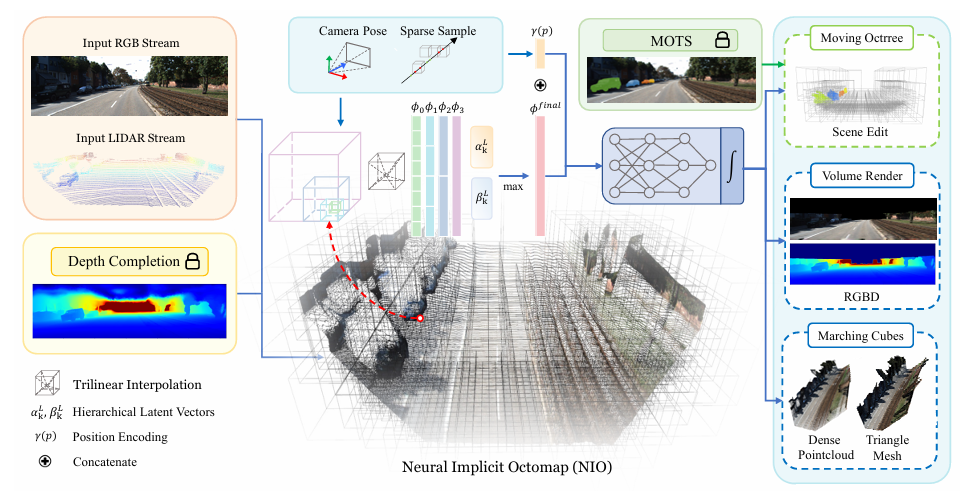
1. Neural Implicit Octomap
NIO的feature有两个,深度和颜色,对深度和颜色使用独立的MLP分别表示几何和图像信息
1.1 Octree-based Voxel Grid
定义八叉树有KKK层,最小的体素分辨率为lll
基于八叉树的结构分配体素,只有在kkk层的子体素k−1k-1k−1层中,有超过两个k−1k-1k−1层子体素有效时,第kkk层体素标记为有效
在连续建图过程中,如果点云对应的点已经关联的有效体素,就不用做任何操作,
如果该点没有关联任何无效体素,说明这是新的区域,就随机初始化隐特征向量,增加到八叉树的结构中
这里个人理解,如果点云数据关联到无效体素,无效体素一般是天空、空气,则很可能是点云数据的误差,正常来所是不会出现的
八叉树结构可以促进帧之间的信息传递,因为相邻帧更容易采集到相同的元素,这里个人理解原因是,对于自动驾驶场景,帧之间的数据是快速变化的,所以基于NICE-SLAM基于体素的特征网格,相邻帧之间可能没有相同的元素,而因为八叉树有远景的数据,即使快速移动,相同的场景即使没有出现,也可能属于同一个远景,可能连接在同一个远景上面,这样是有助于帧之间的信息传递的
1.2 Distance Adaptive Voxel Initialization
这里自适应的距离采用本质上是近大远小的原则,如果假设最大采用距离dmax=100md_{max}=100mdmax=100m,假设八叉树的最大层数K=3K=3K=3
根据论文所说,最大距离对应的分辨率是l∗2K−1l*2^{K-1}l∗2K−1,且kkk层包括从距离2k−K∗dmax2^{k-K}*d_{max}2k−K∗dmax到2k−K+1∗dmax2^{k-K+1}*d_{max}2k−K+1∗dmax,可以列出以下表格,特征维度的计算在Hierarchical Latent Vector Extraction部分提到,kkk层的隐向量维度是k−1k-1k−1的二倍
| kkk | 单个体素数量 | 自适应距离 | 该层的特征维度 | 分辨率 |
|---|---|---|---|---|
| k=0k=0k=0 | 64个 | 12.5−25m12.5-25m12.5−25m | DDD | lll |
| k=1k=1k=1 | 8个 | 25−50m25-50m25−50m | 2D2D2D | 2l2l2l |
| k=2k=2k=2 | 1个 | 50−100m50-100m50−100m | 4D4D4D | 4l4l4l |
2. Dense Mapping Using Hierarchical Latent Vectors
iMAP通过设置关键帧列表来缓解在MLP训练过程中的灾难性遗忘,Nice-SLAM通过优化特征网格,固定MLP来缓解灾难性遗忘,在此篇论文中,同时优化MLP和网格数据,通过引入分层隐向量来缓解灾难性遗忘
2.1 Sparse Hybrid Voxel Sampling
采集到的深度信息经常有很多噪声,在这篇论文中,采用从LIDAR的稀疏深度输入,通过CompletionFormer进行深度的填充,得到稠密深度
在光线上混合采样策略和Nice-SLAM相同,都是均匀采样一部分,再在深度附近采样一部分
但是由于NIO是稀疏的,所以不是所有的采样点都会对应有效的体素,那怎么计算一个采样点是否在有效体素内呢?
论文中给出的方法是大量采样,对于采集到的点计算其三维坐标,论文中提到的除法运算就是,三维坐标点除以分辨率,取整后就可以得到这个采样点落在了哪个体素中,这样就可以通过简单的方法判断采样点是否有效
对于落在有效体素中的采样点,就会做体征提取和MLP,参与到之后的优化中,而对于落在无效体素中的采样点,说明这个采样点是空气,给其特征赋予0,不参与MLP和优化,只参与之后的体渲染(volume rendering)
2.2 Hierarchical Latent Vector Extraction
在2.1之后,每个有效点都和有效体素对应之后,ϕkd(p)\phi^d_k(p)ϕkd(p)和ϕkc(p)\phi^c_k(p)ϕkc(p)用来提取每个层中每个有效体素的深度/颜色特征
在获取每层的特征之后,结合上表中维度的不同,通过控制和αk\alpha_kαk,βk\beta_kβk相乘的次数,来保证每一层的特征维度都是一样的,例如,对于k=0k=0k=0,此时维度为DDD,最后的特征维度就是8∗1D8*1D8∗1D,而k=1k=1k=1,此时维度为2D2D2D,最后的特征维度就是4∗2D4*2D4∗2D,以此类推
之后对于每层的特征,最大池化,获取最终的特征
2.3 MLP Decoder
MLP获得占有率和颜色,通过体渲染得到深度和RGB,计算和真实值的L2L2L2误差,最后联合优化MLP,体素的特征,α\alphaα,β\betaβ
3. Modeling Dynamic Urban Scenes
论文中也提出了移动八叉树
使用MOTSFusion获得每一帧中每个交通工具的语义标签
通过公式,算出这个移动的物体对应的体素index和3D点云,通过移动物体的体素和对应的特征来实现车辆的移动
4. Experiments
- 和iMAP,Nice-SLAM,比室内重建的能力,评估参数:Acc, Comp. Ratio,FPS
- 和两个离线的方法,还有两个在线的方法比较室外场景重建,评估参数:loss,PSNR
- 和Nice-SLAM比较PSNRtrainPSNR_{train}PSNRtrain等参数,证明其没有灾难性遗忘
- 通过不同频率的对数据集中的帧采样模拟快速自运动采集到的数据,通过和Nice-SLAM比PSNR证明其有快速自运动的能力
消融:
- 八叉树的深度,随着KKK的增加,性能提高
- α\alphaα,β\betaβ:把α\alphaα置1,β\betaβ随机,通过比较PSNR证明α\alphaα,β\betaβ是有效的