[C++STL] :list的简介和使用
目录
- list的特性与优点
- list常用API
- list部分实现原理分析
- list的缺点
- 容器优劣比较 vector vs list
list的特性与优点
是 C++ 标准模板库(STL)中的一个序列容器,它允许在容器的任意位置快速插入和删除元素。与数组vector不同,list>不需要在创建时指定大小,并且可以在任何位置添加或删除元素,而不需要重新分配内存
动态大小:list的内存管理是以每一个节点为单位,要插入就new一个节点,然后以很小的代价改变相邻的节点的连接关系。这就不存在空间浪费
插入效率高:可以在列表的任何位置快速插入或删除元素,而不需要像vector那样移动大量元素。
支持双向迭代器:list 提供了双向迭代器,可以向前和向后遍历元素
逻辑连续(注 :list就是只逻辑连续,物理上并不连续的容器):list由一个个节点连接而成,尽管通过next和prev指针感觉list是连续的。但这种连续是逻辑连续,list各个节点物理上是分快分开的
泛式实现:基于模版的好处,list 可以存储任何类型的元素,包括内置类型、对象、指针等。
list常用API
在cplusplus中由很详细的list ,api介绍
链接: cpluscplus
总结api的列表
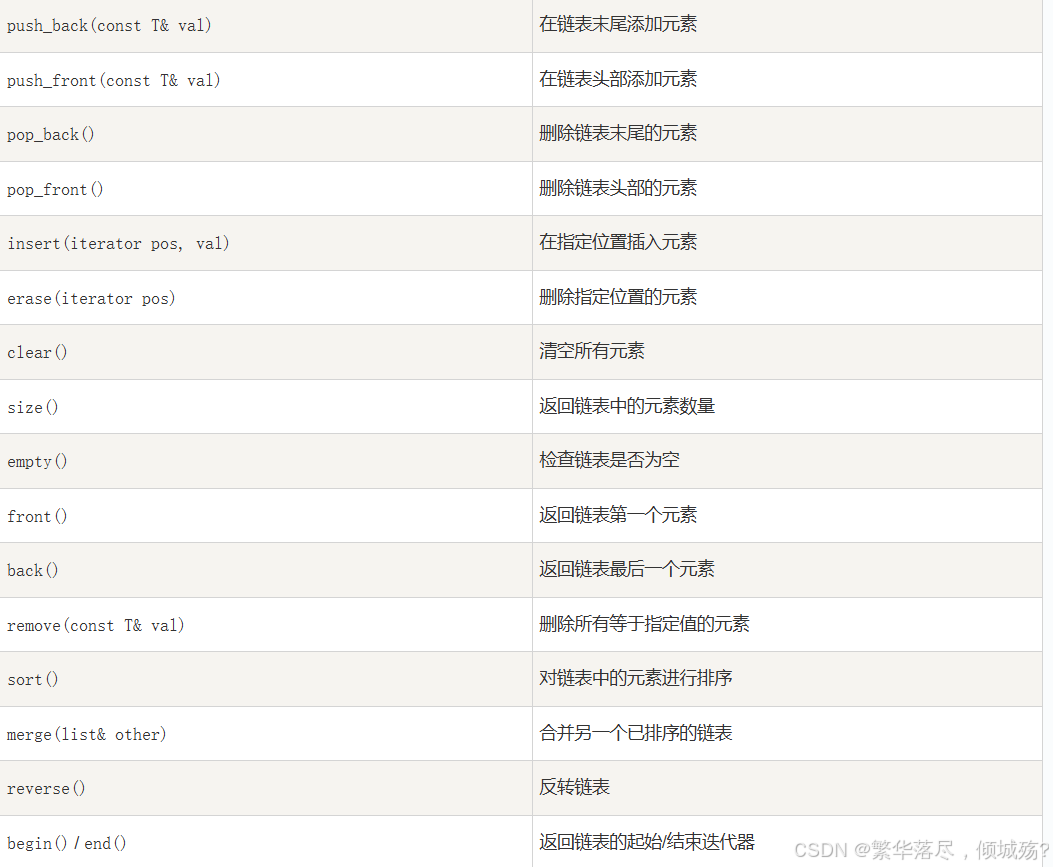
实际使用实例
#include <iostream>
#include <list>int main()
{// 创建一个整数类型的列表std::list<int> numbers;// 向列表中添加元素numbers.push_back(10);numbers.push_back(20);numbers.push_back(30);// 访问并打印列表的第一个元素std::cout << "First element: " << numbers.front() << std::endl;// 访问并打印列表的最后一个元素std::cout << "Last element: " << numbers.back() << std::endl;// 遍历列表并打印所有元素std::cout << "List elements: ";for (std::list<int>::iterator it = numbers.begin(); it != numbers.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl;// 删除列表中的最后一个元素numbers.pop_back();// 再次遍历列表并打印所有元素std::cout << "List elements after removing the last element: ";for (std::list<int>::iterator it = numbers.begin(); it != numbers.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl;return 0;
}list部分实现原理分析
底层存储:list是逻辑连续的,由一个一个的节点构成,
每次push时,只需要new一个新节点,然后改变链接关系即可
双向迭代的实现原理 :list是双端链表,在当前节点时可以访问前置元素和后缀元素。
list 本身并没有直接重载 operator++ 和 operator–,但 list 的迭代器(iterator 和 const_iterator)重载了这两个运算符。
#include <list>
#include <iostream>
using namespace std;int main() {list<int> l = {10, 20, 30, 40};// 获取迭代器(指向第一个元素)auto it = l.begin();// 使用 operator++ 移动到下一个元素(前置++)++it; // 现在指向 20cout << *it << endl; // 输出:20// 后置++(返回移动前的迭代器,通常用于需要保留旧位置的场景)auto old_it = it++; // old_it 仍指向 20,it 移动到 30cout << *it << endl; // 输出:30// 使用 operator-- 移动到上一个元素(前置--)--it; // 移动回 20cout << *it << endl; // 输出:20// 后置--old_it = it--; // old_it 指向 20,it 移动到 10cout << *it << endl; // 输出:10return 0;
}
拷贝构造函数和operator=赋值函数。同样的list的拷贝构造函数和operator=赋值函数必定是 深拷贝 ,不然就会导致两个list对象实例对象指向同一个位置,导致析构函数重复释放同一个位置
