【vllm】源码解读:vLLM 中 Data Parallelism DP=8 核心原理详解
目录
- vLLM DP=8 概述
- vLLM 中的 DP 架构
- DP 引擎核心实现
- 请求调度与批处理
- DP 协调与同步
- vLLM DP 配置与部署
- 性能特点与适用场景
vLLM DP=8 概述
在 vLLM 中,Data Parallelism (DP=8) 是通过多个独立的引擎核心进程实现的并行策略。每个 DP 副本都是一个独立的 DPEngineCoreProc 进程,通过 ZMQ 套接字与前端进程通信,实现 8 倍吞吐量提升。
vLLM DP 架构特点
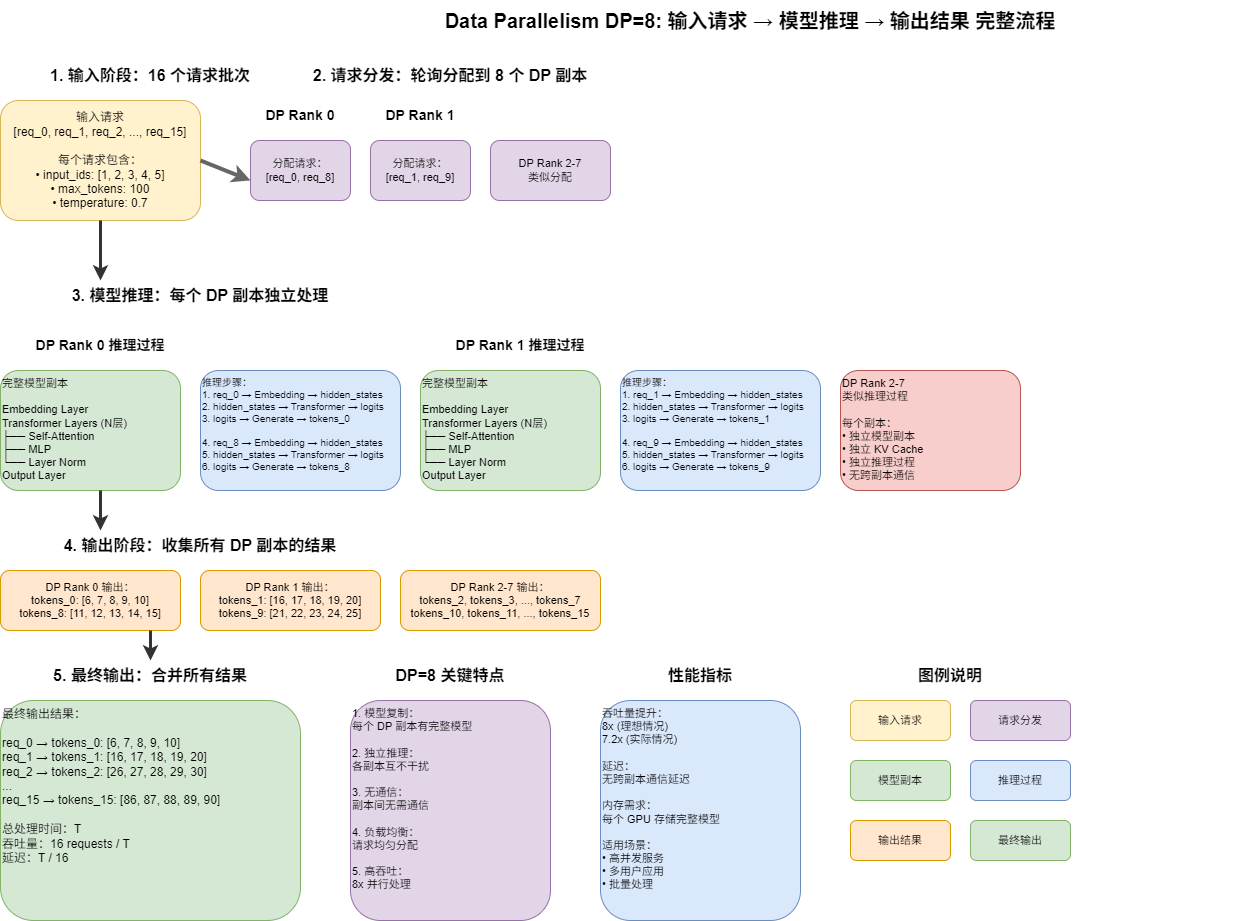
vLLM DP=8 架构:
├── Frontend Process (API Server)
├── DP Coordinator Process (可选)
├── DP Rank 0: DPEngineCoreProc + GPU组1 (TP=8)
├── DP Rank 1: DPEngineCoreProc + GPU组2 (TP=8)
├── DP Rank 2: DPEngineCoreProc + GPU组3 (TP=8)
├── DP Rank 3: DPEngineCoreProc + GPU组4 (TP=8)
├── DP Rank 4: DPEngineCoreProc + GPU组5 (TP=8)
├── DP Rank 5: DPEngineCoreProc + GPU组6 (TP=8)
├── DP Rank 6: DPEngineCoreProc + GPU组7 (TP=8)
└── DP Rank 7: DPEngineCoreProc + GPU组8 (TP=8)
vLLM DP 核心优势
- 独立进程:每个 DP 副本是独立的引擎核心进程
- ZMQ 通信:通过 ZMQ 套接字进行进程间通信
- 负载均衡:智能分发请求到不同 DP 副本
- 协调同步:DP Coordinator 协调所有副本的同步
vLLM 中的 DP 架构
1. DPEngineCoreProc 核心实现
进程架构
在 vLLM 中,每个 DP 副本都是一个独立的 DPEngineCoreProc 进程:
class DPEngineCoreProc(EngineCoreProc):"""ZMQ-wrapper for running EngineCore in background processin a data parallel context."""def __init__(self, vllm_config, local_client, handshake_address, executor_class, log_stats, client_handshake_address=None):# 计数前向传播步数,用于与 DP 对等节点同步self.step_counter = 0self.current_wave = 0self.last_counts = (0, 0)# 初始化引擎dp_rank = vllm_config.parallel_config.data_parallel_ranksuper().__init__(vllm_config, local_client, handshake_address,executor_class, log_stats, client_handshake_address,dp_rank)
DP 初始化过程
def _init_data_parallel(self, vllm_config: VllmConfig):# 配置 GPU 和无状态进程组用于数据并行dp_rank = vllm_config.parallel_config.data_parallel_rankdp_size = vllm_config.parallel_config.data_parallel_sizelocal_dp_rank = vllm_config.parallel_config.data_parallel_rank_localassert dp_size > 1assert 0 <= local_dp_rank <= dp_rank < dp_size# 为每个 DP rank 设置唯一的 KV transfer 配置if vllm_config.kv_transfer_config is not None:vllm_config.kv_transfer_config.engine_id = (f"{vllm_config.kv_transfer_config.engine_id}_dp{local_dp_rank}")self.dp_rank = dp_rankself.dp_group = vllm_config.parallel_config.stateless_init_dp_group()
