VLFM视觉语言基础模型使用指南
0. 简介
VLFM (Vision Language Foundation Model) 是一个先进的视觉-语言基础模型,专为机器人导航和交互设计。它将计算机视觉与自然语言处理相结合,能够:
- 理解自然语言指令:支持人类自然语言的导航指令和任务描述
- 视觉场景理解:分析并理解复杂3D环境中的物体和空间关系
- 执行目标导航:能够找到并识别环境中的特定物体
- 完成指定任务:根据语言指令执行特定操作
VLFM既可在Habitat仿真环境中测试,也可部署到实体机器人(如Boston Dynamics的Spot)上。
1. 环境安装
1.1 基础环境配置
首先依据conda环境安装VLFM需要的基础环境:
conda create -n vlfm python=3.9 cmake=3.14.0
conda activate vlfmpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118sudo apt-get update
sudo apt-get install build-essential
sudo apt-get install gcc g++# https://github.com/IDEA-Research/GroundingDINO/issues/397这个修复安装wheel问题pip install git+https://github.com/IDEA-Research/GroundingDINO.git@34ef00dcdf5cadb84c21b59db4fc42a4d4c75047 salesforce-lavis==1.0.2# 在此仓库中克隆以下仓库(简单克隆就足够了)
git clone git@github.com:WongKinYiu/yolov7.gitgit clone https://github.com/IDEA-Research/GroundingDINO.git
1.2 核心模型组件
VLFM整合了多个先进的视觉和语言模型,形成了一个强大的统一框架:

- GroundingDINO: 视觉-语言理解与目标检测
- MobileSAM: 轻量级分割模型
- YOLOv7: 高效目标检测
- LAVIS: 语言-视觉理解框架
2. Habitat-Sim 安装
2.1 基础安装
根据您的环境选择合适的安装方式:
# 带显示器的机器
conda install habitat-sim=0.2.4 withbullet -c conda-forge -c aihabitat# 无显示器的机器(如集群)
