网站 设计 分辨率wordpress+制作首页模板下载
例题1.汉诺塔问题
1.题目
题目链接:汉诺塔问题
在经典汉诺塔问题中,有 3 根柱子及 N 个不同大小的穿孔圆盘,盘子可以滑入任意一根柱子。一开始,所有盘子自上而下按升序依次套在第一根柱子上(即每一个盘子只能放在更大的盘子上面)。移动圆盘时受到以下限制:
(1) 每次只能移动一个盘子;
(2) 盘子只能从柱子顶端滑出移到下一根柱子;
(3) 盘子只能叠在比它大的盘子上。
请编写程序,用栈将所有盘子从第一根柱子移到最后一根柱子。
你需要原地修改栈。
示例 1:输入:A = [2, 1, 0], B = [], C = []输出:C = [2, 1, 0]
示例 2:输入:A = [1, 0], B = [], C = []输出:C = [1, 0]
提示:
A 中盘子的数目不大于 14 个。
2.算法原理
如何来解决汉诺塔问题
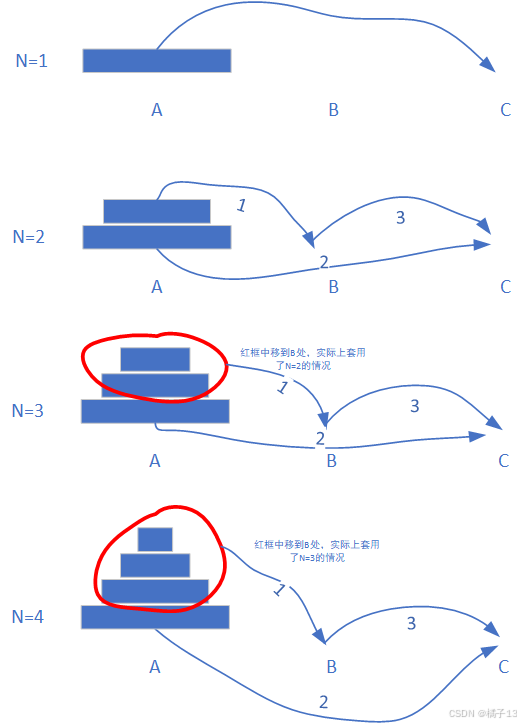
我们发现每一步都可以看成N=2的情况(将塔除了最后一层之外的上面看成一个整体),然后上面部分又可以用前一步来解决。
为什么可以用递归来解决?
大问题→相同类型的子问题
子问题→相同类型的子问题
1.重复子问题——>函数头的设计
将A上面的一堆盘子,借助B,转移到C柱子上面——>dfs(A,B,C,int n)
2.只关心一个子问题在做什么——>函数体的设计
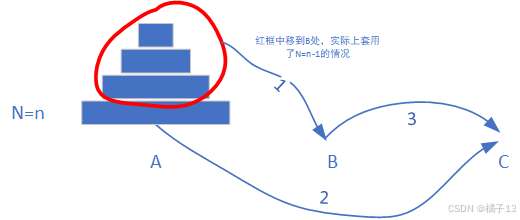
伪代码如下:
1. dfs(A,C,B,n-1)
2. A.back()——>C
3. dfs(B,A,C,n-1)
3.递归的出口
N=1
A.back()——>C
3.编写代码
class Solution {
public:void hanota(vector<int>& A, vector<int>& B, vector<int>& C) {int n = A.size();dfs(A,B,C,n);}void dfs(vector<int>& A, vector<int>& B, vector<int>& C, int n){if(n==1){C.push_back(A.back());A.pop_back();return;}dfs(A,C,B,n-1);//将A的n-1个盘子通过C移动到BC.push_back(A.back());A.pop_back();dfs(B,A,C,n-1);//将B的n-1个盘子通过A移动到C}
