【VLNs篇】11:Dynam3D: 动态分层3D令牌赋能视觉语言导航中的VLM
一. 论文的摘要介绍
| 项目 | 内容 |
|---|---|
| 研究主题 | 具身智能的视觉语言导航 (Vision-and-Language Navigation, VLN) |
| 核心问题 | 现有的基于视频的VLN模型在真实3D环境中存在三大挑战:1. 对3D几何和空间语义理解不足;2. 缺乏大规模探索和长期环境记忆的能力;3. 难以适应动态变化的环境。 |
| 提出方法 | Dynam3D:一个动态、分层的3D表示模型,用于赋能视觉语言模型(VLM)进行导航。 |
| 核心创新点 | 1. 动态分层3D表示:构建了一个“补丁-实例-区域”三层级表示,从精细的几何细节到宏观的场景布局,全面理解3D环境。 2. 实时动态更新:能够在线编码3D实例,并通过视锥剔除(Frustum Culling)等策略实时更新场景表示,移除过时信息,适应环境变化(如物体被移动)。 3. 多层次特征融合与对齐:将3D表示与语言语义进行对齐,并通过特征蒸馏增强泛化能力,使模型能更好地理解导航指令。 4. 专用的3D-VLM框架:将动态生成的3D令牌(补丁、实例、区域)作为视觉输入,送入一个大型语言模型进行多模态推理和动作预测。 |
| 实验与结果 | 在R2R-CE, REVERIE-CE, NavRAG-CE等多个标准VLN基准测试中取得了业界最佳(SOTA)性能。在预探索、终身记忆和真实世界动态环境的机器人实验中也展示了卓越的性能和鲁棒性。 |
二. 具体实现流程
Dynam3D框架的实现流程可以分解为两个主要部分:动态3D场景表示的构建与更新 和 基于该表示的导航动作预测。
输入 (Input):
- 实时传感器数据: 带有位姿信息(位置和朝向)的单目RGB图像和深度图像。
- 任务指令: 自然语言指令 (例如:“去厨房把微波炉里的面包拿给我”)。
- 历史信息: 智能体最近执行过的动作历史。
处理流程 (Processing Pipeline):
-
第1层:补丁特征编码 (Patch-Level Encoding)
- 提取2D特征: 使用预训练的CLIP视觉编码器从输入的RGB图像中提取密集的2D补丁级特征。
- 3D投影: 结合深度图和相机位姿,将每个2D补丁特征投影到3D世界坐标系中,形成一个带特征的3D点云,即“补丁特征点”。
- 动态更新: 这个3D点云是动态的。当智能体移动并获得新视角时,会使用视锥剔除 (Frustum Culling) 策略:
- 移除在新视图中被遮挡或过时的旧特征点。
- 添加从新图像中提取并投影的新特征点。
-
第2层:实例表示构建 (Instance-Level Representation)
- 2D实例分割: 使用FastSAM模型对RGB图像进行快速实例分割,获得每个物体的2D掩码。
- 特征聚合: 将位于同一2D掩码内的所有补丁特征聚合起来,形成该物体的2D实例级特征向量。
- 2D到3D实例匹配:
- 引入一个合并判别器 (Merging Discriminator)。
- 对于每个新的2D实例,判别器会将其与数据库中已有的3D实例进行比较(基于特征相似度和几何距离)。
- 如果匹配成功:将新的2D实例信息合并到对应的3D实例中,更新其表示。
- 如果未匹配:创建一个新的3D实例。
- 这样可以确保即使从不同角度观察,同一个物体也能被识别并拥有一个统一的、持续更新的3D表示。
-
第3层:区域表示构建 (Zone-Level Representation)
- 空间划分: 将整个3D世界空间划分为多个固定大小的立方体网格(区域)。
- 实例聚合: 将位于同一个立方体区域内的所有3D实例特征聚合起来,形成该区域的宏观语义表示(例如,这个区域是“厨房”或“卧室”)。
-
为VLM准备视觉输入
- 生成多层次3D令牌:
- 补丁令牌: 从补丁特征场中渲染出智能体当前视角的360度全景特征图。
- 实例令牌: 获取当前场景中所有3D实例的特征向量。
- 区域令牌: 获取包含这些实例的区域的特征向量。
- 这些令牌都附带了相对智能体的位置编码信息(如相对坐标、距离、方向)。
- 生成多层次3D令牌:
-
3D-VLM推理与动作预测
