【Java面试笔记:多线程】44、深入Java线程池:BlockingQueue实现全景解析与实战指南

在Java并发编程体系中,ThreadPoolExecutor作为线程资源管理的核心组件,其性能与稳定性直接取决于核心参数的合理配置。其中,阻塞队列(BlockingQueue) 作为任务缓冲的关键载体,承担着"削峰填谷"的核心作用——它不仅决定了任务的存储方式,更深刻影响线程池的任务调度逻辑、并发性能与资源占用。
本文将基于阻塞队列的实现特性,结合线程池运行机制,通过源码解析、代码实战与多维度对比,系统梳理5种核心BlockingQueue的选型逻辑,助力开发者构建高效稳定的并发系统。
一、ThreadPoolExecutor与BlockingQueue的协同机制
在深入具体实现之前,必须先明确阻塞队列在线程池中的核心定位。ThreadPoolExecutor的任务处理流程本质是线程资源与任务缓冲的动态匹配过程,而BlockingQueue正是连接两者的关键枢纽。
1.1 线程池任务处理的核心流程
根据ThreadPoolExecutor.execute()方法的源码逻辑,任务提交后将遵循严格的处理顺序(如图1所示):
- 当运行线程数 < 核心线程数(corePoolSize)时,直接创建新线程执行任务,无需入队;
- 当运行线程数 ≥ 核心线程数时,任务优先进入阻塞队列等待;
- 若队列已满且运行线程数 < 最大线程数(maximumPoolSize),创建非核心线程执行任务;
- 若队列已满且线程数达到最大值,触发拒绝策略(RejectedExecutionHandler)。
图1:ThreadPoolExecutor任务处理流程图
这一流程揭示了阻塞队列的双重角色:在正常流量下作为"任务仓库",在流量峰值时作为"扩容触发器"。队列的容量、存储效率与并发性能,直接决定了线程池对流量波动的适配能力。
1.2 阻塞队列的核心契约
BlockingQueue接口在Queue基础上扩展了阻塞式操作,核心方法包括:
put(E e):队列满时阻塞生产者线程,直到队列有空闲位置;take():队列空时阻塞消费者线程,直到队列有可用元素;offer(E e, long timeout, TimeUnit unit):队列满时阻塞指定时间,超时后返回false;poll(long timeout, TimeUnit unit):队列空时阻塞指定时间,超时后返回null。
这些方法通过ReentrantLock与Condition实现线程安全与阻塞唤醒机制,确保多线程环境下的操作原子性。不同实现类的差异主要体现在容量设计、数据结构、锁策略三个维度,这也是后续选型的核心依据。
二、核心BlockingQueue实现深度解析
JDK提供了7种BlockingQueue实现,
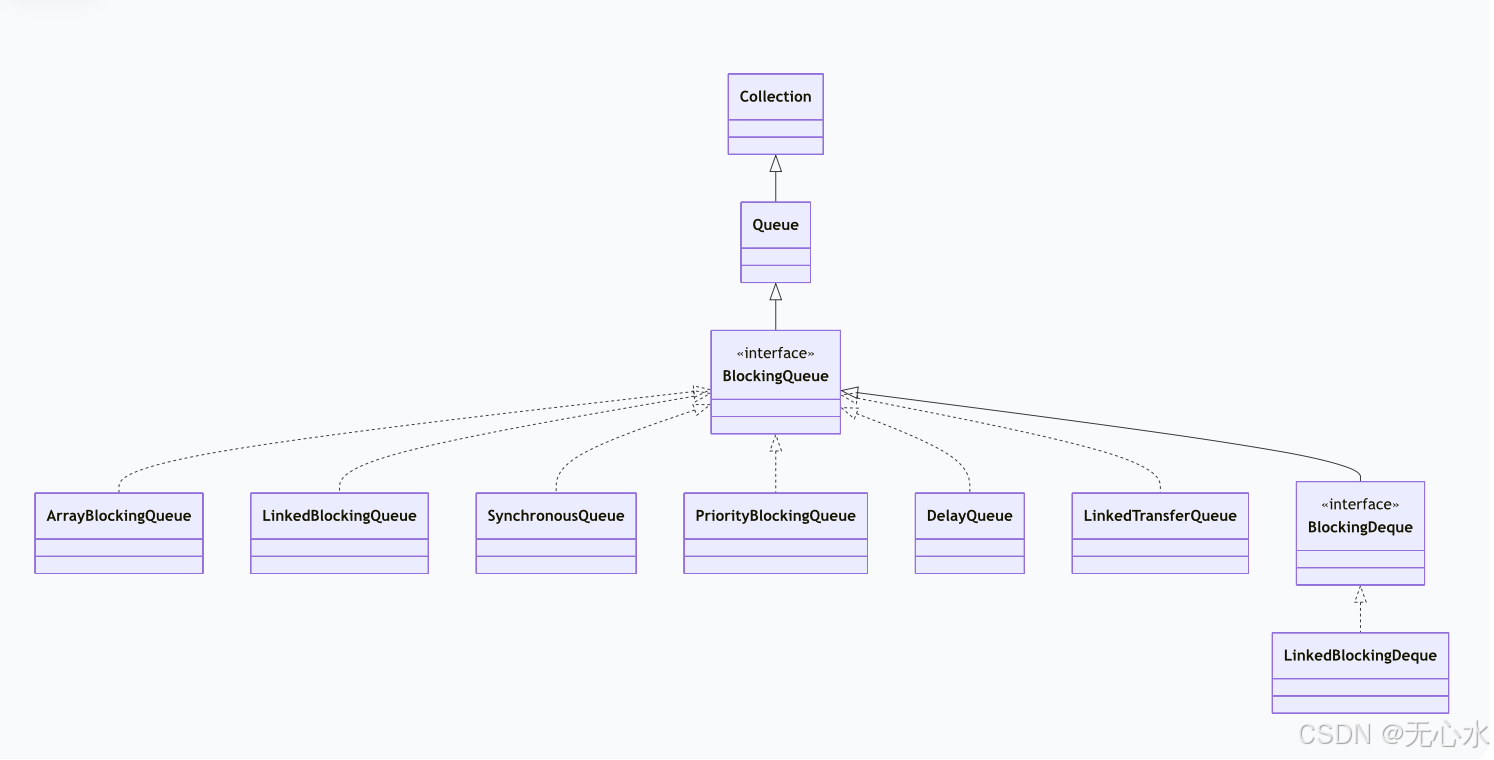
其中ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue与DelayQueue是线程池配置中的常用选择。以下将从特性、源码、实战三个层面逐一剖析。
2.1 ArrayBlockingQueue:数组实现的有界队列
ArrayBlockingQueue是最经典的有界阻塞队列,基于固定大小的数组实现,具有内存占用可控、操作高效的特点,是流量可预估场景的首选。
2.1.1 核心特性
| 维度 | 特性描述 |
|---|---|
| 容量特性 | 必须指定初始容量,创建后不可修改 |
| 数据结构 | 循环数组(减少数组迁移开销) |
| 锁机制 | 单把ReentrantLock控制读写操作 |
| 排序规则 | FIFO(先进先出) |