};
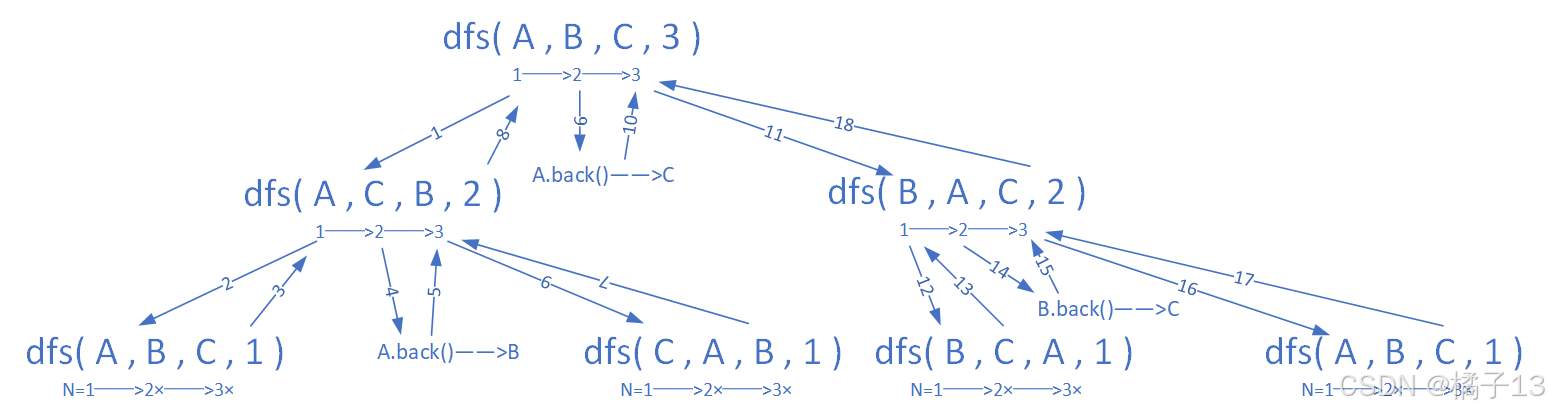
4.递归的细节展开图
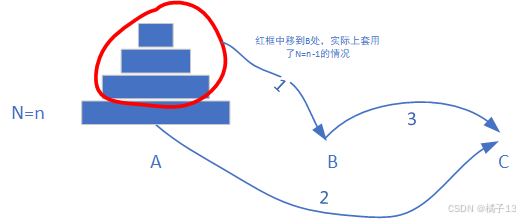
1——>2——>3中的三个步骤分别是上图的三个步骤。
例题2. 合并两个有序链表
1.题目
题目链接:合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
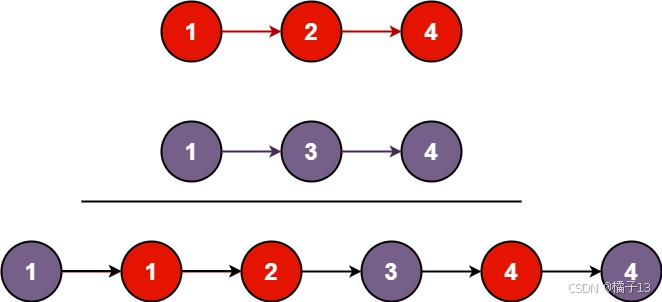
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
2.算法原理
1.重复子问题——>函数头的设计
合并两个有序链表——>Node* dfs(list1,list2)
2.只关心一个子问题在做什么——>函数体的设计
比大小(list1->val <= list2->val)
list1->next = dfs(list1->next,list2);
return list1;
另一半同理
3.递归的退出
list1 == nullptr
return list2
or
list2 == nullptr
return list1
3.编写代码
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if(list1 == nullptr){return list2;}if(list2 == nullptr){return list1;}if(list1->val <= list2->val){list1->next = mergeTwoLists(list1->next, list2);return list1;}else{list2->next = mergeTwoLists(list1, list2->next);return list2;}}
};
4.小总结
循环 vs 递归
都是解决重复子问题!所以循环与递归可以进行相互转化!