- 整合输入: 将上述三种3D令牌、自然语言指令令牌、以及历史动作令牌拼接在一起,作为输入送入一个大型视觉语言模型 (LLaVA-Phi-3-mini)。
- 多模态推理: VLM在这些丰富的、结构化的3D信息和语言指令上进行推理,理解“我应该去哪里”以及“目标是什么”。
- 预测动作: 模型最终输出一个具体的、原子化的导航动作。
输出 (Output):
- 一个原子导航动作,例如:
Turn left 30 degree(左转30度)Forward 50 cm(前进50厘米)Stop(停止,表示任务完成)
数据流 (Data Flow):
RGB-D图像 + 位姿 → CLIP编码 → 2D补丁特征 → 3D投影 → 动态3D补丁点云
RGB图像 → FastSAM → 2D实例掩码 → 聚合 → 2D实例特征 → 合并判别器 → 动态3D实例表示 → 聚合 → 动态3D区域表示
(3D补丁/实例/区域令牌 + 指令 + 历史动作) → 3D-VLM → 导航动作
这个流程形成了一个闭环:智能体执行输出的动作,移动到新位置,获得新的RGB-D图像,然后重复整个流程,直到任务完成。
三. 白话版解说
想象一下,你想让一个机器人帮你去家里拿个东西,比如你对它说:“去书房,帮我把桌上那本蓝色的书拿过来。” 这对我们来说很简单,但对机器人来说却是个巨大的挑战。
以前的机器人是怎么做的?—— 像个“路痴”摄影师
过去的机器人导航,很多时候像一个只顾着拍视频的“路痴”。它一边走一边用摄像头录像,然后把视频片段喂给一个很聪明的大脑(也就是语言模型)。这个大脑尝试从视频里理解:“哦,我好像看到了书房的门,指令里也提到了书房,我应该往那边走。”
这种方法的问题很明显:
- 没有3D概念:视频是平面的。机器人很难真正理解房间的立体结构。它分不清一张桌子有多长,一个走廊有多宽,很容易撞墙或者迷路。
- 记性差:它只记得刚刚路过的画面,对于整个家的布局没有一个整体的“心智地图”。如果你让它去一个去过很多次的地方,它可能还是会像第一次去一样到处乱看。
- 反应迟钝:如果家里环境变了,比如你把一张椅子从客厅挪到了书房门口挡住了路,这个机器人可能就“死机”了,因为它看到的和它“记忆”中的视频片段对不上。
这篇论文提出的新方法:Dynam3D —— 打造一个拥有“3D记忆宫殿”的机器人
这篇论文里的机器人(Dynam3D)就聪明多了。它不再是简单地“看视频”,而是在脑中实时构建一个生动、立体的3D世界模型,就像在玩《我的世界》(Minecraft)一样。
它是怎么做到的呢?分三步走,建立一个从微观到宏观的“记忆宫殿”:
-
第一层:像素级的“乐高积木” (补丁层)
机器人每看到一帧画面,就会把它拆解成无数个微小的“视觉补丁”,就像五颜六色的乐高积木。然后,它利用深度摄像头(能感知距离的眼睛)知道每一块“积木”在三维空间中的精确位置。这样,它眼前的世界就变成了一堆有空间坐标的彩色积木。 -
第二层:拼装成“物体模型” (实例层)
光有积木还不够,机器人需要知道这些积木拼成了什么。它会智能地把属于同一个物体的积木组合起来。比如,它会把所有属于“椅子”的积木块聚在一起,形成一个完整的“椅子”模型。最厉害的是,无论它从哪个角度看这把椅子,它都知道“这还是刚才那把椅子”,而不是一个新的东西。 -
第三层:划分出“功能区域” (区域层)
当机器人识别出房间里有“床”、“衣柜”、“床头灯”这些物体模型后,它会把它们所在的这一大块空间标记为“卧室区域”。同样,看到“冰箱”、“炉灶”、“微波炉”的区域,它就会标记为“厨房区域”。这样,它就对整个家的功能布局有了宏观的认识。
Dynam3D最酷的地方:这个“记忆宫殿”是活的!
这个机器人最牛的地方在于它的记忆是动态更新的。
想象一下,在机器人走向书房的过程中,你悄悄地把原来在桌上的那本蓝色书放到了旁边的书架上。
- 老式机器人:它可能会走到桌子前,发现书不见了,然后就彻底懵圈,任务失败。
- Dynam3D机器人:它会实时更新它的3D地图。当它再次看到桌子时,它会“擦掉”脑中地图里桌上的书,并注意到书架上多了一本蓝色的书。它的“记忆宫殿”会立刻更新。当它的大脑(语言模型)结合指令“找蓝色的书”和更新后的地图时,它会立刻明白:“哦!书被移动到书架上了!” 然后转身走向书架。
