【向量检索与RAG全流程解析】HNSW原理、实践及阿里云灵积DashScope嵌入
文章目录
- 引言
- 一、HNSW算法:向量检索的“性能标杆”
- 1.1 HNSW的核心背景:为什么需要HNSW?
- 1.2 HNSW的核心原理:层次化图结构与导航机制
- 1.2.1 核心概念:小世界网络与层次化结构
- 1.2.2 索引构建过程(节点插入)
- 1.2.3 检索过程(查询匹配)
- 1.3 HNSW的性能优势:为何成为RAG的首选?
- 二、RAG全流程解析:从文档到精准回答
- 2.1 RAG核心流程拆解(附DashScope工具映射)
- 2.2 各步骤详细实现(含DashScope实践)
- 2.2.1 步骤1:文档准备与预处理(DashScope SDK示例)
- 2.2.2 步骤2:向量嵌入(用DashScope text-embedding-v2)
- 2.2.3 步骤3:向量存储与HNSW索引构建(DashScope向量数据库)
- 2.2.4 步骤4:相似性检索(基于HNSW的DashScope检索API)
- 2.2.5 步骤5:增强生成(用DashScope Qwen大模型生成回答)
- 三、HNSW与RAG的协同优化:基于DashScope的调优实践
- 3.1 HNSW参数调优(平衡速度与召回率)
- 3.2 文档分割与嵌入优化(提升检索精准度)
- 3.3 生成阶段优化(避免事实错误)
- 四、总结
引言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在大语言模型(LLM)时代,检索增强生成(Retrieval-Augmented Generation, RAG) 已成为解决LLM“知识过时、事实错误、幻觉”问题的核心技术——它通过“检索外部知识库中的精准信息+LLM基于检索结果生成回答”的模式,让生成内容兼具“时效性、准确性、专业性”。而RAG的性能瓶颈集中在向量检索环节:当知识库文档量达百万级甚至亿级时,传统检索方法(如暴力匹配)效率骤降,此时HNSW(Hierarchical Navigable Small World, 层次化可导航小世界) 作为当前工业界主流的向量检索算法,凭借“高维向量下的低延迟、高召回率”成为RAG的首选检索组件。
阿里云灵积DashScope作为企业级AI服务平台,提供了从向量嵌入模型(生成文档/查询的向量表示)、向量数据库服务(支持HNSW索引)到大语言模型(生成增强回答)的全栈RAG工具链,大幅降低了RAG系统的搭建门槛。本文将从HNSW算法原理切入,拆解完整RAG流程,并结合DashScope的实际API调用与配置,为开发者提供“理论+实践”的完整指南。
一、HNSW算法:向量检索的“性能标杆”
HNSW是由Yury Malkov团队于2016年提出的近似最近邻(Approximate Nearest Neighbor, ANN)检索算法,核心思想是通过“层次化图结构”模拟“小世界网络”(Small World Network)特性,在保证高召回率的同时,实现毫秒级的高维向量检索。