但是有时候代码用循环好写,有时候用递归好写,原因是什么?见第三个问题!
递归 vs 深搜
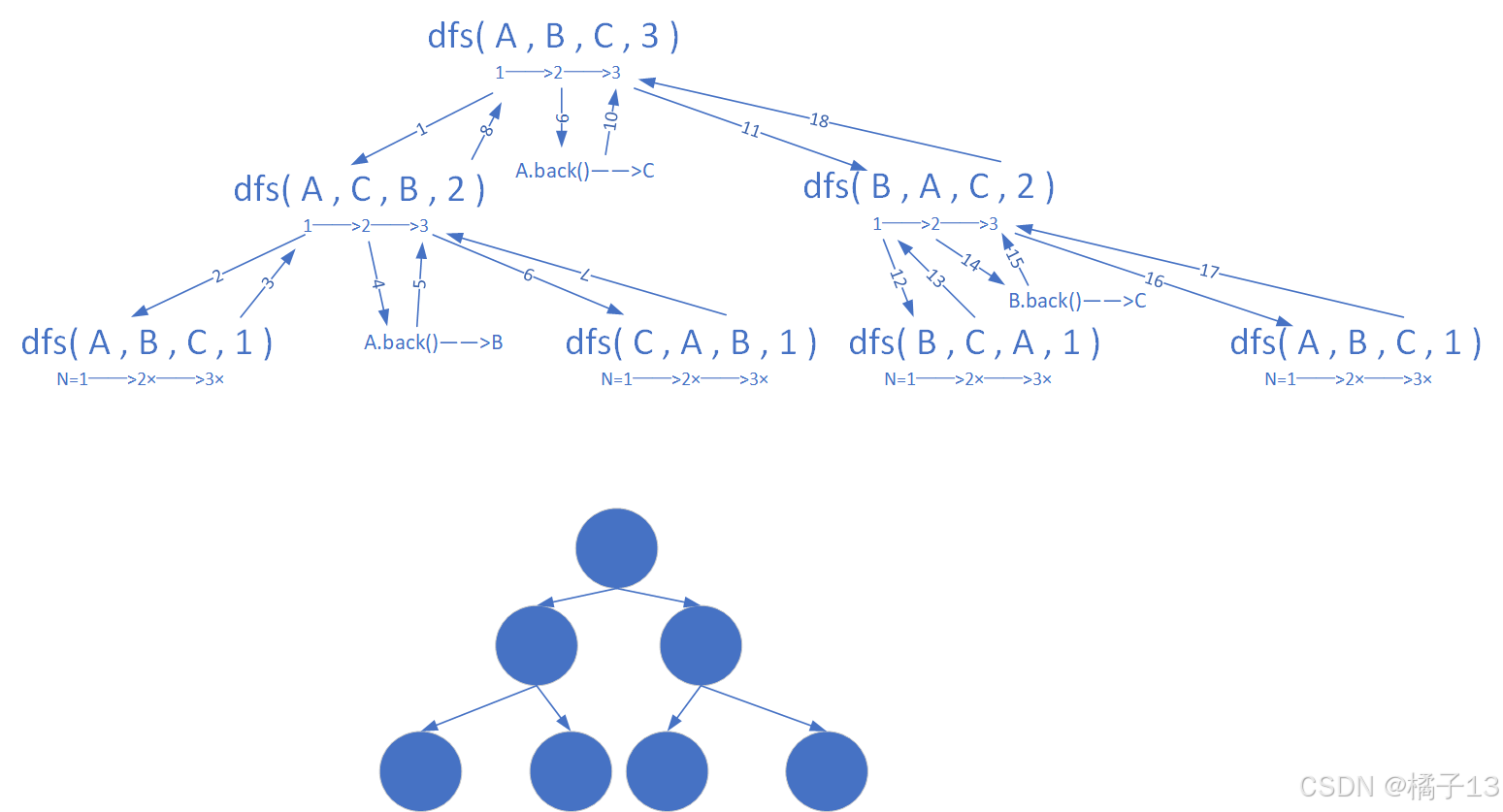
递归的展开图,实际上就是对一颗树做一次深度优先遍历!(dfs)
以汉诺塔问题为例,其递归展开图就是一颗二叉树!