最终决策
最后,机器人把这个丰富、动态的3D地图,连同你的语言指令(“去书房找蓝色的书”),一起输入它强大的大脑。大脑综合所有信息,轻松地规划出最佳路径,并精确地输出下一步动作:“好的,现在我应该左转45度,然后向前走2米。”
个人观点和理解
在我看来,这篇论文不仅仅是对现有技术的一次小修小补,它代表了具身AI导航思路的一个重要转变:从被动的“模式匹配”(在视频流中找线索)转向主动的“世界建模”(构建和理解一个动态的3D世界)。
这个思路非常接近人类导航的方式。我们走路时,脑中也有一个关于环境的3D心智地图,我们会不断更新它。我们知道物体是立体的,有固定的身份,即使我们换个角度看它也不会变。我们还知道环境是会变化的。Dynam3D正是模拟了人类的这种高级认知能力。
这项工作的真正价值在于它大大增强了机器人在真实、非结构化、动态环境中的鲁棒性。实验室里的环境是干净、静态的,但真实世界充满了不确定性:人会走动,东西会被挪位,光线会变化。一个不能适应这些变化的机器人,永远只能是实验室的玩具。Dynam3D通过其动态更新机制,为机器人走出实验室、进入我们日常生活提供了非常坚实的一步。
当然,它也有局限性,比如它还不能像人一样进行复杂的对话和任务调整。但它所展示的“构建动态世界模型”的核心思想,无疑是通向更通用、更智能的家用机器人或自主系统的关键所在。这不仅仅是让机器人“会走路”,更是让它“理解它所在的世界”。
四. 论文翻译
摘要
视觉语言导航(Vision-and-Language Navigation, VLN)是一项核心任务,其中具身智能体利用其空间移动能力,根据自然语言指令在3D环境中导航至指定目的地。最近,具有强大泛化能力和丰富常识知识的视频-语言大模型(Video-VLMs)在应用于VLN任务时表现出色。然而,这些模型在应用于真实世界的3D导航时仍面临以下挑战:1) 对3D几何和空间语义的理解不足;2) 对大规模探索和长期环境记忆的能力有限;3) 对动态和变化环境的适应性差。为了解决这些限制,我们提出了Dynam3D,一个动态分层的3D表示模型,它利用与语言对齐的、可泛化的、分层的3D表示作为视觉输入来训练3D-VLM进行导航动作预测。给定带有位姿的RGB-D图像,我们的Dynam3D将2D CLIP特征投影到3D空间,并构建多层次的3D补丁-实例-区域表示,用于3D几何和语义理解,并采用动态的、逐层更新的策略。我们的Dynam3D能够在线编码和定位3D实例,并在变化的环境中动态更新它们,为导航提供大规模探索和长期记忆能力。通过利用大规模3D语言预训练和任务特定的适应性,我们的Dynam3D在包括R2R-CE、REVERIE-CE和NavRAG-CE在内的VLN基准测试中,在单目设置下取得了新的业界最佳性能。此外,关于预探索、终身记忆和真实世界机器人的实验验证了实际部署的有效性。代码可在 https://github.com/MrZihan/Dynam3D 获取。
1 介绍
视觉语言导航(VLN)任务[1–4]要求智能体整合三个核心能力:1) 理解自然语言指令,2) 探索环境并定位目标或目的地,3) 规划和执行导航动作。如图1(a)所示,最近的工作[5-7]主要集中在使用基于视频的大型模型[8-10]来开发单目VLN系统。这是因为大多数机器人都配备单目摄像头而非全景摄像头,这是一个实际的限制。这些在大型互联网数据上预训练的模型展示了强大的语言理解和多模态推理能力,从而能够有效地遵循指令并持续预测朝向目的地的导航动作。
尽管取得了这些最新进展,但一些限制仍然存在:1) 基于视频的模型难以捕捉大规模3D环境中的空间几何和语义。我们的实验表明,这严重阻碍了这些模型进行广泛探索和有效纠正错误的能力。2) 这些模型缺乏结构化场景记忆的机制。
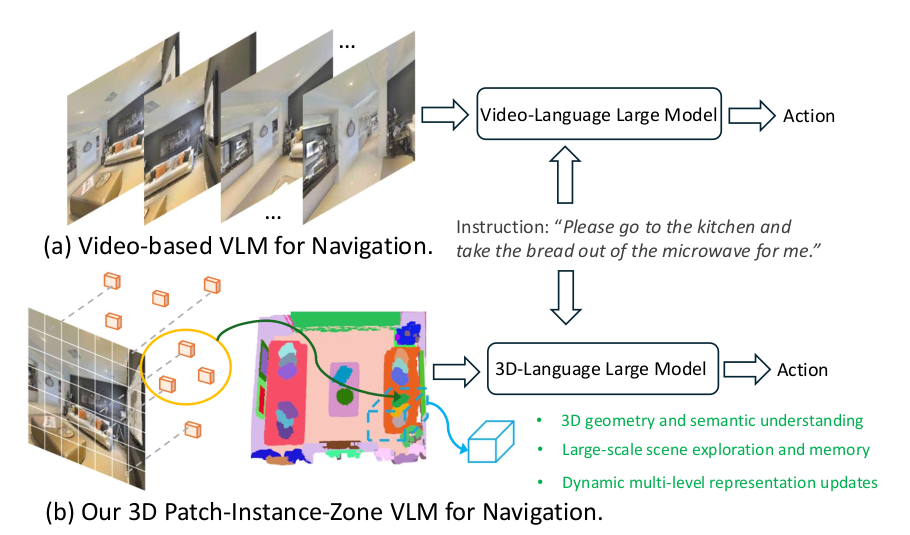
[图 1:用于单目VLN任务的不同视觉语言大模型。与之前基于视频的表示(a)相比,我们的Dynam3D(b)采用动态分层的3D表示,在空间几何和语义理解方面具有优势。]
这阻碍了利用预探索知识,并限制了终身学习的潜力。3) 从历史帧派生的表示不足以应对动态变化的3D场景,其中物体和人类的频繁移动会导致性能下降。