2. 并行配置管理
ParallelConfig 配置
@dataclass
class ParallelConfig:data_parallel_size: int = 1"""数据并行组数量"""data_parallel_size_local: int = 1"""本地数据并行组数量"""data_parallel_rank: int = 0"""数据并行组中的 rank"""data_parallel_rank_local: Optional[int] = None"""本地数据并行组中的 rank"""data_parallel_master_ip: str = "127.0.0.1""""数据并行主节点 IP"""data_parallel_rpc_port: int = 29550"""数据并行消息端口"""data_parallel_master_port: int = 29500"""数据并行主节点端口"""data_parallel_backend: str = "mp""""数据并行后端,mp 或 ray"""
DP 组管理
def stateless_init_dp_group(self) -> ProcessGroup:"""初始化无状态 DP 进程组"""if self.data_parallel_size == 1:return None# 创建 DP 进程组dp_group = torch.distributed.new_group(ranks=list(range(self.data_parallel_size)),backend="nccl")return dp_group
DP 引擎核心实现
1. DP 忙碌循环
核心处理循环
def run_busy_loop(self):"""DP 引擎核心的忙碌循环"""while True:# 1) 轮询输入队列直到有工作要做self._process_input_queue()# 2) 执行引擎步骤executed = self._process_engine_step()self._maybe_publish_request_counts()local_unfinished_reqs = self.scheduler.has_unfinished_requests()if not executed:if not local_unfinished_reqs and not self.engines_running:# 所有引擎都空闲continue# 如果模型没有执行任何就绪请求,必须执行虚拟批次self.execute_dummy_batch()# 3) All-reduce 操作确定全局未完成请求self.engines_running = self._has_global_unfinished_reqs(local_unfinished_reqs)if not self.engines_running:# 通知客户端暂停循环self._notify_wave_complete()self.current_wave += 1self.step_counter = 0
全局同步检查
def _has_global_unfinished_reqs(self, local_unfinished: bool) -> bool:# 优化:每 32 步执行一次完成同步 all-reduceself.step_counter += 1if self.step_counter % 32 != 0:return Truereturn ParallelConfig.has_unfinished_dp(self.dp_group, local_unfinished)
2. 请求处理机制
请求添加
def add_request(self, request: Request, request_wave: int = 0):if self.has_coordinator and request_wave != self.current_wave:if request_wave > self.current_wave:self.current_wave = request_waveelif not self.engines_running:# 收到已完成波的请求,通知前端启动下一个self.output_queue.put_nowait((-1, EngineCoreOutputs(start_wave=self.current_wave)))super().add_request(request, request_wave)
客户端请求处理