# conda install habitat-sim=0.2.4 withbullet headless -c conda-forge -c aihabitat
我们在本地复现所以选择带显示器的,注意我们选择bullet的物理仿真,否则会有问题。
2.2 数据集和工具配置
git clone https://github.com/facebookresearch/habitat-matterport3d-dataset.git
cd habitat-matterport3d-dataset# 将当前目录添加到PYTHONPATH
export PYTHONPATH=$PYTHONPATH:$PWD# 安装必要的Python库
pip install "trimesh[easy]==3.9.1"
pip install -r requirements.txt

2.3 Habitat环境测试
下载测试场景和对象:
sudo apt-get install git-lfspython -m habitat_sim.utils.datasets_download --uids habitat_test_scenes --data-path /media/bigdiskpython -m habitat_sim.utils.datasets_download --uids habitat_example_objects --data-path /media/bigdisk
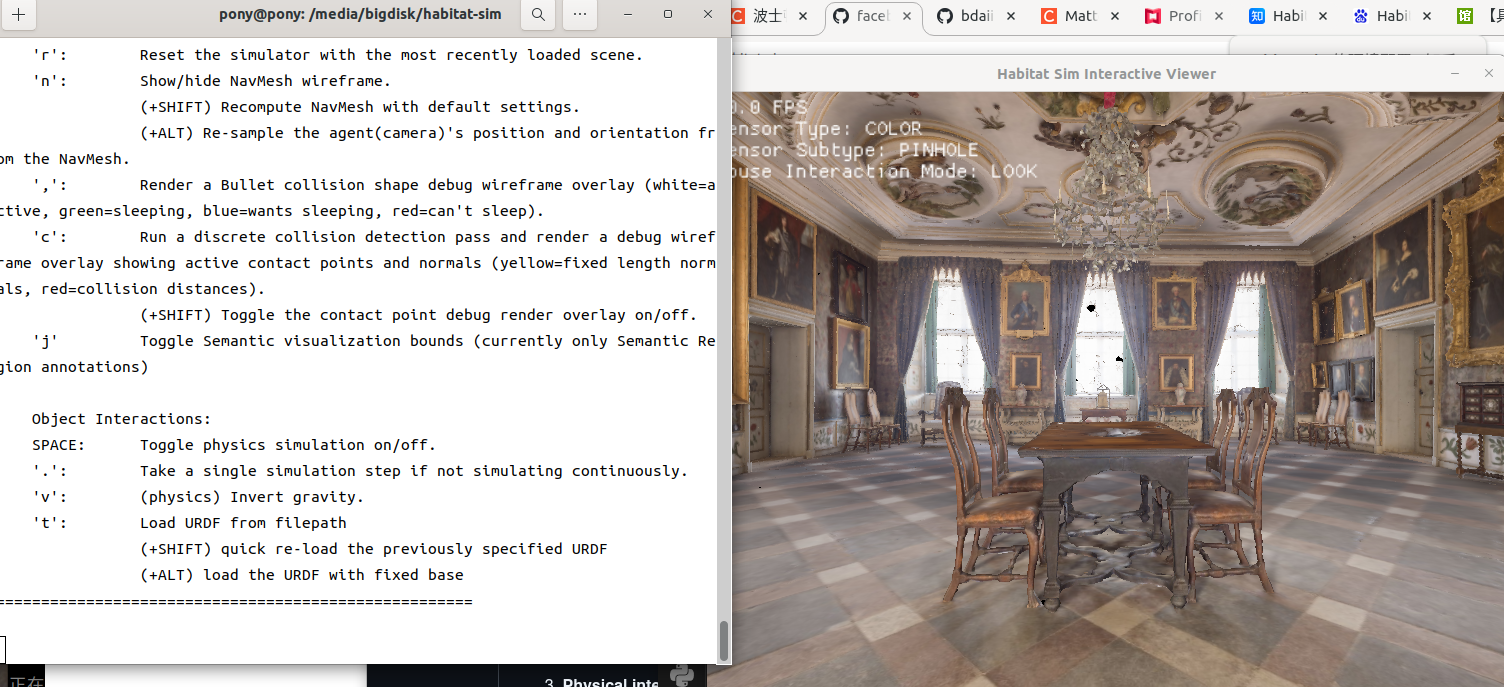
使用交互式查看器测试环境:
git clone https://github.com/facebookresearch/habitat-sim.gitcd ../habitat-simpython examples/viewer.py --scene /media/bigdisk/versioned_data/habitat_test_scenes/skokloster-castle.glb
故障排除: 如果出现
ImportError: numpy.core.multiarray failed to import这个问题,请执行:pip uninstall numpy # 需执行两次以完全卸载 pip install numpy==1.26.4
3. 数据集配置
3.1 下载Matterport3D数据集
使用Matterport API令牌进行下载:
# 设置API令牌
MATTERPORT_TOKEN_ID=a5e78a715f3285af
MATTERPORT_TOKEN_SECRET=676cd40457b6b0fe59adf497e32bd6c3DATA_DIR=</path/to/vlfm/data># 下载HM3D训练集