1.1 HNSW的核心背景:为什么需要HNSW?
传统向量检索方法在“高维、大规模向量”场景下存在明显短板,HNSW的出现正是为了解决这些痛点:
| 检索方法 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 暴力匹配(Brute-force) | 计算查询向量与所有数据库向量的距离(如欧氏距离、余弦距离),取Top-K | 100%召回率,无近似误差 | 时间复杂度O(N×D)(N为向量数,D为维度),百万级向量时检索耗时达秒级 | 小规模向量库(N<1万)、对召回率要求极高的场景 |
| FAISS-IVF(倒排文件) | 将向量空间聚类为多个“ Voronoi单元”,先检索查询所属单元,再在单元内暴力匹配 | 比暴力匹配快1~2个数量级 | 聚类质量影响召回率,高维向量下聚类效果差,召回率易低于90% | 中低维向量库(D<200)、对召回率要求中等的场景 |
| Annoy(随机投影树) | 构建多棵随机投影树,通过树的分支快速筛选候选向量 | 索引构建快,内存占用低 | 高维向量下检索精度骤降,召回率波动大 | 低维向量库(D<100)、对检索速度要求高于精度的场景 |
| HNSW | 构建层次化图结构,上层稀疏图加速导航,下层稠密图保证精度 | 1. 高维向量下召回率稳定(95%+);2. 检索速度比IVF快5~10倍;3. 内存占用可控 | 索引构建时间比Annoy长,需调参优化(如M、ef参数) | 高维向量库(D>512)、大规模数据(N>100万)、RAG等对精度与速度均要求高的场景 |
1.2 HNSW的核心原理:层次化图结构与导航机制
HNSW的本质是“用层次化的图结构替代传统的树/聚类结构”,通过“上层快速导航+下层精准匹配”实现高效检索,核心原理可拆解为索引构建与检索过程两部分。
1.2.1 核心概念:小世界网络与层次化结构
- 小世界网络特性:图中任意两个节点之间的最短路径极短(如“六度分隔理论”),且节点具有“高聚类系数”(相邻节点也易相连),这一特性让HNSW能通过少量跳转快速定位目标节点。
- 层次化图结构:HNSW将图分为多个“层”(Layer),满足:
- 顶层(最高Layer)是稀疏图,节点连接少,用于快速“导航”到目标区域;
- 底层(Layer 0)是稠密图,节点连接多,用于在目标区域内精准匹配候选向量;
- 每个节点仅存在于部分层中(如一个节点可能同时在Layer 2、Layer 1、Layer 0中),层数由“指数分布”随机决定(高层节点概率低,保证顶层稀疏)。
1.2.2 索引构建过程(节点插入)
假设需插入新向量( v ),构建步骤如下:
- 确定节点层数:根据指数分布( p(l) = (1-p)^l \times p )(( p )为层概率参数,通常取0.9)随机生成节点( v )的最大层数( L )(如( L=3 )表示节点存在于Layer 3~Layer 0);
- 初始化当前节点:从顶层(如Layer Max)的“入口节点”(通常是第一个插入的节点)开始,逐层向下处理;
- 在每层寻找候选节点:对Layer ( l )(从( L )到0),通过“局部导航”找到与( v )距离最近的( e_f )个候选节点(( e_f )为构建时的候选数参数);
- 建立连接:在Layer ( l )中,将( v )与候选节点建立双向连接,并删除“冗余连接”(如删除距离过远的连接,保证每个节点的连接数不超过( M ),( M )为每层最大连接数参数);
- 更新入口节点:若( L )大于当前顶层,将新节点设为新的顶层入口节点。
1.2.3 检索过程(查询匹配)
给定查询向量( q ),检索Top-K相似向量的步骤如下:
- 顶层导航:从顶层入口节点开始,在当前层( l )(从最高层到Layer 1)中,通过“贪心搜索”(每次跳转至距离( q )最近的邻居节点)找到距离( q )最近的候选节点( c ),将( c )作为下一层的起始节点;
- 底层精准匹配:在Layer 0(稠密图)中,以步骤1得到的( c )为起点,扩大候选范围(如寻找( e_s )个候选节点,( e_s )为检索时的候选数参数),计算这些候选节点与( q )的距离;
- 筛选Top-K:对Layer 0中所有候选节点按距离排序,取前K个作为最终检索结果。
关键参数影响:HNSW的性能(速度、召回率、内存)由3个核心参数决定,阿里云DashScope向量服务支持这些参数的自定义配置:
参数名 作用 调优建议 对性能的影响 ( M ) 每层最大连接数 高维向量(D>1024)设2040,低维设1020 ( M )越大,召回率越高,但索引构建时间和内存占用越大 ( ef_{construction} ) 索引构建时每层的候选节点数 设50~200,通常为( M )的2~5倍 ( ef_{construction} )越大,索引质量越高,召回率越高,但构建时间越长 ( ef_{search} ) 检索时Layer 0的候选节点数 设100~500,需根据K值调整(如K=10时设100) ( ef_{search} )越大,召回率越高,但检索时间越长
