bge-base embedder论文解读
-
论文标题:C-Pack: Packed Resources For General Chinese Embeddings
-
论文地址:https://arxiv.org/pdf/2309.07597
-
论文发布时间:2023 年 9 月 14 日
本篇论文很多都是对工作量的叙述,技术性较弱,读起来 20 分钟就能看完。放心食用~
论文有开源的代码和 python 库FlagEmbedding,其代码库是我目前见过结构、优雅性最好的 py 包之一。
关于 BGE- C-Pack 需要掌握的知识
BGE-base 系列模型结构
BGE-base 系列模型训练流程
对于 BAAI 开源的整个 python 库FlagEmbedding,其提供的核心功能分为嵌入模型和重排模型,每种功能又分为 Encoder 和 Decoder,然后还可以根据技术再细分。
本篇论文就是下图中的BaseEmbedder模型的分支。
Abstract
论文的贡献是 C-Pack,一套能推动中文通用文本嵌入领域发展的资源包。C-Pack 包含三项关键资源。
-
C-MTP 是一个大规模的文本嵌入训练数据集,它基于对海量无标注语料的整理以及高质量标注语料的整合。
-
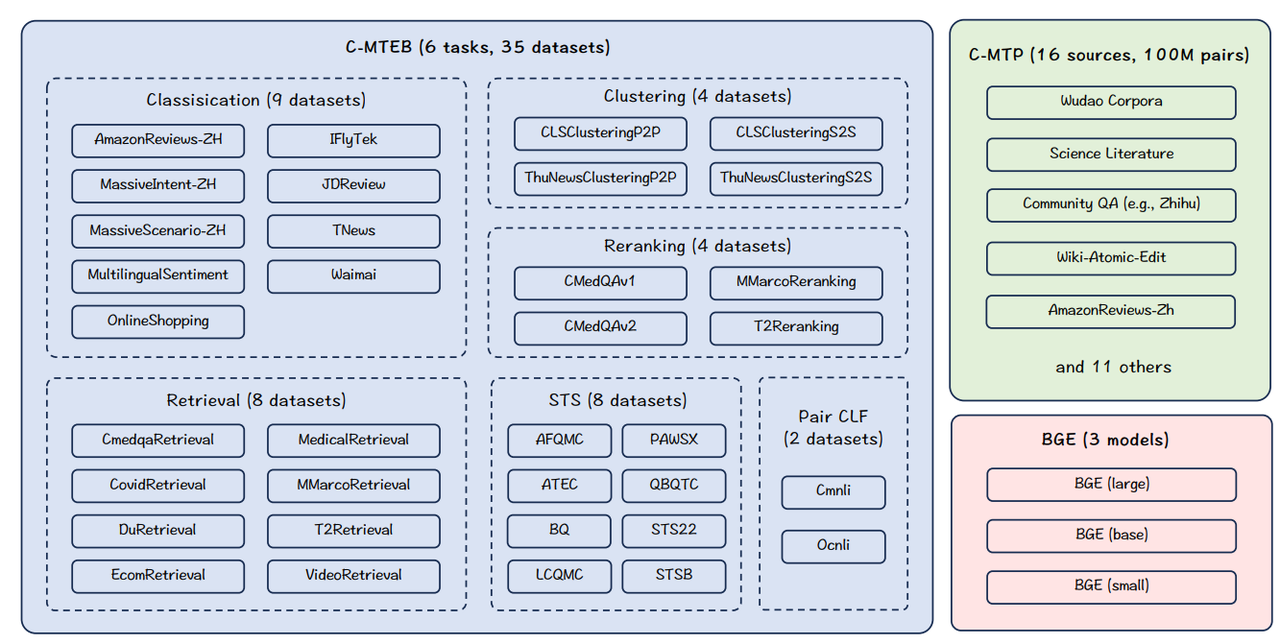
C-MTEB 是一个全面的中文文本嵌入基准,涵盖 6 项任务和 35 个数据集。
-
BGE 是一个涵盖多种规模的嵌入模型系列。模型在 C-MTEB 上的表现超过了所有以往的中文文本嵌入模型,提升幅度超过 10%。
Introduction
各种各样的应用场景需要一个单一的统一嵌入模型,该模型能够在任何应用场景(例如问答、语言建模、对话)中处理各种用途(如检索、排序、分类)。然而,学习通用文本嵌入比学习特定任务的文本嵌入更具挑战性。以下因素至关重要:
-
数据。通用文本嵌入的发展对训练数据提出了更高的要求,具体体现在规模、多样性和质量。
-
训练。通用文本嵌入的训练取决于两个关键要素:一个合适的 backbone 编码器和一个恰当的训练方案。训练通用文本嵌入并非依赖单一算法,而是需要复合方案。具体而言,需要面向嵌入的预训练来准备文本编码器,需要结合复杂负采样的对比学习来提高嵌入的辨别能力,还需要基于指令的微调来整合文本嵌入的不同表示能力。