注 :如果实在不理解深拷贝的原理,可以参考我的博客了解深拷贝和浅拷贝
[C++类和对象] :类的默认成员函数
基于上述特性可以实现一个简单的具有基本功能的list
#include <iostream>
using namespace std;// 1. 节点结构:双向链表的每个节点包含数据、前驱指针、后继指针
template<class T>
struct Node
{T data; // 存储的数据Node* prev; // 前驱节点指针Node* next; // 后继节点指针// 节点构造函数Node(const T& val) : data(val), prev(nullptr), next(nullptr) {}
};// 2. 迭代器类:支持双向移动(++/--),重载解引用(*)和箭头(->)
template<class T>
class MyListIterator
{
public:// 迭代器持有指向节点的指针Node<T>* _node;// 构造函数MyListIterator(Node<T>* node) : _node(node) {}// 前置++:移动到下一个节点,返回自身引用MyListIterator<T>& operator++() {_node = _node->next; // 借助节点的next指针移动return *this;}// 后置++:先返回当前迭代器,再移动(用占位符int区分)MyListIterator<T> operator++(int){MyListIterator<T> temp = *this; // 保存当前状态_node = _node->next;return temp; // 返回移动前的迭代器}// 前置--:移动到上一个节点,返回自身引用MyListIterator<T>& operator--() {_node = _node->prev; // 借助节点的prev指针移动return *this;}// 后置--:先返回当前迭代器,再移动MyListIterator<T> operator--(int) {MyListIterator<T> temp = *this;_node = _node->prev;return temp;}// 解引用:返回节点的数据引用T& operator*(){return _node->data;}// 箭头运算符:返回节点数据的指针(方便访问成员,如it->field)T* operator->() {return &(_node->data);}// 迭代器相等判断:节点指针是否相同bool operator!=(const MyListIterator<T>& other) const {return _node != other._node;}
};// 3. 双向链表类
template<class T>
class MyList
{
public:// 迭代器类型定义(方便外部使用)using iterator = MyListIterator<T>;// 3.1 构造函数:初始化哨兵节点(头哨兵和尾哨兵,简化边界操作)MyList() {// 哨兵节点不存储实际数据,仅用于简化插入/删除的边界判断_head = new Node<T>(T()); // 头哨兵_tail = new Node<T>(T()); // 尾哨兵_head->next = _tail; // 初始状态:头哨兵的next指向尾哨兵_tail->prev = _head; // 尾哨兵的prev指向头哨兵_size = 0; // 初始大小为0}// 3.2 拷贝构造函数(深拷贝)MyList(const MyList<T>& other) {// 初始化自己的哨兵节点_head = new Node<T>(T());_tail = new Node<T>(T());_head->next = _tail;_tail->prev = _head;_size = 0;// 遍历other的每个元素,逐个复制(深拷贝核心)Node<T>* cur = other._head->next; // 从other的第一个实际节点开始while (cur != other._tail) { // 直到other的尾哨兵push_back(cur->data); // 尾插复制的数据(自动创建新节点)cur = cur->next;}}// 3.3 赋值运算符重载(深拷贝)MyList<T>& operator=(const MyList<T>& other){if (this != &other) { // 防止自赋值// 1. 释放当前链表的所有节点(除哨兵)clear();// 2. 