【数据工程】15. Stream Query Processing
1. 查询流数据(Querying Stream Data)
传统数据库查询引擎有一个基本假设:
- 查询是在“一个固定的数据集”上执行的。
- 也就是说,在做查询规划(planning)和查询执行(execution)时,数据被当成是静态的、不再变的。
但是,流式数据不是静态的,而是在不断流入、不断变化,始终“在路上”(in motion)。
这带来了两个核心问题:
- 查询语义应该怎么定义?
(也就是:当数据是无限流的时候,“这个查询到底问的是什么”要怎么说明?) - 查询是否要持续执行?
(换句话说:我们是不是需要一种可以不停运行、不断更新结果的“持续查询”机制,而不是执行一次就结束?)
在经典数据库里,查询执行流程是管道式/阶段式的:
- 解析(Parsing):把查询语句变成内部表示;
- 查询计划(Query Planning):决定用哪些算子、走哪个路径;
- 查询优化(Query Optimization):找出代价更低的执行方式;
- 查询执行(Query Execution):真正跑计划并给出结果。
对于流式数据,问题就在于:数据还在不停变化,那这个流程是不是一直持续着?结果是不是一直在更新?
2. 数据流查询处理(Data Stream Query Processing)
这里引入两个非常关键的概念:无状态操作符(stateless operators) 和 有状态操作符(stateful operators)。
2.1 无状态操作符(Stateless operators)
-
无状态操作符是逐条记录(逐个事件)独立处理的。
它处理当前这条输入数据时,不需要记住过去看到什么。 -
典型的无状态操作符包括:
- 选择(selection,筛选出满足条件的事件)
- 投影(projection,保留/重命名/丢弃某些列)
这些操作可以在每个元素本地完成,不需要跨多条记录关联历史。
示例 SQL:
SELECT sourceIP, time
FROM IPTraffic
WHERE length > 512;
这条查询的逻辑是:“对每条网络流量记录 IPTraffic,如果 length > 512,就输出它的 sourceIP 和 time。”
注意:它不需要知道前后其他记录是什么,只看当前记录本身就可以决定是否输出。
→ 所以它是无状态的(stateless)。
图中右侧的示意:无状态算子就是一个操作符,输入一条,处理一条,输出一条,不保留额外状态。
2.2 有状态操作符(Stateful operators)
-
有状态操作符的输出并不只依赖当前事件本身,而是依赖“多个事件的组合”。
-
常见的有状态操作包括:
- 窗口操作(window operators)
- 聚合(aggregation)
- 连接(join)
这些操作的本质:
它们需要“记住一段时间内看过的多条数据”,而不是只看当前这一条。
例子:
- 窗口聚合(windowed aggregation):例如“计算过去5分钟内的平均温度”。
- 流式连接(stream join):要把一条流和另一条流里匹配到的事件连接起来,所以必须暂存一边或两边最近到达的数据。
要做到这些,首先要定义一个窗口(window)——也就是,明确“我要计算的是哪一段子集,而不是整条无限长的数据流”。
- Join(连接)只有在你有“面向流的 join 算法”时才可行;
- 聚合(aggregation)必须有一个明确的窗口,告诉系统:我们在对什么范围的事件做聚合。
2.3 “State” 是什么?
“State”(状态)指的是:
在流式处理过程中,算子(操作符)为了完成计算而保留下来并不断更新的中间数据。
-
这个状态在多个事件之间是持续存在的;
-
状态对下列操作至关重要:聚合、连接、任何需要“跨多条记录”的逻辑。
-
无状态:操作符本身不保留内存,不记历史;
-
有状态:操作符旁边挂了一个“State”的小仓库,表示它带着累积信息在运行。
3. 有状态应用 vs 无状态应用(Stateful vs Stateless Applications)
从系统层面看,为什么“有状态”和“无状态”的应用差别这么大。
关键区别是:
有状态应用会在不同请求之间保留上下文信息;无状态应用不会。
具体对比点如下:
3.1 可扩展性(Scalability)
- 无状态应用更容易横向扩展,因为每个请求/事件是独立的,丢给哪个实例处理都行;
- 有状态应用因为需要维护用户会话、历史信息或累计状态,所以要做负载均衡和会话黏性(session stickiness)等复杂操作,扩展更难。
3.2 容错性(Fault tolerance)
- 无状态应用更容易容错:如果一台服务器挂了,换一台就好,影响很小;
- 有状态应用要担心状态丢失,比如用户会话信息、聚合的中间结果等,所以往往需要会话复制(session replication)、检查点等机制来保证不丢。
3.3 资源使用(Resource utilisation)
- 无状态应用占用资源较少:因为它不需要保存/管理这些状态;
- 有状态应用需要保存状态(内存、存储)并进行管理和更新,所以资源开销更大,处理逻辑更复杂。
3.4 开发复杂度(Development complexity)
- 无状态应用更容易开发,因为你不需要跨请求维护一致的状态;
- 有状态应用开发更复杂,因为你必须考虑状态的生命周期、同步、恢复等问题(尤其在分布式场景里)。
换句话说:
- 无状态 = 简单/好扩/好恢复
- 有状态 = 强功能/能做聚合、会话、上下文理解,但管理成本更高
4. 窗口化技术(Stream Query Processing: Windowing Technique)
现在我们进入流查询里最关键的概念之一:窗口(window)。
4.1 什么是窗口?
