[论文笔记•(多智能体)]LLMs Can Simulate Standardized Patients via Agent Coevolution
[论文笔记•(多智能体)]LLMs Can Simulate Standardized Patients via Agent Coevolution
一、一句话总结
该研究针对标准化病人(SPs)训练医疗人员成本高、对 SP 身心健康有潜在负面影响的问题,提出EvoPatient 框架—— 一种基于多智能体协同进化的虚拟 SP 模拟方案,通过病人智能体与医生智能体的多轮对话模拟诊断流程(含主诉生成、分诊、问诊、结论阶段),依托注意力库和轨迹库实现无监督协同进化,在仅提供 SP 总体需求的情况下,经 200 个病例、10 小时进化后,需求对齐度较现有推理方法提升超 10%,同时优化资源消耗(平均响应时间 6.6922 秒、每答案 token 数 401.5882),还具备优异的泛化性(跨疾病迁移时相关指标平均提升 3.8%-18.1%),可有效用于人类医生训练,框架代码将开源于https://github.com/ZJUMAI/EvoPatient。
二、论文基本信息
单位:浙江大学
会议:ACL2025 main
阅读时间:2025.10.27
论文地址:LLMs Can Simulate Standardized Patients via Agent Coevolution - ACL Anthology
**代码:**https://github.com/ZJUMAI/EvoPatient
测试
三、研究的核心问题和背景
- 标准化病人(SPs)的作用与局限
- 作用:作为经专业训练的人员,模拟真实病人的症状、病史和情绪状态,在可控环境中提升医疗人员的临床技能、沟通能力和诊断推理能力(引用 Barrows, 1993 等研究)。
- 局限:① 训练和运营成本极高,需大量医学知识和角色专项练习(Levine et al., 2013);② 沉浸式工作可能对 SP 身心健康产生负面影响,如需应对角色相关焦虑(Spencer and Dales, 2006)。
- 现有虚拟 SP 方案的不足
- 规则驱动数字病人:预定义规则和定制对话框架无法捕捉真实病人病情与沟通的复杂性(Othlinghaus-Wulhorst and Hoppe, 2020)。
- LLM-based SP:① 需兼顾 “具备医学知识” 与 “模拟无医学认知病人(隐瞒关键信息)” 的双重角色,仅靠提示工程难以满足要求;② 现有研究(如 Yu et al., 2024 的知识图谱检索、Louie et al., 2024 的专家反馈)未解决 “将信息转化为 SP 标准化表达” 问题,且存在人力密集、泛化性有限的问题。
四、现有方法面临的挑战
五、解决思路
EvoPatient 是无监督、无需权重更新的多智能体协同进化框架,核心目标是让 LLM 模拟 SP 以支持医生训练。
六、框架及具体实现

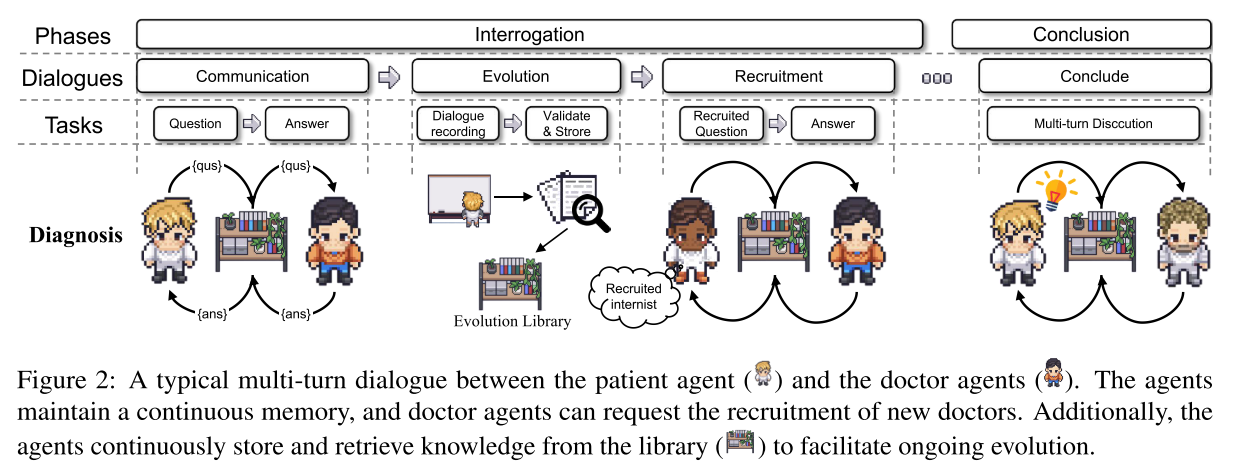
模拟流程(Simulated Flow)
-
功能:以真实医疗记录为输入,将诊断过程建模为结构化阶段,作为模拟工作流,支持场景定制且无需调整通信协议。
-
关键阶段:
阶段 核心内容 主诉生成(Chief Complaint Generation) 病人智能体基于医疗记录生成主诉,通过 “模糊化处理”(移除医疗检测结果、随机句子 dropout)模拟真实病人信息不精确性 分诊(Triage) 医生智能体根据相似主诉从库中检索历史分诊数据,将病人分配至对应专科 问诊(Interrogation) 医生与病人智能体多轮对话,若病情超当前医生专业范围,可招募其他专科医生,此阶段对话密度高、经验积累多 结论(Conclusion) 医生智能体整合信息给出最终诊断,结束模拟 -
补充机制:问诊阶段加入 “病人危机”(如突发疼痛询问),提升模拟真实性,训练医生应急处理能力。
模拟智能体对(Simulated Agent Pair)
- 病人智能体(Simulated Patient Agent)
- 画像设计:构建5000 个涵盖家庭、教育、经济状况及大五人格特质(McCrae and Costa, 1987)的病人画像,提升回答真实性。
- 技术支撑:采用检索增强生成(RAG) 技术(Lewis et al., 2020),从记录中提取相关信息生成答案,避免长上下文信息丢失。
- 医生智能体(Simulated Doctor Agent)
- 问题生成优化:① 提供病人记录和设计画像,引导医生构建专业问题库;② 支持多学科咨询招募,当病情超专业范围时,可动态招募其他专科医生,招募过程遵循拓扑排序形成有向无环图(DAG),避免信息回流。
- 记忆机制:采用 “即时记忆 + 总结记忆”,前者维持近期对话连续性,后者整合关键信息,减轻上下文负担(Liu et al., 2024),确保问题非随意生成。
协同进化机制(Coevolution)
通过两个库实现智能体自主进化,无需人工监督:
- 注意力库(Attention Library)
- 功能:将 SP 需求拆分为多个分支,由注意力智能体提取关键需求形成 “注意力需求(rₐ)”,若生成答案优质,以 < 问题,记录,答案,注意力需求 > 四元组存储,作为病人智能体的少样本演示和优化需求。
- 检索逻辑:新问题到来时,通过文本嵌入器计算相似度(阈值 0.9),检索 Top-k 匹配结果辅助回答。
- 轨迹库(Trajectories Library)
- 功能:存储高质量对话轨迹(tᵢ),以(qⱼ₋₁,aⱼ₋₁,qⱼ,aⱼ)形式记录问题 - 答案序列,医生智能体可提取 “对话捷径”,生成更专业高效的问题,反哺病人智能体进化。
- 收敛条件:连续 6 个病例无新内容加入库中,进化停止。
七、实验
3.3.1 实验基础信息
-
数据集:共20000 + 个不同病例,涵盖阑尾炎、鼻咽癌、肿瘤等,来源包括:① 合作医院的去标识化记录(经伦理审批);② 公开数据集 MTSamples(2023)、MIMIC II(Saeed et al., 2011)。
-
基线方法:Chain-of-Thought(CoT)、CoT-SC(3)、Tree-of-Thought(ToT)、Self-Align、Few-shot(2)、Online Library。
-
模型与参数:中文数据用 Qwen 2.5 72B,英文数据用 GPT-3.5-Turbo,温度参数 1;默认训练病例 200 个,最大对话轮次 10,每轮插入 5 个欺骗性问题。
-
评估指标:
评估对象 指标名称 指标定义 取值范围 病人答案 相关性(α) 答案是否直接完整回答问题、无冗余,用问题与答案语义嵌入的余弦距离量化 [0,1] 病人答案 忠实性(β) 答案是否可从医疗信息推导且符合 SP 需求 [0,1] 病人答案 稳健性(γ) 答案是否泄露医生不应轻易获取的信息(如疾病名称) [0,1] 病人答案 综合能力(Ability) (α+β+γ)/3,衡量病人智能体整体表现 [0,1] 医生问题 特异性 问题是否精准、聚焦病人病例的特定症状 / 情况 - 医生问题 针对性(ε) 问题是否为收集诊断必要信息而设计 [0,1] 医生问题 专业性(ζ) 问题是否体现医学原理与实践理解 [0,1] 医生问题 综合质量(Quality) 整合特异性、针对性、专业性的整体指标 -
3.3.2 核心实验结果
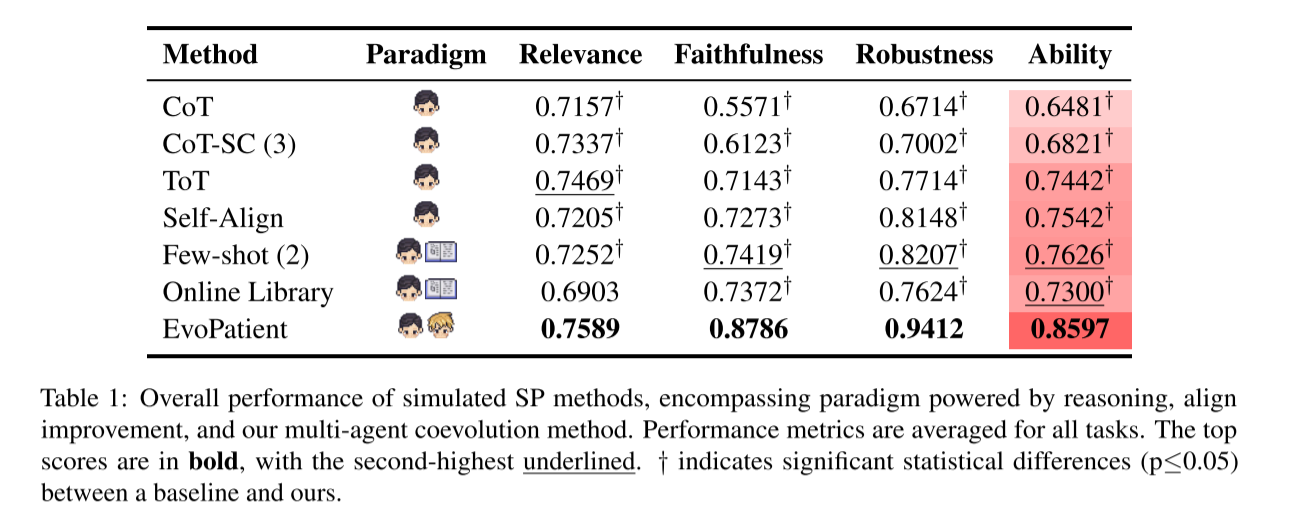
-
总体性能对比:EvoPatient 在所有指标上显著优于基线,具体数据如下表(部分关键指标):
方法 相关性(α) 忠实性(β) 稳健性(γ) 综合能力(Ability) CoT 0.7157† 0.5571† 0.6714† 0.6481† ToT 0.7469† 0.7143† 0.7714† 0.7442† Self-Align 0.7205† 0.7273† 0.8148† 0.7542† Few-shot(2) 0.7252† 0.7419† 0.8207† 0.7626† EvoPatient 0.7589 0.8786 0.9412 0.8597 注:†表示与 EvoPatient 存在显著统计差异(p≤0.05) -
资源消耗优化:EvoPatient 在响应时间、token 数、单词数上均体现高效性,具体如下表:
方法 平均响应时间(秒) 每答案 token 数 每答案单词数 CoT 4.7500 782.0571 45.7429 ToT 21.7040 2679.3428 38.9143 Few-shot(2) 4.7182 959.4355 35.6334 EvoPatient 6.6922 401.5882 32.2432 注:EvoPatient 较 CoT 减少 380.4689 个 token,减少 13.4997 个单词 -
泛化性与迁移性:在鼻咽癌 100 个病例上训练后,直接迁移到其他 5 种疾病,相关指标平均提升:
- 相关性:3.8%
- 忠实性:13.8%
- 稳健性:18.1%
- 综合质量:12.0%
-
信息泄露缓解:进化前病人智能体易泄露疾病名称等关键信息(如回答 “我的鼻咽癌复发”),进化后可有效识别并拒绝欺骗性问题,在人类和 GPT-4 评估中,偏好率显著高于基线。
3.3.3 医生智能体专项分析
- 组件有效性:医生智能体的 “进化机制”“问题库”“画像” 三大组件均对性能有正向贡献,组合后综合质量从 0.4010 提升至 0.5667,问诊相关问题占比从 14.09% 提升至 25.57%。
- 招募策略影响:DAG 结构的招募策略优于树状、链式结构,平衡库的积累速度与数量;多学科招募使问题多样性提升,同时保证专业性,注意力库积累率显著提高。
,组合后综合质量从 0.4010 提升至 0.5667,问诊相关问题占比从 14.09% 提升至 25.57%。 - 招募策略影响:DAG 结构的招募策略优于树状、链式结构,平衡库的积累速度与数量;多学科招募使问题多样性提升,同时保证专业性,注意力库积累率显著提高。