python -m habitat_sim.utils.datasets_download \--username $MATTERPORT_TOKEN_ID --password $MATTERPORT_TOKEN_SECRET \--uids hm3d_train_v0.2 \--data-path $DATA_DIR# 下载HM3D验证集
python -m habitat_sim.utils.datasets_download \--username $MATTERPORT_TOKEN_ID --password $MATTERPORT_TOKEN_SECRET \--uids hm3d_val_v0.2 \--data-path $DATA_DIR
3.2 Object导航任务数据
wget https://dl.fbaipublicfiles.com/habitat/data/datasets/objectnav/hm3d/v1/objectnav_hm3d_v1.zip &&
unzip objectnav_hm3d_v1.zip &&
mkdir -p $DATA_DIR/datasets/objectnav/hm3d &&
mv objectnav_hm3d_v1 $DATA_DIR/datasets/objectnav/hm3d/v1 &&
rm objectnav_hm3d_v1.zip
4. 模型权重配置
4.1 下载预训练模型
VLFM需要三个核心模型的权重文件:
cd vlfm/dataexport http_proxy="http://127.0.0.1:7890"
export https_proxy="http://127.0.0.1:7890"# 下载MobileSAM分割模型权重
https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt (只可点击下载)# 下载GroundingDINO检测模型权重
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth# 下载YOLOv7检测模型权重
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6e.pt
各模型功能示例:
| 模型 | 功能 | 示例图 |
|---|---|---|
| MobileSAM | 图像分割 |  |
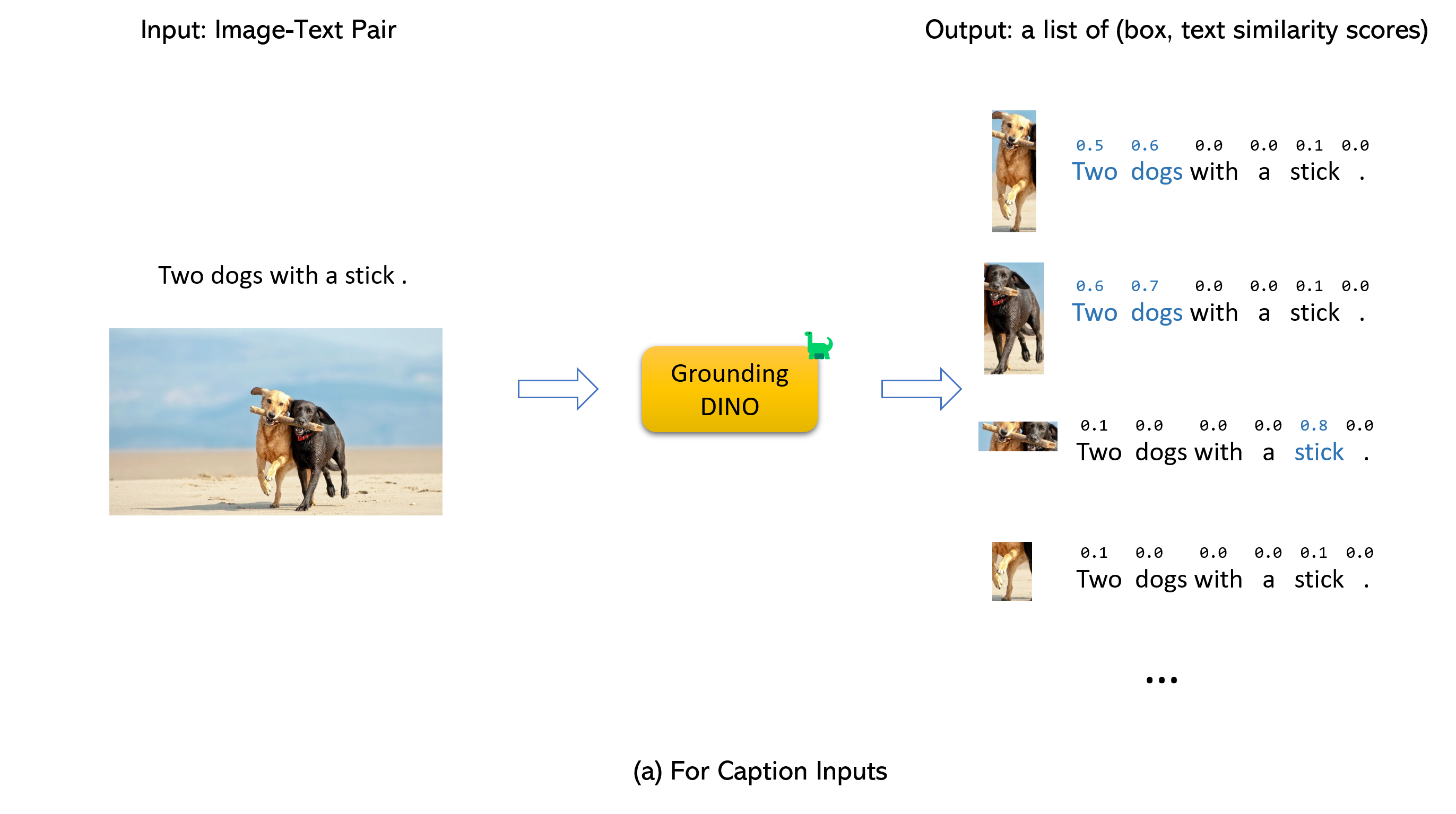
| GroundingDINO | 语言引导的对象检测 |  |
| YOLOv7 | 通用目标检测 | 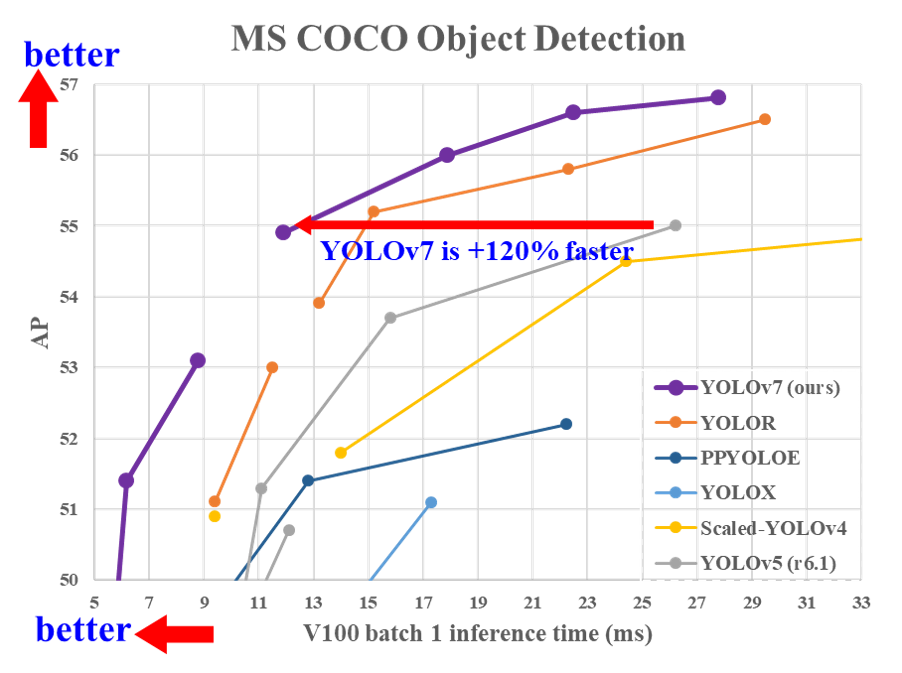 |
4.2 安装VLFM包
根据使用场景选择安装方式:
git config --global http.postBuffer 5242880000
git config --global http.receivepack 5242880000#如果你按照直接安装测试了Habitat,没有按照0.2.4版本安装,那需要卸载然后再安装
pip uninstall habitat-sim habitat-baselines habitat-lab# Habitat仿真环境,出问题可以看这个issue:https://github.com/bdaiinstitute/vlfm/issues/77
pip install -e .[habitat]# Spot实体机器人
# pip install -e .[reality]
因为我们是基于CUDA 11.8的,所以要对pyproject.toml做出如下修改
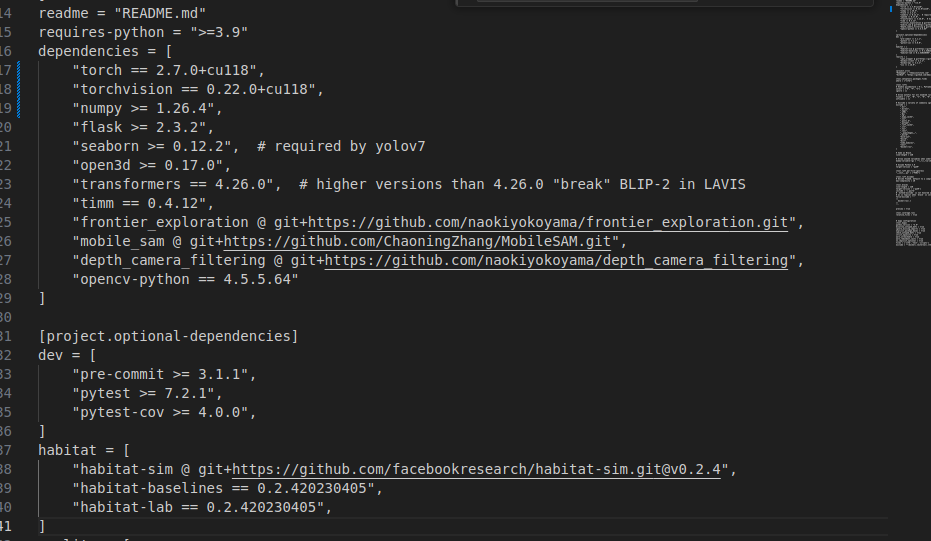
4.3 仿真实现
要运行评估,必须先在后台加载各种模型。只需运行以下命令即可完成一次:
sudo apt-get install tmux
./scripts/launch_vlm_servers.sh
(您可能需要chmod +x先运行此文件。)此命令将创建一个 tmux 会话,该会话将开始加载用于 VLFM 的各种模型并通过 提供服务flask。完成后,请务必终止 tmux 会话以释放您的 GPU。
运行以下命令在 HM3D 数据集上进行评估:
python -m vlfm.run
如果提示下面的这个,输入一下即可生成dummy_policy.pth文件
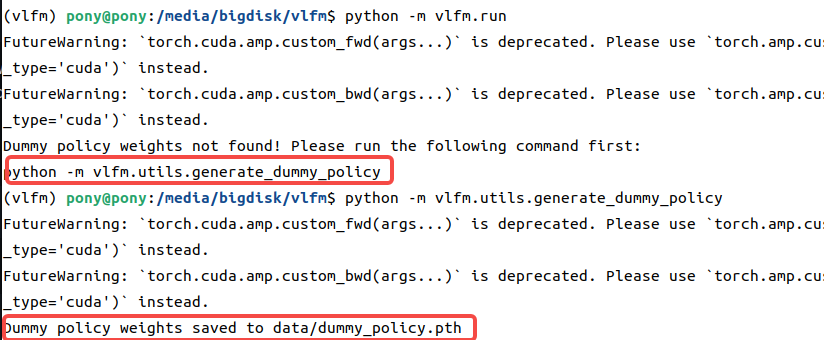
然后再次运行即可

如果需要生成视频,您需要将“磁盘”添加到habitat_baselines.eval.video_option(“[‘disk’]”),您还需要设置habitat_baselines.video_dir您选择的目录。如果不存在,则会创建该目录,然后我们的代码将会改成这样
python -m vlfm.run habitat_baselines.video_dir=itm_aug2 habitat_baselines.eval.video_option='["disk"]' \habitat_baselines.rl.policy.name=HabitatITMPolicyV2 habitat.task.lab_sensors.base_explorer.turn_angle=30 habitat_baselines.num_environments=1 habitat_baselines.eval.split=val_mini
4.4 Vscode 环境配置
如果需要自定义运行和调试,可以首先打开文件夹, 点击“文件”选项卡下的“打开文件夹”。
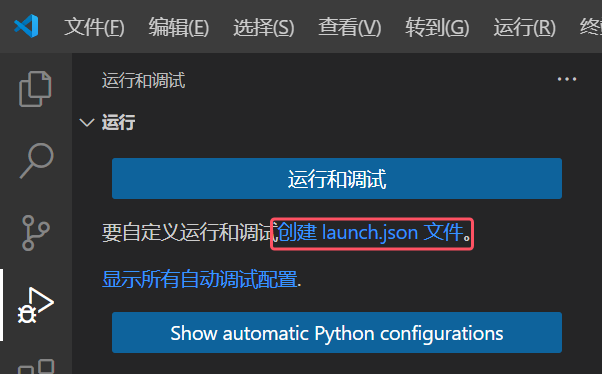
或者直接在“运行”选项卡下点击“添加配置…”
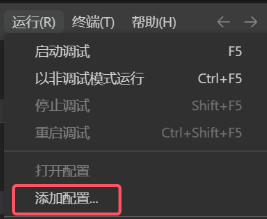
接着会有选择调试器和选择调试配置,还是按照之前所说的进行选择。在打开的文件夹中,会创建一个.vscode子文件夹并在其中创建launch.json文件。
该launch.json是一个调试的配置文件,控制.vscode子文件夹所在的文件夹,其中可以包含多个配置(图20中只有一个),每个配置由多个属性决定,下面将说明这些属性的作用。
以下三个属性是必须的,具体可以参考Visual Studio Code基础:使用debugpy调试python程序
- type:调试器的类型。例如,本文中的调试器是debugpy。
- request:调试的模式,有两种模式可供选择。
- launch:启动程序(由program属性决定)并调试。
- 将程序附加到一个正在运行的进程中进行调试。
- name:配置的名字,显示在“运行与调试”选项栏。
当.vscode文件夹中存在launch.json文件时,vscode会自动识别其中的调试配置并呈现在“运行与调试”选项栏中。想要打开配置文件很容易,只需要使用“运行与调试”选项栏的齿轮或直接在“运行”选项卡下点击“打开配置”,它们会打开当前选择的配置所在的配置文件。
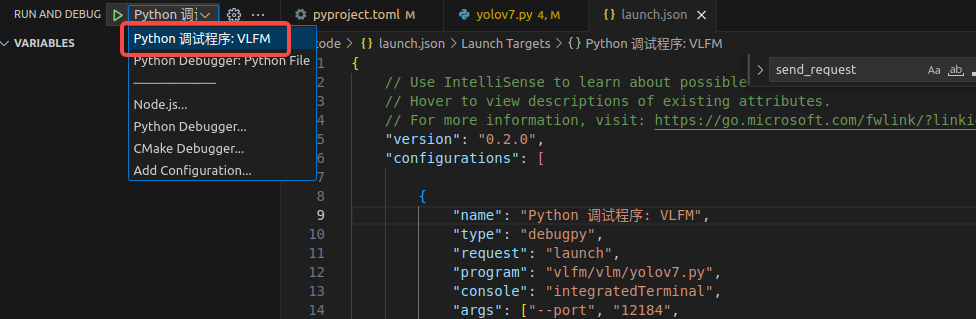
我们这里提供一个配置,用来测试启动yolov7的脚本
{// Use IntelliSense to learn about possible attributes.// Hover to view descriptions of existing attributes.// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Python 调试程序","type": "debugpy","request": "launch","program": "/media/bigdisk/vlfm/vlfm/vlm/yolov7.py","console": "integratedTerminal",// "args": ["--port", "12184",// "--input", "images/ADE/ADE_test_00000001.jpg",// "--opts", "MODEL.WEIGHTS", "weights/MaskFormer_R50_512x512.pkl"],"python": "/home/pony/miniconda3/envs/vlfm/bin/python","env": {"PYTHONPATH": "${PYTHONPATH}:/media/bigdisk/vlfm"}}]