什么时候循环好用,什么时候递归好用?
对于递归问题,由于其展开图是一颗多叉树,如果要改成循环,需要借助数据结构-栈所以代码的成本就出现了。
例子:利用栈来遍历树,这里举例后序遍历。
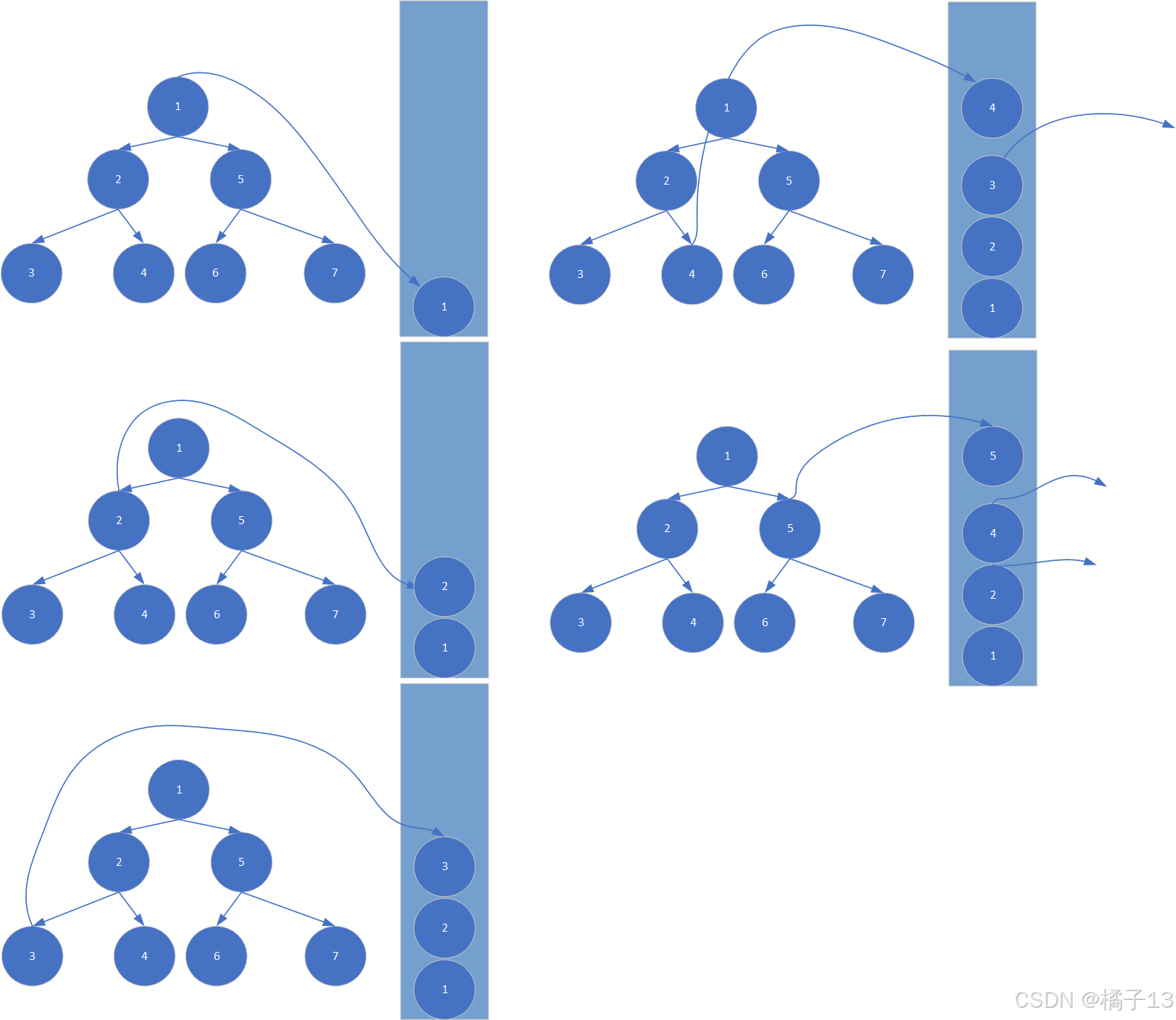
伪代码:
// 后序遍历(左-右-根)
function postOrderTraversal(root):if root is null:return// 初始化栈和辅助变量stack = new Stack()current = rootlastVisited = null // 记录最后访问的节点while current is not null or not stack.isEmpty():// 1. 遍历到最左侧节点,全部入栈while current is not null:stack.push(current)current = current.left// 查看栈顶节点(不弹出)topNode = stack.peek()// 2. 判断是否可以访问当前节点:// a. 右子树为空,直接访问// b. 右子树已访问过(通过lastVisited判断)if topNode.right is null or topNode.right == lastVisited:// 访问节点visit(topNode)// 弹出栈顶节点stack.pop()// 更新最后访问节点lastVisited = topNode// 当前节点置空,避免重复入栈current = nullelse:// 3. 处理右子树current = topNode.right什么时候循环舒服?
对于展开图仅是一个分支的树的递归问题来说,改成循环问题,比较轻松。
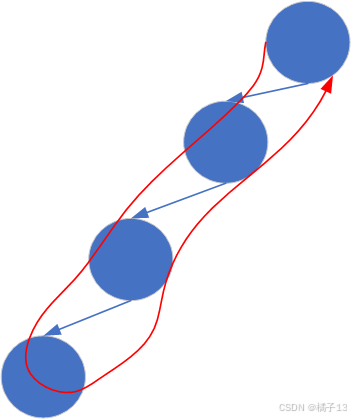
从另一个角度想,一个入栈的过程本质上是一个循环,确切地说是需要循环(入栈前使用->正序,出栈后使用->逆序)。
例子:打印一个数组
1.循环
void printnums(vector<int>& nums)