窗口可以理解成:
从一条“无限长的流”中,切出一个“有限的片段”,用它来做计算。
为什么要窗口?
因为真实的流是无限的,我们不可能在“全体历史”上每次都重算,我们只能在某个局部子范围内做统计、聚合、检测等。
幻灯片里说:
- 窗口让我们可以把无限流,变成一段一段“小块的可行动数据(more actionable segments)”,从而实现真正的实时处理。
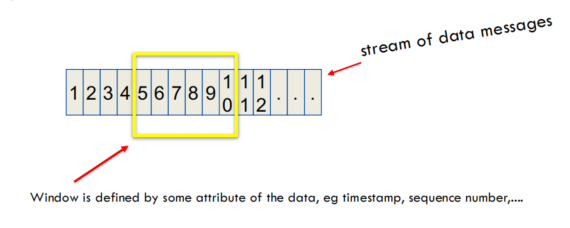
图里的意思:
有一个不断增长的数据消息流(右箭头表示数据还在继续往后到来),
而我们用一个高亮的矩形框(window)圈住其中的一部分元素,比如最近的 N 个,或最近的几秒钟的数据。
并且,窗口的定义通常依赖数据中的某个属性,比如:
- 时间戳(timestamp)
- 序列号(sequence number)
等等。
5. “窗口”是怎么用来驱动查询的(Stream Query Processing: Windowing Technique,第二页)
这里强调两件事:
5.1 窗口的作用
窗口 = 从无限流中提取出一个“有限关系”(finite relation)。
这个“有限关系”就可以像普通表一样,用 SQL 去做聚合、分组、过滤等操作。
也就是说,窗口帮我们把流(stream)暂时变成表(relation),
然后我们对这个表做普通批式SQL操作,
最后再把结果重新变回流输出(result stream)。
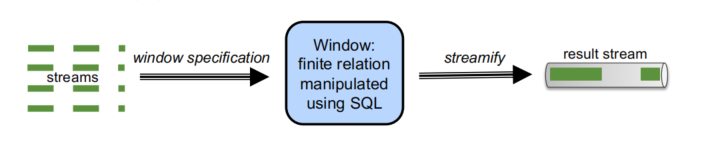
- 多条输入流(streams)
- 通过一个窗口规范(window specification)选出当前关注的那一截
- 得到一个“有限关系”(SQL 可以直接操作)
- 处理完以后再把结果流化(streamify)成一个新的输出流。
5.2 窗口可以怎么定义?
常见的定义方式包括:
- 基于排序属性的窗口(ordering attributes),比如基于时间。
这是最常见的:”最近5分钟的事件“这样的东西。 - 基于元组数量(tuple counts)的窗口。
比如:“最近100条事件”。 - 基于显式标记(explicit markers)的窗口,也叫 punctuation。
系统/应用向流里插入标记,告诉处理器“到此为止算一批”。 - 其他变体,比如:在一个窗口内部再按某个key做分组/分区(partitioning tuples in a window)。
6. 基于排序属性的窗口(Ordering-Attribute-Based Windows)
假设流数据中,有一个属性可以用来定义事件的顺序。
最常见的这个属性就是时间(time)。
例如每条数据有时间戳,这样我们知道先后顺序。
设 T 是窗口长度,比如 5秒、1分钟等,单位就是这个排序属性的单位(例如时间)。
这种基于顺序属性(多半是时间)的窗口,有不同的变体:
6.1 Agglomerative(累积式窗口)
- 从某个开始时刻起,一直往现在累积;
- 随着时间推移,窗口越来越大,从一开始到当前时刻的“全部到达过的事件”都在窗口里。
- 这种窗口适合做“到目前为止的全局统计”。
6.2 Sliding Window(滑动窗口)
- 定义一个固定大小的窗口(例如最近5分钟,或最近100条记录)。
- 每次时间往前推进一点点,窗口也往前滑一点点。
- 结果是:窗口之间是重叠的。
也就是说,同一条事件可以同时属于多个相邻窗口。 - 目的是得到“连续的、平滑更新的”统计量,比如“过去5分钟的平均值,每10秒更新一次”。
6.3 Tumbling Window(翻转/滚动窗口、也叫跳跃窗口)
- 同样有固定大小;
- 但不同之处是:窗口之间不重叠,是背靠背地一个接一个。
- 比如:按整分钟切片,[00:00-00:59], [01:00-01:59], [02:00-02:59] …
- 每条事件只会落到一个窗口里。
- 常用于周期统计(每分钟一次报表、每小时一次聚合等)。
图中第三行显示了一个个并排的方块,没有交叉。
7. 基于元组数量的窗口(Tuple-Count-Based Windows)
这类窗口不是按时间切,而是按条数切。
-
设窗口大小为 N,表示每个窗口中包含 N 个事件(也可以做滑动式或翻转式):
- 滑动式(sliding):窗口大小固定,比如 N=100 条,但每次只往前滑 1 条或几条,所以重叠。
- 翻转式/翻滚式(tumbling):窗口仍然大小 N=100,但是窗口之间不重叠。
问题:
- 如果事件的时间戳不是唯一的、或者时间戳没法严格排序,这种“数N条”的窗口有时比时间窗口更好。
- 但是:当多条记录的时间戳一样,或者记录到达顺序有抖动,你怎么划分它们进哪个窗口?
如果这个划分是任意决定的,那么输出也可能变成不确定的(non-deterministic),因为不同运行可能做出不同的切分。
- “Problematic with non-unique timestamps”
当时间戳重复或乱序,基于条数分窗可能和你的时间逻辑不一致。 - “Ties broken arbitrarily may lead to a non-deterministic output”
当两条记录没法区分先后次序时,系统可能随便决定谁先谁后,这会导致窗口划分不稳定,从而导致结果不完全可重现。
8. 会话窗口 / 标点窗口(Sessions Windows / Punctuation-Based Windows)
这里讲的是“基于标点(punctuation)的窗口”。
思想是这样的:
- 应用程序可以在流中插入一些特殊的“标记事件”(markers),例如“这一轮处理结束了”的信号。
- 同时,每个数据项也可以标识它自己的“开始时间”或“开始处理点”。
这有两个效果:
- 允许窗口的长度不是固定的,而是由数据本身驱动,变成可变长度窗口。
例如:一场竞拍(auction)从开始到结束是一段会话(session),这个 session 的长度不是固定5分钟,而是“这场拍卖什么时候开始,什么时候结束”。 - 允许我们按“会话(session)”把事件分组。
典型例子:用户的交互会话(用户活跃一段时间 -> 断开一段时间 -> 又回来),网络会话,竞拍场次,等等。
所以这种会话窗口,本质是:
- 利用“开始-结束”标记,
- 动态决定窗口的边界,
- 每个窗口对应一段逻辑会话,而不是固定长度的时间片。
9. 小测验(Quiz)
-
在不同的窗口策略中(例如滑动窗口 sliding window、翻转窗口 tumbling window),一条记录(一个tuple)能同时属于多个窗口吗?
正确理解:
- 在滑动窗口(sliding window)里,窗口是重叠的,所以同一条数据可以出现在多个窗口中;
- 在翻转/滚动窗口(tumbling window)里,窗口是互不重叠的,所以同一条数据只能属于一个窗口;
- 所以,答案是:滑动窗口中可以,翻转窗口中不可以。
-
基于标点的窗口(punctuation-based window)属于哪种?它算滑动、翻转,还是都不是?
正确理解:
- 基于标点(punctuation)的窗口其实是由应用插入“结束标记”来划分边界,它并不是固定长度的滑动窗口,也不是固定长度的翻转窗口;
- 它是会话/段落驱动的,所以它既不是传统意义的 sliding,也不是 tumbling,是另一类“按会话/按标记分隔”的可变窗口。