我们提出Dynam3D来缓解上述限制。如图1(b)所示,我们的Dynam3D是一个用于视觉语言导航的3D语言模型,具有动态分层的3D表示。为了编码3D环境,我们使用CLIP提取补丁级别的2D特征,并通过深度图和相机位姿将它们投影到3D空间。我们的Dynam3D使用FastSAM生成2D实例掩码,并聚合每个掩码内的补丁特征,形成实例级别的表示。一个3D实例合并判别器根据几何和语义将2D实例与现有的3D实例对齐,以实现3D实例表示的动态更新。与之前专注于掩码精度的在线3D分割方法不同,我们的Dynam3D主要通过大规模3D语言预训练将实例表示与CLIP的语义空间对齐,以显著改善导航目标定位和3D场景理解。
此外,我们的Dynam3D在空间区域内聚合3D实例特征,以促进对大规模环境的理解。因此,这使得模型能够高层次地理解布局,例如卧室、厨房等,这是仅靠实例级特征无法捕捉的。我们的Dynam3D通过这种分层的补丁-实例-区域表示动态地更新场景:当新的RGB-D观测数据到达时,过时的补丁特征被移除,新的特征被投影并在表示层(补丁-实例-区域)之间传播以适应变化。这些特性使我们的Dynam3D能够维持一个终身且动态的环境记忆,这可以显著提高在真实世界部署中的导航性能。
我们进一步引入了一个可泛化的特征场模型,以在智能体中心的全景范围内渲染3D补丁特征,从而丰富局部几何和语义感知。这些渲染出的3D补丁特征与实例和区域表示相结合,作为3D视觉语言模型(VLM)的视觉输入。给定语言指令和动作历史,3D-VLM直接预测导航动作,例如,转动θ度,前进d厘米,或停止。
总而言之,我们的主要贡献包括:
- 我们提出了Dynam3D,一个多层次的补丁-实例-区域3D表示模型,它在动态环境中执行在线3D实例和区域级别的编码以及实时的分层更新。
- 我们引入了一个3D视觉语言模型,该模型整合了来自可泛化特征场的3D补丁特征和我们Dynam3D的3D实例-区域特征。这平衡了导航规划所需的精细几何结构和全局空间布局。
- 我们的单目VLN系统在包括R2R-CE、REVERIE-CE和NavRAG-CE在内的基准测试上取得了业界最佳性能。结果还展示了我们在预探索、终身记忆和真实世界实验中的强大能力。
2 相关工作
视觉语言导航 (Vision-and-Language Navigation, VLN)。VLN [1, 3, 2, 15–18] 要求智能体理解复杂的自然语言指令并导航到描述的目的地。与早期主要在离散环境模拟器中训练和评估模型的工作[15–17, 19, 20](即,在预定义的导航连接图上移动,配备全景RGB-D相机)形成对比,最近的研究越来越强调在连续环境模拟器[22–26]中的导航以及单目VLN系统在真实世界中的部署。对于连续环境模拟器中的单目VLN,智能体仅配备一个前向的单目RGB-D相机,并使用低级动作进行导航。为了利用大型模型的语言理解和常识推理能力,一些近期工作[29–31, 28]已将2D-VLM应用于VLN任务,取得了显著的性能提升。诸如NaVid、Uni-NaVid和NaVILA等扩展工作进一步利用基于视频的大型模型来构建具有强大真实世界适用性的高性能单目VLN系统。然而,基于视频的表示仍然存在固有限制。例如,它们难以捕捉精细的几何语义和理解大规模的空间布局,这反过来限制了它们在目标定位和路径规划方面的能力。据我们所知,我们的Dynam3D是第一个通过使用3D-VLM在未见过的动态环境中执行单目VLN任务,从而有效解决以往基于视频模型固有局限性的方法。
3D视觉语言模型 (3D Vision-Language Models)。受2D-VLM [32, 33, 8–10]发展的启发,近期工作整合了3D输入,如点云[34–36]或多视图图像[37–39],以实现3D-VLM的3D场景推理能力。这些方法主要在场景表示上有所不同:LL3DA直接编码全场景点云;LEO和Chat-Scene将场景点云分解为对象级片段并编码相应特征。3D-LLM和Scene-LLM从多视图图像开始,应用2D对象分割,并将CLIP特征聚合成像素对齐的3D点。LLaVA-3D建立在预训练的2D-VLM之上,通过多视图输入和3D位置嵌入将2D补丁嵌入到3D体素中。这使得模型能够快速适应3D任务,同时保持强大的2D感知能力。然而,当前的3D-VLM在诸如具身导航等大规模未见和动态任务中面临着根本性挑战。全场景点云或基于体素的表示对于在未见环境中进行实时推理是不切实际的。现有模型缺乏增量更新机制,这使得在动态环境中修改或丢弃过时的场景信息变得困难。此外,它们在全局空间布局和精细几何语义之间的计算权衡方面存在困难。在这种背景下,我们提出了Dynam3D,一个更适合此类动态具身任务的3D-VLM模型。