def _handle_client_request(self, request_type: EngineCoreRequestType, request: Any):if request_type == EngineCoreRequestType.START_DP_WAVE:new_wave, exclude_eng_index = requestif exclude_eng_index != self.engine_index and (new_wave >= self.current_wave):self.current_wave = new_waveif not self.engines_running:logger.debug("EngineCore starting idle loop for wave %d.", new_wave)self.engines_running = Trueelse:super()._handle_client_request(request_type, request)
请求调度与批处理
1. DP 负载均衡
负载统计发布
def _maybe_publish_request_counts(self):if not self.publish_dp_lb_stats:return# 发布请求计数(如果已更改)counts = self.scheduler.get_request_counts()if counts != self.last_counts:self.last_counts = countsstats = SchedulerStats(*counts,step_counter=self.step_counter,current_wave=self.current_wave)self.output_queue.put_nowait((-1, EngineCoreOutputs(scheduler_stats=stats)))
智能负载均衡
vLLM 的 DP 负载均衡考虑以下因素:
- 当前调度的请求数量
- 等待队列中的请求数量
- KV Cache 状态
- 前缀缓存优化
2. 批处理优化
虚拟批次执行
def execute_dummy_batch(self):"""当没有就绪请求时执行虚拟批次"""if self.has_coordinator:# 在协调器模式下,执行虚拟前向传播self.model_executor.execute_dummy_batch()
MoE 模型特殊处理
对于 MoE 模型(如 DeepSeek),vLLM 有特殊的 DP 处理:
# MoE 模型的 DP 同步要求
# 1. 前向传播必须对齐
# 2. 所有 rank 的专家层必须在每次前向传播时同步
# 3. 即使处理的请求少于 DP rank 数量
DP 协调与同步
1. DP Coordinator 进程
协调器作用
- 波次管理:协调所有 DP 副本的波次同步
- 负载均衡:收集各副本的负载统计信息
- 故障处理:监控副本状态,处理故障恢复
波次同步机制
def _notify_wave_complete(self):if self.dp_rank == 0 or not self.has_coordinator:# 通知客户端暂停循环logger.debug("Wave %d finished, pausing engine loop.", self.current_wave)client_index = -1 if self.has_coordinator else 0self.output_queue.put_nowait((client_index, EngineCoreOutputs(wave_complete=self.current_wave)))
2. ZMQ 通信机制
进程间通信
- 输入队列:接收来自前端的请求
- 输出队列:发送结果给前端
- 协调通信:与 DP Coordinator 的通信
通信优化
# ZMQ 套接字配置
handshake_address = f"tcp://{master_ip}:{master_port}"
client_handshake_address = f"tcp://{client_ip}:{client_port}"
vLLM DP 配置与部署
1. 启动配置
命令行参数
# 启动 DP=8, TP=8 配置
vllm serve deepseek-ai/DeepSeek-V2.5 \--data-parallel-size 8 \--tensor-parallel-size 8 \--data-parallel-backend mp \--data-parallel-master-ip 127.0.0.1 \--data-parallel-master-port 29500
环境变量配置
# 设置 DP 相关环境变量
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
export VLLM_DP_SIZE=8
export VLLM_TP_SIZE=8
2. 多节点部署
节点配置