{for(int i = 0; i < nums.size();i++){cout<< nums[i] <<endl;}cout<<endl;
}2.递归
void printnums(vector<int>& nums)
{dfs(nums,0);
}
void dfs(vector<int>& nums, int i)
{if(i == num.size()) return;cout<< nums[i]<<" ";dfs(nums, i+1);
}
//递归逆序打印
void dfs(vector<int>& nums, int i)
{if(i == num.size()) return;dfs(nums, i+1);//交换一下cout<< nums[i]<<" ";
}
这里可以联想到先序遍历vs后序遍历(排除对比中序遍历,因为其只存在二叉树中),它们本质上是递归与打印先后的改变。
例题3.反转链表
1.题目
题目链接:反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
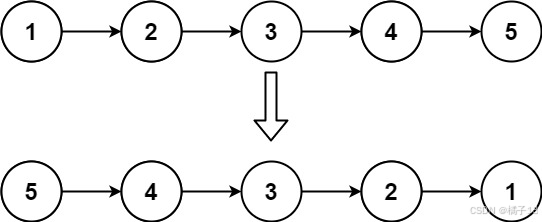
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
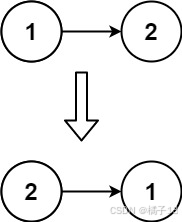
输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
2.算法原理
第一种视角:从宏观角度看待问题
1.让当前节点后面的链表先逆置,并且返回头结点
2.让当前节点添加到逆置后的链表即可
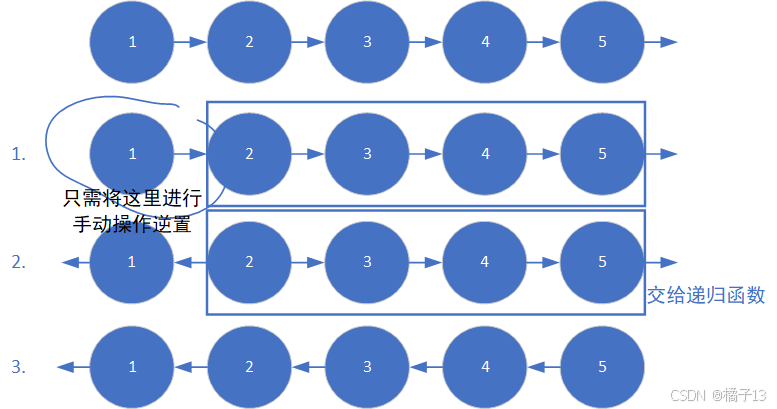
第二个视角:将链表看成一颗树,仅需做一次深度优先遍历即可(后序遍历)
newhead一路下去到尾部,然后递归返回时,顺带着把每个节点逆置。
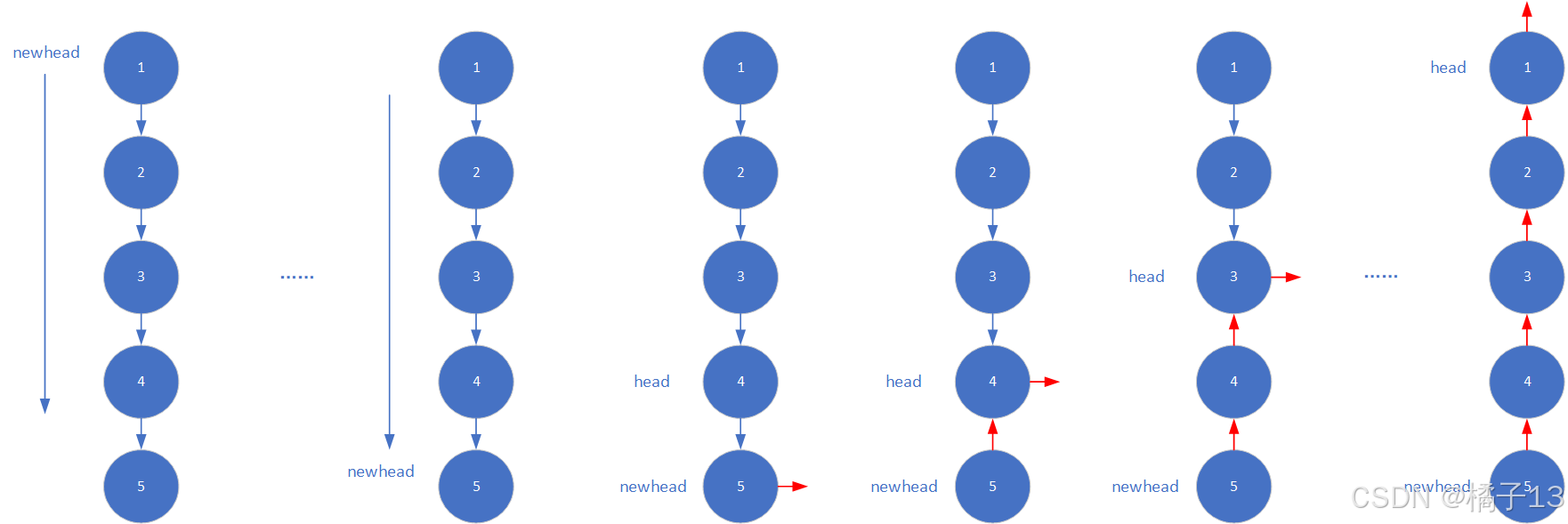
递归展开图如下:

3.编写代码
class Solution {