3 我们的方法
概述。图2展示了我们用于视觉语言导航的Dynam3D框架。该框架将带有位姿的单目RGB和深度图像作为输入,并输出原子导航动作,如转向、前进、停止等。我们的Dynam3D维护一组补丁特征点来编码可泛化的特征场,用于渲染智能体的全景3D补丁令牌。此外,我们的Dynam3D逐层编码和更新3D实例表示和大规模立方体区域表示,以实现多层次的场景理解和目标定位(参见第3.1节)。这些多层次的3D令牌、导航指令和历史动作随后被送入一个3D-VLM中,用于下一个动作的预测(参见第3.2节)。
3.1 动态分层3D表示模型
我们首先设计并预训练一个多层次的3D表示模型,以获取与语言对齐的3D表示,涵盖精细细节和全局布局。
编码补丁特征点 (Encoding the Patch Feature Points)。为了记忆3D环境的几何和语义,我们遵循HNR和g3D-LF的方法,使用CLIP-ViT-L/14@336px作为RGB图像的编码器,来提取2D补丁特征 {gt,i ∈ ℝ768}Ii=1。其中,gt,i表示从智能体观察到的第t帧中提取的2D特征图的第i个补丁特征,并且I = 24 × 24。这些补丁特征 {gt,i}Ii=1 随后利用深度图被投影到相应的3D世界坐标 {Pt,i}Ii=1 中。对于每个特征gt,i,其观测到的水平朝向Ot,i和区域大小st,i也会被计算和存储,以增强空间表示。因此,特征点集合M可以被在线更新,如公式(1)所示:
Mt = Mt-1 ∪ {[gt,i, Pt,i, Ot,i, st,i]}Ii=1 (1)
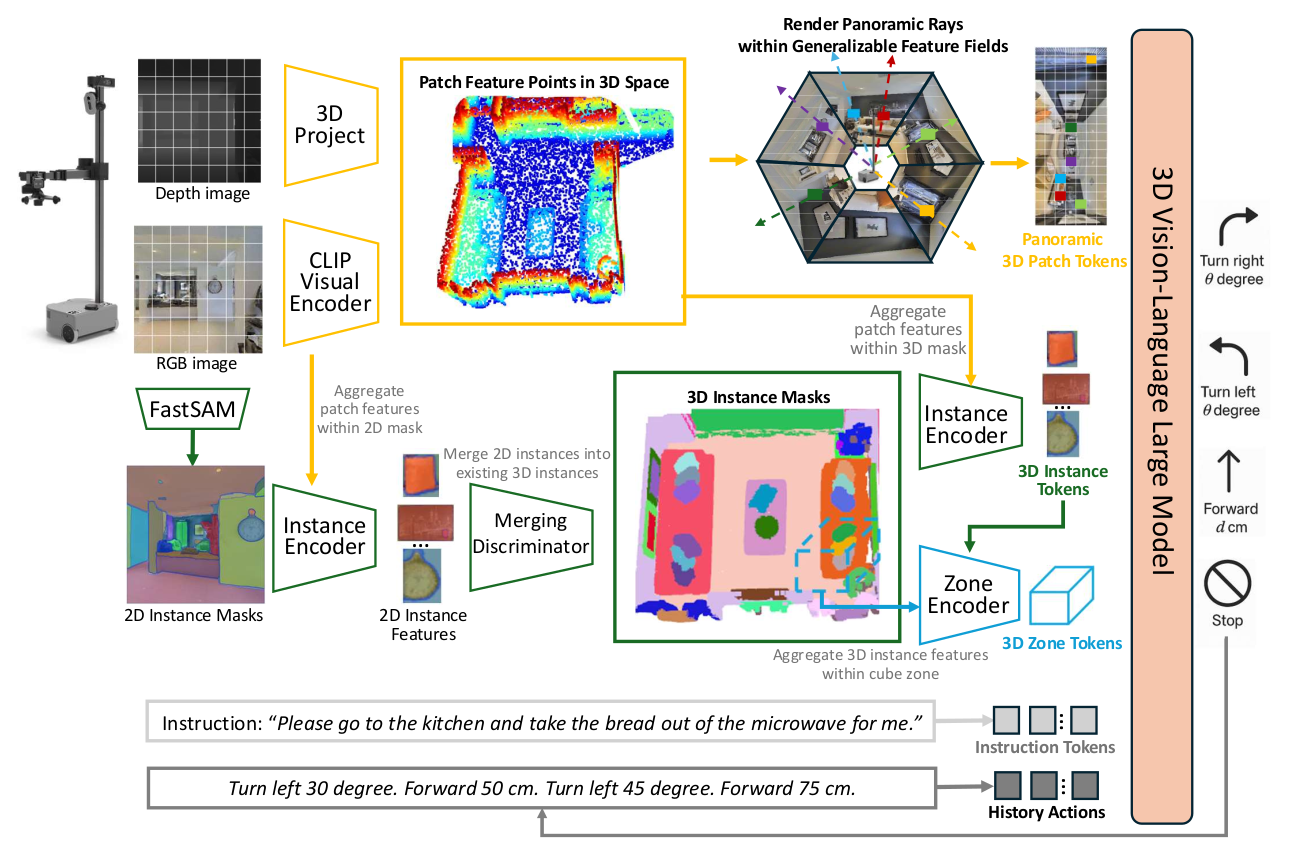
[图 2:我们Dynam3D框架的架构。我们的Dynam3D接收带有位姿的单目RGB和深度图像作为输入,并输出原子导航动作。它编码和更新多层次的3D表示,用于场景理解和目标定位。3D令牌、导航指令和历史动作被整合到3D-VLM中,用于下一个动作的预测。]
更新补丁特征点 (Updating the Patch Feature Points)。如图3所示,我们采用视锥剔除(Frustum Culling)策略来动态更新特征点集M,通过丢弃过时的特征并融入新的特征,这与先前仅简单添加新特征点而不考虑物体运动或移除的方法不同。具体来说,在获得观测到的深度图Dt ∈ ℝH×W后,视锥剔除策略使用相机位姿[R, T]和相机内参K,将每个特征点的3D世界坐标Pw ∈ M转换到该深度图的像素坐标,如下所示:
[Xc, Yc, Zc]T = R*Pw + T, [u, v]T = (1/Zc) * K * [Xc, Yc]T (2)
如果 0 < zc < min(du,v + δ, Δ),0 < u < H,并且 0 < v < W,则执行FrustumCulling(Pw)。
其中,dh,w表示深度图Dt ∈ ℝH×W中第h行第w列的深度值。当 0 < zc < du,v + δ(此处原文为 min(du,v + δ, Δ),但逻辑上应为 du,v + δ,指在物体表面之后)时,一个特征点Pw会通过FrustumCulling(·)函数从特征点集M中被移除,其中δ是一个噪声阈值,Δ是最远剔除距离。在获得RGB-D观测数据时,首先应用视锥剔除,然后添加新的特征点。
动态编码3D实例表示 (Dynamically Encoding 3D Instance Representations)。由于3D补丁特征的数量巨大,直接将其作为3D-VLM的视觉输入在计算上和经济上都是不切实际的。与体素级池化方法(例如LLaVA-3D)不同,我们的Dynam3D在3D实例级别编码特征,因为导航指令中的目标定位大多是以对象实例来描述的。如图2所示,FastSAM快速地将观测到的RGB图像分割成一组2D实例掩码。在每个掩码内,一个基于Transformer的实例编码器将相应的补丁特征 {gm}Mm=1 与位置嵌入 {pm}Mm=1 聚合到一个紧凑的实例级表示O中,并使用一个可学习的令牌q作为查询:
pm = MLP([Pm - Average({Pm}Mm=1), sm, cos(θm), sin(θm)]) (3)
O = InstanceEncoder(q, {gm, pm}Mm=1)
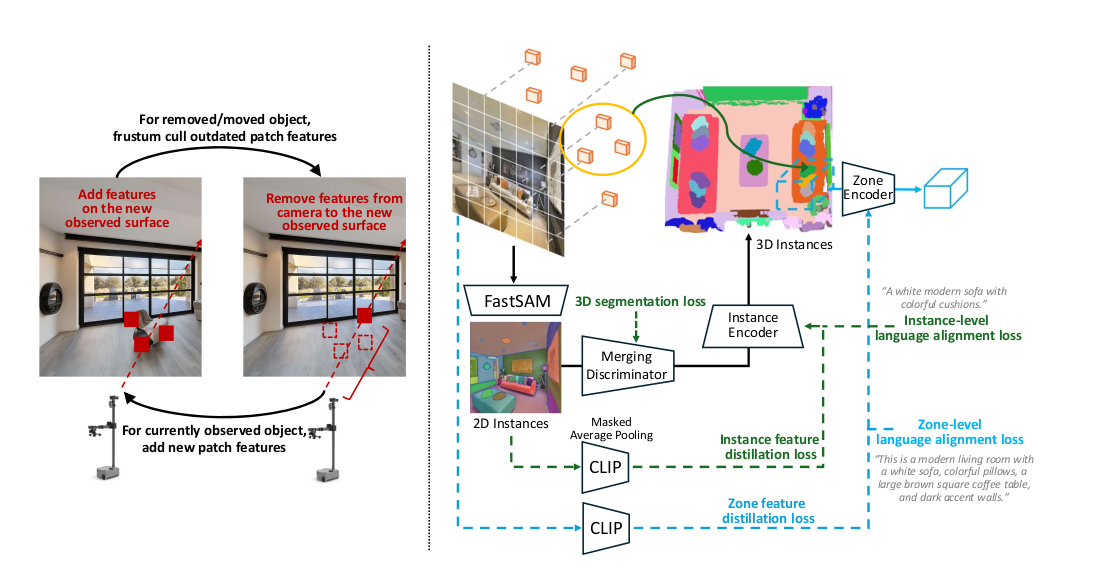
[图 3:左图:特征点更新和视锥剔除策略的图示。右图:我们的Dynam3D模型的特征蒸馏和3D语言对比学习的监督方式。]
与简单的2D实例表示不同,3D实例需要多视图和几何上的一致性,使智能体能够从不同视角识别同一实例。为此,我们训练了一个合并判别器(Merging Discriminator)来将2D实例表示整合到一致的3D实例中,如图2所示。最初,每个2D实例都被视为一个新的3D实例。在随后的每一步中,对于每一个新的2D实例,都会检索出Top-K个最邻近的现有3D实例。合并判别器使用语义和几何编码来评估每个2D-3D实例候选对,以确定对应关系。如果在Top-K个候选者中没有找到匹配项,则创建一个新的3D实例。否则,2D实例将与最相似的3D实例合并,通过拼接它们的补丁特征并通过实例编码器更新3D实例表示。当通过视锥剔除移除过时的补丁时,3D表示会用剩余的相关补丁进行更新。如果一个3D实例的所有补丁都被移除,我们则丢弃该3D实例。
我们使用超过5K个带有3D实例分割数据的房间来训练合并判别器,这些数据来自:ScanNet, HM3D, Matterport3D和3RScan。在这些数据集中,点云实例的标注被处理为每个点都带有世界坐标和实例ID。通过搜索已标注实例点云中最近的匹配点,为补丁分配真值实例ID。对于每个2D或3D实例,其补丁中的多数ID决定了它的真值实例ID。合并判别器使用二元分类损失进行训练,如果2D和3D实例共享相同的真值实例ID,则标签为正(G = 1),否则为负(G = 0):
Lsegm = (1/J) * ΣJj=1 ΣKk=1 CrossEntropy(MergingDiscriminator(O2Dj, O3Dj,k, Dj,k), Gj,k) (4)
函数MergingDiscriminator(·)是一个MLP网络,它接收2D实例特征O2D、3D实例特征O3D以及它们的欧氏距离Dj,k作为输入,并输出一个二维的logit向量。经过广泛的预训练后,MergingDiscriminator(·)函数能有效地将2D实例整合到现有的3D实例中,以维护可更新的多视图且几何一致的3D表示。
3D实例的特征蒸馏与语言对齐。为了将3D实例与语言语义对齐,我们利用来自SceneVerse和g3D-LF的大规模3D语言对进行对比学习。给定一个3D实例特征Oi及其对应的、从CLIP文本编码器提取的标注语言描述特征Ti,我们将Ti视为正样本,而其他实例的描述则作为负样本:
Linstance_text = (1/N) * ΣNi=1 CrossEntropy({CosSim(Oi, Tj)/τ}Nj=1, i) (5)
然而,由于3D语言数据的规模(百万级)远小于图像语言数据集(十亿级),其泛化能力受到限制。因此,我们通过将CLIP的视觉知识蒸馏到我们的Dynam3D模型中来进一步增强泛化能力:
Linstance_distillation = (1/N) * ΣNi=1 CrossEntropy({CosSim(Oi, Ogtj)/τ}Nj=1, i) (6)
为了获得用于蒸馏的真值实例特征Ogt,我们应用FastSAM生成2D实例掩码,并采用来自Feature Splatting的掩码平均池化(MAP)策略,在每个实例掩码内对补丁级特征进行平均池化以获得Ogt。然而,我们观察到,用这种策略提取的实例级特征会受到整体图像背景噪声的干扰。从不同视角获得的同一3D实例的真值实例特征之间存在显著差异,这极大地影响了蒸馏的效果,因为我们的目标之一是实现3D实例表示的多视图一致性。因此,我们提出了一种子空间对比学习(Subspace Contrastive Learning)策略:
Lsubspace_distillation = (1/N) * ΣNi=1 CrossEntropy({CosSim((Oi - Vj), (Ogtj - Vj))/τ}Nj=1, i) (7)
其中,Vj是通过对给定2D视图内的所有补丁特征进行平均池化计算得出的,以产生该视图的局部语义中心,即语义子空间。在公式6中,实例特征通过最大化与CLIP语义空间原点的余弦相似度来进行优化。结果是,正样本被拉近,负样本被推远。然而,不同视图的真值偏差会阻碍这一对比过程。在公式7中,我们将原点锚点替换为视图的语义中心Vj,以减轻偏差效应,施加更强的优化约束,并促进一个具有更强表示能力的更稀疏的特征空间。
3D区域的特征蒸馏与语言对齐。如图2和图3所示,我们引入了区域级表示Z,以进一步捕捉粗粒度的空间布局背景。具体来说,我们的Dynam3D将3D世界坐标空间划分为均匀的立方区域(每个区域跨越数立方米),并使用一个区域编码器来聚合每个区域内的实例级特征O以获得Z。编码过程与公式3类似。对于区域级别的特征蒸馏,我们的Dynam3D采用了一种相对简单的策略:它使用一个区域编码器来聚合属于同一2D视图的3D实例,然后将聚合后的区域表示Z与整个2D视图的CLIP特征对齐。尽管聚合的实例不严格来自同一个立方区域,但这种方法保证了被蒸馏的真值特征的质量。对于区域级的语言对齐,我们遵循g3D-LF的方法,使用细粒度对比学习(Fine-grained Contrastive Learning)进行长文本对比监督。具体来说,我们计算一个区域内的实例表示与长文本表示之间的亲和度矩阵来衡量相似度,然后在不同的区域和文本之间执行对比学习。
3.2 用于导航的3D视觉语言模型
如图2所示,Dynam3D构建了分层的3D表示,从精细的对象实例到大规模的环境区域。利用这些多层次的3D表示作为感知输入,我们引入了一个专为VLN任务量身定制的3D视觉语言模型(3D-VLM)。
通过可泛化特征场编码全景3D补丁令牌 (Encoding Panoramic 3D Patch Tokens via Generalizable Feature Fields)
为了有效地捕捉智能体周围全景的精细几何和语义信息,我们基于g3D-LF的方法,并采用一个可泛化的特征场模型来预测以智能体为中心的3D补丁令牌。具体来说,我们均匀采样12×48条覆盖智能体周围90°垂直和360°水平视野的光线,渲染出3D补丁特征ĝ及其对应的深度估计。这些带有位置嵌入的特征提供了从自我中心视角出发的、丰富且空间上接地的场景几何与语义表示。
多模态推理与动作预测 (Multimodal Reasoning and Action Prediction)
为了平衡多模态推理能力和计算效率,我们将38亿参数的LLaVA-Phi-3-mini集成到我们提出的3D-VLM框架中。由于3D令牌(补丁-实例-区域)与CLIP-ViT-L/14@336px的语义空间对齐,这个2D-VLM强大的多模态理解和推理能力可以有效地转移到3D领域。
如图2所示,我们的3D-VLM的输入和输出格式为:
输入: {patch_tokens}{instance_tokens}{zone_tokens}{instruction_tokens} {history_action_tokens}
输出: 下一个动作: 1) 左转θ度。2) 右转θ度。3) 前进d厘米。4) 停止。
是LLaVA中用于指示后续令牌是上下文的特殊令牌。标记序列的结束。指示后续令牌是模型的响应。为了编码3D令牌与智能体之间的相对位置关系,我们计算每个3D令牌相对于智能体的相对坐标[xc, yc, zc](即相机坐标),以及相对距离Dc和相对水平角θc。每个令牌的[xc, yc, zc, Dc, cos(θc), sin(θc)]随后被送入一个MLP网络,以生成相应的位置嵌入。
从可泛化特征场渲染出的3D补丁令牌{patch_tokens}以12×48令牌的行主序排列,从智能体正后方的光线开始,顺时针进行。这个策略与预训练的LLaVA-Phi-3-mini模型在处理单视图图像时使用的方法相似。实例令牌{instance_tokens}和区域令牌{zone_tokens}根据它们与智能体的欧氏距离从近到远排序。如图2所示,3D-VLM输出带有转动角度或移动距离的原子动作。历史动作{history_action_tokens}存储了最近的四个动作文本,如果少于四个,则用特殊令牌填充。
