【AI论文】注意力照亮大语言模型(LLM)推理:预规划-锚定节奏助力细粒度策略优化
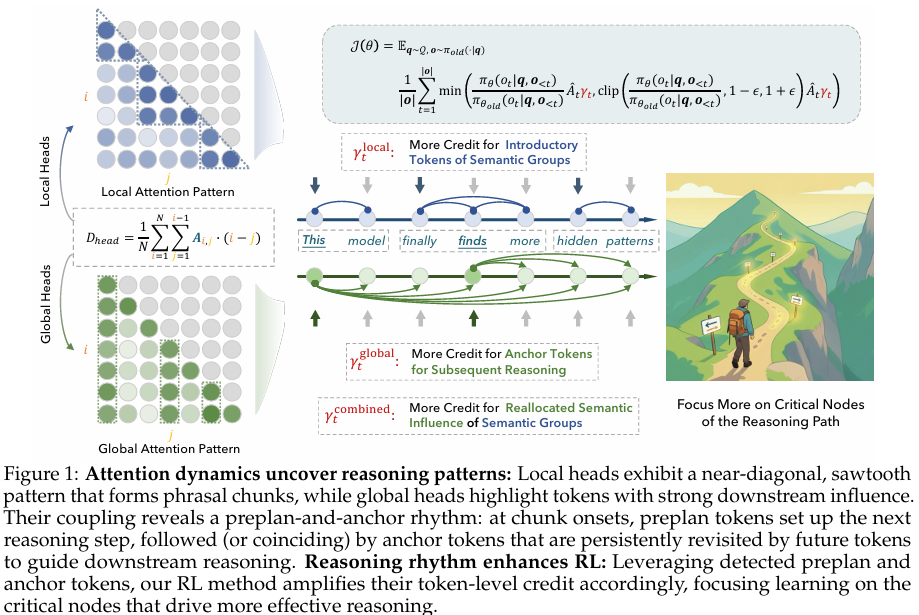
摘要:大型语言模型(LLMs)的推理模式仍不透明,而强化学习(RL)通常在整个生成过程中采用统一的信用分配方式,模糊了关键步骤与常规步骤之间的界限。本研究将注意力视为一种特殊载体,它不仅能让大型语言模型的内部逻辑变得清晰可辨,而且能揭示推理过程本身的机制蓝图,而非仅仅将其视为计算的副产品。我们首先区分了注意力头在局部与全局信息处理方面的差异,发现专注于局部信息的注意力头会在对角线附近产生锯齿状模式,表明存在短语块;而专注于全局信息的注意力头则会暴露出对后续词元产生广泛影响的词元。我们通过两个指标对这些模式进行了形式化描述:1)窗口平均注意力距离,用于衡量截断窗口内向后注意力的范围;2)未来注意力影响力,用于量化一个词元因其从后续词元接收到的平均注意力而体现出的全局重要性。综合来看,这些信号揭示了一种反复出现的“预规划-锚定”机制,即模型首先进行长程上下文参考以生成一个引导性词元,紧接着或同时出现一个语义锚定词元,该词元负责组织后续的推理过程。基于这些发现,我们引入了三种新颖的强化学习策略,这些策略能够动态地对关键节点(预规划词元、锚定词元及其时间耦合关系)进行有针对性的信用分配。实验表明,这些策略在各种推理任务中均能带来一致的性能提升。通过使优化过程与模型的内在推理节奏保持一致,我们旨在将不透明的优化过程转变为一个可操作且具备结构感知能力的流程,以期为大型语言模型推理的更透明、更有效的优化提供潜在方向。Huggingface链接:Paper page,论文链接:2510.13554
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在复杂推理任务上取得了显著成就,这主要得益于训练算法中引入的显式分步思考机制,如强化学习与可验证奖励(RLVR)的结合。RLVR通过自动化正确性检查优化模型输出,鼓励模型在生成最终答案前产生中间推理令牌,从而催生了擅长解决数学、编程和决策制定等挑战性问题的大型推理模型(LRMs)。然而,尽管LLMs在推理任务上表现出色,但其内部推理过程的透明度仍然较低,研究人员往往难以理解模型如何组织其推理步骤、何时以及如何检索和整合信息。
这种不透明性导致优化策略通常将整个生成过程视为统一目标,序列级奖励在整个令牌序列上平均分配,忽视了塑造下游推理的关键时刻与仅详细阐述局部结构的常规步骤之间的区别。
这种不匹配限制了数据效率、可解释性以及在复杂推理任务上性能提升的可靠性。因此,如何揭示LLMs内部的推理结构,并设计出与之相匹配的优化策略,成为当前研究的重要方向。
研究目的
本研究旨在通过分析注意力动态,揭示LLMs内部的推理结构,并提出一种与模型内在推理节奏相匹配的细粒度强化学习(RL)策略。具体研究目的包括:
- 揭示推理节奏:通过分析注意力机制,识别LLMs在推理过程中展现的预规划-锚定节奏,即模型如何通过长距离上下文引用生成介绍性令牌,并随后生成组织后续推理的语义锚定令牌。
- 设计细粒度RL策略:基于揭示的推理节奏,设计一种动态调整令牌级优势的RL策略,重点强化介绍性令牌和锚定令牌,提升模型在复杂推理任务上的性能。
- 验证策略有效性:通过在多个推理基准测试上评估所提策略,证明其相比传统RL方法的优越性,为LLMs的透明化和高效优化提供新的途径。
研究方法
为了实现上述研究目的,本研究采用了以下关键方法和技术:
1. 注意力动态分析
本研究首先分析了LLMs中的注意力机制,以揭示其内部推理结构。
具体方法包括:
- 注意力头分类:根据注意力头的平均注意力范围,将其分类为局部注意力头和全局注意力头。局部注意力头主要关注近距离上下文,形成短语块;全局注意力头则关注远距离上下文,突出对后续令牌有广泛影响的锚定令牌。
- 指标定义:引入两个新指标来量化注意力动态:窗口平均注意力距离(WAAD)和未来注意力影响(FAI)。WAAD衡量令牌在局部窗口内的向后注意力范围,FAI衡量令牌从后续令牌接收的平均注意力,反映其全局重要性。
2. 细粒度RL策略设计
基于注意力动态分析揭示的推理节奏,本研究设计了三种结构感知的RL策略:
- 局部块信用分配:通过检测WAAD变化识别介绍性令牌,并放大这些令牌的优势,以加强局部推理结构的基础。
- 全局锚定信用分配:根据FAI选择锚定令牌,并放大这些令牌的优势,以明确和保持组织后续推理的核心语义承诺。
- 耦合节奏信用分配:结合局部和全局信号,当锚定令牌受局部主导时,将其部分信用重新分配给相关的介绍性令牌,促进块级信用分配的一致性。
3. 实验设置与评估
为了验证所提策略的有效性,本研究在多个推理基准测试上进行了实验评估:
- 基准测试:包括Countdown谜题、CrossThink-QA数据集以及五个数学推理基准测试(AIME24、AIME25、AMC、MATH500和OlympiadBench)。
- 基线方法:采用GRPO作为基线RL方法,并比较所提策略与随机信用分配、高熵信用分配等替代策略的性能。
- 评估指标:主要评估指标为准确率,同时分析训练过程中的性能曲线和收敛速度。
研究结果
通过大量实验验证,本研究取得了以下主要结果:
1. 注意力动态揭示推理节奏
实验结果表明,局部注意力头确实形成了短语块,而全局注意力头则突出了对后续推理有广泛影响的锚定令牌。
通过WAAD和FAI指标,成功识别了预规划-锚定节奏,即模型在生成介绍性令牌后,会生成组织后续推理的锚定令牌。
2. 细粒度RL策略提升性能
在多个推理基准测试上,所提的细粒度RL策略显著提升了模型性能。
例如,在Countdown谜题上,耦合节奏信用分配策略达到了63.1%的准确率,相比GRPO基线方法提升了10.5个百分点。在数学推理基准测试上,所提策略同样展现了一致的性能提升,特别是在复杂任务上(如AIME25和OlympiadBench),提升效果更为显著。
3. 策略有效性与鲁棒性
通过对比实验发现,所提策略相比随机信用分配和高熵信用分配等替代策略具有显著优势。
此外,通过不同Top-k比例的消融实验,验证了策略的鲁棒性,表明合理选择关键令牌进行信用分配是提升性能的关键。
研究局限
尽管本研究在揭示LLMs内部推理结构和设计细粒度RL策略方面取得了显著进展,但仍存在一些局限性:
- 注意力机制的局限性:本研究主要基于自注意力机制进行分析,然而,LLMs中可能包含其他类型的注意力机制(如稀疏注意力、动态注意力等),这些机制在推理过程中的作用尚未得到充分探讨。
- 任务多样性:实验主要在数学推理和简单逻辑谜题上进行,这些任务虽然能够体现模型的推理能力,但可能无法全面反映模型在其他类型任务(如自然语言理解、生成任务)上的表现。
- 模型规模:实验主要在中等规模的LLMs上进行(如Qwen3-4B-Base和Qwen3-8B-Base),这些模型虽然能够展示所提策略的有效性,但可能无法充分体现大规模模型在复杂推理任务上的潜力。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
- 扩展注意力机制分析:研究其他类型的注意力机制在LLMs推理过程中的作用,揭示更全面的推理结构。同时,探索不同注意力机制之间的相互作用和协同效应。
- 多样化任务评估:在更多类型的任务上评估所提策略的有效性,包括自然语言理解、生成任务以及跨模态推理任务等。通过多样化任务评估,验证策略的泛化能力和适应性。
- 大规模模型研究:在更大规模的LLMs上验证所提策略的有效性,探索大规模模型在复杂推理任务上的潜力。同时,研究大规模模型在训练过程中的稳定性和收敛速度等问题。
- 可解释性与透明度提升:进一步研究如何提升LLMs的可解释性和透明度,使研究人员和用户能够更好地理解模型的推理过程和决策依据。通过设计更直观的可视化工具和解释方法,降低模型的使用门槛和信任成本。