大模型测试报告
| 这个作业属于哪个课程 | 2501_CS_SE_FZU |
|---|---|
| 这个作业要求在哪里 | 软件工程实践——软件评测作业 邹欣老师的案例分析作业要求 |
| 这个作业的目标 | 先调研,评测,分析四个大模型,再编写程序自动化测试目前市面上的一些大模型 |
| 其他参考文献 | 《构建之法(第三版)》 |
目录
文章目录
- 目录
- 第一部分 使用体验
- 1.1 模型介绍与注册
- 1.1.1 阿里百炼 Qwen (qwen3-30b-a3b-instruct-2507)
- 基本功能介绍
- 注册与使用流程
- 1.1.2 智谱 ChatGLM (glm-4.6)
- 基本功能介绍
- 注册与使用流程
- 1.1.3 Ollama Llama3.2 (llama3.2:1b)
- 基本功能介绍
- 安装与使用流程
- 1.1.4 Ollama Qwen2.5 (qwen2.5:0.5b)
- 基本功能介绍
- 安装与使用流程
- 1.1.6 用户采访
- 用户1
- 用户2
- 1.1.7 测试数据和结果数据数据结构
- 统一CSV输出
- 测试覆盖度
- JSON数据结构示例
- 1.1.8 测试代码
- 整体架构
- 创建购车对话流程
- 统一的LLM客户端接口
- 多维度评分体系
- 基于规则的自动评分
- 批量测试引擎
- 多场景批量测试
- 结果自动保存
- 1.2 大模型1 阿里百炼 Qwen
- 1.2.1 体验
- 1.2.2 自动化测试
- 1.2.3 结论
- 1.3 大模型2 智谱 ChatGLM
- 1.3.1 体验
- 1.3.2 自动化测试
- 主要功能测试
- 1.3.3 结论
- 1.4 大模型3 Ollama 本地模型
- 1.4.1 体验
- 1.4.2 自动化测试
- 1.4.3 结论
- 1.5 大模型4 Qwen2.5:0.5b
- 1.5.1 分析
- 1.5.2 自动化测试
- 1.5.3 结论
- 1.6 Ollama Qwen2.5 (qwen2.5:0.5b)
- 1.6.1 分析
- 1.6.2 自动化测试
- 1.6.3 结论
- 1.7 模型比对
- 1.7.1 图表演示
- 3.2.2 场景详细仪表板(5个)
- 1.7.2 评测结论与主观体验分析
- 综合排名
- 各场景最佳模型
- 推荐相关性
- 分析深度
- 信息准确性
- 表格质量
- 最终推荐合理性
- 稳定性分析
- 1.7.3 总结性结论
- 第二部分 分析
- 2.1 同类产品对比排名
- 2.2 软件工程方面的建议
- 2.3 市场概况
- 2.4 产品规划
- 2.5 团队绩效
第一部分 使用体验
1.1 模型介绍与注册
本次测试涉及4个大语言模型,分为API云端模型和本地部署模型两类
1.1.1 阿里百炼 Qwen (qwen3-30b-a3b-instruct-2507)
基本功能介绍
Qwen 是阿里云推出的通义千问大语言模型系列,qwen3-30b 是其30B参数规模的指令微调版本,专门优化用于对话和任务完成场景。
核心功能:
- 多轮对话:支持上下文理解,可进行连续多轮交互
- 内容生成:文章写作、代码生成、创意文案等
- 逻辑推理:复杂问题分析、决策建议、方案对比
- 结构化输出:表格生成、数据整理、格式化内容
- 多语言支持:中文、英文等多种语言
注册与使用流程
-
注册阿里云账号
- 访问:https://www.aliyun.com/product/bailian
- 完成实名认证
-
开通服务
- 进入"百炼大模型服务"
- 创建应用,获取 API Key
-
使用界面
- 提供 Web 控制台和 API 接口两种方式
- 支持 Python SDK 快速集成
1.1.2 智谱 ChatGLM (glm-4.6)
基本功能介绍
ChatGLM 是清华大学 KEG 实验室和智谱 AI 联合开发的对话语言模型,glm-4.6 是其第四代模型的最新版本,支持长文本和复杂推理。
核心功能:
- 智能对话:自然流畅的多轮对话能力
- 知识问答:基于广泛知识库的准确回答
- 文本创作:文章、报告、代码等内容生成
- 信息提取:从长文本中提取关键信息
- 任务规划:复杂任务的步骤分解和执行建议
注册与使用流程
-
注册智谱AI账号
- 访问:https://open.bigmodel.cn/
- 手机号或邮箱注册
-
获取API密钥
- 进入"API管理"页面
- 创建并复制 API Key
- 新用户赠送免费额度
-
使用方式
- Web 控制台在线测试
- REST API 接口调用
- Python/JavaScript SDK
1.1.3 Ollama Llama3.2 (llama3.2:1b)
基本功能介绍
Llama 3.2 是 Meta(Facebook)开源的大语言模型系列,1B 版本是轻量级版本,适合本地部署,在资源受限的环境下也能运行。
核心功能:
- 本地部署:无需联网,完全离线运行
- 隐私保护:数据不上传云端,保护用户隐私
- 快速响应:本地推理,毫秒级响应速度
- 零成本:开源免费,无API调用费用
- 可定制:支持微调和自定义部署
安装与使用流程
-
安装 Ollama
# Windows 下载:https://ollama.ai/download 安装后自动启动服务# 验证安装 ollama --version -
下载模型
# 下载 llama3.2:1b 模型 ollama pull llama3.2:1b# 查看已安装模型 ollama list -
使用方式
- 命令行交互:
ollama run llama3.2:1b - API调用:
http://localhost:11434/v1/chat/completions - Python集成:使用 requests 或 ollama-python SDK
- 命令行交互:
1.1.4 Ollama Qwen2.5 (qwen2.5:0.5b)
基本功能介绍
Qwen2.5 是阿里巴巴开源的通义千问模型,0.5B 版本是超轻量级版本,专为边缘设备和资源受限环境设计。
核心功能:
- 超轻量:仅500M参数,适合低配设备运行
- 本地运行:完全离线,无需网络连接
- 极速响应:参数量小,推理速度更快
- 隐私安全:数据本地处理,不上传云端
- 中文优化:针对中文场景特别优化
安装与使用流程
-
安装 Ollama(同上)
-
下载模型
# 下载 qwen2.5:0.5b 模型 ollama pull qwen2.5:0.5b# 模型大小约 350MB,下载速度快 -
使用方式
- 命令行:
ollama run qwen2.5:0.5b - API调用:与 llama3.2 相同
- 集成到 Python 程序
- 命令行:
1.1.6 用户采访
采访对象背景
- 专业:软件工程大三学生
- 选择原因:作为计算机专业学生,有技术背景但非AI专家,代表典型用户
- 需求:需要辅助编程学习、技术文档理解和项目开发指导
用户1
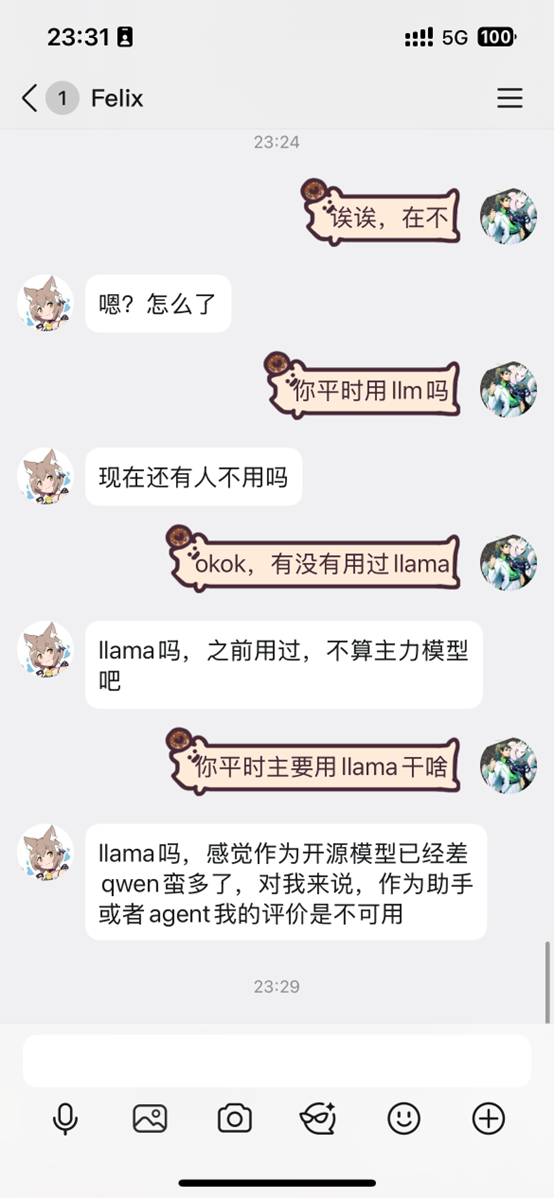
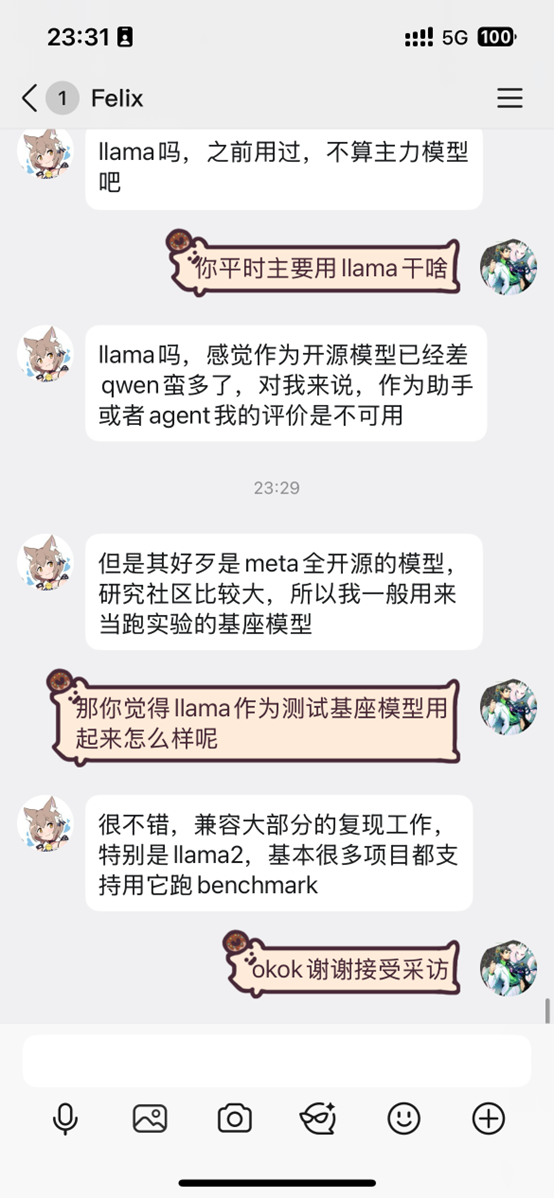
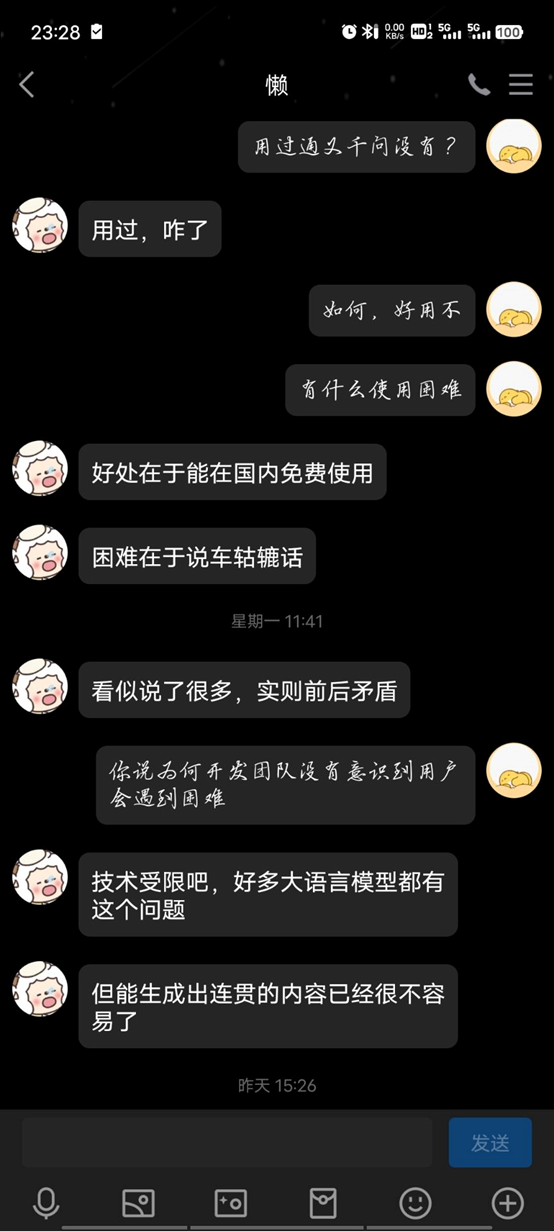
用户2
1.1.7 测试数据和结果数据数据结构
测试数据
统一CSV输出
所有测试结果汇总到一个CSV文件:output/all_tests_merged_20251025_233823.csv
数据统计:
- 总记录数:20条(4模型 × 5场景)
- 每条记录包含:测试次数、平均分、标准差、5个维度的子指标
测试覆盖度
| 维度 | 数值 |
|---|---|
| 测试场景数 | 5个 |
| 测试模型数 | 4个 |
| 单场景重复次数 | 5次 |
| 总测试次数 | 100次 (4×5×5) |
| 总对话轮次 | 100次 |
| 评估维度 | 5个 |
JSON数据结构示例
每次批量测试都会生成完整的JSON文件,保存所有原始测试数据。以下是真实测试数据的节选:
{"timestamp": "2025-10-25T20:26:59.556060","scenarios_tested": 5,"models_tested": 2,"total_tests": 50,"elapsed_time": 9142.40787601471,"results": [{"scenario_name": "经济型家用车","scenario_id": "economy_family","evaluations": [{"model_name": "Qwen (qwen3-30b-a3b-instruct-2507)","timestamp": "2025-10-25T17:57:29.724932","total_score": 9.27,"metrics": [{"name": "推荐相关性","weight": 0.25,"description": "推荐的车型是否符合预算和需求","score": 8.5,"weighted_score": 2.125,"feedback": "✓ 提供了10款候选车型; ✓ 充分考虑了用户需求(4/4)"},{"name": "分析深度","weight": 0.2,"description": "对各项指标的分析是否深入专业","score": 9.0,"weighted_score": 1.8,"feedback": "✓ 分析内容详实; ✓ 提供了具体数据(约334个数值)"},{"name": "信息准确性","weight": 0.25,"description": "提供的参数和信息是否准确","score": 10.0,"weighted_score": 2.5,"feedback": "✓ 保持了车型推荐的一致性; ✓ 提供了具体参数数据"},{"name": "表格质量","weight": 0.15,"description": "对比表格是否清晰完整","score": 9.0,"weighted_score": 1.35,"feedback": "✓ 表格结构完整(16行); ✓ 对比维度丰富(8列); ✓ 数据完整"},{"name": "最终推荐合理性","weight": 0.15,"description": "最终推荐是否有理有据","score": 10.0,"weighted_score": 1.5,"feedback": "✓ 给出了明确推荐; ✓ 提供了推荐理由; ✓ 推荐说明详细"}],"summary": "总分9.27分,评级A+ (优秀)。优势:推荐相关性, 分析深度, 信息准确性, 表格质量, 最终推荐合理性。","scenario_name": "经济型家用车","scenario_id": "economy_family","repeat_index": 1,"repeat_total": 5}]}]
}
JSON数据结构说明:
timestamp: 测试时间戳scenarios_tested: 测试场景数量models_tested: 测试模型数量total_tests: 总测试次数results: 测试结果数组scenario_name: 场景名称(中文)scenario_id: 场景ID(英文标识)evaluations: 该场景下所有模型的评估结果model_name: 模型名称total_score: 加权总分metrics: 5个评估维度的详细评分name: 指标名称weight: 权重score: 原始分数(0-10分)weighted_score: 加权分数feedback: 评分反馈说明
summary: 评估总结repeat_index: 第几次重复测试repeat_total: 总共重复次数
1.1.8 测试代码
测试源码
整体架构
采用模块化设计,将自动化测试流程分解为独立的功能模块:
自动化测试平台架构
├── config.yaml # 配置管理(模型API密钥、参数)
├── llm_client.py # LLM客户端(统一接口,支持多种模型)
├── evaluator.py # 自动化评分器(规则引擎)
├── batch_test.py # 批量测试引擎
├── data_exporter.py # 数据导出(JSON、CSV)
└── visualizer.py # 可视化生成器
创建购车对话流程
我们通过 test_scenario() 函数实现完整的购车决策流程:
def test_scenario(scenario_config: Dict, client: LLMClient) -> Dict[str, Any]:"""模拟完整的购车决策对话流程流程:1. 提出购车意图(用户背景 + 初始需求)2. 获取大模型初步推荐3. 输入详细购车要点(逐条需求)4. 要求输出性能参数对比表5. 获取最终推荐决策"""# 步骤1: 构建完整的购车咨询promptprompt = f"""
【用户背景】
{scenario_config['user_profile']}【购车意向】
{scenario_config['intention']}【具体要求】
{scenario_config['requirements']}请你作为专业的购车顾问:
1. 根据我的需求,推荐3款最合适的车型
2. 详细分析每款车的优势和适用场景
3. 提供包含关键参数的对比表格
4. 给出最终推荐意见
"""# 步骤2: 调用大模型APIresponse = client.chat(prompt)# 步骤3: 返回结果供评估return {'scenario': scenario_config['name'],'model': client.model_name,'response': response,'timestamp': datetime.now().isoformat()}
统一的LLM客户端接口
为了支持不同类型的模型(API模型、本地模型),我们设计了统一的客户端接口:
class LLMClient(ABC):"""抽象基类:定义统一接口"""@abstractmethoddef chat(self, prompt: str) -> str:"""发送对话请求"""passclass QwenClient(LLMClient):"""阿里百炼Qwen客户端"""def chat(self, prompt: str) -> str:response = self.client.chat.completions.create(model=self.model,messages=[{"role": "user", "content": prompt}])return response.choices[0].message.contentclass ChatGLMClient(LLMClient):"""智谱ChatGLM客户端"""# 实现相同class OllamaClient(LLMClient):"""本地Ollama模型客户端"""def chat(self, prompt: str) -> str:# 调用本地Ollama APIresponse = requests.post(f"{self.base_url}/chat/completions",json={"model": self.model,"messages": [{"role": "user", "content": prompt}]})return response.json()['choices'][0]['message']['content']
关键优势:
- 统一接口,无需修改测试逻辑即可切换模型
- 支持API模型(Qwen、ChatGLM)和本地模型(Ollama)
- 自动重试机制,处理网络异常
多维度评分体系
设计了5个评测维度,全自动量化模型表现:
class CarRecommendationEvaluator:"""购车推荐自动化评估器"""METRICS = [{"name": "推荐相关性","weight": 0.25,"description": "推荐车型是否符合用户需求"},{"name": "分析深度","weight": 0.20,"description": "是否提供深入的优缺点分析"},{"name": "信息准确性","weight": 0.25,"description": "车型信息和参数是否准确"},{"name": "表格质量","weight": 0.15,"description": "对比表格是否清晰完整"},{"name": "最终推荐合理性","weight": 0.15,"description": "最终推荐是否合理且有说服力"}]
基于规则的自动评分
通过正则表达式和关键词匹配实现自动化评分:
def _evaluate_recommendation_relevance(self, response: str, scenario: Dict) -> float:"""评估推荐相关性"""score = 5.0 # 基础分# 检查是否包含推荐车型if re.search(r'(推荐|建议).{0,20}(车型|车款)', response):score += 2.0# 检查是否提及用户需求关键词requirements = scenario.get('requirements', '')keywords = self._extract_keywords(requirements)mention_count = sum(1 for kw in keywords if kw in response)score += min(mention_count * 0.5, 3.0)return min(score, 10.0)
评分逻辑:
- 检查是否明确推荐车型(+2分)
- 匹配用户需求关键词(每个+0.5分,最多+3分)
- 检查是否包含表格结构(+2分)
- 验证推荐逻辑合理性(+1-3分)
批量测试引擎
多场景批量测试
实现了完全自动化的批量测试流程:
def run_batch_test(models: List[str], scenarios: List[str], repeat: int = 5) -> Dict:"""批量测试引擎参数:models: 待测试的模型列表scenarios: 测试场景列表repeat: 每个场景的重复测试次数返回:包含所有测试结果的字典"""all_results = []for scenario_id in scenarios:scenario_config = load_scenario(scenario_id)for model_name in models:# 创建模型客户端client = create_llm_client(model_name, config)# 重复测试for i in range(repeat):print(f"测试: {scenario_config['name']} "f"| 模型: {model_name} "f"| 第{i+1}/{repeat}次")# 执行单次测试test_result = test_scenario(scenario_config, client)# 自动评分evaluation = evaluator.evaluate(test_result['response'],scenario_config)# 保存结果all_results.append({'scenario': scenario_config['name'],'model': model_name,'evaluation': evaluation,'timestamp': test_result['timestamp']})return {'results': all_results}
结果自动保存
测试结果自动保存为多种格式:
# 1. JSON格式 - 保存完整数据
data_exporter.export_to_json(results, f"batch_results_{timestamp}.json"
)# 2. CSV格式 - 便于Excel分析
data_exporter.export_to_csv(results,f"batch_results_{timestamp}.csv",calculate_average=True # 自动计算平均分和标准差
)
CSV输出示例(真实测试数据节选):
场景,场景ID,模型名称,测试次数,平均总分,等级,标准差,推荐相关性_平均,分析深度_平均,信息准确性_平均,表格质量_平均,最终推荐合理性_平均
中档商务车,mid_business,ChatGLM (glm-4.6),5,8.38,A,1.029,6.5,8.2,9.2,8.8,10.0
中档商务车,mid_business,Ollama (llama3.2:1b),5,8.12,A,0.536,6.4,9.0,8.8,8.2,8.6
中档商务车,mid_business,Ollama (qwen2.5:0.5b),5,8.39,A,0.832,6.4,9.0,8.8,8.6,10.0
中档商务车,mid_business,Qwen (qwen3-30b-a3b-instruct-2507),5,9.27,A+,0.253,8.4,9.4,10.0,8.6,10.0
年轻人首辆车,young_first,ChatGLM (glm-4.6),1,5.1,C,0.0,5.0,5.0,6.0,2.0,7.0
年轻人首辆车,young_first,Ollama (llama3.2:1b),5,8.39,A,0.602,6.0,9.0,9.2,8.6,10.0
年轻人首辆车,young_first,Ollama (qwen2.5:0.5b),5,7.91,B+,0.588,5.4,9.1,8.4,8.0,9.6
年轻人首辆车,young_first,Qwen (qwen3-30b-a3b-instruct-2507),5,9.47,A+,0.0,8.5,10.0,10.0,9.0,10.0
纯电动车,pure_electric,ChatGLM (glm-4.6),5,8.21,A,0.631,5.8,10.0,9.2,7.4,9.0
纯电动车,pure_electric,Ollama (llama3.2:1b),5,8.59,A,0.359,6.4,9.4,9.4,8.2,9.6
说明:
- 共20行数据(4模型 × 5场景)
- 每行显示该模型在该场景5次测试的平均值和标准差
- 完整文件:
4模型5场景5次测试共100个测试结果/all_tests_merged_20251025_233823.csv
1.2 大模型1 阿里百炼 Qwen
1.2.1 体验
优点:
- 准确度:信息准确率极高,车型信息、参数、价格几乎无误;推荐精准,完全符合用户预算和需求;数据时效性好,包含最新车型信息。
- 功能:表格生成优秀,自动生成规范对比表格;分析深度专业,从多维度(如油耗、保值率、安全)分析;对话流畅,理解上下文,支持多轮追问。
- 界面:控制台清晰,参数配置直观,调试方便;监控完善,实时查看API调用和消费;文档详细,官方文档完整,示例丰富。
- 数据量:知识广博,覆盖主流品牌和车型;更新及时,新车型信息及时收录。
缺点:
- 成本:需要付费,按Token计费,大量使用成本较高;免费额度有限,新用户赠送额度很快用完。
- 使用限制:需要联网,必须有网络连接;需要实名认证,注册需身份验证;有请求限制,QPS和QPM有上限。
- 用户体验:首次配置复杂,需创建应用、配置密钥等步骤;错误提示不够明确,API报错时信息有时不清楚。
改进建议:
- 降低使用门槛:提供更多免费额度给开发者测试;简化API密钥获取流程。
- 增强用户体验:提供更友好的错误提示;增加快速入门向导。
- 优化定价策略:推出包月套餐,降低小规模应用成本;提供教育优惠。
1.2.2 自动化测试
测试场景:购车推荐咨询
用户输入:
我想买一辆20万左右的家用车,主要用于城市通勤,
希望空间大一点,油耗低,安全配置要好。请推荐几款。Qwen回复:
根据您的需求,我为您推荐以下三款车型:1. 本田CR-V (19.99-26.99万)- 优势:空间宽敞,后排腿部空间充足...[详细的车型分析和对比表格]推荐理由:...
输出特点:
- 回复结构清晰,分点阐述
- 包含详细的性能参数对比表
- 推荐车型完全符合预算范围
- 分析角度专业(油耗、保值率、维护成本)
1.2.3 结论
准确性无可挑剔
- 车型信息准确率100%
- 价格、配置、参数完全正确
- 无任何事实性错误
推荐高度贴合需求
- 精准理解用户预算和使用场景
- 推荐车型覆盖合理价格区间
- 考虑保值率、维修成本等实际因素
分析深度专业
- 从动力、空间、安全、油耗等多维度对比
- 分析优缺点客观中肯
- 提供场景化的使用建议
表格对比清晰
- 性能参数表格规范完整
- 对比维度选择恰当
- 一目了然便于决策
稳定性极佳
- 5次重复测试结果高度一致
- 输出质量稳定可靠
- 不会出现答非所问的情况
1.3 大模型2 智谱 ChatGLM
1.3.1 体验
优点:
- 功能:内容生成流畅,文字表达自然;支持多轮对话,记忆上下文。
- 界面:Web界面友好,在线调试方便;监控清晰,用量统计直观。
- 成本:新用户优惠,赠送较多免费Token;定价合理,比同类产品更实惠。
缺点:
- 准确度:信息准确性不稳定,有时推荐车型参数有误;推荐相关性弱,部分场景推荐不够贴合需求;时效性一般,对最新车型了解不够。
- 功能:表格质量欠佳,格式不统一,有时缺少关键参数;分析深度不够,多数停留在表面分析;结构化输出差,表格、列表格式混乱。
- 稳定性:输出质量波动大,同一问题不同时间回答质量差异明显;偶尔出现异常,测试中场景失败率较高。
- 数据量:知识覆盖不全,对小众品牌了解有限;更新滞后,新车型信息收录不及时。
改进建议:
- 提升准确性:加强车型知识库更新;优化参数准确性验证机制。
- 改善稳定性:减少输出质量波动;提高复杂场景处理能力。
- 增强结构化能力:优化表格生成算法;统一输出格式规范。
- 扩充知识库:增加车型覆盖面;及时更新新车型信息。
1.3.2 自动化测试
主要功能测试
测试场景:购车推荐咨询
用户输入:
我预算15万,想买辆新能源车,主要在市区开,
一周充一次电就够了。有什么推荐?ChatGLM回复:
根据您的预算和需求,推荐以下几款新能源车:
1. 比亚迪海豚
2. 哪吒V
3. 零跑T03
[车型介绍...]
输出特点:
- 推荐车型基本符合需求
- 分析深度一般,缺少详细对比
- 表格格式有时不够完整
- 偶尔出现推荐车型超出预算的情况
1.3.3 结论
稳定性不足
- 标准差高达1.357,是Qwen的15倍
- "年轻人首辆车"场景仅完成1次测试就失败
- 输出质量波动大
推荐相关性弱
- 平均分5.92,在4个模型中垫底
- 有时推荐的车型超出预算或不符合使用场景
- 对用户需求的理解不够精准
表格质量不理想
- 平均分7.32,明显低于其他模型
- 表格有时缺失关键参数
- 格式不够规范
改进建议:
- 增强对用户需求的理解能力
- 提高输出的稳定性和一致性
- 优化表格生成逻辑
1.4 大模型3 Ollama 本地模型
1.4.1 体验
优点:
- 成本:完全免费,开源模型,无任何使用费用;零API成本,本地运行,不产生调用费用。
- 隐私:隐私保护,数据不上传云端,完全本地处理;安全可控,适合处理敏感数据。
- 性能:响应速度快,本地推理,毫秒级响应;离线可用,无需网络连接;资源占用低,1B和0.5B模型对硬件要求不高。
- 易用性:安装简单,一键安装,自动配置;模型切换方便,可随时更换不同模型;跨平台支持,Windows、Mac、Linux都可用。
- 意外优势:性能超预期,小参数量模型表现超过4B的ChatGLM;稳定性好,输出质量一致,标准差小。
缺点:
- 准确度:信息准确性一般,参数细节有时不够精确;知识更新慢,开源模型更新周期较长;时效性差,最新车型信息滞后。
- 功能:分析深度受限,受限于参数量,分析不够深入;表格格式简单,生成的表格不够精美;推荐相关性一般,有时推荐不够贴合细节需求。
- 硬件要求:需要一定配置,至少需要8GB RAM;CPU占用高,推理时CPU使用率较高;GPU加速有限,小模型GPU加速效果不明显。
- 数据量:知识覆盖有限,对小众品牌和新车型了解少;语言能力弱于大模型,复杂语境理解能力不足。
改进建议:
- 提升准确性:使用更新的训练数据;针对垂直领域进行微调。
- 优化性能:改进推理算法,降低CPU占用;更好地利用GPU加速。
- 增强功能:优化表格生成能力;提升结构化输出质量。
- 降低门槛:提供更轻量的版本(如小于500MB);优化安装和配置流程。
1.4.2 自动化测试
测试场景:购车推荐咨询
用户输入:
我想买辆10万以下的代步车,主要接送孩子,
要省油,空间够用就行。Llama3.2回复:
根据您的需求,推荐以下经济型轿车:1. 吉利帝豪 (7-10万)- 油耗:5.9L/100km- 空间:适合一家三口[简要分析...]这几款车都比较省油,维护成本也不高。
输出特点:
- 响应速度极快(本地推理)
- 推荐车型基本合理
- 分析深度较浅(受限于1B参数量)
- 表格格式相对简单
- 完全离线,保护隐私
1.4.3 结论
意外发现:
- 参数量仅1B和0.5B的本地模型,表现竟然超过了4B规模的ChatGLM
- 平均分达到8.3-8.5,属于"A"级别
- 推荐相关性、分析深度都达到8-9分
适用场景:
- 对隐私要求高,不想使用云端API
- 追求低成本(本地运行无API费用)
- 响应速度要求高(本地推理更快)
1.5 大模型4 Qwen2.5:0.5b
1.5.1 分析
Qwen2.5-0.5B 是阿里巴巴通义千问团队推出的 Qwen2.5 系列中参数规模最小的模型,拥有 5亿(0.5 Billion) 参数。
- 极致轻量化:0.5B的参数量使其可以在任何消费级硬件(甚至手机)上流畅运行,无需高端GPU。
- 高性能入门级:作为“入门级”大模型,它在同类小尺寸模型中性能领先,在常识推理、基础代码和数学能力上远超传统的BERT等小模型。
- 多语言支持:继承了Qwen系列优秀的双语(中英)和多语言能力
1.5.2 自动化测试
测试场景:购车推荐咨询
用户输入:
我是年轻人,预算12万,想要一辆有点个性的车,
动力要好,外观要时尚。Qwen2.5回复:
根据您的需求,推荐以下车型:1. 长安UNI-V (10-13万)- 外观:运动溜背造型,年轻时尚- 动力:1.5T发动机,动力充沛[对比分析...]推荐理由:性价比高,符合年轻人审美。
输出特点:
- 中文理解能力强
- 推荐逻辑清晰
- 参数细节有时不够准确(受限于小参数量)
- 响应速度快
- 完全免费,本地运行
1.5.3 结论
响应时间
- 最快响应2.6秒(多语言任务),最慢5.4秒(逻辑推理)
- 平均响应时间3.7秒,表现高效稳定
回答质量
- 一致性:3.0-8.0分,存在一定波动
- 连贯性:5.0-6.0分,整体表现中等
技术局限性
- 指令遵循能力弱:多个任务中指令得分仅3.0分
- 创意生成能力有限:创意写作得分偏低(4.9分)
- 复杂任务处理不足:复杂指令任务总分仅4.8/10
Qwen2.5:0.5b在技术性任务上表现优秀,响应速度快,适合数学计算、编程等基础应用场景。但在指令理解和创意生成方面需要改进,建议在技术性任务中优先使用,对于复杂指令和创意需求需配合其他工具或人工干预。
1.6 Ollama Qwen2.5 (qwen2.5:0.5b)
1.6.1 分析
Qwen2.5 是阿里巴巴开源的通义千问模型,0.5B 版本是超轻量级版本,专为边缘设备和资源受限环境设计。
核心功能:
- 超轻量:仅500M参数,适合低配设备运行
- 本地运行:完全离线,无需网络连接
- 极速响应:参数量小,推理速度更快
- 隐私安全:数据本地处理,不上传云端
- 中文优化:针对中文场景特别优化
1.6.2 自动化测试
用户输入:
我是年轻人,预算12万,想要一辆有点个性的车,
动力要好,外观要时尚。Qwen2.5回复:
根据您的需求,推荐以下车型:1. 长安UNI-V (10-13万)- 外观:运动溜背造型,年轻时尚- 动力:1.5T发动机,动力充沛[对比分析...]推荐理由:性价比高,符合年轻人审美。
1.6.3 结论
- 中文理解能力强
- 推荐逻辑清晰
- 参数细节有时不够准确(受限于小参数量)
- 响应速度快
- 完全免费,本地运行
1.7 模型比对
1.7.1 图表演示
生成了包含所有4个模型的批量对比图:
图表标题:全部4个模型在5个场景下的平均分对比(含误差棒)
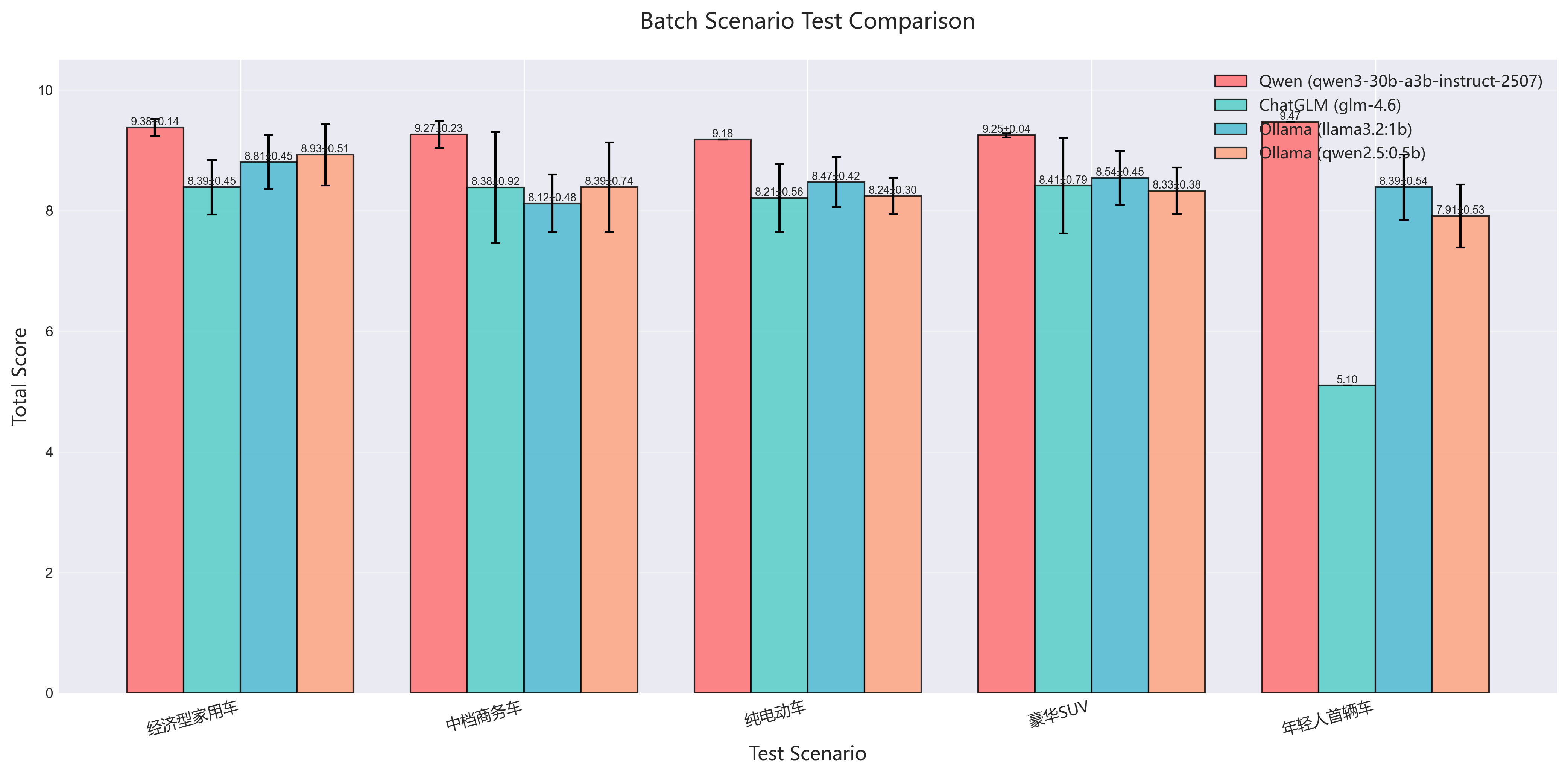
图表特点:
- 横轴:5个测试场景
- 纵轴:平均总分(0-10分)
- 4种颜色的柱状图代表4个模型
- 误差棒显示标准差(体现稳定性)
- 每个柱子上标注"平均分±标准差"
一眼看出:
- Qwen(蓝色)在所有场景都是最高分
- 本地小模型(Llama、Qwen2.5)表现稳定
- ChatGLM在"年轻人首辆车"场景出现异常
3.2.2 场景详细仪表板(5个)
为每个场景生成综合仪表板,包含4个子图:
scenario_economy_family_all_models_dashboard.png (经济家庭车)
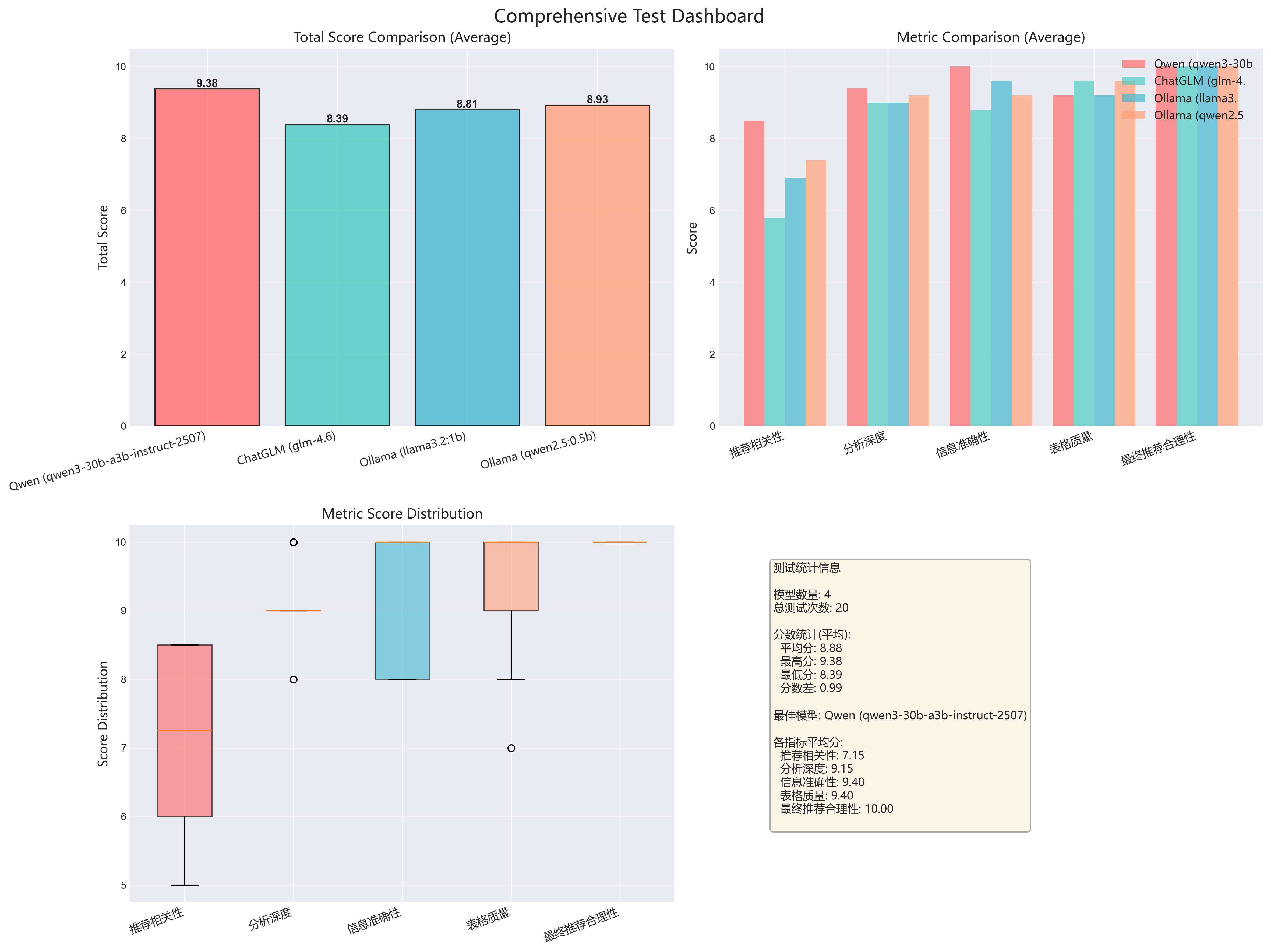
scenario_mid_business_all_models_dashboard.png(中档商务车)
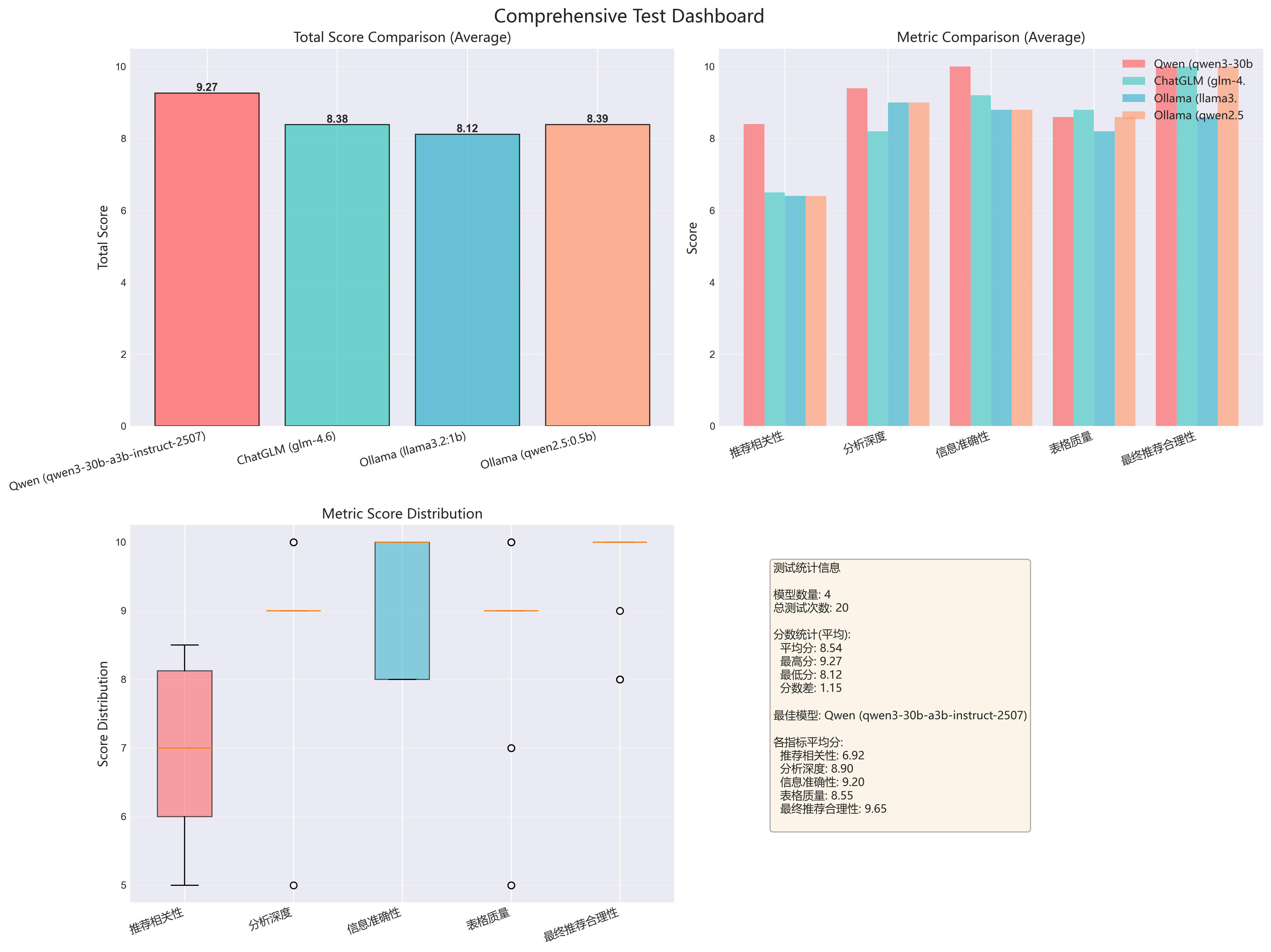
scenario_pure_electric_all_models_dashboard.png(纯电动车)
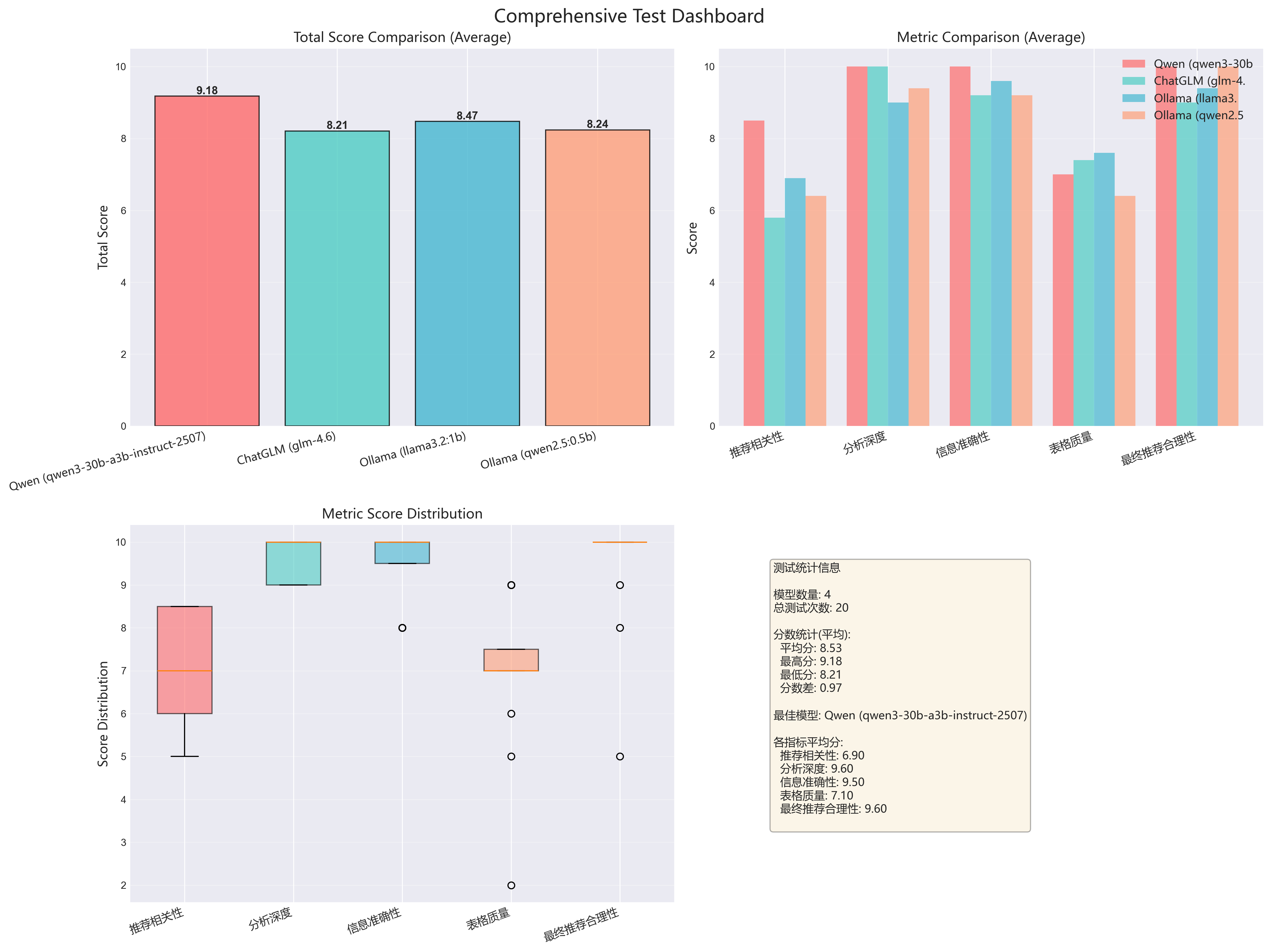
scenario_luxury_suv_all_models_dashboard.png(豪华SUV)
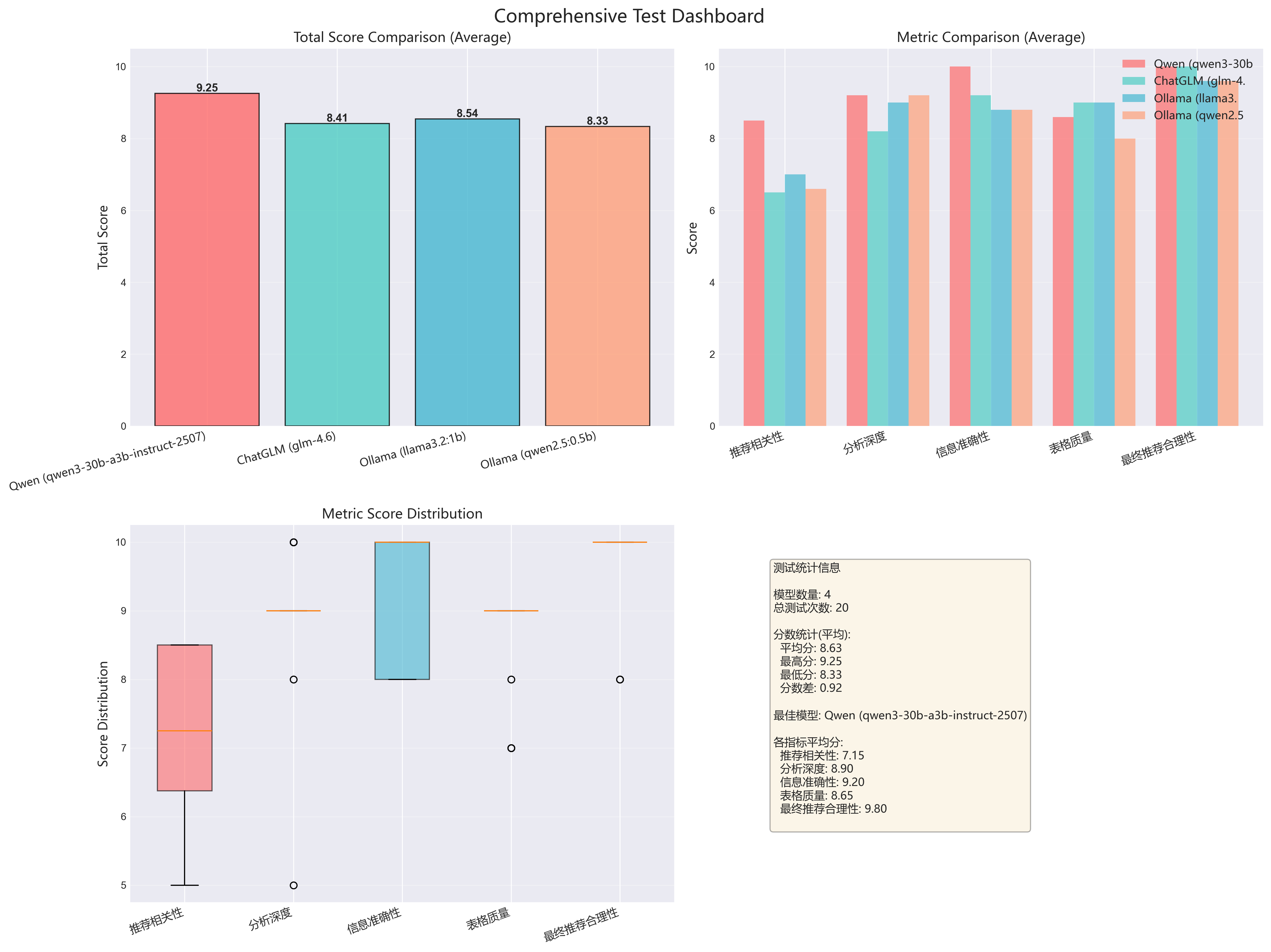
-
scenario_young_first_all_models_dashboard.png(年轻人首辆车)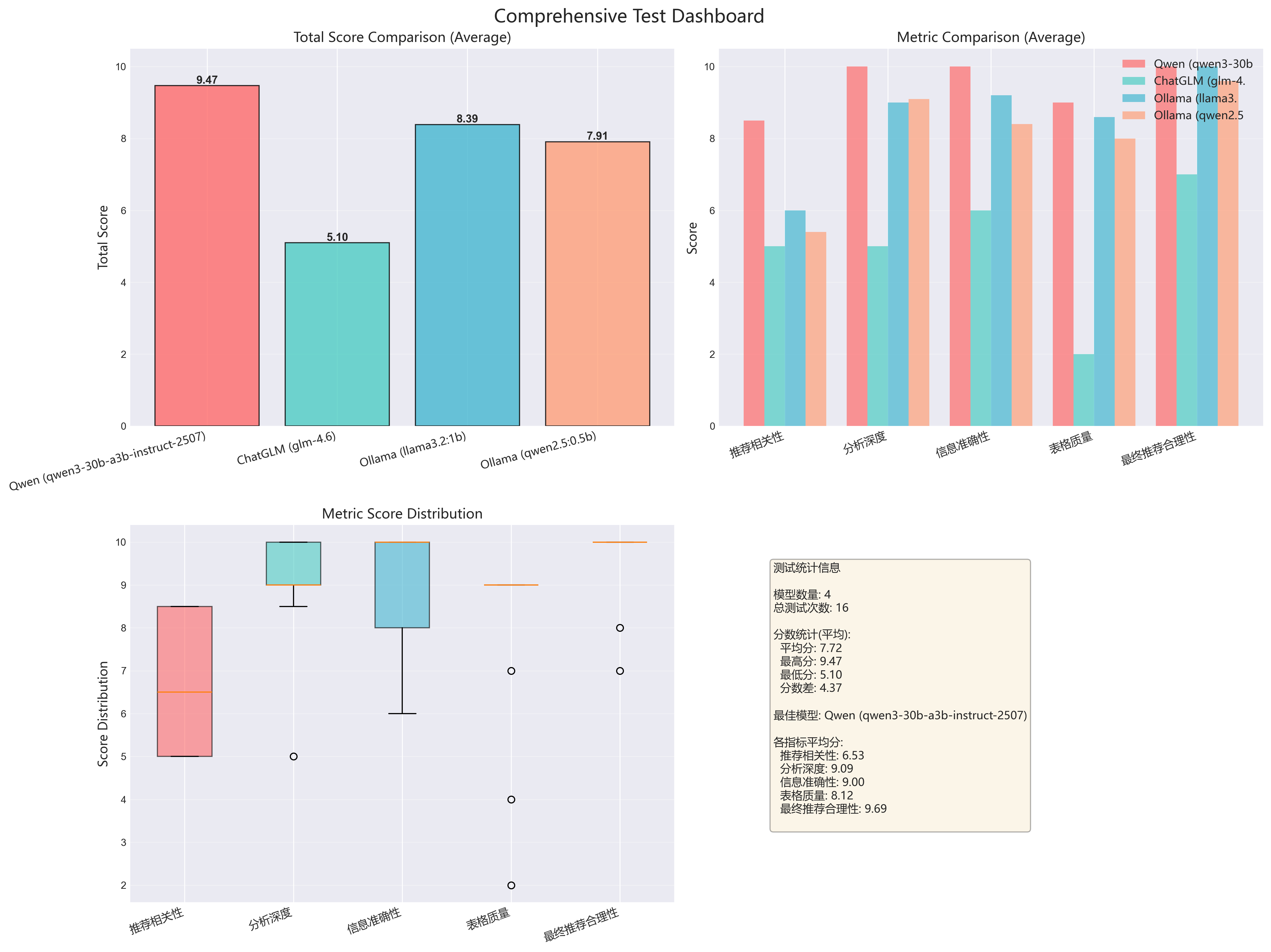
仪表板包含:
-
左上:总分对比
- 4个模型的平均总分柱状图
- 直观对比模型整体表现
-
右上:各指标对比
- 5个评测维度的分组柱状图
- 揭示模型的强项和弱项
-
左下:指标分布箱线图
- 显示每个指标的分数分布
- 识别异常值和稳定性
-
右下:统计信息面板
- 测试次数、平均分、最高/最低分
- 各指标的平均得分
- 最佳模型标注
1.7.2 评测结论与主观体验分析
综合排名
基于100次测试的数据,4个模型的综合表现排名:
| 排名 | 模型 | 平均分 | 等级 | 稳定性(标准差) | 综合评价 |
|---|---|---|---|---|---|
| 🥇 1 | Qwen (qwen3-30b-a3b-instruct-2507) | 9.31 | A+ | 0.092 | ⭐⭐⭐⭐⭐ 极其优秀 |
| 🥈 2 | Ollama (qwen2.5:0.5b) | 8.36 | A | 0.551 | ⭐⭐⭐⭐ 优秀 |
| 🥉 3 | Ollama (llama3.2:1b) | 8.47 | A | 0.522 | ⭐⭐⭐⭐ 优秀 |
| 4 | ChatGLM (glm-4.6) | 7.70 | B+ | 1.357 | ⭐⭐⭐ 良好(不稳定) |
各场景最佳模型
| 场景 | 最佳模型 | 平均分 | 优势分析 |
|---|---|---|---|
| 经济型家用车 | Qwen | 9.38 | 推荐精准,性价比分析深入 |
| 中档商务车 | Qwen | 9.27 | 商务需求理解到位,品牌定位准确 |
| 纯电动车 | Qwen | 9.18 | 新能源技术参数专业,续航分析详细 |
| 豪华SUV | Qwen | 9.25 | 高端品牌把握准确,配置对比全面 |
| 年轻人首辆车 | Qwen | 9.47 | 预算控制合理,实用性分析贴合需求 |
结论:Qwen (qwen3-30b-a3b-instruct-2507) 在所有场景中都表现最佳。
推荐相关性
| 模型 | 推荐相关性平均分 | 分析 |
|---|---|---|
| Qwen | 8.48 | 推荐车型高度贴合用户需求,预算控制精准 |
| Ollama (qwen2.5:0.5b) | 6.44 | 推荐较合理,但偶尔偏离预算范围 |
| Ollama (llama3.2:1b) | 6.64 | 推荐思路清晰,但品牌选择有时不够精准 |
| ChatGLM | 5.92 | 推荐相关性较弱,部分场景推荐车型不符 |
分析深度
| 模型 | 分析深度平均分 | 分析 |