public:ListNode* reverseList(ListNode* head) {if(head == nullptr || head->next == nullptr){return head;}ListNode* newhead = reverseList(head->next);head->next->next = head;head->next = nullptr;return newhead;}
};
例题4.两两交换链表中的节点
1.题目
题目链接:两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
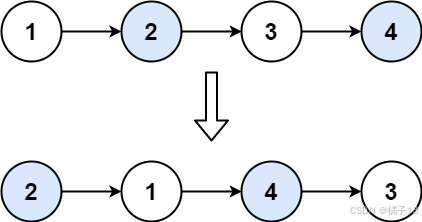
输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
链表中节点的数目在范围 [0, 100] 内
0 <= Node.val <= 100
2.算法原理
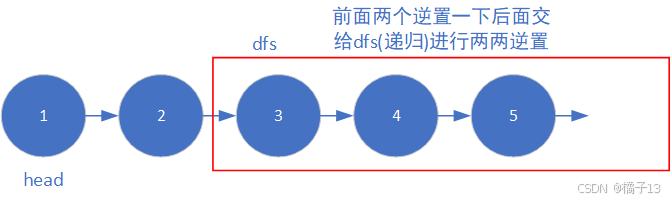
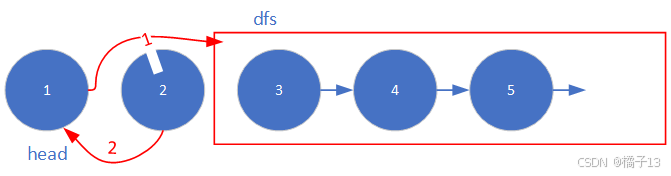
3.编写代码
class Solution {
public:ListNode* swapPairs(ListNode* head) {if(head == nullptr || head->next == nullptr){return head;}ListNode* newhead = head->next;head->next = swapPairs(newhead->next);newhead->next = head;return newhead;}
};
例题5.快速幂pow(x,n)
1.题目
实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,x^n )。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
输入:x = 2.10000, n = 3
输出:9.26100
示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