| 扩容能力 | 不可扩容 |
| 内存效率 | 无节点开销,空间利用率高 |
2.1.2 源码解析:单锁模型与循环数组
ArrayBlockingQueue的核心设计是循环数组+单锁机制,其关键成员变量如下:
// 存储元素的数组
final Object[] items;
// 出队索引(take、poll等操作使用)
int takeIndex;
// 入队索引(put、offer等操作使用)
int putIndex;
// 元素数量
int count;
// 控制并发访问的重入锁
final ReentrantLock lock;
// 队列非空条件(唤醒消费者)
private final Condition notEmpty;
// 队列非满条件(唤醒生产者)
private final Condition notFull;
入队流程(enqueue方法):
private void enqueue(E x) {final Object[] items = this.items;// 放入当前putIndex位置items[putIndex] = x;// 索引循环递增(到达数组末尾则回到起点)if (++putIndex == items.length)putIndex = 0;count++;// 唤醒等待的消费者线程notEmpty.signal();
}
出队流程(dequeue方法):
private E dequeue() {final Object[] items = this.items;@SuppressWarnings("unchecked")// 取出当前takeIndex位置的元素E x = (E) items[takeIndex];// 清空该位置(帮助GC)items[takeIndex] = null;// 索引循环递增if (++takeIndex == items.length)takeIndex = 0;count--;if (itrs != null)itrs.elementDequeued();// 唤醒等待的生产者线程notFull.signal();return x;
}
单锁机制简化了实现逻辑,但也带来了读写互斥的性能瓶颈——当生产者线程持有锁进行入队时,消费者线程必须阻塞等待,反之亦然。这一特性决定了它更适合任务执行时间较长、并发读写压力适中的场景。
2.1.3 线程池实战:流量控制场景
在电商订单处理等需要严格控制资源占用的场景,ArrayBlockingQueue的有界特性可有效防止任务无限堆积导致的OOM(内存溢出)。以下是结合线程池的实战示例:
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;/*** ArrayBlockingQueue线程池实战:订单处理系统(控制任务堆积上限)*/
public class ArrayBlockingQueueDemo {// 任务计数器private static final AtomicInteger TASK_COUNTER = new AtomicInteger(0);public static void main(String[] args) {// 1. 配置线程池参数(核心线程2,最大线程4,队列容量3)ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS,// 有界队列:最多缓存3个任务new ArrayBlockingQueue<>(3),// 自定义线程工厂(命名线程便于排查问题)r -> new Thread(r, "order-thread-" + TASK_COUNTER.incrementAndGet()),// 队列满+线程满时触发:调用者线程执行任务new ThreadPoolExecutor.CallerRunsPolicy());// 2. 