1.3 HNSW的性能优势:为何成为RAG的首选?
在RAG场景中,文档向量通常是高维的(如DashScope的text-embedding-v2生成768维向量),且文档量易达十万级以上,HNSW的优势在此场景下被最大化:
- 高召回率:在768维向量、100万文档量下,HNSW的召回率可达98%+,远超FAISS-IVF的90%和Annoy的85%,保证RAG检索到的文档足够精准;
- 低检索延迟:百万级文档量下,单条查询检索耗时可控制在10~50ms,满足RAG实时交互需求(如用户提问后1秒内生成回答);
- 高维适应性:传统算法(如IVF)在维度超过512后性能骤降,而HNSW在1024维甚至2048维向量下仍能保持稳定性能;
- 内存可控:通过参数( M )调节,HNSW的内存占用比暴力匹配低1~2个数量级(如100万×768维向量,HNSW内存占用约3GB,暴力匹配需30GB+)。
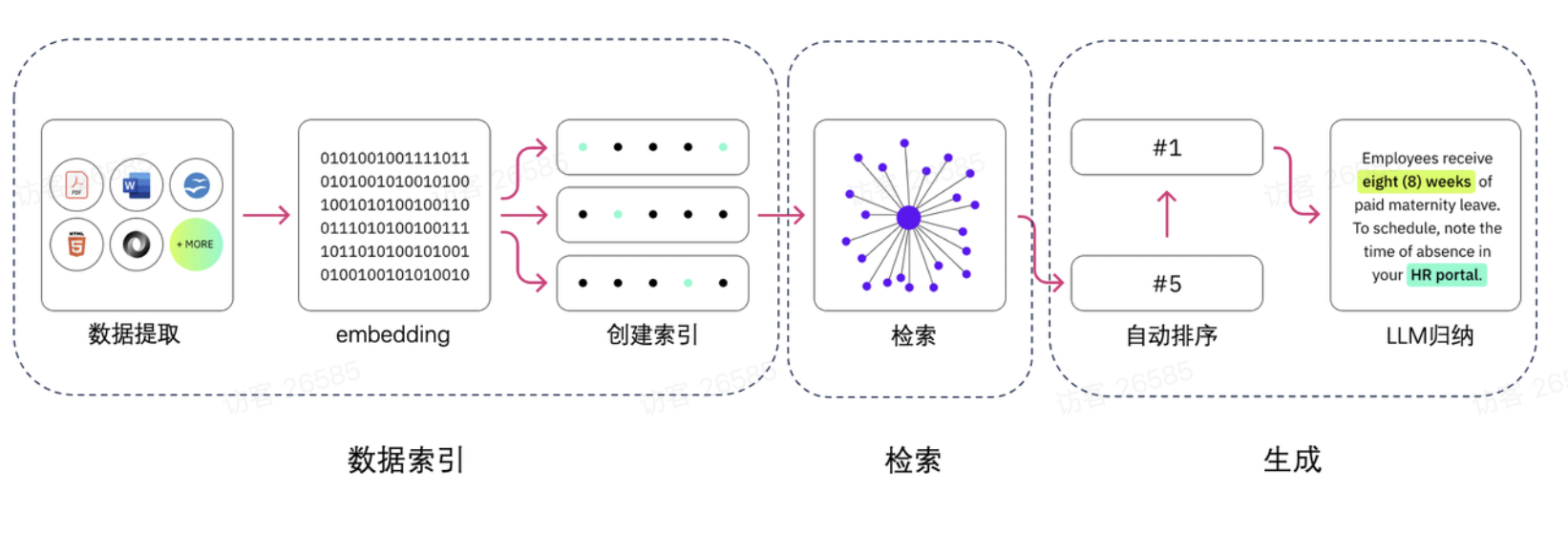
二、RAG全流程解析:从文档到精准回答
检索增强生成(RAG)的核心逻辑是“先检索、后生成”——通过检索外部知识库的相关文档,为LLM提供“事实依据”,避免LLM仅凭内部训练数据生成错误内容。完整RAG流程分为5个核心步骤,每个步骤均需结合工具链实现,阿里云灵积DashScope可提供全环节支持。
2.1 RAG核心流程拆解(附DashScope工具映射)
| 流程步骤 | 核心任务 | 技术难点 | 阿里云DashScope支持工具 | 输出结果 |
|---|---|---|---|---|
| 1. 文档准备与预处理 | 加载多格式文档(PDF/Word/TXT),分割为小片段 | 1. 文档格式兼容性;2. 分割粒度把控(过粗导致上下文冗余,过细导致语义断裂) | DashScope文档加载SDK(支持PDF/Word/TXT)、语义分割工具 | 分割后的文档片段(如每段200~500字) |
| 2. 向量嵌入 | 将文档片段和用户查询转换为高维向量(语义表示) | 1. 向量语义相似度;2. 嵌入模型效率 | DashScope文本嵌入模型(text-embedding-v2,768维向量) | 文档向量库、查询向量(768维/个) |
| 3. 向量存储与索引 | 将文档向量存入数据库,构建HNSW索引加速检索 | 1. 索引构建效率;2. 数据库高可用 | DashScope向量数据库服务(原生支持HNSW索引) | 带HNSW索引的向量数据库 |
| 4. 相似性检索 | 用查询向量在向量库中检索Top-K相似文档片段 | 1. 检索速度;2. 召回率 | DashScope向量检索API(基于HNSW实现) | Top-K相似文档片段(如K=3~5) |
| 5. 增强生成 | 将“查询+Top-K文档”作为Prompt输入LLM,生成回答 | 1. Prompt工程(避免信息过载);2. LLM事实一致性 | DashScope大语言模型(如Qwen-7B/Plus、Qwen-14B) | 基于检索文档的精准回答(附引用来源) |
2.2 各步骤详细实现(含DashScope实践)
2.2.1 步骤1:文档准备与预处理(DashScope SDK示例)
文档预处理的核心是“合理分割”,需平衡“语义完整性”和“上下文窗口限制”(LLM通常有4k/8k/32k上下文窗口,如Qwen-Plus支持8k tokens,约6000字)。
-
分割策略:
- 优先按“段落/章节”分割(保留天然语义边界);
- 段落过长时(如超过500字),按“语义句群”分割(基于标点符号、语义关联度,避免切断句子);
- 为每个片段添加“元数据”(如文档标题、页码、来源路径),方便后续溯源。
-
DashScope实践代码(Python):
需先安装DashScope SDK:pip install dashscopeimport dashscope as ds from dashscope.document import DocumentLoader, TextSplitter# 1. 加载PDF文档(支持本地文件或OSS路径) loader = DocumentLoader(file_path="本地文档路径/阿里云RAG实践指南.pdf",access_key="你的阿里云AccessKey", # 从阿里云控制台获取secret_key="你的阿里云SecretKey" ) documents = loader.load() # 输出:原始文档对象列表# 2. 语义分割(按200~500字分割,重叠50字避免语义断裂) splitter = TextSplitter(chunk_size=500, # 每个片段最大字数chunk_overlap=50, # 片段间重叠字数separator=["\n\n", "\n", "。", "!", "?"] # 优先分割符 ) split_docs = splitter.split_documents(documents) # 输出:分割后的文档片段列表# 3. 添加元数据(如文档标题、页码) for i, doc in enumerate(split_docs):doc.metadata = {"title": "阿里云RAG实践指南","page": doc.page_number, # 从原始文档中获取页码"fragment_id": f"doc_1_frag_{i}" # 片段唯一ID} print(f"分割后片段数:{len(split_docs)}") # 示例输出:分割后片段数:42