提示:
-100.0 < x < 100.0
-231 <= n <= 231-1
n 是一个整数
要么 x 不为零,要么 n > 0 。
-104 <= xn <= 104
2.算法原理
1.相同子问题——>函数头
double myPow(x,n)
2.只关心每一个子问题——>函数体
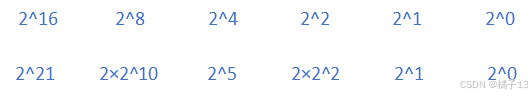
tmp = pow(x,n/2);
return n%2 == 0 ? tmp*tmp : tmp*tmp*x;
3.递归出口
n==0,return 1;
细节问题
1.n为负数时。
把n变成正数,x变成分母。
2.n是2^31,int存不下。
int类型的取值“陷阱”
在 C/C++ 中,int是有符号整数类型,其取值范围由硬件和标准决定,最常见的是 “32 位有符号整数”,范围是:
-2³¹ ~ 2³¹ - 1,对应的具体数值是 -2147483648(最小值)~ 2147483647(最大值)
这个范围有个关键特点:最小值的绝对值比最大值大 1。
比如:
最大值 2147483647 的绝对值是 2147483647(在范围内);
最小值 -2147483648 的绝对值是 2147483648(超出了int的最大值,会导致溢出)。
所以在计算2⁻³¹时,直接转换成1/2³¹会出现问题。
解决方式:转成long long类型
long long是 64 位有符号整数,它的取值范围是 -9223372036854775808(-2⁶³) ~ 9223372036854775807(2⁶³-1)。
这个范围的关键优势是:它能完全容纳int最小值的绝对值。
3.编写代码
class Solution {
public:double myPow(double x, int n) {long long N = n;if(N==0) return 1.0;if(N<0){x = 1/x;N = -N;}double tmp = myPow(x,N/2);return N%2 == 0 ? tmp*tmp:tmp*tmp*x;}
};