【LUT技术专题】双边网格优化的3DLUT-SABLUT

空间感知3D查找表-双边网格优化的3DLUT-SABLUT: Image-adaptive 3D Lookup Tables for Real-time Image Enhancement with Bilateral Grids(2024 ECCV)
- 专题介绍
- 一、研究背景
- 二、SABLUT方法
-
- 2.1 Image Context Extraction
- 2.2 Spatial Feature Fusion by Bilateral Grid
- 2.3 Color Enhancement by 3D Lookup Table
- 三、实验结果
- 四、总结
本文将围绕《SABLUT: Image-adaptive 3D Lookup Tables for Real-time Image Enhancement with Bilateral Grids》展开完整解析。本文提出提出一种结合双边网格(Bilateral Grids) 与3D 查找表(3D LUTs) 的图像增强模型,以解决传统 3D LUT 方法缺乏空间信息、参数多或推理慢的问题。该模型通过 Extractor 提取图像上下文,分别生成图像自适应的双边网格和 3D LUTs;双边网格经切片操作(Slicing) 转化为空间特征,与输入图像融合后,通过 3D LUT 插值(3D LUT transform)生成增强图像,其中双边网格切片用三线性插值、3D LUT 转化用四面体插值效果最优。模型在 FiveK 和 PPR10K 数据集的照片修饰、色调映射任务中,以463.7K 参数实现 SOTA 性能,480p 分辨率推理时间 1.20ms,4K 分辨率 3.64ms,参数规模仅为 SA-3DLUT的 1/10 左右。参考资料如下:
[1]. 论文地址
[2]. 代码地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
【8】Tiny-LUT
【9】3D-LUT
【10】4D-LUT
【11】AdaInt-LUT
【12】Sep-LUT
【13】CLUT
【14】ICELUT
【15】AutoLUT
【16】SA-3DLUT
一、研究背景
该篇文章优化的是SA-3DLUT,SA-3DLUT采用 U-Net backbone 引入空间信息,虽达 SOTA 性能,但参数规模激增(4.5M),推理时间延长(4K 分辨率 4.39ms),难以平衡性能与效率。作者希望能够在感知空间信息的基础上减小参数规模和推理时间。
二、SABLUT方法
该模型核心是通过双边网格(传递空间信息) 与3D LUT(实现颜色增强) 的结合,在不增加参数的前提下引入空间信息,同时保持实时推理能力。流程如图所示:
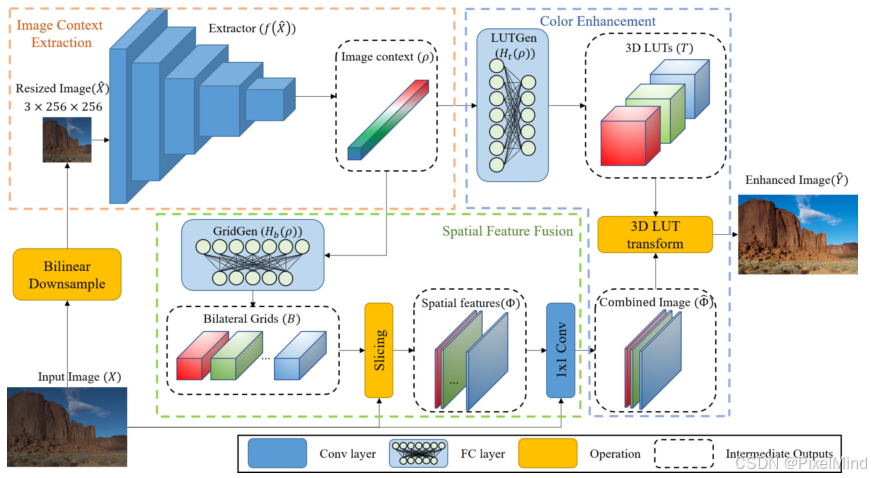
包含几个组件:
- Image Context Extractor:此与3DLUT一样,是一个简单的5 层 CNN结构,用于提取图像上下文,为后续模块提供基础特征。
- Spatial Feature Fusion:利用2 层全连接(FC)层组成的GridGen,输出 K 个双边网格,后续利用切片操作(Slicing),以输入图像为引导图,查询点定义为当前的空间位置x,y以及对应的各个通道的值,组成一个3D的查询点使用三线性插值得到双边插值信息Spatial feature,读者可以类比双边插值,双边插值需要考虑空间位置和像素信息,这里是一样的,只不过虽然是RGB图像但只考虑一个通道,因为查询点有限。 这个信息与原始输入统一进行1x1 Conv的融合得到Combined Image。
- Color Enhancement:该模型跟3DLUT无区别,通过LUTGen生成3DLUT,然后使用这个3DLUT完成插值,只不过此时3DLUT不是直接作用到原始图像上,而是作用到经过Spatial Feature Fusion处理后的图像上。
接着是一个前置知识,3DLUT插值方法包含两种:三线性插值,四面体插值,四面体插值所需要查询的点会更少一些,这2种插值方式在SR-LUT中有讲解,不了解的读者可以先熟悉这两种插值方法。
2.1 Image Context Extraction
此为前面的特征提取,网络结构如下所示:
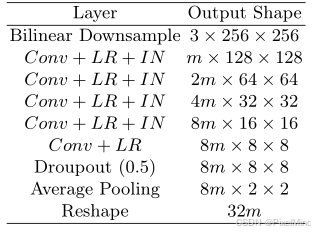
其中,Conv代表stride=2,卷积核为3x3的卷积块,LR代表LeakyReLU,IN代表Instance normalization。公式表示如下: ρ = f ( X ^ ) \rho = f(\hat{X}) ρ=f(X^)其中, ρ ∈ R 32 m \rho \in \mathbb{R}^{32m} ρ∈R32m 为图像上下文向量, X ^ \hat{X} X^ 为双线性下采样后的图像, f ( ⋅ ) f(\cdot) f(⋅) 表示上下文提取过程, m m m 为Extractor宽度超参数。
2.2 Spatial Feature Fusion by Bilateral Grid
整体流程分为以下几步:
- 首先需要生成Grid,Grid Gen的结构如下所示:
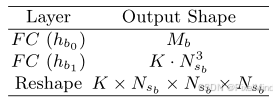
公式表示如下: B = H b ( ρ ) = h b 1 ( h b 0 ( ρ ) ) : R 32 m → h b 0 R M b → h b 1 R K × N s b × N s b × N s b B = H_{b}(\rho) = h_{b_1}\left(h_{b_0}(\rho)\right): \mathbb{R}^{32m} \stackrel{h_{b_0}}{\to} \mathbb{R}^{M_b} \stackrel{h_{b_1}}{\to} \mathbb{R}^{K \times N_{s_b} \times N_{s_b} \times N_{s_b}} B=Hb(ρ)=hb1(hb0(ρ)):R32m→hb0RMb→hb1RK×Nsb×Nsb