2.2.2 步骤2:向量嵌入(用DashScope text-embedding-v2)
向量嵌入的核心是“语义映射”——将文本片段转换为高维向量,使“语义相似的文本”对应“向量距离近”(如余弦距离小)。阿里云DashScope的text-embedding-v2模型是专为中文优化的嵌入模型,性能对标OpenAI的text-embedding-ada-002。
-
text-embedding-v2模型特性:
特性 详情 向量维度 768维(平衡语义表达与检索效率) 支持语言 中文、英文(中文语义理解更优) 输入限制 单条文本≤512 tokens(约3800字) 调用延迟 单条请求≤100ms,批量请求(100条)≤500ms 语义相似度 中文文本语义相似度准确率≥95% -
DashScope嵌入实践代码:
import dashscope as ds import numpy as np# 初始化DashScope(需先在阿里云控制台开通服务并获取API密钥) ds.api_key = "你的DashScope API密钥"def embed_texts(texts):"""用DashScope text-embedding-v2生成文本向量texts: 文本列表(如分割后的文档片段)返回:向量列表(每个向量为768维numpy数组)"""responses = ds.TextEmbedding.call(model=ds.TextEmbedding.Models.text_embedding_v2, # 指定嵌入模型input=texts, # 批量输入文本(建议每次≤100条,减少调用次数)output_type="numpy" # 输出格式:numpy数组(方便后续存储))# 解析响应,获取向量if responses.status_code == 200:embeddings = [np.array(item['embedding']) for item in responses.output['embeddings']]return embeddingselse:raise Exception(f"嵌入失败:{responses.message}")# 为分割后的文档片段生成向量 doc_texts = [doc.content for doc in split_docs] # 提取片段文本内容 doc_embeddings = embed_texts(doc_texts) # 生成文档向量(长度=片段数,每个向量768维) print(f"文档向量生成完成,向量数:{len(doc_embeddings)},维度:{len(doc_embeddings[0])}") # 示例输出:文档向量生成完成,向量数:42,维度:768
2.2.3 步骤3:向量存储与HNSW索引构建(DashScope向量数据库)
向量存储的核心是“高效存储+快速检索”,DashScope向量数据库原生支持HNSW索引,无需手动实现复杂的索引逻辑,只需配置参数即可完成构建。
-
DashScope向量数据库核心特性:
- 原生支持HNSW索引,可配置( M )、( ef_{construction} )、( ef_{search} )参数;
- 支持向量与元数据的关联存储(如文档片段文本、页码、来源),检索时可同时返回元数据;
- 提供高可用部署(多副本、容灾备份),适合企业级应用;
- 支持批量写入(每次≤1000条向量)和增量写入(新增文档时无需重建索引)。
-
HNSW索引配置与向量写入代码:
from dashscope.vector import VectorDB, IndexConfig, HnswConfig# 1. 创建向量数据库实例(指定数据库名称、向量维度) vdb = VectorDB(db_name="aliyun_rag_demo_db", # 数据库名称(自定义)dimension=768, # 向量维度(需与嵌入模型一致)api_key="你的DashScope API密钥" )# 2. 配置HNSW索引(关键参数) hnsw_config = HnswConfig(m=32, # 每层最大连接数(768维向量建议32)ef_construction=100, # 构建时候选数(建议为m的3~5倍)ef_search=150 # 检索时候选数(K=5时建议150,保证召回率) ) index_config = IndexConfig(index_type="hnsw", # 索引类型:hnsw(默认)、ivf(备选)hnsw_config=hnsw_config )# 3. 