}
5. 代码梳理
5.1 pyproject.toml 文件解析
这是一个 Python 项目的配置文件 pyproject.toml,用于定义项目构建设置、依赖关系和各种开发工具的配置。以下是对文件各部分的解释:
5.1.1 基本项目设置
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
- 指定使用 setuptools 作为构建系统,要求版本不低于 61.0
5.1.2 项目信息
[project]
name = "vlfm"
version = "0.1"
description = "Vision-Language Frontier Maps"
- 项目名称为"vlfm"(Vision-Language Frontier Maps)
- 当前版本为 0.1
5.1.3 依赖管理
项目依赖包括:
- 核心机器学习库:torch 2.7.0、torchvision 0.22.0
- 视觉相关:opencv-python、mobile_sam、open3d
- 语言模型:transformers 4.26.0
- 其他工具库及自定义包
5.1.4 可选依赖
文件定义了三组可选依赖:
dev- 开发工具,包括 pre-commit、pytest 等habitat- 与 Habitat 模拟环境相关的依赖reality- 与 Spot 机器人实际操作相关的依赖(包括波士顿动力的 SDK)
5.1.5 Ruff (代码检查)
[tool.ruff]
select = ["E", "F", "I"] # 启用 pycodestyle、Pyflakes 和 import 排序
line-length = 120 # 与 Black 保持一致的行长度
target-version = "py39" # 针对 Python 3.9
5.1.6 Black (代码格式化)
[tool.black]
line-length = 120
target-version = ['py39']
5.1.7 Mypy (类型检查)
[tool.mypy]
python_version = "3.9"
disallow_untyped_defs = true
5.2 整体项目梳理与代码呈现