拷贝other的元素(同拷贝构造)Node<T>* cur = other._head->next;while (cur != other._tail) {push_back(cur->data);cur = cur->next;}}return *this;}// 3.4 析构函数:释放所有节点(包括哨兵)~MyList() {clear(); // 释放实际元素节点delete _head; // 释放头哨兵delete _tail; // 释放尾哨兵_head = _tail = nullptr;_size = 0;}// 3.5 尾插元素void push_back(const T& val) {Node<T>* new_node = new Node<T>(val); // 创建新节点Node<T>* last = _tail->prev; // 找到当前最后一个实际节点(尾哨兵的前一个)// 调整指针关系:新节点插入到last和尾哨兵之间last->next = new_node; // last的next指向新节点new_node->prev = last; // 新节点的prev指向lastnew_node->next = _tail; // 新节点的next指向尾哨兵_tail->prev = new_node; // 尾哨兵的prev指向新节点_size++; // 大小+1}// 3.6 头插元素void push_front(const T& val){Node<T>* new_node = new Node<T>(val); // 创建新节点Node<T>* first = _head->next; // 找到当前第一个实际节点(头哨兵的后一个)// 调整指针关系:新节点插入到头哨兵和first之间_head->next = new_node; // 头哨兵的next指向新节点new_node->prev = _head; // 新节点的prev指向头哨兵new_node->next = first; // 新节点的next指向firstfirst->prev = new_node; // first的prev指向新节点_size++; // 大小+1}// 3.7 清空所有元素(保留哨兵)void clear(){Node<T>* cur = _head->next;while (cur != _tail) { // 遍历所有实际节点Node<T>* next = cur->next; // 保存下一个节点(防止删除后丢失)delete cur; // 释放当前节点cur = next;}// 重置哨兵关系(回到初始状态)_head->next = _tail;_tail->prev = _head;_size = 0;}// 3.8 迭代器接口:begin返回第一个元素的迭代器,end返回尾哨兵的迭代器iterator begin() {return iterator(_head->next); // 头哨兵的next是第一个实际节点}iterator end() {return iterator(_tail); // 尾哨兵作为end(最后一个元素的下一个位置)}// 3.9 获取大小size_t size() const {return _size;}private:Node<T>* _head; // 头哨兵(不存数据)Node<T>* _tail; // 尾哨兵(不存数据)size_t _size; // 实际元素个数
};list的缺点
不支持随机访问 :list逻辑连续,但是物理上不连续 ,这句注定了list不支持随机访问。而随机访问这个特性非常重要,支持随机访问的容器是支持排序等stl算法的基础
查询效率低 :因为不支持operator[],所以
要查询某个位置的节点需要遍历迭代器++到这个节点去。查询的复杂度是O(N)
导致内存碎片化 :list 每次插入元素都需 new 一个节点,频繁的小对象内存分配会增加内存分配开销,且易导致内存碎片化(大量小内存块分散,难以被后续大内存申请利用)
容器优劣比较 vector vs list
vector :
优点 :
- 查询快支持operator[]
- 尾部插入删除快
- 可随机访问,这个特性让vector可以适配很多算法
缺点:
- 头部和中部插入删除元素慢
- 增容时效率低需要O(N)赋值,而且可能有大量的内存空间浪费
list:
优点:
1.只要给出了要操作的位置(通常是迭代器),插入和删除都非常快O(1)
2.每新加入一个元素都new 一个对象,减少了内存空间的浪费。
缺点:
1.不支持operator[],查询某位置的元素慢,需要一个一个迭代过去
2.不像vector每次操作都开辟的是大块空间,所以list每次开辟小块空间会导致内存碎片化
3.不支持随机访问,不支持这个特性就不能适配stl的很多算法
总结 :
vector 和 list 可以说是一对互补的容器
vector适用需要频繁随机访问,但是本次不怎么修改的场景
list适用需要频繁大量修改的场景