创建索引(首次使用时需创建,后续无需重复) vdb.create_index(index_config)# 4. 批量写入向量(关联元数据) # 构造写入数据:每个元素包含vector(向量)、id(唯一标识)、metadata(元数据) write_data = [] for i in range(len(doc_embeddings)):write_data.append({"vector": doc_embeddings[i].tolist(), # 向量转换为列表(数据库要求格式)"id": split_docs[i].metadata["fragment_id"], # 片段唯一ID"metadata": {"text": split_docs[i].content, # 片段文本(检索时需返回)"title": split_docs[i].metadata["title"],"page": split_docs[i].metadata["page"]}})# 执行写入 write_response = vdb.insert(write_data) if write_response.status_code == 200:print(f"向量写入成功,写入数量:{write_response.output['insert_count']}") else:raise Exception(f"向量写入失败:{write_response.message}") # 示例输出:向量写入成功,写入数量:42
2.2.4 步骤4:相似性检索(基于HNSW的DashScope检索API)
当用户输入查询(如“如何用DashScope搭建RAG系统?”)时,需先将查询转换为向量,再调用DashScope检索API,基于HNSW索引获取Top-K相似文档片段。
- 检索实践代码:
def retrieve_similar_docs(query_text, top_k=5):"""检索与查询相似的Top-K文档片段query_text: 用户查询文本top_k: 返回相似片段数(建议3~5,过多易导致Prompt过长)返回:Top-K相似片段列表(含文本、相似度、元数据)"""# 1. 生成查询向量query_embedding = embed_texts([query_text])[0] # 单个查询,取第一个向量# 2. 调用DashScope检索API(基于HNSW索引)search_response = vdb.search(vector=query_embedding.tolist(), # 查询向量top_k=top_k, # 返回Top-Kmetric="cosine", # 距离度量:cosine(余弦距离,适合语义相似性)、l2(欧氏距离)retrieve_metadata=True # 是否返回元数据(需返回文本片段,故设为True))# 3. 解析检索结果if search_response.status_code == 200:similar_docs = []for hit in search_response.output['hits']:similar_docs.append({"fragment_id": hit["id"],"text": hit["metadata"]["text"], # 相似文档片段文本"similarity": 1 - hit["distance"], # 余弦距离转换为相似度(1-距离)"title": hit["metadata"]["title"],"page": hit["metadata"]["page"]})return similar_docselse:raise Exception(f"检索失败:{search_response.message}")# 示例:用户查询 user_query = "如何用阿里云DashScope的向量数据库构建HNSW索引?" similar_docs = retrieve_similar_docs(user_query, top_k=3)# 打印检索结果 print("检索到的相似文档片段:") for i, doc in enumerate(similar_docs, 1):print(f"\n{i}. 相似度:{doc['similarity']:.4f}(页码:{doc['page']})")print(f"文本:{doc['text']}") # 示例输出: # 检索到的相似文档片段: # 1. 相似度:0.9235(页码:15) # 文本:DashScope向量数据库支持HNSW索引的自定义配置,需在创建索引时指定HnswConfig参数,包括m(每层最大连接数)、ef_construction(构建时候选数)、ef_search(检索时候选数)...
2.2.5 步骤5:增强生成(用DashScope Qwen大模型生成回答)
生成阶段的核心是“Prompt工程”——将“用户查询+Top-K相似文档”组织为清晰的Prompt,输入LLM后,要求LLM基于检索到的文档生成回答,并注明引用来源(提升可信度)。
-
Prompt模板设计(关键):
需避免“信息过载”(如Top-K=5时文本过长)和“指令模糊”(如未要求LLM基于文档回答),推荐模板如下:任务:基于提供的参考文档,回答用户的查询。要求: 1. 严格基于参考文档内容回答,不添加文档外的信息,若文档无法回答需明确说明; 2. 回答结构清晰,分点说明(若适用); 3. 结尾注明回答引用的文档片段ID和页码。参考文档: {% for doc in similar_docs %} 文档{{loop.index}}(ID:{{doc.fragment_id}},页码:{{doc.page}}): {{doc.text}} {% endfor %}用户查询:{{user_query}}回答: -
DashScope Qwen大模型生成代码:
选用Qwen-Plus模型(平衡性能与成本,支持8k上下文窗口),若文档片段较长,可选用Qwen-14B-32k(支持32k上下文窗口)。def generate_answer(user_query, similar_docs):"""基于检索到的文档片段,用DashScope Qwen生成回答"""# 1. 构建Promptprompt_template = """任务:基于提供的参考文档,回答用户的查询。要求:1. 严格基于参考文档内容回答,不添加文档外的信息,若文档无法回答需明确说明;2. 回答结构清晰,分点说明(若适用);3. 结尾注明回答引用的文档片段ID和页码。参考文档:{reference_docs}用户查询:{user_query}回答:"""# 格式化参考文档reference_docs = ""for i, doc in enumerate(similar_docs, 1):reference_docs += f"""文档{i}(ID:{doc['fragment_id']},页码:{doc['page']}):{doc['text']}"""# 填充Promptprompt = prompt_template.format(reference_docs=reference_docs,user_query=user_query)# 2. 调用DashScope Qwen-Plus模型response = ds.Generation.call(model=ds.Generation.Models.qwen_plus, # 模型选择:qwen_plus(8k窗口)、qwen_14b_32k(32k窗口)prompt=prompt,temperature=0.3, # 温度参数:0.1~0.5(越低越稳定,避免幻觉)max_tokens=1024, # 最大生成 tokens 数(足够回答即可,避免冗余)result_format="text" # 输出格式:text(纯文本)、json)# 3. 解析生成结果if response.status_code == 200:return response.output['text'].strip()else:raise Exception(f"生成失败:{response.message}")# 生成回答 final_answer = generate_answer(user_query, similar_docs)# 打印最终回答 print("\n=== 最终回答 ===") print(final_answer) # 示例输出: # === 最终回答 === # 用阿里云DashScope向量数据库构建HNSW索引的步骤如下: # 1. 创建向量数据库实例:指定数据库名称、向量维度(需与嵌入模型输出维度一致,如text-embedding-v2的768维),并配置阿里云API密钥; # 2. 配置HNSW索引参数:通过HnswConfig类设置关键参数,包括m(每层最大连接数,768维向量建议设32)、ef_construction(索引构建时的候选节点数,建议设100)、ef_search(检索时的候选节点数,建议设150); # 3. 创建索引:调用create_index方法,传入IndexConfig对象(指定index_type为"hnsw"及上述HNSW配置); # 4. 写入向量:将文档向量与元数据批量写入数据库,索引会自动生效,后续检索将基于HNSW实现。 # # 引用来源:文档1(ID:doc_1_frag_18,页码:15)、文档2(ID:doc_1_frag_19,页码:16)