VLFM 的架构将视觉语言模型与传统的机器人映射和导航技术相结合,创建了一个能够理解语义目标并有效探索环境的系统。这是整体流程图:
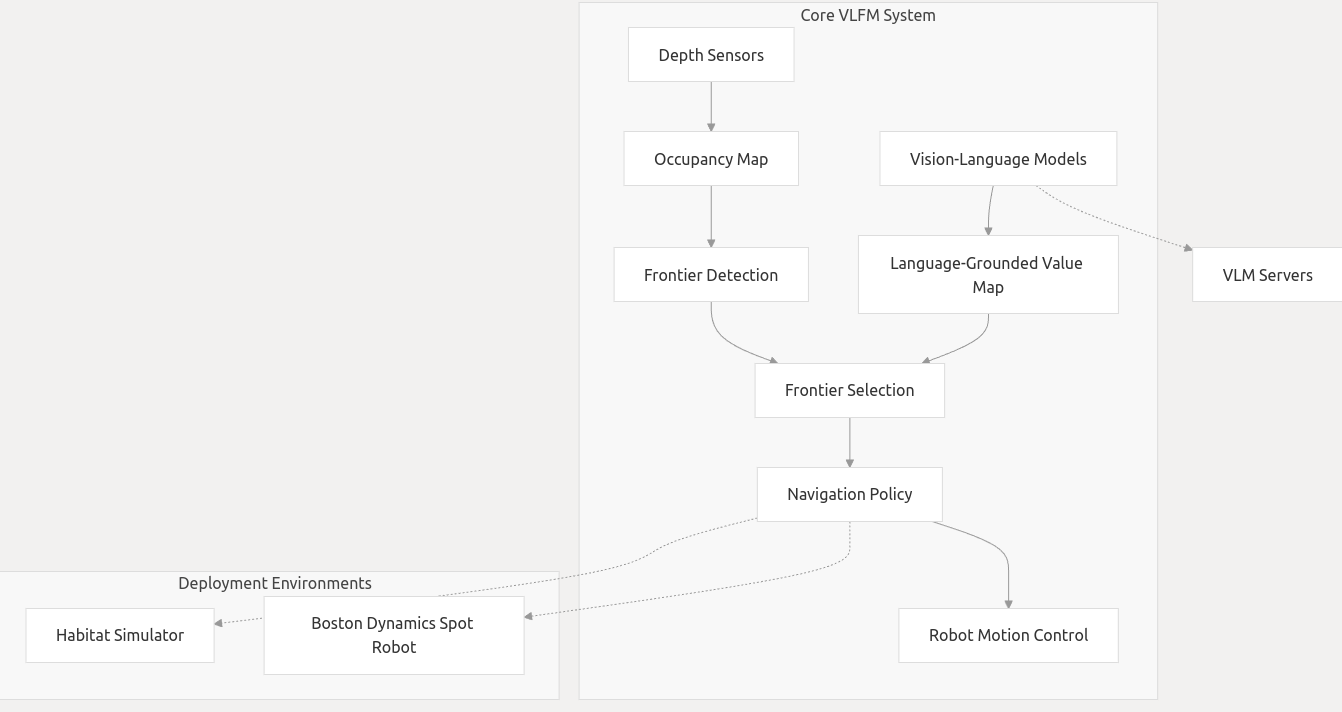
VLFM 使用多种视觉语言模型来理解视觉输入并通过语义描述识别对象:
- GroundingDINO:用于通过自然语言查询进行对象检测
- BLIP2ITM:执行图像文本匹配以验证对象存在
- MobileSAM:提供分割功能
- YOLOv7:用于一般物体检测
5.2.1 代码结构概述
VLFM 项目的代码结构组织清晰,主要包括以下几个核心模块:
- 视觉语言模型 (vlm) - 包含各种视觉语言模型的封装和接口
- 策略实现 (policy) - 实现导航决策逻辑
- 地图构建 (mapping) - 负责构建和维护环境地图
- 环境交互 (reality) - 处理与真实或模拟环境的交互
- 工具函数 (utils) - 提供各种辅助功能

5.2.2 视觉语言模型的集成
VLFM 将多种视觉语言模型封装为统一的接口,方便策略调用和集成。以 YOLOv7 的实现为例:
class YOLOv7:def __init__(self, weights: str, image_size: int = 640, half_precision: bool = True):# 设置设备(GPU/CPU)self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")self.half_precision = half_precision and self.device.type != "cpu"# 加载模型self.model = attempt_load(weights, map_location=self.device)stride = int(self.model.stride.max())self.image_size = check_img_size(image_size, s=stride)self.model = TracedModel(self.model, self.device, self.image_size)if self.half_precision:self.model.half()# 模型预热,提高第一次推理速度if self.device.type != "cpu":dummy_img = torch.rand(1, 3, int(self.image_size * 0.7), self.image_size).to(self.device)if self.half_precision:dummy_img = dummy_img.half()# 进行三次推理预热for