4 实验
4.1 与SOTA方法的比较
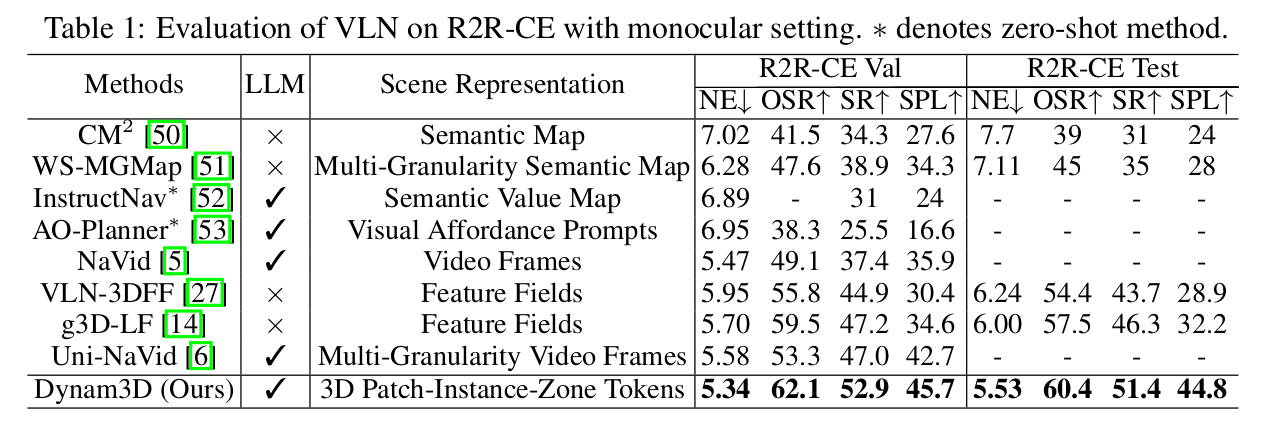
如表1和表2所示,我们在三个不同的连续环境VLN基准上评估了我们的Dynam3D的导航性能。具体来说,R2R-CE数据集(表1)提供逐步跟随指令。与之前的SOTA方法(例如g3D-LF和Uni-NaVid)相比,我们的Dynam3D在导航成功率(SR)上实现了近5%的提升。
[表 1:在R2R-CE上使用单目设置的VLN评估。]
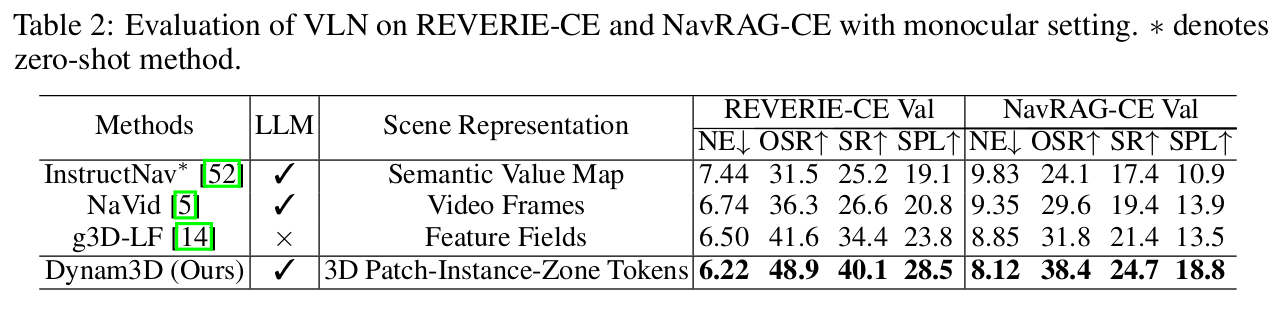
为了在更具挑战性和现实性的基准(如使用粗粒度和高级别目的地描述的REVERIE-CE,以及需要理解复杂用户需求的NavRAG-CE)上进行公平比较,我们重新训练了NaVid和g3D-LF… 我们的Dynam3D仍然表现出显著的改进,在REVERIE-CE上的成功率(SR)超过NaVid 13%以上,在NavRAG-CE上超过5%。
[表 2:在REVERIE-CE和NavRAG-CE上使用单目设置的VLN评估。]
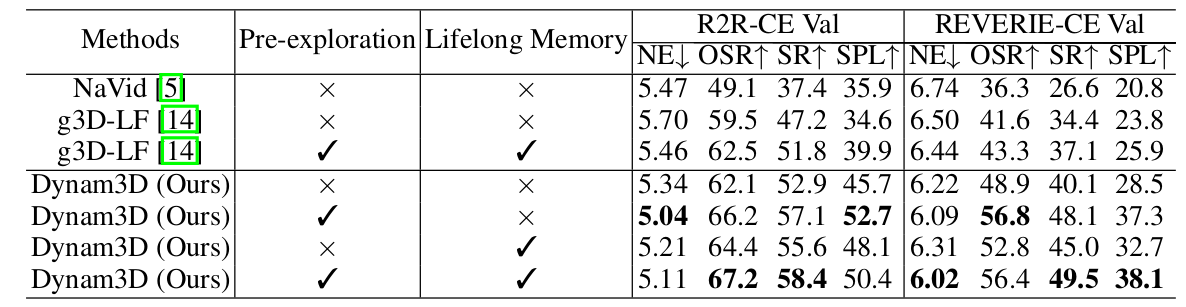
4.2 预探索与终身记忆实验
如表3所示,我们额外评估了在预探索(Pre-exploration)和终身记忆(Lifelong Memory)设置下的性能,以进一步展示我们Dynam3D的优势。
[表 3:VLN的预探索与终身记忆评估。]
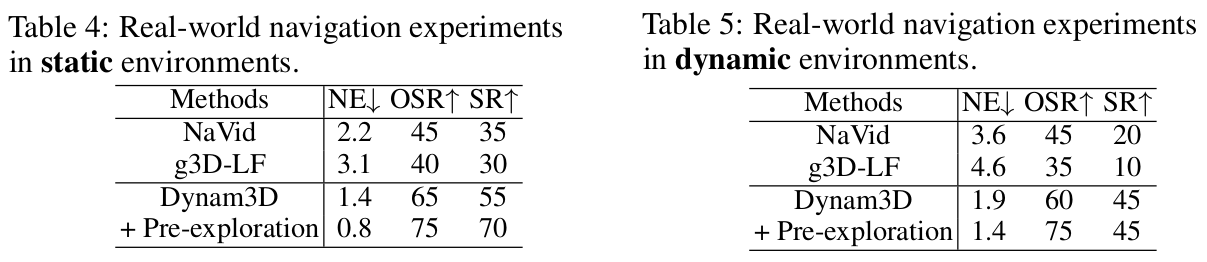
4.3 真实世界与动态环境实验
如表4、表5和图4所示,我们使用Hello Robot Stretch 3在真实世界的静态和动态环境中评估了我们的Dynam3D。
[表 4 & 5:在静态/动态环境下的真实世界导航实验。]

[图 4:真实世界动态环境中的导航演示。]
4.4 计算成本与实时性分析
我们使用单个NVIDIA RTX 4090 GPU在R2R-CE数据集上评估了计算成本。在训练期间,每个导航步骤平均耗时455毫秒(约0.46秒):其中83毫秒用于3D表示更新,315毫秒用于大型语言模型,57毫秒用于其他操作。在推理期间,平均步骤时间增加到649毫秒(约0.65秒),其中83毫秒用于3D表示更新,540毫秒用于大型语言模型推理,26毫秒用于其余组件。大多数导航片段可以在20到40个导航步骤内完成,我们的导航系统支持实时3D表示更新和导航动作预测,以实现高效的训练和推理。
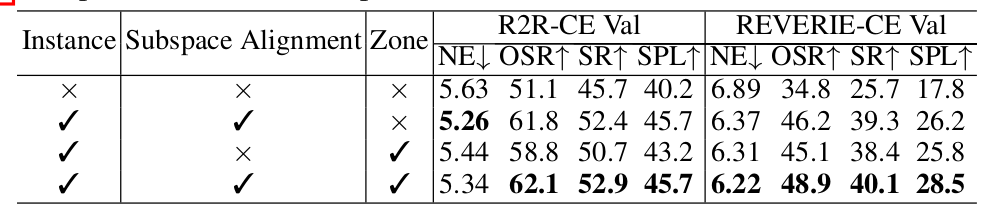
4.5 消融研究
表6报告了我们的消融研究结果。移除3D实例和区域表示(第一行),仅使用来自特征场的3D补丁令牌,会导致性能大幅下降,尤其是在REVERIE-CE上,其成功率(SR)下降了近15%。这凸显了实例-区域表示在支持有效导航和大规模探索中的关键作用,因为仅局部补丁级特征提供的空间覆盖范围有限。仅移除区域表示(表6,第二行)会导致在REVERIE-CE上轻微的性能下降。这表明大规模的区域特征对于使用粗粒度和高级别指令的导航有积极贡献。在没有子空间对齐(Subspace Alignment)监督的情况下(表6,第三行),导航性能显著下降,这凸显了朴素的CLIP特征蒸馏对于3D实例监督的局限性。子空间对比学习有效地减轻了来自不同视图的实例特征偏差。
[表 6:Dynam3D在R2R-CE Val Unseen基准上的消融研究。]
5 结论
我们介绍了Dynam3D,一个用于单目视觉语言导航的动态分层3D表示框架。通过将补丁-实例-区域特征与语言语义对齐,并实现实时场景更新,我们的Dynam3D增强了在动态环境中的空间理解、长期记忆和适应性。我们的模型在多个VLN基准上取得了业界最佳结果,并展示了在真实世界部署中的强大泛化能力。
局限性。我们的Dynam3D预测导航动作时没有明确输出目标实例的坐标,这限制了其在某些任务(如移动操作)中的应用。此外,它缺乏问答、对话和任务更新的能力,这为更好的导航智能体指明了潜在的研究方向。