模拟提交10个订单任务(每个任务执行1秒)for (int i = 1; i <= 10; i++) {int orderId = i;executor.execute(() -> {try {// 模拟订单处理耗时Thread.sleep(1000);System.out.printf("[%s] 处理订单完成,订单ID:%d%n",Thread.currentThread().getName(), orderId);} catch (InterruptedException e) {Thread.currentThread().interrupt();System.out.printf("订单%d处理被中断%n", orderId);}});System.out.printf("提交订单%d,当前队列任务数:%d%n",i, executor.getQueue().size());}// 3. 优雅关闭线程池executor.shutdown();try {if (!executor.awaitTermination(10, TimeUnit.SECONDS)) {executor.shutdownNow();}} catch (InterruptedException e) {executor.shutdownNow();}}
}
运行结果分析:
提交订单1,当前队列任务数:0
提交订单2,当前队列任务数:0
提交订单3,当前队列任务数:1
提交订单4,当前队列任务数:2
提交订单5,当前队列任务数:3
提交订单6,当前队列任务数:3
提交订单7,当前队列任务数:3
[order-thread-1] 处理订单完成,订单ID:1
[order-thread-2] 处理订单完成,订单ID:2
提交订单8,当前队列任务数:2
提交订单9,当前队列任务数:3
提交订单10,当前队列任务数:3
[order-thread-3] 处理订单完成,订单ID:3
[order-thread-4] 处理订单完成,订单ID:4
[main] 处理订单完成,订单ID:10 // 调用者线程执行被拒绝的任务
...
当提交第6个任务时,队列已满(容量3),线程池开始创建非核心线程(第3、4个线程);提交第10个任务时,线程数已达最大值4,触发CallerRunsPolicy,由主线程直接执行任务。这一过程完美体现了有界队列对流量的控制能力。
2.2 LinkedBlockingQueue:链表实现的高吞吐队列
LinkedBlockingQueue基于单向链表实现,默认采用无界设计,通过双锁机制实现读写分离,在高并发场景下具有更优的吞吐量,是JDK预定义线程池FixedThreadPool的默认队列。
2.2.1 核心特性
| 维度 | 特性描述 |
|---|---|
| 容量特性 | 默认无界(Integer.MAX_VALUE),可指定初始容量 |
| 数据结构 | 单向链表(节点包含前驱指针与数据) |
| 锁机制 | 两把ReentrantLock(putLock/takeLock)分离读写 |
| 排序规则 | FIFO(先进先出) |
| 扩容能力 | 无界模式下自动增长,有界模式不可扩容 |
| 内存效率 | 节点有额外指针开销,空间利用率低 |
2.2.2 源码解析:双锁模型与读写分离
LinkedBlockingQueue通过分离入队与出队锁,实现了生产者-消费者并行操作,其核心成员变量如下:
// 链表节点
static class Node<E> {E item;Node<E> next;Node(