-
基准。另一个先决条件是建立适当的基准,通过这些基准可以全面评估文本嵌入的所有必要能力。
近年来,该领域取得了持续进展,例如 Contriever、E5、GTR 和 OpenAI 文本嵌入。然而这些模型大多专注于以英语为中心的场景。相比之下,具有竞争力的通用中文嵌入模型十分匮乏。
为了应对上述挑战,论文提出了一个名为 C-Pack 的资源包,它从以下几个方面为通用中文嵌入的发展做出贡献。
-
C-MTEB(中文大规模文本嵌入基准)。该基准是作为 MTEB 的中文扩展而建立的。C-MTEB 收集了 35 个公开可用的数据集,这些数据集分属 6 类任务。
-
C-MTP(中文大规模文本对)。这是一个包含 1 亿个文本对的大规模训练数据集。该数据集的大部分内容来自海量网络语料库,例如百度百科、知乎以及中国的主要新闻网站。利用数据中丰富的结构化信息提取语义相关的文本对,如标题与文档、副标题与段落、问题与答案、问题与相似问题等。提取的数据会经过进一步清洗,用于文本嵌入的大规模弱监督训练。还整合了多种标记数据集,为文本嵌入的最终优化提供高质量的监督信号。
-
BGE(北京人工智能研究院通用嵌入模型)。提供了一系列训练良好的中文通用文本嵌入模型。有三种可选的模型规模:小型(2400 万参数)、基础型(1.02 亿参数)和大型(3.26 亿参数)。
-
训练方案。论文还整合并优化了训练方法,以构建通用文本嵌入,包括面向嵌入的文本编码器的预训练、通用对比学习和特定任务微调。
C-Pack
Benchmark: C-MTEB
论文收集了总共 35 个与中文文本嵌入评估相关的公开数据集。所收集的数据集根据其可能评估的嵌入能力进行分类,评估任务分为 6 组:检索、重排序、STS(语义文本相似度)、分类、配对分类和聚类,每个类别下都有多个数据集。
-
检索。检索任务需要处理测试查询和一个大型语料库。对于每个查询,它会在语料库中找到最相似的前𝑘个文档。检索质量可以通过不同截断点的排序和召回率指标来衡量。NDCG@10 作为主要指标。
-
重排序。重排序任务会给出测试查询及其候选文档(1 个正面文档加 N 个负面文档)。对于每个查询,它会根据嵌入相似度对文档进行重排序。平均准确率(MAP)分数被用作主要指标。
-
STS(语义文本相似度)。STS 任务是基于两个句子的嵌入相似度来衡量它们的相关性。使用给定的标签计算斯皮尔曼相关系数为主要指标。
-
分类。分类任务平均精度被用作主要指标。
-
句子对分类。该任务处理一对输入句子,其关系由二值化标签表示。通过嵌入相似度来预测这种关系,其中平均精度被用作主要指标。
-
聚类。聚类任务是将句子分组为有意义的簇。使用小批量 k 均值方法进行评估,批量大小为 32,k 等于小批量内的标签数量。V-measure 分数被用作主要指标。
Training Data: C-MTP
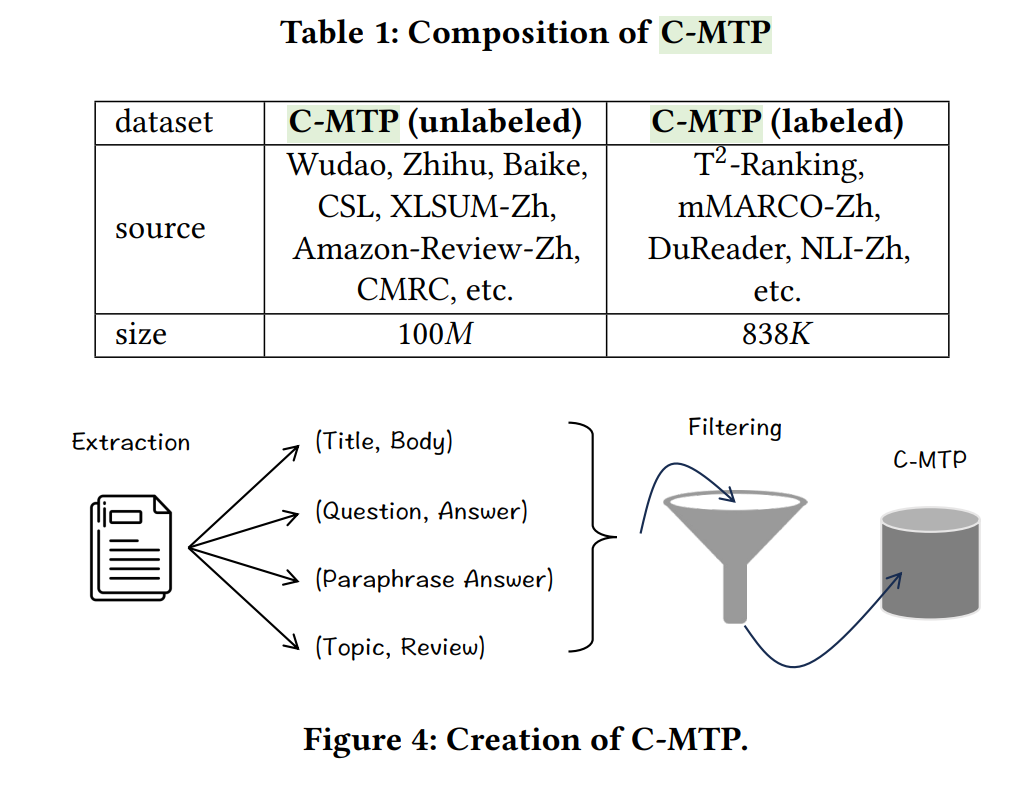
论文构建了最大的数据集 C-MTP,用于通用中文嵌入的训练。C-MTP 的数据来源于两个渠道。大部分数据基于对海量无标签数据的整理,即 C-MTP(无标签),包含 1 亿对文本。同时,小部分数据来自对高质量有标签数据的综合整合,即 C-MTP(有标签),约有 100 万对文本。数据收集过程简要介绍如下。
C-MTP(无标签)。寻找各种各样的语料库,从中可以从纯文本中提取丰富语义的成对结构。数据主要来源是开放网络语料库,对于每篇文章,都会提取诸如(标题、正文)、(副标题、段落)等结构,以形成文本对。此外,还从知乎、百科、新闻网站等其他网络内容中收集数据,这些数据补充了其他形式的文本对,特别是(问题、答案)、(标题改写)、(答案改写)等。除了公开的网络内容,还探索了其他公开的中文数据,例如 CSL(科学文献)、Amazon-Review-Zh(主题及其评论)、Wiki Atomic Edits(改写文本)、CMRC(机器阅读理解)、XLSUM-Zh(摘要)等。
C-MTP(有标签)。收集有标签的数据是为了进一步扩充训练数据。包含以下有标签的数据集:T2−RankingT^{2}-RankingT2−Ranking、DuReader、mMARCO、CMedQA-v2、multi-cpr、NLI-Zh、cmnli 和 ocn li。总共有 838,465 对文本,包含了各种问答和释义模式。
Model Class: BGE
BGE-base 系列模型基于类 BERT 架构,经过三个阶段的训练。有三种规模可供选择:大型(含 3.26 亿参数)、基础型(含 1.02 亿参数)和小型(含 2400 万参数)。
Training Recipe

BGE 的训练方案包含三个主要部分:
1)使用纯文本进行预训练;
2)使用 C-MTP(无标签)进行对比学习;
3)使用 C-MTP(有标签)进行多任务学习。
预训练。模型在海量纯文本上进行预训练,以更好地支持嵌入任务。采用了 RetroMAE 中提出的 MAE 风格方法,该方法简单但高效。被污染的文本被编码为其嵌入,然后通过轻量级解码器从该嵌入中恢复出干净的文本:
min⋅∑x∈X−logDec(x∣eX~),eX~←Enc(X~)min \cdot \sum_{x \in X}-log Dec\left(x | e_{\tilde{X}}\right), e_{\tilde{X}} \leftarrow Enc(\tilde{X})min⋅∑x∈X−logDec(x∣eX~),eX~←Enc(X~)
通用微调。预训练模型通过对比学习在 C-MTP(无标签)上进行微调,旨在学习区分成对文本与其负样本:
min⋅∑(p,q)−loge(ep,eq)/τe(ep,eq)/τ+∑Q′e(ep,eq′)/τmin \cdot \sum_{(p, q)}-log \frac{e^{\left(e_{p}, e_{q}\right) / \tau}}{e^{\left(e_{p}, e_{q}\right) / \tau}+\sum_{Q'} e^{\left(e_{p}, e_{q'}\right) / \tau}}min⋅∑(p,q)−loge(ep,eq)/τ+∑Q′e(ep,eq′)/τe(ep,eq)/τ
其中,p 和 q 是成对文本,q′∈Q′q' \in Q'q′∈Q′是负样本,𝜏是温度。对比学习的一个关键因素是负样本。论文没有刻意挖掘难负样本,而是完全依赖批次内负样本,并采用较大的批次大小(高达 19,200)来提高嵌入的辨别能力。
特定任务微调。嵌入模型使用带标签的 C-MTP 进一步微调。带标签的数据集规模较小,但质量更高。然而,其中包含的任务类型不同,其影响可能相互矛盾。采用两种策略来缓解这一问题。
一方面,利用基于指令的微调,通过区分输入来帮助模型适应不同的任务。对于每个文本对,在查询侧附加一个特定任务指令It:q′←q+ItI_{t}:q' \leftarrow q+I_{t}It:q′←q+It。该指令是一个语言提示,用于明确任务的性质,例如“search relevant passages for the query”。