# Node 0
python -m vllm.entrypoints.api_server \--model deepseek-ai/DeepSeek-V2.5 \--data-parallel-size 8 \--tensor-parallel-size 8 \--node-size 2 \--node-rank 0 \--master-addr 10.99.48.128 \--master-port 13345# Node 1
python -m vllm.entrypoints.api_server \--model deepseek-ai/DeepSeek-V2.5 \--data-parallel-size 8 \--tensor-parallel-size 8 \--node-size 2 \--node-rank 1 \--master-addr 10.99.48.128 \--master-port 13345
3. 外部负载均衡
外部 LB 模式
# 启用外部负载均衡
vllm serve model \--data-parallel-size 8 \--data-parallel-external-lb \--data-parallel-rank 0 # 显式指定 rank
混合 LB 模式
# 启用混合负载均衡
vllm serve model \--data-parallel-size 8 \--data-parallel-hybrid-lb \--data-parallel-start-rank 0
性能特点与适用场景
1. vLLM DP 性能特点
吞吐量提升
- 理想情况:8x 吞吐量提升
- 实际情况:7.2x 吞吐量提升(考虑通信开销)
- MoE 模型:可能略低(需要专家层同步)
延迟特性
- 无跨副本通信延迟:DP 副本间独立处理
- ZMQ 通信延迟:进程间通信开销
- 协调同步延迟:波次同步的额外开销
2. 适用场景
高并发服务
# 多用户并发场景
class MultiUserDPService:def __init__(self):self.dp_engine = DPEngineCoreProc() # DP=8def handle_concurrent_users(self, user_requests):# 将不同用户的请求分发到不同 DP 副本dp_assignments = self.distribute_by_user(user_requests)return self.dp_engine.process_batch(dp_assignments)
MoE 模型优化
# DeepSeek 等 MoE 模型的 DP 优化
class MoEDPConfig:def __init__(self):# 对注意力层使用 DPself.attention_dp = True# 对专家层使用 EP 或 TPself.expert_parallel = True# 启用专家并行self.enable_expert_parallel = True
批量推理
# 大规模批量推理
class BatchDPInference:def __init__(self):self.dp_engine = DPEngineCoreProc() # DP=8def process_large_batch(self, batch_size=1000):# 将大批次分发到 8 个 DP 副本dp_batches = self.split_batch(batch_size, 8)return self.dp_engine.process_parallel_batches(dp_batches)
3. 最佳实践
负载均衡优化
- 智能分发:考虑 KV Cache 状态和前缀缓存
- 动态调整:根据副本负载动态调整分发策略
- 故障恢复:单个副本故障不影响其他副本
内存管理
- 独立 KV Cache:每个 DP 副本维护独立的 KV Cache
- 前缀缓存优化:智能路由相似前缀到同一副本
- 内存监控:实时监控各副本的内存使用情况
总结
vLLM 中的 Data Parallelism DP=8 通过以下方式实现高效并行推理:
vLLM DP 核心特点
- 独立进程架构:每个 DP 副本是独立的
DPEngineCoreProc进程 - ZMQ 通信:通过 ZMQ 套接字实现进程间通信
- 协调同步:DP Coordinator 协调所有副本的波次同步
- 智能负载均衡:考虑 KV Cache 状态和前缀缓存优化
vLLM DP 实现优势
- 进程隔离:单个副本故障不影响其他副本
- 灵活部署:支持单节点和多节点部署
- MoE 优化:对 MoE 模型有特殊的 DP 处理机制
- 外部集成:支持外部负载均衡器集成
适用场景
- 高并发服务:多用户同时访问的场景
- MoE 模型:DeepSeek 等专家混合模型
- 批量推理:大规模离线推理任务
- 多租户:不同用户请求的隔离处理
通过 vLLM 的 DP=8 实现,可以在 8 个独立的引擎核心进程上并行处理请求,显著提高系统吞吐量和用户体验!