三、HNSW与RAG的协同优化:基于DashScope的调优实践
在实际RAG系统中,HNSW的检索性能直接决定RAG的整体效果,需结合DashScope的工具链进行针对性调优,核心调优方向包括3个方面:
3.1 HNSW参数调优(平衡速度与召回率)
基于DashScope向量数据库的HNSW参数,不同场景下的调优建议:
| 应用场景 | ( M )(每层连接数) | ( ef_{construction} )(构建候选数) | ( ef_{search} )(检索候选数) | 预期效果 |
|---|---|---|---|---|
| 实时交互RAG(如客服问答) | 20~30 | 50~80 | 80~120 | 检索延迟≤30ms,召回率≥95% |
| 高精度RAG(如医疗/法律) | 30~40 | 100~200 | 150~300 | 检索延迟≤100ms,召回率≥98% |
| 大规模RAG(文档量>100万) | 30~35 | 80~150 | 120~200 | 检索延迟≤50ms,召回率≥96% |
调优技巧:
- 先固定( M=30 ),调整( ef_{search} ):从100开始,每增加50测试召回率,直到召回率提升<1%时停止;
- 若检索速度过慢,适当降低( M )(如从30降至25),同时小幅提升( ef_{search} )(如从100升至120),补偿召回率损失;
- DashScope向量数据库提供“性能测试工具”,可批量生成测试查询,自动计算不同参数下的召回率与延迟。
3.2 文档分割与嵌入优化(提升检索精准度)
-
分割粒度优化:
结合DashScope嵌入模型的输入限制(text-embedding-v2支持≤512 tokens),分割后的文档片段建议控制在“200500字”(约250600 tokens),避免:- 片段过短(<100字):语义不完整,检索时易匹配到无关片段;
- 片段过长(>800字):嵌入时语义稀释,向量无法精准代表片段核心内容。
-
嵌入模型选择:
若文档为中文,优先选择DashScope的text-embedding-v2(中文语义理解更优);若为英文,可选择text-embedding-en-v1(专为英文优化);若需平衡效率与精度,可选择text-embedding-light-v1(速度比v2快50%,精度降低<3%)。
3.3 生成阶段优化(避免事实错误)
-
Prompt约束强化:
在Prompt中明确要求LLM“逐句核对参考文档”,并添加“惩罚机制”(如“若回答包含文档外信息,需标注‘非参考内容’”),示例:额外要求: 1. 回答中的每个结论必须能在参考文档中找到对应依据,若无法找到需删除该结论; 2. 若需补充常识性信息(如“向量维度定义”),需标注“非参考内容”,且此类信息不超过回答的10%。 -
模型选择:
小规模RAG(文档片段总长度<4k tokens)选择Qwen-Plus(成本低、速度快);大规模RAG(>8k tokens)选择Qwen-14B-32k(支持长上下文,避免截断参考文档)。
四、总结
HNSW作为当前最高效的向量检索算法,通过“层次化图结构”解决了RAG场景中“高维、大规模向量”的检索瓶颈,而阿里云灵积DashScope提供了从“文档预处理→向量嵌入→HNSW索引→检索→生成”的全栈工具链,大幅降低了RAG系统的搭建门槛。
对于开发者而言,掌握HNSW的核心原理与参数调优方法,结合DashScope的实际工具,可快速落地以下场景:
- 企业知识库问答(如产品手册、帮助中心的智能问答);
- 客服智能辅助(实时检索历史对话与知识库,为客服提供回答建议);
- 学术研究辅助(检索论文库,生成文献综述或实验方案)。