2025年mathorcup大数据竞赛B题【物流理赔风险识别及服务升级问题】原创论文分享(含完整python代码)
大家好呀,从发布赛题一直到现在,总算完成了2025年mathorcup大数据竞赛B题【物流理赔风险识别及服务升级问题】完整的成品论文。
本论文可以保证原创,保证高质量。绝不是随便引用一大堆模型和代码复制粘贴进来完全没有应用糊弄人的垃圾半成品论文。

B题论文共105页,一些修改说明13页,正文86页,附录6页,代码量1w+行
比我预计出论文时间晚了一些,主要是第三问做得太复杂了,基本上把所有能解决样本不均衡的方法都试了,再加上用了三个模型跑,以及参数调优,所以太耗费时间。
这道题第一问就是先做数据清洗和预处理,在这里,我们必须针对于25个特征变量对照着题目给出的数据说明逐一分析,然后再慎重处理,比较复杂,但必须做到位,因为这里的数据是我们后面所有求解的基础。然后就是选择标注模型了,需要注意的是,通过可视化分析,这道题不能用kmeans聚类,只能用分位数回归,然后就比较简单了,跑一下得出最终结果即可。
第二问当然首先还是要处理附件2数据,处理完成后,为了提高精度,我新增了两个衍生特征变量,模型选择方面,我用了随机森林 gbdt和lightgbm三个模型,最终预测精度是在75%以上,这已经是在这道题目在不去除重要数据,也就是在保证模型可迁移性和实际应用能力情况下,能达到的最高精度了。
第三问就比较复杂了,由于样本特别不均衡,也就是说非合理诉求数据较少,我们必须采用多种方案逐步去探索到底如何解决,我依然用随机森林这三个模型,然后一开始采用基于类别权重去训练,效果一般,然后又进行smote过采样,精度提升,但是lightgbm这个表现最好的精度下降,所以我又针对这个模型,用了它内部不平衡处理机制进行处理,精度提升,最后就是针对它进行超参数优化了,必须要注意的是,第三问不能用精确率去衡量模型表现,没有任何意义,因为即便非合理诉求类别全部预测为0,精度也在80%以上,只能选择f1得分去衡量,最后超参数优化后,f1能到0.4以上,也是保留这道题真实数据情况下,能达到的最高精度了(真要是去除一些数据的话,可以达到很高,但这个没有意义)。
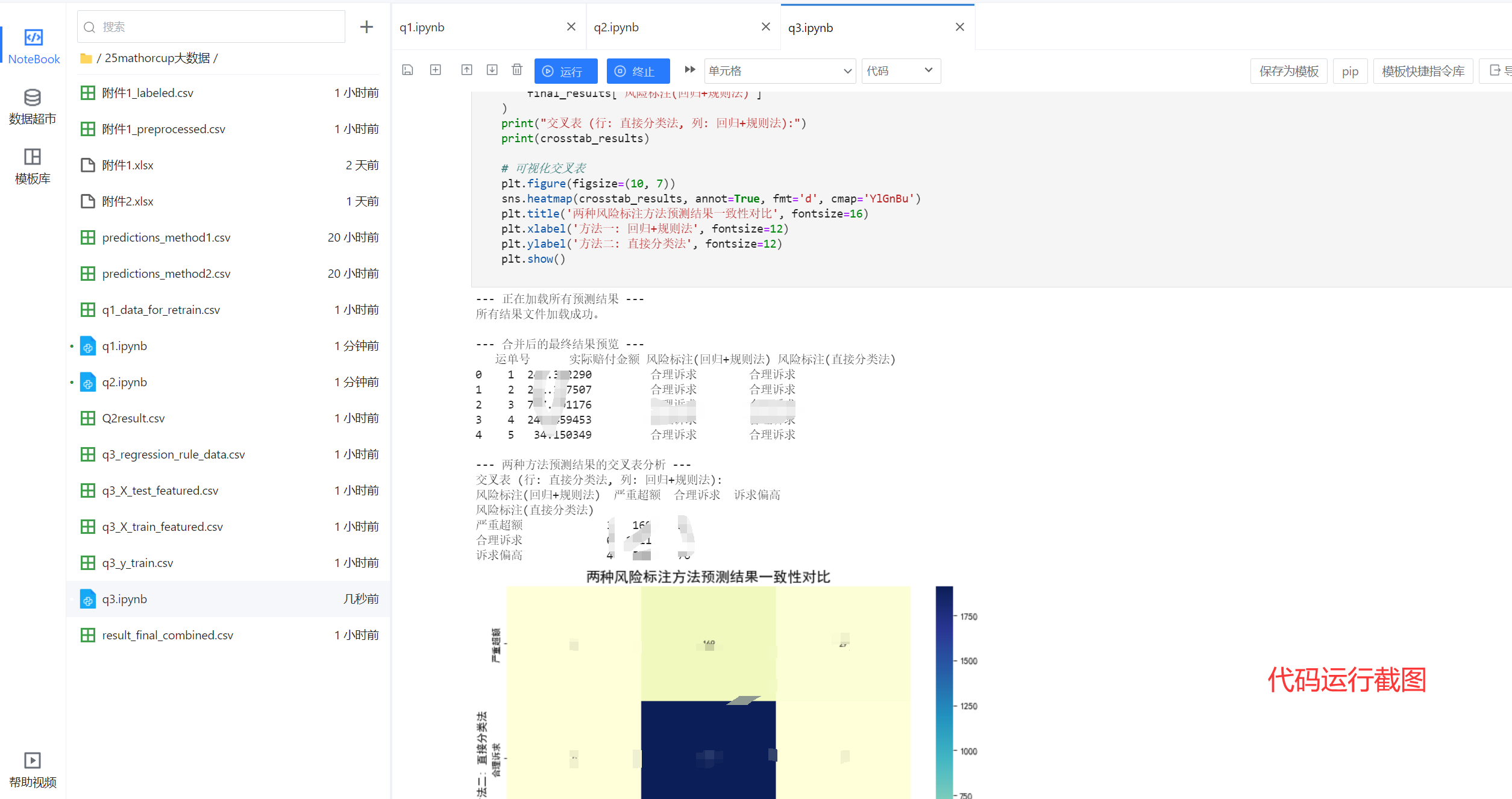
最后无非就是用之前回归预测的数值+第一问的规则标注和直接进行机器学习分类这两种方法的对比了,我在论文里有非常详细的求解,对比和分析。在最后result结果表的处理上,我是把两种方法的标注结果都分别列出来了,因为毕竟两种方法各有优劣。
之所以篇幅这么长,是因为:
我论文很多的篇幅需要用来解释我为什么要这么做,基本就是手把手教你怎么做,并且我还要照顾每个人的水平,所有会有些地方需要写得很繁琐,一些中间过程展现得事无巨细,并且表格很多,你们自己放到附录即可
2025年第六届MathorCup数学应用挑战赛——大数据竞赛更新汇总贴0 赞同 · 0 评论 文章
放一点图吧:


上述完整论文的查看请点击我的下方个人卡片即可啦↓: