第二十周周报
文章目录
- 摘要
- Abstract
- 自监督学习(Self-supervised learning) 介绍
- supervised与self-supervised的区别
- BERT简介
- Masking Input(随机遮盖一些输入单位)
- Next Sentence Prediction
- BERT的实际用途⇒下游任务(Downstream Tasks)
- BERT的应用
- 总结
摘要
本周学习了自监督式学习中的代表模型 BERT(Bidirectional Encoder Representations from Transformers),理解了它如何在没有人工标签的数据上“自我监督”地学习语言。其训练包含两个主要任务:一是将句子中随机遮挡(mask)若干词,再预测其原词;二是判断两句话是否存在逻辑衔接关系。BERT 的双向 Transformer 架构令其能从上下文全面理解文本语义。通过预训练后再进行微调(fine-tune),它可广泛应用于文本分类、问答系统、命名实体识别等任务,为自然语言处理带来巨大突破。
Abstract
This week, I learned the representative model Bert (bidirectional encoder representations from transformers) in self supervised learning, and understood how it “self supervised” language learning on data without manual labels. The training includes two main tasks: one is to mask several words in sentences and then predict their original words; The second is to judge whether there is a logical cohesion between the two sentences. Bert’s bidirectional transformer architecture enables it to fully understand text semantics from the context. Fine tune after pre training can be widely used in text classification, question answering system, named entity recognition and other tasks, bringing a huge breakthrough for natural language processing.
自监督学习(Self-supervised learning) 介绍
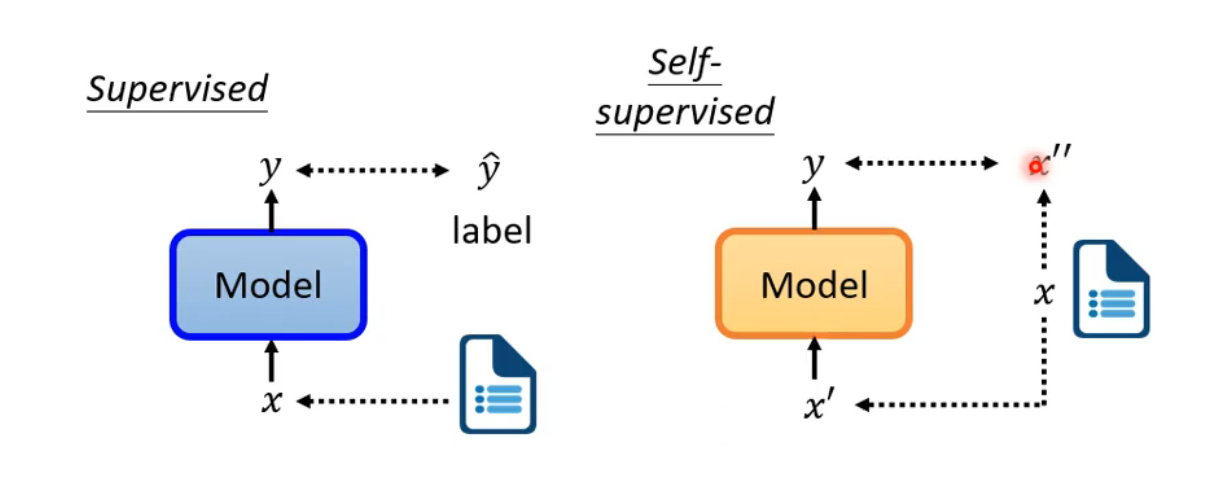
supervised与self-supervised的区别
supervised learning是需要有标签的资料的,而self-supervised learning不需要外界提供有标签的资料,他的带标签的资料源于自身。输入的资料x分两部分,一部分用作模型的输入,另一部分作为y要学习的label资料。
BERT简介
Masking Input(随机遮盖一些输入单位)
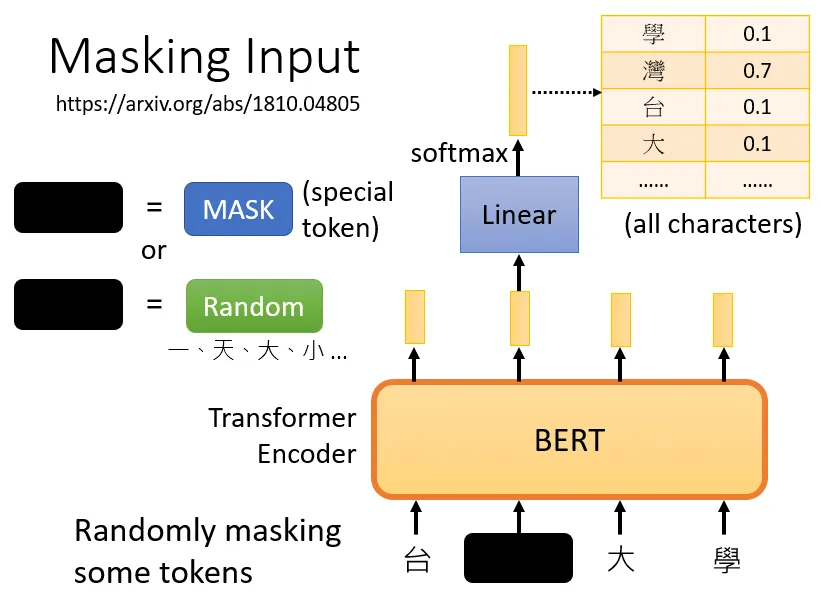
BERT一般用在自然语言处理上,所以他的输入一般是一排文字(语音、图像也可以看成是sequence),我们需要做的是把输入的文字中的一部分随机盖住。
随机遮盖的方法有两种:1.使用特殊单位来代替原单位;2.随机使用其他的单位来代替原单位。台大学就是x`(作为模型的输入),台湾大学等字体就是x``(作为输出要学习的label资料)。
训练方法:
1.向BERT输入一个句子,先随机决定哪一部分的汉字将被mask。
2.输入一个序列,我们把BERT的相应输出看作是另一个序列
3.在输入序列中寻找mask部分的相应输出,将这个向量通过一个Linear transform(矩阵相乘),并做Softmax得到一个分布。
4.用一个one-hot vector来表示MASK的字符,并使输出和one-hot vector之间的交叉熵损失最小。
Next Sentence Prediction
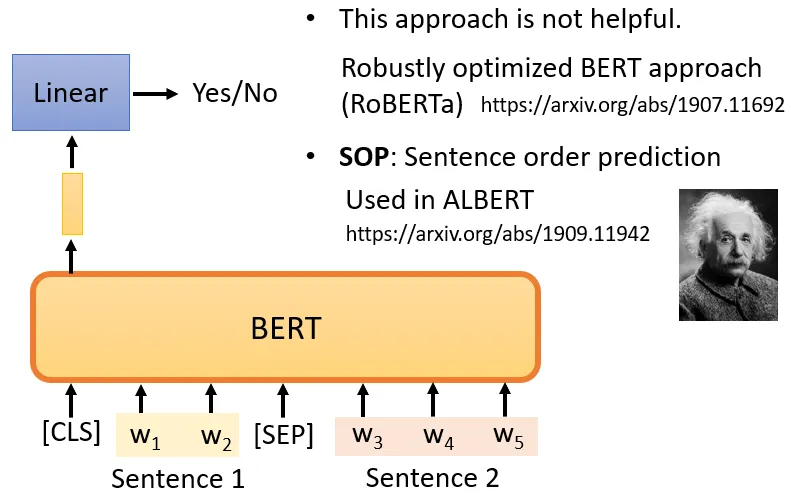
从数据库中拿出两个句子,两个句子之间添加一个特殊标记[SEP],在句子的开头添加一个特殊标记[cls],根据符号,BERT就可以知道,这两个句子是不同的句子。
CLS的输出经过和masking input一样的操作,来判断句子是否相接。但是有很多文献说这个方法对于预训练的效果并不是很大。
Sentence order prediction,SOP(句子顺序预测)⇒ALBERT
挑选的两个句子是相连的。可能有两种可能性供BERT猜测:
句子1在句子2后面相连,
句子2在句子1后面相连。
BERT的实际用途⇒下游任务(Downstream Tasks)
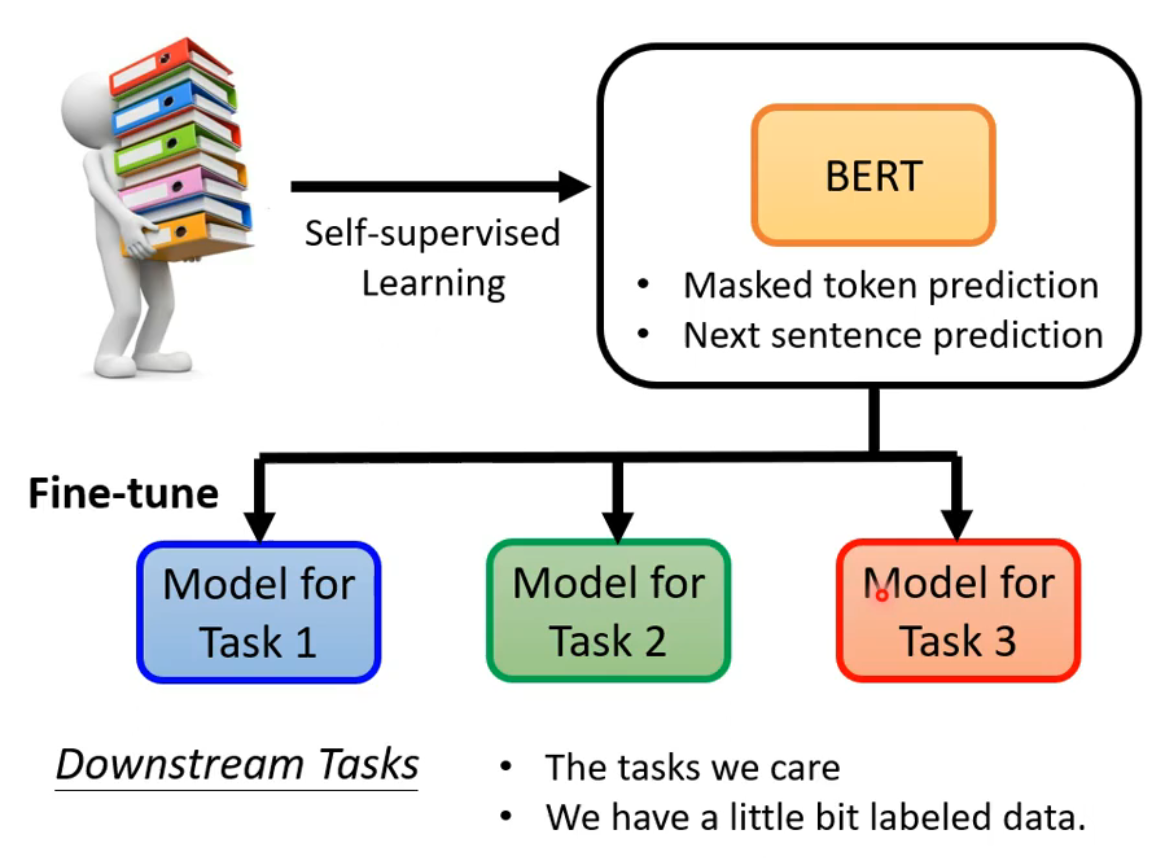
预训练与微调:
预训练:产生BERT的过程 微调:利用一些特别的信息,使BERT能够完成某种任务
BERT只学习了两个“填空”任务:
1.一个是掩盖一些字符,然后要求它填补缺失的字符。
2.预测两个句子是否有顺序关系。
但是,BERT可以被应用在其他的任务【真正想要应用的任务】上,可能与“填空”并无关系甚至完全不同。【胚胎干细胞】当我们想让BERT学习做这些任务时,只需要一些标记的信息,就能够“激发潜能”。
目前要pre-train一个能做填空题的BERT难度很大,一方面是数据量庞大,处理起来很艰难;另一方面是徐连的过程需要很长的时间。
GLUE(测试BERT的能力)
GLUE是自然语言处理任务,总共有九个任务。BERT分别微调之后做这9个任务,将9个测试分数做平均后代表BERT的能力高低。

BERT的应用
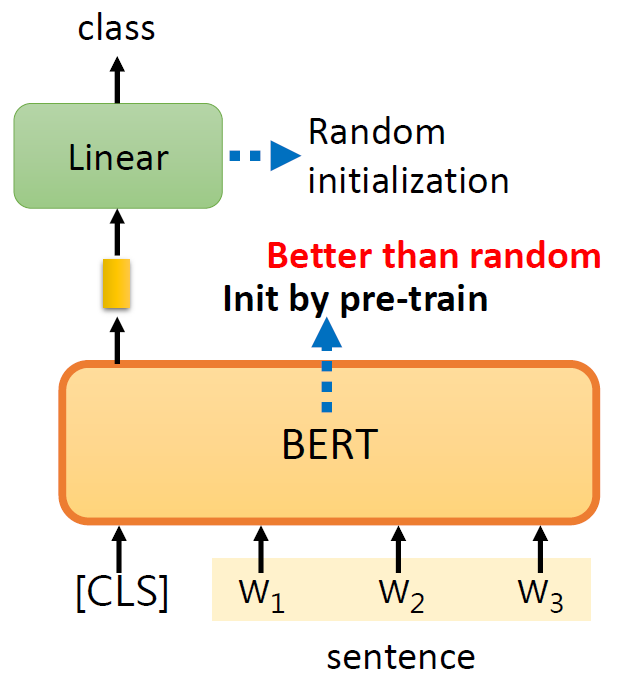
case 1-语句分类
输入句子,输出类别。CLS是一个特殊的token(单位),linear的参数是随机初始化的。训练就是更新BERT和linear这两个模型里的参数。判断该句子是积极的还是消极的
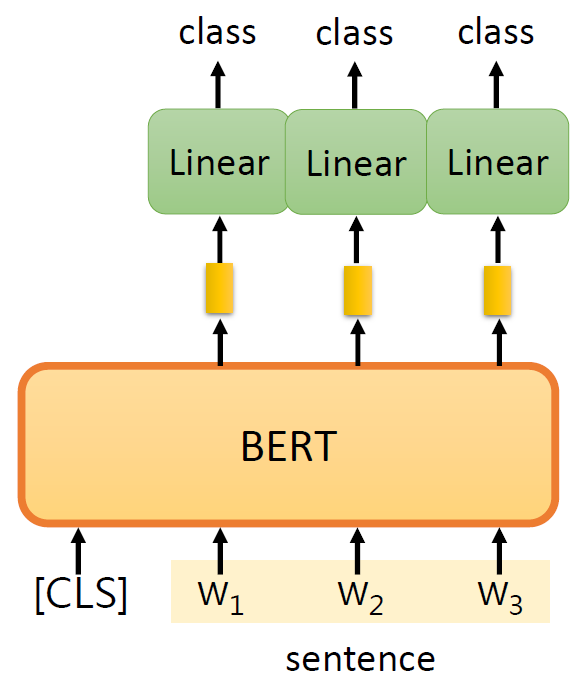
case 2-词性标注
输入句子,输出类别序列。
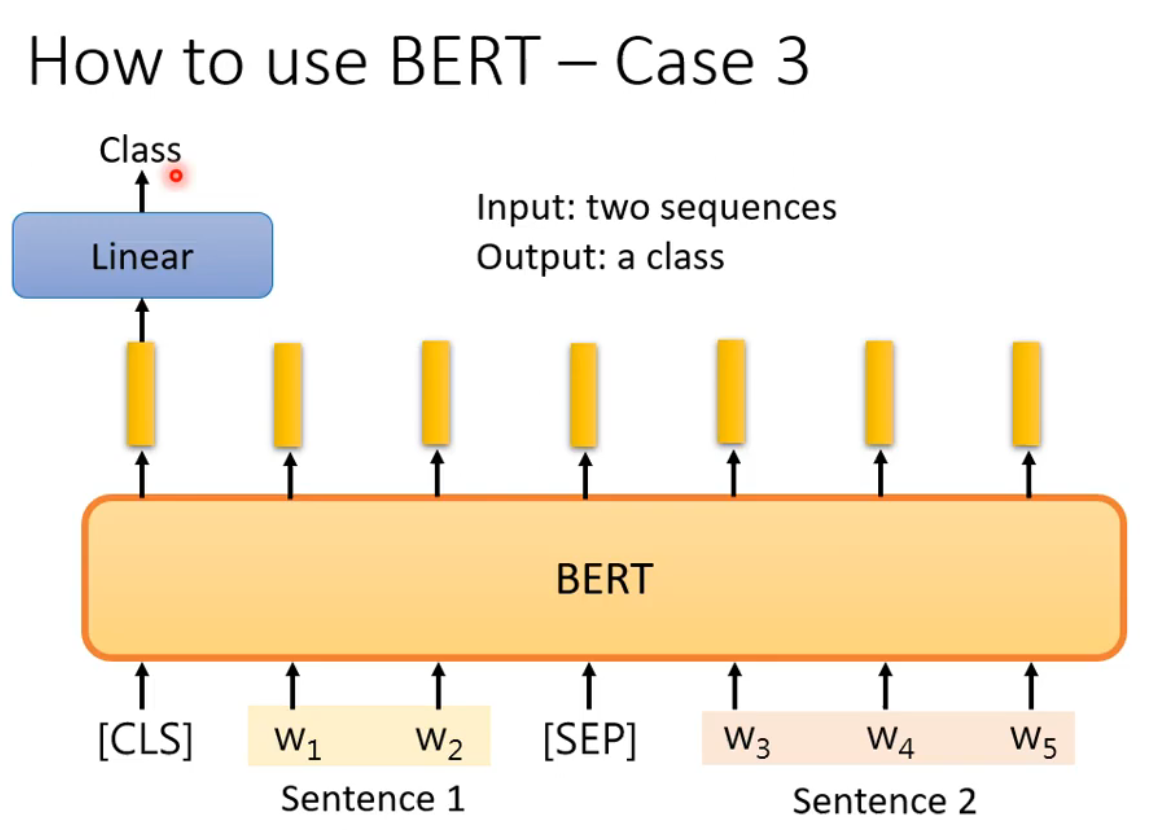
case 3-句意立场分析
输入两个句子,输出类别。输出的类别是三个中的一个:contradiction(对立的)、entailment(同边)、neutral(中立的)。
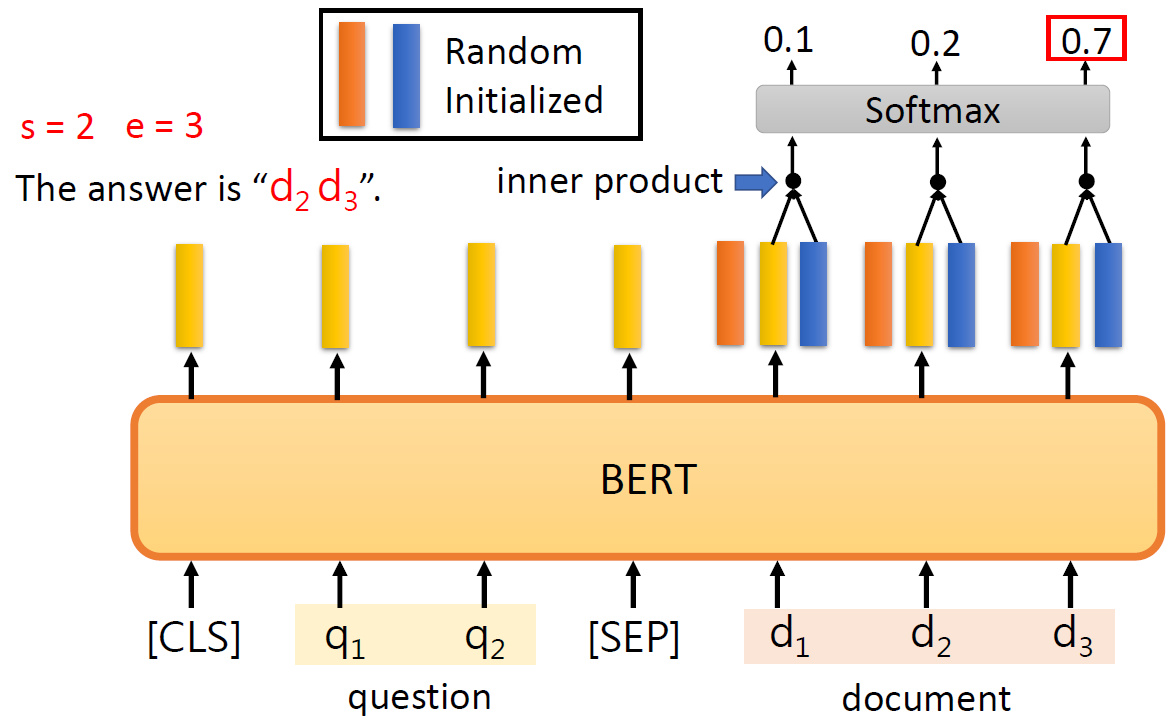
case 4-问答系统
这个问答系统是针对回答能在文中找到的问答。输入问题和文章,输出两个正整数s,e,表示第s个字到第e个字之间的字就是答案。

在BERT模型中,橙色向量与蓝色向量的维度需与BERT输出的词向量维度保持一致,以便进行内积计算。通过内积运算并经过softmax归一化后,得到每个位置作为答案起始或结束的置信分数,其中得分最高的位置即对应答案的起始位置或结束位置——橙色向量负责标识起始位置,蓝色向量则对应结束位置。
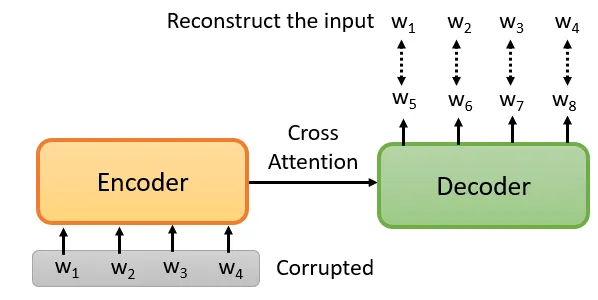
pre-train a seq2seq model
输入是一串句子,输出是一串句子,中间用Cross Attention连接起来,然后你故意在Encoder的输入上做一些干扰来破坏它。Encoder看到的是被破坏的结果,Decoder应该输出句子被破坏前的结果,训练这个模型实际上是预训练一个Seq2Seq模型。
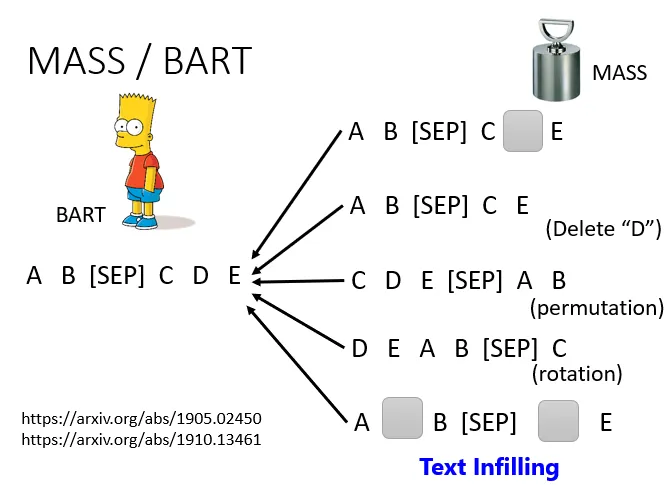
总结
通过本次学习,我理解了自监督学习的核心思想及 BERT 模型的原理。BERT 通过 Masked Language Model 和 Next Sentence Prediction 任务,让模型在无标注数据中学习语言规律。其双向注意力机制使模型能更准确地理解语义。此次学习让我认识到 BERT 在文本分类、问答系统等应用中的潜力,并激发了我继续探索 GPT 与模型微调方法的兴趣。