另一方面,更新负采样:除了批次内负样本外,为每个文本对挖掘一个难负样本。
Experiments
General Evaluation
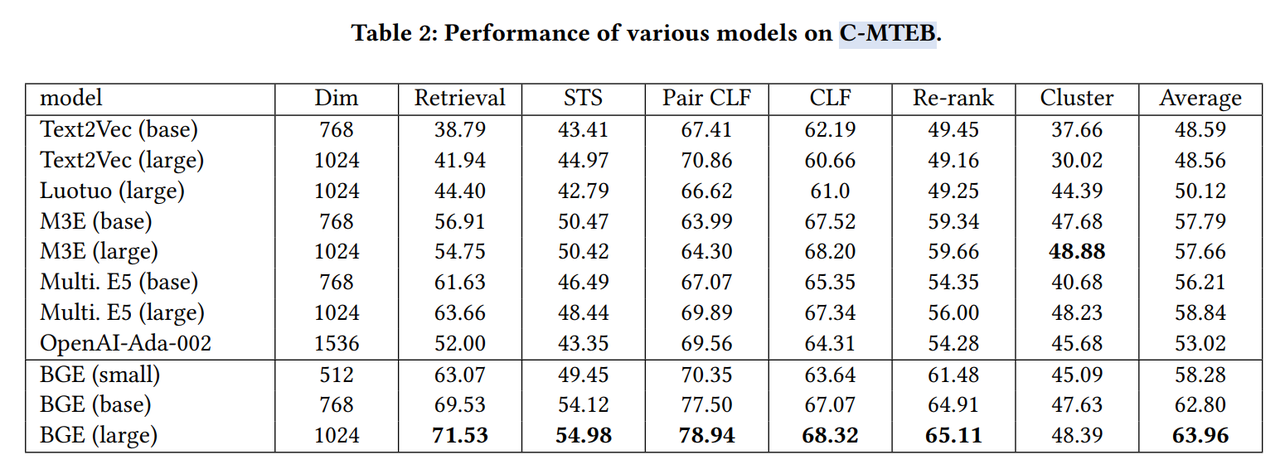
论文的模型大幅超越了现有的中文文本嵌入模型。这不仅体现在平均性能上的压倒性优势,还在 C-MTEB 的大多数任务中都有显著提升。提升最明显的是检索任务,其次是 STS、句子对分类和重排序任务。
Detailed Analysis
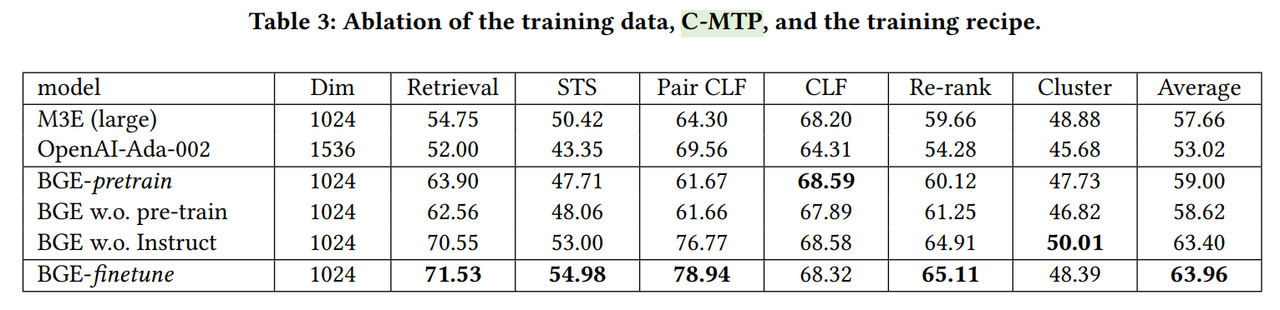
先分析训练数据 C-MTP 的影响。
C-MTP 由两部分组成。1)C-MTP(无标签),用于通用微调;此阶段生成的模型称为中间检查点,记为 BGE-pretrain。2)C-MTP(有标签),在 BGE-pretrain 的基础上进一步进行特定任务微调;此阶段生成的模型称为最终检查点,记为 BGE-finetune。从实验结果中的观察,C-MTP(无标签)和 C-MTP(有标签)都对嵌入质量有显著贡献。
然后分析指令微调的影响。
在特定任务微调过程中对指令的运用,特定任务指令充当硬提示。它会区分嵌入模型的激活状态,使模型能更好地适应各种不同的任务。通过移除这一操作进行了消融研究,记为“w.o. Instruct”。
再分析预训练的影响。
论文使用专门预训练的文本编码器来训练 BGE,而不是使用像 BERT 和 RoBERTa 这样的常见选择。为了探究其影响,将预训练文本编码器替换为广泛使用的 Chinese-RoBERTa,记为“BGE w.o. pre-train”。
最终消融结果见表 3。
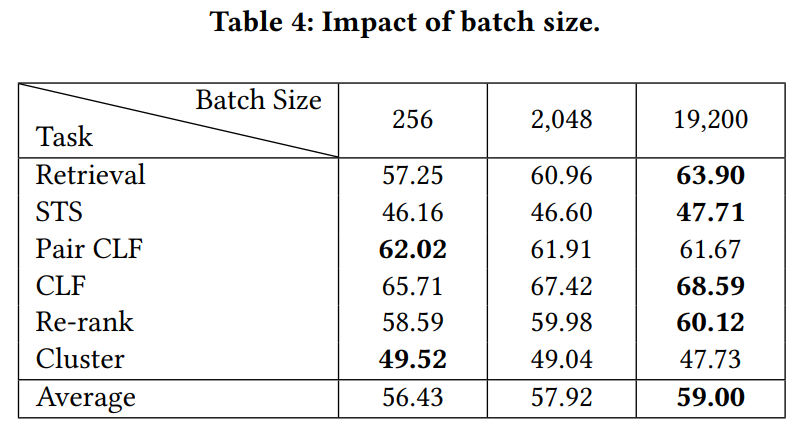
最后分析训练 batch 的影响。
论文训练方案的一个显著特点是,在对比学习中采用了较大的批次大小。根据以往的研究,嵌入模型的学习可能会受益于负样本数量的增加。由于依赖批次内的负样本,因此需要尽可能扩大批次大小。通过对批次大小(记为 bz)分别为 256、2028 和 19,200 的情况进行对比,发现随着批次大小的增加,嵌入质量有持续的提升。其中,检索性能的提升最为显著。这可能是因为检索通常是在大型数据库上进行的,此时嵌入需要具有高度的区分性。