i in range(3):self.model(dummy_img)def predict(self, image: np.ndarray, conf_thres: float = 0.25, iou_thres: float = 0.45, classes: Optional[List[str]] = None, agnostic_nms: bool = False) -> ObjectDetections:# 图像预处理orig_shape = image.shapeimg = cv2.resize(image, (self.image_size, int(self.image_size * 0.7)), interpolation=cv2.INTER_AREA)img = letterbox(img, new_shape=self.image_size)[0]img = img.transpose(2, 0, 1)img = np.ascontiguousarray(img)# 转换为torch张量并执行推理img = torch.from_numpy(img).to(self.device)img = img.half() if self.half_precision else img.float()img /= 255.0if img.ndimension() == 3:img = img.unsqueeze(0)with torch.inference_mode():pred = self.model(img)[0]# 应用非极大值抑制pred = non_max_suppression(pred, conf_thres, iou_thres, classes=classes, agnostic=agnostic_nms)# 处理检测结果pred = pred[0]pred[:, :4] = scale_coords(img.shape[2:], pred[:, :4], orig_shape).round()# 归一化坐标pred[:, 0] /= orig_shape[1]pred[:, 1] /= orig_shape[0]pred[:, 2] /= orig_shape[1]pred[:, 3] /= orig_shape[0]# 创建检测结果对象boxes = pred[:, :4]logits = pred[:, 4]phrases = [COCO_CLASSES[int(i)] for i in pred[:, 5]]return ObjectDetections(boxes, logits, phrases, image_source=image, fmt="xyxy")