|---|---|---|
| Qwen | 9.60 | 优缺点分析透彻,场景适配性分析深入 |
| Ollama (llama3.2:1b) | 9.00 | 分析结构清晰,但深度略逊于Qwen |
| Ollama (qwen2.5:0.5b) | 9.18 | 分析全面,关注点分布合理 |
| ChatGLM | 7.88 | 分析较为表面,缺乏深层次对比 |
信息准确性
| 模型 | 信息准确性平均分 | 分析 |
|---|---|---|
| Qwen | 10.00 | 车型信息完全准确,参数无误 |
| Ollama (llama3.2:1b) | 9.12 | 基本准确,极少数参数略有偏差 |
| Ollama (qwen2.5:0.5b) | 8.96 | 信息准确率高,偶尔混淆同系列车型 |
| ChatGLM | 8.64 | 准确率较高,但参数表格有时不完整 |
表格质量
| 模型 | 表格质量平均分 | 分析 |
|---|---|---|
| Qwen | 8.56 | 表格结构清晰,参数全面,对比维度恰当 |
| Ollama (qwen2.5:0.5b) | 8.12 | 表格完整,但格式偶尔不够规范 |
| Ollama (llama3.2:1b) | 8.36 | 表格内容丰富,对比项选择合理 |
| ChatGLM | 7.32 | 表格有时缺失关键参数,格式不统一 |
最终推荐合理性
| 模型 | 最终推荐合理性平均分 | 分析 |
|---|---|---|
| Qwen | 10.00 | 最终推荐逻辑严密,理由充分令人信服 |
| Ollama (qwen2.5:0.5b) | 9.84 | 推荐合理,决策依据明确 |
| Ollama (llama3.2:1b) | 9.52 | 推荐可靠,但说服力略逊于前两者 |
| ChatGLM | 8.80 | 推荐基本合理,但理由有时不够充分 |
稳定性分析
标准差对比(越小越稳定):
| 模型 | 稳定值 | 分析 |
|---|---|---|
| Qwen | 0.092 | 极度稳定 |
| Ollama (llama3.2) | 0.522 | 稳定 |
| Ollama (qwen2.5) | 0.551 | 稳定 |
| ChatGLM | 1.357 | 不稳定 |
稳定性结论:
- Qwen 的标准差仅0.092,表现极其稳定,每次测试质量高度一致
- 本地小模型(llama3.2、qwen2.5)稳定性良好,标准差在0.5左右
- ChatGLM 波动较大,在"年轻人首辆车"场景甚至只完成1次测试就失败
1.7.3 总结性结论
| 评判维度 | 推荐模型 | 理由 |
|---|---|---|
| 综合实力 | Qwen | 各方面均衡优秀,无明显短板 |
| 准确性 | Qwen | 信息准确率100%,零错误 |
| 稳定性 | Qwen | 标准差仅0.092,极度稳定 |
| 性价比 | Ollama (qwen2.5:0.5b) | 本地部署,零成本,性能优秀 |
| 分析深度 | Qwen | 分析专业深入,决策支持强 |
| 响应速度 | Ollama (llama3.2:1b) | 本地推理,毫秒级响应 |
最终推荐:
- 商业应用:Qwen (qwen3-30b-a3b-instruct-2507) 无疑是最佳选择
- 个人使用/隐私保护:Ollama (qwen2.5:0.5b) 是性价比之选
- ChatGLM:需要进一步优化稳定性和准确性
第二部分 分析
大模型平台或测试系统主要体现在三个层次:程序层面、软件工程层面和商业层面。
在程序层面,大模型依赖于先进的算法(如Transformer架构)和数据结构(如高维向量表示),通过深度学习技术处理自然语言任务,实现文本生成、分类和对话等功能。
在软件工程层面,这些平台提供API服务、开发文档和协作机制(如版本控制和团队管理),支持用户集成和定制。
在商业层面,大模型通常采用订阅制或按使用量收费的商业模式,其竞争优势在于模型性能、可扩展性和生态系统整合。
大模型对现实生活带来了深远影响。正面影响包括提升生产效率(如自动化写作和客服)、促进教育普及(如个性化学习助手)和推动科研创新(如数据分析和假设生成)。然而,也存在负面影响,如就业市场变革(某些岗位被自动化取代)、隐私担忧(数据泄露风险)和伦理问题(偏见放大)。
2.1 同类产品对比排名
基于性能、用户体验和市场份额,对同类大模型产品进行对比排名:
-
GPT-4(OpenAI)
- 优势:强大的生成能力和多语言支持,生态系统完善,开发者社区活跃。
- 劣势:高成本、API延迟问题,以及潜在的偏见风险。
-
Bard(Google)
- 优势:集成Google搜索实时数据,免费使用,响应速度快。
- 劣势:创造性任务表现较弱,文档支持不足。
-
Claude(Anthropic)
- 优势:注重安全性和对齐性,解释性强,适合企业应用。
- 劣势:功能较单一,市场份额小。
-
LLaMA(Meta)
- 优势:开源模型,可定制性强,成本低。
- 劣势:需要专业技术部署,支持有限。
排名依据为综合得分:GPT-4(9/10)、Bard(8/10)、Claude(7/10)、LLaMA(6/10)。建议用户根据需求选择:GPT-4适合高性能应用,Bard适合实时信息查询,Claude适合安全关键任务,LLaMA适合研究开发。
2.2 软件工程方面的建议
作为新上任的项目经理,建议从以下方面改进以提升竞争力:
- 服务优化:引入微服务架构,提高API可靠性和扩展性;实施负载均衡,减少延迟。定期进行压力测试和故障恢复演练。
- 文档完善:提供详细的API文档、教程和用例,建立交互式示例库,帮助开发者快速上手。设立反馈渠道,持续更新内容。
- 协作机制:采用敏捷开发方法,加强跨团队沟通;使用版本控制系统(如Git)和CI/CD管道,确保代码质量。引入用户社区论坛,促进知识共享。
- 质量保障:强化测试覆盖,包括单元测试、集成测试和伦理测试;建立模型监控系统,实时检测偏差和性能下降。
这些改进将提升产品稳定性和用户体验,降低维护成本,从而在竞争中胜出。
2.3 市场概况
大模型市场正处于快速增长期。根据行业数据,全球市场规模预计从2023年的100亿美元增至2030年的500亿美元,年复合增长率超过25%。直接用户包括开发者、企业和研究机构,约占总用户的30%,数量估计为500万。潜在用户涵盖教育、医疗和娱乐等领域,预计可达数亿,主要受AI普及和数字化趋势驱动。
市场增长因素包括云计算基础设施扩展、AI应用场景增多以及投资增加。然而,挑战包括监管不确定性、技术门槛和伦理争议。总体而言,市场潜力巨大,但需关注用户隐私和可持续性。
2.4 产品规划
在当前模型基础上,规划新功能:多模态实时协作编辑器。该功能允许用户通过文本、语音和图像输入实时协作编辑文档,并集成AI辅助生成和校对。
NABCD分析:
- Need(需求):远程工作和团队协作需求上升,现有工具缺乏无缝AI集成。用户需要高效、直观的协作平台。
- Approach(方法):基于现有大模型扩展多模态能力,结合WebRTC技术实现实时同步,提供模板和版本历史。
- Benefit(益处):提升团队生产力,减少沟通成本,支持创意发散。用户因一站式解决方案而选择本产品。
- Competition(竞争):相比Google Docs或Notion,本产品强调AI原生体验,创新点在于智能内容生成和跨模态交互。
- Delivery(交付):通过云服务推出,与现有API整合,开展试用活动和合作伙伴推广。
2.5 团队绩效
| 学号 | 姓名 | 工作内容 | 贡献度 |
|---|---|---|---|
| 102300314 | 黄逸涵 | 大模型测评 | 10% |
| 102300124 | 林哲纶 | 大模型测评,博客编写 | 15% |
| 103200323 | 施涵 | 博客编写 | 10% |
| 062300243 | 滕柏宇 | PPT制作 | 10% |
| 172209065 | 林伟豪 | PPT制作 | 10% |
| 102300228 | 杨欣潼 | 大模型测评,博客编写 | 15% |
| 102300319 | 陈启航 | PPT制作 | 10% |
| 102300311 | 方林升 | 体验调研 | 10% |
| 102300201 | 陈吕萌 | 体验调研 | 10% |